转自:https://zhuanlan.zhihu.com/p/695534674
Ollama 与 OpenWebUI 介绍
Ollama 是一个运行大模型的工具,可以看成是大模型领域的 Docker,可以下载所需的大模型并暴露 API。
OpenWebUI 是一个大模型的 Web UI 交互工具,支持 Ollama,即调用 Ollama 暴露的 API 实现与大模型交互:

部署方案选型
OpenWebUI 的仓库中自带 Ollawma + OpenWebUI 的部署方式,主要是 kustomize 和 helm 这两种方式,参考 open-webui 仓库的 kubernetes 目录。
但我更推荐直接写 YAML 进行部署,原因如下:
Ollama+OpenWebUI所需 YAML 相对较少,直接根据需要写 YAML 更直接和灵活。- 不需要研究
OpenWebUI提供的kustomize和helm方式的用法。
选择模型
Llama3 目前主要有 8b 和 70b 两个模型,分别对应 80 亿和 700 亿规模的参数模型,CPU 和 GPU 都支持,8b 是小模型,对配置要求不高,一般处于成本考虑,可以直接使用 CPU 运行,而 70b 则是大模型, CPU 肯定吃不消,GPU 的配置低也几乎跑不起来,主要是显存要大才行,经实测,24G 显存跑起来会非常非常慢,32G 的也有点吃力,40G 的相对流畅(比如 Nvdia A100)。
准备 Namespace
准备一个 namespace,用于部署运行 llama3 所需的服务,这里使用 llama namespace:
kubectl create ns llama
部署 Ollama
apiVersion: apps/v1
kind: StatefulSet
metadata:name: ollamanamespace: llama
spec:serviceName: "ollama"replicas: 1selector:matchLabels:app: ollamatemplate:metadata:labels:app: ollamaspec:containers:- name: ollamaimage: ollama/ollama:latestports:- containerPort: 11434resources:requests:cpu: "2000m"memory: "2Gi"nvidia.com/gpu: "0" # 如果要用 Nvidia GPU,这里声明下 GPU 卡limits:cpu: "4000m"memory: "4Gi"volumeMounts:- name: ollama-volumemountPath: /root/.ollamatty: truevolumeClaimTemplates:- metadata:name: ollama-volumespec:accessModes: ["ReadWriteOnce"]resources:requests:storage: 200Gi # 注意要确保磁盘容量能够容纳得下模型的体积
---
apiVersion: v1
kind: Service
metadata:name: ollamanamespace: llamalabels:app: ollama
spec:type: ClusterIPports:- port: 11434protocol: TCPtargetPort: 11434selector:app: ollama
部署 OpenWebUI
OpenWebUI 是大模型的 web 界面,支持 llama 系列的大模型,通过 API 与 ollama 通信,官方镜像地址是:ghcr.io/open-webui/open-webui,在国内拉取速度非常慢,如果你的环境有 DockerHub 加速,可以替换成 DockerHub 里长期自动同步的 mirror 镜像:docker.io/imroc/open-webui:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: webui-pvcnamespace: llamalabels:app: webui
spec:accessModes: ["ReadWriteOnce"]resources:requests:storage: 2Gi---
apiVersion: apps/v1
kind: Deployment
metadata:name: webuinamespace: llama
spec:replicas: 1selector:matchLabels:app: webuitemplate:metadata:labels:app: webuispec:containers:- name: webuiimage: imroc/open-webui:main # docker hub 中的 mirror 镜像,长期自动同步,可放心使用env:- name: OLLAMA_BASE_URLvalue: http://ollama:11434 # ollama 的地址tty: trueports:- containerPort: 8080resources:requests:cpu: "500m"memory: "500Mi"limits:cpu: "1000m"memory: "1Gi"volumeMounts:- name: webui-volumemountPath: /app/backend/datavolumes:- name: webui-volumepersistentVolumeClaim:claimName: webui-pvc---
