一些机器学习概念解释
点击查看代码
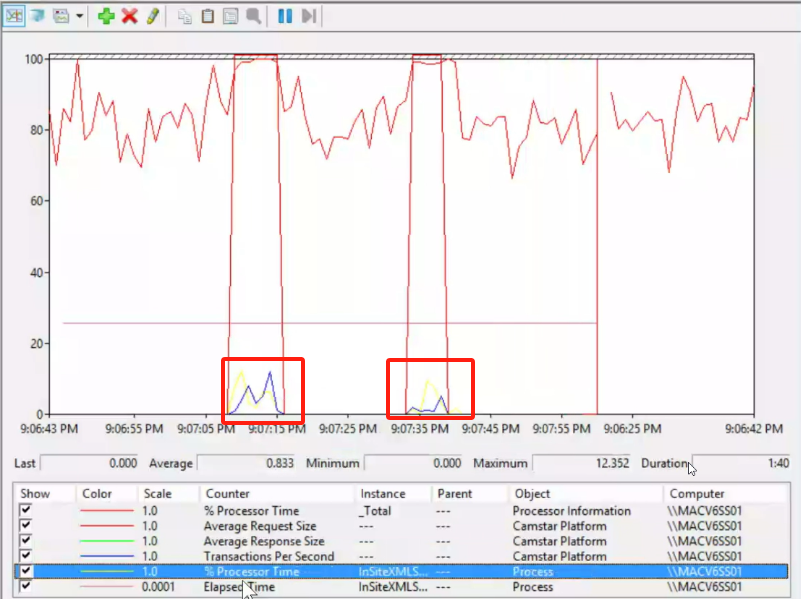
* 机器学习:是AI的一个子集,不用人类显式编程,让计算机通过算法自行学习和改进 * 监督学习:有数据、有标签,告诉机器什么是什么,让机器来学习输入和输出的映射关系。比如:分类和回归(预测)* 非监督学习:有数据没有标签,让机器自己寻找规律。比如:聚类* 半监督学习:有数据和少量标签,让机器学一点,然后自行寻找规律、探索分类* 强化学习:就是训狗。小狗自行做出动作,但是根据训犬师的引导发现有些行为可以获得零食,有些会受到惩罚。通过观察动作和奖惩之间的联系,让小狗行为达到预期。即让机器在环境中采取行动,获得反馈,从反馈里自己总结经验,以最大化奖励和最小化损失。主要是用来培训机器人的,让计算机接触一个完全没做过的任务,只告诉它目标,让它自行探索解决问题的途径,比如告诉机器人让它投篮,中了会得一分,机器人会尝试各种方法去投篮,开始可能命中率低,之后会自行总结方法,提高命中率。这类机器人代笔:阿尔法go。* 遗传算法:和强化学习类似。