多年前搞大数据,因为单节点无力存储和计算PB级别的数据,所以hadoop这种分布式存储和计算框架是标配!如今搞大模型,仍然需要对大量样本数据做计算,因为涉及矩阵运算,单机单卡运算效率太低,也涉及到分布式计算了,大模型时代的分布式pre-train和Inference框架就有现成的—deepspeed!
1、老规矩,先直观体验一下deepspeed的使用:
(1)自己定义一个简单的模型:model.py
import torch import numpy as npclass FashionModel(torch.nn.Module): def __init__(self):super().__init__()self.seq = torch.nn.Sequential(torch.nn.Linear(in_features=784, out_features=300),torch.nn.ReLU(),torch.nn.Linear(in_features=300, out_features=10))def forward(self, batch_x):return self.seq(batch_x)def img_transform(img): img = np.asarray(img) / 255return torch.tensor(img, dtype=torch.float32).flatten()
(2)训练的核心代码train.py:
import argparse import torch import torchvision import deepspeed from model import FashionModel, img_transform# 命令行参数:deepspeed ds_train.py --epoch 5 --deepspeed --deepspeed_config ds_config.json parser = argparse.ArgumentParser() parser.add_argument("--local_rank", type=int, default=1, help="local rank passed from distributed launcher") parser.add_argument("--epoch", type=int, default=1, help="epoch") parser = deepspeed.add_config_arguments(parser) cmd_args = parser.parse_args() # deepspeed命令行参数 dataset = torchvision.datasets.FashionMNIST(root='./dataset', download=True, transform=img_transform) # 数据集 dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, num_workers=4, shuffle=True) # 数据加载器,batch_size应该等于train_batch_size/gpu数量 model = FashionModel() # 自定义的模型 model, _, _, _ = deepspeed.initialize(args=cmd_args, model=model, model_parameters=model.parameters()) # deepspeed分布式模型 loss_fn = torch.nn.CrossEntropyLoss()for epoch in range(cmd_args.epoch):for x, y in dataloader:x = x.cuda()y = y.cuda()output = model(x)loss = loss_fn(output, y)model.backward(loss) # 走deepspeed风格的backward model.step()print("epoch {} done...".format(epoch))model.save_checkpoint('./checkpoints')
配置文件ds_config.json
{"train_batch_size": 128,"gradient_accumulation_steps": 1,"optimizer": {"type": "Adam","params": {"lr": 0.00015}},"zero_optimization": {"stage": 2} }
deepseed安装好后,直接一行命令就开始运行:deepspeed ds_train.py --epoch 2 --deepspeed --deepspeed_config ds_config.json ;从日志可以看出:有几块显卡就会生成几个进程并发训练;显卡之间使用nccl互相通信;
主进程rank 0 打印日志:
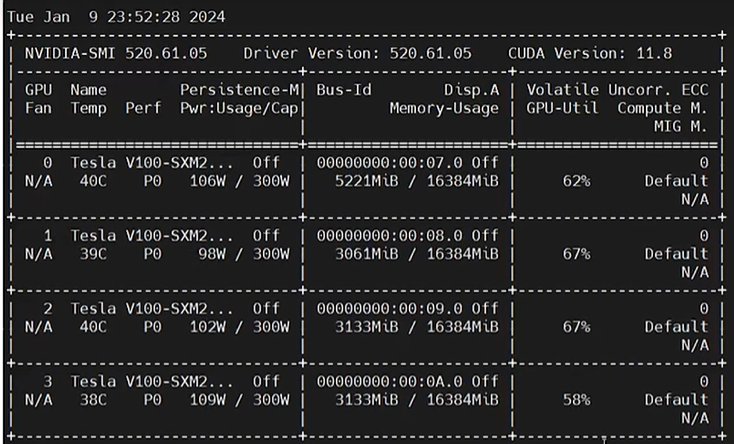
显存都用上了:
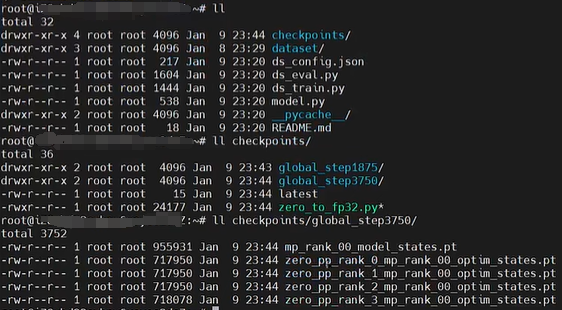
训练完毕生成的模型:
pre-train完成后的总要对LLM评估吧,代码ds_eval.py:
import argparse from model import FashionModel, img_transform import deepspeed import torchvision import torch### deepspeed ds_eval.py --deepspeed --deepspeed_config ds_config.json parser = argparse.ArgumentParser() parser.add_argument('--local_rank', type=int, default=-1, help='local rank passed from distributed launcher') parser = deepspeed.add_config_arguments(parser) cmd_args = parser.parse_args() # deepspeed命令行参数 model = FashionModel().cuda() # 原始模型 model, optimizer, _, _ = deepspeed.initialize(args=cmd_args, model=model, model_parameters=model.parameters()) # deepspeed分布式棋型 