日升时奋斗,日落时自省
目录
1、单机架构
2、应用数据分离架构
3、应用服务集群架构
4、读写分离/主从分离架构
5、冷热分离架构
6、垂直分库架构
7、微服务架构
8、容器编排架构
9、小结
1、单机架构
特征:应用服务和数据库服务器公用一台服务器
出现场景:访问量较小,单机可以满足,由于现在硬件的升级,所以一台服务器够支持很多请求

红色箭头表示请求访问,蓝色箭头表示响应
单机程序中,其实靠的不就是数据库信息的拉取嘛,但是数据库也不是不能去掉,光服务器负责所有操作(单机架构是比较常见架构使用)
一台主机的硬件资源是有上限的,CPU、内存、硬盘、网络每次请求都会收到一个请求,都是需要消耗上述的一些资源,现在一台主机都够用(不行了其实也可以增加硬件资源,但是肯定硬件资源不能在加了就开始使用分布式)
优点:部署简单、成本低
缺点:性能有严重平静、数据库和应用互相竞争资源
2、应用数据分离架构
特征:应用服务和数据库服务使用不同服务器
出现场景:单机架构存在严重的资源竞争,导致站点变慢
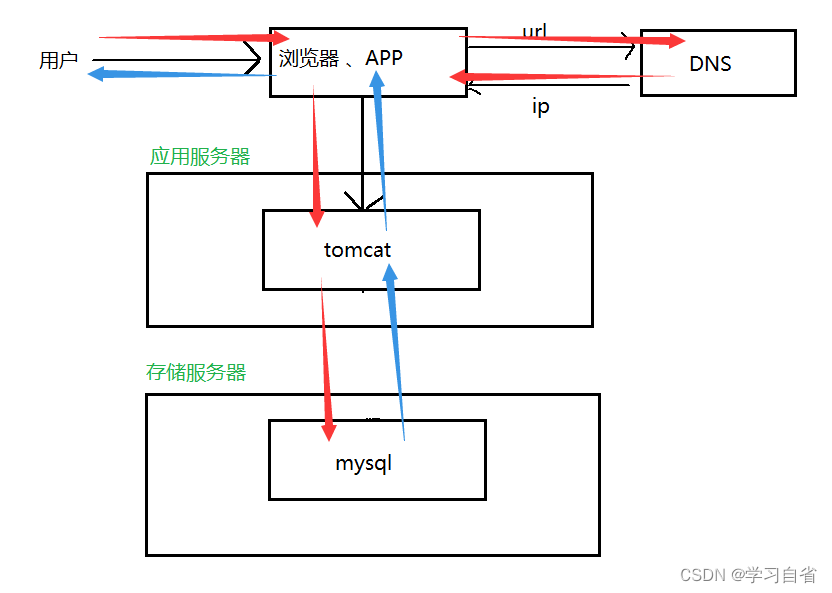
红色箭头表示请求访问,蓝色箭头表示响应
