- 安装显卡驱动和开发库
- 对于 Tesla 系列显卡
- 对于 N 卡
- 安装 CUDA 和 cuDNN
- 安装 Miniconda
- 安装 PyTorch 和 Transformers
- 使用 Modelscope 下载加载模型
- PyCharm 项目配置
- 模型加载和对话
- CPU 和 GPU 问题
- transformers 版本错误
- TORCH_USE_CUDA_DSA 错误
学习模型开发时,搭建环境可能会碰到很多曲折,这里提供一些通用的环境搭建安装方法,以便读者能够快速搭建出一套 AI 模型开发调试环境。
安装显卡驱动和开发库
本文只讲述 NVIDIA 显卡驱动的安装方法。
NVIDIA 显卡有多个系列,常用的有 Tensor 和 GeForce RTX 系列,两类显卡的驱动安装方式不一样,下面的章节会单独介绍如何安装驱动。
第一步,检测电脑是否正确识别显卡或已安装驱动。
打开设备管理器,点击 显示适配器 ,查看设备列表是否存在显卡。

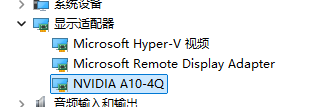
如果电脑已经识别出显卡,可以通过 NVIDIA GeForce Experience 或者在其它驱动管理工具更新到最新版本的驱动程序。
或者直接到官方驱动页面搜索显卡型号要安装的驱动程序,Nvida 官方驱动搜索下载页面:https://www.nvidia.cn/drivers/lookup/
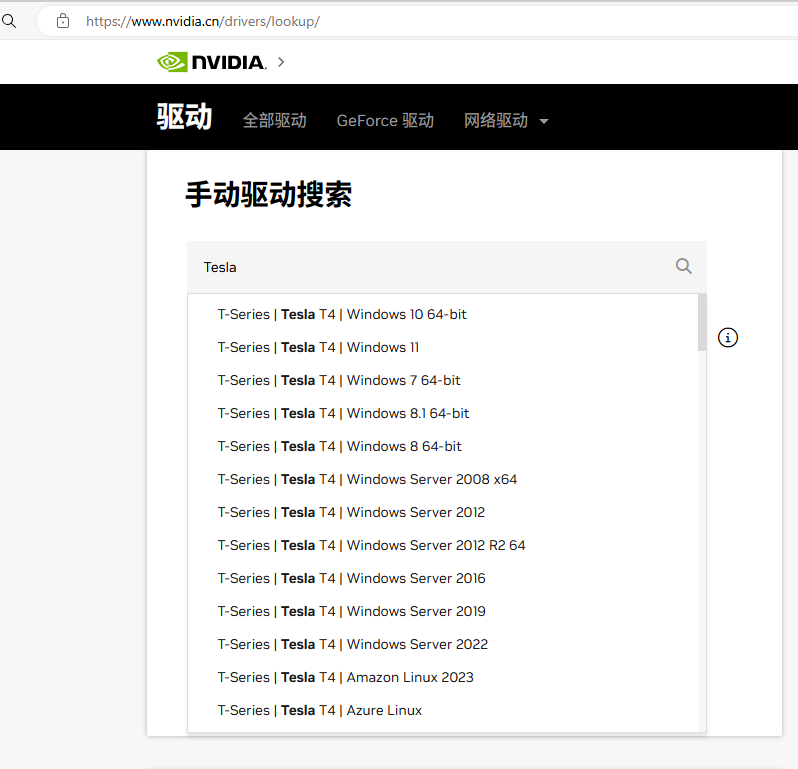
对于 Tesla 系列显卡
例如在 Azure 等云平台创建 GPU 服务器后,如果显卡是 Tesla ,刚开机时可能识别不出显卡,需要先安装驱动之后才能显示显卡设备。
Windows 可参考该链接安装:https://learn.microsoft.com/zh-CN/azure/virtual-machines/windows/n-series-driver-setup
