Laconic Private Set-Intersection From Pairings (2022)
[!IMPORTANT]
论文地址:https://eprint.iacr.org/2022/529.pdf
代码地址:https://github.com/relic-toolkit/relic/tree/main/demo/psi-client-server
代码运行参考:RELIC 库学习
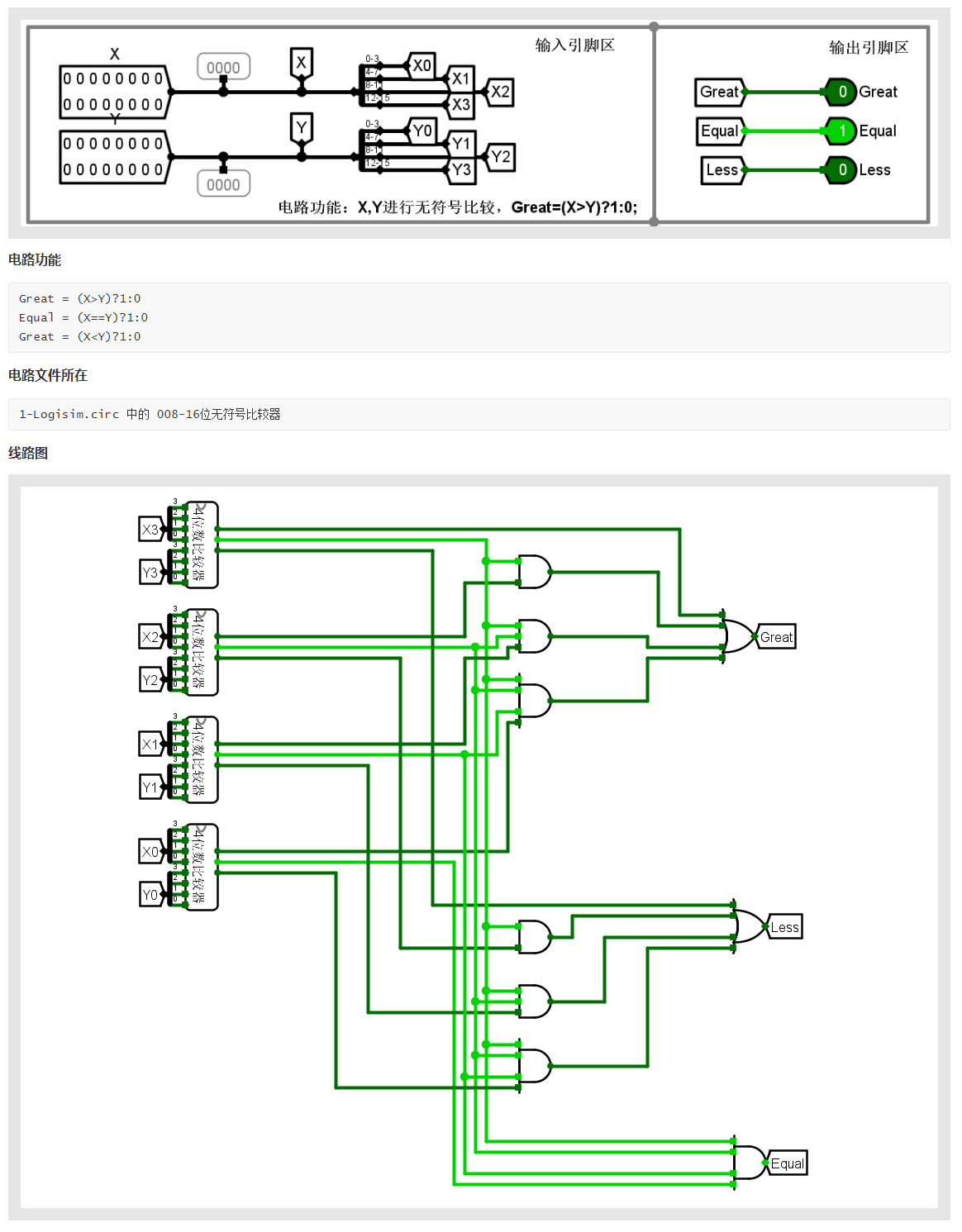
Laconic 算法介绍
Laconic 适用于算力和存储受限的客户端与算力和存储能力强大的服务器进行交互的场景。
问题:目前的 PSI 方案需要服务端和客户端之间进行复杂的计算,这对算力较弱的客户端很不友好,因为不可能要求其下载并保存巨量的数据,并基于这些数据完成复杂的计算。
2017 年,CDG 等人提出了 Laconic 的概念,Laconic 是一个在具有大输入的接收方 R(这里指服务端)和具有小输入的发送方 S(这里指客户端)之间的交互式协议,协议通常需要满足下列三个性质:
- 协议应当仅包含两条消息(也即 Laconic)
- 发送方(客户端)的总通信开销与接收方(服务端)的输入大小无关
- 接收方(服务端)的第一条消息应该可以被多个不同的发送方 \(S_i\)(客户端)复用,即计算一次,多次使用
本文所提出的两方 Laconic PSI,满足上述三个性质,旨在从理论和时间角度最大限度的减少发送方(客户端)的开销,发送方(客户端)的消息大小与其输入集合呈线性关系,发送方(客户端)的计算开销与接收方的输入无关。
但是,该算法需要在服务端进行大量的计算,服务端的压力比较大。
PSI Protocol
\(X_{-i}:=X \backslash\left\{x_i\right\}\):即将 \(x_i\) 从原集合中删除,剩下的元素组成的新的集合:
协议的具体流程如下:
| 序号 | 阶段 | 服务端 Receiver | 客户端 Sender | |
|---|---|---|---|---|
| 服务端和客户端共享: 1. \(H:\{0,1\}^* \rightarrow\{0,1\}^\lambda\) 2. \(e: \mathbb{G}_1 \times \mathbb{G}_2 \rightarrow \mathbb{G}_T\) |
||||
| 0 | Setup | \(X=\left\{x_1, \ldots, x_m\right\}\) 获得 \(\operatorname{setup}_{\mathcal{R}}\) |
可信第三方选择 \(s \in \mathbb{Z}_q^*\) 1. 计算 \(\operatorname{setup}_{\mathcal{R}}=\left(S_1, S_2, \ldots, S_m\right)\) 传给服务端:\(S_i=g_2^{s^i} \text { for } i=0, \ldots, m\) 2. 计算 \(\operatorname{setup}_{\mathcal{S}}=\left(S^{\prime}\right)\) 传给客户端:\(S^{\prime}=g_1^s\) |
