背景
最近时不时收到 K8S 告警提示项目 POD 出现 OOM 问题,只要触发了项目重新部署或者把 POD 删掉,内存就恢复了,过了一段时间才缓慢增长(基本上要隔几天,这也是这个问题比较难定位和复现的原因)
分析
起初以为是某一个SQL没有限制 limit 或者是程序有死循环把内存跑满了,后面从日志看到这个错误,check_worker_exit_status,同时对应的 worker 进程异常退出了,可以看到这里有记录对应的进程 ID,记住这个 PID,后面发挥很大的作用。

思路一
本想着以前也改过几个内存泄露的问题,这次估计也是大同小异(后面发现是我想多了),先揪着代码的 while(true) 死循环研究,确实发现了一些不合理的点,同时也把引用的变量这一块给梳理了一遍,提交了第一版代码,原本以为能顺利解决,可过一天后告警还是出现了。。。
思路二
换个思路继续研究这个问题,会不会是某个上传文件接口把内存打满了,不过后面看了以下 server.php 的配置,基本上可以 pass 这个情况了
思路三
会不会是某个大的 SQL 查询把内存打满了?既然我有错误日志,我就顺着错误日志的上下文开始排查,但是发现即使打印了日志,无奈开了几个 worker,导致无法分析日志都是哪个 worker 打印的,随即给日志加上 worker 进程 ID,方便后续观察问题。发现后面加上之后,是可以看到 worker 进程最后执行的 SQL,但是自己查了下 SQL,也没发现什么异常点
思路四
观察到报错的时候,worker 进行的 ID 已经飙到 78万了,这个一开始真的还没怎么留意,后面还观察到每次出现这个报错的时间点,又恰恰是整点前后的时间,心里差不多已经有答案了,大概率是定时任务出现问题了!
由于当时也尝试过本地复现,无奈本地的环境变量一直把定时任务关了,导致没怎么留意这一块,不过也好,总算有突破口,开干!
复现
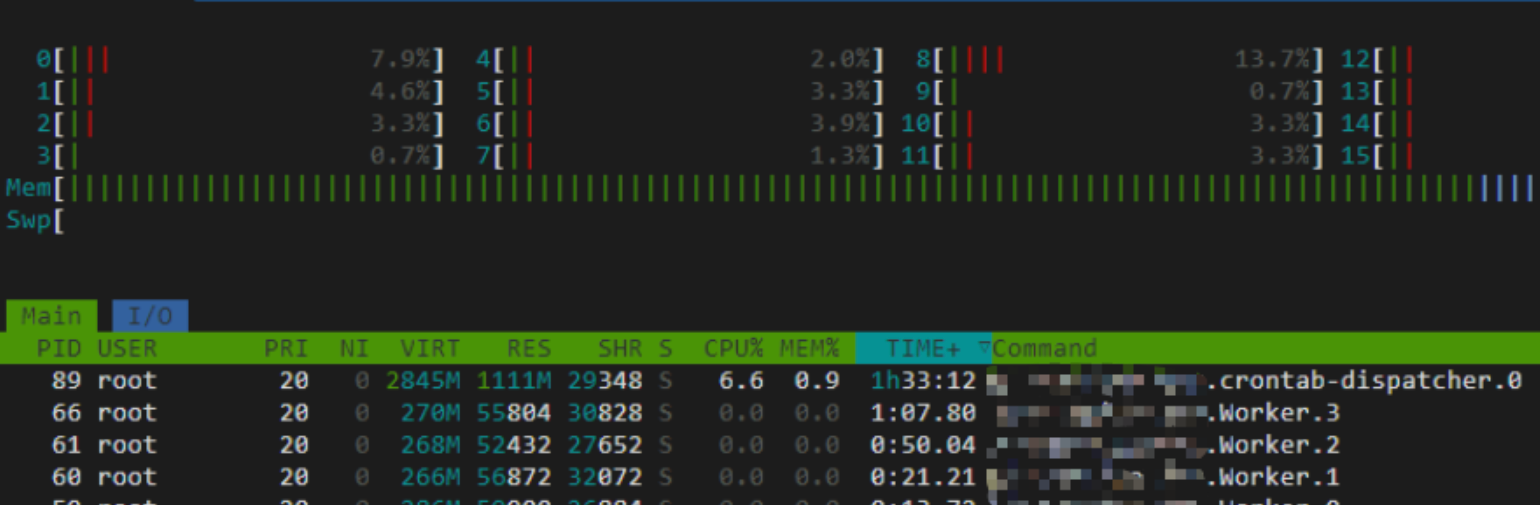
观察到代码有几个定时任务,且是分钟级别的,由于这个复现比较麻烦,且要等很长一段时间,随即把本地的定时任务改成秒级,即每秒跑一次,同时为了方便数据观察,把本地的 worker 数量调整为 1,进入容器开始观察内存的变化情况,跑了 15 分钟左右,发现 worker 进程(PID=22)的内存大幅增长,已经增加到 462M 了,1 个小时后甚至到了 806M



