文章目录
- 一、数据库编程
- 1.1 connect()函数
- 1.2 命令参数
- 1.3 常用语句
- 二、正则表达式
- 2.1 匹配方式
- 2.2 字符匹配
- 2.3 数量匹配
- 2.4 边界匹配
- 2.5 分组匹配
- 2.6 贪婪模式&非贪婪模式
- 2.7 标志位
一、数据库编程
- 可以使用python脚本对数据库进行操作,比如获取数据库数据保存到文件中,这个功能可以通过数据库相关模块进行实现。
- 在python2.x版本中使用的是MySQLdb模块,python3.x版本中使用的是pymysql模块,两者用法几乎相同。
- pymysql是第三方模块,需要单独安装,首选通过pip安装PyMySQL。
- 对不同类型的数据库操作,需要安装导入的模块也不同。
1.1 connect()函数
- connect()函数:用来建立和数据库的连接。
| connect()函数常用参数 | 描述 |
|---|---|
| host | 数据库主机地址 |
| user | 数据库账户 |
| passwd | 账户密码 |
| db | 使用的数据库 |
| port | 数据库主机端口,默认3306 |
| connect_timeout | 连接超时时间,默认10,单位秒 |
| charset | 使用的字符集 |
| cursorclass | 自定义游标使用的类。上面示例用的是字典类,以字典形式返回结果,默认是元组形式。 |
1.安装pymysql模块。
pip3 install pymysql
2.准备好数据库信息。
##安装数据库实例。
docker run -d --name qingjun -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7.30##创建数据库和表,用来测试。
create database test;
use test;
create table user(id int primary key not null auto_increment,username varchar(50) not null,password varchar(50) not null);
3.连接数据库,开始操作数据库。
import pymysql##数据库信息。
conn = pymysql.connect(host='192.168.161.132',port=3306,user='root',password='123456',db='test',charset='utf8',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor() ##建立数据库连接。# 创建一条记录.
sql = "insert into user(username, password) values('qingjun', '123456')"
cursor.execute(sql) ##执行sql语句。
conn.commit() ##写入到数据库。
4.查看数据库数据。

1.2 命令参数
| 连接对象常用方法 | 描述 |
|---|---|
| commit() | 提交事务。对支持事务的数据库和表,如果提交修改操作,不适用这个方法,则不会写到数据库中 |
| rollback() | 事务回滚。对支持事务的数据库和表,如果执行此方法,则回滚当前事务。在没有commit()前提下。 |
| cursor([cursorclass]) | 创建一个游标对象。所有的sql语句的执行都要在游标对象下进行。MySQL本身不支持游标,MySQLdb模块对其游标进行了仿真。 |
| 游标对象常用方法 | 描述 |
|---|---|
| close() | 关闭游标 |
| execute(sql) | 执行sql语句 |
| executemany(sql) | 执行多条sql语句 |
| fetchone() | 从运行结果中取第一条记录,返回字典 |
| fetchmany(n) | 从运行结果中取n条记录,返回列表 |
| fetchall() | 从运行结果中取所有记录,返回列表 |
1.3 常用语句
1.插入数据。
import pymysql
conn = pymysql.connect(host='192.168.161.132',port=3306,user='root',password='123456',db='test',charset='utf8',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()##插入一条数据。
sql = "insert into user(username, password) values('wuhan', '88')"
cursor.execute(sql)
conn.commit()
conn.close() ##关闭游标##插入多条数据。
sql = "insert into user(username, password) values(%s,%s)"
args = [('beijing',222),('shenzheng',9990)]
cursor.executemany(sql,args)
conn.commit()
conn.close() ##关闭游标

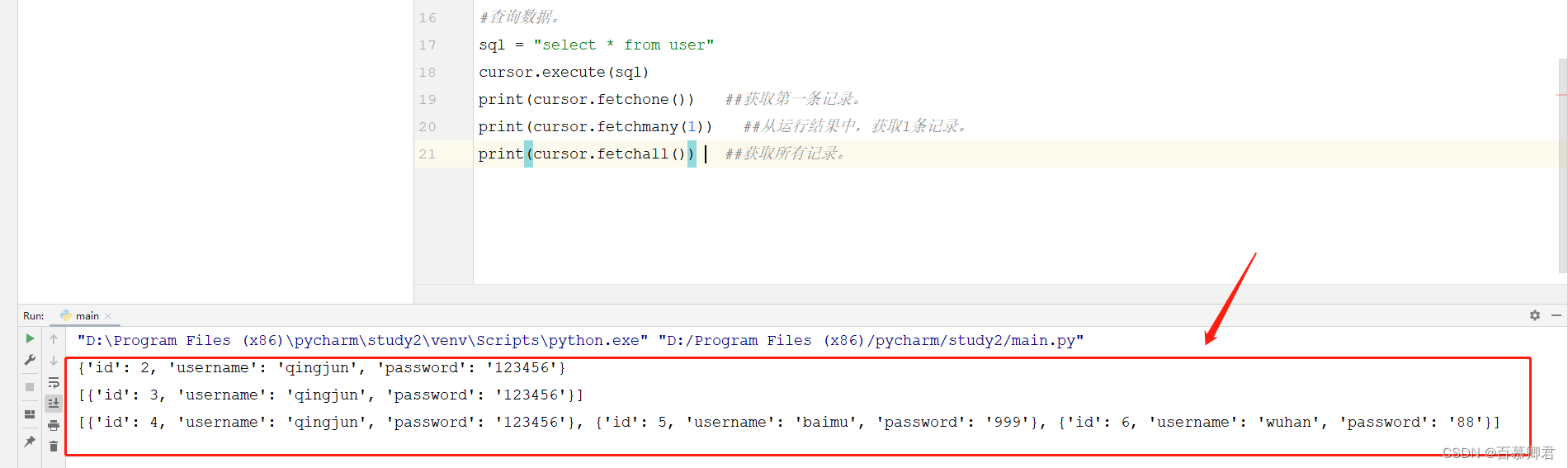
2.查询数据。
import pymysql
conn = pymysql.connect(host='192.168.161.132',port=3306,user='root',password='123456',db='test',charset='utf8',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()##查询数据。
sql = "select * from user"
cursor.execute(sql)
print(cursor.fetchone()) ##获取第一条记录。
print(cursor.fetchmany(1)) ##从运行结果中,获取1条记录。
print(cursor.fetchall()) ##获取所有记录。
conn.close() ##关闭游标
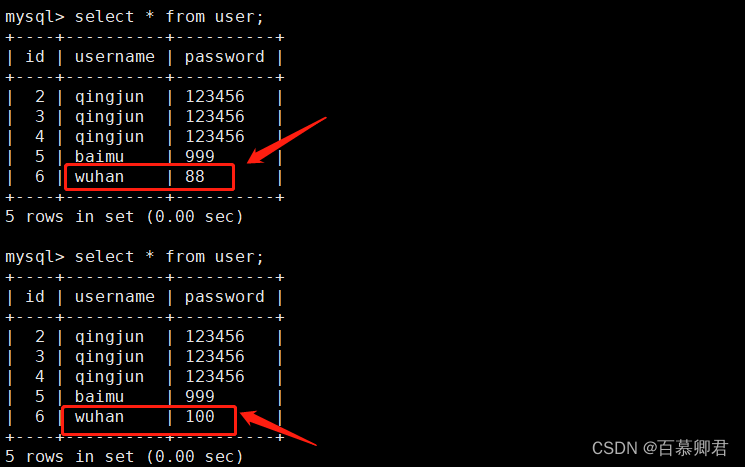
3.修改数据。
import pymysql
conn = pymysql.connect(host='192.168.161.132',port=3306,user='root',password='123456',db='test',charset='utf8',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()##修改数据。
