Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model(2024,8)
Paper
TODO: 目前没有开源代码,实时关注一下official code,Meta的工作基本开源的.本文给出了一种新的T2I的方法.
lucidrains的代码
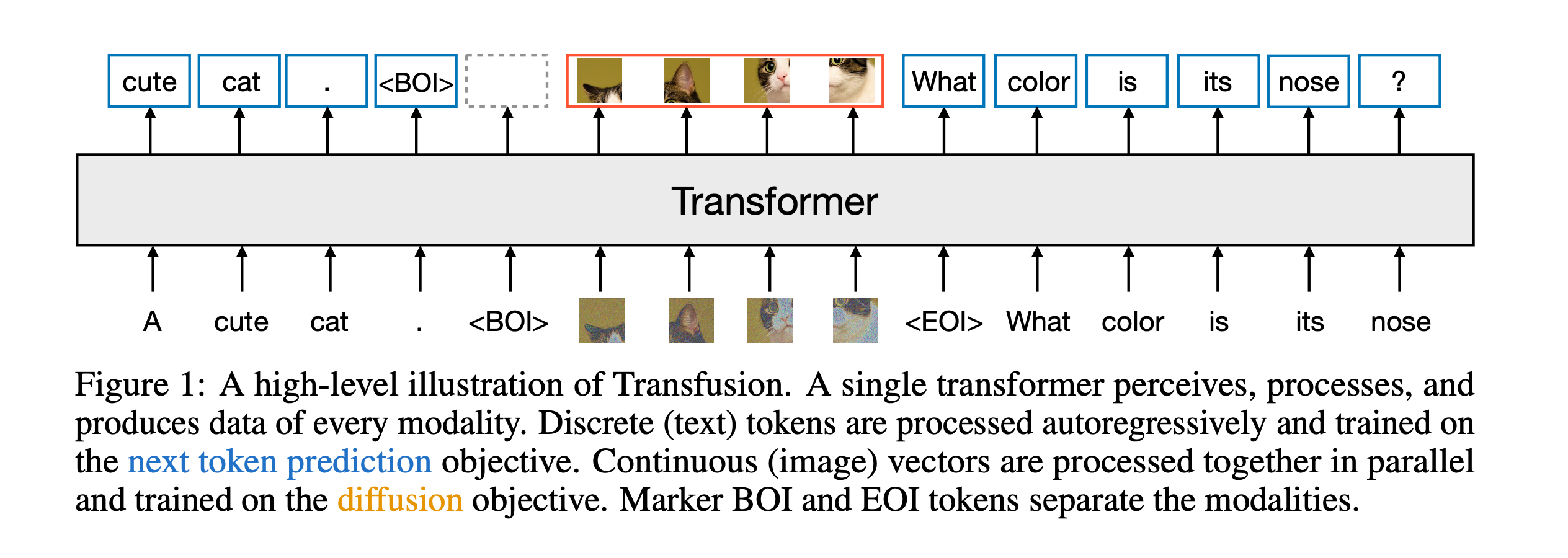
本质是将LLM的transformer和图像中的diffusion结合了起来,使用同一个transformer来同时处理文本和图像信息.之前的DiT架构都是使用一个预训练的TextEncoder来提取文本信息,,并通过Concat、AdaLN、
CrossAttention、MMDit等方式将文本信息融入模型,而本文的方式直接同时训练文本和图像信息,并且是使用同一个模型来进行处理.
