Python爬虫
一、爬虫相关概念介绍
1.什么是互联网爬虫
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据URL进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心
- 爬取网页:爬取整个网页,包含了网页中所有的内容
- 解析数据:将网页中你得到的数据进行解析,也就是找到你所需要的数据
- 难点:爬虫和反爬虫之间的博弈。即“抓取数据”和”拒绝给你数据”之间的博弈
3.爬虫分类
- 通用爬虫
- 聚焦爬虫
根据需求,实现爬虫程序,抓取需要的数据
设计思路
1.确定要爬取的url
如何获取Url
2.模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问
3.解析html字符串(根据一定规则提取需要的数据)
如何解析
4.urllib库使用
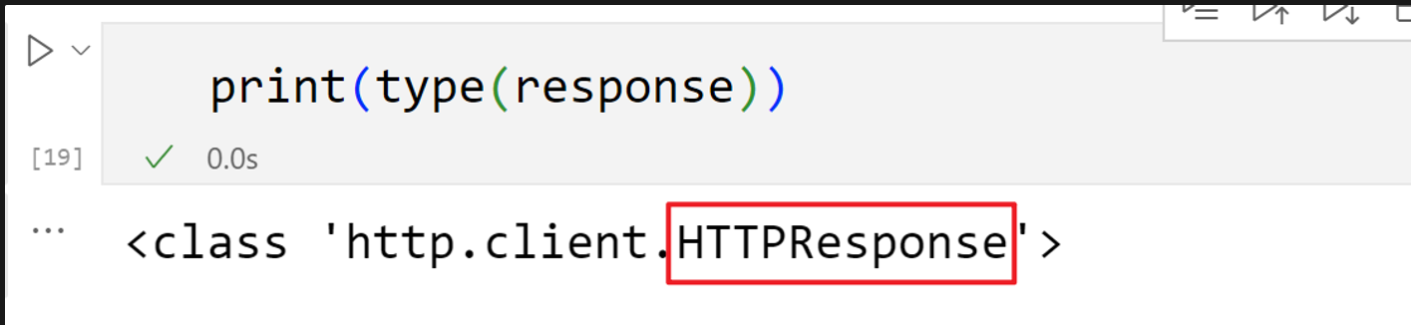
二、一个类型and六个方法
HTTPResponse类型
