最近遇到一家客户的Oracle数据库,版本是11g,字符集是US7ASCII,当使用PL/SQL Developer工具插入和查询中文时都没问题,但是Java程序使用JDBC插入和查询中文时,中文乱码。
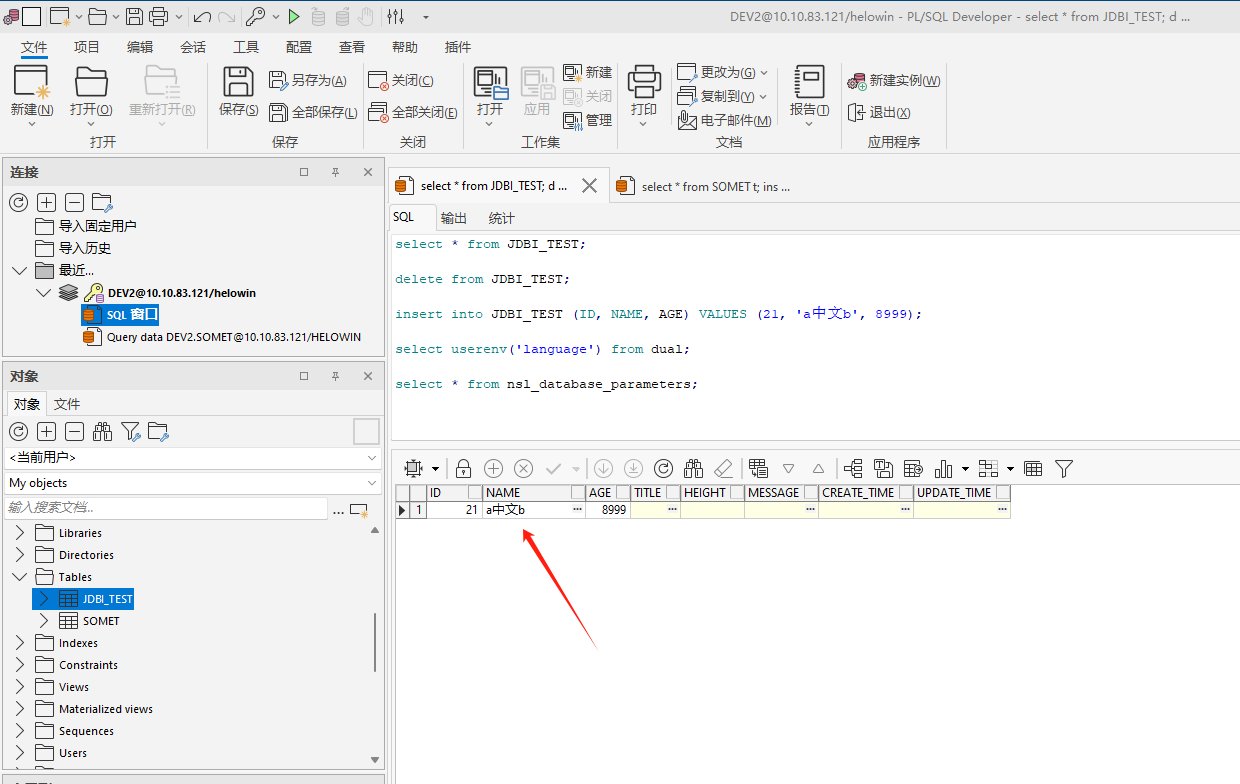
比如'a中文b'通过JDBC查询出来的乱码是这样的'aᅱᅫᅣb'

查询了一些资料,看到有网友通过这种方式解决了(只列出关键代码)。但是这个方法对于我的环境没有效果。
Properties properties = new Properties();properties.setProperty("serverEncoding","ISO-8859-1");properties.setProperty("clientEncoding","GBK");String DBURL = "jdbc:wrap-jdbc:filters=encoding:jdbc:oracle:thin:@//100.100.100.100:1521/helowin";
理论上来说,US7ASCII是不能保存中文的,因为ASCII编码一个字符只占用一个字节,即8位,而且首位是0. 但是看PL/SQL Developer的确把中文查出来了,挺让人疑惑的(后面想可能是因为PL/SQL用的胖客户端,做了某些处理,而JDBC用的是瘦客户端)。
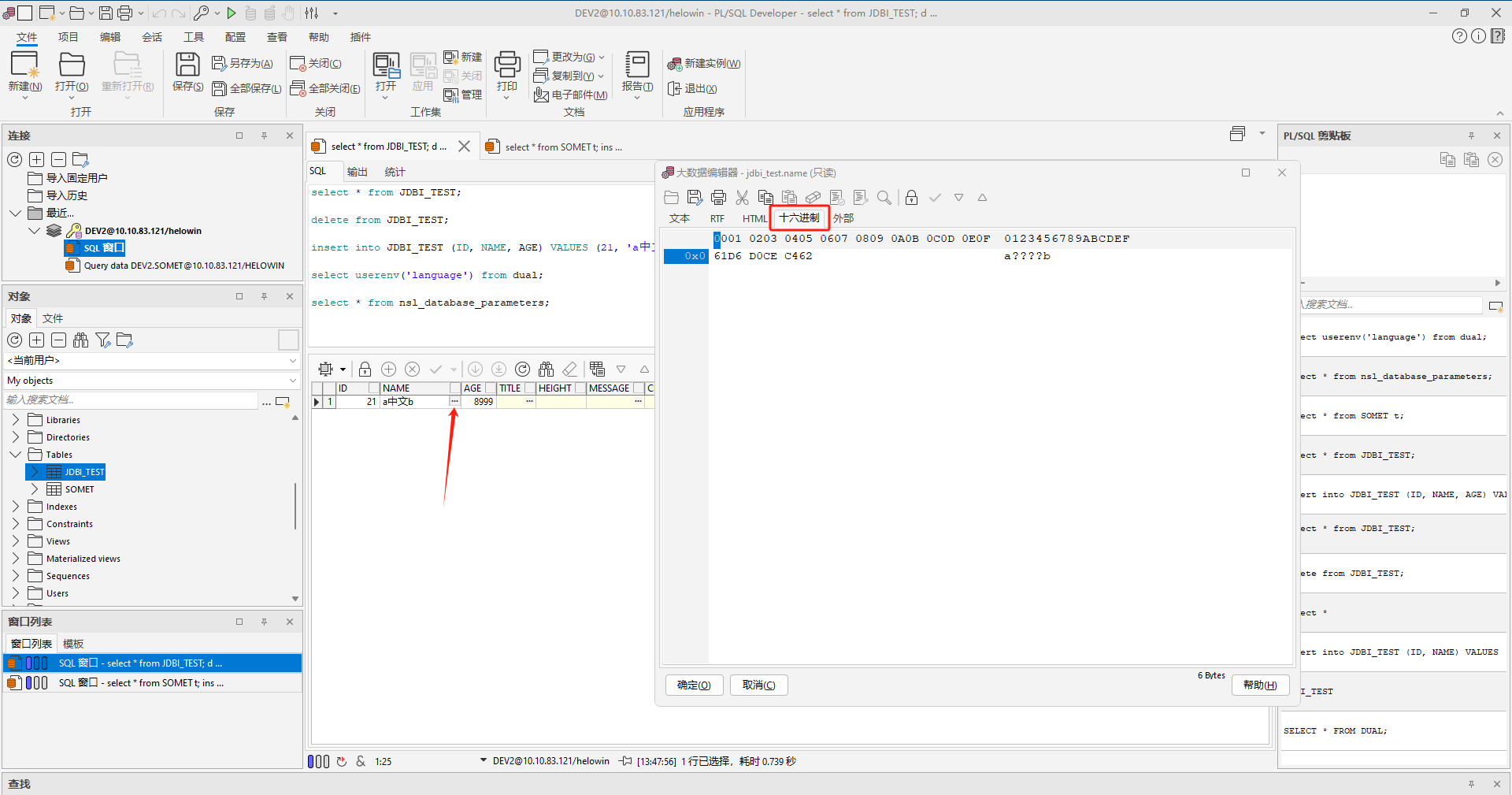