sql = "update user set password='100' where username='wuhan'"
cursor.execute(sql)
conn.commit()
conn.close() ##关闭游标
4.删除数据。
import pymysql
conn = pymysql.connect(host='192.168.161.132',port=3306,user='root',password='123456',db='test',charset='utf8',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()##删除数据。
sql = "delete from user where username='qingjun'"
cursor.execute(sql)
conn.commit()
conn.close() ##关闭游标
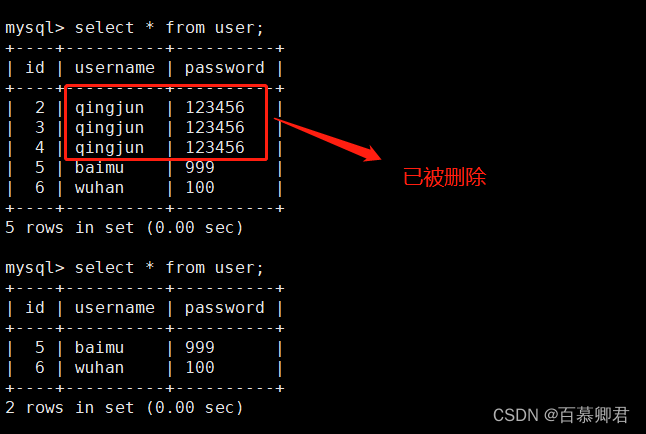
5.遍历查询结果。
try:with conn.cursor() as cursor:sql = "select id,username,password from user"cursor.execute(sql)result = cursor.fetchall()for dict in result:print(f"ID: {dict['id']}, 用户名: {dict['username']}, 密码: {dict['password']}")
finally: ##不管try是否执行成功,finally都执行。conn.close()
二、正则表达式
- 正则表达式是对字符串操作的一种逻辑方式,就是用实现定义好的一些特定字符及这些特定字符的组合,组成一个规则字符串,这个规则字符串就是表达对字符串的逻辑,给定一个正则表达式和另一个字符串,通过正则表达式从字符串我们想要的部分。
- Python正则表达式主要由re标准库提供,拥有了基本所有的表达式。
2.1 匹配方式
| 方法 | 描述 |
|---|---|
| re.compile(pattern, flags=0) | 把正则表达式编译成一个对象。 pattern 指的是正则表达式,flags是标志位的修饰符,用于控制表达式匹配模式 |
| re.match(pattern, string, flags=0) | 匹配字符串开始,如果不匹配返回None |
| re.search(pattern, string, flags=0) | 扫描字符串寻找匹配,如果符合返回一个匹配对象并终止匹配,否则返回None |
| re.split(pattern, string, maxsplit=0, flags=0) | 以匹配模式作为分隔符,切分字符串为列表 |
| re.findall(pattern, string, flags=0) | 以列表形式返回所有匹配的字符串 |
| re.finditer(pattern, string, flags=0) | 以迭代器形式返回所有匹配的字符串 |
| re.sub(pattern, repl, string, count=0, flags=0) | 字符串替换,repl替换匹配的字符串,repl可以是一个函数 |
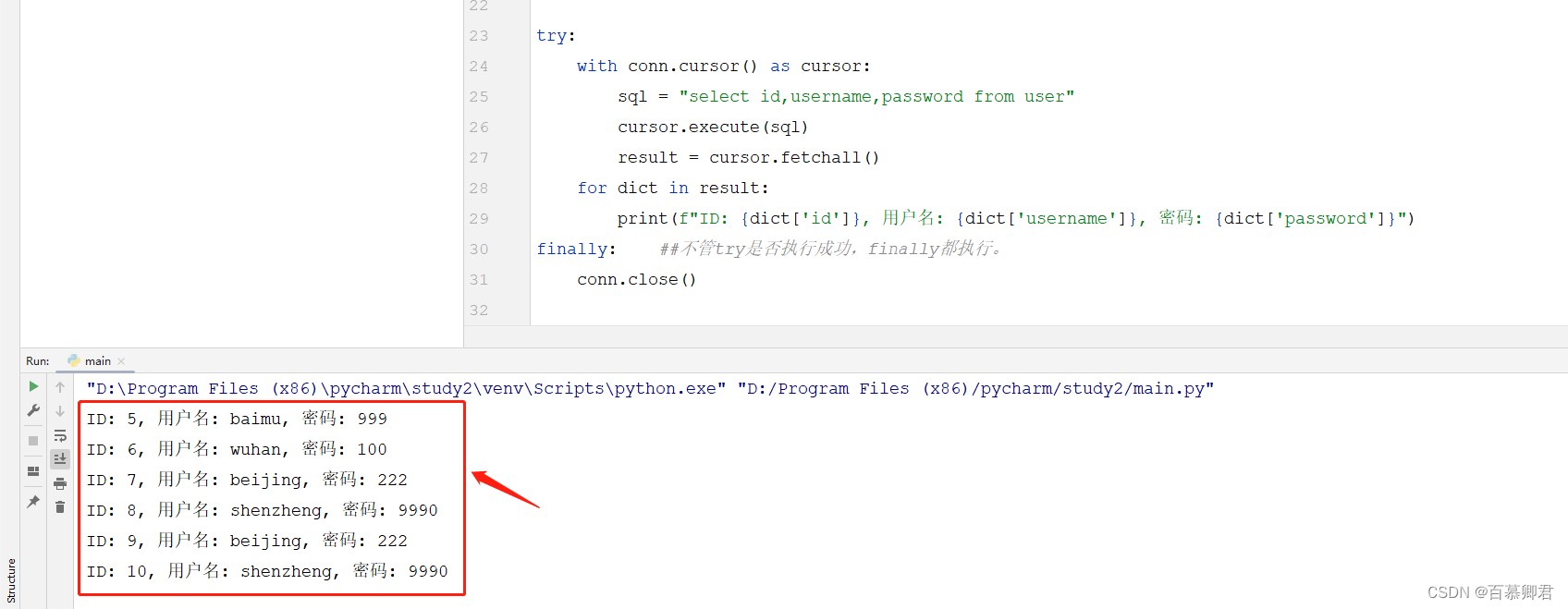
1.老方法匹配字符串。优点是,方便再次使用。
a = 'this is jdasi1!#@sjkdjalk'import re
pattern = re.compile("this") ##预定义正则表达式。
baimu = pattern.match(a) ##使用预定义的正则表达式匹配字符串,
print(baimu)
print(baimu.group()) ##过滤出匹配的字符串。
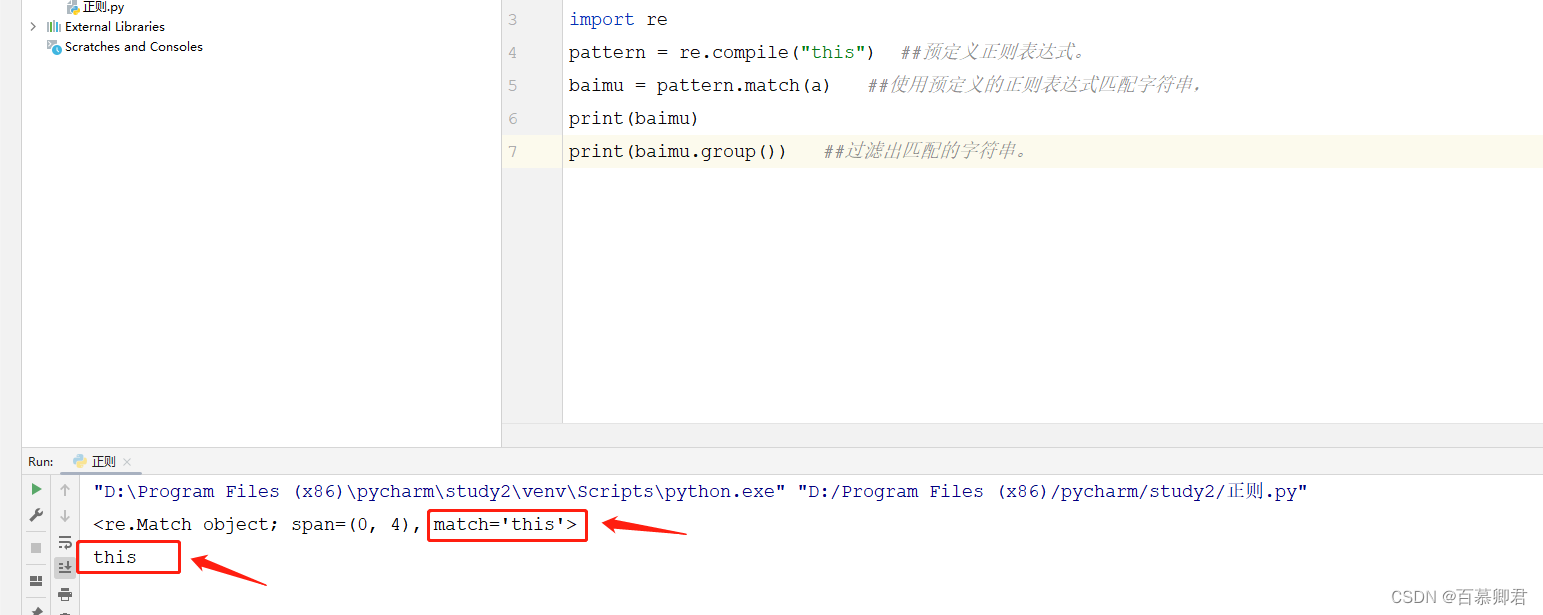
2.常用方式匹配,优点是,更直观。从第一个字符串开始匹配。
a = 'this is jdasi1!#@sjkdjalk'import re
qingjun = re.match("this",a)
print(qingjun.group())
3.扫描匹配。
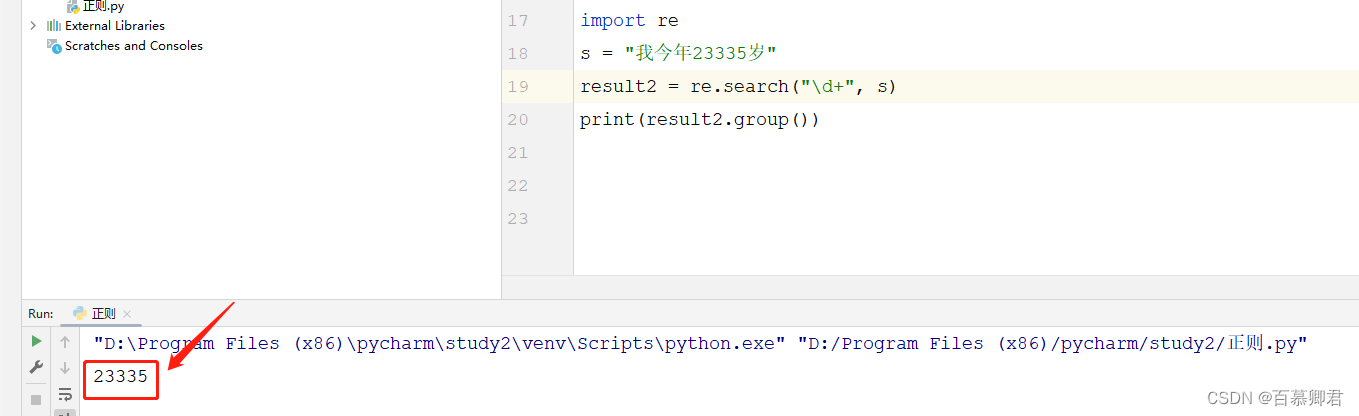
import re
s = "我今年23335岁"
result2 = re.search("\d+", s)
print(result2.group())
4.以匹配模式作为分隔符,切分字符串为列表。
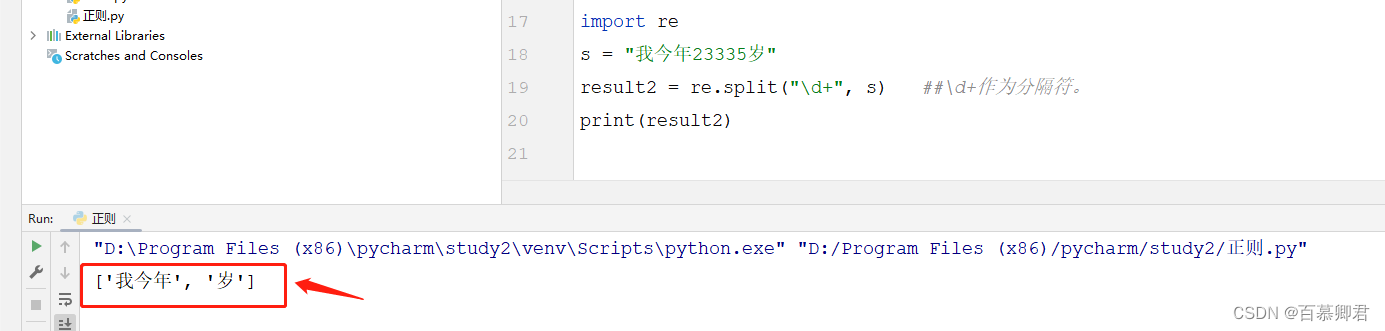
import re
s = "我今年23335岁"
result2 = re.split("\d+", s) ##\d+作为分隔符。
print(result2)
5.以列表形式返回所有匹配的字符串。
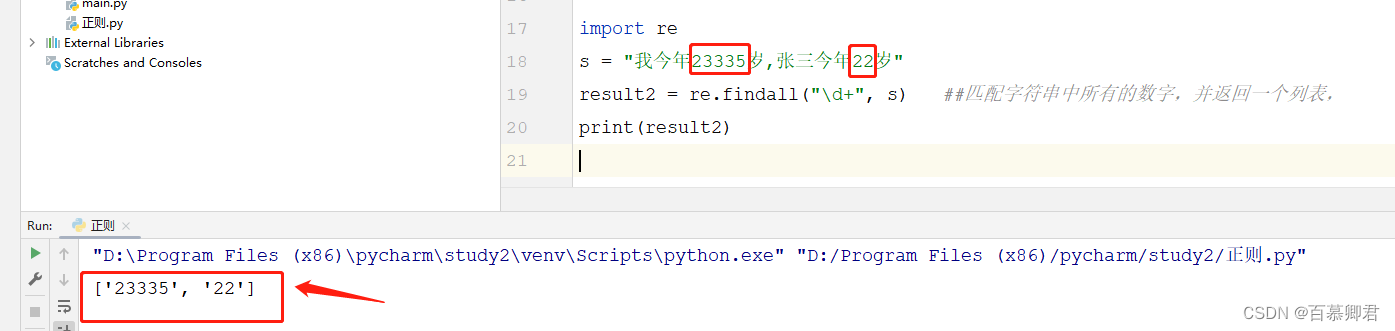
import re
s = "我今年23335岁,张三今年22岁"
result2 = re.findall("\d+", s) ##匹配字符串中所有的数字,并返回一个列表,
print(result2)
6.替换匹配。
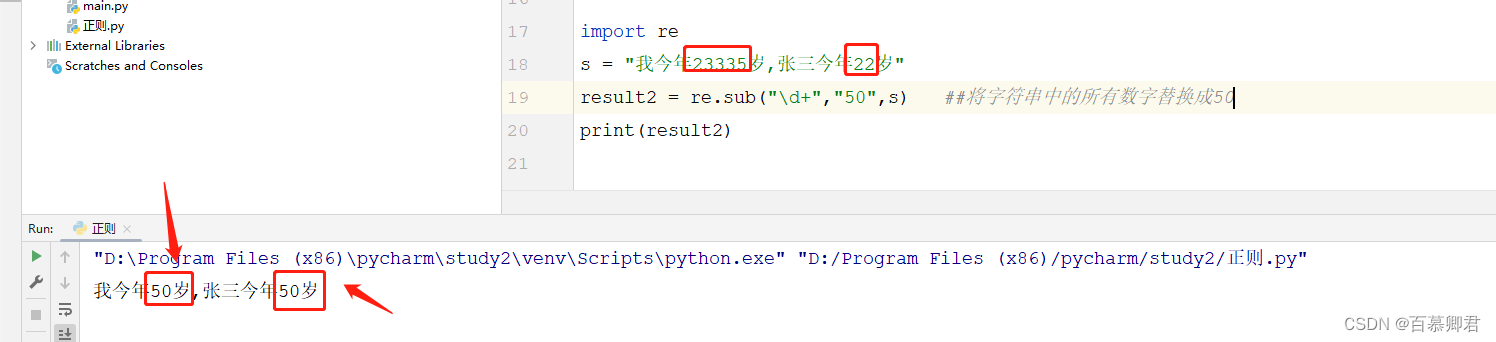
import re
s = "我今年23335岁,张三今年22岁"
result2 = re.sub("\d+","50",s) ##将字符串中的所有数字替换成50
print(result2)
2.2 字符匹配
| 字符匹配 | 描述 |
|---|---|
| . | 任意单个字符(除了\n) |
| [ ] | 匹配中括号中的任意1个字符。并且特殊字符写在[ ]会被当成普通字符来匹配 |
| [ .-.] | 匹配中括号中范围内的任意1个字符,例如[a-z],[0-9] |
| [^] | 匹配 [^字符] 之外的任意一个字符 |
| \d | 匹配数字,等效[0-9] |
| \D | 匹配非数字字符,等效[^0-9] |
| \s | 匹配单个空白字符(空格、Tab键),等效[\t\n\r\f\v] |
| \S | 匹配空白字符之外的所有字符,等效[^\t\n\r\f\v] |
| \w | 匹配字母、数字、下划线,等效[a-zA-Z0-9_] |
| \W | 与\w相反,等效[^a-zA-Z0-9_] |
1.匹配单个字符,使用"."
