前言
什么是幻读?幻读这个概念产生是因为事物隔离级别可重复读需要解决的一个问题。
可重复读,顾名思义,就是一个事物中多次读取的结果是一致的。
那其中就包含两个需要解决的问题:
-
虚读: 对同一行数据,每次读取的不一致。具体表现为T1读取某一数据后,当T2进行了修改,然后T1再次读该数据的时候与上一次读取不一致。
-
幻读: 事物在操作过程中,进行了两次查询,第二次查询的结果包含了第一次查询中未出现的数据或者缺少了第一次查询中的数据,因为可能在执行过程中,另一个事物进行插入造成的。
因为这两个问题,所以为不可重复读,那么解决这两个问题,就是可重复读了,下面只讨论可重复读的情况。
读有两种方式:
- 快照读
- 当前读
第一种关于快照读呢,是mvcc的东西,思想就是会生成一个快照,然后用户读取的时候就是读取快照的东西。
所以快照读是不会有幻读的情况,而在mysql官方文档中,当前读才是幻读的讨论范围。
什么是当前读呢?数据库里面有三条数据(1,2,3),然后事务A进行了全体查询(1,2,3),然后事务B进行修改了一条数据(1,2,4),这个时候事务A又进行一次全体查询,那么如果是快照读的话就应该是(1,2,3),
因为A读取的就是当前的快照,读取是A第一次查询语句的快照,因为B在A之后提交,所以读取的就是(1,2,3)。如果是当前读的话,那么就是(1,2,4),就是读取当前已经提交的。
那么为什么要当前读呢?有些人觉得快照读不挺好吗?为什么要去做当前读呢?
这个是应对更新并发问题的,比如说使用快照读,当我们要订单退款的时候,业务是这样的,先检查订单的状态为支付状态,然后就钱打给付款方,然后设置为退款。
假如并发场景,同时有两个退款业务对同一个订单进行退款的话,那么根据快照读,两个同时读取都是支付状态,然后执行了后面两遍操作,然而实际上我们是希望执行一遍的。
那么就需要当前读去锁住查询记录,然后进行后面的操作。
快照读的场景,一般就是一些查询,比如查看一些流水,银行交易记录查询,为了防止并发时数据不一致问题,可以使用快照读操作来确保查询时数据的一致性,
这里说明一下,一些初学者可能认为事务就是用来更新的,其实不是,事务就是要么全部成功,要么全部失败。
现在我们知道了当前读是为了所谓当前查询的数据,那么这个时候是无法删除和修改的。
但是另外一个问题出现了,那就是插入操作,比如第一次读取的时候是(1,2,3),然后第二次查询的时候是(1,2,3,4),因为行锁并不会去锁住新插入的行。
那么这个时候就不是可重复读了,两次读不一致,这也是为什么叫做幻读,就是第一次读取和第二次读取不一致,感觉产生了一种幻觉。
比如当查询的时候发现没有4,然后去插入的时候又报错。那么根据这种情况,就有了一种间隙锁,来解决幻读的问题。
下面来看看,可重复读下面的锁的情况,因为有间隙锁的存在,所以有时候我们可能遇到一些明明简单更新,怎么执行这么慢的问题,方便做优化。
正文
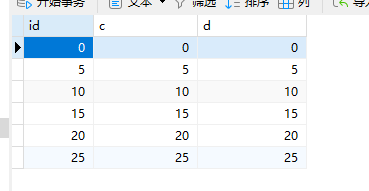
CREATE TABLE `t` (
`id` int(11) NOTNULL,
`c` int(11) DEFAULTNULL,
`d` int(11) DEFAULTNULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
那么就以下面得实验为例:
场景一:
sessionA:
BEGIN;
SELECT * FROM t WHERE d =5 FOR UPDATE;

sessionB:
update t set d =5 where id = 0;
此时sessionB能否正常更新?
