一、梯度下降法
梯度下降法就是一种通过求目标函数的导数来寻找目标函数最小化的方法。梯度下降目的是找到目标函数最小化时的取值所对应的自变量的值,目的是为了找自变量X。
梯度:是一个矢量,其方向上的方向导数最大(意味着在这个方向上,函数的值增加最快。从图形上看,就是函数图形在某点最“陡峭”的方向)。其大小正好是此点的最大方向导数。
梯度下降算法用下山来类比就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的方向走,然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
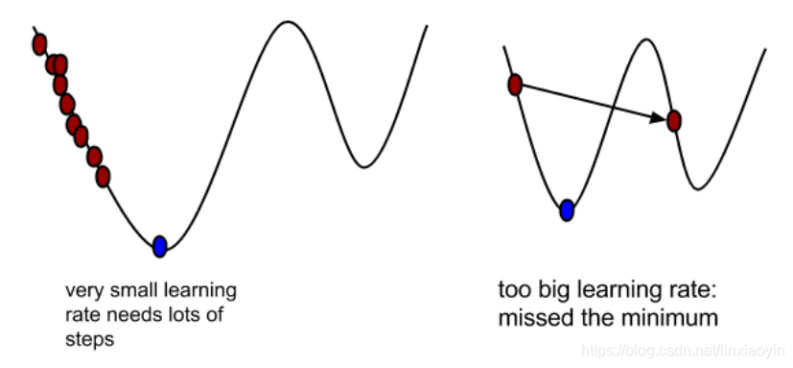
学习率决定了模型在每一次迭代中沿着梯度下降(或上升,对于最大化问题)方向更新参数的幅度。
学习率的重要性:
过大:如果学习率设置得太大,模型在训练过程中可能会跳过最优解,导致训练过程中的损失值在最优解附近波动,甚至发散,无法收敛。
过小:如果学习率设置得太小,虽然模型最终能够收敛到最优解附近,但训练过程会非常缓慢,需要更多的迭代次数,增加了计算成本和时间成本。
适中:选择合适的学习率可以让模型在合理的时间内快速且稳定地收敛到最优解附近。
二、特征缩放(归一化):提升模型精度(消除不同量纲)
例如: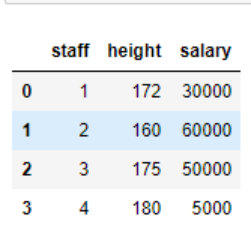
假设用神经网络来学习这份数据,那么就会导致取值范围更大的薪水会主导模型的训练,也就是模型会偏向于薪水,但通常我们不希望我们的算法一开始就偏向于某个特征,因此要对数据做归一化处理。
下面是课程中出现的两种归一化操作
归一化处理方法一:
归一化处理方法二: data[col] = (data[col]-data[col].min()) /、(data[col].max()-data[col].min())
三、Relu激活函数:将所有的负值置为0,而正值保持不变,从而引入非线性因素,模拟复杂的神经网络。
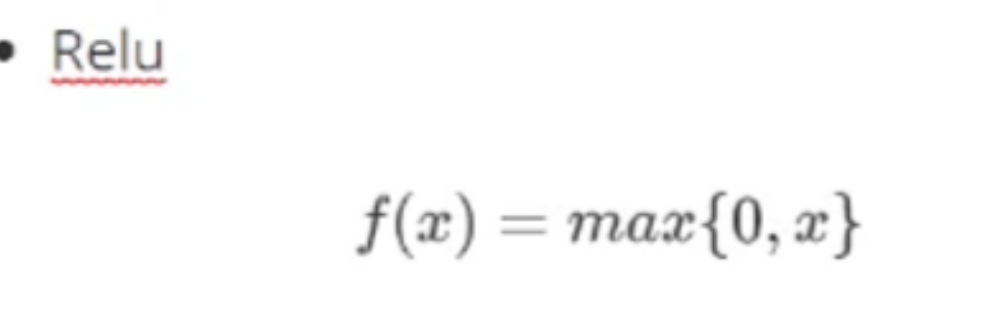
四、损失函数(Mseloss)
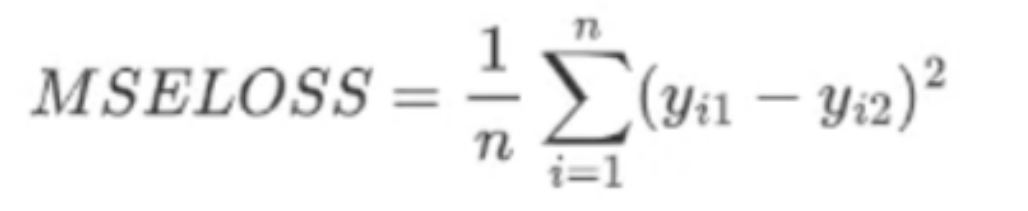
五、onehot编码处理(将分类变量转换为机器学习算法可以处理的数值形式)
定义One-Hot编码函数
def oneHotEncode(df, colNames):
1. df: 一个pandas DataFrame,包含要进行One-Hot编码的列。
2. colNames: 一个列表,包含要进行One-Hot编码的列名。
for col in colNames:dummies = pd.get_dummies(df[col], prefix=col)
使用pandas的get_dummies函数对指定列进行One-Hot编码。这里,prefix参数用于为生成的虚拟列添加前缀,以便更容易地识别它们来自哪个原始列。
df = pd.concat([df, dummies],axis=1)
使用pandas的concat函数将原始DataFrame和编码后的虚拟列(dummies)沿着列方向(axis=1)连接起来。这会在原始DataFrame的右侧添加新的虚拟列。
df.drop([col], axis=1, inplace=True)
从原始DataFrame中删除已经进行One-Hot编码的原始列。(inplace=True参数表示直接在原始DataFrame上进行修改,而不是返回一个新的DataFrame。)
return df
当所有指定列都经过One-Hot编码并删除原始列后,函数返回修改后的DataFrame。