就是模拟人类进化,淘汰弱者适者生存,让计算器设计模型,并基于以前的模型设计更多代的模型,然后自行淘汰掉效果不好的模型,并基于留下的强者进行变异和繁衍。* 深度学习:是机器学习的另一种类,核心在于使用人工神经网络,通过层次化的方法提取和表示数据特征。比如学习识别小猫的流程:1.将猫猫图片传入输入层(让机器看到图片)--- 2. 通过隐藏层对数据进行复杂的数学运算,识别特征 --- 3. 输出层获得结果人工神经网络(Artificial Neural Network(ANN))就是让机器模仿人类神经元来进行学习,很多NN就是Neural Network的缩写。可以用于深度学习、监督学习、无监督学习、强化学习如果人工神经网络分三层来传递信息,那么深度学习可能就要分几十层甚至上百层,所以对硬件设备要求高,通常还是选择云服务器或者基站来学习。深度学习的框架有很多,两巨头是谷歌的TensorFlow和脸书的pytorch,前者学习曲线更陡峭,覆盖从低层次的数学运算到直接使用的模型,更全面;后者更容易直接用模型上手。都是不错的选择。其他还包括ONNX, Caffe, Torch,Theano, DL4J等。但一般用前两个就是了* 生成式AI: 深度学习的一种应用,利用神经网络来学习现有内容的模型和结构(比如视频、文本、图片、音频等),学习生成新内容* 大语言模型(LLM,Large Language Model):也是深度学习的一种应用,专门用于进行自然语言处理任务。【大】:模型参数量大,训练过程也需要海量文本数据集。比如谷歌的BERT模型,擅长理解上下文,但不擅长文本生成,被认为不属于生成式AI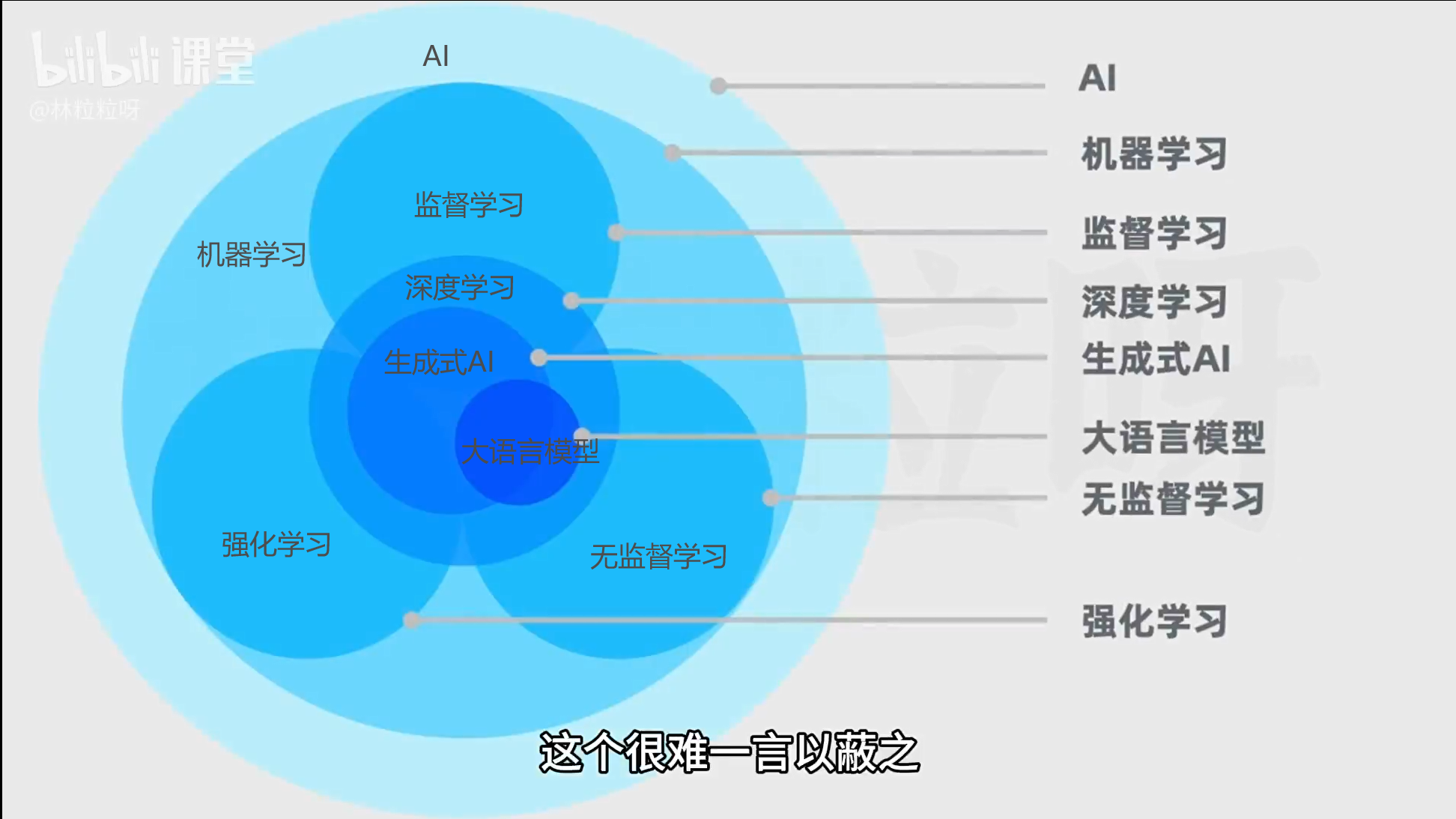
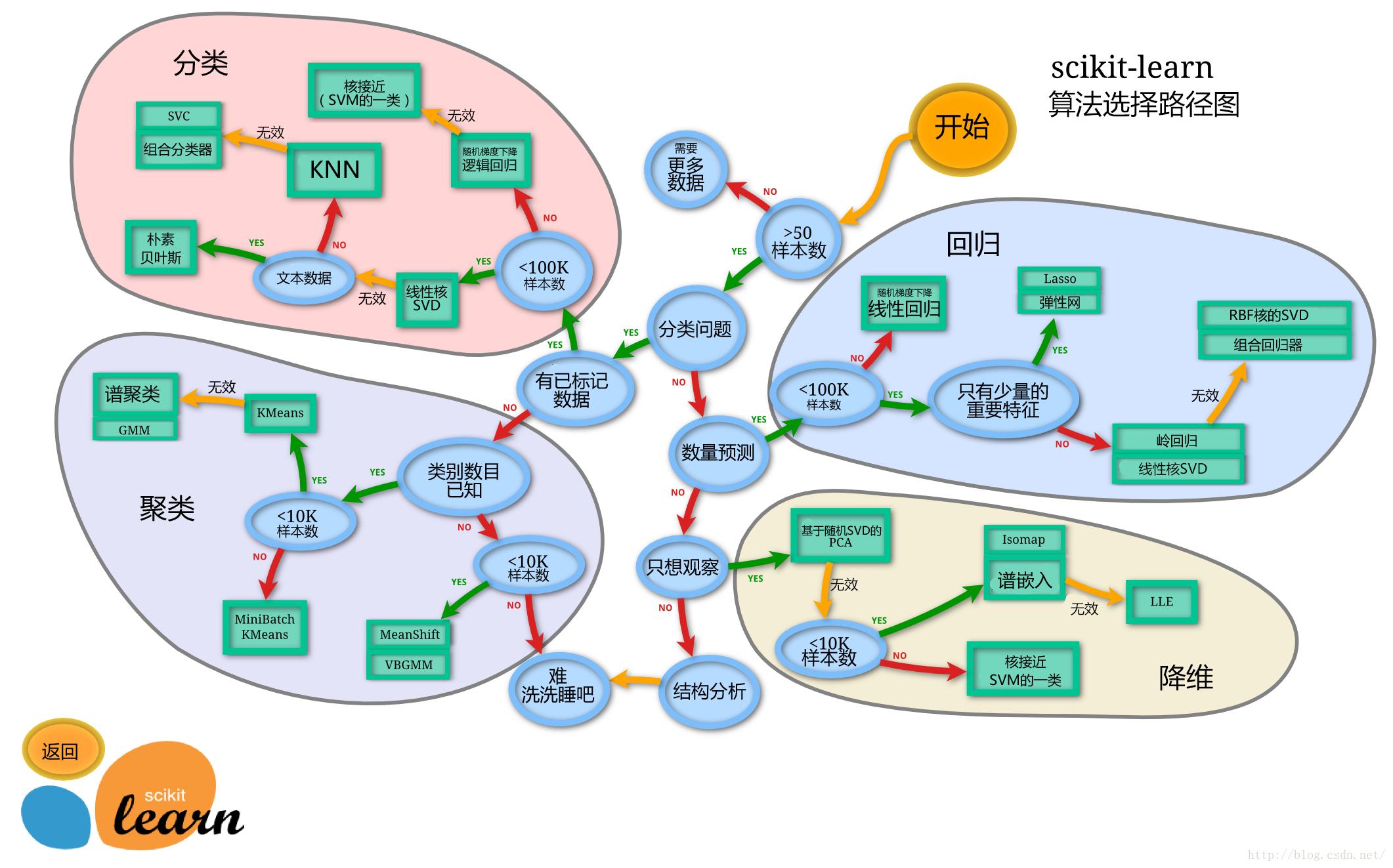
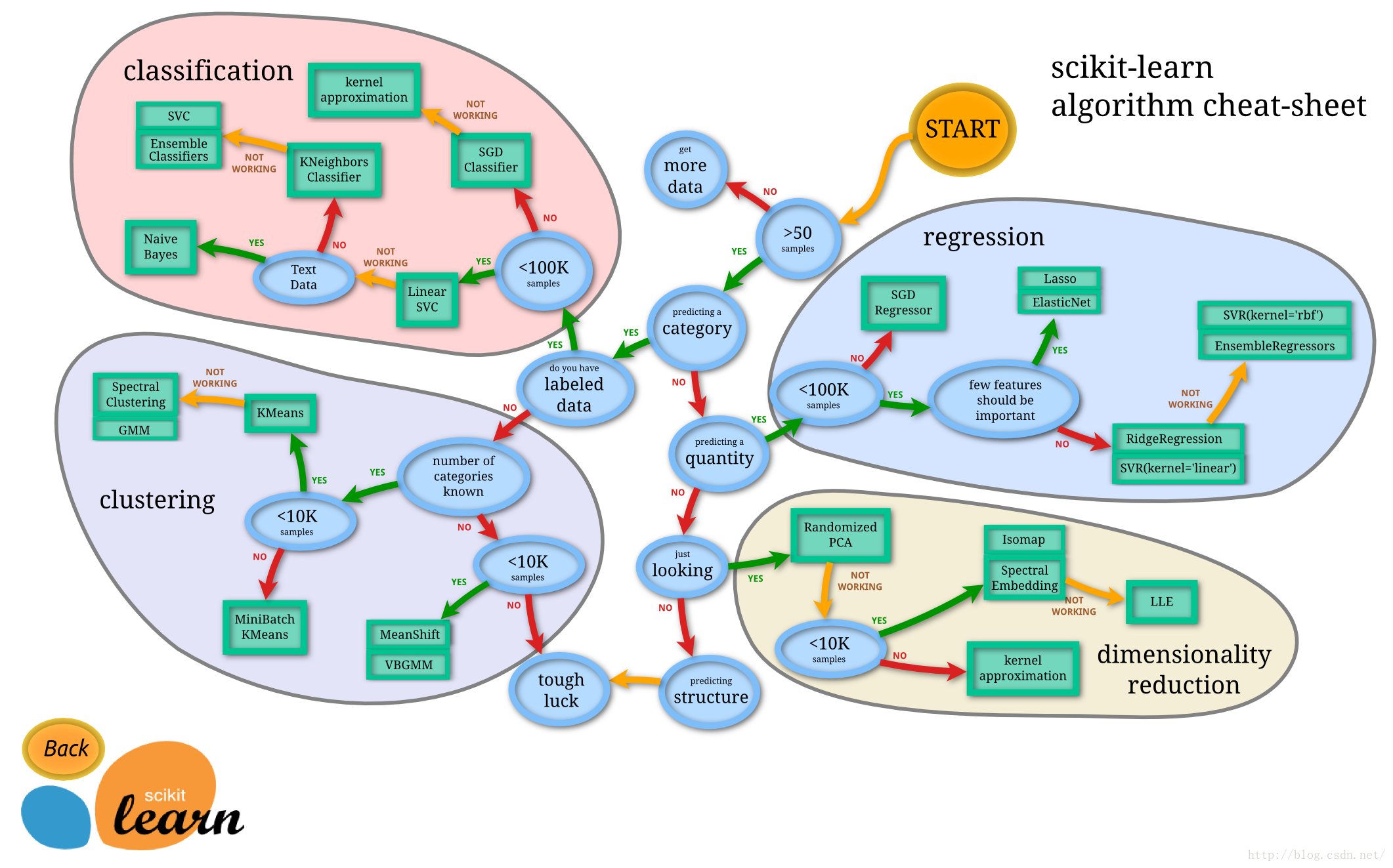
Sciki-learn:简称sklearn,是一种python中强大的传统机器学习模块。对常用的机器学习算法进行了封装,包括回归、降维、分类和聚类四大机器学习算法。具体需要使用到什么模块,可以通过查看下图来进行判断,需要用哪个模块再学具体使用方法吧。该模块的数据库很有价值,from sklearn import datasets。