model.load_checkpoint('./checkpoints') # 加载参数 model.eval() # 分布式推理模式# 只有主控进程带头做这些动作 if torch.distributed.get_rank() == 0:dataset = torchvision.datasets.FashionMNIST(root='./dataset', download=True, transform=img_transform) # 训练数据集batch_X = torch.stack([dataset[0][0], dataset[1][0]]).cuda()outputs = model(batch_X) # 分布式推理print('分布式推理:', outputs.cpu().argmax(dim=1), [dataset[0][1], dataset[1][1]])### 模型转成torch单体 torch.save(model.module.state_dict(), 'model.pt') # 保存为普通torch模型参数 model = FashionModel().cuda() # 加载torch模型 model.load_state_dict(torch.load('model.pt')) model.eval() # 单体推理 outputs = model(batch_X) print('单体推理:', outputs.cpu().argmax(dim=1), [dataset[0][1], dataset[1][1]])
评估代码也简单,也是直接一行命令:deepspeed ds_eval.py --deepspeed --deepspeed_config ds_config.json
import argparse from model import FashionModel, img_transform import deepspeed import torchvision import torch### deepspeed ds_eval.py --deepspeed --deepspeed_config ds_config.json parser = argparse.ArgumentParser() parser.add_argument('--local_rank', type=int, default=-1, help='local rank passed from distributed launcher') parser = deepspeed.add_config_arguments(parser) cmd_args = parser.parse_args() # deepspeed命令行参数 model = FashionModel().cuda() # 原始模型 model, optimizer, _, _ = deepspeed.initialize(args=cmd_args, model=model, model_parameters=model.parameters()) # deepspeed分布式棋型 model.load_checkpoint('./checkpoints') # 加载参数 model.eval() # 分布式推理模式# 只有主控进程带头做这些动作 if torch.distributed.get_rank() == 0:dataset = torchvision.datasets.FashionMNIST(root='./dataset', download=True, transform=img_transform) # 评估数据集batch_X = torch.stack([dataset[0][0], dataset[1][0]]).cuda()outputs = model(batch_X) # 分布式推理print('分布式推理:', outputs.cpu().argmax(dim=1), [dataset[0][1], dataset[1][1]])### 模型转成torch单体 torch.save(model.module.state_dict(), 'model.pt') # 保存为普通torch模型参数 model = FashionModel().cuda() # 加载torch模型 model.load_state_dict(torch.load('model.pt')) model.eval() # 单体推理 outputs = model(batch_X) print('单体推理:', outputs.cpu().argmax(dim=1), [dataset[0][1], dataset[1][1]])
运行效果如下:

直观感受完了deepspeed的使用,感觉比较简单,底层分布式的训练方案已经由框架都封装好了,开发人员直接调用即可! 接下来最重要的就是了解分布式训练方案的原理了!
2、做分布式训练,要么是单节点显存不够,要么是算力不够。算力主要是各种矩阵运算啦,GPU硬件本身就是为这种计算定制的,软件层面无法明显优化,所以分布式系统主要优化的就是显存的占用啦!
(1)先看看单机单卡训练时的显存占用,假设模型的参数量是m:
- 参数本身存储需要显存,用FP32和FP16混合精度存放,需要6m显存
- 梯度保存:用FP16存放,需要2m显存
- optimizer优化器:以adam为例,梯度下降的时候要存梯度和梯度平方,每个参数要存2个状态,需要8m显存

在不考虑存放训练数据的前提下,pre-train至少需要6m+2m+8m=16m的显存,所以后续的重点就是怎么优化这三部分显存占用啦!
(2)先来看看最简单的一种情况:data parallel,简称DP。假设有N个显卡:
- 就是把训练数据均分成N份,然后N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- 产生的gradient都发送给某个特定的显卡(这里用0号显卡表示)
- 0号显卡根据gradient更新自己网络的参数,然后把新的参数广播发送给其他所有显卡,让所有显卡的网络参数保持一致
- 除了0号显卡,其他显卡的作用就是计算loss和梯度
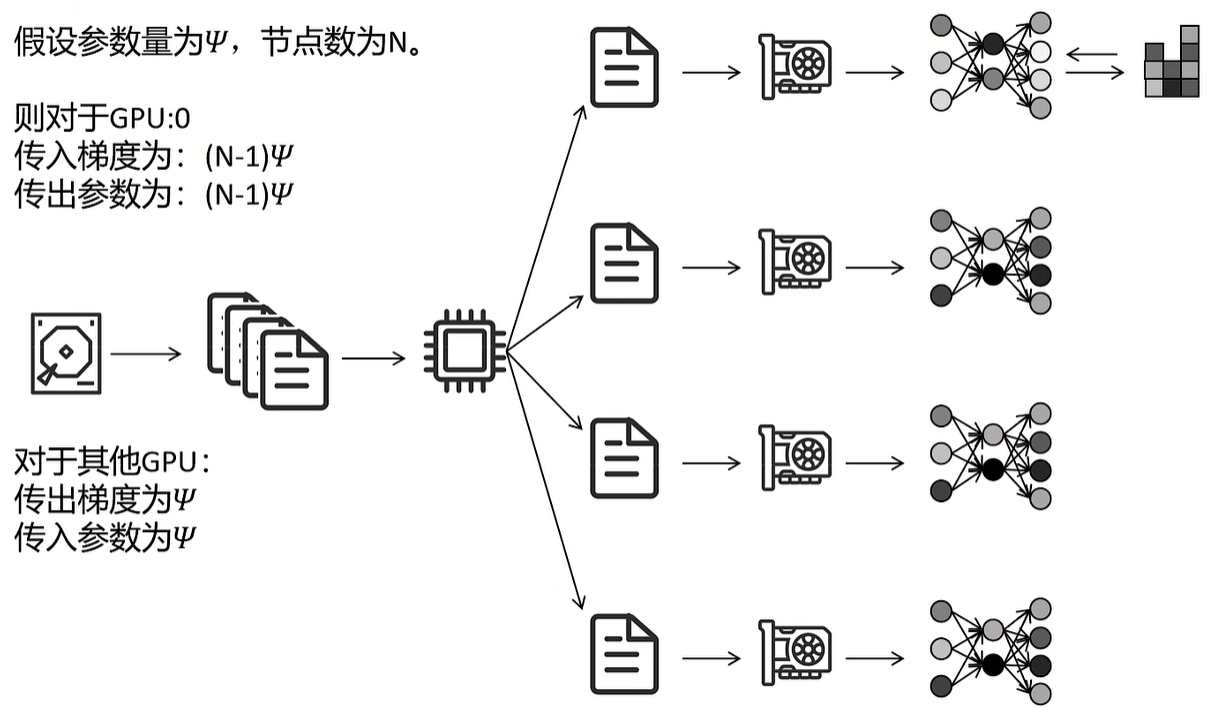
这种DP方式的缺陷很明显:0号显卡要收集其他所有显卡梯度,更新参数后要把新的参数广播给所有显卡,显卡之间的通信量很大,具体同步的数据量和显卡数据是线性正比的关系!
