方便管理,主要是想熟悉下git的操作
先创建并且切换到一个新的分支:
git commit --allow-empty -am "before starting PA1"
git checkout -b PA1
其中--allow-empty表示允许提交一个空的提交,git默认是不能提交一个空的提交信息,如果当前的文档没有什么修改,那么就是不能提交的,但是加上了这一行信息之后就可以提交了
-am:分为2个参数-a表示自动暂存所有所有已经跟踪的文件的更改
在git status之后
显示以下信息:
zzhi@zzhi:~/NEMU2021$ git status On branch master Your branch is ahead of 'origin/master' by 6 commits. (use "git push" to publish your local commits)nothing to commit, working tree clean这句话是 Git 命令
git status输出,用于显示当前分支的状态。它提供了有关当前分支和远程分支的同步状态的信息。具体的含义如下:
On branch master:
- 你当前所在的分支是
master。这表示你正在master分支上工作。Your branch is ahead of 'origin/master' by 6 commits:
- 你的本地
master分支比远程origin/master分支领先 6 个提交。也就是说,你在本地master分支上有 6 个提交,这些提交还没有推送到远程仓库的master分支。- 这些提交可能是在本地进行了新的工作或修改,而这些修改尚未同步到远程仓库。
(use "git push" to publish your local commits):
- 你可以使用
git push命令将本地master分支上的提交推送到远程仓库,以使远程的master分支也包含这些提交。- 这条提示建议你使用
git push将本地的更改更新到远程仓库,以保持远程仓库的内容与本地同步
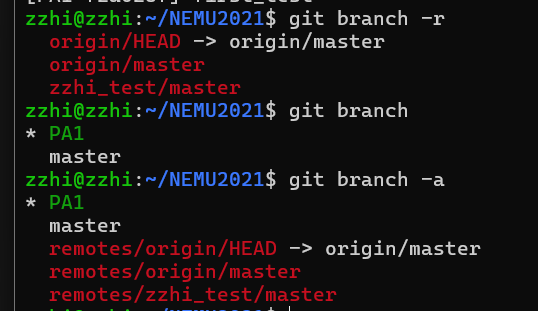
在 Git 中,分支是平行的,没有严格的“分支下有分支”的结构。每个分支都是独立的,并且都从某一个提交(commit)开始,可以从任意其他分支派生出来。
平行分支
- 概念:当你创建一个新分支时,它相对于其他分支是平行的。所有分支都是平行的,可以独立发展。Git 以分布式方式工作,每个分支都有自己独立的提交历史。
- 操作:你可以在任意一个分支上创建一个新的分支,并且新分支和源分支是平行的,它们可以各自进行独立的开发,直到你选择将它们合并。
创建新分支的示例
假设你有一个
master分支,并从它创建了两个新的分支feature-A和feature-B:git checkout -b feature-A master git checkout -b feature-B master在这个例子中,
feature-A和feature-B都是从master分支派生出来的,但是它们彼此是平行的,互不影响。分支的独立性
每个分支都可以有自己的提交历史,可以从不同的点开始。即使它们是从同一个起点(比如
master)分出来的,一旦开始开发,两个分支的内容就会逐渐不同。你可以在需要时将这些分支合并到一起,也可以将一个分支重新派生出新的分支。分支结构的灵活性
Git 的分支模型非常灵活,你可以随时从任何分支创建新分支。即使从某个分支上创建了新分支,它们依然是平行的,而不是嵌套的。
示例:从
feature-A创建feature-A1你可以在
feature-A上再创建一个新分支feature-A1:git checkout -b feature-A1 feature-A尽管
feature-A1是从feature-A分出来的,但它依然是平行的。这意味着你可以独立地操作feature-A和feature-A1,它们的关系仅仅是feature-A1继承了feature-A的历史。总结
Git 中的分支都是平行的,彼此之间没有严格的层级结构。你可以从任何分支派生出新的分支,Git 会记录这些分支的共同历史,但从逻辑结构上,它们都是平行的,不存在“分支下有分支”的层级关系。
要将 Git 库的一个分支上传到云端(远程仓库)的另一个分支,可以按照以下步骤进行:
1. 确保分支最新
确保你要上传的分支是最新的,拉取最新的更改:
git checkout 你想要上传的本地分支名 git pull origin 本地分支名例如,如果你要上传的是
feature-branch:git checkout feature-branch git pull origin feature-branch2. 推送到远程的另一个分支
使用
git push命令将当前分支推送到远程仓库的另一个分支。你可以通过以下命令实现:git push origin 本地分支名:远程分支名例如,如果你想将本地的
feature-branch分支推送到远程的another-branch分支,可以使用:git push origin feature-branch:another-branch这个命令的意思是:将本地的
feature-branch分支的内容推送到远程仓库的another-branch分支。如果another-branch不存在,Git 会在远程仓库中创建它。3. 检查推送结果
你可以通过以下命令查看远程分支的状态,确保推送成功:
git branch -r这将列出所有远程仓库的分支,你应该可以看到
another-branch已经存在。4. (可选)设置远程跟踪分支
如果你希望在将来继续从本地的
feature-branch推送到远程的another-branch,可以设置远程跟踪分支:git branch --set-upstream-to=origin/another-branch feature-branch这样,在未来推送时,你只需运行
git push,而无需每次都指定远程分支。总结
以上步骤将帮助你将一个本地分支的内容上传到远程仓库的另一个分支。如果远程分支不存在,Git 会自动创建它。这个方法适用于将代码从一个分支迁移到另一个分支,或在不同分支之间进行同步。
NEMU概述
对于一般的应用程序而言,假如没有虚拟机的参与,则是操作系统直接运行在计算机硬件上,对计算机底层的硬件进行了抽象,向上为用户的程序提供了接口和服务。当运行这些应用程序的时候就需要使用这些接口
总的来说:程序不是直接运行在硬件系统之上的,而是在操作系统之上
对于虚拟机nemu来说,nemu是运行在机器操作系统之上的软件,它模拟了虚拟的计算机硬件。
红白机游戏是比较特殊的存在,在红白机之中是直接运行在红白机硬件上的,在nemu中,nemu只是模拟了一个硬件系统,本身在这个虚拟的硬件系统再没有更多的操作系统,红白机游戏就是直接运行在这个nemu模拟出来的硬件系统之上的
关于实现
把计算机看做成为一个由若干的硬件部件组成的,每一个硬件部件都是由一个c语言的数据对象来模拟,
其实就只是某种数据结构,仅仅是模拟硬件的话感觉并不会很难,感觉只是传统的大模拟
阅读源代码
对于计算机硬件系统模拟的主体就只是在nemu目录中
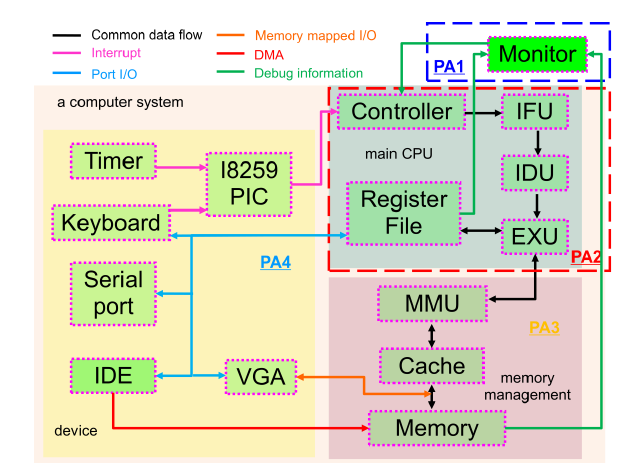
首先关于这一张图片,因为上学期的计算机系统基础说实话学的一点都不好,一定会回来补的(!!!!!
4个关键部分:设备device、储存管理memory management、main cpu、monitor

配置了一下ctags之后感觉vim要比vscode好用了
可以在函数和变量之间跳转,这样就能看到每一步分别是怎么样子的,感觉好好用
8.27
20:00

这一步是在初始化monitor,
在一路跳转init_log的时候看到有很多的参数都是叫做argc和argc
在计算机编程中,特别是在使用C和C++语言时,
argc和argv是用于处理命令行参数的两个参数,它们通常出现在main函数的定义中:int main(int argc, char *argv[]) {// Your code here }
argc
全称: Argument Count
含义:
argc表示传递给程序的命令行参数的个数。包括程序本身的名称在内。比如,如果你在命令行中运行以下命令:./my_program arg1 arg2那么
argc的值将是 3,因为命令行参数包括./my_program(程序名称)、arg1和arg2。
argv
- 全称: Argument Vector
- 含义:
argv是一个指向字符串数组的指针,每个元素都是一个C字符串(即一个字符指针)。这些字符串就是传递给程序的命令行参数。具体地说,argv[0]是程序的名称,argv[1]是第一个命令行参数,argv[2]是第二个参数,依此类推。如果没有提供命令行参数,argv数组中的元素就是程序的名称,而argv[1]及其后面的元素为NULL。示例代码
#include <iostream>int main(int argc, char *argv[]) {std::cout << "Number of arguments: " << argc << std::endl;for(int i = 0; i < argc; ++i) {std::cout << "Argument " << i << ": " << argv[i] << std::endl;}return 0; }示例输出
假设编译后的程序名为
my_program,并在命令行中运行以下命令:./my_program hello world输出将是:
Number of arguments: 3 Argument 0: ./my_program Argument 1: hello Argument 2: world在这个例子中,
argc的值是 3,argv是一个包含三个字符串的数组。总结
argc是命令行参数的个数。argv是一个字符串数组,存储了所有的命令行参数。
知道了argc和argv的作用,还会注意到argv是一个指针类型
想能跳转到argv,但是提示tags not found ,可能是ctags的时候有问题,但是我现在已经花了很长时间去处理工具熟悉操作已经不想干那些了,现在还是想能好好的阅读下代码
想起手册中的不要太注意细节,想想也是我也看不懂,但是作者本意应该不是这个意思,但是殊途同归,决定先看看妖完成的具体的任务
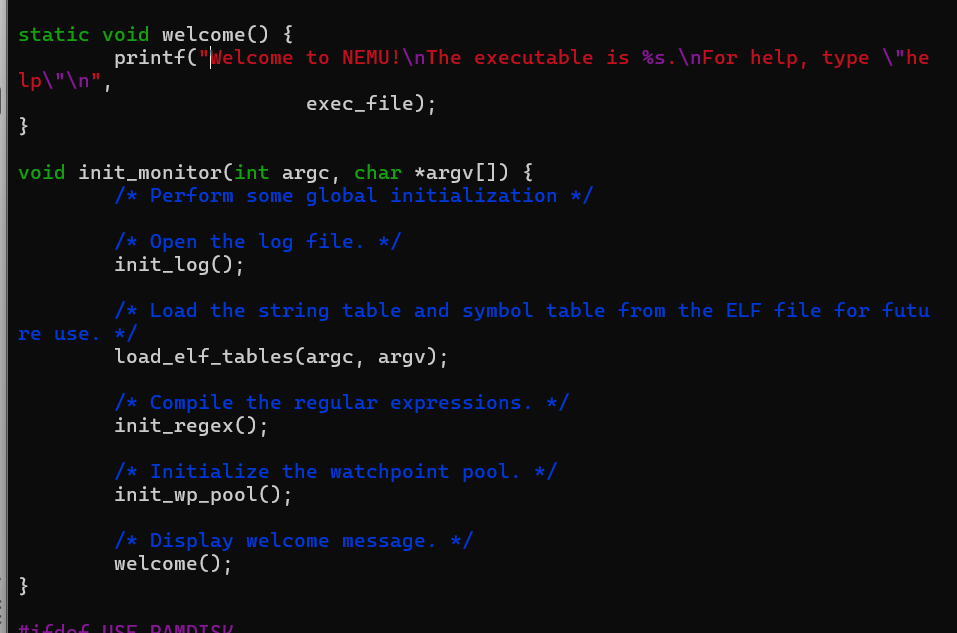
