1. subprocess模块
1.1 概念
subprocess模块启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值
简单理解:可以远程连接电脑(socket模块)
1.2 Popen方法
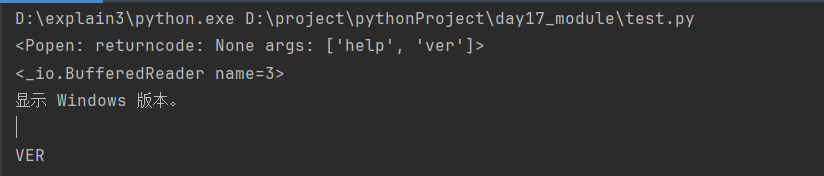
import subprocessres = subprocess.Popen(['help', 'ver'], # windows中执行的命令要放在列表里面,命令单词之间用逗号隔开shell=True, # Windows和Linux都填写Truestdout=subprocess.PIPE, # 存储正确结果的返回值stderr=subprocess.PIPE) # 存储错误结果的返回值
print(res) # <Popen: returncode: None args: ['help']>
print(res.stdout) # <_io.BufferedReader name=3>
print(res.stdout.read().decode('gbk')) # Linux默认编码格式是utf-8,国内Windows默认编码格式是gbk
subprocess模块首先推荐的是run方法,更高级的方法使用Popen接口
1.3 run方法
# run参数的含义
# *popenargs:解包,将命令单词用逗号隔开放列表里 ['cd', '目录']
# timeout:超时时间,执行某个命令,在指定时间内没有执行成功就返回错误信息
# check:如果该参数设置为True,并且进程退出状态码不是0,则弹出CalledProcessError 异常。
# stdout:存储正确结果的管道
# stderr:存储错误结果的管道
# shell:Windows和Linux都填True
# encoding:如果指定了该参数,则 stdin、stdout 和 stderr 可以接收字符串数据,并以该编码方式编码,否则只接收 bytes 类型的数据。
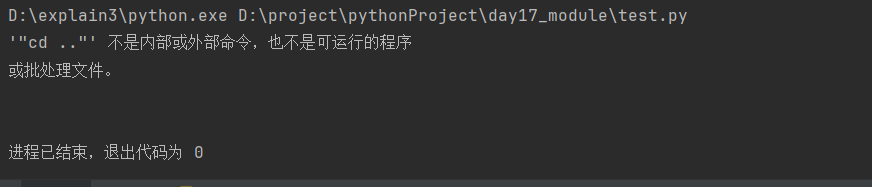
import subprocessres = subprocess.run(["cd .."], # 格式一定为列表形式shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,encoding='gbk'# 如果这里是True就不需要执行上面的stdout和stderr,错误的情况下正常打印错误信息# 如果这里是False程序就会直接报错# capture_output=True
)
print(res.stderr)
1.4 call方法
import os
import subprocessroot_dir = os.path.dirname(os.path.dirname(__file__))
print(root_dir)
subprocess.call('help') # 可以执行简单的命令,不能执行下方复杂的命令
subprocess.call(['dir', 'D:\project\pythonProject'])
subprocess.call(['dir', 'D:\\project\\pythonProject'])
2. 正则表达式re模块
2.1 概念
正则表达式的主要作用是用于检索、替换那些符合某个特定模式的文本。它通过使用特定的字符和字符组合来形成一个“规则字符串”,这个“规则字符串”用来表达对字符串的过滤逻辑,从而实现对文本的模式匹配和操作。
2.2 引入
# 校验手机号是否符合规范
def check_pn(pn):if not pn.isdigit():return '必须是数字'if len(pn) != 11:return '必须11位'if pn[0:2] not in ['13', '14', '15', '16', '17', '18', '19']:return '号段错误'return f'号码:{pn}格式正确'while True:num = input('请输入手机号:')print(check_pn(num))
正则表达式进行格式匹配
import redef check_pn(pn):# ^1是否以1开头,接下来的1位是否位3~9,结尾是否为数字,结尾位数是否为9位pattern = '^1[3456789]\d{9}$'if not re.match(pattern, pn):return '格式不正确'return f'手机号:{pn}格式正确'while True:num = input('请输入手机号:')print(check_pn(num))
2.3 字符组
概念:在同一个位置可能出现的各种字符组成了一个字符组
语法:[ ]
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
|
正则 |
待匹配字符 |
匹配结果 |
说明 |
|
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
|
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
|
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
|
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
|
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
|
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
# findall方法:在指定文本中查找符合正则表达式的内容
import rea = '789'
pattern1 = '[1]' # pattern1 = ['1']这样写会报错
# 去a中查找符合pattern1的内容,有则返回,没有则返回空
print(re.findall(pattern1, a)) # []
b = '123'
pattern2 = '[1]'
print(re.findall(pattern2, b)) # ['1']
c = '666'
pattern3 = '[0-9]' # 匹配0~9的数字
pattern4 = '[0123456789]'
print(re.findall(pattern3, c)) # ['6', '6', '6']
print(re.findall(pattern4, c)) # ['6', '6', '6']
d = '123abcABC'
pattern5 = '[a-z]' # 匹配所有小写字母
