一、遇到问题时,处理过程
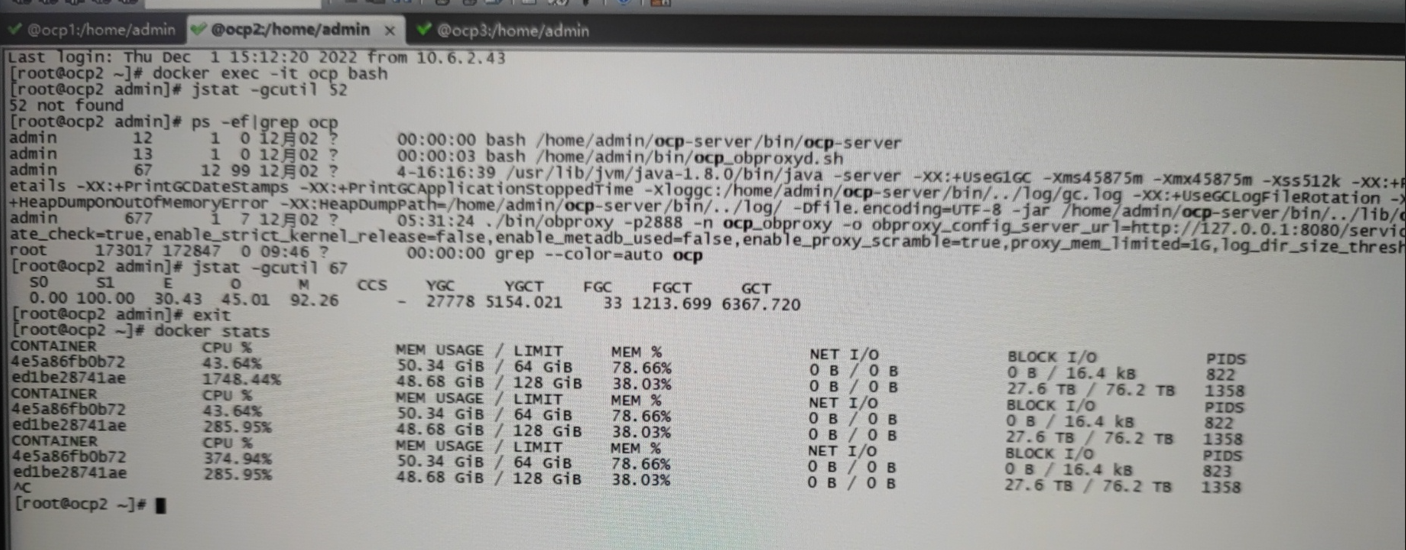
关于调整ocp-server的jvm大小解释:1、在docker容器内设置export JVM_HEAP_SIZE=xxxx,然后重启对应的ocp-server进程(/home/admin/ocp-server/bin/ocp-server),注意这里的大小不要超过docker容器的大小上限。2、在调整完ocp容器的内存大小之后(docker update --memory=60g <container_id_or_name>),重启ocp容器,容器内的ocp-server进程的jvm大小也会跟着变化,这个原因还是因为/home/admin/ocp-server/bin/ocp-server这个问题里面这个文件定义了ocp-server启动时的大小,如果变量JVM_HEAP_SIZE没有设置的话,它是根据当前系统可用内存的7/10来分配。docker ps docker stats查看容器内存CPU使用情况: docker stats【1】 、ocp不定期自动挂掉-fgc问题 处理情况1============================================【处理】:修改缓冲池资源的先添加ocp 容器的内存资源, docker update --memory 36G --memory-swap -1 {CONTAINER_ID}, 现在是20G ,可以先加到36G, 然后在 ocp_meta租户的ocp库 里面执行下这个 sql,replace into config_properties(`key`, value) values ('ocp.alarm.detect.executor.core_pool_size', 10) ,('ocp.alarm.detect.executor.max_pool_size', 20); 加资源三个节点都要加,然后再重启下ocp ,我们再观察下。 麻烦再把 ocp docker 里/home/admin/logs/ocp , gc开头的日志拿一下有空可以到 ocp 的容器里切换到 admin 用户再执行下 jstat -gcutil <ocp-server-pid> 看下 FGC FGC如果是0那就没有什么问题,如果还是有数值,麻烦再联系下我们,1、 ocp 的容器里切换到 admin 用户再执行下 jstat -gcutil <ocp-server-pid> 看下 FGC [19613 是OCP的进程ID的意思] ps -ef | grep ocp jstat -gcutil 19613 stats 看下延迟的store是否有gc,oms docker里 jstat -gcutil `ps -ef | grep storexxxx | grep java | awk '{print $2}'` 3000原因分析: 客户环境: ocp_monitor租户 4c16g,这个设置偏小, 影响的主要是内存,CPU 应该对 OCP 的影响不太大,可以看下容器的 load top 里面就有:机器的 load1、load5、load15 ,哪个进程占用大的内存。 尝试 meta 集群需要加资源, 尝试 ocp上调整unit资源是不是可以解决问题。工单总结: 1、增加客户OCP内存由20G ——> 36G ,OCP资源观察很多天相对运行稳定。 2、增加cpu的话从8c增加16C,并且 OCP 扩大 64G 后重启 java 进程。 3、建议暂时把awr功能关了,待下个版本修复。这个不确定具体时间,研发老师现在规划还没完整的出来 如果开启awr会导致fcg,那这可能还需要优化,可以建议关掉这个功能,等后续版本优化好了再升级ocp,打开对应功能。