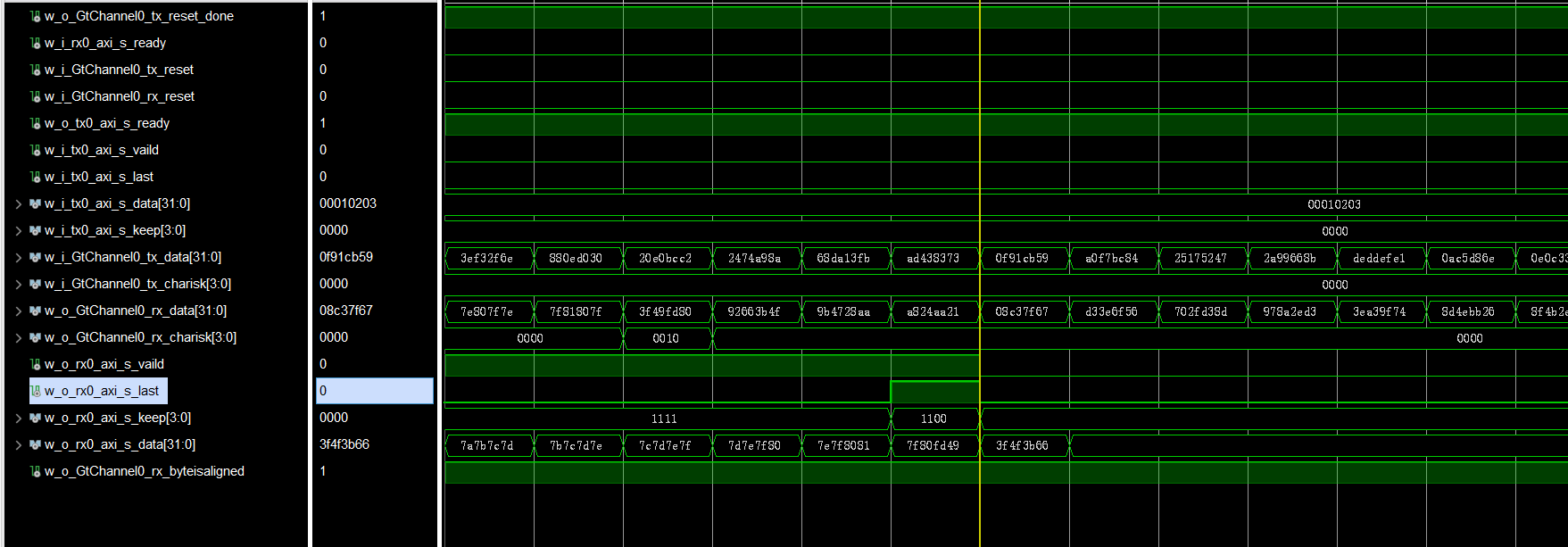
15-并发控制理论
并发控制横跨了多个层级:
- operator Execution 操作执行
- Access Methods 读表
- buffer Pool Manager 缓存池
日志恢复
- buffer Pool Manager 缓存池
- Disk 磁盘管理
Motivation:
- 当多人修改数据库同一条数据,就会出现竞争问题
- 把100块钱从A账户转移到B账户,如果A账户扣100之后,机房断电了。当断电恢复之后,当前的数据库状态应该是什么?(如果没有恢复,状态肯定是错误)

上面一个涉及丢失更新的问题 Lost Updates ,用并发控来解决。下面一个问题,用持久性来解决,用恢复来解决
并发控制和恢复是数据库非常重要的功能。他们是实现事务ACID特性的基础。
基础理论(txn)是事务.txn 是一个数据库操作的基础操作单元。如果没有显示开txn,在数据库中一条sql也是一个txn。

批: 关于存储过程的理解
- 从表现上来看,存储过程整个可以看成是一个大的事务。要么执行成功,要么执行失败。这也就是其与其他程序事务的区别
转账包含3个动作:
这三条语句要么都成功,要么都失败。

想当然的思路:
- 一次只执行一条(不能并发跑,影响数据库的性能)
- 将整个数据复制一份,备份一份。在复制一份上进行修改,如果执行成功,就持久化,否则不操作(数据量太大)

所谓并发,就是多个事务交替的执行。以并发的好处:
- 单条相应时间更短
- 对系统更高的利用效率

并发的要求
- 正确性
- 公平
并发限制的必要性,如果并发不进行限制,会导致什么问题呢?多个txn交叉运行,会有问题
- 可能使得数据永久性损失

多个txn能否并发,如何并发?如何交叉执行。这就是接下来要解决的问题
需要寻找一些标准,

数据库不知道sql语句本身代表的含义,所以 数据库要判断txn之间能否交叉运行,如何交叉运行,要根据sql本身去分析。

记住:这里的data object。为研究方便,将事务简化成 读写操作。
如下介绍数据库中操作数据的格式。begin开始,commit、abort(rollback)结束为止。 有的地方叫rollback