是不能的。
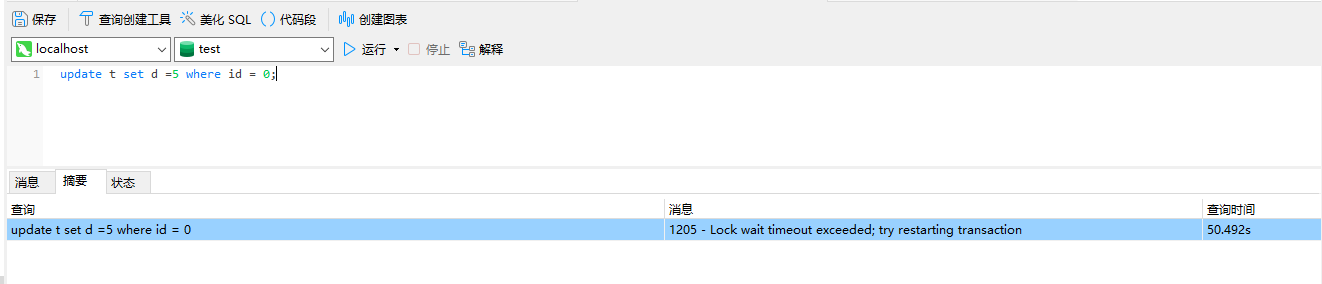
这个时候就是被锁住了。
那么可以看到SELECT * FROM t WHERE d =5 FOR UPDATE;不是锁住了某一行,而且d=5的全部插入和更新都是不行的。
那么假如没有间隙锁会发生什么?也就是快照读的情况下,也就是session B也的确更新了,也就是我们再读已提交的前提下运行会是什么呢?
那么如果SessionA再执行SELECT * FROM t WHERE d =5 结果会是什么呢?
结果还是这个:

因为读已提交的话,那么SessionA开始事物的时候sessionB还没有提交,那么读取的就是sessionA那个时候的数据,这就是快照读。
那么来看一下SELECT * FROM t WHERE d =5 FOR UPDATE;的间隙锁的机制。
因为查询条件是d,那么间隙锁的因子自然也是d了。
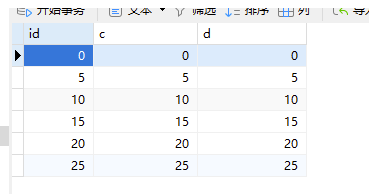
那么对于d来说有7个间隙。
分别是:

数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是
间隙锁跟我们之前碰到过的锁都不太一样。
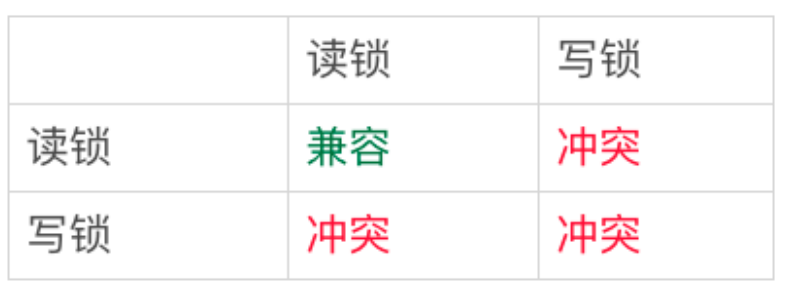
行锁的问题是: 如果我加了读锁,那么另外一个事务加了写锁,那么就冲突了。
但是间隙锁不一样,如果加了间隙锁,那么只有插入操作会影响。
比如sessionA 执行:
begin;
select * from t where c = 7 lock in share mode;
然后sessionB 执行:
begin;
select * from t where c = 7 for update;
这个时候sessionB 是不会被阻塞的。
因为c=7不存在,所以sessionA加的是间隙锁(5,10),然后同样sessionB 加的也是间隙锁,所以不会阻塞。
如果c=7存在的话,那么sessionB就会阻塞,因为行锁读和行锁写互斥就会等待。
这里一个点就出现了,比如select * from t where c = 7 lock in share mode;,间隙锁锁住的是(5,10),而不是这一行。
当运行我sessionA后,然后sessionC运行:INSERT t VALUES(8,8,8),发现是阻塞的:

间隙锁和行锁合称next-key lock,每个next-key lock是前开后闭区间。也就是说,我们的表t初始化以后,如果用select *fromt for update要把整个表所有记录锁起来,就形成了7个next-key
lock,分别是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。
你可能会问说,这个supremum从哪儿来的呢?
这是因为+∞是开区间。实现上,InnoDB给每个索引加了一个不存在的最大值supremum,这样才符合我们前面说的“都是前开后闭区间”。
临时插一个东西,就是有人问啊,比如说:
你看啊, lock in share mode 这个呢,别人可以读但是不能写入,不是同样可以起到不让修改的作用,而且别人还能读嘛,为什么更新的时候要用for update呢?