LLM AI的发展史
点击查看代码
17年前 语言模型主要架构为循环神经网络 RNN(Recurrent Neural Network)—— 无法并行计算,只能依次;不擅长处理长文本,无法捕捉长距离的语义关系。后来出现RNN改良版本,长短期记忆网络LSTM(Long Short-Term Memory) —— 还是无法并行计算,处理长文本能力有限2017年 谷歌团队 Transformer >>>> ① Attention 解决了短时记忆问题(浏览全文并给予每个词不同的权重);② 位置编码解决了文字序列问题,从而同时处理序列里的所有位置,独立计算。
Transformer 模型的原理:大致可以分为编码层和解码层。以翻译为例,输入的文本进入编码层被token化 --- 传入嵌入层 ,把每个token用向量嵌入--- 将词向量位置编码,即把位置向量和词向量相加,从而让模型既理解词意思,又捕获词的位置和顺序关系 --- 编码器核心部分,结合attention自注意力机制对位置编码进一步并行计算权重。(有些是多头自注意力机制)--- 前馈神经网络,通过额外计算提高模型的表达能力 --- 将序列 传给解码器 作为输入(解码器还会把之前生成的文本共同作为输入) --- 完成嵌入层和位置编码 --- 针对已生成的序列的带掩码的多头自注意力层 --- 针对输入序列的抽象表示的多头自注意力 --- 前馈神经网络 --- 线性层和softmax层,把解码器输出的表示转化为词汇表的概率分布* 编码器和解码器都是多个堆到一起的。实际上解码器是在根据概率猜测下一个输出是什么,所以当模型开始胡说八道,就叫出现了幻觉 hallucination* Token:文本的基本单位,取决于不同的token化方法。短单词可能一个词为一个token,长单词可能会被拆解为多个token。每个token会被用整数数字表示,即token ID,以便于计算机储存。* 向量嵌入:即用一串数字来表示token,这样能记录更多的语法语义等信息* 多头自注意力:即每个attention模块关注不同的词,比如有的关注动词、有的关注情感类词等* 