引言
该项目将引导您完成构建简单 GPT-2 模型的所有步骤,并使用 Taylor Swift 和 Ed Sheeran 的一堆歌曲进行训练。本文的数据集和源代码将在 Github 上提供。
构建 GPT-2 架构
我们将逐步推进这个项目,不断优化一个基础的模型框架,并在其基础上增加新的层次,这些层次都是基于 GPT-2 的原始设计。
我们将按照以下步骤进行:
- 制作一个定制的分词工具
- 开发一个数据加载程序
- 培养一个基础的语言处理能力
- 完成 GPT-2 架构的实现(第二部分)
该项目分为两个部分,第一个部分介绍语言建模的基础知识,第二部分直接跳到 GPT-2 实现。我建议您按照本文进行操作并自己构建它,这将使学习 GPT-2 变得更加有趣和有趣。
最终模型:
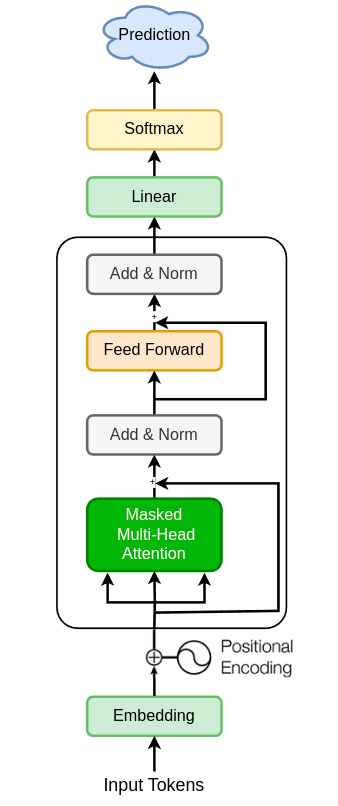
1. 构建自定义分词器
语言模型不像我们一样看到文本。相反,它们将数字序列识别为特定文本的标记。因此,第一步是导入我们的数据并构建我们自己的角色级别分词器。
data_dir = "data.txt"
text = open(data_dir, 'r').read() # load all the data as simple string# Get all unique characters in the text as vocabulary
chars = list(set(text))
vocab_size = len(chars)

如果您看到上面的输出,我们就有了在初始化过程中从文本数据中提取的所有唯一字符的列表。字符标记化基本上是使用词汇表中字符的索引位置并将其映射到输入文本中的相应字符。
# build the character level tokenizer
chr_to_idx = {c:i for i, c in enumerate(chars)}
idx_to_chr = {i:c for i, c in enumerate(chars)}def encode(input_text: str) -> list[int]:return [chr_to_idx[t] for t in input_text]def decode(input_tokens: list[int]) -> str:return "".join([idx_to_chr[i] for i in input_tokens])

import torch
# use cpu or gpu based on your system
device = "cpu"
if torch.cuda.is_available():device = "cuda"# convert our text data into tokenized tensor
data = torch.tensor(encode(text), dtyppe=torch.long, device=device)
现在,我们有了标记化的张量数据,其中文本中的每个字符都转换为各自的标记。
import torchdata_dir = "data.txt"
text = open(data_dir, 'r').read() # load all the data as simple string# Get all unique characters in the text as vocabulary
chars = list(set(text))