优点:成本相对可控、性能相比单机有提升、数据库单独隔离、不会因为应用把数据库搞坏,不至于数据库瘫痪
缺点:硬件成本变高、性能有瓶颈,无法对应海量并发(当前数据库仍然是要接收所有请求处理处理)
3、应用服务集群架构
特征:引入负载均衡,应用以集群方式运作
出现场景:单个应用不足以支持海量的并发请求,高并发的时候站点响应变慢
注:能接收请求量多到数千,多个应用服务器集群同时处理大量请求量(此处tomcat就是横向扩展)
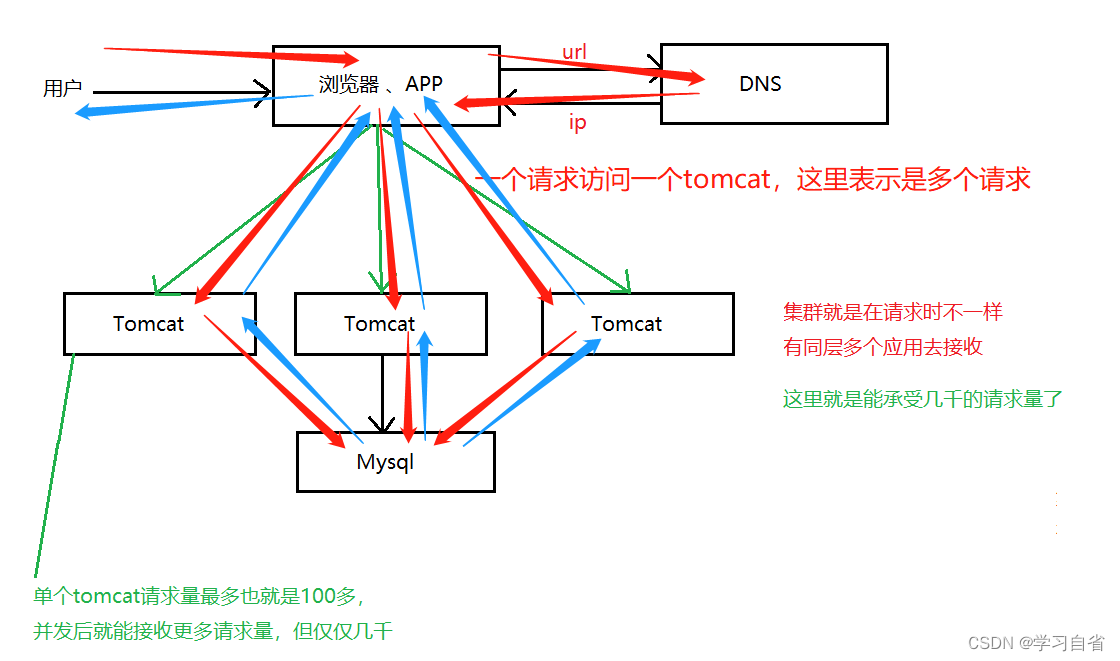
注:如果请求量更大呢,其实也同样可以按照上面的方法,交给一个更大应用服务接收请求,不够再进行横向扩展(第一先交给上层管理,第二同层进行横向扩展)
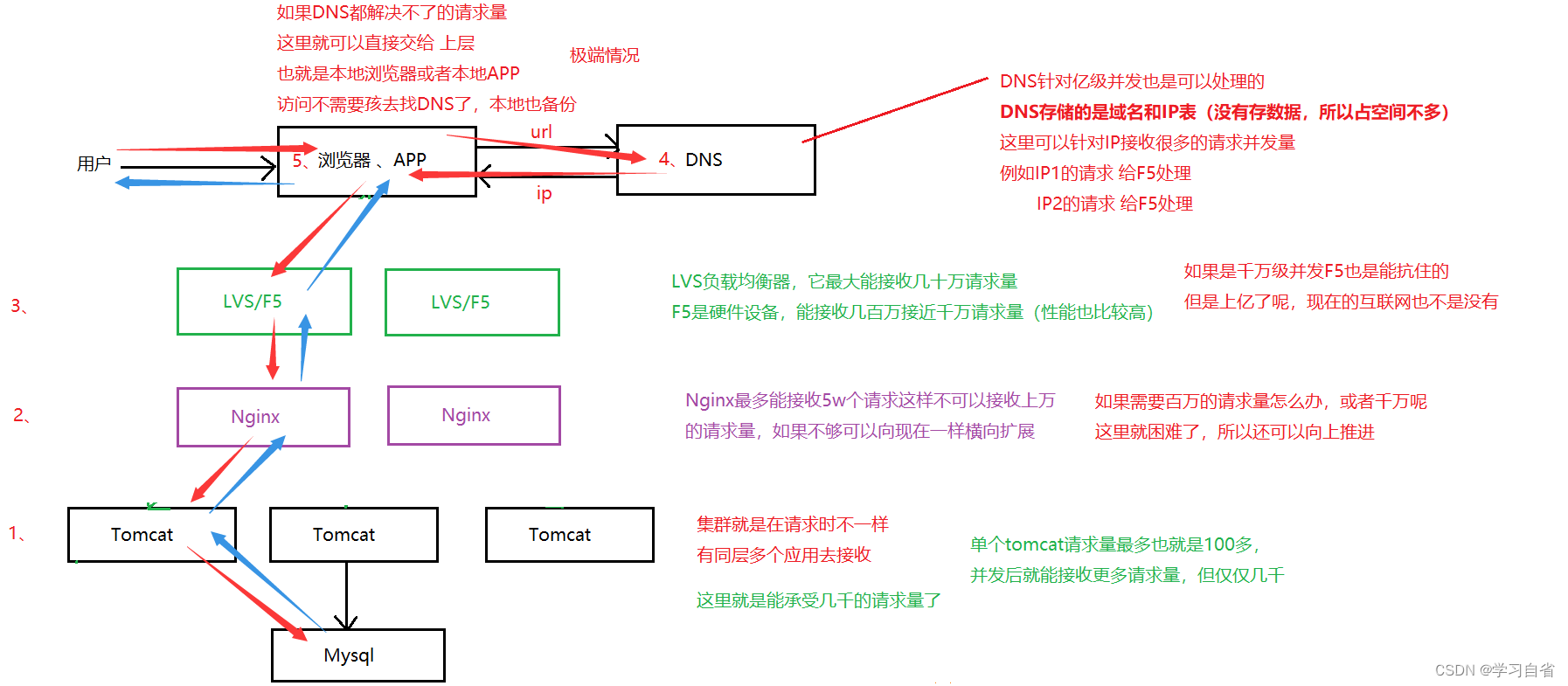
红色箭头表示请求访问,蓝色箭头表示响应
注:根据需求而定不是说这样的架构一定好,能承载越多并发量就越适合当前,根据情况而定;对于图解有个解释,上面画的只是一个大概的图,实际上有了上层之后,下层就需要更多来接收,毕竟上层是负载均衡器,还是要给下层分配的
优点:
针对应用服务器
(1)高可用:应用满足高可用,不会一个服务出问题整个站点挂掉
(2)高性能:如果不是访问数据库,应用相关处理海量请求快速响应
