Win10+anaconda+CUDA+pytorch+vscode配置
- 1.安装anaconda
- 2.安装CUDA
- 确认CUDA版本
- 确认CUDA和pytorch版本
- 安装CUDA
- 3.安装cudnn
- 4.安装Pytorch
- 5.vscode配置
- 安装VScode
- vscode配置pytorch环境
1.安装anaconda
官网https://www.anaconda.com 下载安装,路径全英文然后记得有一步添加path路径勾选上
2.安装CUDA
确认CUDA版本
这一步一定要确认自己电脑的GPU是否符号版本要求,打开anaconda prompt,输入nvidia-smi查看电脑GPU状态;
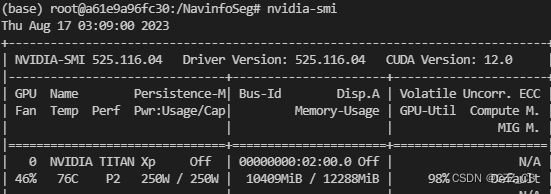
CUDA version:12.0代表你的电脑所能安装的CUDA的最高版本,CUDA版本向下兼容,可以安装比12.0小的CUDA版本;
若电脑上已经安装CUDA,安装新的版本之前一定要先卸载旧版本具体方法参考:
卸载CUDA
确认CUDA和pytorch版本
根据官网:https://pytorch.org/get-started/previous-versions/
找到自己要安装的pytorch版本选择对应的CUDA版本
安装CUDA
一定要根据上面两步确认自己的电脑应该安装哪个版本的CUDA避免后续出现问题;
官网下载:https://developer.nvidia.com/cuda-toolkit-archive
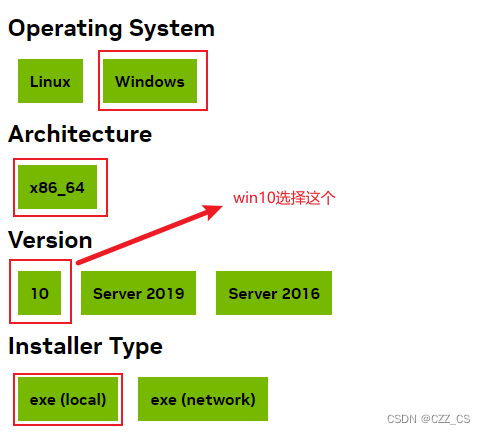
下载成功后双击.exe打开进行安装,有一步不选择精简,选择自定义安装。其他安装按照默认步骤进行即可,记住自己的安装路径;
3.安装cudnn
官网下载cudnn
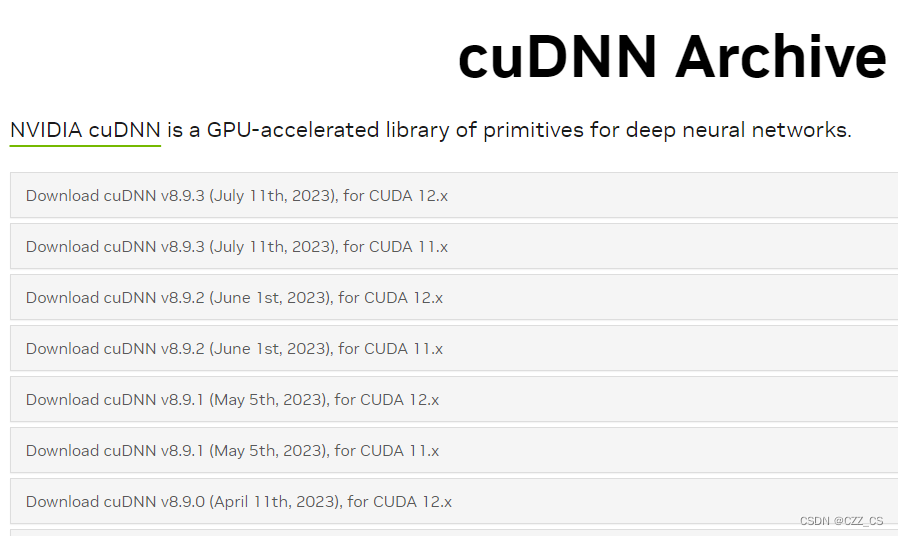
一定要选择和CUDA版本匹配的版本
注意这里下载需要注册,可以复制链接和迅雷一起食用效果更佳
下完成后,解压到本地,打开之前cuda的安装目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
找到你安装的版本目录,打开,找到bin、include、lib目录,将cuDNN压缩包内对应的文件复制到bin、include、lib目录。
4.安装Pytorch
打开anaconda prompt
pytorch和python对应的版本:https://blog.csdn.net/Y2894297258/article/details/130775874
conda enc list #查看已经存在的虚拟环境
conda remove -n pytorch_c --all #删除名为pytorch_c的虚拟环境
conda create -n pytorch_x python=3.6 #创建名为pytorch_x的虚拟环境,python的版本根据需要选择
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch #根据pytorch官网给的conda命令进行安装,直接官网安装可能慢一些,可以使用国内的镜像源
安装完成后,输入
python
import torch
torch.__version__
torch.cuda.is_avalible() #true则为安装成功GPU版本的
5.vscode配置
安装VScode
从官网下载,然后默认安装
vscode配置pytorch环境
安装python插件

添加Python解释器
按快捷键 “Ctrl+Shift+P” ,调出全局设置搜索窗口,然后输入 “Python:Select Interpreter” 后会出现 “Python:Select Interpreter” 选项,点击该选项;注意这里的python.exe要选择自己的pytorch环境下的;
激活pytorch环境
打开一个终端
若是PS中断输入
cmd #回到CMD
conda activate pytorch_c #激活pytorch环境