\(Y=\left\{y_1, \ldots, y_n\right\}\) 获得 \(\operatorname{setup}_{\mathcal{S}}\) |
| 1 | First Round | 将 \(R\) 传给客户端 \(\to\) |
获得 \(R\) | |
| 2 | Second Round | 获得 \((T_j, U_j)\) | 将 \((T_j, U_j)\) 传给服务端 \(\leftarrow\) |
计算 \((T_1, U_1, ..., T_n, U_n)\) \(T_j = H\left(e\left(g_1^{t_j}, R\right)\right)\\ U_j = \left(S^{\prime} \cdot g_1^{-y_{\pi(j)}}\right)^{t_j}\) |
| 3 | RetrieveOutput | 对每个 \((T_j, U_j)\) 对,计算: For j = 1 to n: For k = 1 to m: 如果 \(H\left(e\left(U_j, R_{-k}\right)\right) \stackrel{?}{=} T_j\),则表明 \(x_k = y_{\pi(j)}\), 即 \(x_k\)为交集中元素 |
从上述 Laconic-PSI Protocol 可知:
- 服务端与客户端仅有两次交互
- 客户端的总通信开销仅与客户端的输入大小有关:\((T_j, U_j)\)
- 服务端需要计算一个 R 和 m 个 \(R_{-k}\),每个值的计算量都非常大(\(R_{-k}=\left(\prod_{i=0}^{m-1} S_i^{p\left(X_{-k}, i\right)}\right)^r=\left(\prod_{i=0}^{m-1} g_2^{{s^i}\times {p\left(X_{-k}, i\right)}}\right)^r\)),这导致服务端的计算耗时比较大,但是可以复用。如果服务端数据保持不变,\(R\) 和所有的 \(R_{-k}\) 首次计算后可以在多个客户端之间进行复用,但是,一旦服务端数据发生改变(例如增加了新的数据),所有的 \(R\) 都需要重新计算
- 在最后的求交阶段(Retrieve Output),每个 $y_j $(或者说 \((T_j, U_j)\))需要和 m 个 \(R_{-k}\) 进行“比较”,也就是说,为了判断某个 $y_j $ 是否在交集内,我们最多需要计算 m 次,那么总的计算复杂度为 \(O(mn)\),这也导致服务端的计算耗时比较大。论文 4.4 中提到了分桶(bucketing)的优化方案,可以将这一步中的计算复杂度由 \(O(mn)\) 降低到 \(O(mn/t)\),但是该优化方案会增大 First Round 阶段服务端的计算和传输数据量,具体而言,优化方案的步骤如下:
- 使用哈希函数,将服务端的数据 X 先分装到 \(t\) 个哈希桶中,这样每个桶中的数据量为 \(m/t\)
- 使用相同的哈希函数,将客户端的数据 Y 也分装到 \(t\) 个哈希桶中,每个桶的数据量为 \(n/t\)