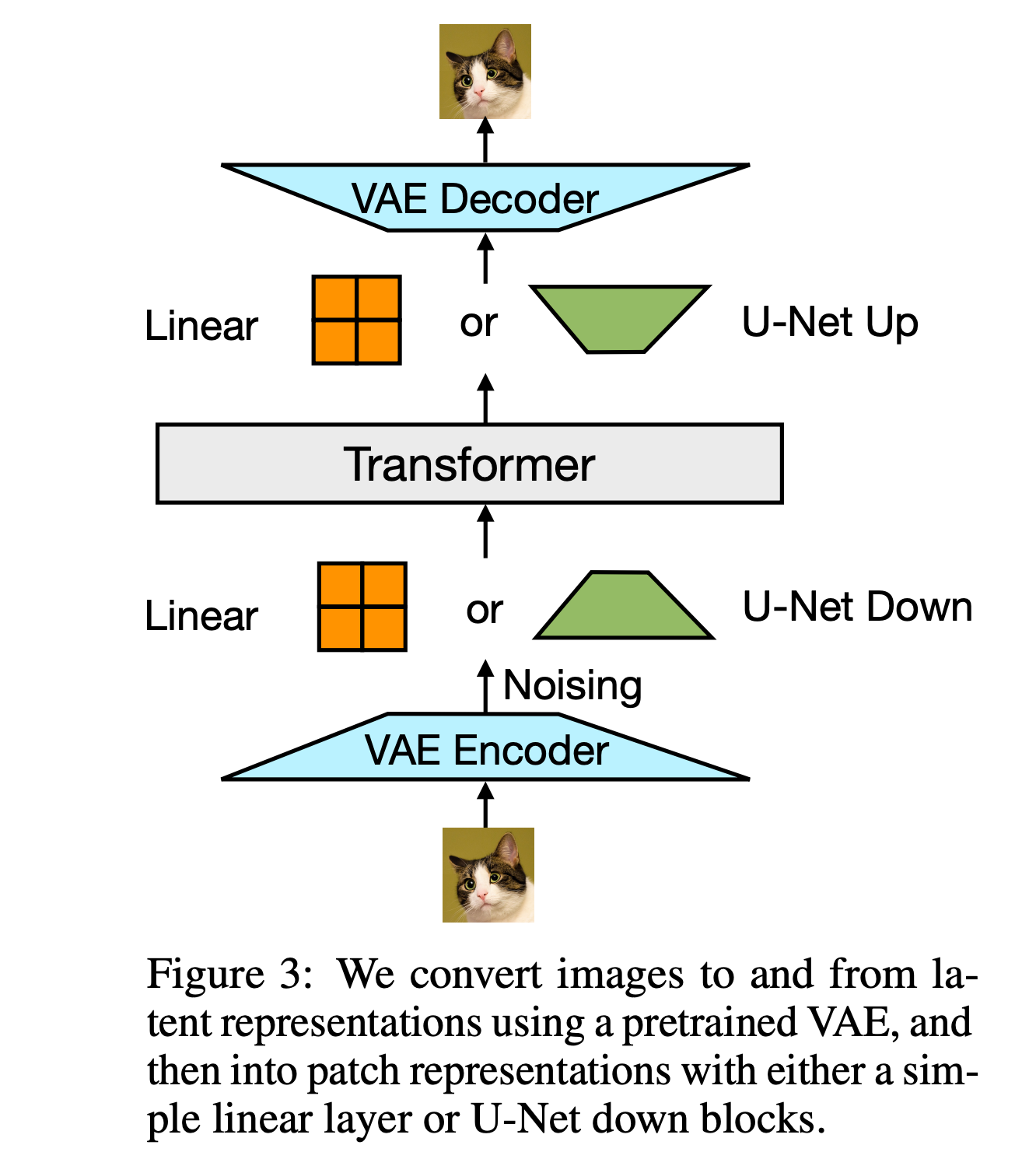
如上图,图像经过一个VAE来得到tokens,并插入到文本token中,文本也会在经过一个tokenizer之后通过一个轻量级的模块进行处理,然后再通过一个transformer来处理文本和图像的信息.
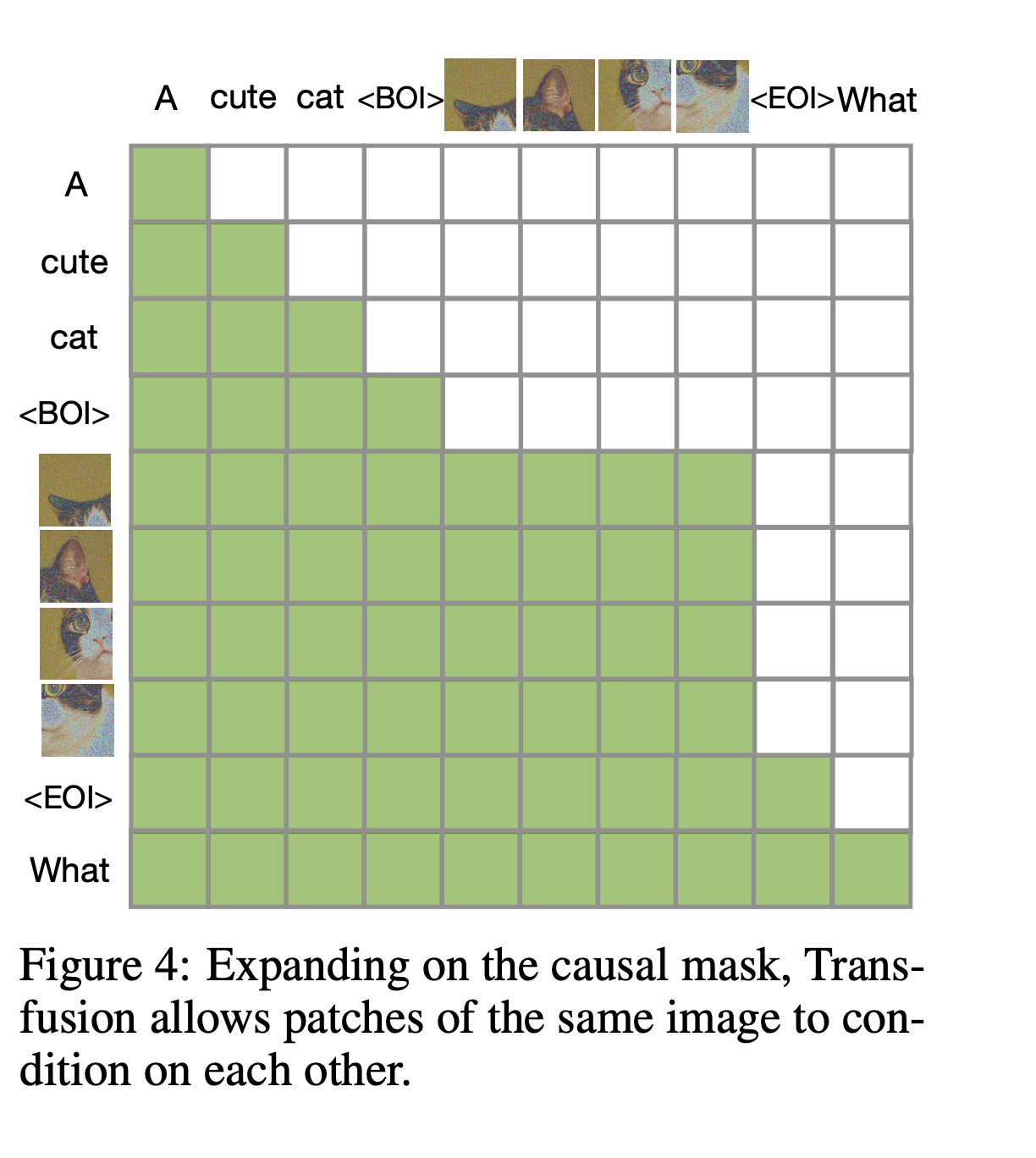
文本的attention方式和图像不一致,文本因为要采用causal的方式,而图像则需要采用bidirectional的方式.
Loss : \(\mathcal{L}_\text{Transfusion}=\mathcal{L}_\text{LM}+\lambda\cdot\mathcal{L}_\text{DDPM}\)
对于文本采用了LLM modeing,对于图像采用了DDPM的loss,训练细节和效果可以参看论文.
论文通过提出Transfusion方法来解决多模态模型的训练问题。Transfusion的核心思想是训练一个单一的模型来同时处理离散和连续的数据模态,具体解决方案包括以下几个关键步骤:
-
数据表示:将文本数据表示为离散的token序列,将图像数据通过变分自编码器(VAE)编码为连续的潜在空间补丁序列。在混合模态的示例中,使用特殊的开始图像(BOI)和结束图像(EOI)标记来分隔文本和图像序列。
-
模型架构:使用一个单一的Transformer模型来处理所有序列,无论其模态如何。对于文本,使用嵌入层将token转换为向量;对于图像,尝试了两种将局部窗口的补丁向量压缩成单个Transformer向量的方法:简单的线性层和U-Net的上下块。
-