(3)扩展能力:支持横向扩展
缺点:
针对数据库
(1)性能瓶颈:无法应对数据库的海量查询
(2)可用性:数据库是点单的,所以一旦崩溃就是整个系统挂掉
(3)运维成本高:扩展部署运维工作增加
(4)硬件成本高:说的就是F5这个硬件
4、读写分离/主从分离架构
特征:将数据库集群化,但是为了保证所取数据都是相同的,就让一个数据哭来下,剩下的小弟们跟随大哥进行同步;数据库服务器搭建主从集群,一主一从、也可以一主多从都可以,,数据哭主机负责写操作,从机只负责读操作
出现场景:数据库到达瓶颈,而互联网应用一般读多写少,数据库承载压力主要来源于读的请求你造成的,那么针对这样的情况把读操作和写操作分开
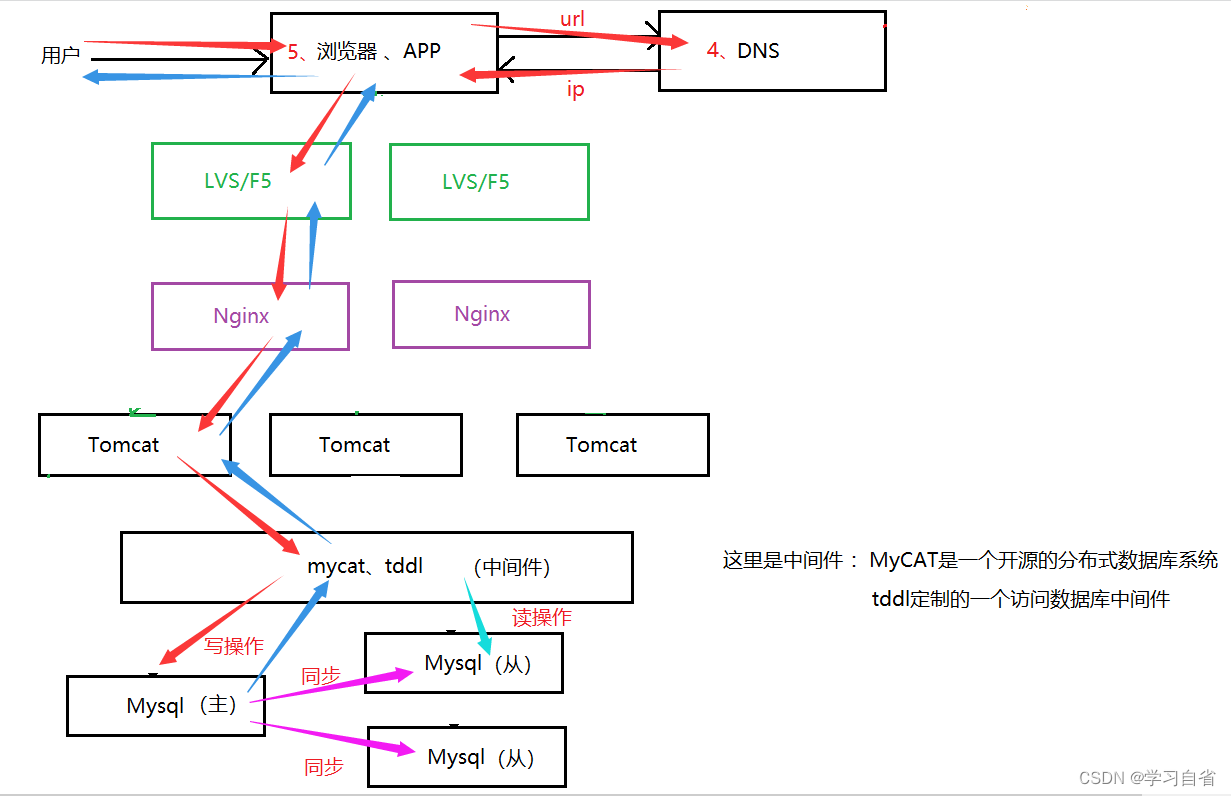
注:红色箭头表示请求是写操作;浅蓝色箭头表示读操作;紫色箭头表示写操作进行同步,同步给从库;蓝色箭头表示响应
优点:
针对请求访问
(1)读取性能提升
(2)读取操作为主数据库减轻了大部分请求的压力,写操作性能也得以提升
(3)可用性:一个数据库的坍塌不会给系统带来致命的伤害,提高了可用性
缺点:
针对热点数据
(1)读库虽然分担了很多请求量,但是它也会负载,热点数据的疯狂访问
