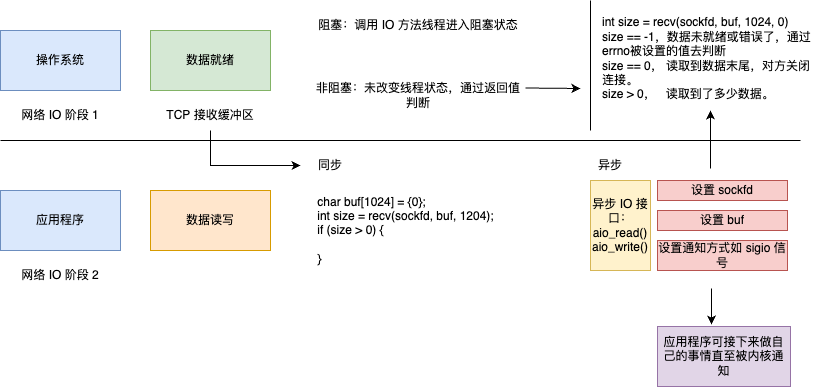
CrossEntropy Loss 计算过程全分析
- 前提条件:分类标签labels和模型输出结果outputs = model(inputs)

- outputs为一个未经过 softmax 的 logits 向量 𝑧 = [𝑧1, 𝑧2, …, 𝑧C],对应每个类别 𝐶 的原始分数。e.g.,二分类问题,有两个原始分数(𝐶 等于2):
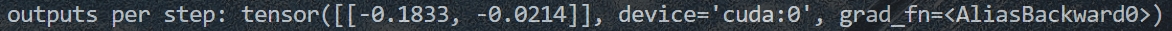
- 利用Softmax将outputs包含的所有原始分数转成一串概率分布:
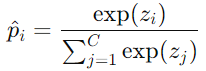
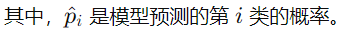
FYI: e指数的结果始终为正;根据公式也能看出来,每个类别的概率介于0,1之间,所有类别的概率加一起为1。
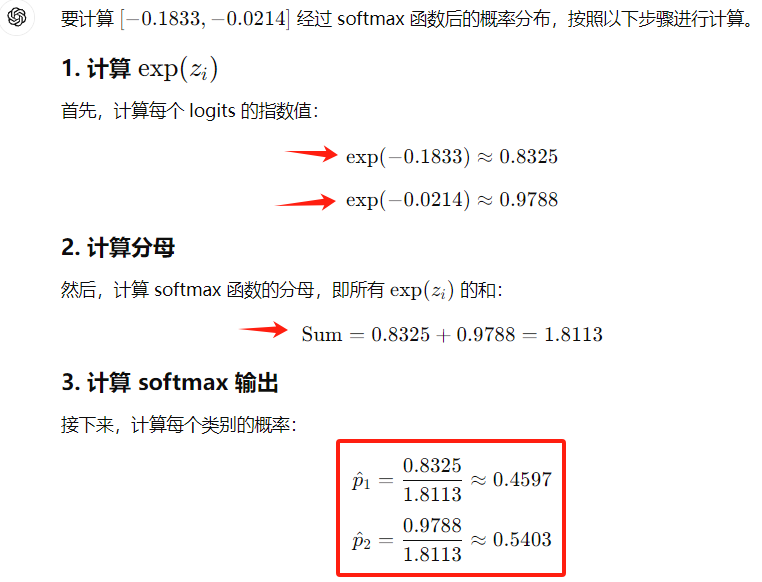
举例说明:
- 利用one-hot编码将labels转成跟预测概率长度相等的向量,e.g.,label为1,经过one-hot编码之后为[0, 1]。
FYI: Pytorch里面计算CrossEntropyLoss时,这个步骤自动执行。 - 仅考虑正确类别对应的预测概率(即 one-hot labels [0, 1]中的1对应的预测概率,于是下图的p值等于0.5403),并取其对数的负值,最终的交叉熵损失为:
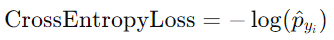
具体计算为:

⭐特别地,对于 batch size 大于1的情况,Pytorch在计算过程中会帮我们求平均:
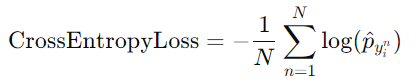
练习:outputs为[[-0.0464, -0.0268], [-0.0234, -0.0091]],labels为[0, 1],请给我计算最终的交叉熵损失。