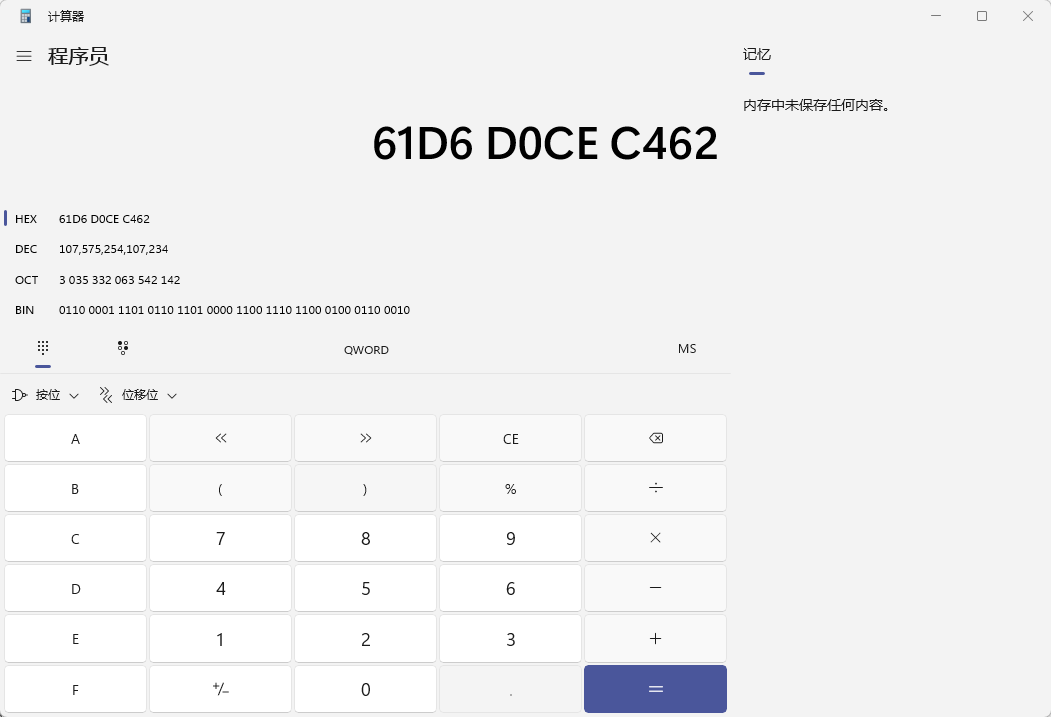
通过查看16进制,我们可以看到,数据是这样保存的,再用计算器算一下,我们可以看到,每个中文其实占用了两字节,每个字母占用了1字节,而且中文字节是1开头,挺像GBK编码方式的。
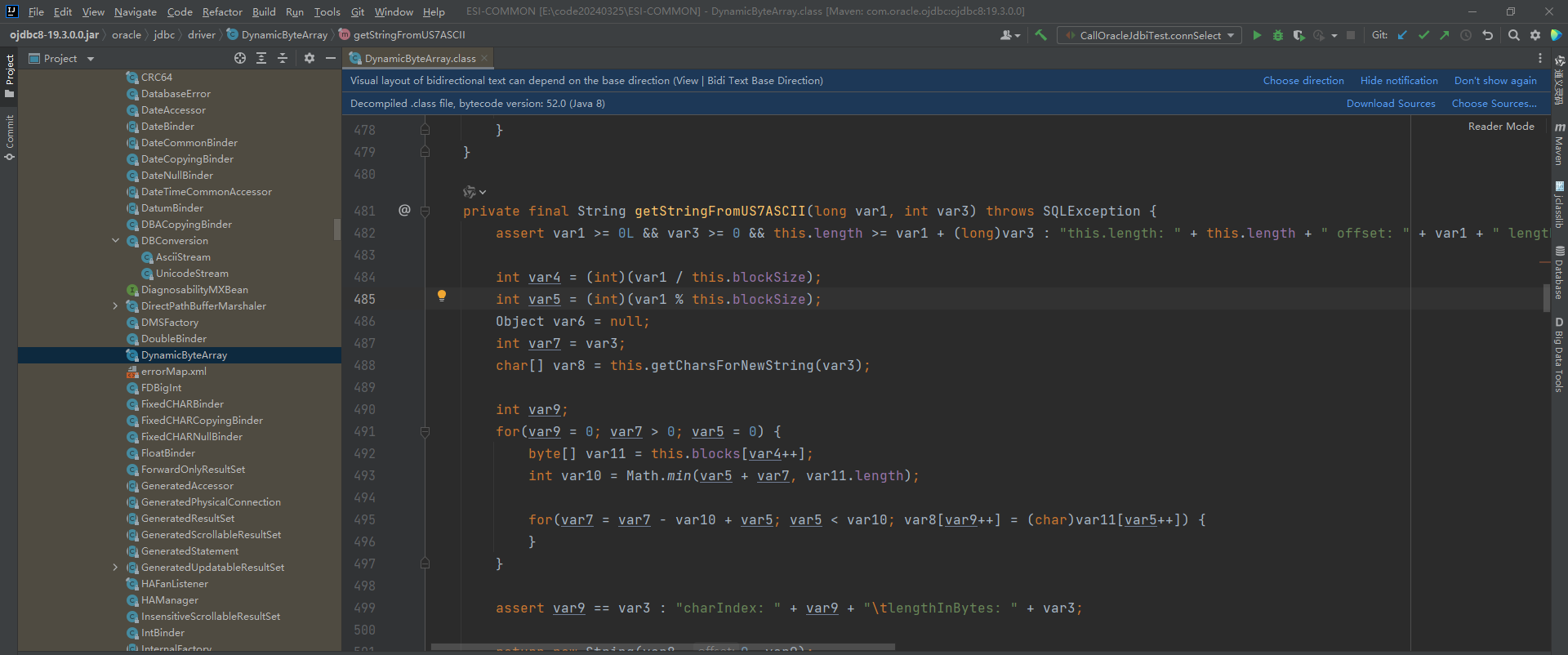
而Oracle驱动中,如果采用ResultSet的getString方法来获取值,会走到这么一段代码中去,这段代码获取到的char[]其实把每个中文拆分成了两个字符去处理,所以得到的结果是乱码,而且乱码部分的字符数是中文数的两倍。
经过测试发现采用ResultSet的getBytes(int columnIndex)方法先得到byte数组,再用new String转GBK可以得到正常的中文。
最终我的解决方法:
插入数据时,对可能存在中文的值进行一次转码
String newName = new String(textValue.getBytes("GBK"), "ISO-8859-1");
查询数据时,对于VARCHAR2和CHAR类型的列,从ResultSet中获取值时先用getBytes(int columnIndex)方法,然后再用new String(byte bytes[], String charsetName) 转为GBK
以下是我对NAME字段进行处理的例子。