(2)同步从库挂掉,或者延时,导致主库和从库数据有一定可能不一致
(3)服务器成本需要增加(添东西了,能不增加)
5、冷热分离架构
这里针对冷热数据进行解析:针对所谓数据都有常用数据,不常用数据,也就衍生出了“二八原则”,20%的热点数据,能满足80%的访问需求(不是说一定就是20%,按照业务需求来定夺分配,“一九”也不是没有)
特征:引入缓存,实行冷热分离,将热点数据放到缓存中快速响应
出现场景:海量的请求导致数据库负载过高,站点响应在度变慢,说明数据库已经开始吃力了;不足以提供较高的舒适度
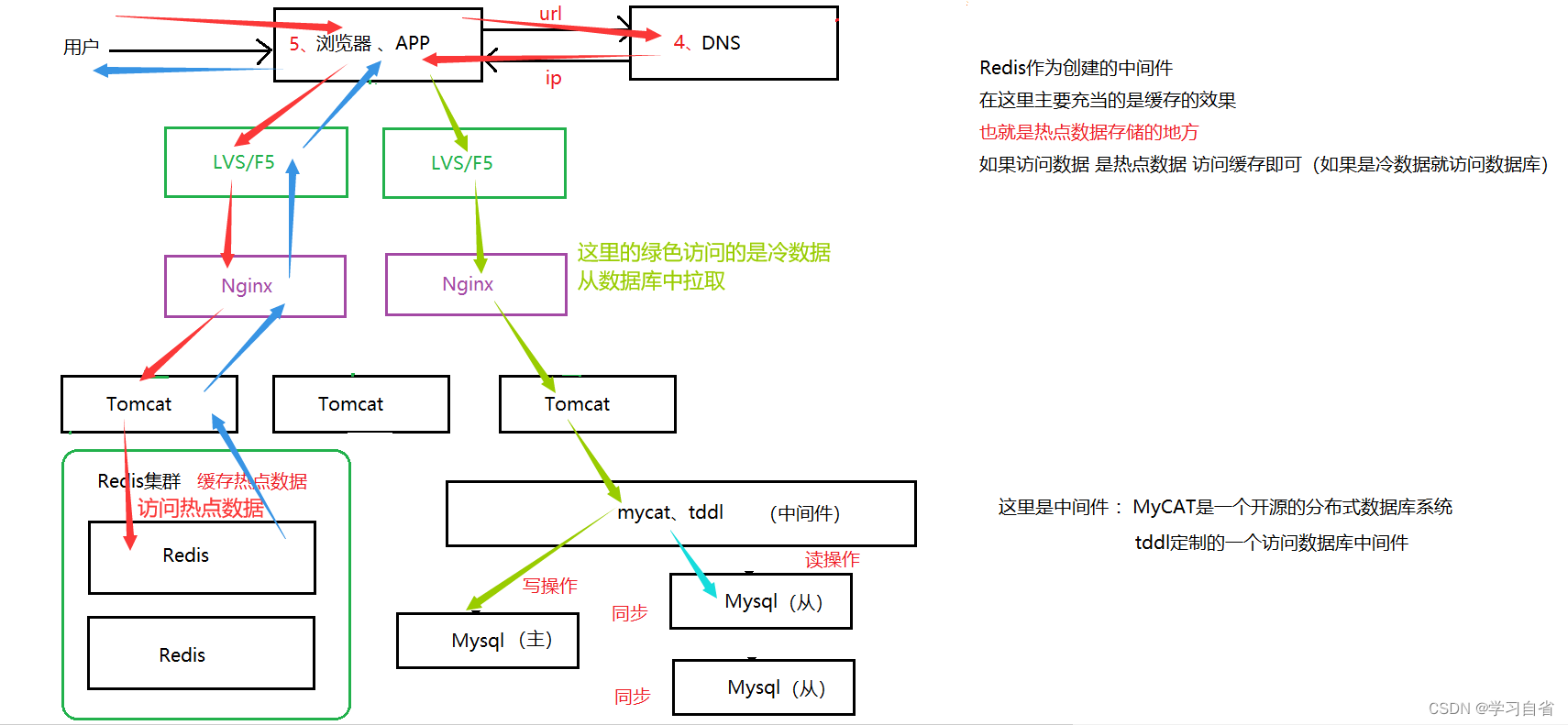
优点:大幅度降低数据库的访问请求,性能提升非常明显(访问缓存相比访问数据库快)
缺点:
(1)涉及到缓存就会设想到缓存到来的相关问题,缓存击穿、缓存失败、缓存雪崩等问题
(2)服务器成本的提高
(3)业务量支持变大,数据库单库太大,单表个体太大还是会导致数据库查询很慢,导致数据库再度到达瓶颈期
6、垂直分库架构
特征:数据库的数据被拆分,数据库数据分布式存储,分布式处理,分布式查询,也可以理解为分布式数据库架构