a = 'this is jdasi1!#@sjkdjalk'
import reqingjun1 = re.match(".",a)
qingjun2 = re.match("..",a)
qingjun3 = re.match("...",a)
print(qingjun1.group())
print(qingjun2.group())
print(qingjun3.group())
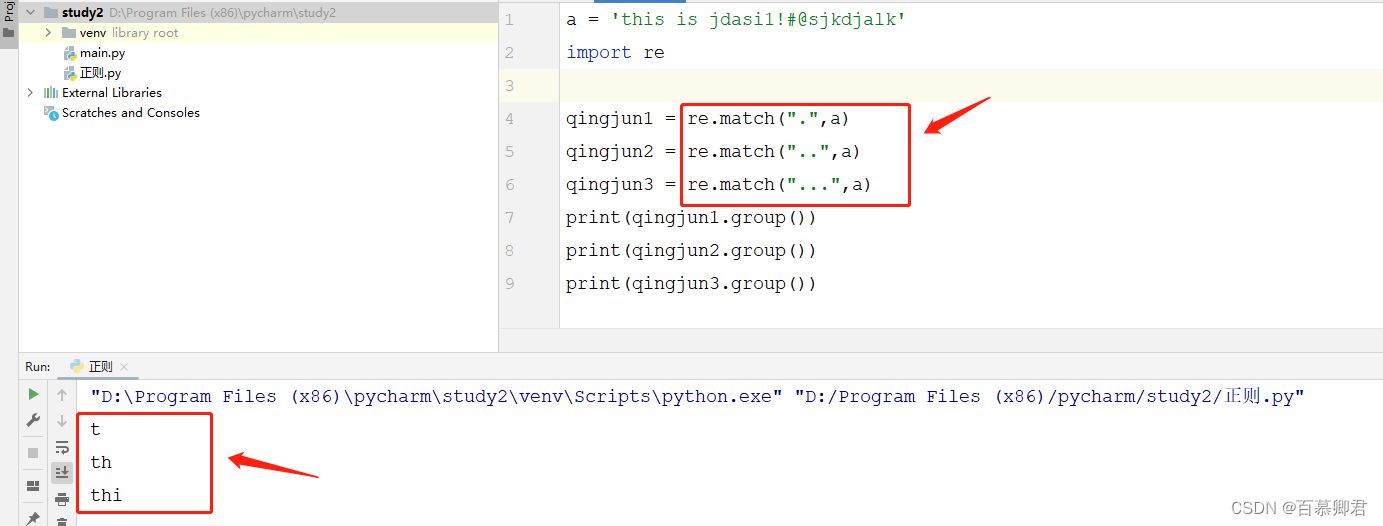
2.匹配[ ]中任意一个字符。
a = 'this is jdasi1!#@sjkdjalk'
import reqingjun1 = re.match("[tZZx]",a)
qingjun2 = re.match("[tZZx][shj]",a)
qingjun3 = re.match("[tZZx][shj][iOk]",a) ##第1个[]匹配字符串中第1个字符,第2个[]匹配字符串中第1个字符,以此类推。
qingjun4 = re.match("[^i]",a) ##取反匹配,匹配除i之外的任意字符,所以能匹配到t。
qingjun5 = re.match("[a-z][a-k]",a) ##匹配a~z中任意字符。
print(qingjun1.group())
print(qingjun2.group())
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
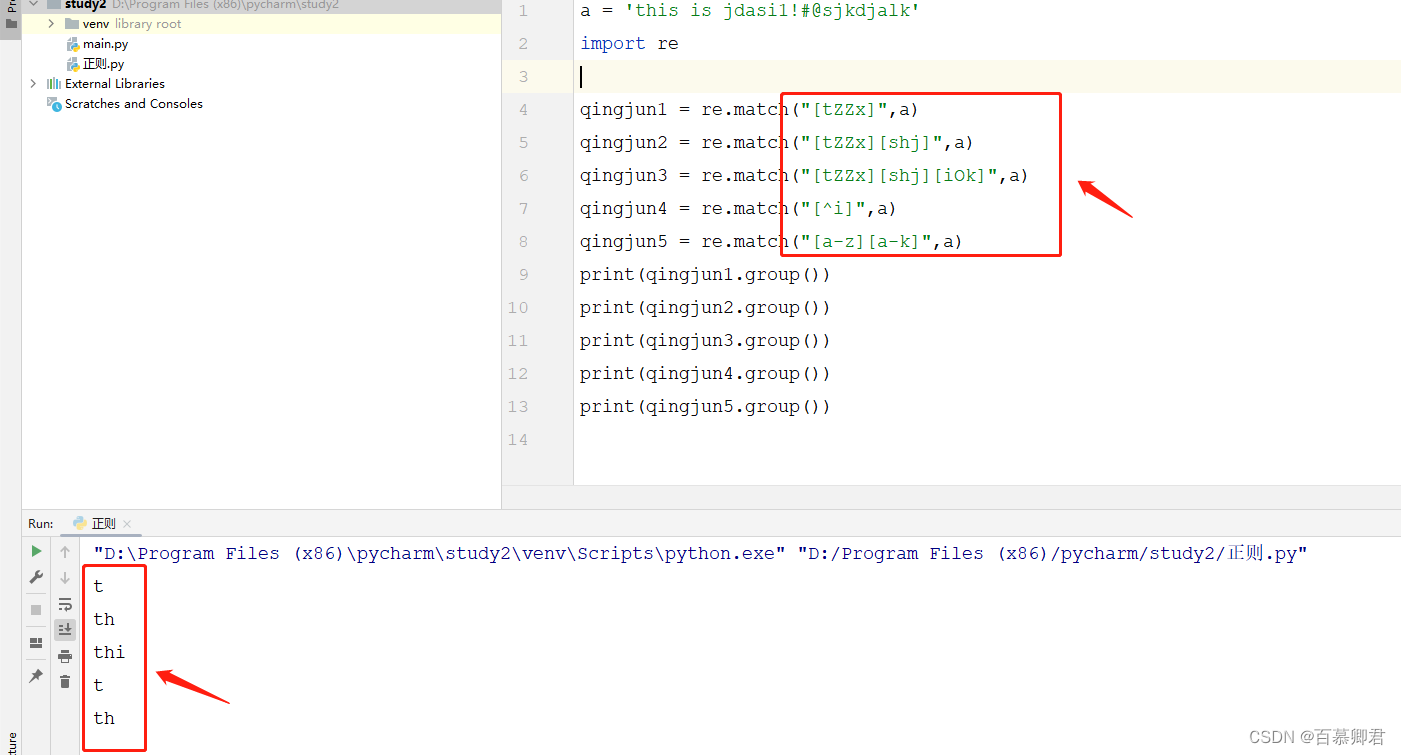
3.匹配数字,”\d“。
a = '99isl3'
import reqingjun1 = re.match("[0-9]",a)
qingjun2 = re.match("[0-9][0-9]",a)
qingjun3 = re.match("[0-9][0-9][a-z]",a)
qingjun4 = re.match("\d\d",a) ## \d等同于[0-9]
qingjun5 = re.match("\d\d[a-z]",a)
qingjun6 = re.match("\d\d\D",a) ## \D等同于[^0-9]
print(qingjun1.group())
print(qingjun2.group())
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