表示从服务器接收到的 HTTP 响应的对象类型,通常在处理网络请求时使用。它包含了服务器返回的各种信息,如状态码、响应头和响应体
read()readline()只读取一行readlines()读取多行getcode()获取状态码geturl()getheaders()获取状态信息
三、下载
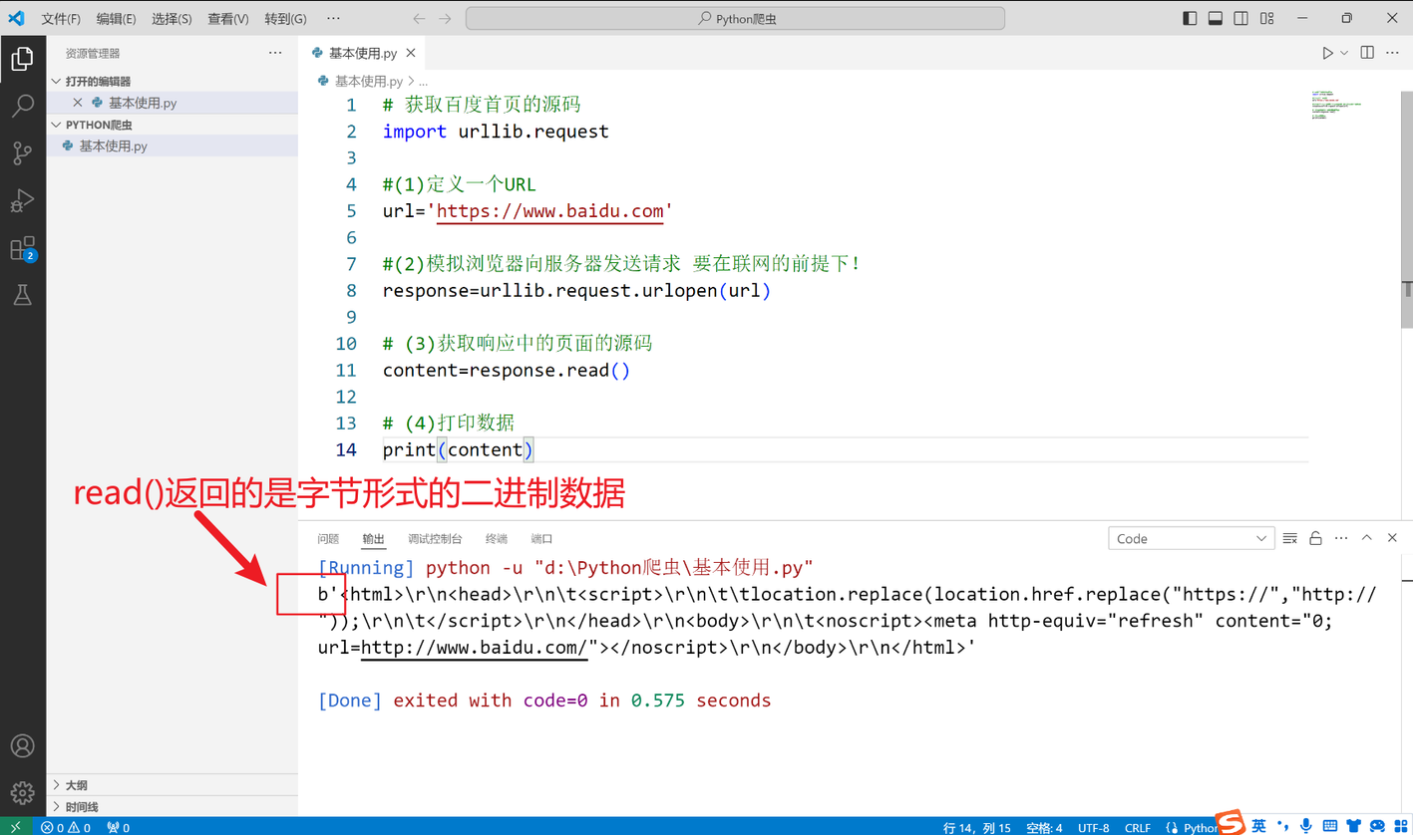
下载网页
#下载网页
url_page='http://www.baidu.com'
urllib.request.urlretrieve(url_page,'baidu.html')
下载图片
通过“复制图像链接”获取图片的存取路径,注意urlretrieve()函数里要对应好文件格式
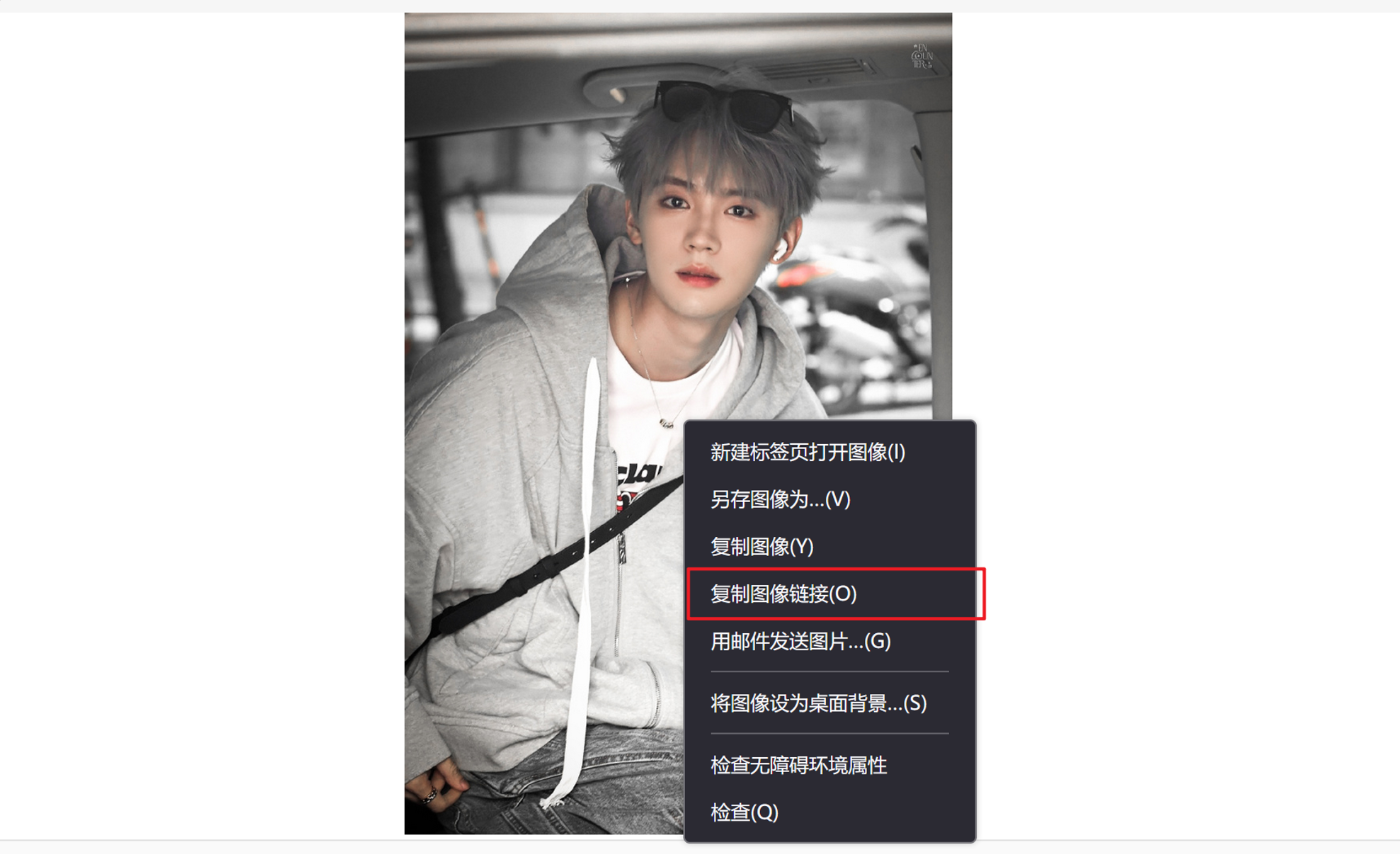
#下载图片
url_img='https://ww1.sinaimg.cn/mw690/007SWX7Ugy1hr6kqd0netj32wi4crqve.jpg'
urllib.request.urlretrieve(url_img,'zhouyiran.jpg')
下载视频
鼠标右击选择“检查”
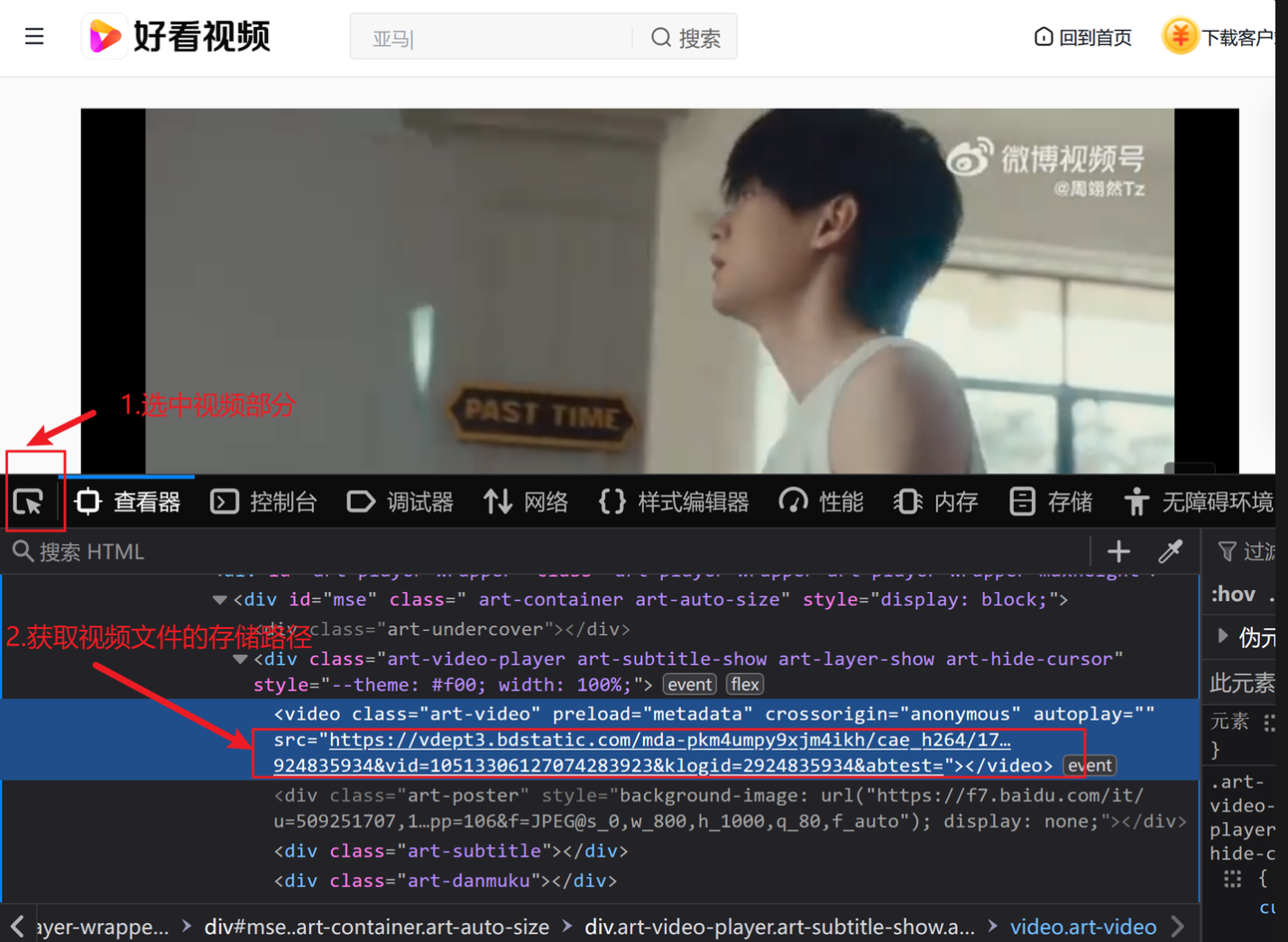
