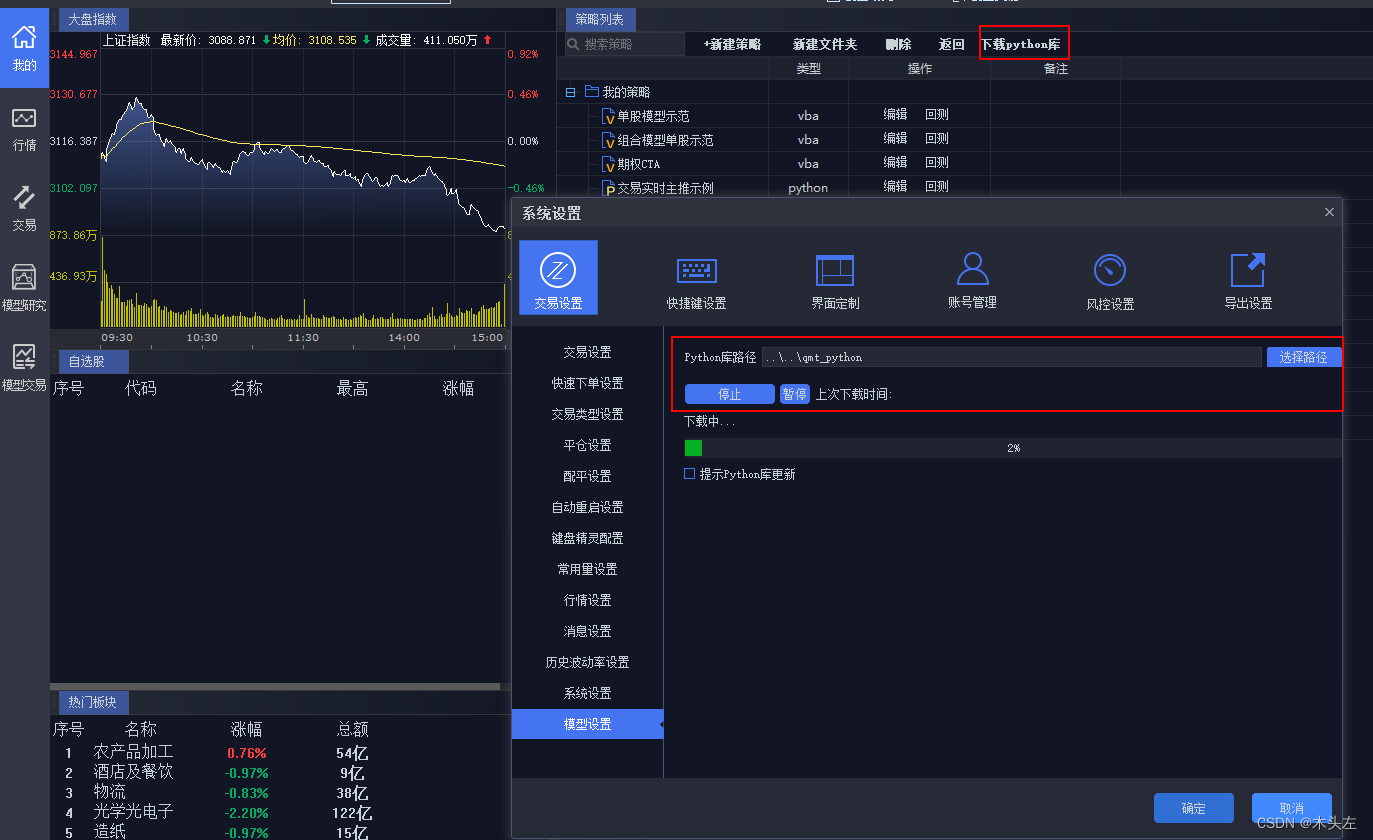
selenium+phantomjs绕过接口加密
我们为什么需要selenium
之前我们讲解了 Ajax 的分析方法,利用 Ajax 接口我们可以非常方便地完成数据的爬取。只要我们能找到 Ajax 接口的规律,就可以通过某些参数构造出对应的的请求,数据自然就能被轻松爬取到。
但是,在很多情况下,Ajax 请求的接口通常会包含加密的参数,如 token、sign 等。
由于接口的请求加上了 token 参数,如果不深入分析并找到 token 的构造逻辑,我们是难以直接模拟这些 Ajax 请求的。
解决方法:
- 一种是深挖其中的逻辑,把其中 token 的构造逻辑完全找出来,再用 Python 复现,构造 Ajax 请求;
- 另外一种方法就是直接通过模拟浏览器的方式,绕过这个过程。因为在浏览器里面我们是可以看到这个数据的,如果能直接把看到的数据爬取下来,当然也就能获取对应的信息了。
由于第 1 种方法难度较高,在这里我们就先介绍第 2 种方法,模拟浏览器爬取。
selenium是什么
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面源代码,做到可见即可爬。对于一些使用 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。本课时就让我们来感受一下它的强大之处吧。
大家经常听说的是selenium加PhantomJS
selenium是操作浏览器的软件包,PhantomJS是特殊浏览器,不显示任何页面,被称为无头浏览器,这样可以运行的更快,但是该浏览器已经不再更新,属于半淘汰品了。因为谷歌59以上版本已经支持无头模式了
import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Serviceoptions = webdriver.ChromeOptions()
# 设置无头模式
# options.add_argument('--headless')# selenium新版本: 将谷歌驱动网址用service包裹一下
service = Service('D:\extention\spider\day4\chormedriver\chromedriver-win64\chromedriver.exe')
# 驱动
driver = webdriver.Chrome(service=service, options=options)
# 访问网址
driver.get('https://baidu.com')
# 等待30秒
time.sleep(30)
准备工作
以 Chrome 为例来讲解 Selenium 的用法。在开始之前,请确保已经正确安装好了 Chrome 浏览器并配置好了 ChromeDriver。另外,还需要正确安装好 Python 的 Selenium 库。
驱动下载地址: https://googlechromelabs.github.io/chrome-for-testing/#canary
安装selenium: pip install selenium
基本使用
import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWaitoptions = webdriver.ChromeOptions()
# 设置无头模式
# options.add_argument('--headless')# selenium新版本: 将谷歌驱动网址用service包裹一下
service = Service('D:\extention\spider\day4\chormedriver\chromedriver-win64\chromedriver.exe')
# 驱动
browser = webdriver.Chrome(service=service, options=options)
try:# 访问网址browser.get('https://baidu.com')# 获取输入框input = browser.find_element('xpath', "//*[@id='kw']")# 输入pythoninput.send_keys('python')# 点击确定input.send_keys(Keys.ENTER)# 智能等待wait = WebDriverWait(browser, 10)# 直到某个元素出现wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="content_left"]')))print(f"网页url: {browser.current_url}")print(f"cookies: {browser.get_cookies()}")print(f"网页源代码: {browser.page_source}")
finally:browser.close()声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。
此外,我们可以用如下方式进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
这样就完成了浏览器对象的初始化并将其赋值为 browser 对象。接下来,我们要做的就是调用 browser 对象,让其执行各个动作以模拟浏览器操作。
访问页面
我们可以用 get 方法来请求网页,只需要把参数传入链接 URL 即可。比如,这里用 get 方法访问淘宝,然后打印出源代码,代码如下
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()运行后会弹出 Chrome 浏览器并且自动访问淘宝,然后控制台会输出淘宝页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们就可以驱动浏览器并获取网页源码,非常便捷。