print(re.findall(pattern5, d)) # ['a', 'b', 'c']
e = '123abcABC'
pattern6 = '[A-Z]' # 匹配所有大写字母
print(re.findall(pattern6, e)) # ['A', 'B', 'C']
f = '123abcABC'
pattern7 = '[0-9a-zA-Z]' # 匹配大小写字母、数字
print(re.findall(pattern7, f)) # ['1', '2', '3', 'a', 'b', 'c', 'A', 'B', 'C']
2.4 字符组案例
# [ ]匹配字符组中的任意一个字符
# [^ ]匹配除了字符组外的任意一个字符
# ^[ ]匹配以字符组中的任意一个字符开头import rea = '球王和球玉和球土和球欧冠和球'
pattern1 = '球[王和球玉和球土和球欧冠和球]'
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧']
b = '球王和球玉和球土和球欧冠和球'
pattern2 = '球[王和玉和土和欧冠和]*' # *匹配0次或无数次
print(re.findall(pattern2, b)) # ['球王和', '球玉和', '球土和', '球欧冠和', '球']
c = '球王和球玉和球土和球欧冠和球'
pattern3 = '球[^和]'
print(re.findall(pattern3, c)) # ['球王', '球玉', '球土', '球欧']
d = '11aa22bb33'
pattern4 = '\d+' # 匹配数字1次或多次
print(re.findall(pattern4, d)) # ['11', '22', '33']
2.5 元字符
元字符 匹配内容
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配换行符
\t 匹配制表符 是1个tab键,相当于4个空格
\b 匹配单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
import rea = '12 \n ab'
pattern1 = '.' # 匹配换行符外的所有字符
print(re.findall(pattern1, a))
# ['1', '2', ' ', ' ', 'a', 'b'] 空格也能匹配
b = '12_ \n ab_%&*'
pattern2 = '\w' # 匹配字母、数字、下划线
print(re.findall(pattern2, b)) # ['1', '2', '_', 'a', 'b', '_']
c = '12_ \n ab_%&*'
pattern3 = '\s' # 匹配任意的空白符
print(re.findall(pattern3, c)) # [' ', '\n', ' ']
d = '12_ \n ab_%&*'
pattern4 = '\d' # 匹配数字
print(re.findall(pattern4, d)) # ['1', '2']
e = '12_ \n\n \nab_%&*'
pattern5 = '\n' # 匹配换行符
print(re.findall(pattern5, e)) # ['\n', '\n', '\n']
f = '12_ \n\t ab_%&*\t'
pattern6 = '\t' # 匹配制表符(制表符是一个tab键,相当于4个空格)
print(re.findall(pattern6, f)) # ['\t', '\t']
g = 'hello hi how'
pattern7 = "'[how]'\b" # ???匹配单词的结尾
print(re.findall(pattern7, g)) # []
h = '123abc'
pattern8 = '^[0-9]' # 匹配字符串的开始
print(re.findall(pattern8, h)) # ['1']
pattern9 = '^[a-z]'
print(re.findall(pattern9, h)) # []
i = '12_ \n ab_%&@'
pattern10 = '[0-9]$' # 匹配字符串的结尾
print(re.findall(pattern10, i)) # []
pattern11 = '@$'
print(re.findall(pattern11, i)) # ['@']
j = '12_ \n ab_%&*'
pattern12 = '\W' # 匹配非数字、字母、下划线
print(re.findall(pattern12, j)) # [' ', '\n', ' ', '%', '&', '*']
k = '12_ \n ab_%&*'
pattern13 = '\D' # 匹配非数字
print(re.findall(pattern13, k)) # ['_', ' ', '\n', ' ', 'a', 'b', '_', '%', '&', '*']
l = '12_ \n\t ab_%&*\t'
pattern14 = '\S' # 匹配非空白符
print(re.findall(pattern14, l)) # ['1', '2', '_', 'a', 'b', '_', '%', '&', '*']
m = '12_ \n\t ab_%&*\t'
pattern15 = '[0-9]|[a-z]' # a|b,匹配字符a或字符b
print(re.findall(pattern15, m)) # ['1', '2', 'a', 'b']
n = '123456789 \n abcd'
pattern16 = '12([0-9])4' # () 匹配括号内的表达式,也表示一个组
print(re.findall(pattern16, n)) # ['3']
o = '123456789 \n abcd'
pattern17 = '23[0-9][0-9]678' # [...]匹配字符组中的字符
print(re.findall(pattern17, o)) # ['2345678']
pattern18 = '23([0-9][0-9])678'
print(re.findall(pattern18, o)) # ['45']
p = '123456789 \n abcd'
pattern19 = '[^0-9]' # 匹配除了字符组中字符的所有字符
print(re.findall(pattern19, p)) # [' ', '\n', ' ', 'a', 'b', 'c', 'd']
2.6 位置元字符案例
import re# . 表示任意一个字符
a = '球王球玉球土球欧冠'
pattern1 = '球.'