不过有个新的疑惑,发现开启定时任务后,有两个进程,一个是普通的 worker 进程,一个是 crontab-dispatcher 进程,一开始没想这么多,以为是定时任务的进程把任务分发给 worker 进程执行,到这里以为是框架的问题,因为自己的定时任务的配置都是按照文档里面的说明来的,理论上不会有问题,如果有问题也是大面积出问题。
先上 GitHub 看看有没有相关的 issue,先是找到个说可以自己用垃圾回收简单处理下,随机尝试下,但是没有效果
// 执行垃圾回收 gc_collect_cycles();
后面找到个类似的 issue
这哥么的情况跟我差不多,后面看到开发者说有个定时任务的策略可以改成携程策略,尝试改下,替换定时任务的执行策略
\Hyperf\Crontab\Strategy\StrategyInterface::class => \Hyperf\Crontab\Strategy\CoroutineStrategy::class,
问题基本上解决了,worker 进程内存没有缓慢增加了,自此以为问题解决了,调整代码,发版,美美睡一觉(高兴太早了)

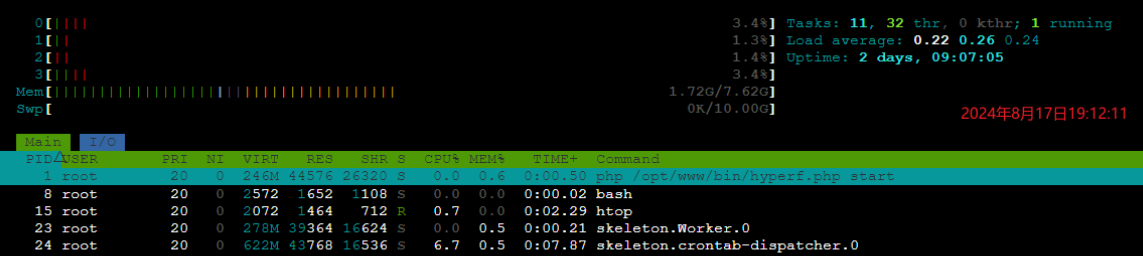
新的问题
跑了一天,还是收到告警,直接到线上看啥情况,发现 worker 进程的内存没有明显增长了,但是取而代之 crontab-dispatcher 进程的内存开始疯长,也就是内存换个进程跑,还是没解决问题,这里基本上可以说明是定时任务配置有问题,排查定时任务配置
看到定时任务的配置,发现有两个参数是关闭了,后面查看下 官方文档,发现这两个配置是为了控制任务并发和多实例触发的问题,如果关闭的话,代码没有做任何锁处理,会导致这个定时任务被重复执行多次,修改之后观察了半个月,没有收到类似的告警,问题基本上解决了


解决
期间虽然还怀疑是 server.php 配置有问题,以为是用了 SWOOLE_PROCESS 导致资源没分配好,把请求都打到某一个 worker 引发这个问题,不过后面可以排除这个,虽说有点小影响,SWOOLE_BASE 相比 SWOOLE_PROCESS 请求分配会均匀些,但不是本次问题的重点。说下结论
- 修改定时任务执行策略为 CoroutineStrategy
- 修改定时任务配置,处理好任务重复执行问题
结论
主要是两个问题,一、定时任务执行策略没配置携程策略,导致 worker 进程内存只增不减;二、定时任务配置错误,导致任务重复执行造成内存缓慢泄露


![[图文直播]基于ZFile和MinIO搭建私有网盘](https://img2023.cnblogs.com/blog/3485711/202409/3485711-20240901163234831-2006360717.png)