带掩码的多头自注意力层:编码器中自注意力会关注输入序列里所有其他词,但解码器中自注意力只关注某词前面的所有词,以保证文本生成时遵循正确的时间顺序后来transformer出现了一些变种:① 仅编码器/自编码模型:如BERT等,用来掩码语言建模、情感分析等② 仅解码器/自回归模型:如GPT-2, GPT-3等,用来文本生成③ 编码器-解码器/序列到序列模型:如T5, BART等,把一个序列转换另一个序列,用来翻译、总结2018年 OPENAI--GPT 1.0; 谷歌--BERT2019年 OPENAI--GPT 2.0; 百度--ERNIE 1.0GPT:generative pre-trained transformer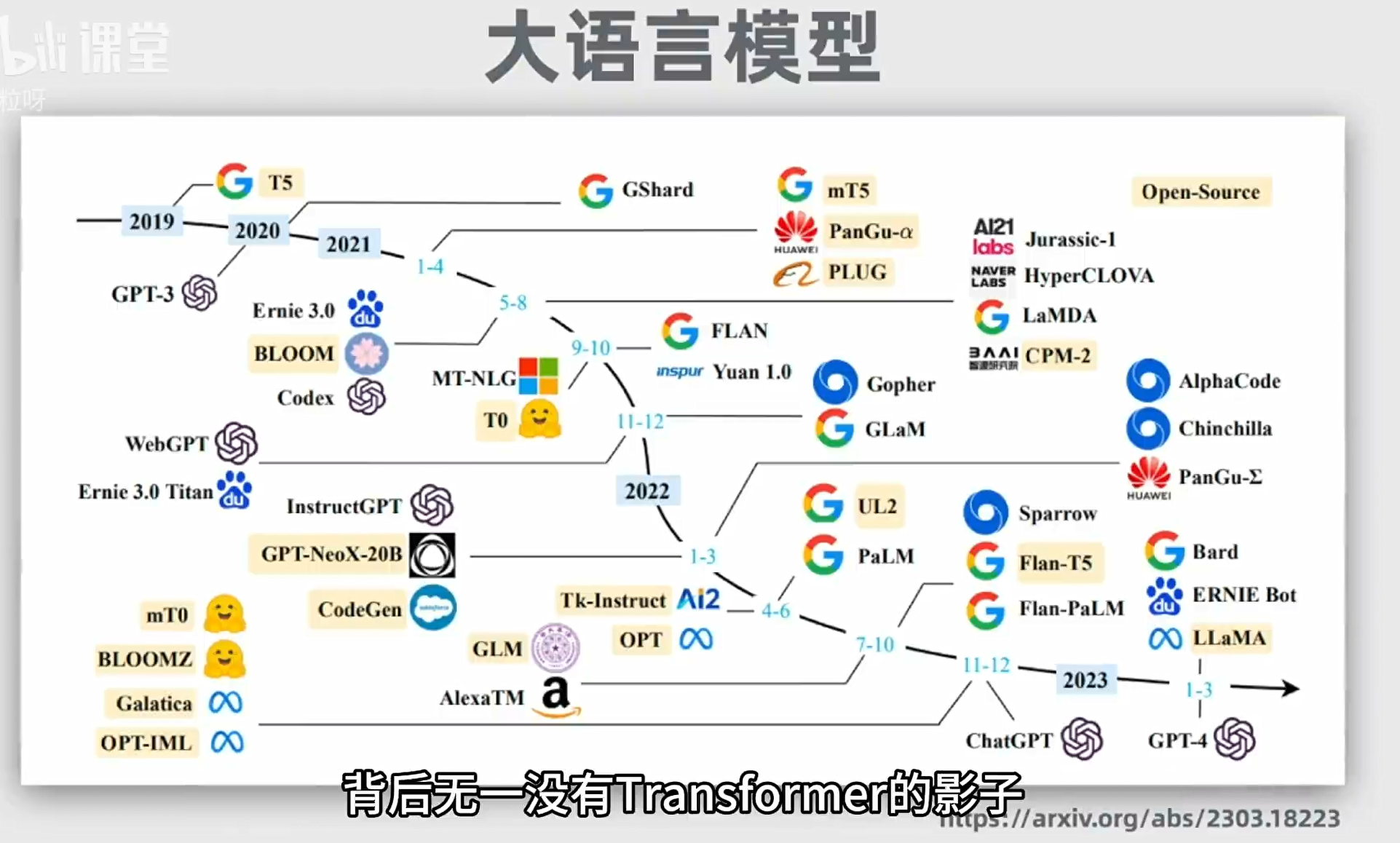

![[笔记]快速傅里叶变换(FFT)](https://img2024.cnblogs.com/blog/3322276/202407/3322276-20240715100606097-912730953.png)