Linux 可参考该链接安装:https://learn.microsoft.com/zh-CN/azure/virtual-machines/linux/n-series-driver-setup
对于 Windows ,安装方法比较简单,只需要按照文档下载 GRID 程序安装包即可。

安装后驱动,启动命令查看支持的 CUDA 版本:
nvidia-smi
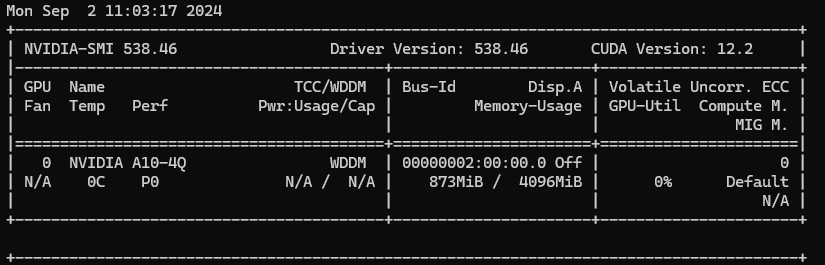
可以看到,该驱动版本只支持 12.2 的 CUDA 版本。
对于 N 卡
对于 GeForce RTX 4060TI 、GeForce RTX 4070 等显卡,可以直接到官方下载驱动安装器:
https://www.nvidia.cn/geforce/drivers/
一般来说,家用主机的出厂时都会安装好的驱动的。
安装 CUDA 和 cuDNN
CUDA 是 NVIDIA 专为图形处理单元 (GPU) 上的通用计算开发的并行计算平台和编程模型。借助 CUDA,开发者能够利用 GPU 的强大性能显著加速计算应用。
简单来说 CUDA 就是支持 CPU 分发和 GPU 并行计算的编程模型,为了使用 CUDA ,需要安装开发工具包。
CUDA 介绍:
https://developer.nvidia.cn/cuda-zone
https://developer.nvidia.com/zh-cn/blog/cuda-intro-cn/
CUDA 安装包下载地址:https://developer.nvidia.com/cuda-downloads
下打开安装包,根据提示操作安装即可,简洁安装会安装 C 盘,高级安装可以自定义安装位置,建议使用简洁安装,以免出现额外情况。

安装完成后,环境变量会多出两条记录:

cuDNN 是基于 GPU 的深度学习加速库,下载文件后是一个压缩包。
下载地址:https://developer.nvidia.com/cudnn-downloads
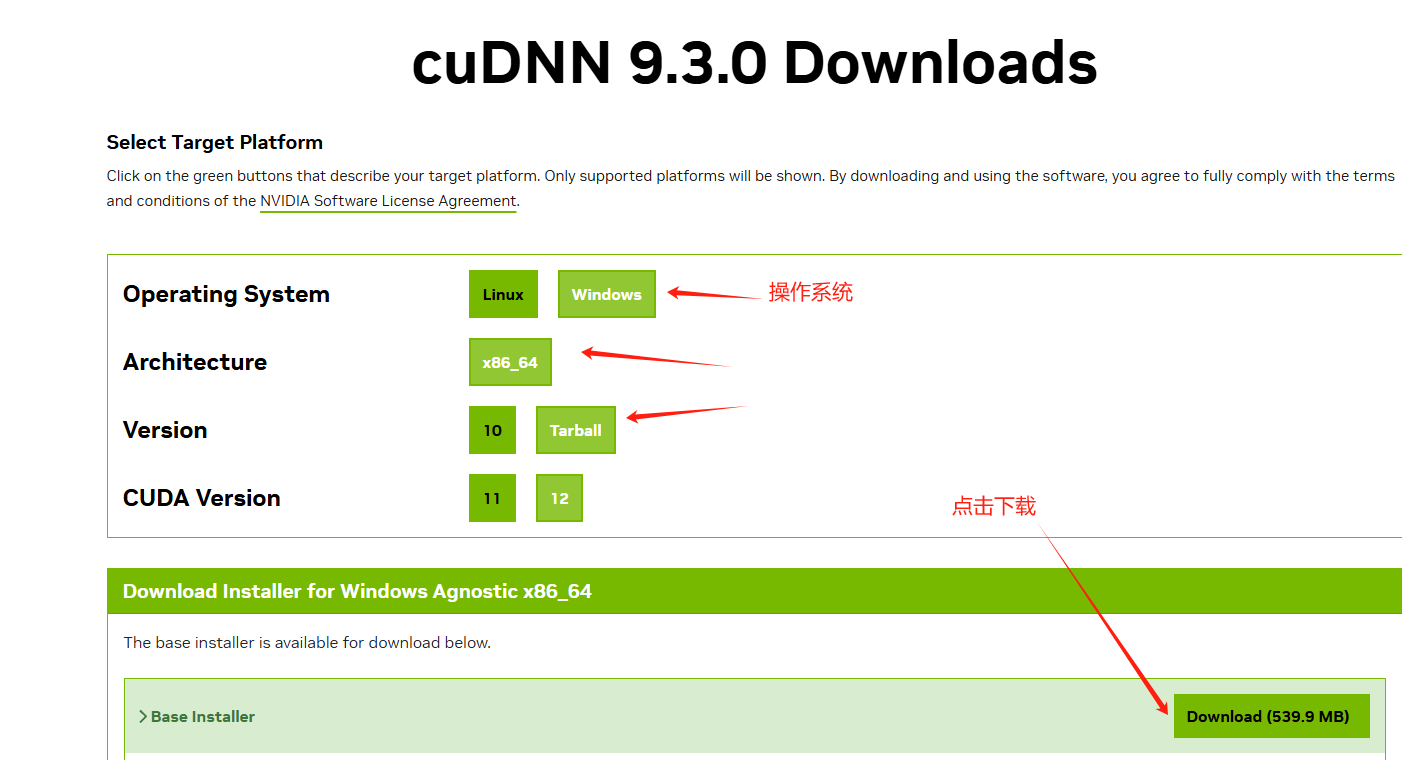
打开 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\,找到版本目录,或者通过环境变量 CUDA_PATH 找到安装目录,将 cuDNN 压缩包的内容复制合并到 CUDA 目录。
最后将 bin、lib、lib\x64、include、libnvvp 五个目录添加到环境变量 Path 中。
也不知道具体到底需要多少环境变量,加就是了。
安装 Miniconda
Miniconda 是一个 Python 包管理器,能够在系统中创建多个环境隔离的 Python 环境。
下载地址:https://docs.anaconda.com/miniconda/
下载完成后,搜索 miniconda3 快捷菜单,以管理员身份运行,点击可以打开控制台,菜单列表会有 cmd 和 powershell 两个快捷链接,建议使用 powershell 入口。
后续执行 conda 命令,都要使用管理员身份运行。
配置国内源加速下载:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
执行 conda env list 目录查看默认环境安装目录。

如果电脑已经安装过 Python 并且添加了环境变量,则不要将 G:\ProgramData\miniconda3 添加到环境变量中,因为这样会导致环境缭乱。
如果电脑还没有安装过 Python ,则可以直接将 G:\ProgramData\miniconda3 、G:\ProgramData\miniconda3\Scripts 添加到环境变量中。