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧']# ^ 以某个字符开头
b = '球王球玉球土球欧冠'
pattern2 = '^球.'
print(re.findall(pattern2, b)) # ['球王']# $ 以某个字符结尾
c = '球王球玉球土球欧冠'
pattern3 = '球.$'
print(re.findall(pattern3, c)) # []
pattern4 = '球..$'
print(re.findall(pattern4, c)) # ['球欧冠']# ^以某个字符开头 \w匹配字母、数字、下划线 {5}重复5次
d = 'city_haaland'
pattern5 = "^\w{5}"
print(re.findall(pattern5, d)) # ['city_']# \w匹配字母、数字、下划线 {5}重复5次 $以某个字符结尾
e = 'leo_messi'
pattern6 = "\w{5}$"
print(re.findall(pattern6, e)) # ['messi']# ^以某个字符开头 \w匹配字母、数字、下划线 {5}重复5次 $以某个字符结尾
f = 'leo_messi'
pattern7 = "^\w{5}$"
print(re.findall(pattern7, f)) # []# 字符串长度必须是5位,以字母、数字、下划线开头,并且以字母、数字、下划线结尾
g = 'messi'
pattern8 = "^\w{5}$"
print(re.findall(pattern8, g)) # ['messi']
2.7 量词
量词 用法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
量词默认是贪婪匹配,尽可能多拿
import rea = '01111123'
pattern1 = '0([0-9]*)23' # *重复0次或更多次
print(re.findall(pattern1, a)) # ['11111']
b = 'aabbbcccc'
pattern2 = 'aa([a-z]+)cccc' # +重复一次或更多次
print(re.findall(pattern2, b)) # ['bbb']
c = '01111123'
pattern3 = '0([0-9]?)23' # ?重复0次或一次
print(re.findall(pattern3, c)) # []
pattern4 = '011111([0-9]?)3'
print(re.findall(pattern4, c)) # ['2']
d = '01111123'
pattern5 = '0([0-9]{5})23' # {n}重复n次
print(re.findall(pattern5, d)) # ['11111']
e = '01111123'
pattern6 = '0([0-9]{3,})23' # {n,}重复n次或更多次 这里最少是3次,包括3
print(re.findall(pattern6, e)) # ['11111']
f = '01111123'
pattern7 = '0([0-9]{2,9})23' # {n,m}重复n到m次 这里最少是2次,包括2,最多是9次
print(re.findall(pattern7, f))
2.8 量词案例
import rea = '球王和球玉和球土和球欧冠和球'
pattern1 = '球.?' # ?匹配0次或1次
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧', '球']
b = '球王和球玉和球土和球欧冠和球'
pattern2 = '球.*' # *匹配0次或无数次
print(re.findall(pattern2, b)) # ['球王和球玉和球土和球欧冠和球']
c = '球王和球玉和球土和球欧冠和球'
pattern3 = '球.+' # +匹配1次或无数次
print(re.findall(pattern3, c)) # ['球王和球玉和球土和球欧冠和球']
d = '球王和球玉和球土和球欧冠和球'
pattern4 = '球.{1}' # {1}匹配指定次数1次
print(re.findall(pattern4, d)) # ['球王', '球玉', '球土', '球欧']
e = '球王和球玉和球土和球欧冠和球'
pattern5 = '球.{1,}' # {1,}匹配1次或更多次
print(re.findall(pattern5, e)) # ['球王和球玉和球土和球欧冠和球']
f = '球王和球玉和球土和球欧冠和球'
pattern6 = '球.{1,3}' # {1,3}匹配1到3次,尽可能多拿
print(re.findall(pattern6, f)) # ['球王和球', '球土和球']