Transformation 转换算子
RDD 整体上分为 Value、双Value、Key-Value 三种类型。
Value 类型
Map算子
函数签名
def map[U:ClassTag](f:T=>U):RDD[U],它通过接受一个参数,并且遍历该 RDD 中每一个数据项,依次应用函数 f 并得到新的 RDD;
object Value01_map {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")val sc = new SparkContext(conf)// 创建RDDval rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)// 执行 map 算子val rdd2 = rdd.map(_ * 2)rdd2.collect().foreach(println)sc.stop()}
}
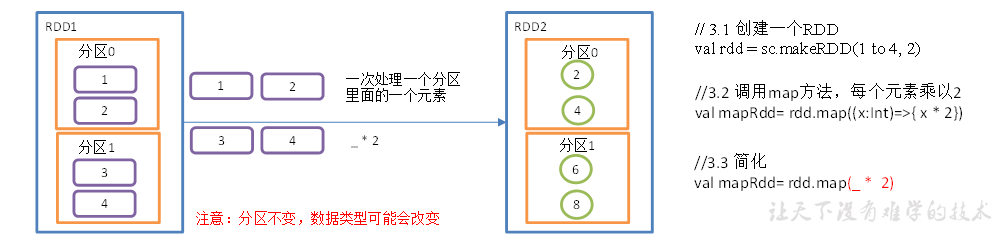
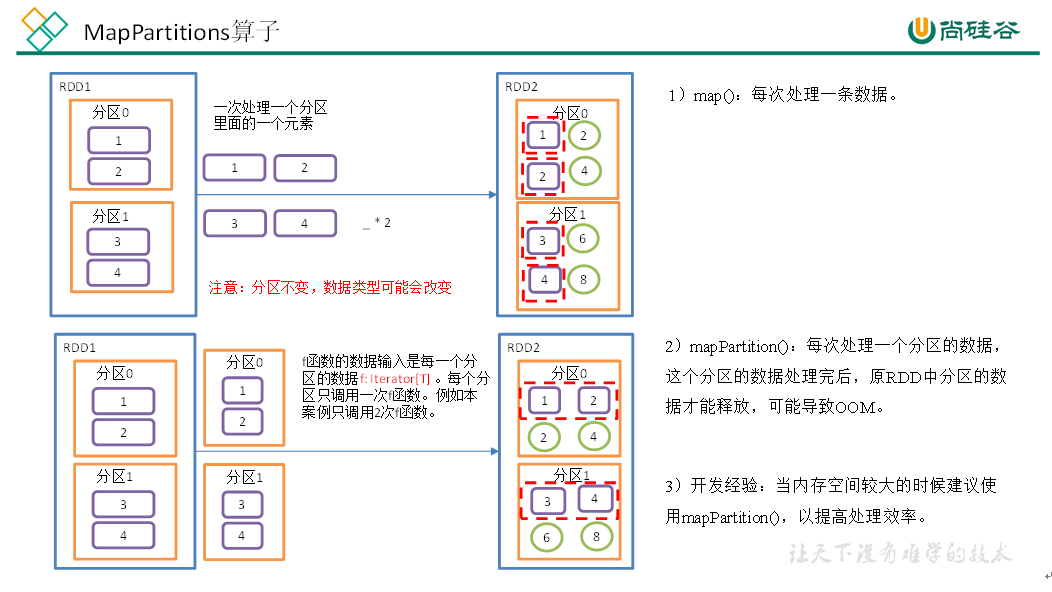
mapPartitions()以分区为单位执行 Map 算子,将一个分区的数据放入迭代器中,批处理一次处理一个分区的数据。
def mapPartitionsFunc(): Unit = {val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")val sc = new SparkContext(conf)val rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)val rdd1 = rdd.mapPartitions(x=>x.map(_*2))rdd1.collect().foreach(println)// 将RDD的一个分区作为几个集合进行结构转换,只需要保证最后一个分区输出一个集合即可val value:RDD[Int] = rdd.mapPartitions(list => {println("mapPartitoins调用")list.filter(i => i%2 == 0)})value.collect().foreach(println)sc.stop()