就比如:
begin;
select * from t where c = 7 lock in share mode;
INSERT t VALUES(7,7,7);
COMMIT
这样不也是可以的嘛。
如果这样问,就是有点没有搞清楚间隙锁和读写锁的区别。
lock in share mode 和 for update都会出现间隙锁,可以解决不会插入的问题。
但是如果c=7真的存在,那么就是行锁存在了:
begin;
select * from t where c = 7 lock in share mode;
update t
set b=5 where c =7
COMMIT
如果这种情况,并发情况下就会出现死锁情况。
比如sessionA:
begin;
select * from t where c = 7 lock in share mode;
然后sessionB:
运行:
begin;
select * from t where c = 7 lock in share mode;
然后sessionA运行:
UPDATE t
SET d=10
where c = 7
就卡住了,并发的情况就会现在问题,所以在更新的时候就使用for update。
而不是说在更新的时候使用 lock in share mode可以让其他用户读取到,这样交叉锁,反而会造成死锁,造成更新错误。
然后再插入一点,那就是如果sessionA是:
begin;
select * from t where c = 7 FOR UPDATE
然后使用sessionB:
select * from t where c = 7
是不会被阻塞的,因为一个是当前读,一个是快照读,快照读不会去检查锁的概念,读取的是快照,知道这一点还是很有用的,其实数据库效率还是很高的,并不会说当更新的时候会不让快照读取的情况。
然后有人这样问了,那么读取不更新(更新一般读是当前读,作为判断条件)的时候快照读不就好了啊,为什么要当前读呢?有些场景即使是查询还是要当前读的:
即使快照读和当前读的时间差很短,有些场景仍然需要确保读取到最新的数据:
- 在需要实时数据的场景下,即使短暂的时间差也可能导致信息不准确。
- 对于需要及时反馈或实时决策的系统,即使短暂延迟也可能影响结果。
- 在高并发环境下,即使短暂的时间差也可能导致数据不一致或冲突。因此,即使时间差很短,某些情况下仍需要使用当前读来确保读取到最新的数据。
主要是一些高并发场景下,更新的时候不让用户看到信息,确保读取的是最新的数据。
当然还有一些业务场景,比如说查询某些数据,然后通过这些数据统计更新另外一个数据,如果是并发场景的话,那么可能更新不是最新的,因为可能后面的事务读取的可能是更靠前的数据,
这是很有可能的(比如事务B比事务A提前发起,但是事务B先完成)。
回到间隙锁的问题上来:

在高并发的场景下,如果插入一条存在的行,那么很可能会死锁,那么这个问题怎么解决呢?
业务场景描述是:查询一个值,如果不存在就插入,那么这个时候因为不存在就有间隙锁,高并发的场景下会出现死锁,这个问题何解?
这种情况呢?可以使用这个:ON DUPLICATE KEY UPDATE, 如果重复的时候就更新,这是一种解决方案,因为是原子性,就不会存在这种锁的问题。
把 on duplicate key update 例子说明一下把:
假设有一个名为users的表,其中有一个名为email的列,该列具有唯一性约束,用于存储用户的电子邮件地址。如果我们想要插入一条用户数据,如果该用户的电子邮件地址已经存在,我们希望更新该用户的其他信息,而不是插入一个新的记录。
示例SQL语句如下:
INSERT INTO users (id, name, email) VALUES (1, 'Alice', 'alice@example.com')
ON DUPLICATE KEY UPDATE name = 'Alice', email = 'alice@example.com';
在这个例子中,如果email列存在重复值(即已经存在alice@example.com的记录),则会更新该记录的name和email列的值。
当然有人提及到id不是主键也是唯一性吗,是的,上面只是用email作为回答,如果id相同的话,也会进行更新,而不是插入。
如果一张表有多个唯一性约束,当使用ON DUPLICATE KEY UPDATE语句时,MySQL会根据多个唯一性约束中的任何一个冲突来判断是否执行更新操作。如果任何一个唯一性约束被违反,就会触发更新操作。MySQL不会根据多个唯一性约束的组合来判断是否执行更新操作,而是根据单个唯一性约束的冲突情况来确定是否执行更新操作。
如果两列组合在一起形成唯一性约束,那么在使用ON DUPLICATE KEY UPDATE时,如果这两列的组合值已经存在,就会触发更新操作。这意味着当这两列的组合值冲突时,ON DUPLICATE KEY UPDATE仍然是有用的,可以用来更新已存在记录的其他列值。
那么加锁的原则是什么呢?