print(qingjun6.group())
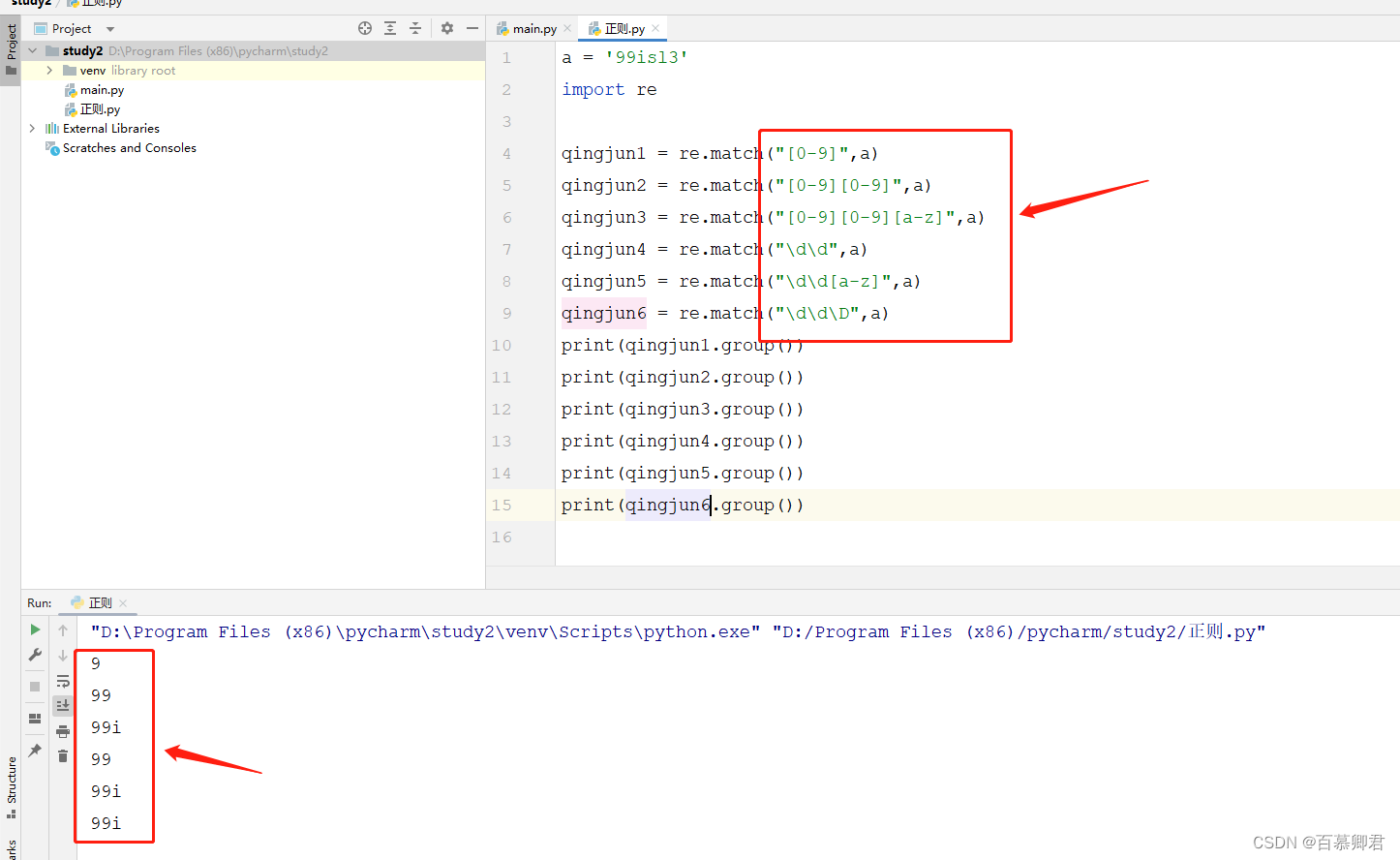
4.匹配单个空白字符,”\s“。
a = '99 isl3'
import reqingjun3 = re.match("\d\d\s\D",a)
qingjun4 = re.match("[0-9][0-9]\s[a-z]",a)
print(qingjun3.group())
print(qingjun4.group())
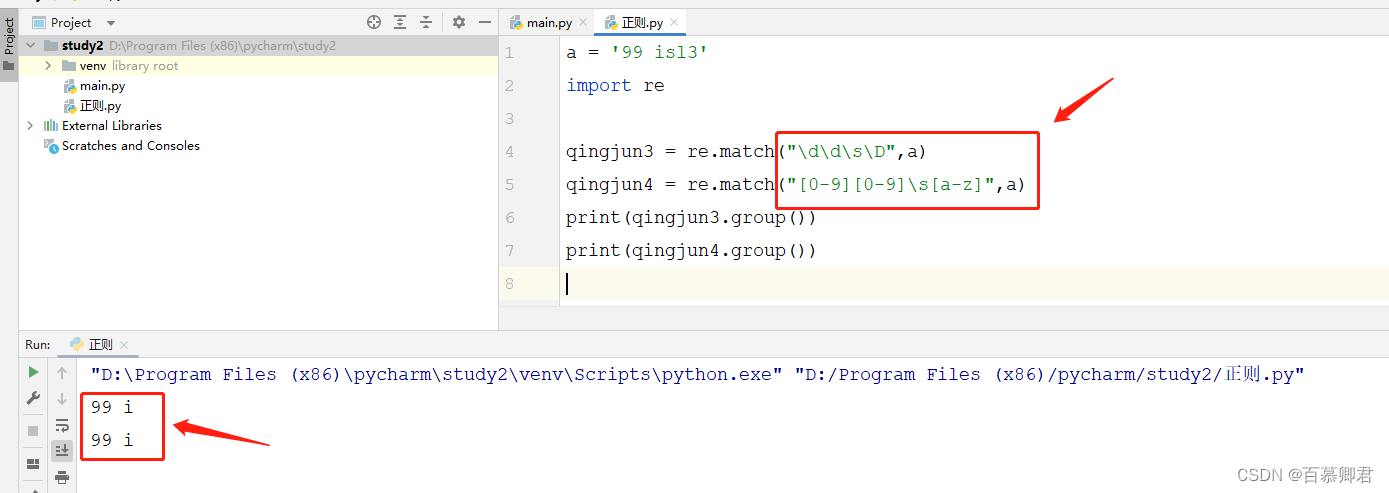
5.匹配空白字符之外的所有字符,”\S“。
a = '99 isl3'
import reqingjun3 = re.match("\d\d\s\D",a)
qingjun4 = re.match("[0-9][0-9]\s[a-z]",a)
qingjun5 = re.match("\S\S\s[a-z]",a)
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
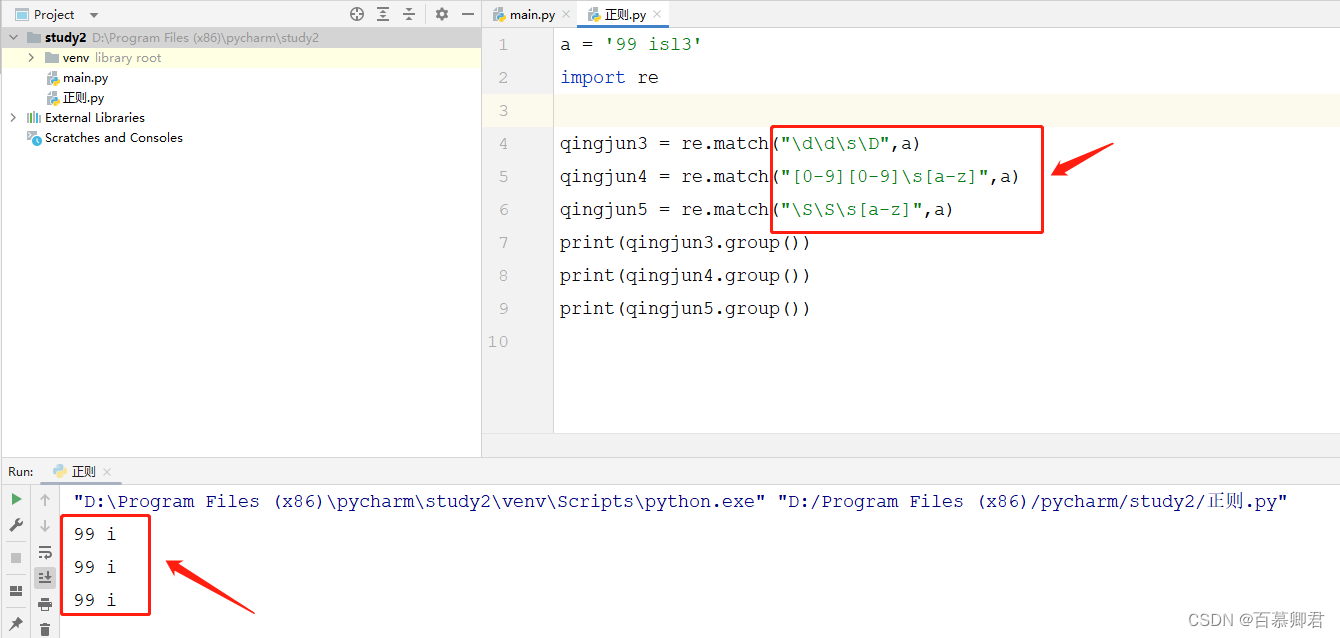
6.匹配字母、数字、下划线,“\w”
a = '99 _\sl3'
import reqingjun3 = re.match("\d\d\s\w\D",a) ## \w等效[a-zA-Z0-9_]
print(qingjun3.group())
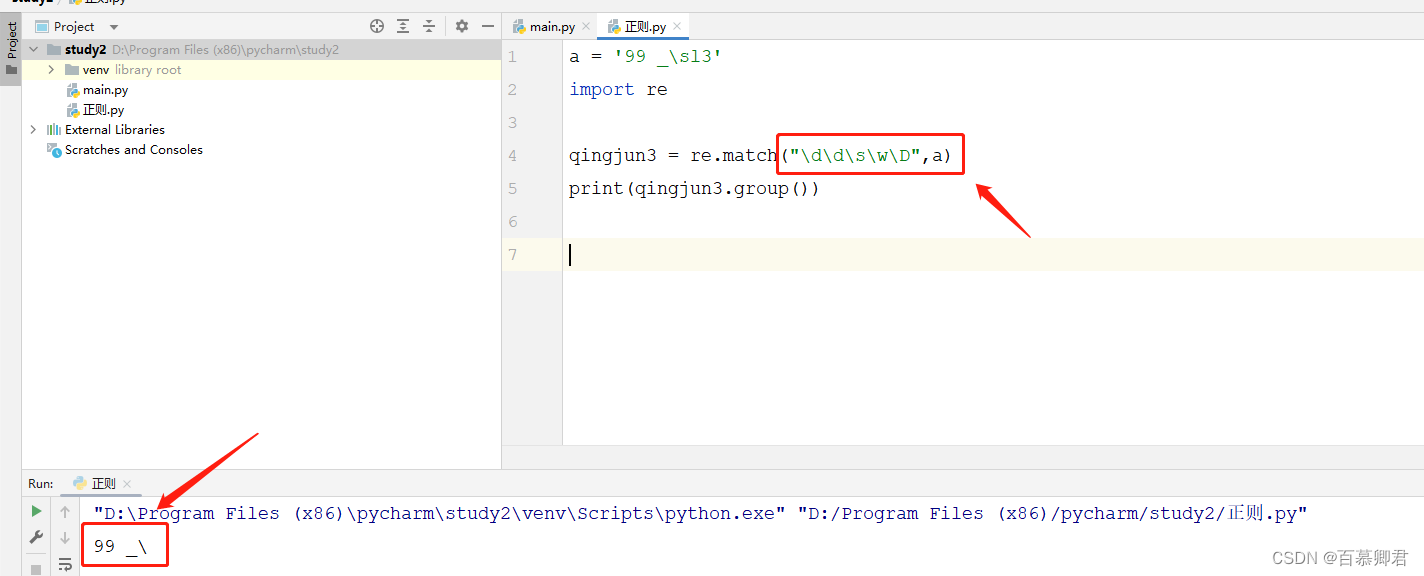
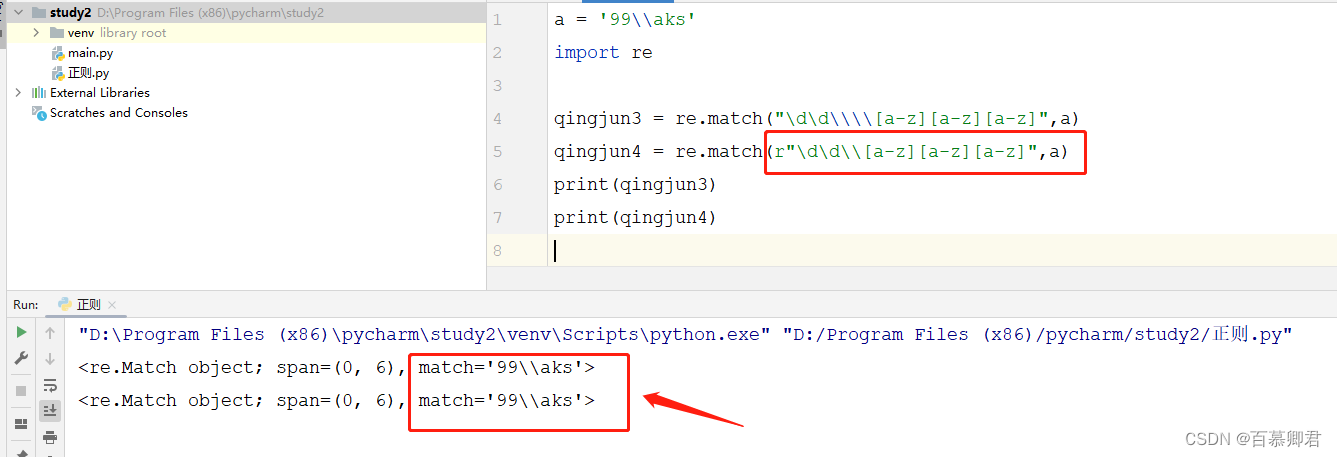
7.自动转义,”r““表示原始字符串,有了它,字符串里的特殊意义符号就会自动加转义符。
a = '99\\aks'
import reqingjun3 = re.match("\d\d\\\\[a-z][a-z][a-z]",a) ##不加r,则需要额外对\转义。
qingjun4 = re.match(r"\d\d\\[a-z][a-z][a-z]",a) ##加r,自动对\转义。
print(qingjun3)
print(qingjun4)
2.3 数量匹配
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式0次或多次(无限次) |
| + | 匹配前面的子表达式1次或多次 |
| ? | 匹配前面的子表达式0次或1次 |