笔者电脑卸载了手动安装的 Python,只使用 miniconda3 提供的环境。
如果 Python、pip 使用的是自行安装的,直接执行命令安装依赖包的时候,跟 miniconda3 环境是隔离的。如果需要在 miniconda3 环境安装依赖包,需要打开 miniconda3 控制台执行 pip 命令,这样安装的包才会出现在 miniconda3 环境中。
一个环境中安装依赖包后,不同的项目可以共用已下载的依赖包,不需要每个项目单独下载一次。
安装 PyTorch 和 Transformers
Flax、PyTorch 或 TensorFlow 都是深度学习框架,而 Transformers 底层可以使用 Flax、PyTorch 或 TensorFlow 深度学习框架,实现模型加载、训练等功能。
PyTorch 安装参考文档:https://pytorch.org/get-started/locally/
可以安装 GPU 版本(CUDA)或 CPU 版本,然后复制下方提示的安装命令。

conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
然后还需要执行命令安装 Transformers 和一些依赖库。
pip install protobuf 'transformers>=4.41.2' cpm_kernels 'torch>=2.0' gradio mdtex2html sentencepiece accelerate
可能会自动安装最新版本的 transformers,会出问题,后面的章节讲述如何解决。
使用 Modelscope 下载加载模型
ModelScope 是阿里云主导的一个国内 AI 模型社区,提供了各类模型和数据集以及开发工具库,由于 huggingface 上手难度稍大以及国外网络原因,这里使用 Modelscope 下载和加载模型。
