背景
Image caption是计算机视觉研究领域中的一个重要分支,其主要目标是根据输入的图像信息,生成相应的文字描述,从而完成对图像内容的准确描述。对于图像描述任务而言,最关键的是能够将图片中的信息以清晰准确的文字形式展现出来。对于熟悉图像领域的专家而言,这个问题应该并不陌生。
主流结构:Transformer
为了实现图像描述的任务,常见的方法是采用编码器-解码器(encoder-decoder)的结构。这种结构可以将输入的图像信息通过编码器进行抽象和提取,得到一个表示图像特征的向量。然后,解码器将这个向量作为输入,逐步生成与图像内容相对应的文字描述。这种结构的实现中,常常使用transformer作为主体机构。
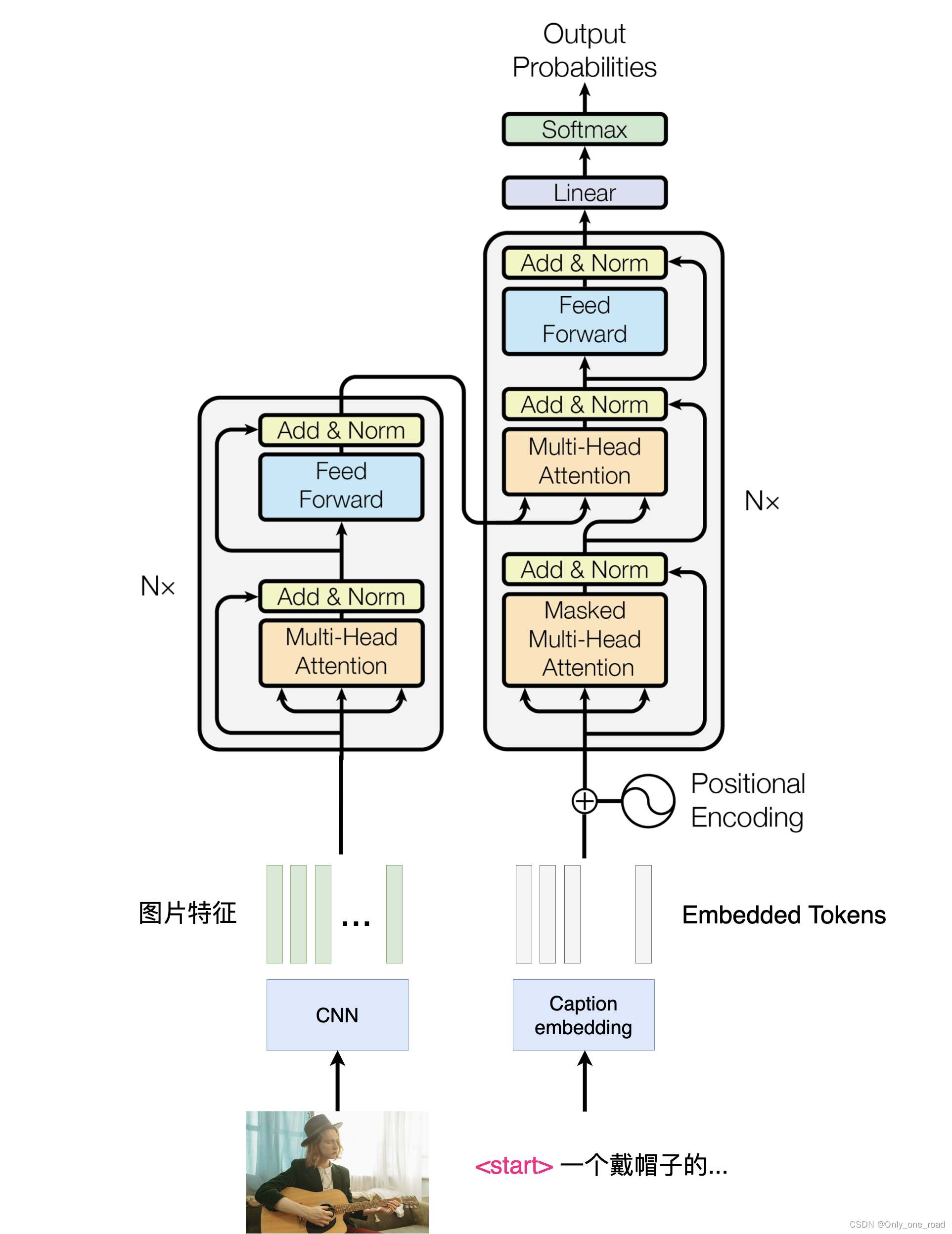
Transformer是一种基于自注意力机制的神经网络模型,其在自然语言处理领域取得了巨大的成功。它通过对输入序列中的不同位置进行自注意力计算,从而实现了对序列信息的全局建模。在图像描述任务中,transformer可以用来处理图像特征的编码和生成文字描述的解码过程。通过自注意力机制,transformer能够捕捉到图像中不同区域的语义关联,从而生成更准确、更有表现力的图像描述。
Robotic Transformer 2
随着大模型的涌现,多模态任务的能力得到了显著提升。DeepMind提出了他们的机器人大模型Robotic Transformer 2(RT2),展现出了出色的语义理解和视觉理解能力。这一模型在许多任务中展现出了惊人的表现,例如帮助疲倦的人选择最适合的饮料。
RT2的强大之处在于它能够同时处理语义和视觉信息,从而实现对多模态任务的高效处理。对于上述的例子,当面对一个疲倦的人时,RT2可以通过语义理解和视觉分析,准确判断出他们的需求,并选择出最适合的饮料。RT2的语义理解能力使其能够理解人类的需求和意图,通过对语言输入的处理,它能够准确地解析出人们所表达的需求。同时,RT2的视觉理解能力使其能够分析和理解图像或视频中的内容,从中获取关键信息。通过将这两种能力结合起来,RT2能够在多模态任务中取得出色的表现。