(3)DP的改进版:distributed data parallel,简称DDP;和DP比,每块卡单独生成一个进程;
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- 因为每张卡的数据不同,所以loss和梯度肯定不同,此时通过Ring-allReduce同步梯度,让每张卡的梯度保持一致
- 每张卡根据梯度更新自己的网络参数;因为每张卡的loss和梯度是要通过Ring-allReduce互相同步的,并且网络的初始状态也是一样的,所以每张卡的optomizer和网络状态始终是一样的!
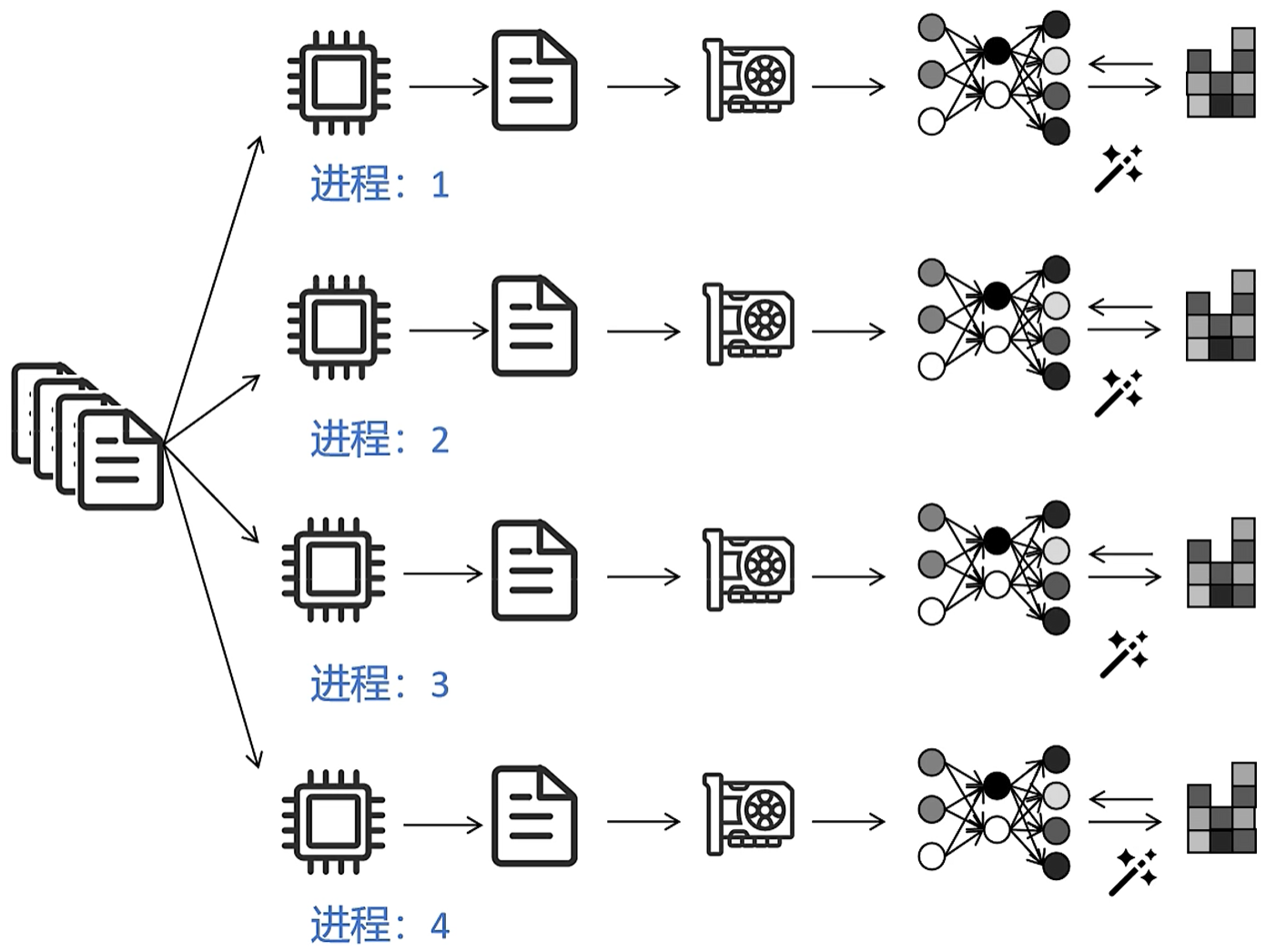
显卡集群总的数据传送量:因为使用了Ring-allReduce传输数据(每个结点只给下一个结点传输数据,并不是整个集群广播),所以总的传入传出总量是固定的,不会因为显卡集群扩大导致数据传输大增!

3、上述的DP和DDP,通过分布式增加了算力,但缺陷还是很明显的:并未节约显存!所以由此产生了ZeRO技术!