init_monitor
init monitor中的这个welcome绝对是我看的最清楚的一段代码了orz
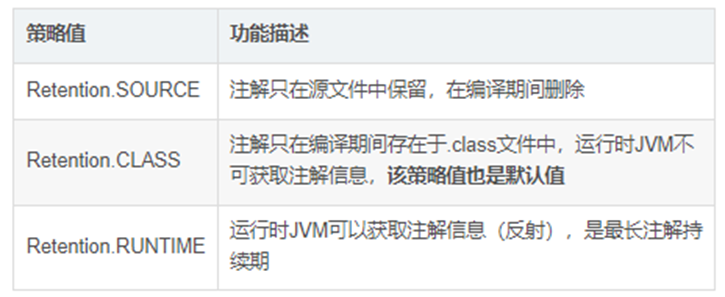
关于符号表和符号串表,是ELF文件的格式,说了自己学的不好,等稍微浏览一遍之后就开始学这部分内容,之后再专门贴上我学习的笔记链接
关于第一行是要打开log文件,什么是log文件我怎么可能会懂。尝试跳转看下,就是打开了一个log文件然后基本上是看起来像c++的文件输入输出(雾
多半是什么记录日志,什么乱七八糟的不管了
接下来是要使用elf文件的时候要加载它的字符串表和符号表,是使用elf文件的最初的操作
编译正则表达式+初始化监视点池。不懂
可以看到,只有这一个函数用到了argv和argu的参数,在其内部也就只有加载这个elf的时候使用到了这些参数,关于elf的内容说不定还是需要好好研究下
应该是记录更基本的初始过程的文件。
reg_test
测试寄存器结构,我已经改过了
在代码中有很多的条件编译的代码,但是我看不懂
没使用过,何来看的懂,但是有学长在写acm的板子题的时候就在用了这种东西,之后也要学下。
什么乱七八糟的
直接甩给gpt(
assert是一个用于调试的宏,用来验证程序在运行时的某些条件是否为真。它通常用于确保程序状态的正确性,当某些假设或条件在运行时不成立时,assert会触发错误,通常是终止程序并输出错误信息。工作机制
在你给出的代码中,
assert的定义如下:#define assert(cond) \ do { \if(!(cond)) { \panic("Assertion failed: %s", #cond); \} \ } while(0)这个宏的工作方式如下:
cond:assert的参数cond是一个条件表达式。- 检查条件:
if(!(cond))检查条件表达式cond是否为false(即条件不满足)。- 触发错误: 如果条件不满足,调用
panic函数,输出一条错误消息并终止程序。#cond使用了 C 语言的预处理器特性,将cond表达式转换为字符串形式,以便在错误消息中显示具体的条件内容。例子
假设你有以下代码:
int x = 5; assert(x == 10);在运行时,如果
x不等于10,assert将调用panic,输出错误信息,例如:Assertion failed: x == 10用途
- 调试阶段:
assert通常在调试阶段使用,用来捕获意外的程序状态。- 防御性编程: 通过
assert,开发者可以在关键位置检查程序的状态,防止潜在的逻辑错误在代码运行时蔓延。在生产环境中的使用
在生产环境中,有时会禁用
assert(通常通过定义NDEBUG),以避免因非致命的断言失败而导致程序崩溃。禁用assert可以通过在编译时定义NDEBUG宏:#define NDEBUG #include <assert.h>这样,所有的
assert语句将被编译器忽略。在你的代码中,
panic函数显然用于处理断言失败的情况。具体的panic函数的实现应该会终止程序,并输出类似assert的错误信息。
可以看到,Assert就只是一个用来判断程序有没有正确运行,然后利用了c语言的特性,把判断错误的条件返回出来了,这个特性感觉还是很好用的,调用的panic是什么东西还是不太重要
回头看代码

在这一段代码中,可以比较简单的看清楚
关注到是一直在跑随机数
首先是对cpu.eip和sample跑了相同的随机数,对于eip寄存器(记录当前要处理的指令的内存地址)
但是查看了之前的函数没有发现会改变eip寄存器数值的地方
不知道是为什么还要再检验
可能是开发过程中的事情吧
然后对于其他的代码,reg相关的函数

实际上就是从中取出了想要的位数

没在去查enum是什么意思,但是应该就是赋值了连续的自然数,在for循环中一直在对sample的数组赋值,其中也在验证reg取出的位数是不是正确的,for循环结束之后就开始验证寄存器的结构
这些
enum定义了寄存器的标识符,通常用于处理器模拟器或低级系统编程中,以便于在代码中引用寄存器。每个enum列表中包含了一组与 x86 架构相关的寄存器的标识符,用于在程序中对寄存器进行操作
还是比较清晰的
期间我按到了ctrl + z,强制退出了,
会有一些问题,只要输入
fg就能再打开,正常退出之后就好了
注意到

在 x86 架构中,CPU 的寄存器结构可以根据指令的编码格式组织。为了使寄存器访问更符合 x86 指令格式,你可以重新组织
CPU_state结构体,并使用union来实现寄存器的不同视图。这样可以方便地访问寄存器的不同部分(例如,字节、字或双字)。寄存器结构组织
在 x86 架构中,通用寄存器(GPRs)如
eax、ebx等可以被视为不同的部分:
- 32-bit:
eax,ebx,ecx,edx,esp,ebp,esi,edi- 16-bit:
ax,bx,cx,dx(通过高 8 位和低 8 位的部分访问)- 8-bit:
al,ah,bl,bh,cl,ch,dl,dh
到这个程度差不多了,先继续吧
retart
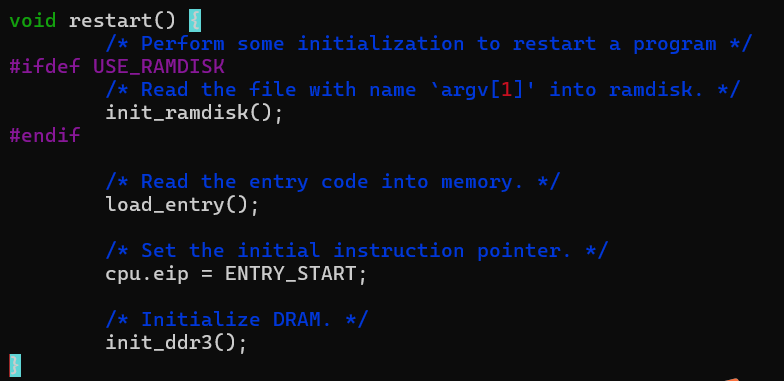


在完整的计算机中,程序的可执行文件应该放在磁盘中
但是nemu没有磁盘,就是把内存开始的位置附近的一段区间当做是磁盘,这样的磁盘的名称是ramdisk
当前的ramdisk只是用于存放要在nemu中运行的程序的可执行文件,这个文件是运行nemu的一个参数
这个init是把这个文件从真实的磁盘中读入到了ramdisk
操作手册真的说的很好,不用再研究了,直接读就好了,死的很安心(
entry
rom ram bios
是这一部分的关键词了
真实计算机启动之后会把控制权交给bios然后由bios进行初始化工作之后把磁盘中的有意义的程序读入到内存中执行
代码还是看不太懂,好烦,时间好少
不知道为什么有点破防了,耻辱下班(!








![[COCI2013] hiperprostor 题解](https://cdn.luogu.com.cn/upload/image_hosting/yryh388w.png)