private Connection getOracleConnection() throws Exception {Class.forName("oracle.jdbc.OracleDriver");Properties properties = new Properties();properties.setProperty("user", "YourUser");properties.setProperty("password", "YourPassword");String url = "jdbc:oracle:thin:@//100.100.100.100:1521/helowin";return DriverManager.getConnection(url,properties);}@Testpublic void connSelect() throws Exception {Connection connection = getOracleConnection();PreparedStatement preparedStatement = connection.prepareStatement("select * from JDBI_TEST");ResultSet resultSet = preparedStatement.executeQuery();if (resultSet == null) {return;}ResultSetMetaData metaData = resultSet.getMetaData();int columnCount = metaData.getColumnCount();List<Map<String, Object>> list = new ArrayList<>();while (resultSet.next()) {Map<String, Object> map = new HashMap<>();for (int i = 0; i < columnCount; i++) {String columnName = metaData.getColumnName(i + 1);if (!"NAME".equals(columnName)) {continue;}byte[] bytes = resultSet.getBytes(i + 1);map.put(columnName, bytes);}list.add(map);}list.forEach(map -> {Object name = map.get("NAME");try {logger.info("name: {}, {}", Arrays.toString((byte[]) name), new String((byte[]) name, "GBK"));} catch (UnsupportedEncodingException e) {e.printStackTrace();}});}