| {n} | 匹配花括号前面字符n个字符 |
| {n,} | 匹配花括号前面字符至少n个字符 |
| {n,m} | 匹配花括号前面字符至少n个字符,最多m个字符 |
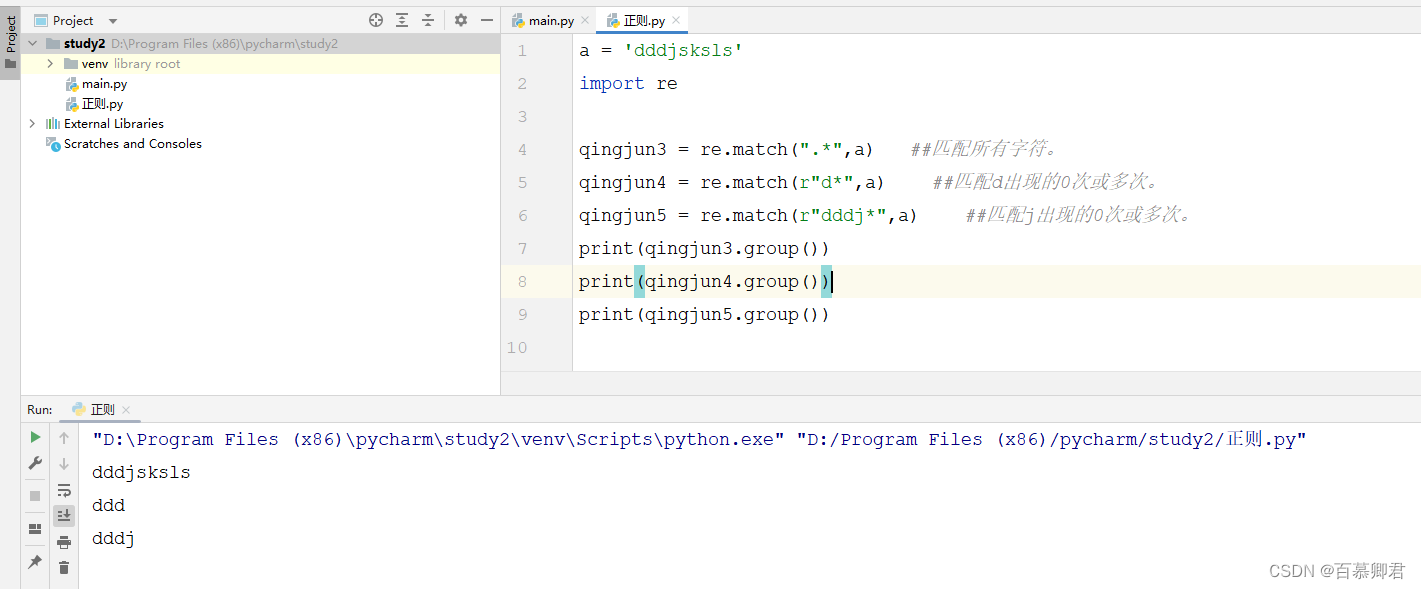
1.匹配0次或无限次,“ * ”的用法。
a = 'dddjsksls'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"d*",a) ##匹配d出现的0次或多次。
qingjun5 = re.match(r"dddj*",a) ##匹配j出现的0次或多次。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
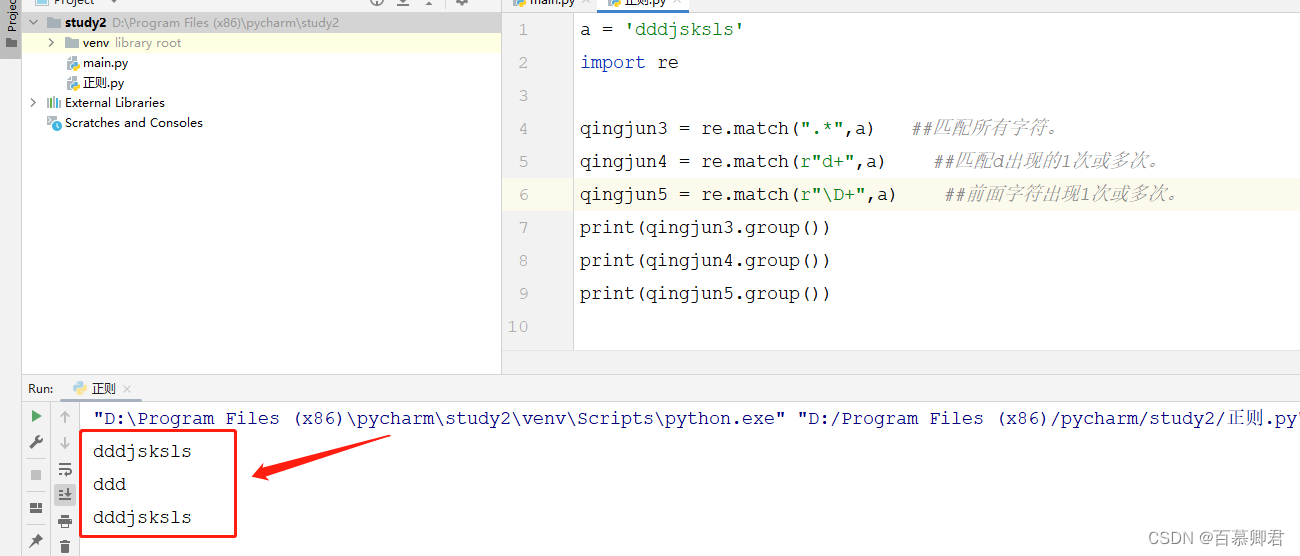
2.匹配1次或多次,“ + ”的用法。
a = 'dddjsksls'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"d+",a) ##匹配d出现的1次或多次。
qingjun5 = re.match(r"\D+",a) ##前面字符出现1次或多次。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
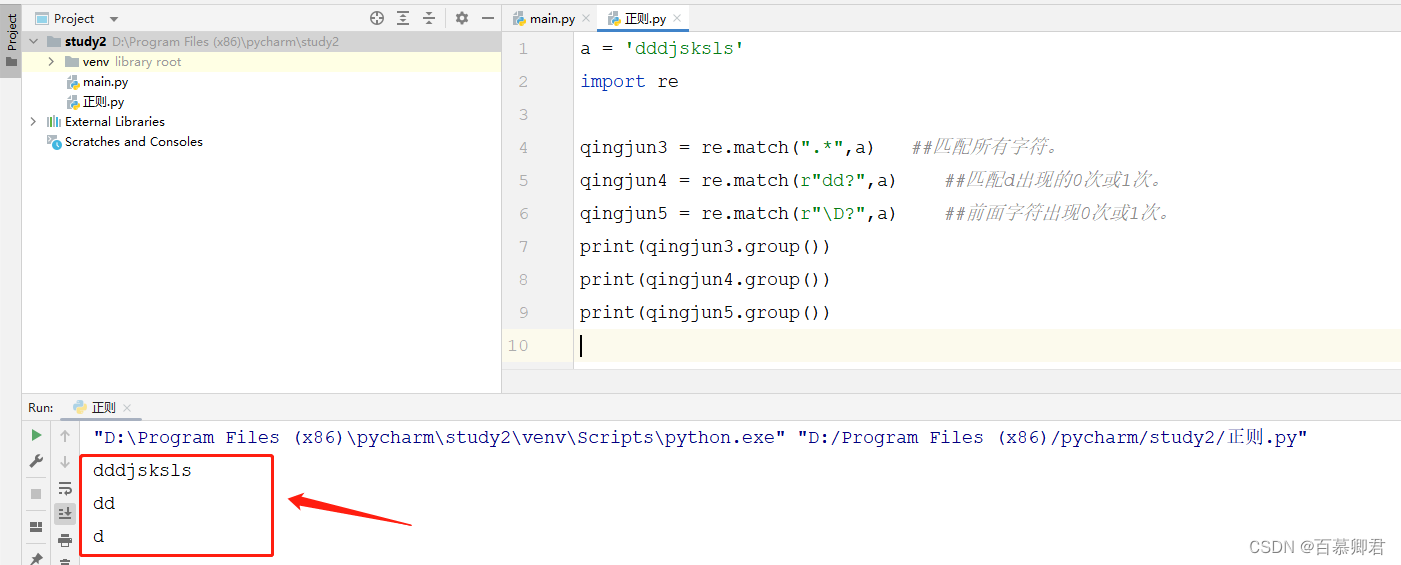
3.匹配1次或多次,“ ? ”的用法。
a = 'dddjsksls'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"dd?",a) ##匹配d出现的0次或1次。
qingjun5 = re.match(r"\D?",a) ##前面字符出现0次或1次。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
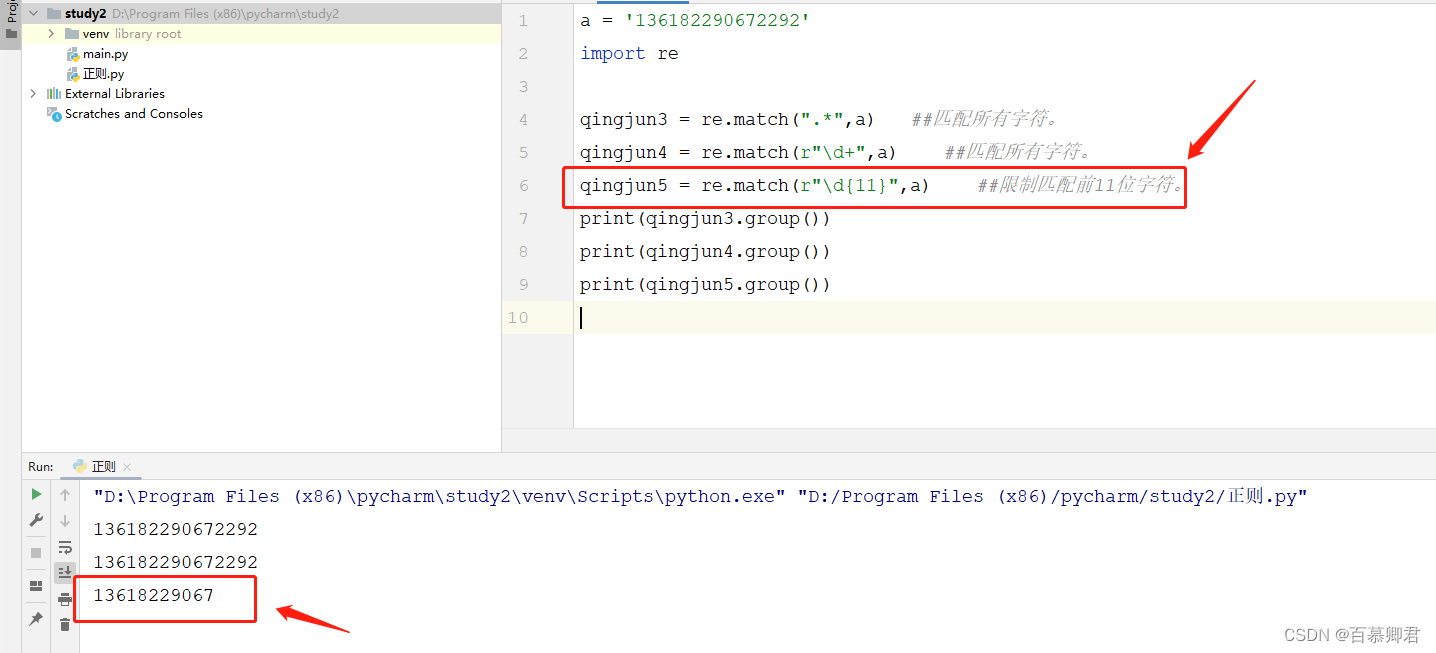
4.限制匹配,只匹配{ n }前的n个字符,超过n个字符的之外所有字符都不能被匹配到。
a = '136182290672292'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"\d+",a) ##匹配所有字符。
qingjun5 = re.match(r"\d{11}",a) ##限制匹配前11位字符。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