(1)预训练时,optimizer占用8倍参数量的显存空间,是最耗费显存的,所以肯定先从这种“大户”下手啦!前面的DP和DDP,每块显卡都保存了完整的optimizer,互相都有冗余,能不能消除这个冗余了?比如集群有3块显卡,每块显卡只存1/3的optimizer状态?这就是ZeRO-1的思路!举个栗子:transformer不论decoer还是encoder,不是由一个个block上下叠加组成的么?比如有12个block、3块显卡,那么每块显卡存储4个block的optimizer,不就ok啦?
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- foward时所有显卡可以并行(因为都存储和FP16的网络参数),然后各自计算loss和梯度
- 最关键的就是BP了:现在每块显卡只存了部分optimizer,怎么做BP更新参数了?
- 因为每块显卡都有完整的FP16网络参数,所以每块显卡都可以并且需要根据loss计算梯度
- 最后4个block的optimizer是GPU2负责,所以GPU0和1并不更新这4个block的参数。但是更新参数涉及梯度啊,GPU2的loss和梯度信息不完整,这时就需要GPU0和1把自己计算的梯度信息发送给GPU2,整合后计算mean,用于更新最后4个block的参数!
- 同理,中间4个block的梯度由GPU0和2发送给CPU1,GPU1整合后计算mean,用于更新中间4个block的参数!最前面4个block的梯度由GPU1和1发给GPU0,GPU0整合后计算mean再更新网络参数!
- 3块显卡更新了各自负责block的网络参数,然后互相广播,至此:每块GPU的网络参数都是最新的了!
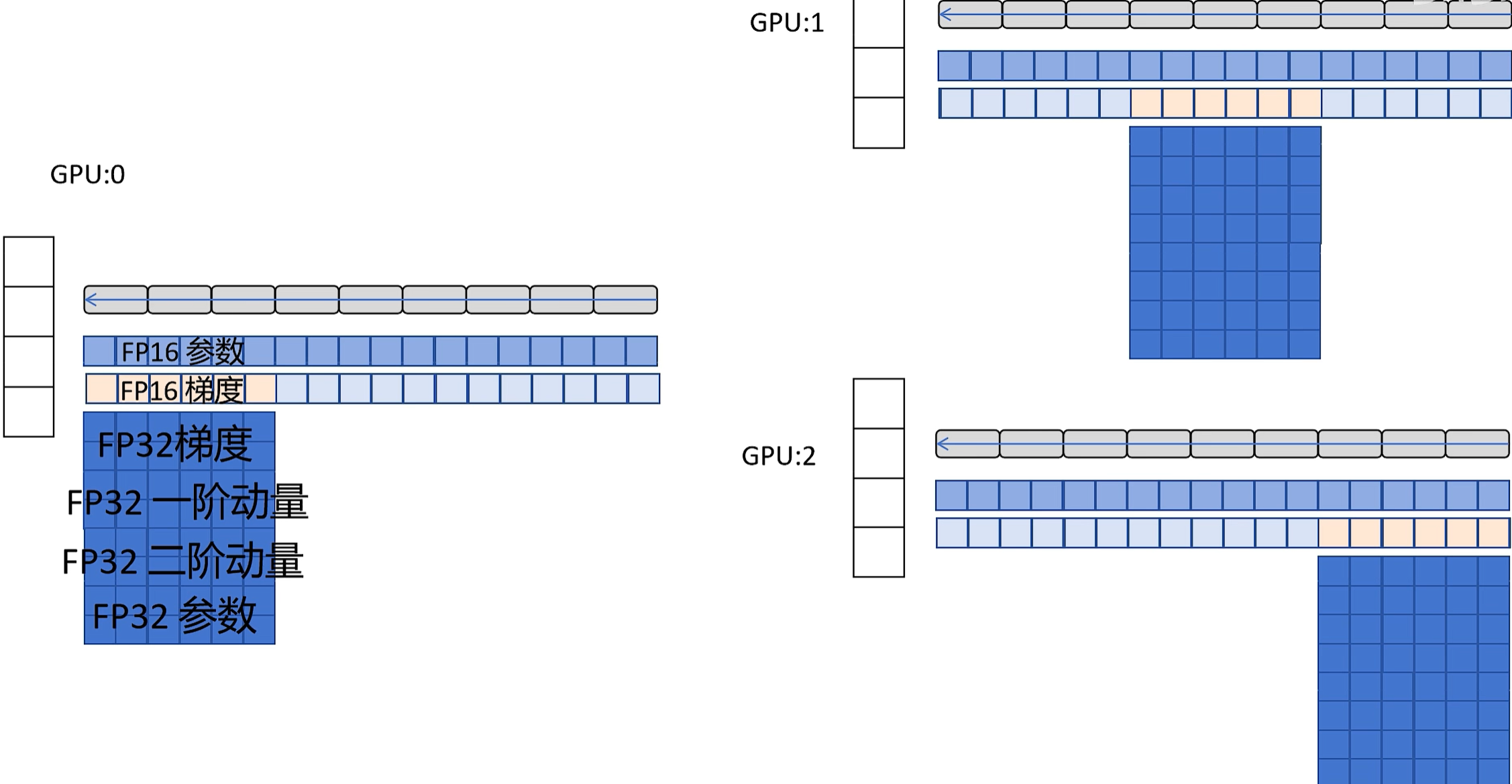
通信量分析:和DDP是一样的,但是每块显卡节约了显存!最核心的就是每块显卡都把不属于自己负责那段网络的梯度发送给指定负责的网卡,并未盲目全体广播,此处节约了带宽!但因为每块显卡要广播更新后的网络参数,所以网络通信相比DDP并未减少!