vocab_size = len(chars)# build the character level tokenizer
chr_to_idx = {c:i for i, c in enumerate(chars)}
idx_to_chr = {i:c for i, c in enumerate(chars)}def encode(input_text: str) -> list[int]:return [chr_to_idx[t] for t in input_text]def decode(input_tokens: list[int]) -> str:return "".join([idx_to_chr[i] for i in input_tokens])# convert our text data into tokenized tensor
data = torch.tensor(encode(text), dtyppe=torch.long, device=device)
2. 构建数据加载器
现在,在构建模型之前,我们必须定义如何将数据输入模型进行训练,以及数据的维度和批量大小。
让我们定义我们的数据加载器如下:
train_batch_size = 16 # training batch size
eval_batch_size = 8 # evaluation batch size
context_length = 256 # number of tokens processed in a single batch
train_split = 0.8 # percentage of data to use from total data for training# split data into trian and eval
n_data = len(data)
train_data = data[:int(n_data * train_split)]
eval_data = data[int(n_data * train_split):]class DataLoader:def __init__(self, tokens, batch_size, context_length) -> None:self.tokens = tokensself.batch_size = batch_sizeself.context_length = context_lengthself.current_position = 0def get_batch(self) -> torch.tensor:b, c = self.batch_size, self.context_lengthstart_pos = self.current_positionend_pos = self.current_position + b * c + 1# if the batch exceeds total length, get the data till last token# and take remaining from starting token to avoid always excluding some dataadd_data = -1 # n, if length exceeds and we need `n` additional tokens from startif end_pos > len(self.tokens):add_data = end_pos - len(self.tokens) - 1end_pos = len(self.tokens) - 1d = self.tokens[start_pos:end_pos]if add_data != -1:d = torch.cat([d, self.tokens[:add_data]])x = (d[:-1]).view(b, c) # inputsy = (d[1:]).view(b, c) # targetsself.current_position += b * c # set the next positionreturn x, ytrain_loader = DataLoader(train_data, train_batch_size, context_length)
eval_loader = DataLoader(eval_data, eval_batch_size, context_length)

我们现在已经开发了自己的专用数据加载工具,它既可以用于模型的训练阶段,也可以用于评估阶段。这个工具包含一个 get_batch 功能,它能够一次性提供大小为 batch_size 乘以 context_length 的数据批次。
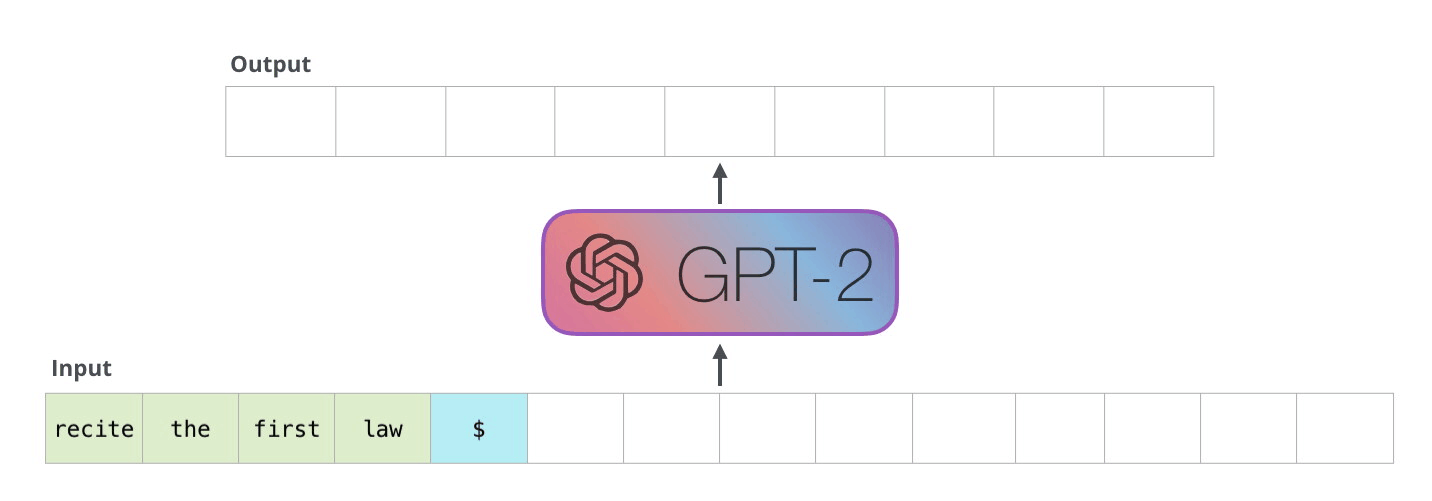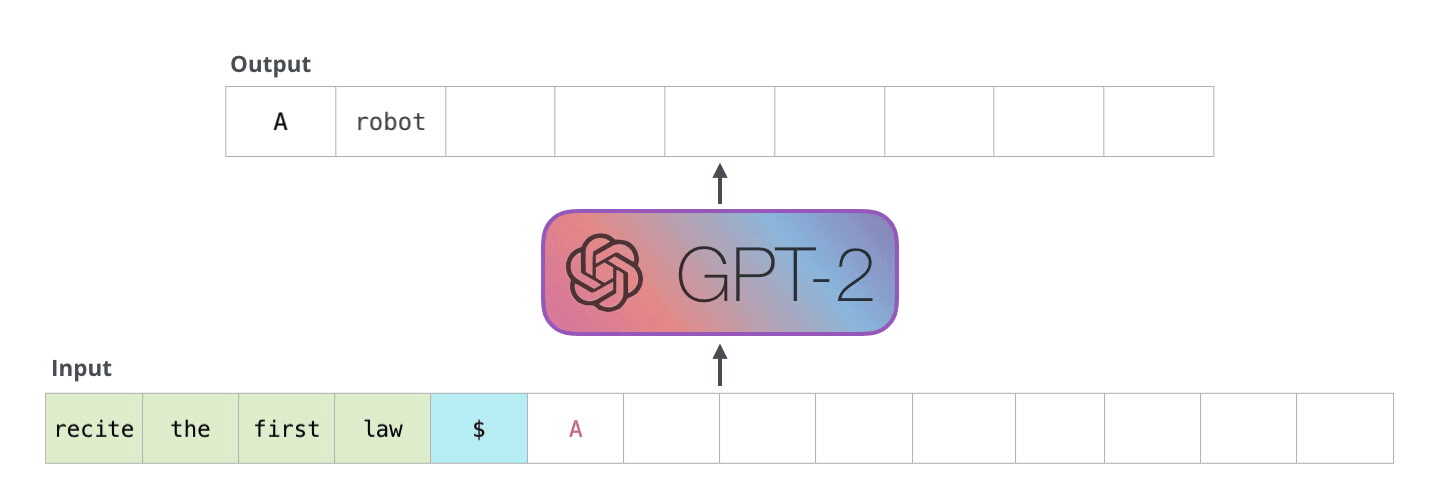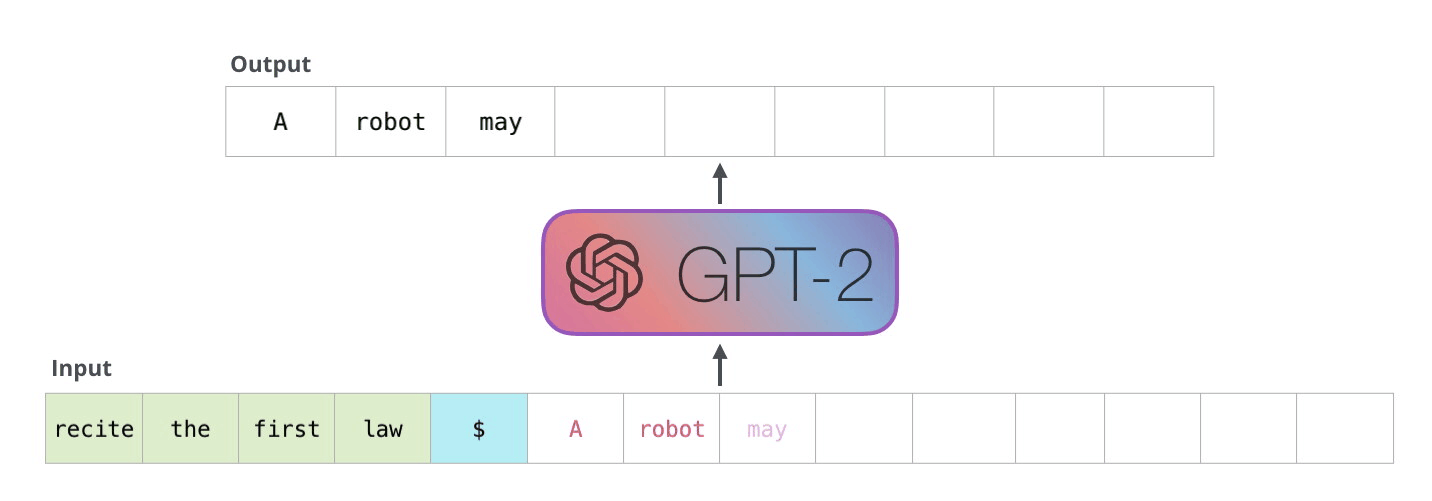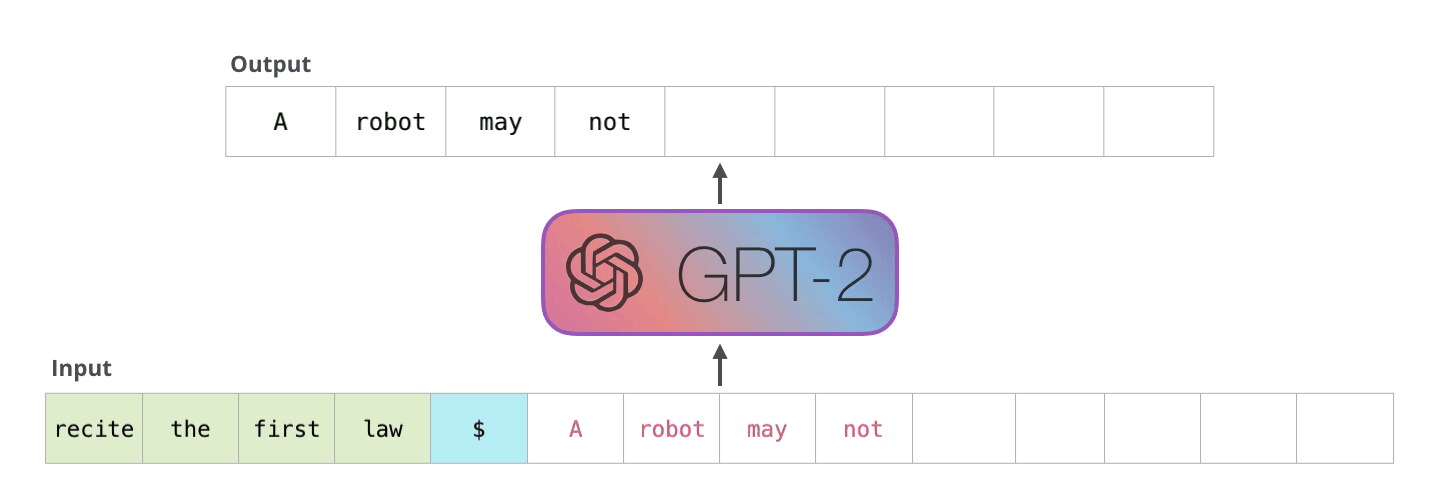
如果你好奇为什么 x 的范围是从序列的起始点到结束点,而 y 的范围则是从 x 的起始点后一位到结束点后一位,这是因为模型的核心任务是预测给定前序序列之后的下一个元素。换句话说,在 y 中会多出一个标记,这样模型就可以基于 x 中的最后 n 个标记来预测下一个,也就是第 (n+1) 个标记。如果这听起来有些难以理解,可以参阅下面的图解说明。
3. 训练简单的语言模型
现在,我们即将利用我们刚刚加载的数据,来搭建和训练一个基础的语言模型。
在本节中,我们将保持操作的简洁性,采用一个简单的二元语法模型,即基于上一个词来预测下一个词。如你所见,我们将只利用 Embedding 层,而忽略主解码模块。
Embedding 层能够为词汇表中的每个字符表示出 n = d_model 个独特的属性,并且该层会根据字符在词汇表中的索引来提取这些属性。
你会惊讶地发现,仅仅依靠 Embedding 层,模型就能表现出色。我们将通过逐步增加更多的层来优化模型,所以请耐心等待并继续关注。
嵌入的维度,也就是 d_model,目前设置为等于词汇表的大小 vocab_size,这是因为模型的最终输出需要对应到词汇表中每个字符的对数几率,以便计算它们各自的概率。在未来,我们会引入一个线性层(Linear 层),它负责将 d_model 的输出维度转换为 vocab_size,这样我们就可以使用自定义的嵌入维度 embedding_dimension。
import torch.nn as nn