出现场景:写操作比较多,单机库性能已经支持不了了,需要拆分数据库,数据表的数据量太多,操作压力大,需要进行分表,降低运维难度,就有了分布式数据库,库表本来也就支持分布式
分库分表:

垂直分库:是指按照业务功能模块进行分库,将不同的业务模块分别放在不同的物理数据库中,这样可以提高系统的性能和扩展性
水平分库:是指按照用户属性(地市或者ID的hash)进行分库,将全省划分为个大区,每个大区有一个物理数据库,这样可以提高系统的扩展性和性能
注:这里就不在往整个架构图中带入了,这里直接将常见到的应用带入到架构中,这些中间件都是可以支持分库操作,内部实现思想也基本如上
分布式数据库:
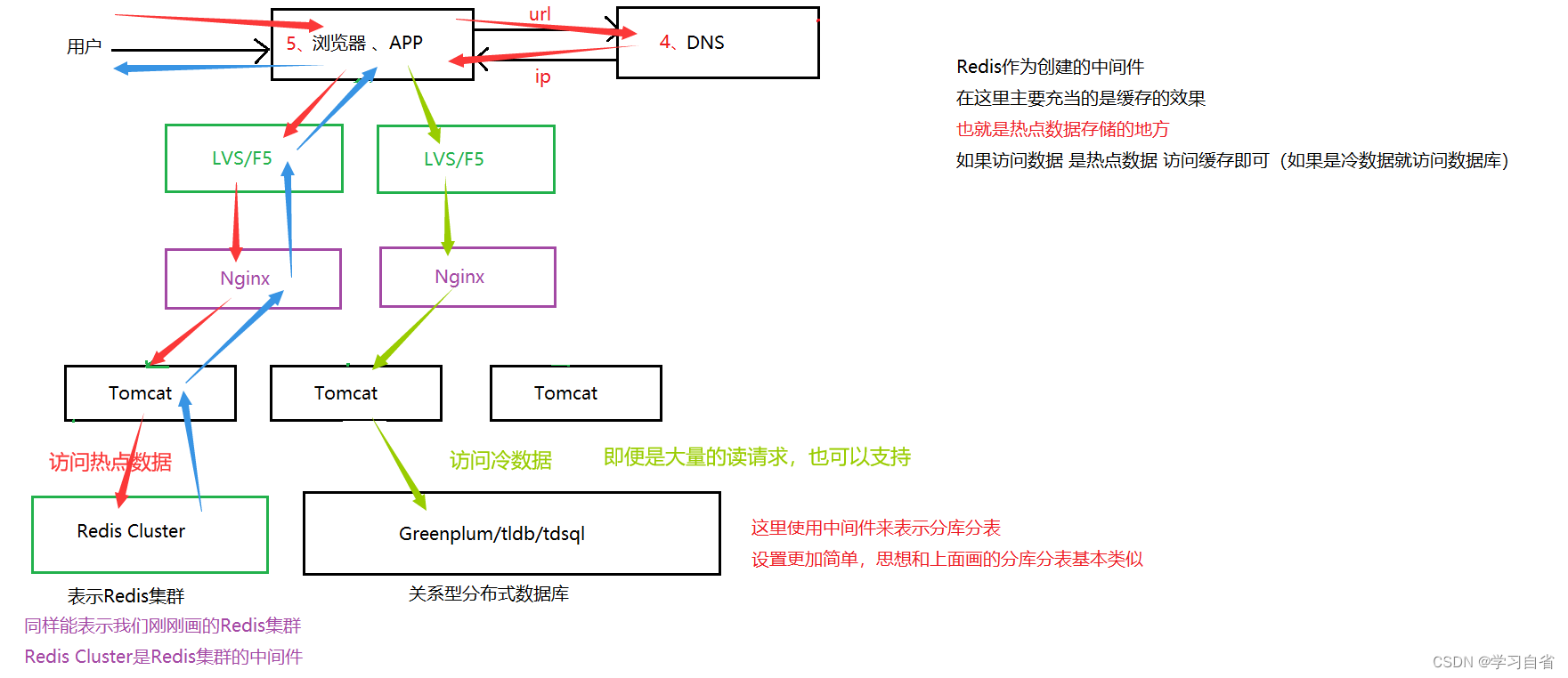
优点:数据库吞吐量大幅度提升,不再是瓶颈期
缺点:
(1)跨库join操作,分布式事务等问题,需要对应进行解决,目前的mpp都有解决对策
(2)数据库和缓存结合能够支持海量的请求,但是应用代码整体耦合,修改一行代码就需要连带修改很多,整体重新发布
7、微服务架构
特征:按照业务板块来分应用代码,是单个应用的职责更清晰,相互之间可以做到独立升级迭代
出现场景:场景不定全看自己对微服务的定位,这里针对几点进行评定