这个思路有点像国内的铁路局:国家在不同的区域分别设置了铁路局,每个局负责自己片区铁路线路的建设和运维;等建设完毕就把这个消息发送给其他铁路局,然后开通相应的运输路线!
(2)既然每块GPU只负责更新部分参数,那是不是只保存对应的梯度也行了?这就是ZeRO-2的思路!
- 数据照样均分成,N个显卡同时做forward和backward;N快显卡网络的初始参数都是一样的
- foward时所有显卡可以并行(因为都存储和FP16的网络参数),然后各自计算loss和梯度
- 做BP时:
- GPU0和GPU1计算出最后4个block的梯度后发给GPU2,让GPU2更新optimizer和网络参数,这部分的梯度自己都丢弃,完全不存;
- 其他两个block的参数做法类似,不再赘述
- 最后3块显卡再互相广播更新后的网络参数
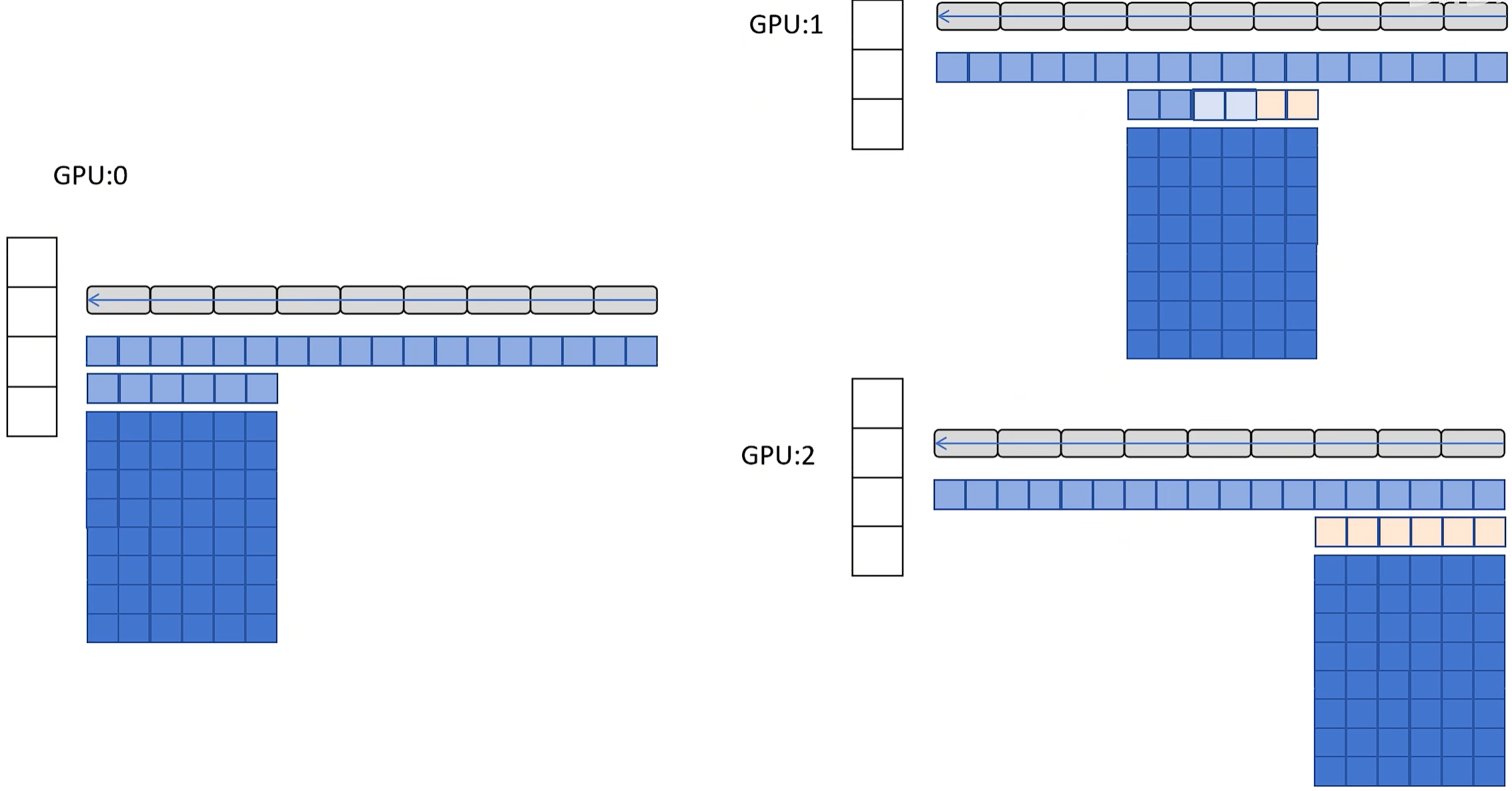
(3)既然optimizer和梯度都可以只存部分,那参数是不是也可以了?这就是ZeRO-3的思路了!但这次的情况又有点不同:网络参数都不完整,怎么forward?这就只能依靠广播了,需要用到的时候让其他GPU发过来!
- 数据均分成N份,同时做forward;但因为每块显卡的参数都不全,所以涉及到自己的时候要让其他显卡发过来;比如最前面4个block做forward,GPU0有,但是GPU1和2没有,就让GPU0广播;其他block同理,用的时候广播,用完就丢弃不存储!
- BP计算loss和梯度也要网络参数啊,咋办?同样还是广播的方式补全!