- 然后服务端和客户端对应的哈希桶独立地进行上述算法中 First Round 和 Second Round 的计算,即服务端需要对每个桶中的数据独立计算 R 和 \(m/t\) 个 \(R_{-k}\),客户端也对每个桶的数据独立计算 \((T_j, U_j)\)
- 这样在 Retrieve Output 阶段,需要比较的次数不再是 \(m \times n\),而是 $t \times m/t \times n/t = mn/t $

证明算法正确性
证明上述算法的正确性:即当 \(H\left(e\left(U_j, R_{-k}\right)\right) \stackrel{?}{=} T_j\) 时,可以证明 \(x_k = y_j\) 为交集中的元素。证明过程如下:


勘误:服务端需计算 m (非 m-1)个 \(R_{-k}\) 值,k 取值从 1 到 m
与 NR-PSI 比较
服务端的集合大小 \(N_s\) >> 客户端的集合大小 \(N_c\)
| 两方交互次数 | 通信开销 | 客户端所需容量 | 何方计算交集? | 计算交集时客户端的每个元素所需的比较次数 | 服务端计算量 | 当服务端增加新元素 | |
|---|---|---|---|---|---|---|---|
| NR-PSI | 3 + 1 + 2 = 6 | 与服务端的集合大小线性相关 | 较大,需存储服务端的全部数据(哈希桶) | 客户端 | 3 + s(布谷鸟哈希) | 较小 | 仅需将新元素加密后插入哈希桶中,然后将新桶发送给客户端 |
| Laconic PSI | 2 | 与客户端的集合大小线性相关 | 较小,仅与客户端集合大小线性相关 | 服务端 | \(N_s\) | 较大 | $$ 与 所有的 \(R_{-k}\) 都需要重新计算,计算量较大 |
NR-PSI 的交互次数计算如下:参考 隐私求交代码实践
- Base Phase:R-OT 需要两方进行 3 次交互
- 服务端 \(\to\) 客户端:\((h_0, h_1)\)
- 服务端 \(\leftarrow\) 客户端:\((v_0, v_1)\) 和 \(u\),OT 阶段结束
- 服务端 \(\leftarrow\) 客户端:\(u^i = G(k_{i,0})\bigoplus G(k_{i,1})\bigoplus r\),R-OT 结束
- Setup Phase:1 次,传输 CF
- 服务端 \(\to\) 客户端:Cuckoo Filter (CF)
- Online Phase:2 次
- 服务端 \(\leftarrow\) 客户端:\(b_{i,j} = c_{i,j} \bigoplus y_i[j]\)
- 服务端 \(\to\) 客户端:\(r_{i, j}^{1-b_{i, j}} \oplus\left(r_{i, j}^{b_{i, j}} \cdot a_j\right)\) 和 \(\tilde{g}\)
参考资料
- 双线性对在密码学中的应用(下)
- ECC 椭圆曲线原理
- ECC 椭圆曲线密码学的原理、公式推导、例子、Python 实现和应用