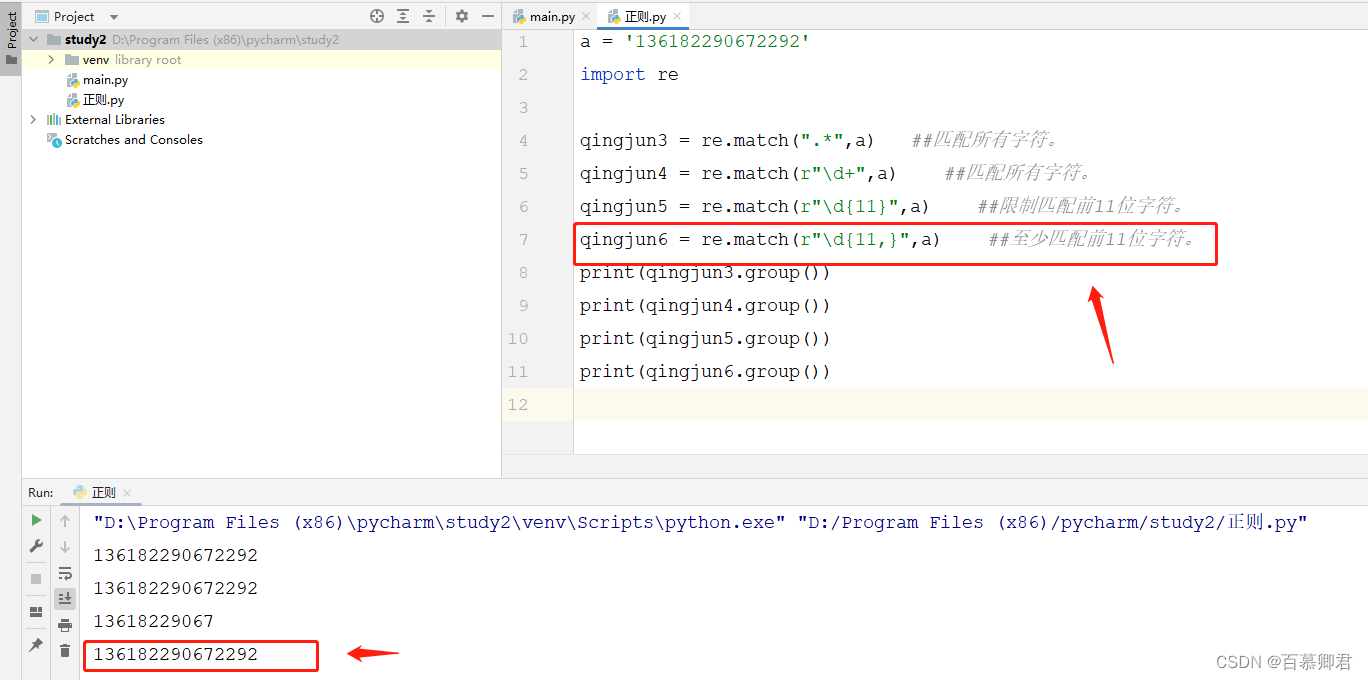
5.限制匹配,至少匹配{ n, }中n个字符。
a = '136182290672292'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"\d+",a) ##匹配所有字符。
qingjun5 = re.match(r"\d{11}",a) ##限制匹配前11位字符。
qingjun6 = re.match(r"\d{11,}",a) ##至少匹配前11位字符。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
print(qingjun6.group())
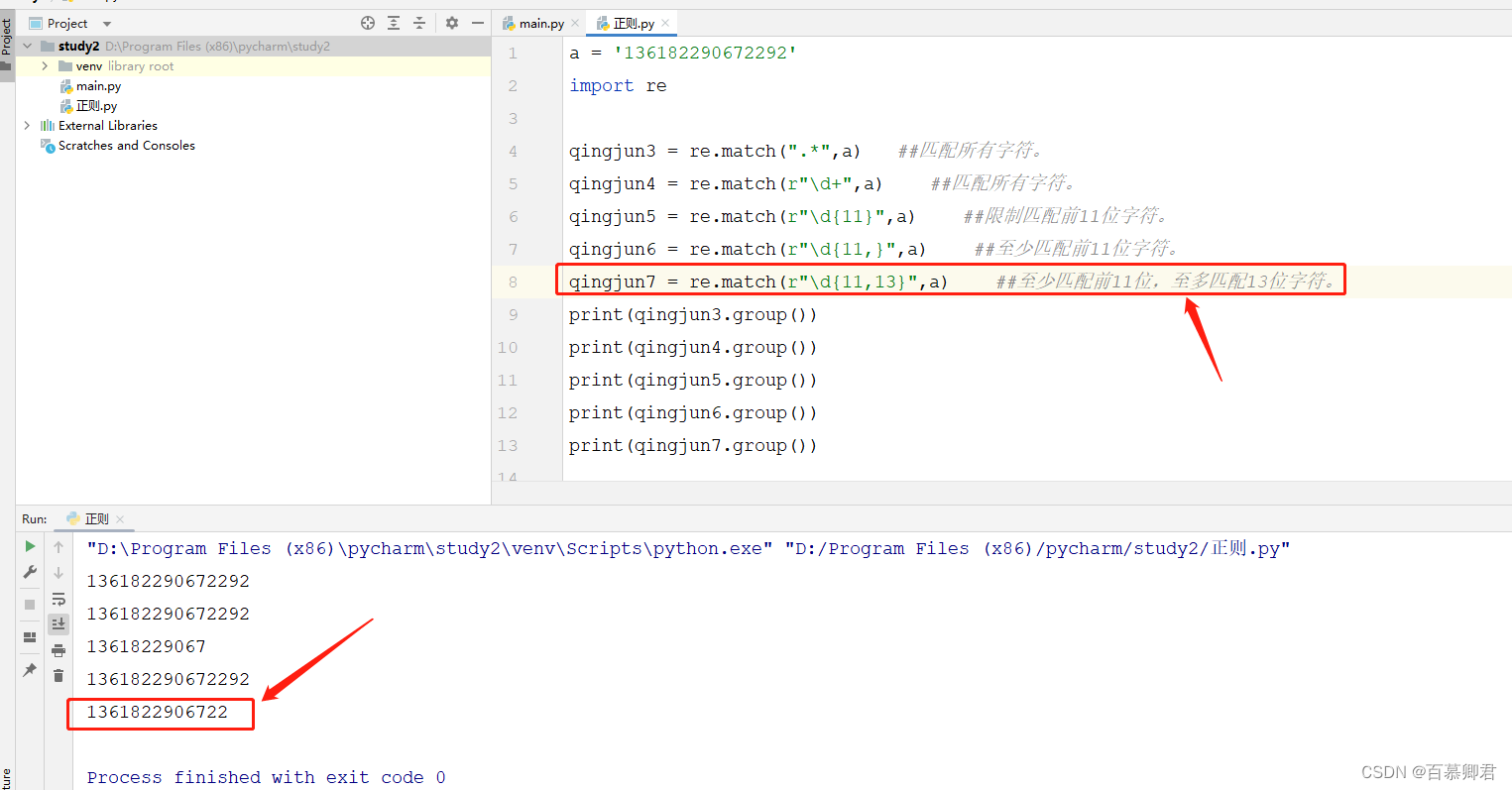
6.限制匹配,至少匹配{ n,m }中前n位字符,且至多匹配前m位字符。
a = '136182290672292'
import reqingjun3 = re.match(".*",a) ##匹配所有字符。
qingjun4 = re.match(r"\d+",a) ##匹配所有字符。
qingjun5 = re.match(r"\d{11}",a) ##限制匹配前11位字符。
qingjun6 = re.match(r"\d{11,}",a) ##至少匹配前11位字符。
qingjun7 = re.match(r"\d{11,13}",a) ##至少匹配前11位,至多匹配13位字符。
print(qingjun3.group())
print(qingjun4.group())
print(qingjun5.group())
print(qingjun6.group())
print(qingjun7.group())
2.4 边界匹配
| 字符 | 描述 |
|---|---|
| ^ | 匹配以什么开头 |
| $ | 匹配以什么结尾 |
| \b | 匹配单词边界 |
| \B | 匹配非单词边界 |
1.例一,判断用户输入的邮箱格式。
import reemail = input("请输入你的邮箱:")
qingjun = re.match('^\w+@[a-z]+\.[a-z]+$',email) #2571788322@qq.com
if qingjun:print("格式正确!")
else:print("格式错误!")