apiVersion: v1
kind: Service
metadata:name: webuinamespace: llamalabels:app: webui
spec:type: ClusterIPports:- port: 8080protocol: TCPtargetPort: 8080selector:app: webui
打开 OpenWebUI
你有很多方式可以将 OpenWebUI 暴露给集群外访问,比如 LoadBalancer 类型 Service、Ingress 等,也可以直接用 kubectl port-forward 的方式将 webui 暴露到本地:
kubectl -n llama port-forward service/webui 8080:8080
浏览器打开:http://localhost:8080,首次打开需要创建账号,第一个创建的账号为管理员账号。
下载模型
方法一:通过 OpenWebUI 下载
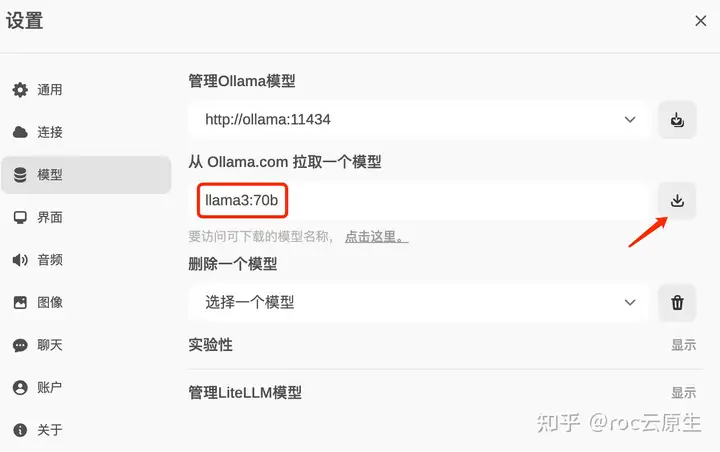
进入 OpenWebUI 并登录后,在 设置-模型 里,输出需要下载的 llama3 模型并点击下载按钮(除了基础的模型,还有许多微调的模型,参考 llama3 可用模型列表)。
接下来就是等待下载完成:

注意:如果页面关闭,下载会中断,可重新打开页面并重新输入要下载的模型进行下载,会自动断点续传。
方法二:执行 ollama pull 下载
进入 ollama 的 pod:
kubectl -n llama exec -it ollama-0 bash
执行 ollama pull 下载需要的模型,这里以下载 70b 模型为例:
ollama pull llama3:70b
等待下载完成。
注意: 如果kubectl的连接中断,下载也会中断,可重新执行命令断点续传。
你也可以使用nohup ollama pull llama3:70b &来下载,通过tail -f nohup.out查看下载进度,这样可以保证即使 kubectl 中断或退出也会继续下载。
方案三:使用 init container 自动下载模型
如果不想每次在新的地方部署需要手动下载模型,可以修改 Ollama 的部署 YAML,加个 initContainer 来实现自动下载模型(自动检测所需模型是否存在,不存在才自动下载):
initContainers:- name: pullimage: ollama/ollama:latesttty: truestdin: truecommand:- bash- -c- |model="llama3:8b" # 替换需要使用的模型,模型库列表: https://ollama.com/library/llama3ollama serve &sleep 5 # 等待 ollama server 就绪,就绪后才能执行 ollama cli 工具的命令result=`ollama list | grep $model`if [ "$result" == "" ]; thenecho "downloading model $model"ollama pull $modelelseecho "model $model already been downloaded"fivolumeMounts:- name: ollama-volumemountPath: /root/.ollama
开始对话
打开 OpenWebUI 页面,选择模型,然后就可以在对话框中开始对话了。

小技巧
GPU 调度策略
对于像 70b 这样的模型,需要较好的 GPU 才能跑起来,如果集群内有多种 GPU 节点,需要加下调度策略,避免分配到较差的 GPU。
比如要调度到显卡型号为 Nvdia Tesla V100 的节点,可以给节点打上 label:
kubectl label node gpu=v100
然后配置下调度策略:
nodeSelector:gpu: v100
省钱小妙招
- 如果使用云厂商托管的 Kubernetes 集群,且不需要大模型高可用,可以购买竞价实例(Spot),会便宜很多。
- 如果只在部分时间段使用,可以使用定时伸缩,在不需要的时间段将 Ollama 和 OpenWebUI 的副本数自动缩到 0 以停止计费,比如 使用 KEDA 的 Cron 触发器实现定时伸缩。
常见问题
节点无公网导致模型下载失败
ollama 所在机器需要能够访问公网,因为 ollama 下载模型需要使用公网,否则会下载失败,无法启动,可通过查看 init container 的日志确认:
$ kubectl logs -c pull ollama-0
time=2024-04-26T07:29:45.487Z level=INFO source=images.go:817 msg="total blobs: 5"