(1)扩展性差:应用程序不能轻松扩展,因为每次需要更新应用程序时,都必须重新构建整个系统
(2)持续开发困难一个很小的改动会惊动整个系统的代码连带改动,无法频繁并容易发布(这个是灵活性的体现)
(3)不可靠:一个功能不起作用了整个系统可能不能动
(4)代码维护比较吃力,都是在一起的,接手人需要了解整个系统才能每步修改
微服务体现:
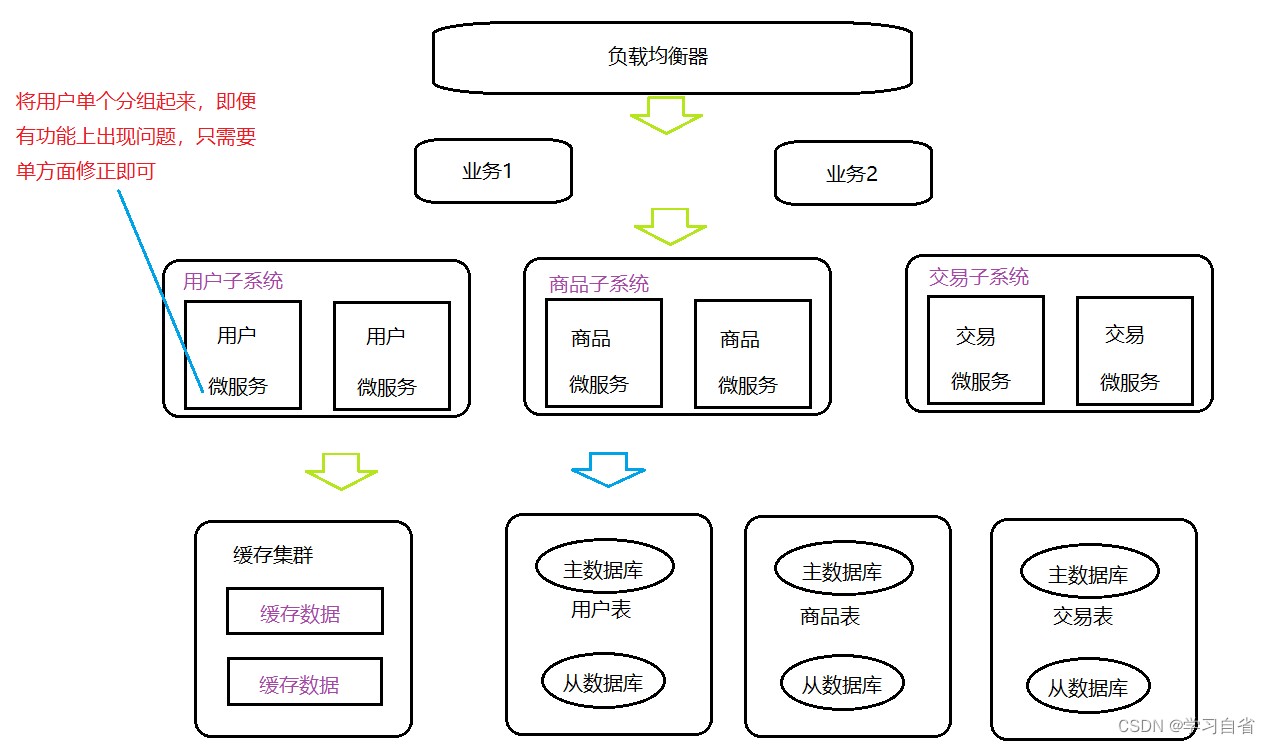
架构演示:
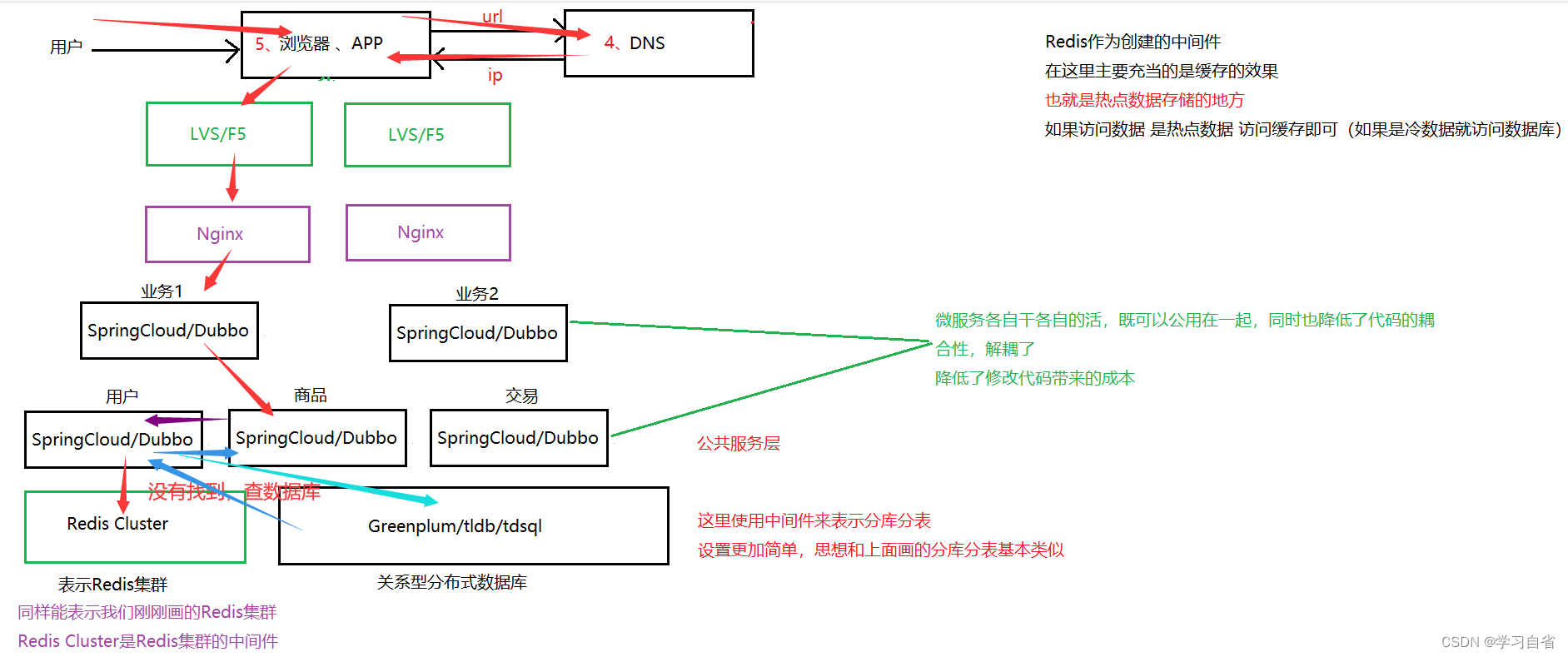
注:图并没有画完,这里解释当我们找商品的时候,是可以去访问用户,返回用户信息之后,在去找商品,商品查找操作是一样的,先找缓存,如果缓存没有在找数据库
优点:
(1)灵活性高:服务独立测试、部署、升级、发布
(2)独立扩展:微服务将功能独立起来,各自扩展互不干扰
(3)提高容错性:一个服务问题,不会两边挂
(4)支持编程语言多
缺点:
(1)运维复杂度高:应用和服务的部署变得复杂,同一台服务器上不是多个服务还要解决运行环境冲突的问题,如果需要动态扩缩场景,需要水平扩展服务的性能,就需要在新增服务上准备运行环境(2)资源使用变多:独立一个微服务是需要消耗CPU和内存的
