原文:https://blog.csdn.net/jarodyv/article/details/128994176
参考:https://blog.csdn.net/engchina/article/details/138258047
为了使大模型的生成和表达更加多样,GPT采用了tempture以及top-p方法。
GPT的输出层后面一般跟着softmax,在判别式模型中我们会输出概率最高的那一类别。
这样的贪心策略会使得模型的输出相对固定,生成内容很死板。因此提出了此两种方法。
top_p采样
chatgpt采用一种top-p方法来进行采样,解决该问题。简而言之,就是对结果从高到低排序,按累积概率p截尾去掉概率小的分布,最后筛选得到几个概率较高的结果,归一化后按分布抽样。
温度采样
温度采样受统计热力学的启发,高温意味着更可能遇到低能态。在概率模型中,logits 扮演着能量的角色,我们可以通过将 logits 除以温度来实现温度采样,然后将其输入 Softmax 并获得采样概率。
越低的温度使模型对其首选越有信心,而高于 1 的温度会降低信心。0 温度相当于 argmax 似然,而无限温度相当于于均匀采样。
温度采样中的温度与玻尔兹曼分布有关,其公式如下所示:
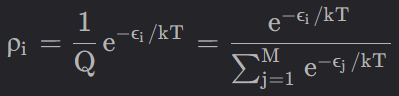
该式就是softmax的变体,T值越大时,结果越呈现一种均匀分布。
此外还有频率惩罚(frquency_penalty)、存在惩罚(presence_penalty),使大模型有更大的概率输出从未使用的词语,去除重复的输出或提示。
最后,还有likehood,生成新词时,会为每一个词赋likehood值,某词的likehood值越高,则越有可能在下一轮输出某词。




![[深入理解Java虚拟机]HotSpot虚拟机对象](https://img2024.cnblogs.com/blog/1533409/202407/1533409-20240714204252307-306282878.png)