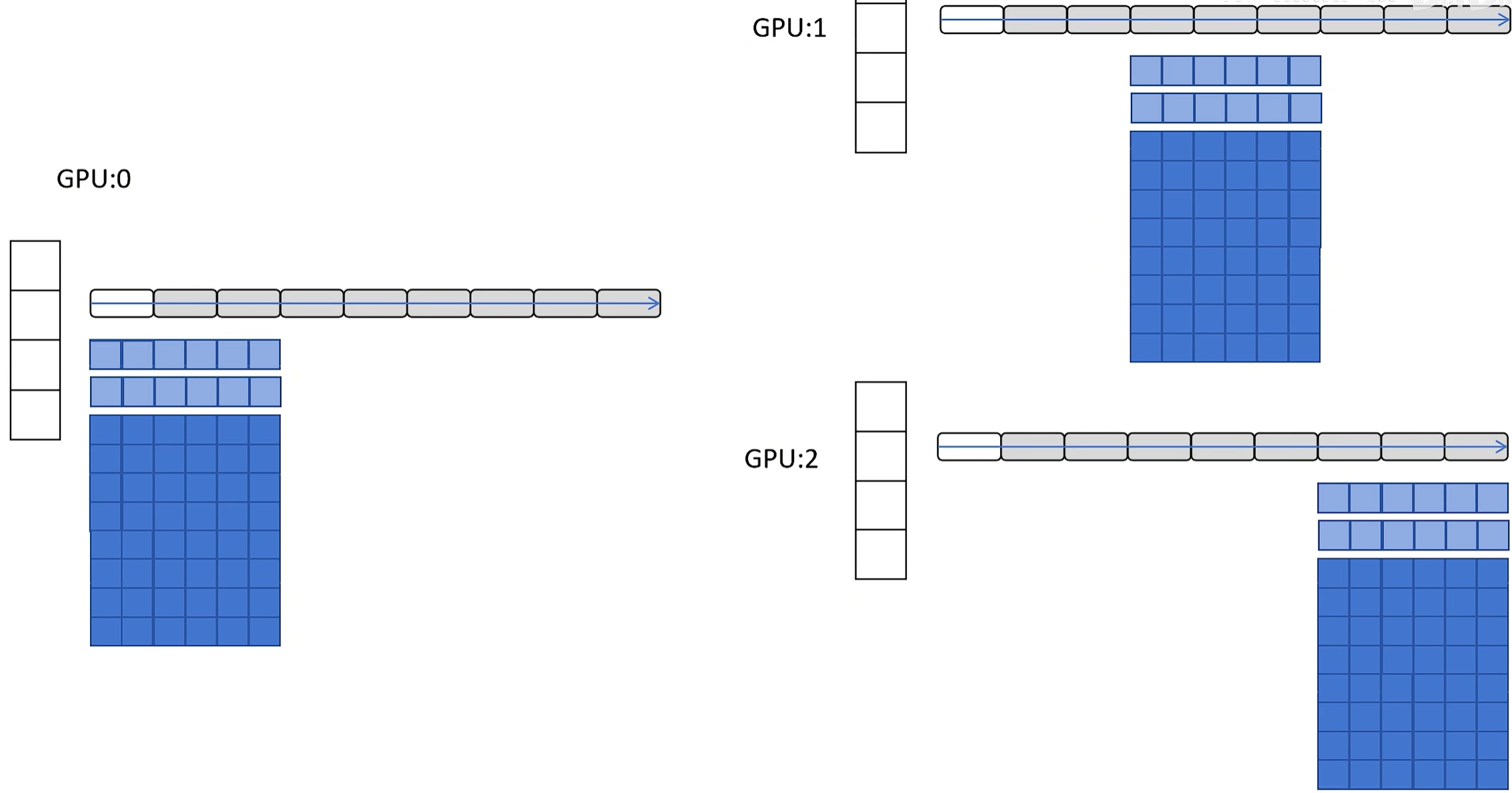
这种思路本质是需要用到的时候让其他GPU配合发送过来,用完就删除不存储!用显卡之间的带宽换显存的空间!通行量如下:

通行量是DDP的1.5倍,但是显存占用比DDP小了接近60倍!最后,来自ZeRO官方论文的总结对比:分别是DDP、ZeRO1/2/3阶段的显存消耗:
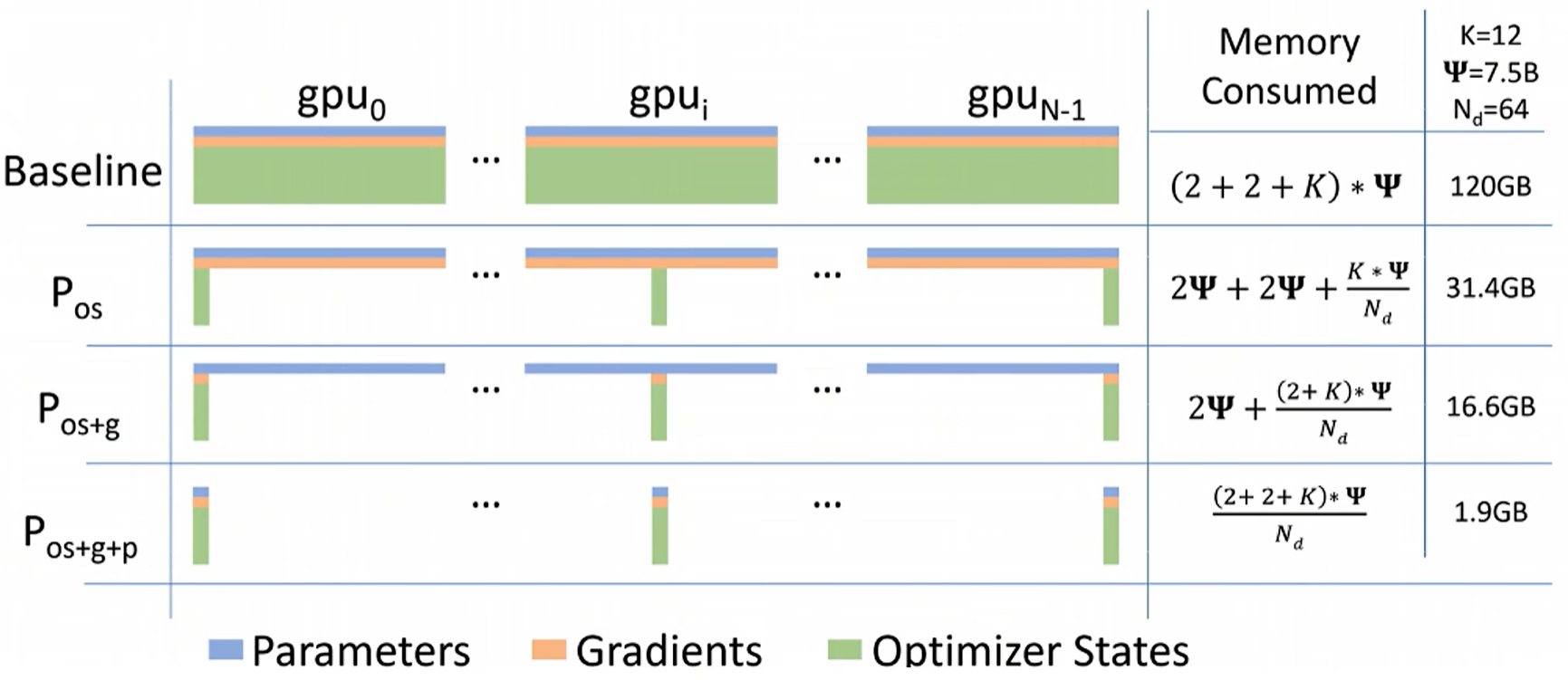
实战中,一般采用ZeRO-2: 没有增加通行量,但是极大减少了显存的占用!
其他
1、以前做大数据,hadoop是标配,会安装、运维、调优甚至修改hadoop框架内部各种组件的研发很吃香,进大厂后工资都不低;同理,在以后AI时代,会安装、运维、调优甚至更改分布式训练/微调/推理框架的研发肯定更吃香,这绝对是个很不错的方向!