time=2024-04-26T07:29:45.487Z level=INFO source=images.go:824 msg="total unused blobs removed: 0"
time=2024-04-26T07:29:45.487Z level=INFO source=routes.go:1143 msg="Listening on [::]:11434 (version 0.1.32)"
time=2024-04-26T07:29:45.488Z level=INFO source=payload.go:28 msg="extracting embedded files" dir=/tmp/ollama188207103/runners
time=2024-04-26T07:29:48.896Z level=INFO source=payload.go:41 msg="Dynamic LLM libraries [cuda_v11 rocm_v60002 cpu cpu_avx cpu_avx2]"
time=2024-04-26T07:29:48.896Z level=INFO source=gpu.go:121 msg="Detecting GPU type"
time=2024-04-26T07:29:48.896Z level=INFO source=gpu.go:268 msg="Searching for GPU management library libcudart.so*"
time=2024-04-26T07:29:48.897Z level=INFO source=gpu.go:314 msg="Discovered GPU libraries: [/tmp/ollama188207103/runners/cuda_v11/libcudart.so.11.0]"
time=2024-04-26T07:29:48.910Z level=INFO source=gpu.go:126 msg="Nvidia GPU detected via cudart"
time=2024-04-26T07:29:48.911Z level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-04-26T07:29:49.089Z level=INFO source=gpu.go:202 msg="[cudart] CUDART CUDA Compute Capability detected: 6.1"
[GIN] 2024/04/26 - 07:29:50 | 200 | 45.692µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/26 - 07:29:50 | 200 | 378.364µs | 127.0.0.1 | GET "/api/tags"
downloading model llama3:70b
[GIN] 2024/04/26 - 07:29:50 | 200 | 15.058µs | 127.0.0.1 | HEAD "/"
pulling manifest ⠏ time=2024-04-26T07:30:20.512Z level=INFO source=images.go:1147 msg="request failed: Get \"https://registry.ollama.ai/v2/library/llama3/manifests/70b\": dial tcp 172.67.182.229:443: i/o timeout"
[GIN] 2024/04/26 - 07:30:20 | 200 | 30.012673354s | 127.0.0.1 | POST "/api/pull"
pulling manifest
Error: pull model manifest: Get "https://registry.ollama.ai/v2/library/llama3/manifests/70b": dial tcp 172.67.182.229:443: i/o timeout
大模型的生成速度非常慢
70b 是 700 亿参数的大模型,使用 CPU 运行不太现实,使用 GPU 也得显存足够大,实测用 24G 显存的显卡运行速度也非常非常慢,如果没有更好的 GPU,如何提升生成速度呢?
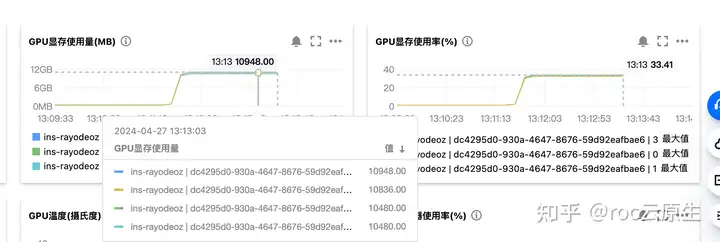
可以使用多张 GPU 卡并行,修改 ollama 的 YAML,在 requests 中声明 GPU 的地方,多声明一些 GPU 算卡:
resources:requests:nvidia.com/gpu: "4"
这样,在模型跑起来的时候,几张 GPU 算卡可以均摊显存,而不至于跑满:


![[N1CTF 2018]eating_cms 1](https://img2024.cnblogs.com/blog/3335050/202407/3335050-20240717144045078-1791221152.png)