2.5 分组匹配
| 字符 | 描述 |
|---|---|
| | | 匹配竖杠两边的任意一个正则表达式 |
| (re) | 匹配小括号中正则表达式。使用\n反向引用,n是数字,从1开始编号,表示引用第n个分组匹配的内容。 |
| (?Pre) | 分组别名,name是表示分组名称 |
| (?P=name) | 引用分组别名 |
1.分组选择匹配,能匹配中()中的任意一个。
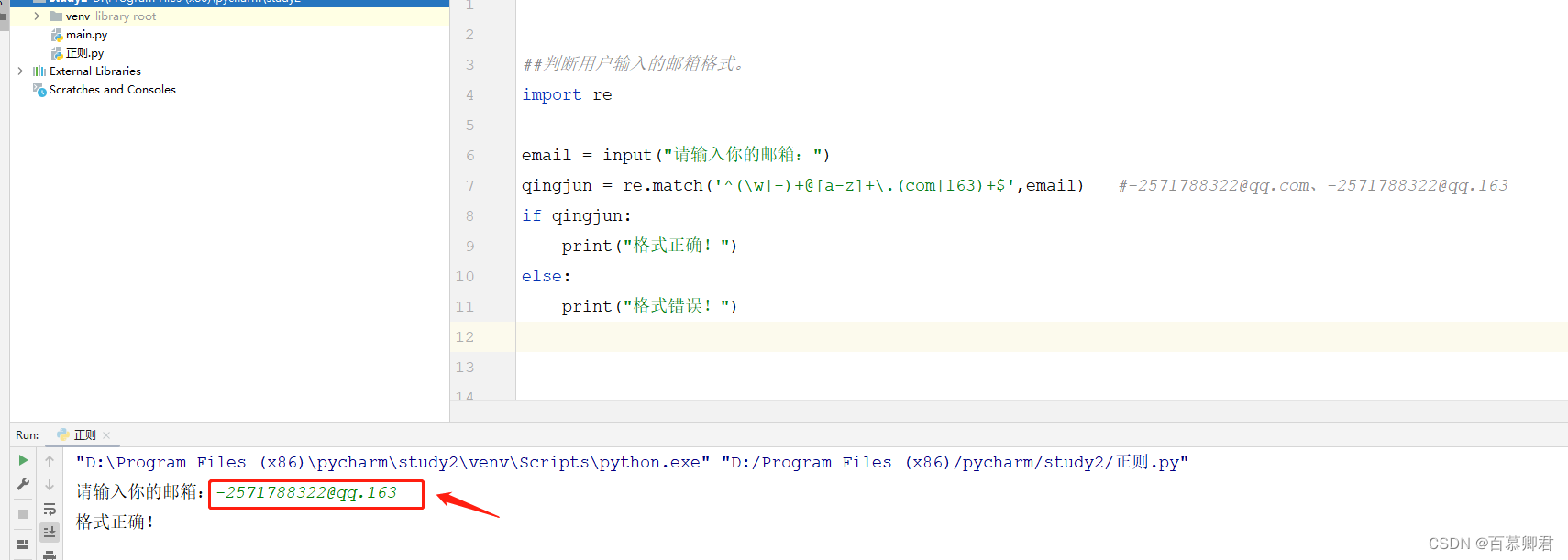
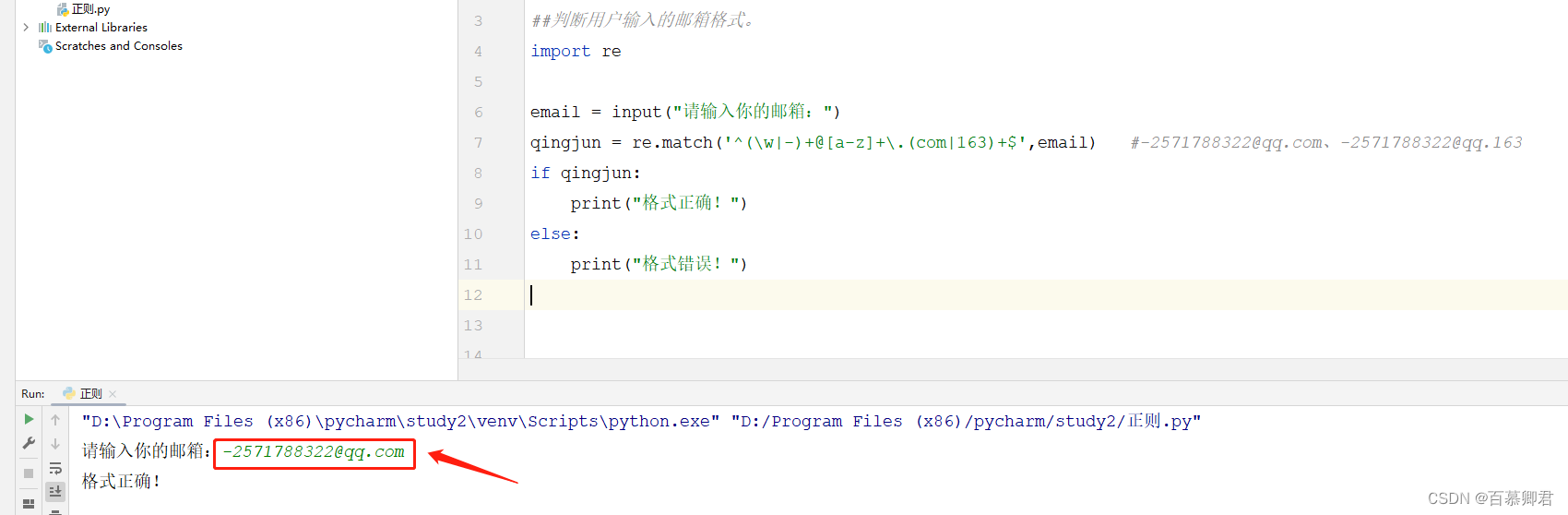
##判断用户输入的邮箱格式。
import reemail = input("请输入你的邮箱:")
qingjun = re.match('^(\w|-)+@[a-z]+\.(com|163)+$',email) #-2571788322@qq.com、-2571788322@qq.163
if qingjun:print("格式正确!")
else:print("格式错误!")
2.引用分组。
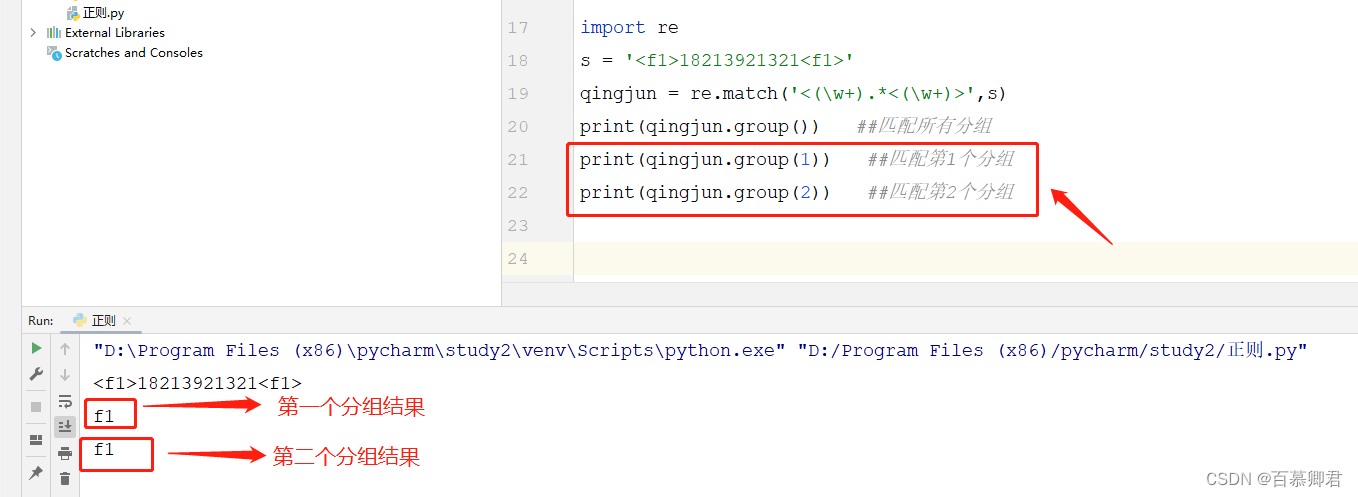
import re
s = '<f1>18213921321<f1>'
qingjun1 = re.match('<(\w+).*<(\w+)>',s) ##qingjun1效果等于qingjun2。
qingjun2 = re.match('<(\w+).*<(\\1)>',s) ##正常语法是\n,n为数字,这里需要转义一下,表示引用第一个分组结果。print(qingjun2.group()) ##匹配所有分组。
print(qingjun2.group(1)) ##匹配第1个分组。
print(qingjun2.group(2)) ##匹配第2个分组。
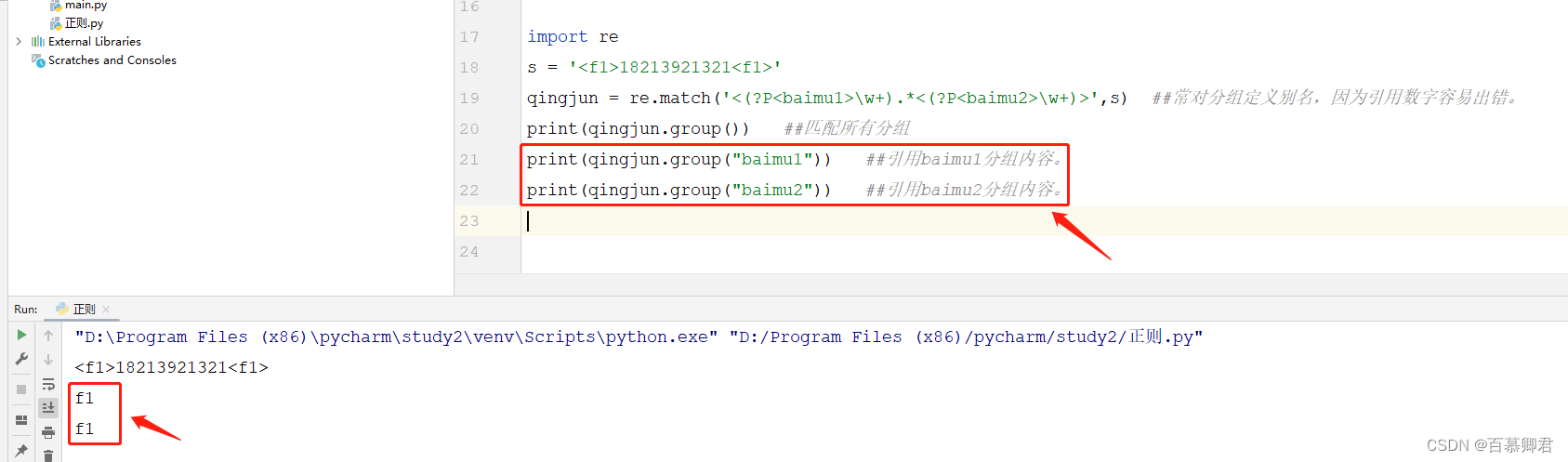
3.分组别名引用。
import re
s = '<f1>18213921321<f1>'
qingjun = re.match('<(?P<baimu1>\w+).*<(?P<baimu2>\w+)>',s) ##常对分组定义别名,因为引用数字容易出错。
print(qingjun.group()) ##匹配所有分组
print(qingjun.group("baimu1")) ##引用baimu1分组内容。
print(qingjun.group("baimu2")) ##引用baimu2分组内容。
2.6 贪婪模式&非贪婪模式
- 贪婪模式:尽可能最多匹配。
- 非贪婪模式:尽可能最少匹配,一般在量词(*、+)后面加个?问号就是非贪婪模式。
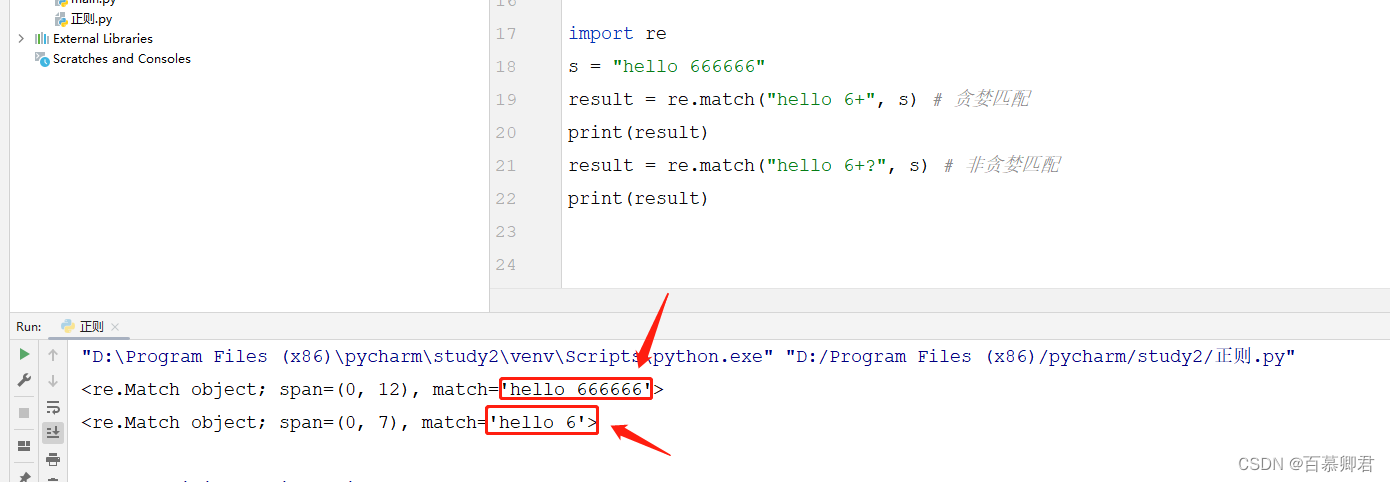
1.例一,贪婪模式和非贪婪模式的区别。
import re
s = "hello 666666"
result = re.match("hello 6+", s) # 贪婪匹配
print(result)
result = re.match("hello 6+?", s) # 非贪婪匹配
print(result)
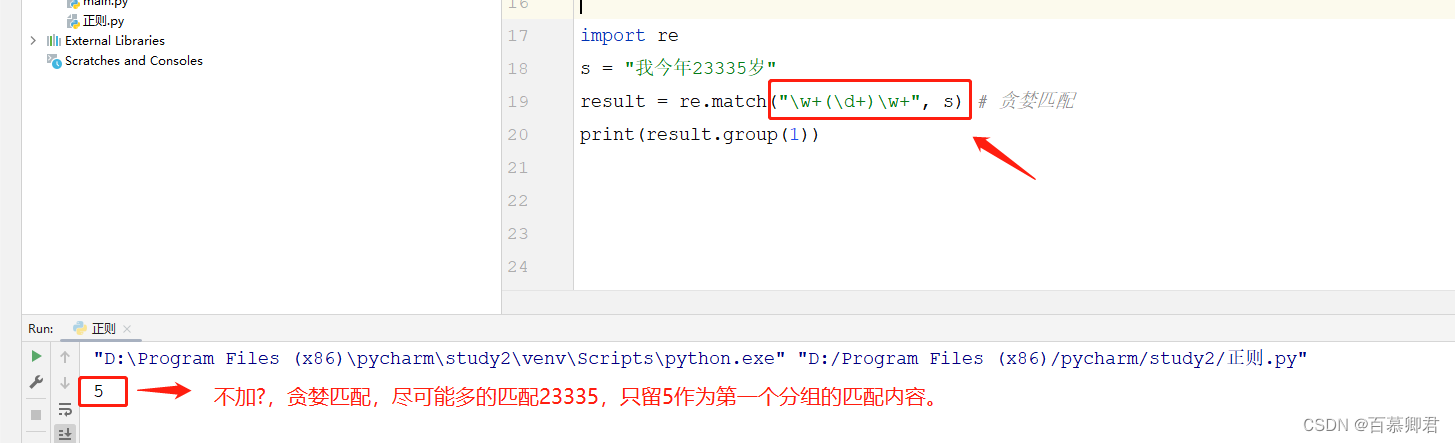
2.例2,贪婪模式。
import re
s = "我今年23335岁"
result = re.match("\w+(\d+)\w+", s) # 贪婪匹配
print(result.group(1))
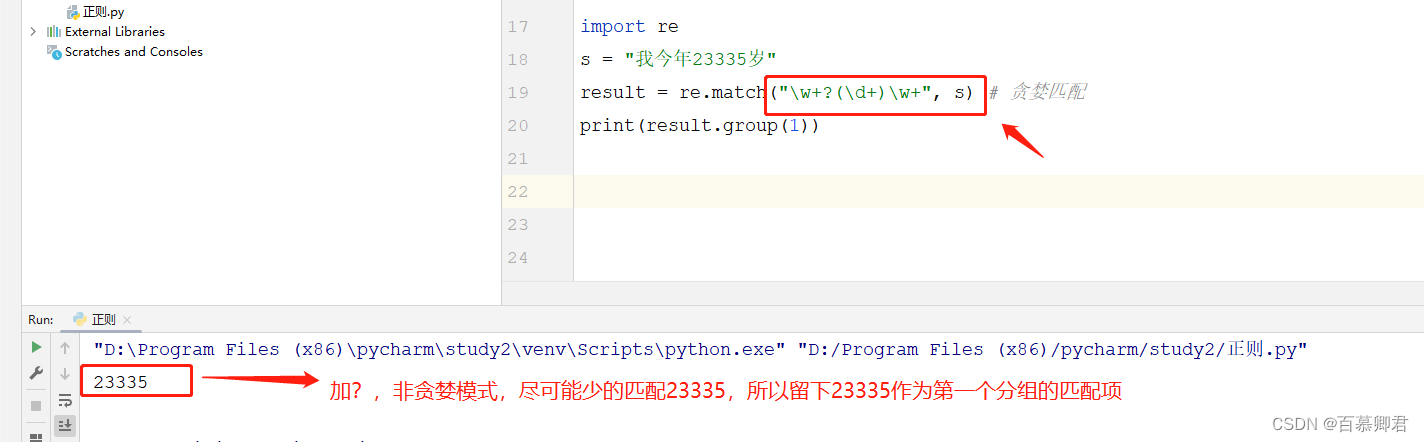
3.例三,非贪婪模式。
import re
s = "我今年23335岁"
result = re.match("\w+?(\d+)\w+", s) # 贪婪匹配
print(result.group(1))
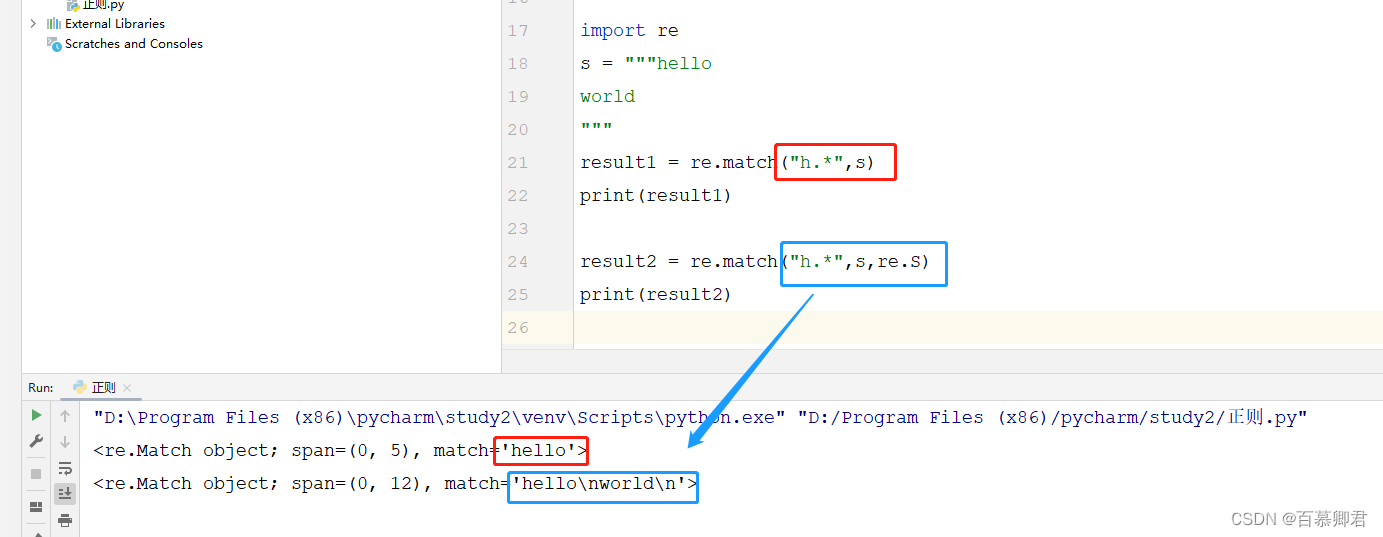
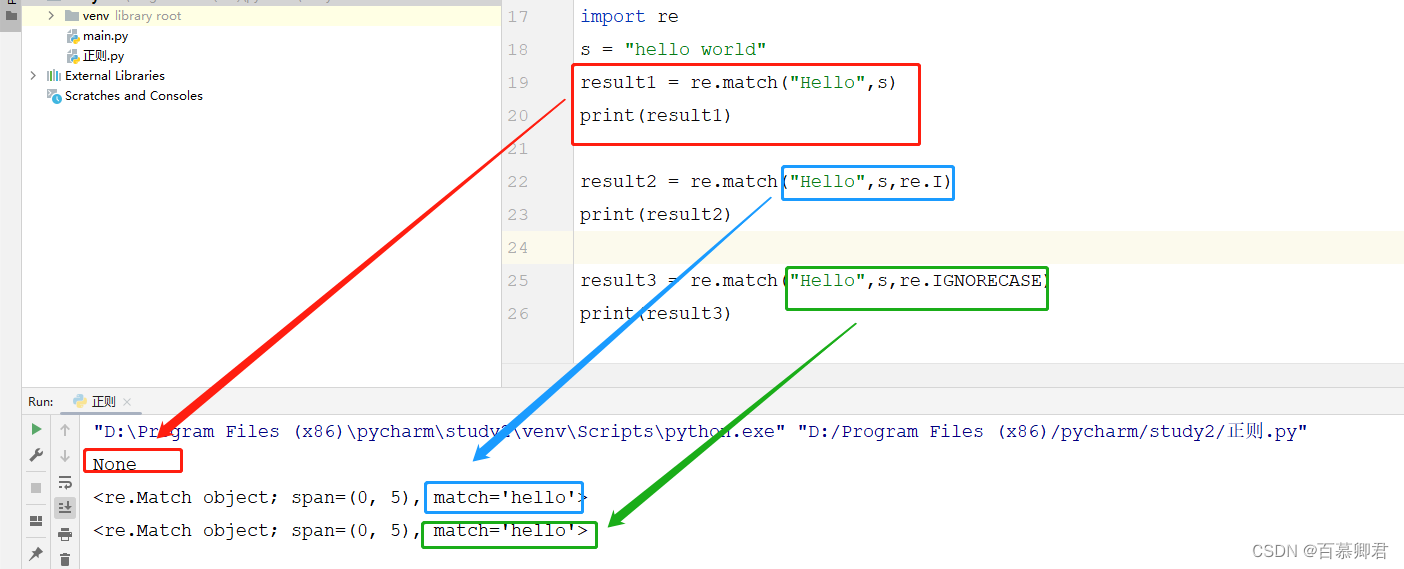
2.7 标志位
| 字符 | 描述 |
|---|---|
| re.I/re.IGNORECASE | 忽略大小写 |
| re.S/re.DOTAIL | 匹配所有字符,包括换行符\n,如果没这个标志将匹配除了换行符 |
1.忽略大小写匹配。
import re
s = "hello world"
result1 = re.match("Hello",s)
print(result1)result2 = re.match("Hello",s,re.I) ##写法一。
print(result2) result3 = re.match("Hello",s,re.IGNORECASE) ##写法二。
print(result3)
2.匹配所有字符,包括换行符。
import re
s = """hello
world
"""result2 = re.match("h.*",s,re.S)
print(result2)