1.迭代器
1.1 迭代器介绍
迭代器是用来迭代取值的工具
# while循环实现迭代取值
a = [1, 2, 3, 4, 5, 6]
index = 0
while index < len(a):print(a[index])index += 1
1.2 可迭代对象
内置有_ _iter_ _方法的对象都是可迭代对象
# 字符串 是可迭代对象
a = 'messi'
print(a.__iter__()) # <str_iterator object at 0x000001E100A5A740>
# 整数、浮点数、布尔值 不是可迭代对象
print(1.__iter__) # invalid decimal literal
print(2.3.__iter__)
print(True.__iter__)
# 列表、元组、字典、集合都是可迭代对象
print([1, 2, 3].__iter__())
print((4, 5, 6).__iter__())
print({1: 'one', 2: 'two', 3: 'three'}.__iter__())
print({7, 8, 9}.__iter__())
1.3 迭代器对象
在可迭代对象的基础上具有_ _next_ _方法的对象
即同时具有_ _ iter_ _和_ _ next_ _方法的对象就是迭代器对象
a = 'messi'.__iter__() # 先用__iter__方法生成一个可迭代对象,再使用可迭代对象逐步取值
print(a.__next__()) # m
print(a.__next__()) # e
print(a.__next__()) # s
print(a.__next__()) # s
print(a.__next__()) # i
# print(a.__next__()) # 超过数量时会报错
a = 'messi'.__iter__() # 超过数量时,再次迭代同个对象,只能重新调用iter方法创建一个新的迭代器对象
print(a.__next__()) # m# 列表、元组、字典、集合都是迭代器对象
print([1, 2, 3].__iter__().__next__()) # 1
print((4, 5, 6).__iter__().__next__()) # 4
print({1: 'one', 2: 'two', 3: 'three'}.__iter__().__next__()) # 1
print({'j', 'q', 'k'}.__iter__().__next__()) # k
2. 生成器
2.1 概念
生成器是一种特殊的迭代器,可以在需要时生成数据,而不必提前从内存中生成并存储整个数据集
通过生成器,可以逐个生成序列中的元素,无需一次性生成整个序列
生成器在处理大数据集时,具有节省内存、提高效率的优点
print(range(10)) # range(0, 10)
2.2 生成器的创建方式
2.2.1 列表推导式
使用列表推导式时,将列表推导式的方括号改为圆括号,即可创建一个生成器
# 将列表改为元组,看起来像元组推导式,其实是一个生成器对象
a = (b * 3 for b in range(5))
print(a) # <generator object <genexpr> at 0x00000201A76793F0>print(next(a)) # 0
print(next(a)) # 3
print(next(a)) # 6
print(next(a)) # 9
print(next(a)) # 12
print(next(a)) # 超过数量时仍然会报错
2.2.2 使用关键字yield
(1)概念
使用yield关键字定义一个生成器函数时,生成器函数中的yield语句会暂停函数执行并返回一个值,下一次调用该函数时会继续执行并返回下一个值。
yield返回一个值的用法与return用法类似。
def f1():yield 1print(666)yield 2yield 3r = f1()
print(r) # <generator object f1 at 0x000001C41BC293F0>
print(next(r)) # 1
print(next(r)) # 666# 2
在上面的代码中,f1()是一个生成器函数,通过yield关键字逐个生成值
在调用该函数时,会得到一个生成器对象
调用next()函数,可以逐个返回生成器中的值
(2)yield的应用
# 在函数内可以采用表达式形式的yield
def eater():print('开始吃饭')while True:food = yieldprint(f'端上桌的是{food}')# 可以拿到函数的生成器对象持续为函数体send值,以上整个代码为生成器函数
a = eater() # 得到生成器对象
print(type(a), a) # <class 'generator'> <generator object eater at 0x0000021D758993F0>
# 需要先'初始化'(启动)一次函数,让函数暂停在food = yield,等待调用a.send()方法为其传值
a.send(None) # 等同于next(a)
# 开始吃饭 暂停在food = yield,因此会打印
a.send('potato')
a.send('fish')
使用装饰器完成生成器对象创建和函数初始化
def init(func):def inner(*args, **kwargs):g = func(*args, **kwargs) # 创建生成器对象next(g) # 函数初始化,暂停在food = yield位置return g # 将生成器对象返回出去return inner@init
