方法代码如下:
private boolean executeCachedSql(String sql, int flags,String @Nullable [] columnNames) throws SQLException {//第一部分PreferQueryMode preferQueryMode = connection.getPreferQueryMode();boolean shouldUseParameterized = false;//第二部分QueryExecutor queryExecutor = connection.getQueryExecutor();//第三部分Object key = queryExecutor.createQueryKey(sql, replaceProcessingEnabled, shouldUseParameterized, columnNames);CachedQuery cachedQuery;//第四部分boolean shouldCache = preferQueryMode == PreferQueryMode.EXTENDED_CACHE_EVERYTHING;if (shouldCache) {cachedQuery = queryExecutor.borrowQueryByKey(key);} else {cachedQuery = queryExecutor.createQueryByKey(key);}//第五部分if (wantsGeneratedKeysOnce) {SqlCommand sqlCommand = cachedQuery.query.getSqlCommand();wantsGeneratedKeysOnce = sqlCommand != null && sqlCommand.isReturningKeywordPresent();}//第六部分boolean res;try {res = executeWithFlags(cachedQuery, flags);} finally {if (shouldCache) {queryExecutor.releaseQuery(cachedQuery);}}return res;}
对传入的参数进行分析,
- sql显然是SQL语句;
- flags根据名称只能推测是什么标志,待定;
- columnNames为一个可为空的String数组,和列名有关,待定。
接下来,拟定分为六部分,对每一部分的代码进行分析。
第一部分
PreferQueryMode preferQueryMode = connection.getPreferQueryMode();
该方法本质上为:
public PreferQueryMode getPreferQueryMode() {return queryExecutor.getPreferQueryMode();}
而queryExecutor为connection对象的一个属性
/* Actual network handler */private final QueryExecutor queryExecutor;
查看QueryExecutor的注释
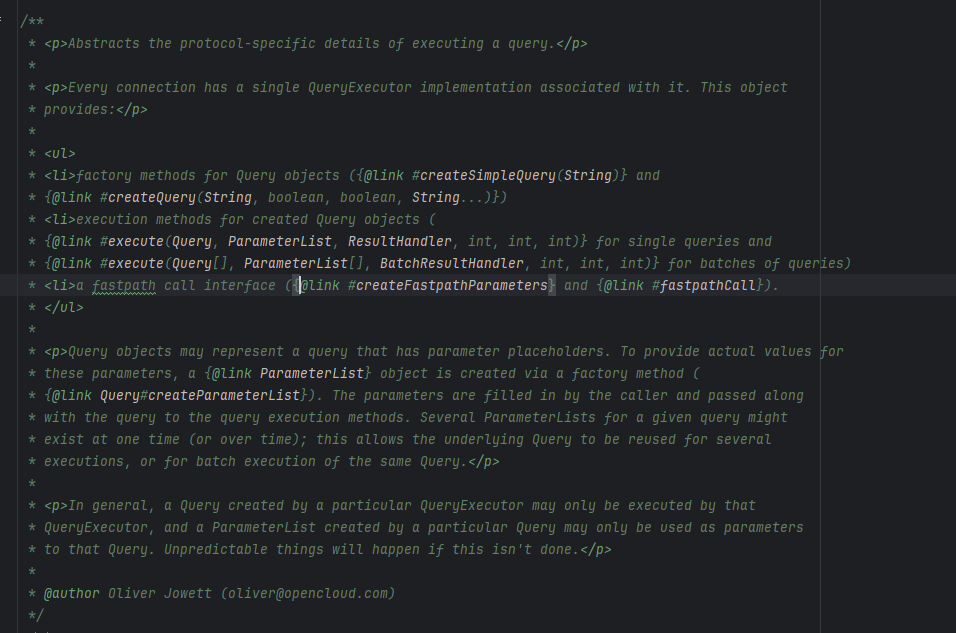