六、课程中出现的一些数据处理操作
1、替换特定字符:
data = data.replace('-', '-1')
这行代码在data DataFrame中全局搜索所有的'-'字符,并将它们替换为字符串'-1'。注意,这里的替换是全局的,它会检查DataFrame中的所有元素(即所有列和行中的每个单元格),并将找到的'-'替换为'-1'。这种替换默认不会改变数据的类型,即如果原数据是数值类型,替换后的结果仍然是字符串类型。
2、更改数据类型:
data.notRepairedDamage = data.notRepairedDamage.astype('float32')
这行代码将data DataFrame中notRepairedDamage列的数据类型转换为float32。这通常用于确保列中的数据是以浮点数形式处理的,这对于数值计算和机器学习模型训练特别有用。
3、基于条件更新数据:
data.loc[data['power']>600,'power'] = 600
这行代码使用loc方法基于条件更新data DataFrame中的power列。具体来说,它查找power列中大于600的所有值,并将这些值设置为600。这是一种常见的数据预处理步骤,用于处理异常值或限制某些特征的范围,以便更好地进行后续的数据分析或机器学习模型训练。
4、填充空缺值
data[col] = data[col].fillna('-1')
对于config['cate_cols']中指定的所有分类特征列,使用字符串'-1'来填充缺失值。
5、处理无关数据
data.drop(['name', 'regionCode'], axis=1, inplace=True)
从数据集中移除了name和regionCode列
del test_data['price'] 删除‘price’列
6、筛选或隐藏数据
test_data = data[pd.isna(data.price)] 从 data DataFrame 中筛选出那些 price 列包含缺失值(即 NaN)的行,并将这些行存储到新的 DataFrame test_data 中。
train_data = train_data.drop(data[pd.isna(data.price)].index) 隐藏price 列中含有缺失值(NaN)的行
7、打乱数据顺序(使随机化)
train_data.sample(frac=1)这行代码就是用于随机化train_data DataFrame中的行顺序,以确保模型训练的公平性和泛化能力。
8、初始化
初始化函数 init
在Python中,特别是在使用面向对象编程(OOP)时,init 函数是一个特殊的方法,被称为类的构造函数或初始化方法。当创建类的新实例时,Python 会自动调用这个方法。init 方法的主要目的是初始化新创建的对象的状态或属性。在PyTorch的nn.Module子类中定义网络结构时,init 方法用于定义网络层的结构,即哪些层将被包含在网络中,以及这些层的配置(如输入和输出维度)。
9、前向传播函数 forward
def forward(self, x): 定义了数据通过网络的前向传播过程。x是输入数据。
y = self.layers(x): 将输入数据x传递给self.layers(即前面定义的层序列),执行前向传播,并将结果存储在y中。这里的y是网络的最终输出。
return y: 返回网络的输出y。
七、tensor类
X=torch.tensor(train_data.values, dtype=torch.float32)