安装 modelscope:
pip install modelscope
PyCharm 项目配置
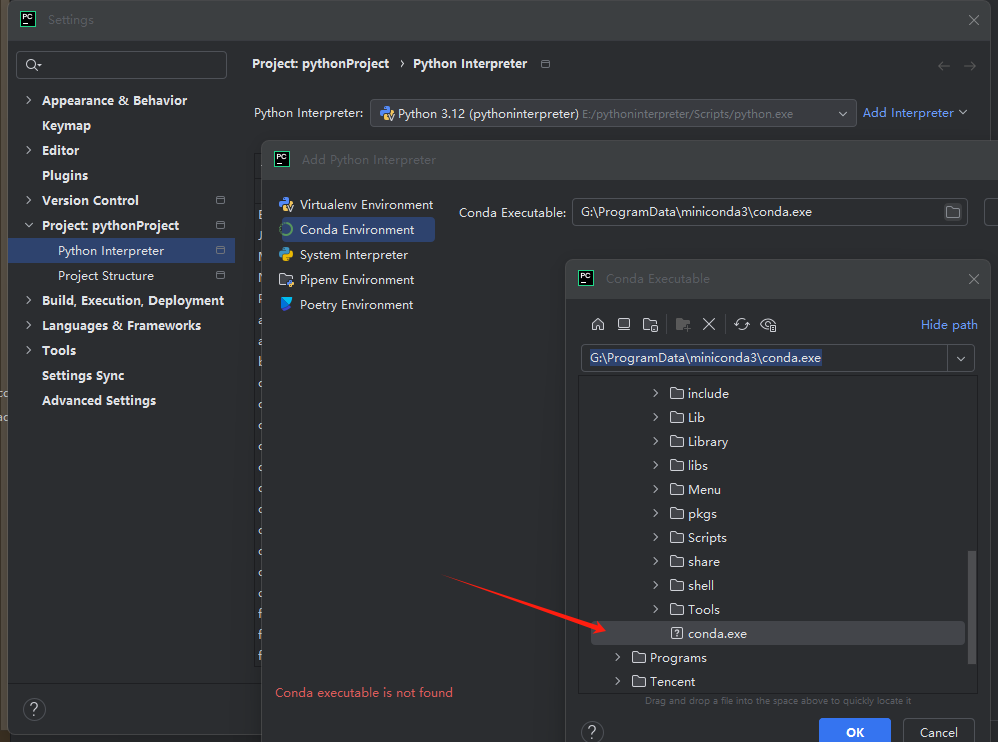
PyCharm 是最常用的 Python 编程工具,因此这里讲解如何在 PyCharm 中配置 miniconda3 环境。
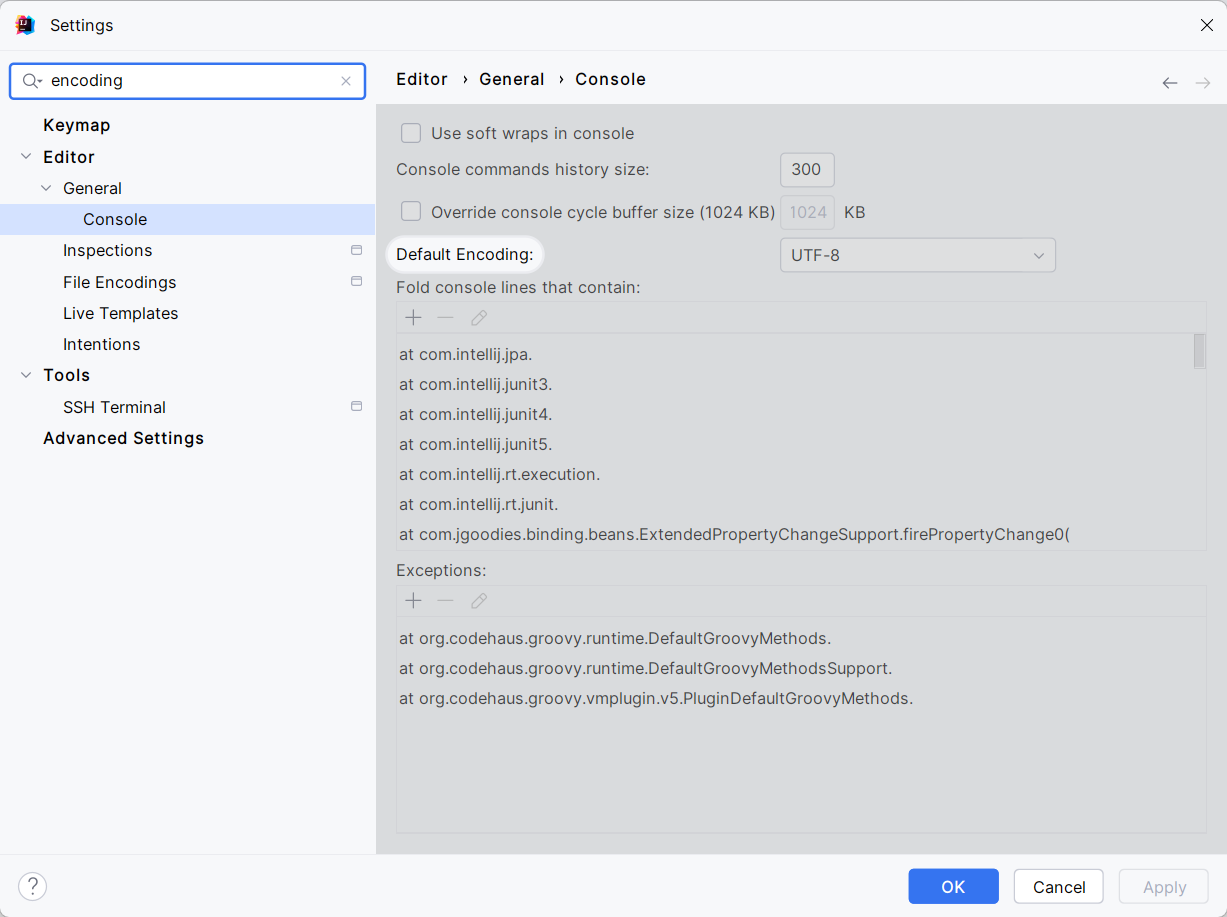
打开 PyCharm ,在设置中添加 miniconda3 的环境,步骤如图所示。
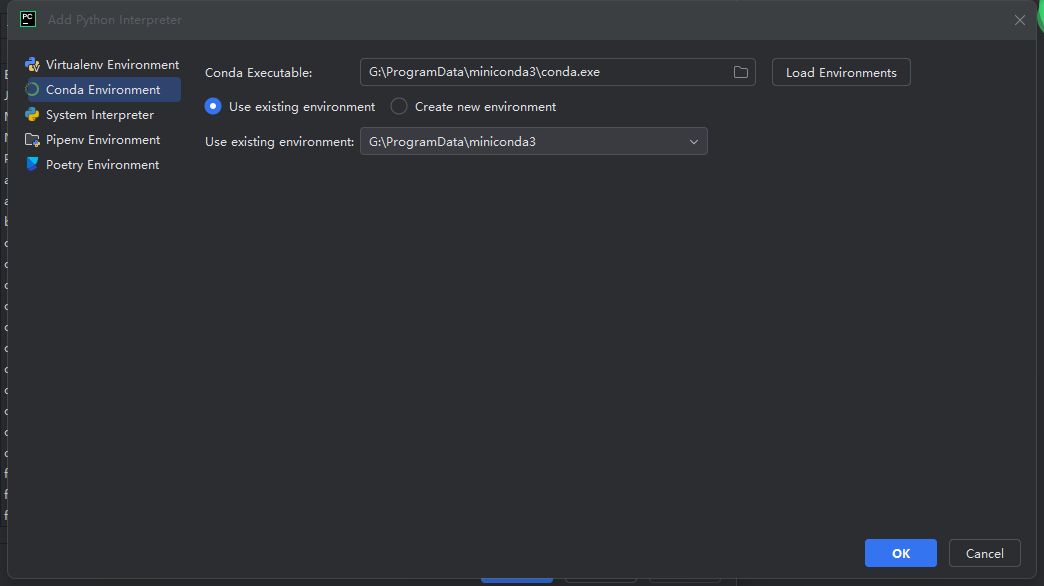
然后创建一个项目,在项目中选择基于 conda 的环境。
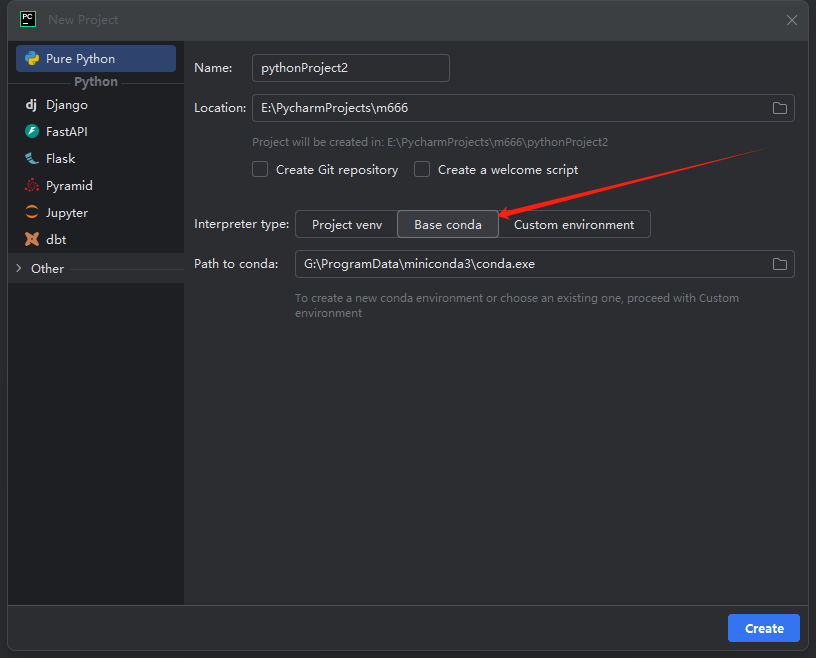
模型加载和对话
在项目目录下创建 main.py 文件。
将以下代码贴到 main.py,然后运行代码,会自动下载模型、加载模型和对话。
from modelscope import AutoTokenizer, AutoModel, snapshot_download# 下载模型
# ZhipuAI/chatglm3-6b 模型仓库
# D:/modelscope 模型文件缓存存放目录
model_dir = snapshot_download("ZhipuAI/chatglm3-6b",cache_dir="D:/modelscope", revision="v1.0.0")# 加载模型
# float 是 32,half 是16 位浮点数,内存可以减少一半
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()# 开始对话
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)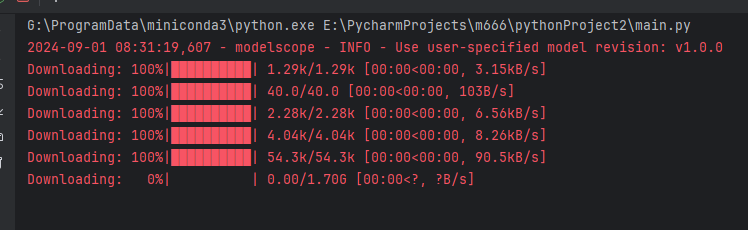