# 下载视频
url_video='https://vdept3.bdstatic.com/mda-pi79hyfq8jscww7u/360p/h264/1694155424021989258/mda-pi79hyfq8jscww7u.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1720607496-0-0-d017b040f470523698685d8261770983&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=1896481070&vid=10142877359436078513&klogid=1896481070&abtest=101830_2-102148_1-17451_2-3000225_3'
urllib.request.urlretrieve(url_video,'zhou.mp4')
四、请求对象的定制(user-agent反爬)
HTTP:HTTP以明文形式传输数据,数据在传输过程中没有加密,容易被中间人截获和篡改。
HTTPS:HTTPS使用SSL/TLS协议对数据进行加密,确保数据在传输过程中是安全的,即使被截获也无法轻易解密
user-agent:Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的UA来判断的。UA可以进行伪装。
URL的组成

首先找到百度首页的user-agent
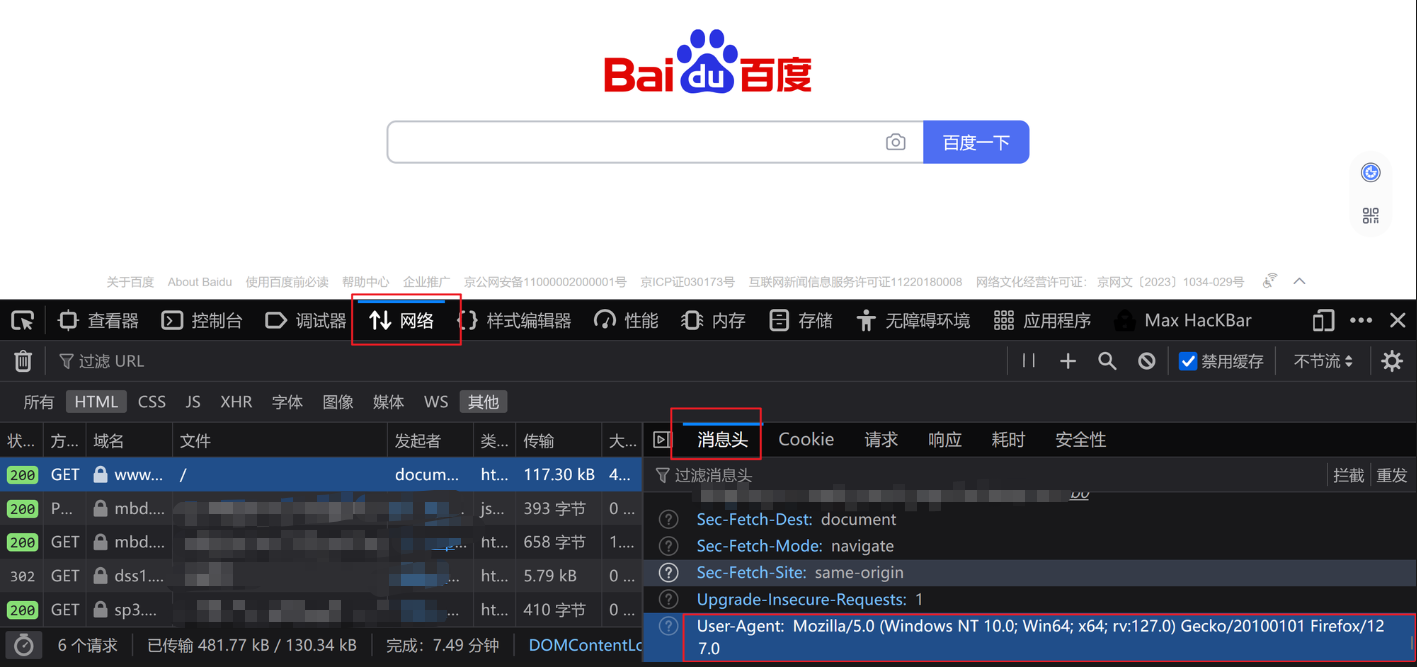
然后用以下代码进行反爬
import urllib.requesturl='https://www.baidu.com'# 构造字典
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0'
}# 因为参数位置不对应,所以要写明参数名,再写参数值
request=urllib.request.Request(url=url,headers=headers)# 进行包装后再读取
response=urllib.request.urlopen(request)content=response.read().decode('utf-8')print(content)