2、显卡之间通信,涉及到参数传递的,会让显卡组成虚拟环,环内每个显卡的每个维度都依次给下一个显卡发送数据,直到每个显卡的参数都一样位置,这期间的经历称为scatter-reduce和all-gather!
scatter-reduce:单个维度向下扩散依次累加;这里一看到reduce,就想起了10多年前因大数据爆火的map-reduce框架;这里的reduce功能和map-reduce的功能原理上一模一样,没本质区别!
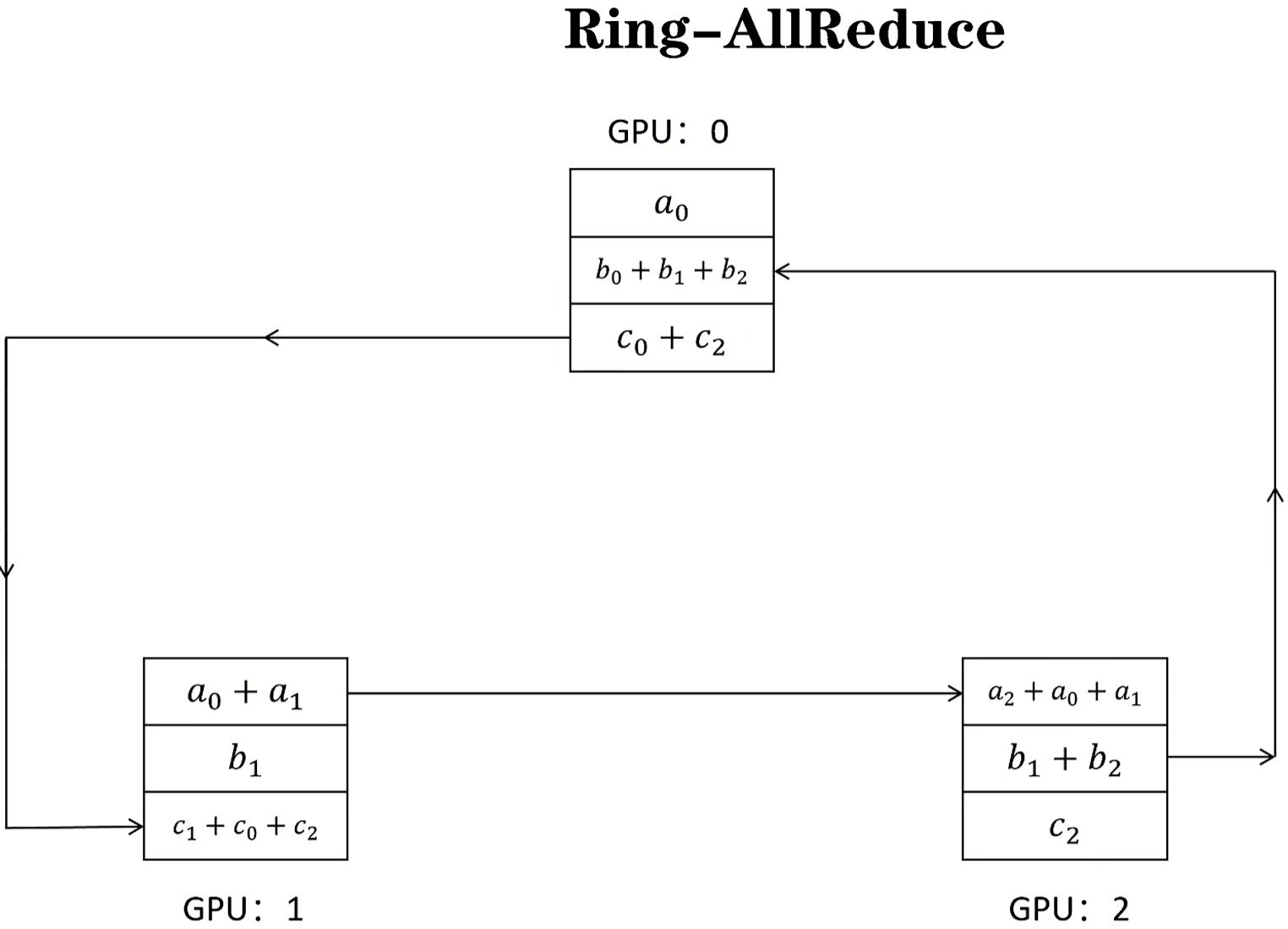
all-gather:单个完成的维度往下扩散,确保其他显卡该维度的数据是正确的!