"ZhipuAI/chatglm3-6b" 指的是 ZhipuAI 仓库的 chatglm3-6b 模型,可以通过 ModelScope 查看社区已上传的各类模型:
https://www.modelscope.cn/models
revision="v1.0.0" 下载版本号跟仓库分支名称一致,可以填写不同分支名称下载不同的版本。
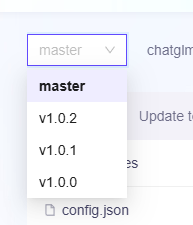
CPU 和 GPU 问题
如果出现以下报错,可能安装的是 CPU 而不是 GPU 版本的 PyTorch。
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
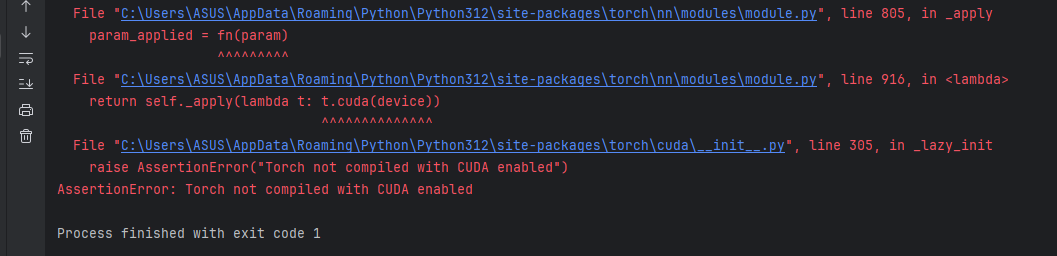
执行代码:
import torch
print(torch.__version__)
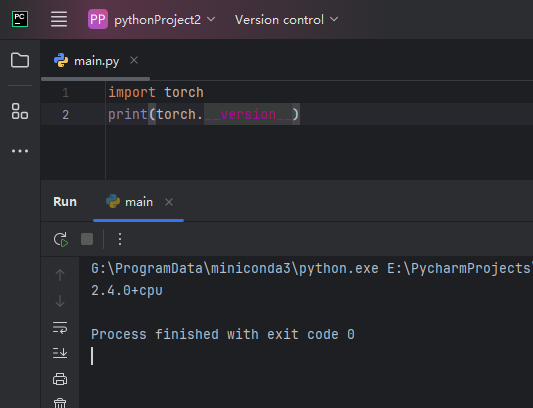
按经验,如果使用了 pip 安装相关库,而不是使用 conda 命令安装的,需要执行以下命令卸载 pytorch:
pip uninstall torch torchvision torchaudio
conda uninstall pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
然后执行命令重新安装 pytorch:
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
重新执行命令后即可正常:
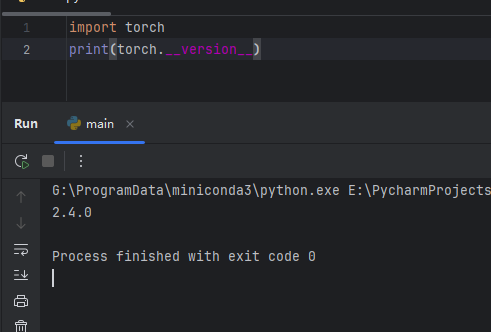
transformers 版本错误
由于安装各类库的时候都是安装最新版本安装的,可能有部分库不兼容,执行到以下代码行时,抛出错误。
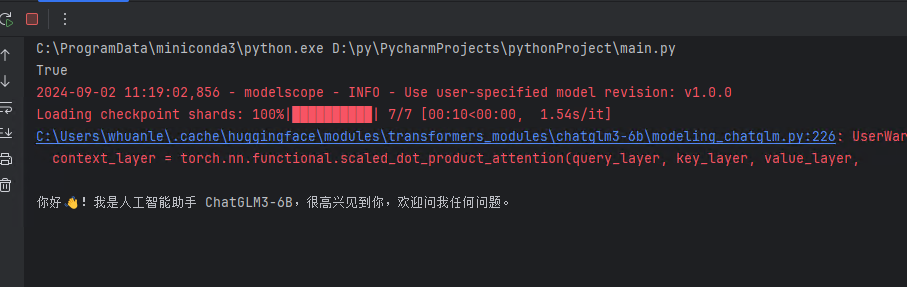
response, history = model.chat(tokenizer, "你好", history=[])
首先出现以下警告,然后出现报错:
1Torch was not compiled with flash attention. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:555.)context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
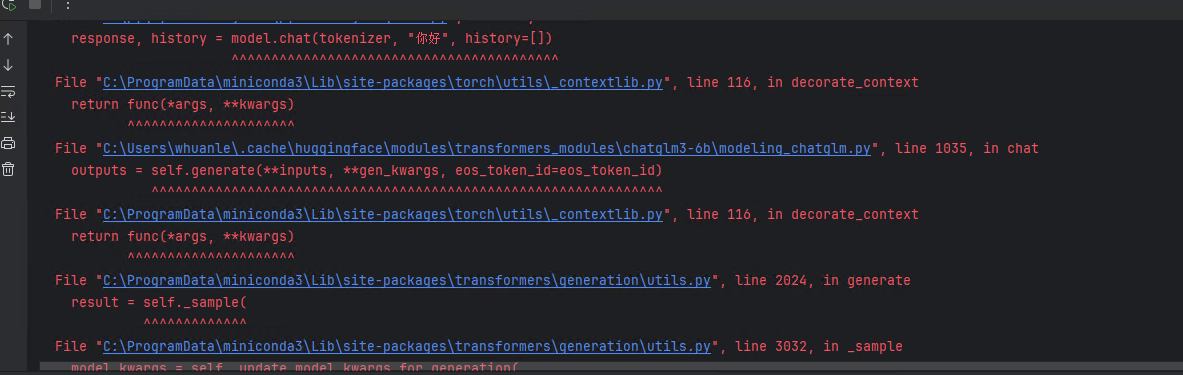
需要将 transformers 版本安装要求的最新版本(升级)。
pip install transformers==4.41.2
经历各种曲折,最后终于成功了:
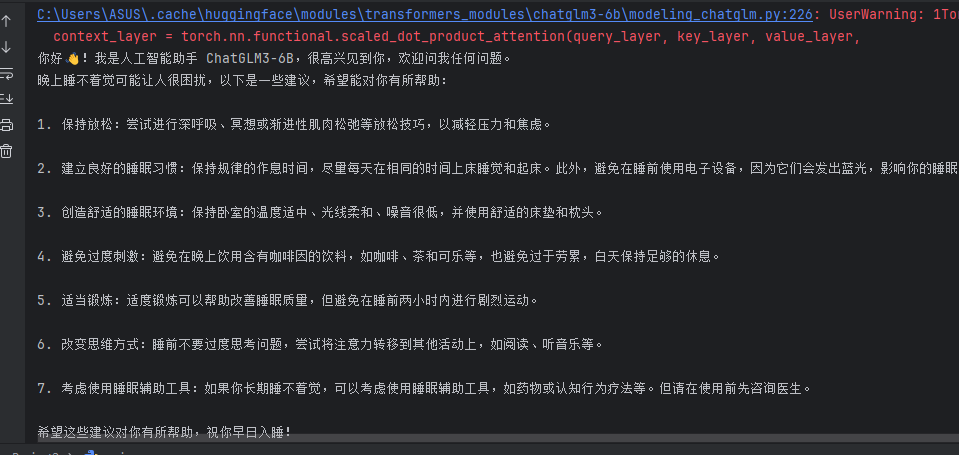
TORCH_USE_CUDA_DSA 错误
笔者碰到的问题应该是 GPU 性能不够导致的,该问题出现在 Azure A10 机器上,家用的 RTX 4060TI 没有出现这个问题。
不过也有可能是显卡驱动跟 CUDA 版本不一致导致的。
File "C:\ProgramData\miniconda3\Lib\site-packages\transformers\generation\utils.py", line 2410, in _samplenext_token_scores = logits_processor(input_ids, next_token_logits)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "C:\ProgramData\miniconda3\Lib\site-packages\transformers\generation\logits_process.py", line 