简单的总结:其抽象化了执行查询时与特定协议相关的细节,使得数据库连接可以通过单一的QueryExecutor实现来执行查询,而不必关心底层数据库协议或查询执行的具体细节。
而官方文档中有以下描述:

考虑到我们此次研究的方法,与之相关的点应该就是:提供创建Query对象的方法,并可以将该对象作为参数,执行查询语句。
查看Query类的注释
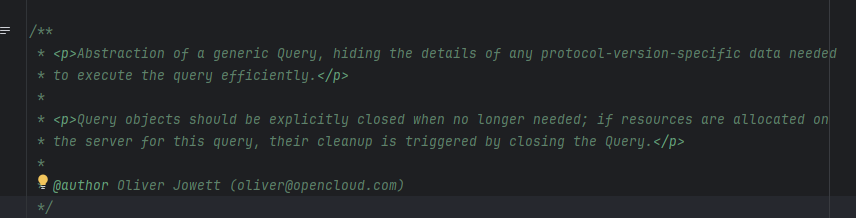
简单的总结:隐藏执行查询时所需的任何有关协议数据的细节,以便能够高效地执行查询。
不觉明历,看看官方文档

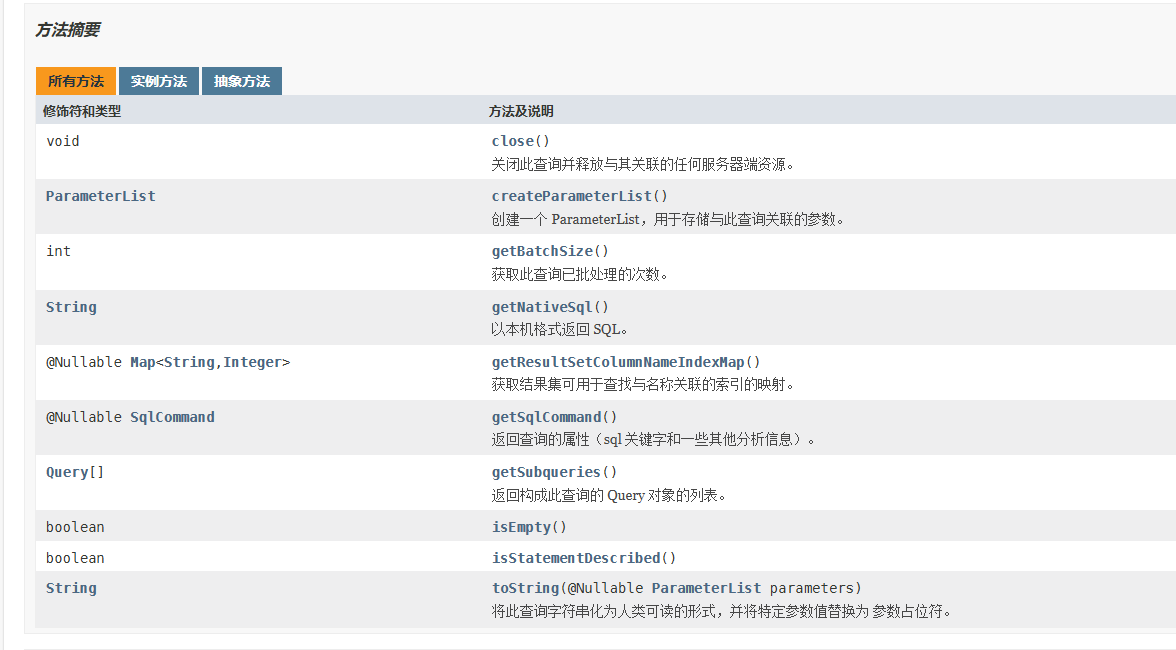
若有所得,在此基础上我们保持对该类的印象,回到第一部分的方法部分。
现在进度为queryExecutor.getPreferQueryMode(),按照当前的所得知的信息,Connection类中有一个QueryExecutor“类型”的属性,而QueryExecutor“类”中又有一个PreferQueryMode类的属性。
跳转到QueryExecutor接口的实现类QueryExecutorBase,找到preferQueryMode属性
我们发现,没有注释,继而跳到PreferQueryMode类的定义位置,查看其结构和注释
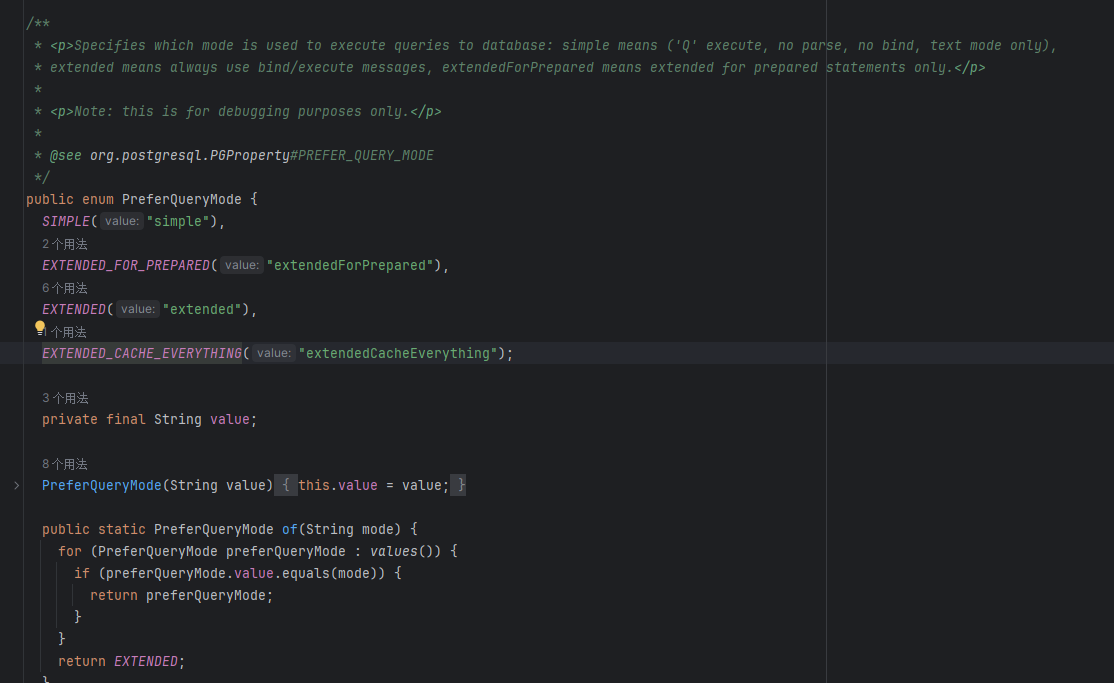
从其注释和明确的结构可知,PreferQueryMode类用于指定数据库的查询模式,Pgjdbc的查询模式如下:
- SIMPLE("simple"):表示使用简单的查询执行模式,即直接以文本形式发送查询,不进行解析和绑定操作。
- EXTENDED_FOR_PREPARED("extendedForPrepared"):表示仅对预处理语句使用扩展的查询执行模式,即使用bind/execute消息。
- EXTENDED("extended"):表示对所有查询都使用扩展的查询执行模式。
- EXTENDED_CACHE_EVERYTHING("extendedCacheEverything"):注释中未提到,从命名上看,它可能表示在扩展模式下缓存所有内容。
到此,我们已经知道了第一部分的作用,即获取当前连接指定的查询模式。
第二部分
QueryExecutor queryExecutor = connection.getQueryExecutor();
该方法即获得该connection实例的queryExecutor属性,关于QueryExecutor在第一部分也有了提及,此处不再重复。
到此,我们知道了第二部分的作用,即获取当前连接的queryExecutor属性。
第三部分
Object key = queryExecutor.createQueryKey(sql, replaceProcessingEnabled, shouldUseParameterized, columnNames);
首先,先分析一下传入的参数,sql、columnNames和shouldUseParameterized均在方法中提及,唯有replaceProcessingEnabled为方法所在类的属性,如下:

该属性未发现注释,字面意思理解为是否启用替换处理,结合上下文猜测应该为对sql语句是否启用替换处理,暂时如此推测,继续向下处理。
从QueryExecutorBase类中找到该方法