(3)处理故障困难:需要查查看不同的日志完成问题定位,每个都是独立的,如果出问题需要慢慢排查
8、容器编排架构
特征:借助容器化技术(Docker)将应用/服务可以打包为镜像,通过容器编排工具(k8s)来动态分布和部署镜像,服务以容器化方式运行
出现场景:
(1)微服务拆分细致,服务多部署工作量大,配置复杂容易出错
(2)微服务数量多扩缩容麻烦,而且容易出错,每次缩容后再扩容又需要重新配置服务对应的环境参数
(3)微服务之间运行环境可能冲突,需要更多的资源来进行部署或者通过修改配置来解决冲突
容器化举例:
这里就我们比较熟悉的Java一套体系来说 java应用涉及:java、jdk、centos7 但是我们放到服务器上一次一次放太麻烦了,docker可以直接打包这个三个体系称为一个体系,直接部署到服务器上

容器化体现:
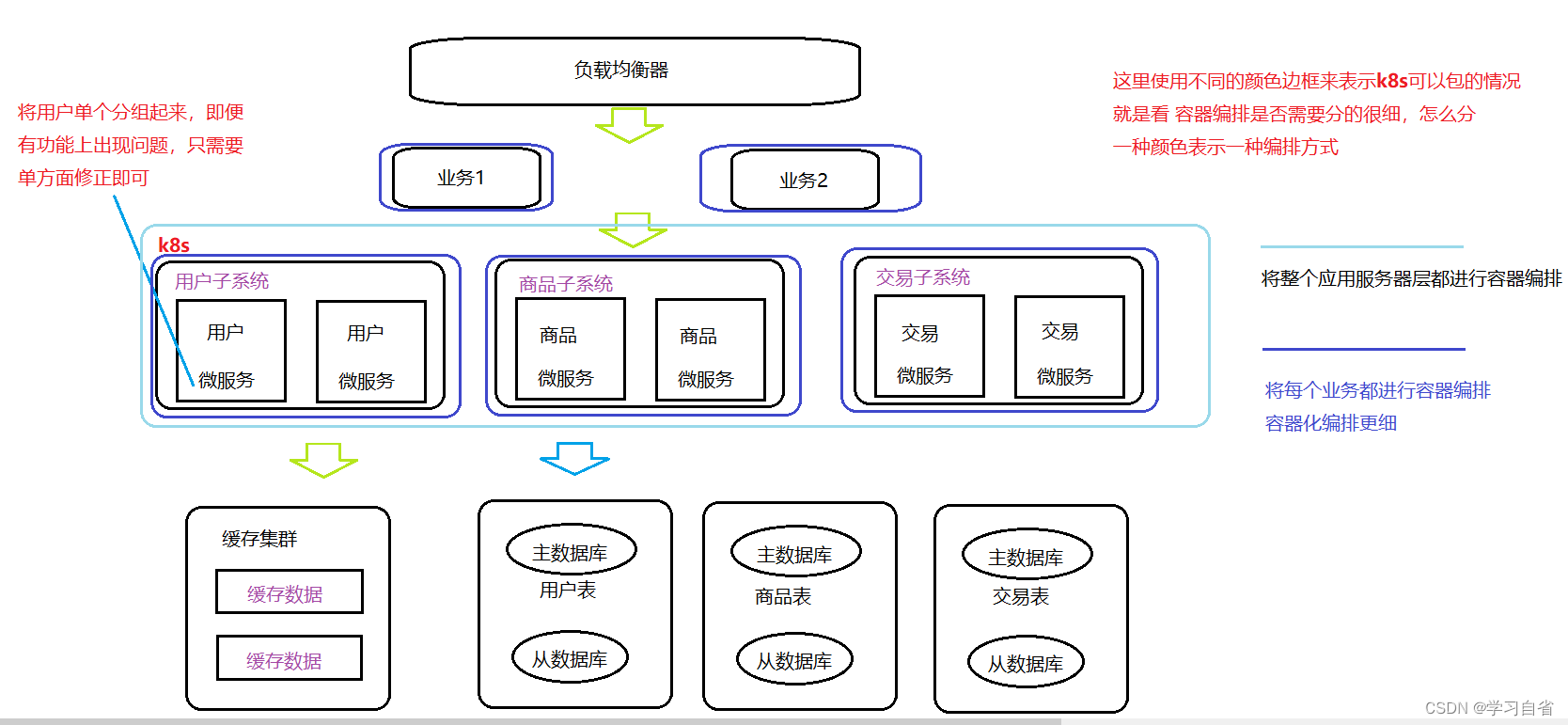
容器编排架构:
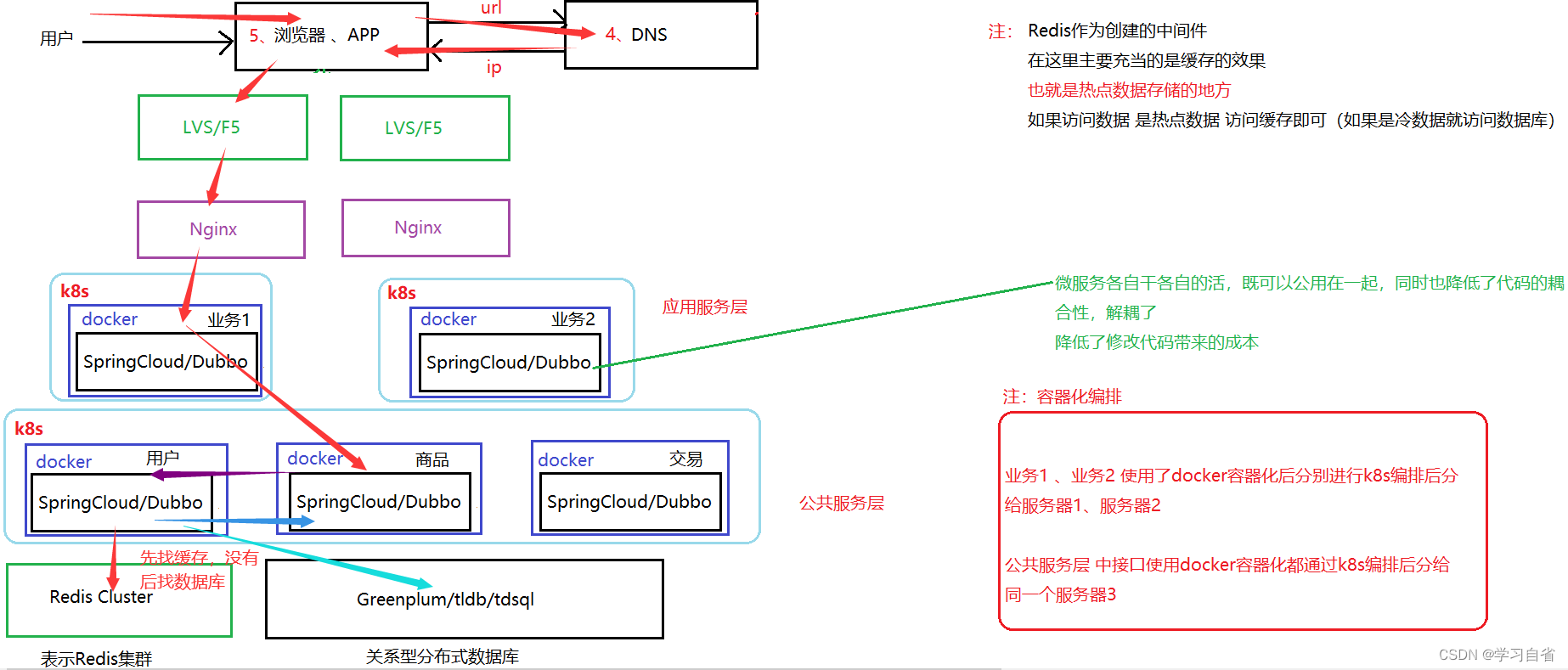
红色箭头表示请求,蓝色箭头表示响应,紫色箭头表示去拿用户信息,浅蓝色箭头表示缓存没有,访问数据库