import torch.nn.functional as Fclass GPT(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.wte = nn.Embedding(vocab_size, d_model) # word token embeddingsdef forward(self, inputs, targets = None):logits = self.wte(inputs) # dim -> batch_size, sequence_length, d_modelloss = Noneif targets != None:batch_size, sequence_length, d_model = logits.shape# to calculate loss for all token embeddings in a batch# kind of a requirement for cross_entropylogits = logits.view(batch_size * sequence_length, d_model)targets = targets.view(batch_size * sequence_length)loss = F.cross_entropy(logits, targets)return logits, lossdef generate(self, inputs, max_new_tokens):# this will store the model outputs along with the initial input sequence# make a copy so that it doesn't interfare with model for _ in range(max_new_tokens):# we only pass targets on training to calculate losslogits, _ = self(inputs) # for all the batches, get the embeds for last predicted sequencelogits = logits[:, -1, :] probs = F.softmax(logits, dim=1) # get the probable token based on the input probsidx_next = torch.multinomial(probs, num_samples=1) inputs = torch.cat([inputs, idx_next], dim=1)# as the inputs has all model outputs + initial inputs, we can use it as final outputreturn inputsm = GPT(vocab_size=vocab_size, d_model=d_model).to(device)
我们已经成功构建了一个模型,它仅由一个嵌入层(Embedding layer)和用于生成标记的 Softmax 函数组成。接下来,让我们观察一下,当模型接收到一些输入字符时,它的反应和表现会是怎样。
现在,我们来到了最后的关键步骤——训练模型,让它学会识别和理解字符。接下来,我们将配置优化器。目前,我们选择使用一个基础的 AdamW 优化器,设置的学习率为 0.001。在未来的章节中,我们会探讨如何进一步提升优化过程。
lr = 1e-3
optim = torch.optim.AdamW(m.parameters(), lr=lr)
Below is a very simple training loop.