@Overridepublic final Object createQueryKey(String sql, boolean escapeProcessing,boolean isParameterized, String @Nullable ... columnNames) {Object key;if (columnNames == null || columnNames.length != 0) {// Null means "return whatever sensible columns are" (e.g. primary key, or serial, or something like that)key = new QueryWithReturningColumnsKey(sql, isParameterized, escapeProcessing, columnNames);} else if (isParameterized) {// If no generated columns requested, just use the SQL as a cache keykey = sql;} else {key = new BaseQueryKey(sql, false, escapeProcessing);}return key;}
参数对应关系:sql同上,escapeProcessing对应是否启用替换处理,isParameterized对应是否启动参数化,columnNames未知。
结合注释推测,对传入的columnNames数组有了推测,其应该为select语句查询的字段名,根据本方法的判断逻辑,该数组应该是有三种状态:
null,表示全查
有限个字段名,查这些字段
String[0],表示该语句并非查询语句
因而,我们对该方法有了大致推测:
sql为SQL语句;
escapeProcessing对应是否启用替换处理(待定);
isParameterized对应是否启动参数化;
columnNames为若该sql为select语句时查询的字段名列表;
本方法应为:为该sql语句新建查询键。此处,将自学查询建的知识,对该部分进行补充。
对应判断逻辑为:
若columnNames为null或有值,则新建一个有返回值的查询建。
否则,若启动参数化,则使用该sql语句做查询键,
若未启动参数化,则新建一个Base查询键
总结,该部分的作用为为该sql语句新建查询键,该查询建默认启动参数化。
第四部分
boolean shouldCache = preferQueryMode == PreferQueryMode.EXTENDED_CACHE_EVERYTHING;if (shouldCache) {cachedQuery = queryExecutor.borrowQueryByKey(key);} else {cachedQuery = queryExecutor.createQueryByKey(key);}
该部分的逻辑很容易理解,若该连接指定的查询模式为EXTENDED_CACHE_EVERYTHING,则根据查询键尝试从缓存中获得该查询,否则新建一个查询。
此部分对于该模式的运作不甚了解,猜测应该是在新建的缓存查询是共享的,能根据查询建找到就不要选择新建,不慎了解,不多言,待补充。
通过查看该CachedQuery类的注释可知,其存储解析后的JDBC查询信息,其主要目的在于通过java.sql.Connection#prepareStatement(String)方法多次执行相同查询时,减少解析的开销。