注:这里的图没有画完,同样是访问商品时拿到用户数据信息,再次进行数据访问,先访问缓存,数据不存在访问数据库
优点:
(1)部署运维简单快速:一条命令就可以完成几百个服务的部署或者扩缩容
(2)隔离性好:容器与容器之间文件系统,网络相互隔离,不会产生环境冲突
(3)支持滚动更新:版本间奇幻都可以通过一个命令完成升级或者回滚
缺点:
(1)技术栈变多,技术要求严格
(2)运维成本极高,机器不是随时都会面临如此的资源消耗,一般只会维持一段时间,剩余时间还是闲置状态,此时资源利用率低,推荐云厂商服务器解决问题
9、小结

注:最后压力给到了应用,但是并没有结束,应用的改动会影响整个系统的代码耦合性太高,导致运维部署发布都需要很多次,任务量很大(图太长了,不太会截,这里分开截,内容是连续的)

下面就有了微服务,微服务并没有解决运维任务量大的问题,微服务只是将代码解耦,能让开发更加便捷,各司其职互不影响,运维的麻烦还是经过docker容器化打包成镜像交给k8s进行编排降低运维的任务量
![[国产MCU]-W801开发实例-GPIO输入与中断](https://img-blog.csdnimg.cn/11706f63104d4d5cbcd8ed76a4bf459a.png#pic_center)