epochs = 5000
eval_steps = 1000 # perform evaluation in every n steps
for ep in range(epochs):xb, yb = train_loader.get_batch()logits, loss = m(xb, yb)optim.zero_grad(set_to_none=True)loss.backward()optim.step()if ep % eval_steps == 0 or ep == epochs-1:m.eval()with torch.no_grad():xvb, yvb = eval_loader.get_batch()_, e_loss = m(xvb, yvb)print(f"Epoch: {ep}tlr: {lr}ttrain_loss: {loss}teval_loss: {e_loss}")m.train() # back to training mode

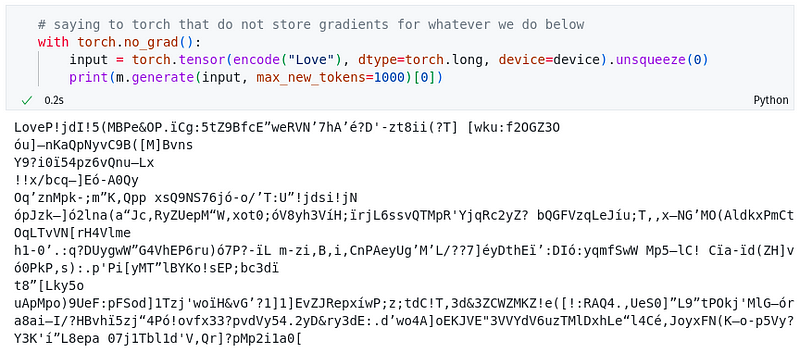
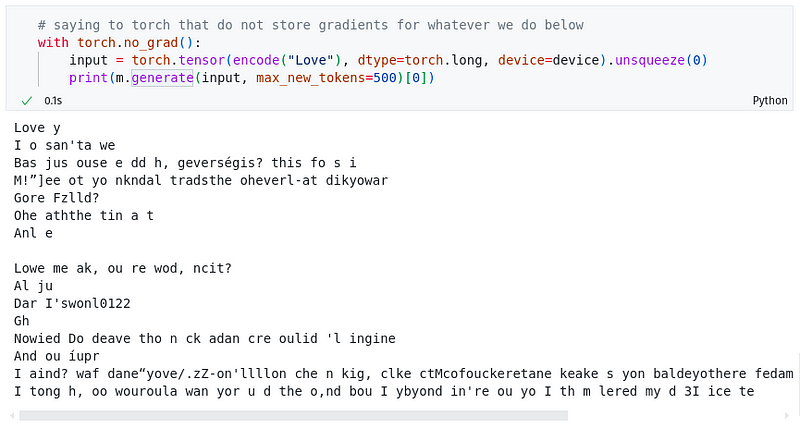
我们取得了相当不错的损失值。但我们还没有完全成功。你可以看到,直到训练的第2000个周期,错误率有了显著的下降,但之后的提升就不明显了。这是因为模型目前还缺乏足够的智能(或者说是层数/神经网络的数量),它仅仅是在比较不同字符的嵌入表示。
现在模型的输出看起来如下所示:
本文由mdnice多平台发布