def eater():print('开始吃饭')while True:food = yieldprint(f'端上桌的是{food}')# eater() 相当于inner(),拿到的是已经生成并且暂停在food = yield的生成器对象g
# 将上面eater()赋值给变量名,变量名send方法往生成器对象传值
a = eater() # 开始吃饭
a.send('potato') # 端上桌的是potato
a.send('fish') # 端上桌的是fish
3. for循环原理
def circle(start, end, step=1):while start < end:yield startstart += stepa = circle(1, 5) # 得到一个生成器对象a
print(next(a)) # 第一次执行next,调用函数,开始循环,start初始值为1,遇到yield函数暂停并将值返回
print(next(a)) # 第二次执行next,执行yield下一行的赋值语句,开始下一次循环,遇到yield函数暂停并将值返回
print(next(a))
print(next(a))
print(next(a)) # 超过个数将报错,了解类的知识再解决报错问题
for循环内部原理:
把关键字in后面的数据类型转换为了迭代器iter
循环next取值
next取值完毕后进行下一次next会报错,自动处理错误并且结束while循环
4. 模块
4.1 模块介绍
概念:
在python中,一个py文件就是一个模块,文件名aaa.py则模块名是aaa
模块的来源:
内置的:python解释器自带,如os、random
第三方的:开发者写好的模块,需要先下载再使用 pandas、requests
自定义的:程序员自己开发的模块
模块的存在形式:
一个py文件就是一个模块
一系列py文件的集合就是一个包
4.2 模块的使用
准备:新建一个文件foo.py
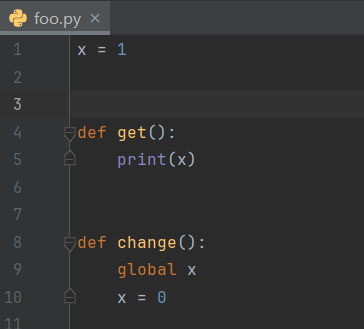
(1)直接导入
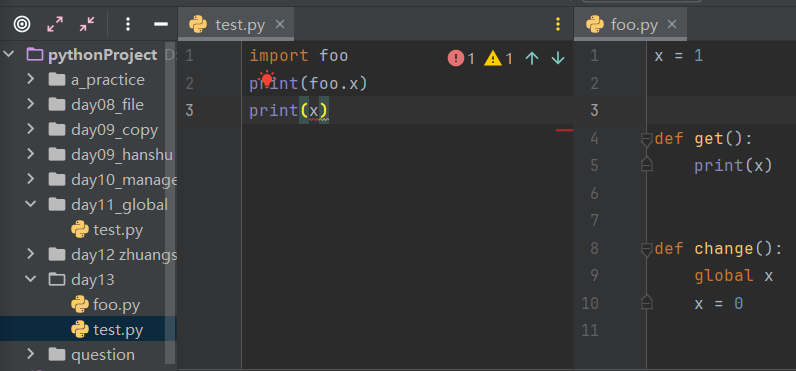
要想在另外一个 py 文件中引用foo.py中的功能
需要使用 import foo
首次导入模块会做三件事:
执行源文件代码
产生一个新的名称空间用于存放源文件执行过程中产生的名字
在当前执行文件所在的名称空间中得到一个名字 foo,该名字指向新创建的模块名称空间
若要引用模块名称空间中的名字,需要加上该前缀
import导入模块方式:
用import语句导入多个模块,可以写多行import语句
import module1
import module2
...
import moduleN
还可以在一行导入,用逗号分隔开不同的模块
import module1,module2,...,moduleN
(2)详细导入
from 模块位置 import 模块名:
使用import foo导入模块后,引用模块中的名字都需要加上foo.作为前缀
而使用from foo import x,get,change,Foo则可以在当前执行文件中直接引用模块foo中的名字
导入所有:
5. 包
模块是单独的py文件,一系列功能的集合体
包是模块加上_ _ init_ _.py的文件夹,是模块的集合体
5.1 创建包语法
(1)自动创建
在pycharm的文件夹上右键选择新建---python package
自动创建一个文件夹,并且当前文件夹中会自带一个_ _init_ _.py文件
(2)手动创建
创建一个文件夹,然后在当前的文件夹中创建一个_ _init_ _.py文件
5.2 使用包
(1)详细导入
详细导入语法 从指定包下面的模块中导入相应的方法
from control.Add import add
from control.multy import multy
(2)包内注册模块
_ _init_ _.py可以注册当前包下面的所有模块和功能
from control import add,multy
在加载带有_ _init_ _.py的包的时候
自动加载_ _ init_ _.py文件里面的所有代码
5.3 相对路径/绝对路径
相对路径 相对于当前文件夹来说的路径
绝对路径 相对于当前盘符来说的路径
. 当前目录
.. 上一级目录
6. json模块
以前存储文件时用的时text文本存储用户数据,文本只能切分和存储字符串数据,python中的字典对于字符串来说不行,所以就有一个比较普遍的存储文件的方式json
import jsona = {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'}# 将源数据转换为json字符串
b = json.dumps(a)
print(b, type(b)) # {"name": "messi", "age": 37, "club": "miami", "address": "usa"} <class 'str'># 将json字符串转换为源数据
c = json.loads(b)
print(c, type(c)) # {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} <class 'dict'># 将源数据写入到json文件中
with open('new.json', 'w', encoding='utf-8') as f:json.dump(a, f, ensure_ascii=False)# 将json文件的数据转换成源数据
with open('new.json', 'r', encoding='utf-8') as f2:data = json.load(f2)
print(data, type(data)) # {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} <class 'dict'>