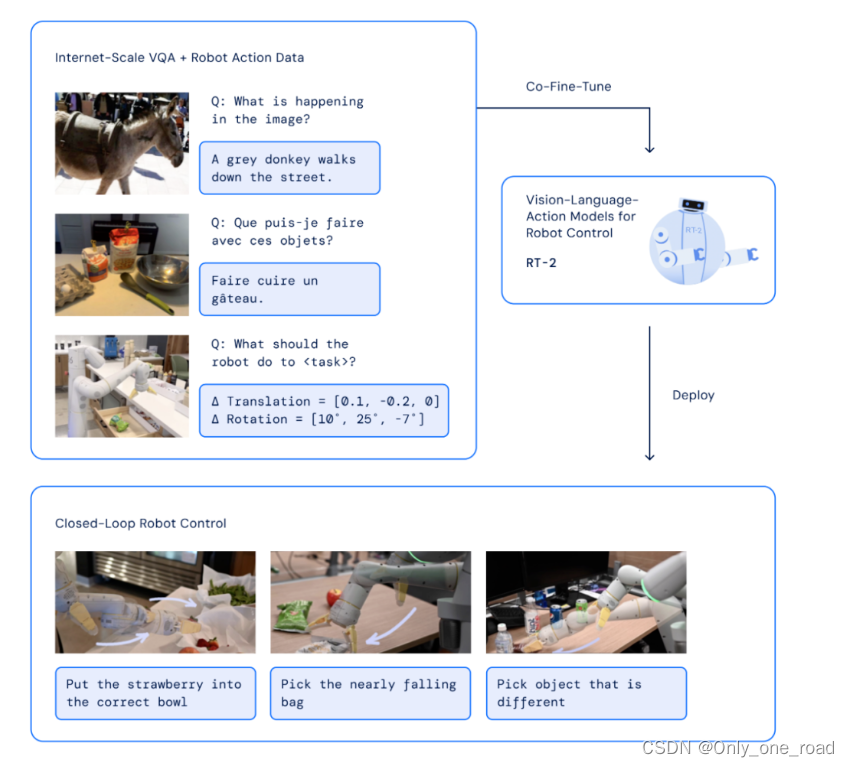
DeepMind的Robotic Transformer 2展现出了强大的语义与视觉理解能力,在多模态任务中表现出色。这一能力对于实际应用具有重要意义,为人们提供了更智能、便捷的服务和体验。
在实际生活中,空间是由三维坐标组成的。然而,简单的图像字幕或视觉问答往往无法满足下游场景应用对空间信息的需求。传统的图文生成模型对于三维空间数据并不敏感,无法通过图像中的三维信息来进行空间描述。对于空间描述的需求,我们需要更加细致和准确的方法来处理三维空间数据。
空间信息:Generating Visual Spatial Description via Holistic 3D Scene Understanding
今年ACL 2023上发布了一篇重要的论文,题为《Generating Visual Spatial Description via Holistic 3D Scene Understanding》。该论文探讨了从平面图像中理解空间语义的新任务,即视觉空间位置描述。通过构建大规模的图片-空间描述数据集并结合预训练的视觉语言模型,同时提出了一种基于3D特征和空间场景图建模的全新框架,实现了基于空间感知的图文生成领域,并为空间感知建模提供了新的方法。这项研究的核心目标是通过对平面图像进行全面的3D场景理解,从而实现对视觉空间描述的生成。
方法
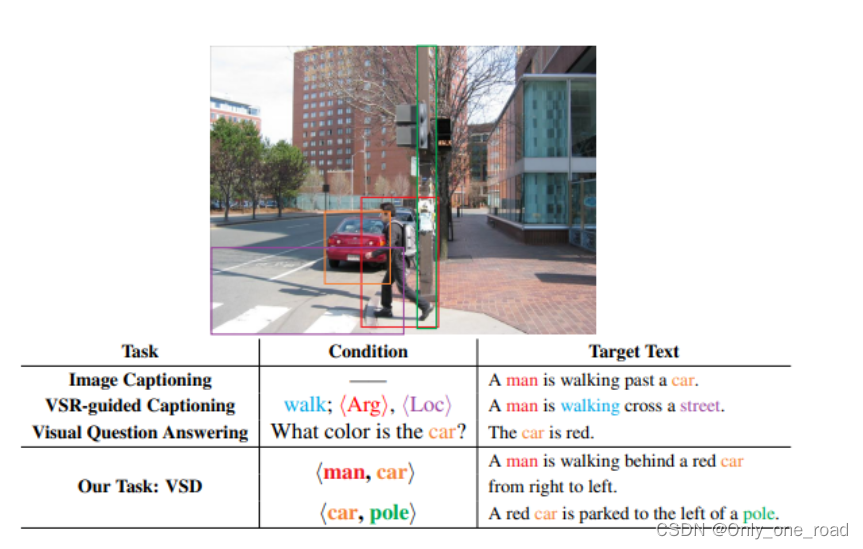
针对空间语义理解问题,该论文提出了一项基于空间的图文生成任务,即视觉空间位置描述(Visual Spatial Description,VSD)。该任务的主要目标是根据给定的图片和两个实体,生成描述这两个实体空间位置关系的自然语言描述。例如,在给定的图片中,根据实体"man"和"car",生成如下的空间位置描述:"A man is walking behind a red car from right to left." VSD任务通过从"空间位置信息"的角度对场景进行描述,并将核心描述准确表达出来。