- 原则1:加锁的基本单位是next-key lock。
- 原则2:查找过程中访问到的对象才会加锁。
- 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。
- 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key
lock退化为间隙锁。 - 一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
数据还是:
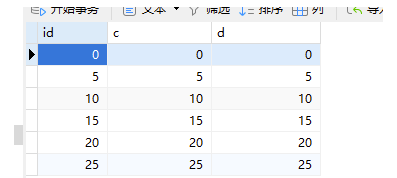
案例一:
sessionA:
begin;
update t set = d=d+1 where id=7
这个时候因为id=7不存在,加的是间隙锁,(5,10);
案例二:
sessionA:
begin;
select id from t where c=5 lock in share mode;
这个时候锁的范围是什么呢? next-key lock 是(0,5]吗?
(0,5]表示,(0,5)间隙锁加上c=5这个行锁。
要注意c是普通索引,因此仅访问c=5这一条记录是不能马上停下来的,需要向右遍历,查到
c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock。
但是同时这个符合优化2:等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此
退化成间隙锁(5,10)。
也就是一个next-key lock (0,5], 然后一个间隙锁(5,10)。
我们知道c=5,这条数据是(5,5,5),那么这个时候是否能执行:
UPDATE t
set d =7
where id=5
答案是可以,那么不是说,(5,5,5)已经锁住了吗?怎么还能更新?
根据原则2 ,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索
引,所以主键索引上没有加任何锁。
也就是说,select id from t where c=5 lock in share mode; 给的是索引c上,c=5这一行加的一个索引,而不是在主键索引上加的锁。
如果是c没有索引的话,那么就会锁住主键索引,把索引c删了试一下, 这个时候就被阻塞了:

上面就不等50秒了。
所以在我们看来,索引其实就是另外一张表,因为主键索引,其实也就是叶子节点是真实数据。
这个例子说明,锁是加在索引上的;同时,它给我们的指导是,如果你要用lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。
如果你想给索引主键加锁的话,那么就需要select d fromt where c=5 lock in share mode,加入索引不存在的字段即可,这样会回表,现在可以把索引c加上(ALTER TABLE t add INDEX(c)),再试一次,这里就不展示了。
案例三:
select * from t where id>=10 and id<11 for update;
这个的加锁范围是什么?
首先id>=10,这个时候id=10是存在的,所以范围是lock-key 是(5,10],但是因为id是唯一索引,所以根据优化一,退化成行锁。
然后id>10 和id<11,那么这个时候继续向右前进,那么就是(10,15],也就是15会加上行锁,试一下。
UPDATE t
SET d=20
WHERE id=15
然后发现锁住了。

案例四:
非唯一索引的范围查询那么是怎么样的呢?
select * from t where c>=10 and c<11 for update;
因为c是非唯一索引,找到c=10,这个时候不满足优化二,lock-key 为(0,10],然后继续向右是(10,15]。
案例五:
begin;
select * from t where id>10 and id<=15 for update;
那么这个时候的锁是什么样的呢,id>10 遍历到15,那么这个时候的next-key 是1(0,15],这个时候也满足id<=15;
那么是不是这个时候加锁就结束了呢? 这个时候要遍历到不符合的为止,(15,20] 依然需要加锁。
案例六:非唯一索引上存在 案 "等值等 "的例子
insert into t values(30,10,30);
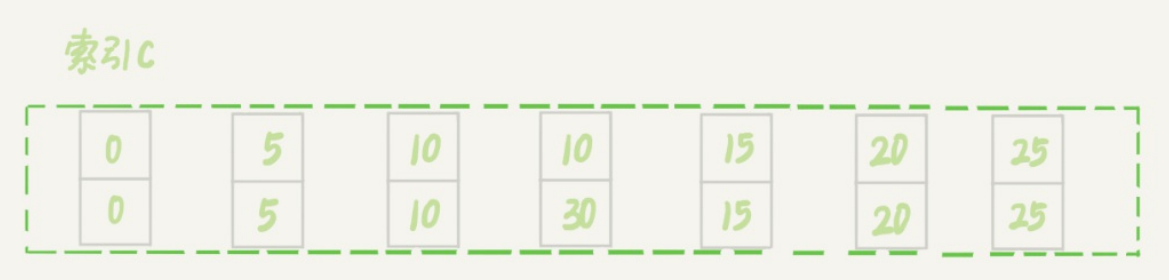
这时,session A在遍历的时候,先访问第一个c=10的记录。同样地,根据原则1,这里加的是
(c=5,id=5)到(c=10,id=10)这个next-key lock。
然后,session A向右查找,直到碰到(c=15,id=15)这一行,循环才结束。根据优化2,这是一个
等值查询,向右查找到了不满足条件的行,所以会退化成(c=10,id=10) 到 (c=15,id=15)的间隙
锁;
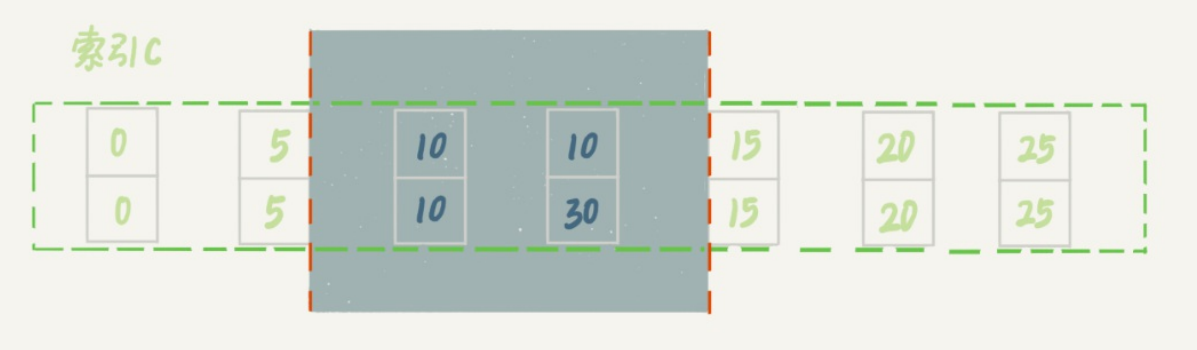
这个蓝色区域左右两边都是虚线,表示开区间,即(c=5,id=5)和(c=15,id=15)这两行上都没有锁。
案例7 limit语句加锁:
sessionA:
begin;
delect from t where c=10 limit 2;
这个例子里,session A的delete语句加了 limit 2。你知道表t里c=10的记录其实只有两条,因此
加不加limit 2,删除的效果都是一样的,但是加锁的效果却不同。可以看到,session B的insert
语句执行通过了,跟案例六的结果不同。
这是因为,案例七里的delete语句明确加了limit 2的限制,因此在遍历到(c=10, id=30)这一行之
后,满足条件的语句已经有两条,循环就结束了。
因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所
示:
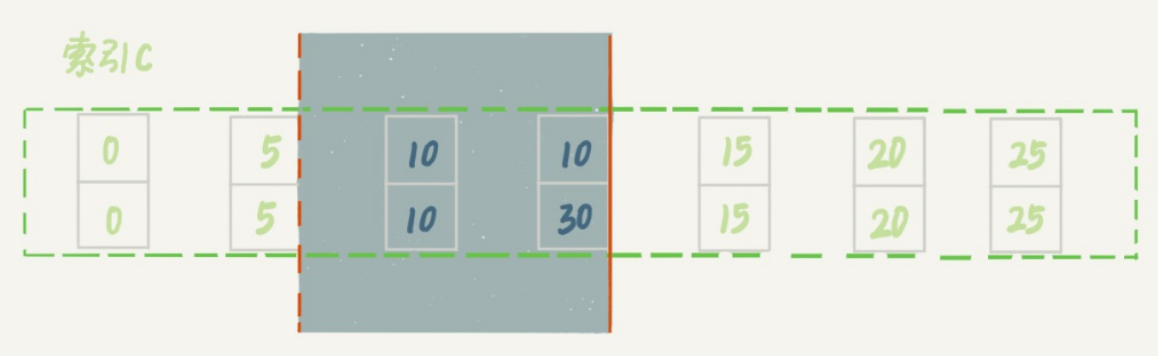
案例八:一个死锁的例子

- session A 启动事务后执行查询语句加lock in share mode,在索引c上加了next-key
lock(5,10] 和间隙锁(10,15); - session B 的update语句也要在索引c上加next-key lock(5,10] ,进入锁等待;
- 然后session A要再插入(8,8,8)这一行,被session B的间隙锁锁住。由于出现了死
锁,InnoDB让session B回滚。
你可能会问,session B的next-key lock不是还没申请成功吗?
其实是这样的,session B的“加next-key lock(5,10] ”操作,实际上分成了两步,先是加(5,10)的间
隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的。
也就是说,我们在分析加锁规则的时候可以用next-key lock来分析。但是要知道,具体执行的时
候,是要分成间隙锁和行锁两段来执行的
结
后续继续补充