查找节点
单个节点
Selenium 提供了 find_element 这个通用方法,它需要传入两个参数:查找方式 By 和值。
By.ID
By.XPATH
By.TAG_NAME: 标签名称
By.CLASS_NAME
By.CSS_SELECTOR: CSS选择器
By.LINK_TEXT: 精确查询,a标签中文字
By.PARTIAL_LINK_TEXT: 模糊查询,a标签中文字
多个节点
Selenium 提供了 find_elements这个通用方法,它需要传入两个参数:查找方式 By 和值。
返回:一个包含 多个WebElement对象的 列表
节点交互
Selenium 可以驱动浏览器来执行一些操作,或者说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。
更多的操作可以参见官方文档的交互动作介绍 :http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement。
动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们调用它的输入文字和清空文字方法;对于按钮,我们调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖拽、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在我要实现一个节点的拖拽操作,将某个节点从一处拖拽到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
执行JavaScript
Selenium API 并没有提供实现某些操作的方法,比如,下拉进度条。但它可以直接模拟运行 JavaScript,此时使用 execute_script 方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,Selenium 是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame 方法来切换 Frame。示例如下:
登录qq空间小案例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from multiprocessing import Pooldr = webdriver.Chrome(r'D:\an\Lib\site-packages\chromedriver.exe')
dr.get('https://qzone.qq.com/')
dr.switch_to.frame('login_frame')
dr.find_element(By.PARTIAL_LINK_TEXT,'密码登录').click()
dr.find_element(By.ID,'u').send_keys('80713767')
dr.find_element(By.ID,'p').send_keys('1234567')
dr.find_element(By.ID,'login_button').click()前进后退
平常我们使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back 方法后退,使用 forward 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()Cookies
使用 Selenium,还可以方便地对 Cookies 进行操作,例如获取、添加、删除 Cookies 等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
选项卡管理
在访问网页的时候,我们通常会开启多个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
示例如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,
NoSuchElementException
browser = webdriver.Chrome()
try:browser.get('https://www.baidu.com')
except TimeoutException:print('Time Out')
try:browser.find_element_by_id('hello')
except NoSuchElementException:print('No Element')
finally:browser.close()
案例:振坤行商品信息
振坤行分析:
- 不登陆,只允许搜索一次,搜索第二次就会封禁IP,此IP以后每次搜索则会跳转登陆页面
- 登录必须企业认证
以下是假如不登陆可以搜索无限次的情况下,进行爬取商品信息的代码(学习用法即可)
下面代码为获取振坤行商品信息
import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from multiprocessing import Pooldef get_data(key):global browsertry:options = webdriver.ChromeOptions()# selenium新版本: 将谷歌驱动网址用service包裹一下service = Service('D:\extention\spider\day4\chormedriver\chromedriver-win64\chromedriver.exe')# 句柄browser = webdriver.Chrome(service=service, options=options)# 访问网址browser.get('https://www.zkh.com/')# 最大化浏览器窗口browser.maximize_window()# 智能等待wait = WebDriverWait(browser, 10)# 直到搜索框出现wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'form-key')))# 输入关键词keybrowser.find_element(By.CLASS_NAME, 'form-key').send_keys(key)# 输入回车browser.find_element(By.CLASS_NAME, 'form-key').send_keys(Keys.ENTER)# 爬取商品价格信息while True:page = 1# 等待搜索结果出来time.sleep(0.5)# 智能等待商品元素出现# 完整性和唯一性: 类名应该是目标元素的完整类名,并且最好是唯一的。# WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='total-main-sku-wapper']/div[@class='goods-list-outer']/div[@class='goods-item-box-new clearfix flow-side-goods-item-inner']/div[@class='goods-item-wrap-new clearfix common-item-wrap']")))# 右侧滚动条拉到最后for i in range(6):browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')# 等待浏览器拉到底部time.sleep(1)print(1111)# 智能等待最后一个商品元素出现WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, "//div[@class='goods-item-wrap-new clearfix common-item-wrap'][50]")))print(f"-------------------当前{key},第{page}页")divs = browser.find_elements(By.XPATH, "//div[@class='goods-item-wrap-new clearfix common-item-wrap']")for div in divs:integer = div.find_element(By.XPATH, "//span[@class='integer xh-highlight']").textdecimal = div.find_element(By.XPATH, "//span[@class='decimal']").textprice = integer + decimalprint(price)# 获取最大页max_page = browser.find_element(By.XPATH, "//button[@class='numberbtn'][6]").textif page == max_page:break# 点击下一页page += 1browser.find_element(By.XPATH, "//button[@class='nextbtn']").click()finally:browser.close()if __name__ == '__main__':get_data("口罩")
多进程优化
if __name__ == '__main__':# get_data("口罩")pool = Pool(3)try:for kw in ['雨衣', '螺丝', '口罩']:pool.apply_async(get_data, args=(i,))except KeyboardInterrupt:pool.terminate()finally:pool.close()pool.join()如何加代理?
首先你得有代理,可以买小象代理或者芝麻代理
proxy = 'http://{}'.format('183.165.224.223:4231')
proxies = {'http': proxy,'https': proxy,}option = webdriver.ChromeOptions()
option.add_argument('--proxy-server={}'.format(proxy))
dr = webdriver.Chrome(r'D:\an\Lib\site-packages\chromedriver.exe',options=option)
dr.get('https://2023.ip138.com/')
如何规避监测风险?
网站会根据环境变量检查你是否为selenium,所以我们要伪装环境变量,消除指纹
stealth.min.js就是一系列修改环境变量的方法
with open('stealth.min.js') as f:js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js
})
这里提供一个检测浏览器环境的网站给你参考
https://bot.sannysoft.com/
stealth.min.js安装方法:
-
安装node.js环境
-
运行命令即可获得此文件
npx extract-stealth-evasions
selenium里的xpath和正常xpath区别
- 正常:
- 获得文字信息: "//a/text()"
- 获取属性: "//a/@href"
- selenium
- 获得文字信息: "//a".text
- 获取属性: "a".get_attribute('href')
弊端
- 登录需要滑块验证,selenium无法爬取
- 登录需要手机号验证码,selenium无法爬取
适用场景
- 不登陆的数据爬取
- 根据用户名和密码进行登录的网站的 数据爬取
更多精致内容




![HAJX[2024] 15Day游记](https://img.zcool.cn/community/01d0155da69a02a801209e1fd6db36.gif)