VSD任务的提出对于图文生成领域的空间感知具有重要意义。通过对空间位置关系的建模,可以使生成的描述更加准确、具有表现力,并且能够提供对场景的全面理解。这种基于空间的图文生成任务为实际应用提供了新的方法和思路。
建模与结构

整体模型机构如下图:
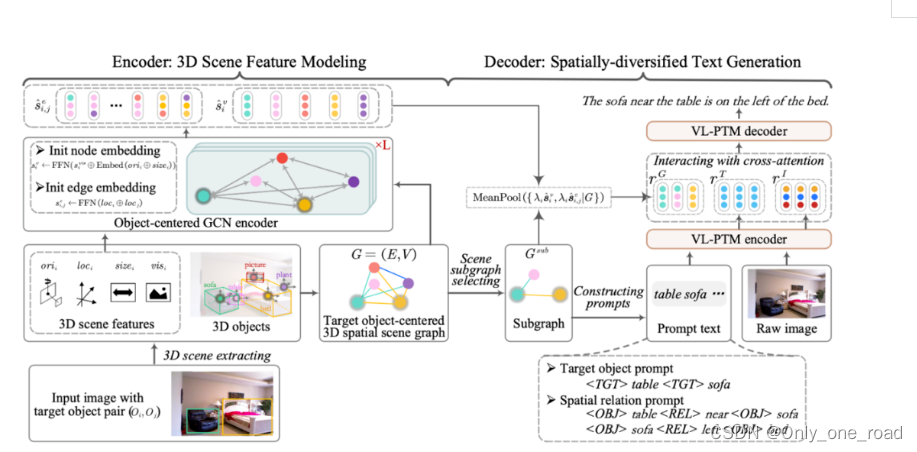
论文采用 3D 检测模型,对评价图像进行 3D 场景估计和目标检测,得到场景中每个物体的位置、姿态等 3D 特征。具体的可以去研究论文。
思路与方案
针对以上思路,图像文本生成一定是要多模态的方法吗,可否借助大模型的优势去做一些工作呢。针对这个问题,进行了相关的实验。采用两部走的方案,检测+描述生成。检测部分可以采用目标检测常见的一些模型与方法,比如yolo等,同时也可以采用3D目标检测的方法。这样就可以得到检测结果。[[检测出的物体1,坐标1][检测出的物体2,坐标2]....],其中坐标可以是二维[X,Y]或三维[x,y,z]。基于上述检测结果采用prompt+gpt3.5就表示出图像的描述。
同样针对视频,可以采用关键帧的思路,作为模型的输入,得到关于视频的描述。
第一帧
检测到的物体: 中年人、车
坐标信息:车:[0,200,0]、中年人:[60,100,0]
第二帧
检测到的物体: 中年人、车
坐标信息:车:[0,200,0]、中年人:[-60,100,0]描述:在第一帧中,我看到了一辆车和一个中年人。车在视野的中心,而中年人在车的右侧。然后在第二帧中,中年人从车的右侧移动到了车的左侧。可以看到模型对于空间关系有一定的理解力。图像生成文字描述,具体的场景需要结合不同的需求去建模,并不一定是多模态解决问题。
Reference:
1.https://arxiv.org/abs/2305.11768
2.https://www.blog.google/technology/ai/google-deepmind-rt2-robotics-vla-model