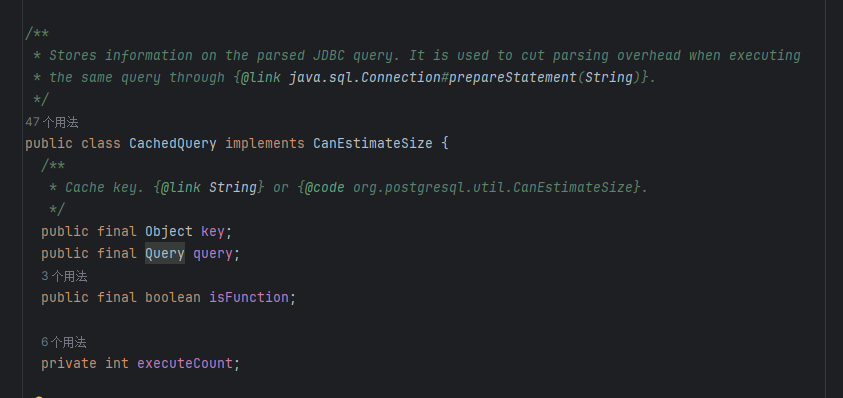
总之,该部分的作用是:根据该查询键获得一个CachedQuery类的实例。
第五部分
if (wantsGeneratedKeysOnce) {SqlCommand sqlCommand = cachedQuery.query.getSqlCommand();wantsGeneratedKeysOnce = sqlCommand != null && sqlCommand.isReturningKeywordPresent();}
wantsGeneratedKeysOnce是PgStatement类的一个属性,其注释说明,其用来标记调用 execute 或 executeUpdate 方法时,调用者是否希望获取这次执行所生成的键。由此描述可知,该属性与执行的sql语句类型有关。
如果当前sql想要获得这次执行所生成的键,则调用cachedQuery.query.getSqlCommand()方法获得sqlCommand,若其非空且包含对应关键词,则更新wantsGeneratedKeysOnce。获得的qlCommand并未在之后的部分使用。
总之,该部分的作用为:更新wantsGeneratedKeysOnce属性。
第六部分
boolean res;try {res = executeWithFlags(cachedQuery, flags);} finally {if (shouldCache) {queryExecutor.releaseQuery(cachedQuery);}}
该部分的主要部分为:res = executeWithFlags(cachedQuery, flags);,很明显该方法为执行查询,但至此我们对flags参数的含义和res的含义未加确定,因而追踪一步:
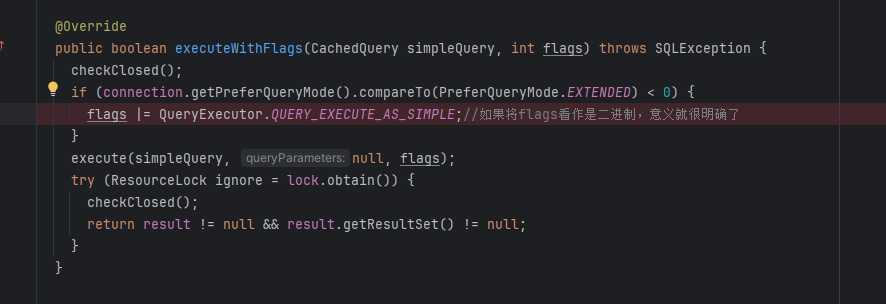
显然在此,flags的实际应用形式为二级制,每一位作为一个标志,每一位都能存储一条二元信息,其可以看作是一个二元数组的形式;res则为指示是否有返回值。因为该方法调用层次过多,故不在此详述
总结,本部分作用为:实现查询,并返回是否有返回结果的判断
总结
参数意义
String sql : sql语句
int flags:一个记录标志信息的二进制数组
String @Nullable [] columnNames :存储查询字段名的数组,如非查询语句,其为String[0],需要注意的是,null代表全体字段名,而不是异常。
结论
本文详细分析了PgStatement的executeCachedSql(String sql, int flags, String @Nullable [] columnNames)方法的作用,但对某些部分方法的并未追踪到底层,拟定另起文章对某些部分的底层方法进行学习分析。
随学随改






![无缝融入,即刻智能[1]:MaxKB知识库问答系统,零编码嵌入第三方业务系统,定制专属智能方案,用户满意度飙升](https://ai-studio-static-online.cdn.bcebos.com/df281e813160472791f441f27125fb0111d6e50251c946a6b823e01f4c29e55c)