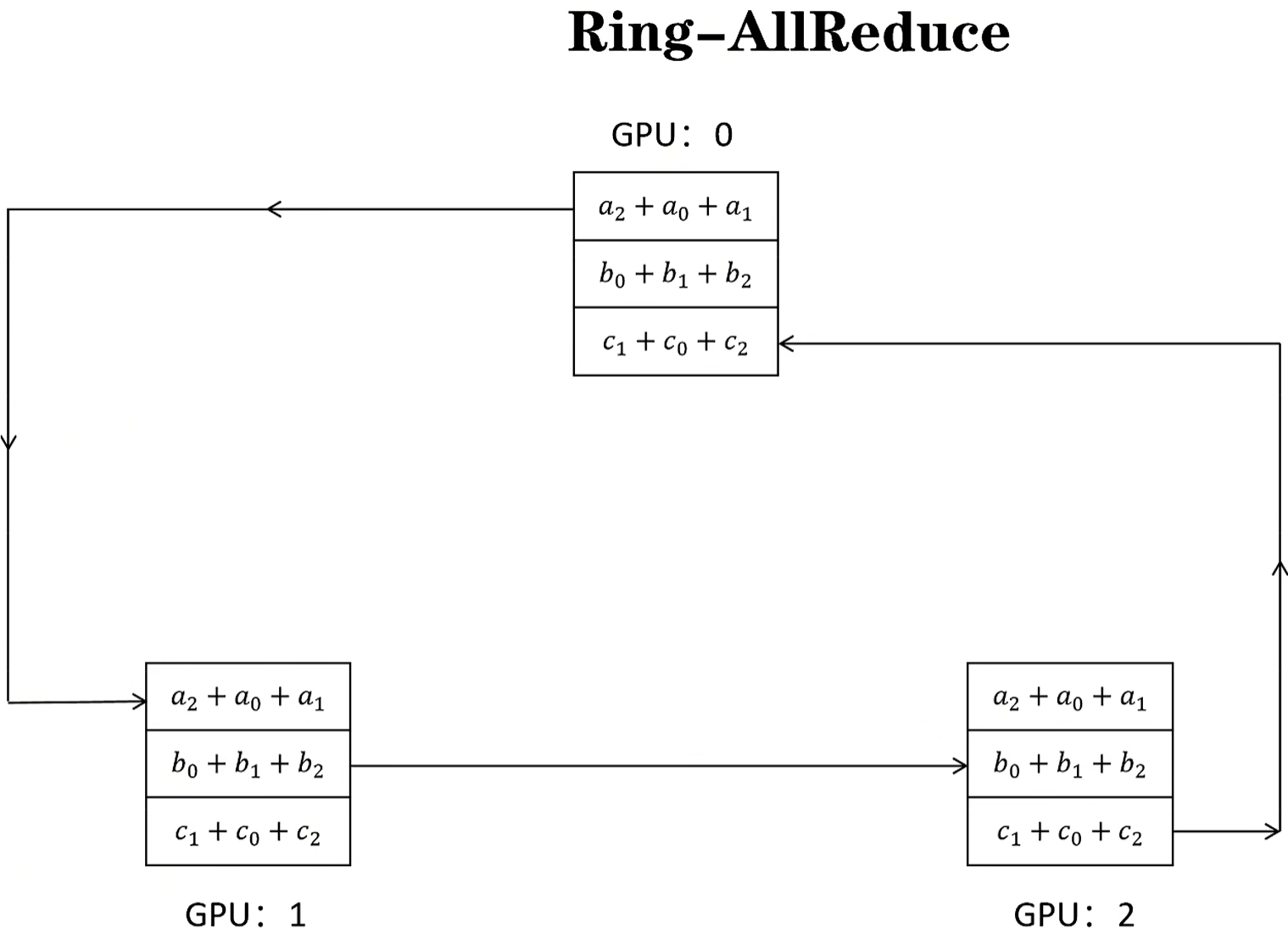
在Ring-allReduce中,每块显卡都在发送和接受数据,可以最大程度利用每块显卡的上下行带宽!
参考:
1、https://www.bilibili.com/video/BV1LC4y1Y7tE/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 deepspeed训练和推理
2、https://www.bilibili.com/video/BV1fb421t7KN/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 分布式大模型训练
3、https://www.deepspeed.ai/ https://github.com/microsoft/DeepSpeed https://www.deepspeed.ai/getting-started/ 官网
4、https://www.bilibili.com/video/BV1ks4y1u7qr/?vd_source=241a5bcb1c13e6828e519dd1f78f35b2 DeepSpeed-Chat 模型训练实战
5、https://arxiv.org/pdf/1910.02054 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
6、https://www.bilibili.com/video/BV1mm42137X8/?spm_id_from=333.788.recommend_more_video.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 DeepSpeed ZeRO技术