注意力机制:结合了因果注意力(用于文本token)和双向注意力(用于图像补丁)。这允许图像内的每个补丁能够相互注意,同时只能注意序列中先前出现的文本或图像补丁。
-
训练目标:对文本token应用语言建模目标(LLM),对图像补丁应用扩散目标(LDDPM)。通过简单地将两种模态上计算的损失相加,并引入一个平衡系数λ,来训练模型。
-
推理算法:根据训练目标,解码算法在两种模式(LM和扩散)之间切换。在LM模式下,从预测分布中逐个采样token。当采样到BOI标记时,切换到扩散模式,按照扩散模型的标准程序解码图像。
-
实验验证:通过一系列受控实验,论文展示了Transfusion在不同模型大小和数据量下的性能,以及与Chameleon方法的比较。实验结果表明,Transfusion在每种模态组合中的扩展性都优于Chameleon方法。
-
架构改进:论文还探讨了Transfusion模型的不同变体,包括使用不同大小的图像补丁、不同的编码/解码架构(线性层与U-Net块),以及限制图像噪声的程度,以提高特定任务的性能。
-
图像编辑能力:论文进一步展示了Transfusion模型在图像编辑任务上的潜力,通过在少量图像编辑数据上微调预训练模型,使其能够根据指令执行图像编辑。

![[MySQL]B+树能存储多少数据](https://img2024.cnblogs.com/blog/1533409/202409/1533409-20240904225031138-767558854.png)




![[计算机网络]协议栈](https://img2024.cnblogs.com/blog/1533409/202409/1533409-20240904220429579-1230290363.png)