回滚有可能是程序本身发出的,也有可能是数据库本身发出的。
比如当前的txn和其他的txn产生了dead clock,那么数据库会主动打断当前txn的进程
改变不了之前的冲突情况。
接下来介绍txn的ACID四个性质。
前面说了 事务并发执行的要满足正确性与公平性,如下是正确性的四个标准:即 数据库执行txn怎么才算正确执行了,标准是什么?

原子性:要么执行成功,要么失败。
一致性:数据在执行txn之前和之后,状态要保持一致。数据来自于真实世界,反应真实世界,所以执行前后也要满足真实世界的逻辑。比如 A向B账户赚钱,A账户和B账户的钱 转账前后要保持一致。
隔离性:无论多少个txn在并发执行,从结果上来说和数据库串行执行一个txn的结果一致。
持久性:一个txn一旦执行成功,其对数据的影响是持久的。 无论是否停电或者是否发生其他非可抗因素。
通俗的版本:

今天要研究四个方面如何实现?

原子性质:

txn只有两种结局:成功,终止(被回滚)
在用户看来, 你的指令要么全部执行,要么一个也不执行。

两个场景发生之后,数据库当前这批数据的状态应该是什么?

实现原子性的手段:
- 日志
- 执行一步,同时在日志中,记录如果回滚,该如何操作(一般上是两份日志,一个是undo,一个是redo)
- undo log 一般是在内存和磁盘中都会存日志
- 好像是飞机的黑匣子一样
日志不光有回滚txn的作用,还有审计和提高执行效率的作用。
审计:如果数据库出问题,查看是哪些操作触发了审计。
提高效率:即先记录,在当时并不是真的执行,而后再在合适的时候,执行。 lazy evaluation
- 只备份你修改的page:增量备份。今天这个技术已经被淘汰了。

一致性:
txn执行前后,要满足基本的真实世界的逻辑。
一致性分为:
- 数据库一致性
- txn一致性

数据库一致性:
前后一致性,后面的操作

txn的一致性:要靠业务来保证。

批注:似乎在求解一个带约束的优化问题,最大化的执行事务 在 正确性和公平性的限制下。
二版:最大化事务的并发量
- 约束条件:ACID
隔离性:
理想的隔离:在一个时间只运行一个txn。
在后面我们会看到:数据库使用了非常复杂的方法来实现个理性。为什么要实现隔离性?
为了提高并发度,同时也方便了使用者,写sql的人。
- 用户在进行转账操作的时候,直接写转账的sql,能不能操作成功,数据库来做检查。
数据库做隔离性,就是为了用户能更好的实现业务。

所以,我们需要一种方法来交替穿插的跑txn。这里面有一个基准:数据库角度肯定是多个txn一起执行的,但是对用户来说要像串行跑一样。
接着从实际的执行效果,对txn进行分类,看看那些类可以进行直接跑,哪些类可以转化为串行跑。
并发控制协议是决定多个txn如何交替,按照什么顺序执行?什么时候让txn失败

有两大流派:
- 悲观派:事情还未发生之前做控制,让坏的事情不要发生。比如 后续介绍的两阶段锁
- 乐观派:先发展,后治理。矫枉必过正。出问题了再去让出问题的txn回滚掉,比如 时间戳并发控制
乐观比悲观好。实际中,应该是乐观悲观并用。

如何实现并发?

从结果分析:如何才算正确的输出。因为无论如何执行,要保证结果都是正确的。正确的基准是什么?是串行执行的结果。只要是和串行执行的结果相符合,那么就是正确的执行。并发的目标就是同时运行多个事务但是和串行的效果是一样的。

并没有说,T1一定要比T2先执行,或者 T2一定要比T1先执。但是运行的结果一定要和串行运行的结果相同。


从结果来看,上述两个事务顺序无论谁先执行结果都是正确的。上述叫真正顺序的执行。
interleave(交错)
如果是真的并发过来的,那么怎么让它交叠的去跑?
交替跑是一个优化问题,优化目标是最大并发量,约束条件是什么?是公平,正确。
可以更好的利用带宽,利用cpu。
交叠跑:
- 最大化系统并发量
- 更好的利用多核cpu(系统可用性更高,能更加充分的利用系统)
如果一个txn出错了,那么它不会影响别的txn

如果对并发不进行控制,如下就是随机跑的案例。(这页PPT有问题)

如下这个就是错误的,存在一致性问题。

转换成数据库的操作,数据库在干什么?对数据库而言,所有的操作落实下去无非是读写两个操作。所以后续用读写操作为线条,来分析并发中可能遇到的种种问题,而后对种种问题进行解决。

后面分析问题的形式就要发生变化了。变成读写角度了
我们可以从人为的角度,判定txn的执行是否存在问题,那么我们如何编写程序,让数据库来识别出txn的执行是否存在问题?
以真正串行的调度作为基准,如果实际txn的执行可以等价成串行,那么没有问题。

那么如何等效?

真正串行的执行称之为:Serial Schedule。
ps:这里面几个改变,serial schedule(串行化调度),Equivalent Schedules(等价串行化),Serializable Schedule(可串行化调度)的概念
等效串行化:(串行等价)
- 如果执行的效果 和串行一致,那么称之为等效串行化(无论实际制定的顺序是什么,描述有歧义)

可串行化调度 。如果每一个txn都保证一执行,那么可串行化调度也保证了一致性。

可串行化是一个不太好理解的概念。更大的灵活性意味着更大的并行度。
接下来,从行为或者实际遇到的问题的角度,来分析什么场景下的并发可以等效串行,什么可以直接转化为串行?

冲突操作的定义:两个操作是冲突的,其需要满足如下条件:
- 来自不同的事务
- 针对在相同的object上,至少有一个是写
根据上面的定义,冲突有如下三种:

接下来,逐一的看:
读写冲突:一个读了两次,一个在读的中间写了一次,此时前后不一致称之为 读写冲突(又叫不可重复读)

明显破坏了隔离性,第一次读和第二次读不一样。
写读冲突:(先写后读,而后撤销写操作)叫脏读

交叉之后,可串行的执行,会出问题。
串行的结果,要么最后A和B是T1写的结果;要么是T2写的结果;这两者任意一个结果都是正确的。不能是两者混着
写写冲突:结果交叉。

研究冲突是为了更好的串行化。
可串行化有两种
- 基础冲突
- 基于观察的串行化

两个txn是冲突等效,当且仅当:
- 如果
一些冲突操作可以转换为 串行化操作
ex:不懂这里

S是冲突等效的,当你可以将s变换成串行调度通过交换不同txn的连续非冲突操作。

判断如下是否能可以转化成可串行化序列

为什么可以滑动?因为不同的action是不存在。
在时间上不同的操作可以滑动位置。(ps:滑动位置只是说明可以串行化,那么实际执行也是串行化吗?)

一个反例:

一旦有重复,写些冲突,不能等效交换。没办法转化成真正串行的。
如果有冲突,不能等效交换位置。

如下也不能交换位置:

除了如上的三种冲突,都是可以交换位置的。

当存在多个txn的时候,交换操作就会变得很难,所以需要新的算法。
引出依赖图这个工具:

构建依赖图。(感觉拓扑排序可能在这里有用)
如果依赖图有环,永远无法等效成串行化。构建依赖图,判断是否有环,

如果两个调换位置,那么就和串行化之后结果不同的。

因为图中不存在环,所以可以先执行T2,再执行T2,再执行T3。
如上三个可串行化。不是真串行化,是执行效果相当于串行化。
如下是一个反例:永远没有通过滑动的办法,将如下操作等效为串行化。

好像给了一个依赖图无法包含的问题。我不懂
前面的是基于冲突的,下面是基于观察的。


依赖图显示不可以,但是根据实际的业务发现是可串行的。依赖图是有局限性的,依赖图会错杀一些真正可串行化的情况


基于人类 观察的可串行化 比 基于冲突的 局限性更少。但是无法实现。
两种都没办法做到100%的不误杀,因为算法没办法理解业务。多少都会存在错杀的情况。

实际中,基于冲突的用的更多,因为更好实现。错杀的特殊情况有些可以形成案例,摘出来,单独判断。(大模型套小模型,大模型+规则)
大部分数据库对于只读txn,那么就不需要判断读写依赖,写读依赖。直接并发就可以了。
多种调度并发执行分类:
真正串行的是一小部分,稍微多点的是 冲突可串行化。再多的是观察可串行化。

持久性:



并发控制和恢复是数据库最重要的功能之一。mysql是免费开源的数据库支持事务。
txn可以极大的减轻业务的实现复杂度。
并发控制是自动实现的
- 并发控制要保证:并发执行的效果和单独的串行执行效果相同
大部分情况下,能用事务尽量用事务,但是某些地方可能直接coding性能更好,因为数据库不理解业务。