}
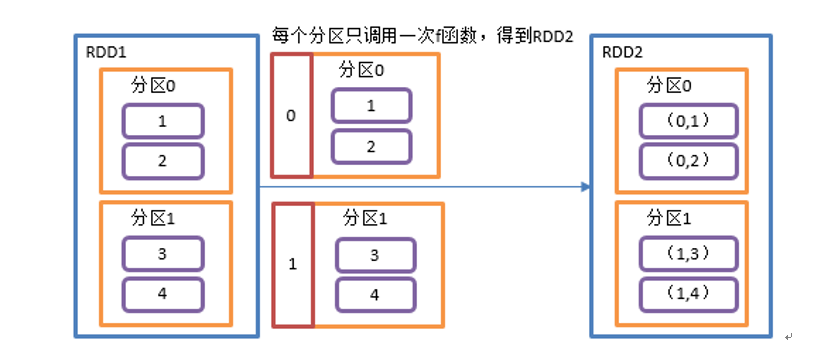
mapPartitionsWithIndex(),将分区号、分区数据作为一个元组进行处理。
def mapPartitionsWithIndexFunc(): Unit = {val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")val sc = new SparkContext(conf)val rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)val rdd1 = rdd.mapPartitionsWithIndex((index, items) => {items.map(item=>{(index, item*2)})})rdd1.collect().foreach(println)sc.stop()
}
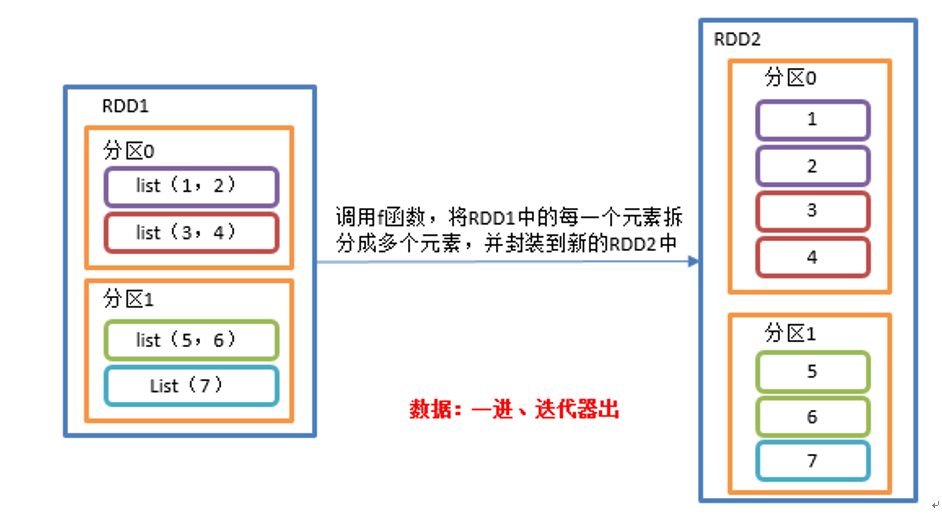
flatMap(),与 map 类似将 RDD 中每个元素通过 f 函数转换为新元素并封装到 RDD 中,区别在于 f 函数的返回值是一个集合,并将每一个该集合中的元素拆分出来放到新的 RDD中。
def flatMapTest(): Unit = {val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")val sc = new SparkContext(conf)val listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)listRDD.flatMap(x=>x).collect.foreach(println)sc.stop()}
三种 Map 方式对比:
map()每次处理分区中的一个数据;mapPartitions()每次处理一个分区的数据,并且只有当前分区数据处理完毕后才能处理下一个分区数据,所以可能导致 OOM;mapPartitionsWithIndex()处理的是分区号和数据组成的元组;