这行代码是使用PyTorch库来将一个名为train_data的数据集(可能是一个pandas DataFrame或者类似的二维数据结构)转换为PyTorch张量(Tensor)。这里,train_data.values获取了train_data中的值,通常是一个NumPy数组,然后这个数组被转换成了一个PyTorch张量,并且指定了数据类型为torch.float32。
补充:item()函数将pytorch张量转化成Python标量
X = X.reshape(-1, 334) 这行代码是在对已经存在的PyTorch张量 X 进行重塑(reshape)操作。这里,X 是一个多维张量,而 reshape 方法被用来改变其形状,但不改变其数据。
具体来说,reshape(-1, 334) 的含义是:
-1:这个维度的大小是自动计算的,以便保持张量中元素的总数不变。这里,PyTorch会计算需要多少行(第一个维度)来确保总的元素数量与原始张量相同,同时保持第二个维度为334。
334:这是重塑后张量的第二个维度的大小,即每行将包含334个元素。
这种重塑操作在准备数据以输入到神经网络中时非常常见。例如,如果你有一个包含多个样本的数据集,每个样本都有334个特征,但原始数据的形状可能不是 (n_samples, 334),你就可能需要使用 reshape 方法来将其转换为这种形状。
1、Tensor的基本概念
Tensor是一个多维数组,可以表示标量、向量、矩阵以及更高维度的数组。在深度学习中,Tensor是数据的基本单位,用于存储和传输数据。Tensor的维度(也称为秩)决定了其结构,例如:
Rank为0的Tensor是标量(Scalar),表示一个单一的数值。
Rank为1的Tensor是向量(Vector),表示一维数组。
Rank为2的Tensor是矩阵(Matrix),表示二维数组。
Rank大于2的Tensor称为高维张量,可以表示更复杂的数据结构。
2、Tensor的属性
Tensor具有多个属性,这些属性描述了Tensor的基本特征,包括:
数据类型(dtype):Tensor中元素的数据类型,如float32、int64等。
形状(shape):Tensor的维度信息,用元组表示,例如(2, 3)表示一个2行3列的二维Tensor。
设备(device):Tensor存储的设备,可以是CPU或GPU,用于指定Tensor的计算位置。
梯度(grad)(在PyTorch中):如果Tensor的requires_grad属性被设置为True,则PyTorch会跟踪与该Tensor相关的所有计算,并在调用.backward()时计算其梯度。
3、Tensor的创建与操作
在PyTorch和TensorFlow中,可以通过多种方式创建Tensor,例如:
一)直接创建:使用框架提供的函数,如PyTorch中的torch.tensor()、torch.zeros()、torch.ones()等,或TensorFlow中的tf.constant()、tf.zeros()、tf.ones()等。
二)从其他数据类型转换:可以从Python的内置数据类型(如列表、元组)或NumPy数组转换而来。
Tensor支持多种操作,包括基本的数学运算(如加减乘除)、矩阵运算(如矩阵乘法)、广播(Broadcasting)等。这些操作使得Tensor能够灵活地表示和处理复杂的数据结构和计算任务。
4、Tensor的应用
在深度学习中,Tensor被广泛应用于神经网络的构建和训练过程中。神经网络的每一层都涉及到Tensor的输入、输出和计算。通过前向传播(Forward Pass),数据以Tensor的形式在神经网络中流动,并产生最终的输出。然后,通过反向传播(Backward Pass)和梯度下降等优化算法,计算并更新网络中的参数(以Tensor的形式表示),以最小化损失函数并提高模型的性能。