98, in __call__scores = processor(input_ids, scores)^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "C:\Users\xxx\.cache\huggingface\modules\transformers_modules\chatglm3-6b\modeling_chatglm.py", line 55, in __call__if torch.isnan(scores).any() or torch.isinf(scores).any():^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: CUDA error: the launch timed out and was terminated
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.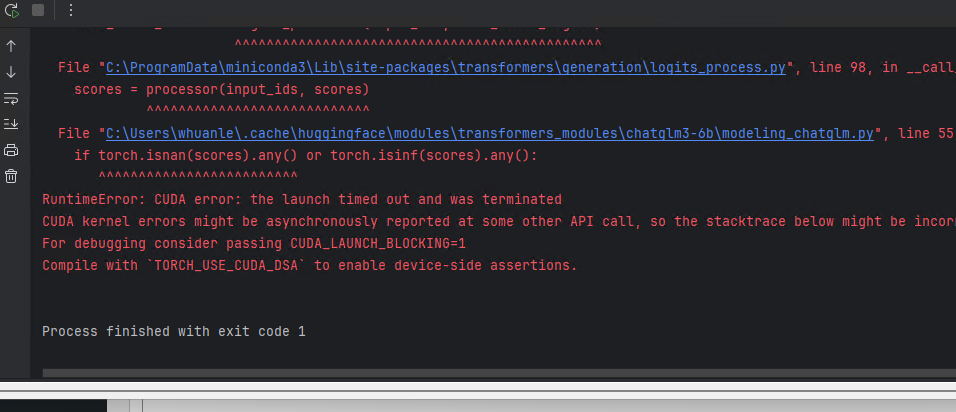
使用 CPU 是可以的:
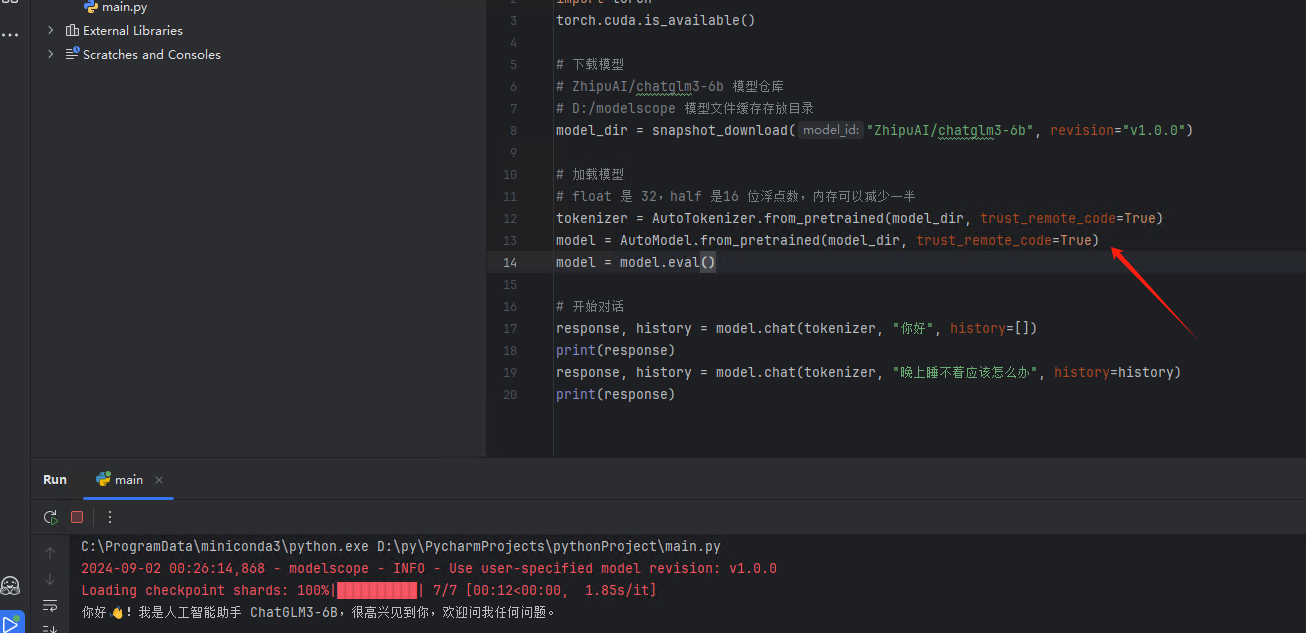
随便跑了一个 demo ,也是可以执行的。
https://github.com/pytorch/examples/blob/main/mnist/main.py
可能是 CUDA 库和驱动库版本不一致导致的,首先执行 nvidia-smi 命令,检查显卡驱动库兼容的 CUDA 版本。
下载安装对应版本的 CUDA,然后重新解压 cuDNN 以及设置环境变量。
最后,服务器也成功搭建起 AI 环境。