目前,客户环境负载较高,未发生故障和告警,运行稳定但是未能根本解决问题,1是客户增大资源配置,2是等新版解决BUG升级。问题就是增加租户副本的时候会卡住并失败,重试才能成功,我怀疑是不是监控采集太频繁导致FGC让任务失败,具体的麻烦帮忙看一下在 metadb 里执行下这个 sql ,里面可以查下管理的规模 select count(1) from ob_cluster; select count(1) from ob_tenant; select count(1) from compute_host;select * from task_definition where name = 'Collect cluster snapshot' select `key`, value from config_properties where `key` like '%ocp.alarm.detect.executor%';ocp-server 的容器配置需要看下容器的信息,或者你在镜像里面执行下 ps -ef | grep java replace into config_properties(`key`, value) values ('ocp.alarm.detect.executor.core_pool_size', 20) ,('ocp.alarm.detect.executor.max_pool_size', 30);执行下这个 sql,然后挨个重启下 ocp 的镜像,之后再观察下是否还有 fgc 吧【2】 、ocp不定期自动挂掉-fgc问题 处理情况2============================================ 处理办法: 1、ocp-server 的容器配置需要看下容器的信息,执行下 ps -ef | grep java ,再进入容器中,运行:jstat -gcutil <pid> ,pid 就是 java 的进程,观察 fgc 使用情况是否很高。 2、看下 ocp-server 的资源分配了多少,管理了多少集群、租户、主机规模 metadb 下执行以下sql:select count(1) from ob_cluster; select count(1) from ob_tenant; select count(1) from compute_host; select * from task_definition where name = 'Collect cluster snapshot' select `key`, value from config_properties where `key` like '%ocp.alarm.detect.executor%';修改执行下这个 sql,将两个参数再调小: replace into config_properties(`key`, value) values ('ocp.alarm.detect.executor.core_pool_size', 20) ,('ocp.alarm.detect.executor.max_pool_size', 30);然后重启下各个 ocp 的镜像,之后再观察下是否还有 fgc 原因: OCP有些任务比较消耗资源,告警每分钟会并发 100 (默认值)个线程查询监控数据,将两个参数再调小观察验证: root@ocp_metna use ocp metadb执行 select count(1) from ocp_exporter_address where status='inactive'; select count(1) from ocp_exporter_address where status='active'; 点击一下右上角的实时按钮,看OCP界面是否有数据
二、再说,故障现象
现象1:

现象2: