这是我第一次对系统进行调优,涉及代码和JVM层面的调优。如果你能看到最后的话,或许会对你日常的开发有帮助,可以避免像我一样,犯一些低级别的错误。本次调优的代码是埋点系统中的报表分析功能,小公司,开发结束后,没有Code Review环节,所以下面某些问题,也许在Code Review环节就可以避免。
这次调优所使用到的工具有:JProfiler、Arthas、Visual VM。
Arthas用于查看多个方法耗时,JProfiler和Visual VM用于观察JVM运行过程中的堆内存变化,GC活动图,实时对象数和大小等。
调优前后,JDK8,堆内存大小为500M,使用SerialGC,相同数据量的情况下,系统的响应速度提升了70%。

功能介绍
在开始之前,为了大家更好的阅读这篇文章,我会先简要介绍一下这个系统。
此系统是一个埋点系统,客户端上报埋点数据之后,可以在后台对上报的埋点数据进行报表分析。比如统计留存、活跃人数、游戏玩家性别比例等等。
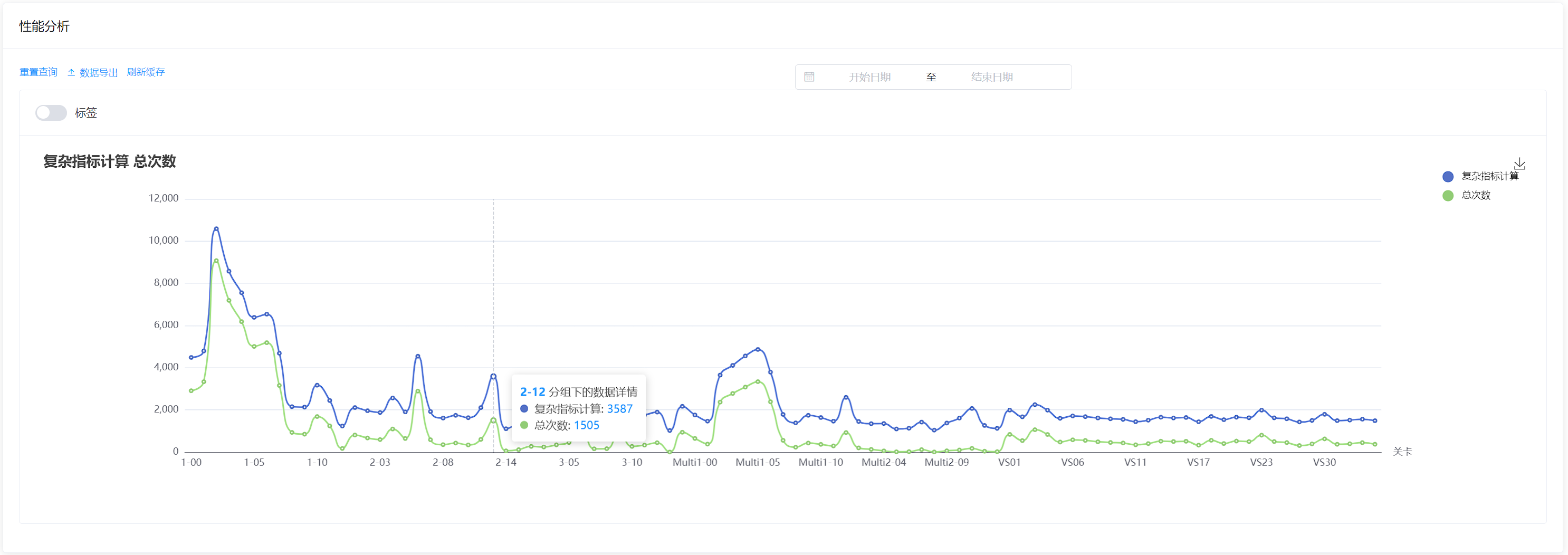
该系统的报表分析功能的逻辑为:
-
数据获取:从数据库中根据分析时间拉取埋点数据。
-
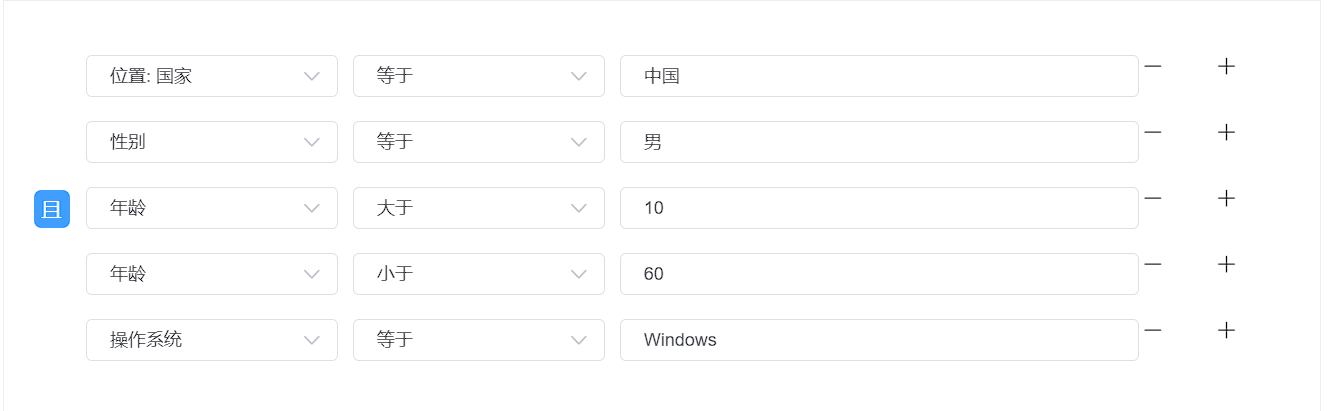
全局过滤:对从数据库拉取到的埋点数据执行全局过滤。全局过滤可以对埋点数据中的各个参数执行多个
且或或操作。全局过滤后的埋点数据才会进行后续的维度和指标计算。
-
维度计算:维度(类似于XY轴中的X轴值)是通过将查询到的埋点数据按照分组字段进行分组,该分组字段的值便作为维度值。维度值类型可以是数值、日期、字符串。根据维度值的类型可以进行降序和升序操作,维度可以分为一维和二维。
-
指标计算:通过将埋点数据按照分组字段进行分组后,得到一组一组的埋点数据,每一组埋点数据由多条埋点数据组成。指标便是通过对每一组中的所有埋点数据执行数值运算,并且可以添加过滤条件(例如只计算性别为”女”的用户)。一个报表可以包含多个指标。
- 数据组装,前端展示。
上述便是埋点报表功能的主要流程,导致该功能响应超时的原因便是由于维度排序,埋点数据过滤,指标计算导致的。
同事在后台进行报表分析时,发现在分析数据量在3万多的情况下,接口出现了超时(30s),我一开始以为是由于从数据库拉取数据造成的,但是我通过服务的运行日志发现,在这个接口执行过程中,执行SQL耗时不高并且该SQL走了索引,可以直接将数据库方面的原因排除。
维度优化
定位问题代码
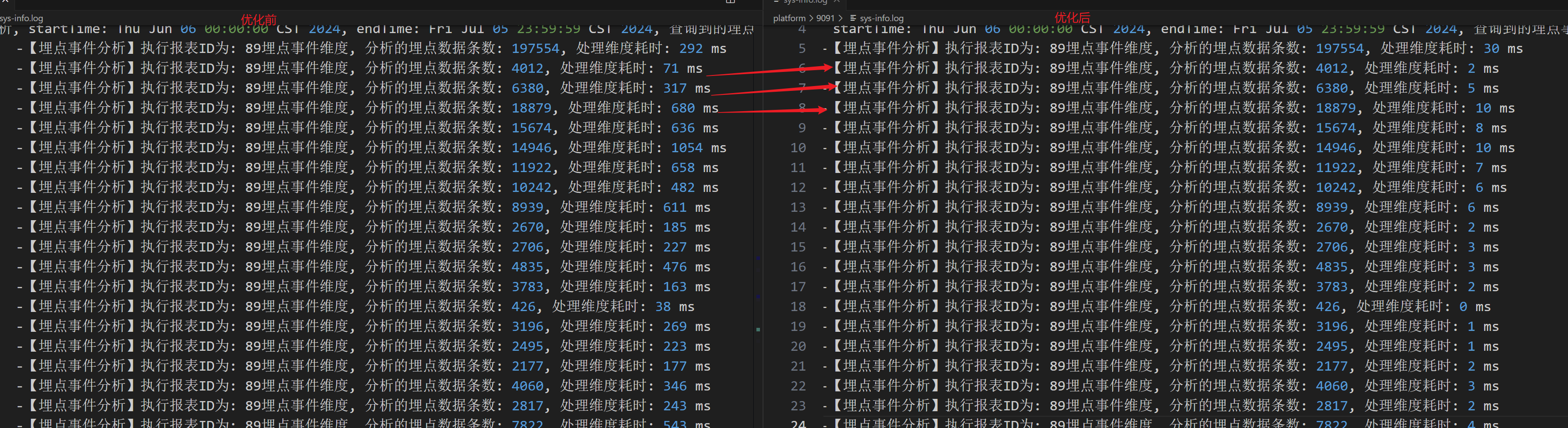
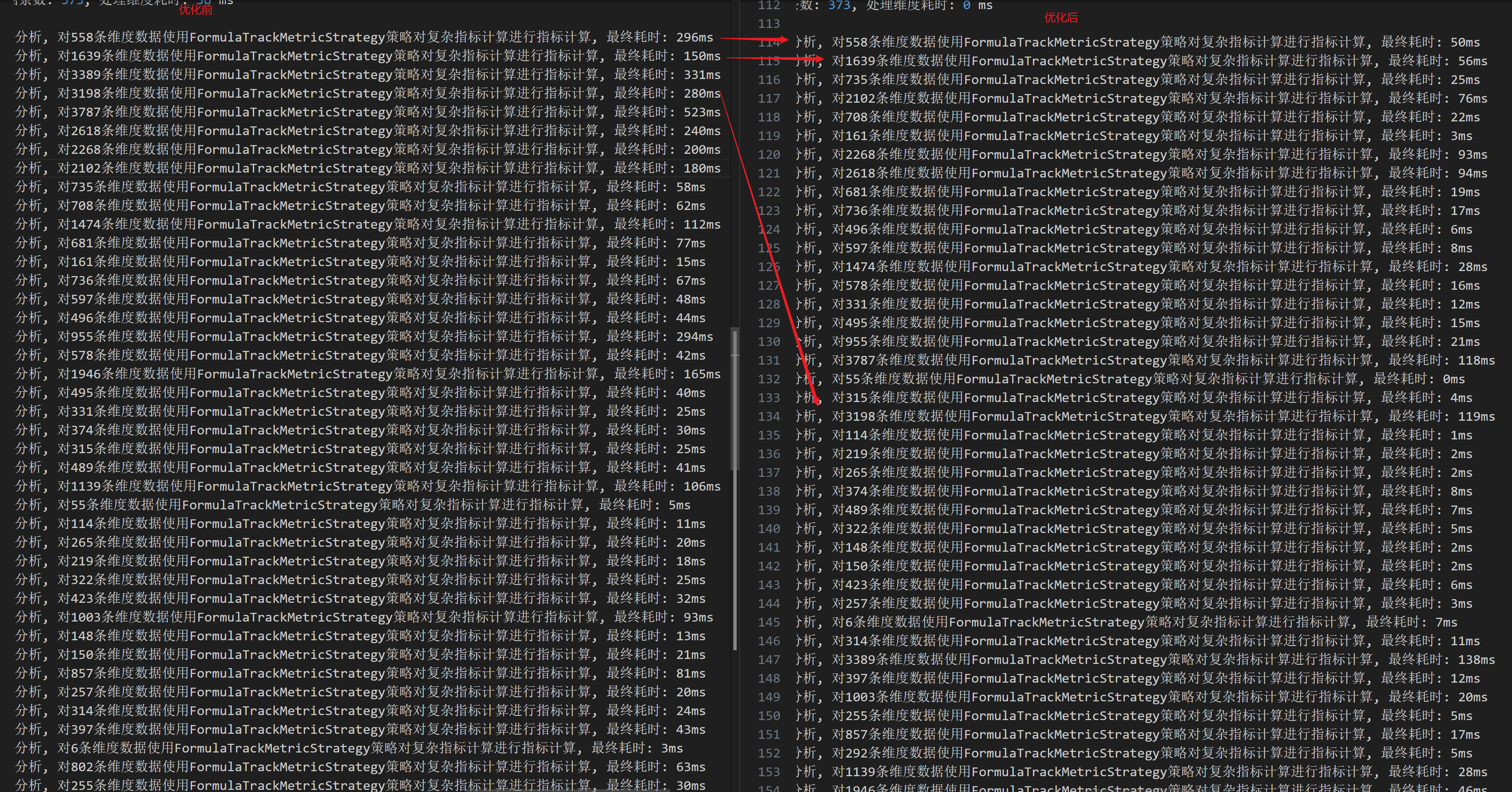
对日志进一步分析发现,发现在处理维度数据时,耗时非常大,因为维度的计算方式很简单,但是耗时却是非常大,这很问题。
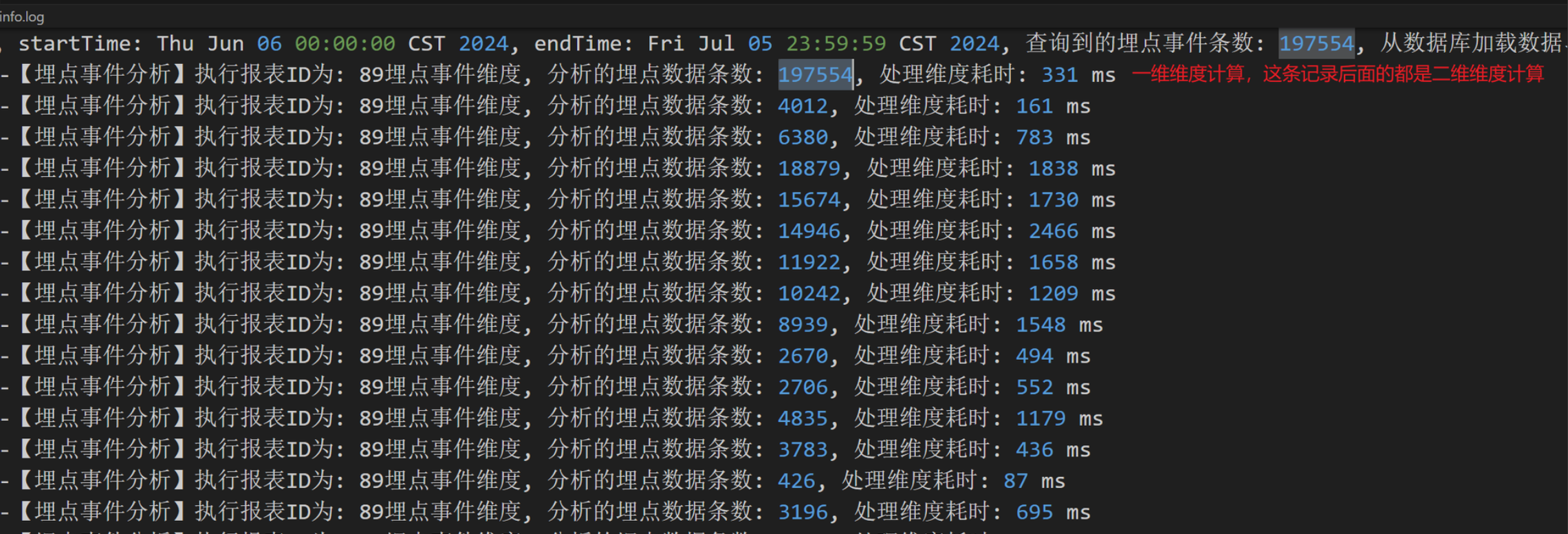
从上面的日志中我们可以看到,在对197554条数据进行一维分析时才花了331 ms,但是使用同样的代码,对4012条数据进行维度分析,却花了161 ms,一维和二维都是执行相同的代码,但是耗时却相差这么大。
执行维度分析的代码为:
public List<DimensionData> query(DimensionSetting dimensionSetting, TrackReportSetting trackReportSetting, List<TrackData> trackDataList) {List<DimensionData> dimensionDataList = null;try {// doQuery方法是根据分组字段对埋点数据进行分组 dimensionDataList = doQuery(dimensionSetting, trackReportSetting, trackDataList);dimensionDataList = applyDimensionIntervalRange(dimensionDataList, dimensionSetting);// 对分组后的维度值进行排序sortDimension(dimensionDataList, dimensionSetting);} finally {completeQuery(dimensionDataList);}return dimensionDataList;
}
因为这部分的代码比较简单,我一开始并不清楚是由什么导致的,但是后面通过Arthas发现,耗时高是由于执行sortDimension(dimensionDataList, dimensionSetting)方法导致的。
private void sortDimension(List<DimensionData> dimensionDataList, DimensionSetting dimensionSetting) {dimensionDataList.sort(new DimensionData());AtomicLong atomicSortValue = new AtomicLong(0L);dimensionDataList.forEach(t -> {t.setSortValue(atomicSortValue.getAndAdd(1L));});
}
public class DimensionData implements Comparator<DimensionData> {private DimensionSetting dimensionSetting;private String dimensionLabel;// 省略其它字段@Overridepublic int compare(DimensionData data1, DimensionData data2) {DimensionSetting dimensionSetting = data1.getDimensionSetting();AssertUtils.stateThrow(dimensionSetting != null, () -> new XcyeDataException("埋点维度设置不能为空!"));DimensionSetting.DimensionSortTypeEnum sortType = dimensionSetting.getSortType();if (DimensionSetting.DimensionSortTypeEnum.NATURAL == sortType) {Comparator naturalOrder = Comparator.naturalOrder();return naturalOrder.compare(data1.getDimensionLabel(), data2.getDimensionLabel());}String comparableLabel1;String comparableLabel2;if (DimensionSetting.DimensionSortTypeEnum.DESC == sortType) {// 降序comparableLabel1 = data2.getDimensionLabel();comparableLabel2 = data1.getDimensionLabel();} else {// 升序comparableLabel1 = data1.getDimensionLabel();comparableLabel2 = data2.getDimensionLabel();}Object comparableObj;Comparable comparable;if (NumberUtil.isNumber(comparableLabel1) && NumberUtil.isNumber(comparableLabel2)) {comparable = Double.parseDouble(comparableLabel1);comparableObj = Double.parseDouble(comparableLabel2);} else if (((DateUtils.isDate(comparableLabel1, "yyyy-MM-dd") || DateUtils.isDate(comparableLabel1, "yyyy-MM-dd HH:mm:ss"))&& (DateUtils.isDate(comparableLabel2, "yyyy-MM-dd") || DateUtils.isDate(comparableLabel2, "yyyy-MM-dd HH:mm:ss")))) {comparable = new Date(DateUtils.parse(comparableLabel1).getTime());comparableObj = new Date(DateUtils.parse(comparableLabel2).getTime());} else {// 其他 一律当做字符串处理comparable = comparableLabel1;comparableObj = comparableLabel2;}return comparable.compareTo(comparableObj);}
}
罪魁祸首便是compare(DimensionData data1, DimensionData data2)方法,因为一开始设计的时候,并没有提供设置维度类型的选项,但是通常来说,维度一般只会有三种类型,分别是数值字符串,字符以及日期字符串。
上面compare方法便是先尝试对字符串进行数值解析,如果解析失败,再当作时间字符串进行解析,如果还是解析失败,最后才当作普通字符串。
但是在尝试进行数值,日期解析时,在方法执行的内部,会创建额外的对象,至于会创建多少个对象,和维度值的个数有关,并且上面代码本来就存在大量问题。
通过添加JVM参数也可以看到,在执行上面排序的过程中,确实会触发多次GC,从下图也可以看到,在执行compare方法的过程中,GC很频繁,每次GC应用线程的停顿时间平均5ms。
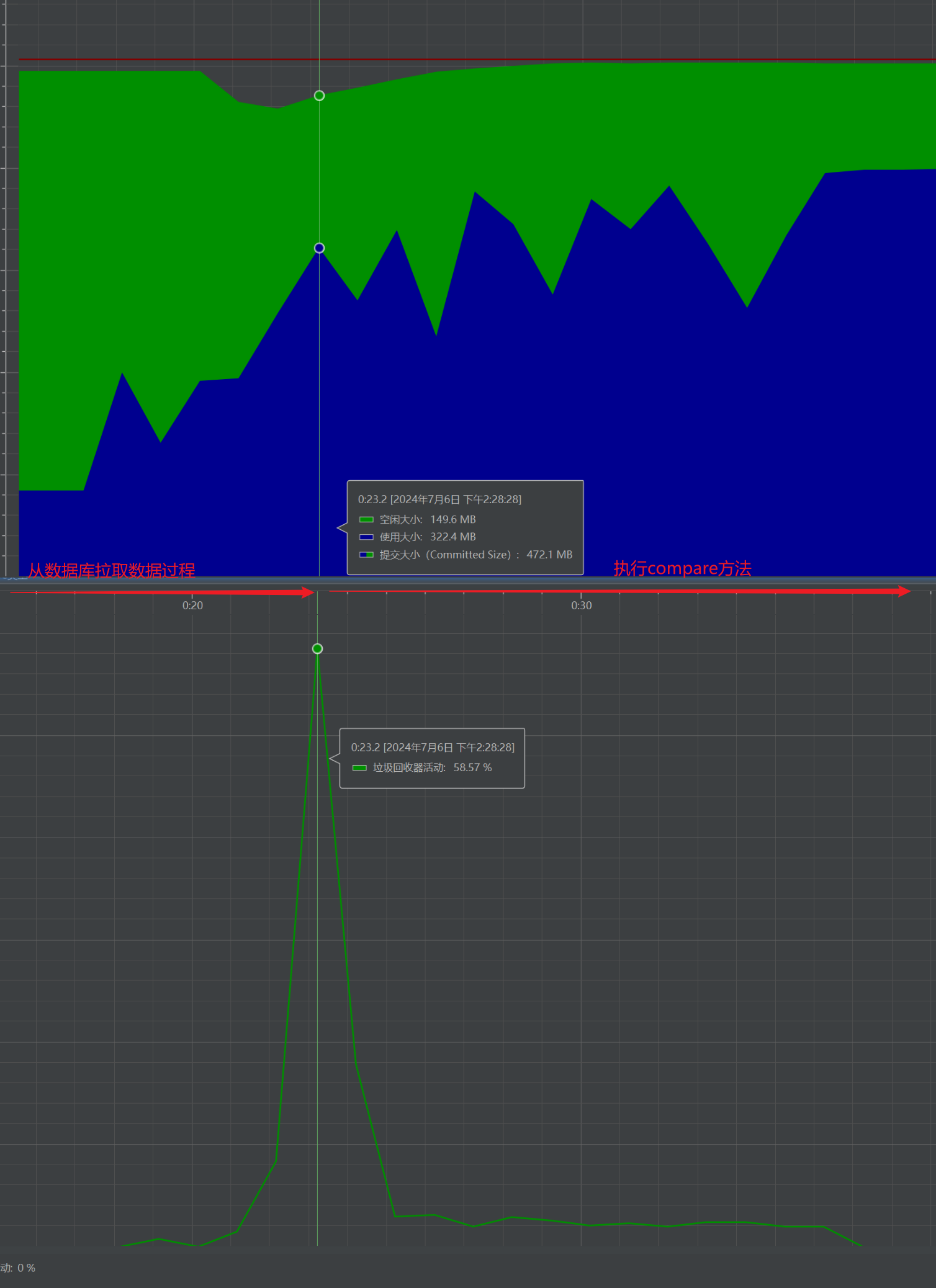
优化排序
既然已经导致compare方法运行时间长的原因了,只需要对症下药就行了。我是采用缓存+提供维度参数类型方式进行优化。优化后的代码为:
public class DimensionData implements Comparator<DimensionData> {private DimensionSetting dimensionSetting;private String dimensionLabel;private ConcurrentHashMap<String, Object> localComparatorCache;@Overridepublic int compare(DimensionData data1, DimensionData data2) {DimensionSetting dimensionSetting = data1.getDimensionSetting();AssertUtils.stateThrow(dimensionSetting != null, () -> new XcyeDataException("埋点维度设置不能为空!"));DimensionSetting.DimensionSortTypeEnum sortType = dimensionSetting.getSortType();if (DimensionSetting.DimensionSortTypeEnum.NATURAL == sortType) {Comparator naturalOrder = Comparator.naturalOrder();return naturalOrder.compare(data1.getDimensionLabel(), data2.getDimensionLabel());}String comparatorLabel;String comparedLabel;if (DimensionSetting.DimensionSortTypeEnum.DESC == sortType) {// 降序comparatorLabel = data2.getDimensionLabel();comparedLabel = data1.getDimensionLabel();} else {// 升序comparatorLabel = data1.getDimensionLabel();comparedLabel = data2.getDimensionLabel();}Object comparedValue = parseComparedValue(comparedLabel, dimensionSetting, data1);Comparable<Object> comparable = (Comparable<Object>) parseComparedValue(comparatorLabel, dimensionSetting, data2);return comparable.compareTo(comparedValue);}private Object parseComparedValue(String comparatorLabel, DimensionSetting dimensionSetting, DimensionData dimensionData) {ConcurrentHashMap<String, Object> localComparatorCacheTemp = dimensionData.getLocalComparatorCache();if (localComparatorCacheTemp == null) {throw new XcyeOtherException("localComparatorCache不能为空!");}DimensionSetting.DimensionFieldValueTypeEnum fieldValueType = dimensionSetting.getFieldValueType();if (fieldValueType == null || DimensionSetting.DimensionFieldValueTypeEnum.STRING == fieldValueType) {return comparatorLabel;}Object value = localComparatorCacheTemp.get(comparatorLabel);if (value == null) {try {if (DimensionSetting.DimensionFieldValueTypeEnum.NUMBER == dimensionSetting.getFieldValueType()) {value = Double.parseDouble(comparatorLabel);localComparatorCacheTemp.put(comparatorLabel, value);} else if (DimensionSetting.DimensionFieldValueTypeEnum.DATE == dimensionSetting.getFieldValueType()) {value = DateUtils.parse(comparatorLabel);localComparatorCacheTemp.put(comparatorLabel, value);} else {value = comparatorLabel;}} catch (Exception e) {log.error("对维度标签进行排序转换时出错: {}", e.getMessage(), e);return comparatorLabel;}}return value;}
}
localComparatorCache是一个局部缓存,维度计算完成后便会被移除。在对维度值进行解析时,通过在前端传递此维度值的类型,这样,我们便可以不用执行尝试解析维度值类型,也就不用创建额外的对象。
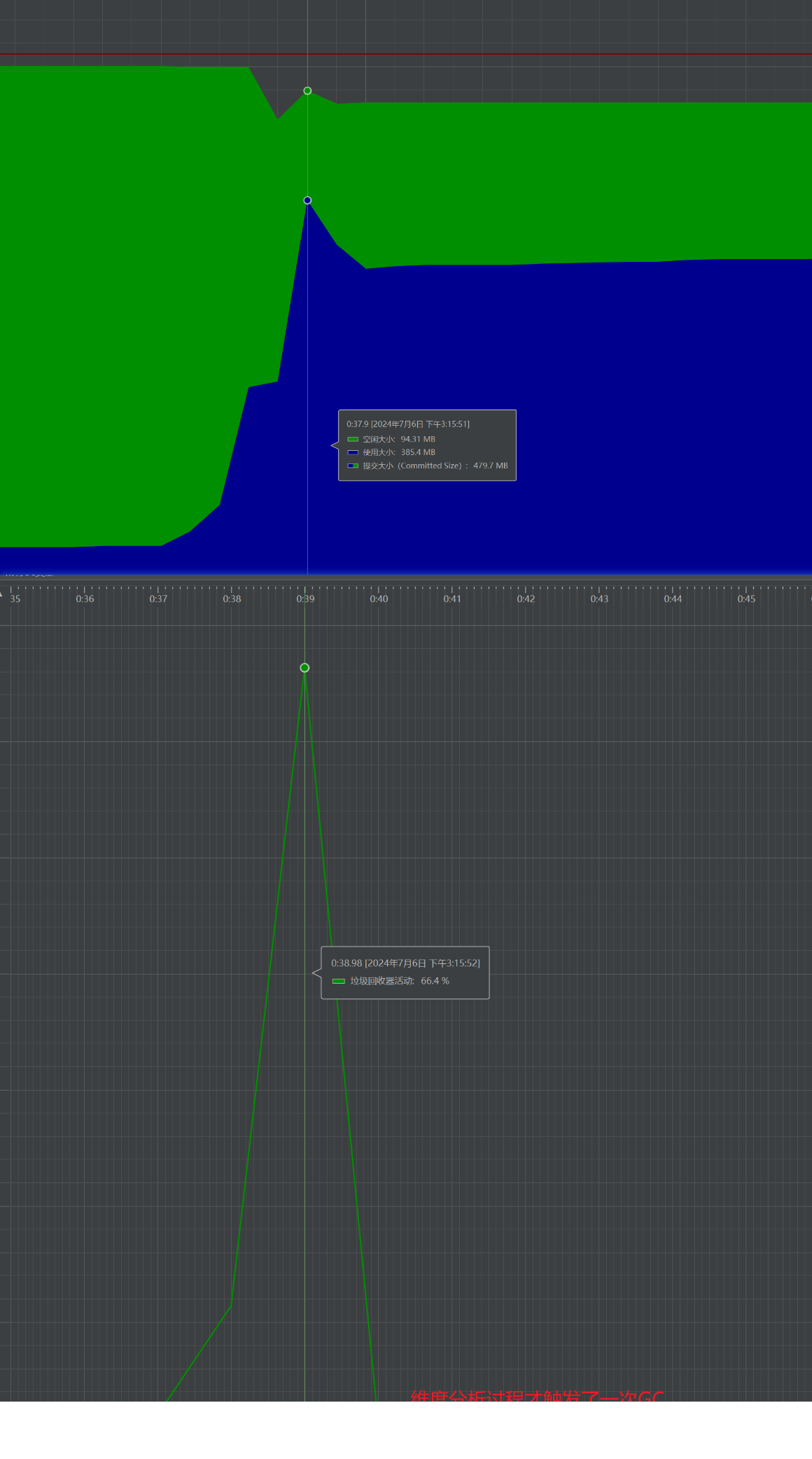
优化之后的运行结果为:
JVM优化前后对比:
| 优化前 | 优化后 | |
|---|---|---|
| GC次数 | 每次执行compare,平均触发3次 | 全部执行完才触发1次 |
指标优化
优化1
指标部分相对于维度部分来说,比较复杂,因为会涉及到数据过滤,四则运算,公式解析等,这部分是采用多线程方法运行的。
先看一下优化前的运行日志(耗时同样很感人):
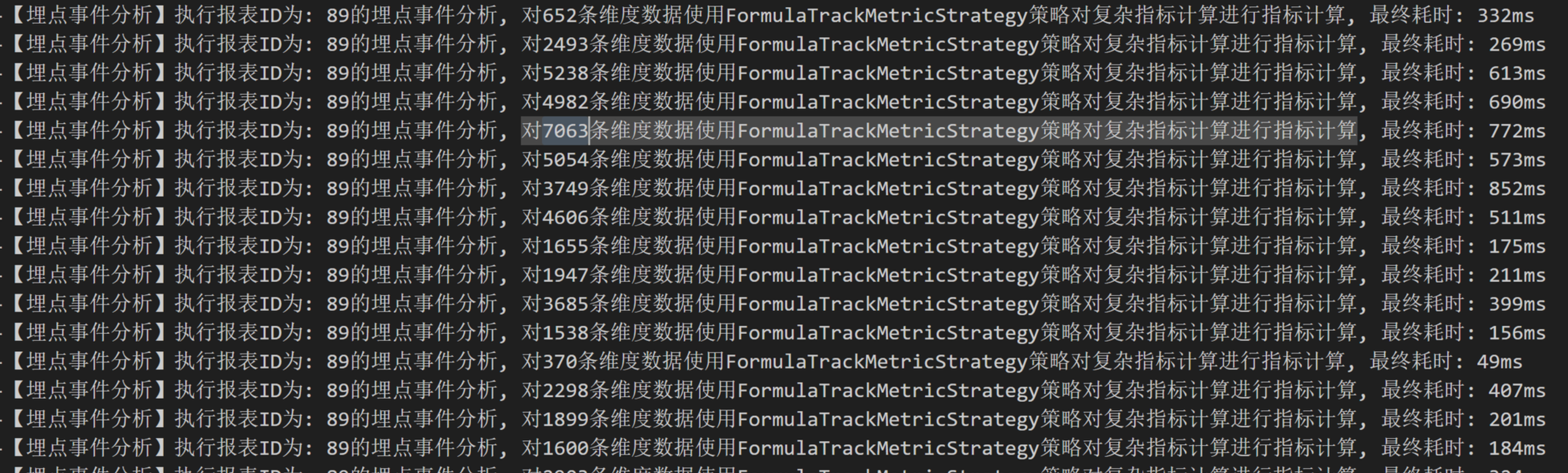
入口方法:
public List<DimensionMetricData> doQuery(MetricSetting metricSetting, List<DimensionData> dimensionDataList, int leftOffset, int rightOffset) {// 查询事件参数集合for (int i = leftOffset; i <= rightOffset; i++) {DimensionData dimensionData = dimensionDataList.get(i);TrackDataCalculatorDTO trackDataCalculator = new TrackDataCalculatorDTO();trackDataCalculator.setPrecomputeTrackDataList(dimensionData.getTrackDataList());// 存在性能问题MetricCalculator metricCalculator = new TrackFormulaMetricCalculator(metricSetting, dimensionData);Double metricValue = (Double) metricCalculator.calculate(trackDataCalculator);// 存在性能问题String formatValue = MathUtils.doubleFormat(metricValue, metricSetting.getMaximumFractionDigits());// 其余代码}
}// MathUtils.java
public class MathUtils {/*** 格式化小数点*/public static String doubleFormat(double num1, int maximumFractionDigits) {return numberFormat(getFormatPattern(maximumFractionDigits), num1);}private static String getFormatPattern(int maximumFractionDigits) {StringBuilder format = new StringBuilder("#.");for (int i = 0; i < maximumFractionDigits; i++) {format.append("#");}return format.toString();}private static String numberFormat(String pattern, double num) {NumberFormat instance = NumberFormat.getInstance(Locale.CHINA);if (!(instance instanceof DecimalFormat)) {throw new XcyeOtherException("Unexpected NumberFormat implementation");}DecimalFormat decimalFormat = (DecimalFormat) instance;decimalFormat.setRoundingMode(RoundingMode.DOWN);decimalFormat.applyPattern(pattern);return decimalFormat.format(num);}
}
上面代码并不是导致指标计算耗时高的原因,我这里贴出来,是为了在不影响系统正常运行的情况下,可以优化的点。
从上面代码可以看到,在for循环中创建都创建了TrackFormulaMetricCalculator和TrackDataCalculatorDTO对象,TrackDataCalculatorDTO对象创建的目的是为了封装一些计算所需要的参数,创建TrackFormulaMetricCalculator是为了实例化一个公式计算器,并且通过构造方法传递一些参数。
初步理解上面的代码好像没有问题,但是再加上for循环并且doQuery在被调用多次的情况下,那么上面的代码,同样会存在运行过程中创建大量对象的问题,如果堆大小分配不高的情况下,那必然会触发GC。
TrackFormulaMetricCalculator#calculate()方法的执行需要依赖于几个对象,但是并没有其它的类需要从TrackFormulaMetricCalculator类中获取任何属性变量,也就是说TrackFormulaMetricCalculator类可以完全当作一个工具类或者是静态类使用,或者说这种类所对应的对象是线程安全的,可以在任何地方调用对象中的方法(前提是方法不需要依赖于对象内的属性)。
基于上面的分析以及场景,我将TrackFormulaMetricCalculator类中的属性字段都移除,这些字段通过向calculate方法传参的方式进行传递,这样,TrackFormulaMetricCalculator类就可以创建一个常量对象。
对于 TrackDataCalculatorDTO类来说,该类的作用便是存储方法执行过程中,产生的非返回值数据,但是因为doQuery方法内的局部变量是线程安全的,所以可以在doQuery方法中,控制TrackDataCalculatorDTO类只被new一次。
工具类MathUtils中存在的问题为,getFormatPattern(int maximumFractionDigits)方法每次调用的时候,都会构造一个新的字符,然而小数点一般只会有1到4个,所以我们可以将getFormatPattern方法改为,先从缓存中获取指定小数点长度的pattern字符,如果没有,再进行创建。
numberFormat方法同样可以改成走缓存的方式,先根据pattern从缓存中获取DecimalFormat,如果没有,再执行获取DecimalFormat,这样可以减少执行NumberFormat.getInstance的执行。
优化之后的代码为:
private static final MetricCalculator METRIC_FORMULA_CALCULATOR_INSTANCE = new TrackFormulaMetricCalculator();@Overridepublic List<DimensionMetricData> doQuery(MetricSetting metricSetting, List<DimensionData> dimensionDataList, int reportId,TrackEvent trackEvent, List<TrackParameter> trackParameterList) {TrackDataCalculatorDTO trackDataCalculator = new TrackDataCalculatorDTO();trackDataCalculator.setReportId(reportId);// 查询事件参数集合for (DimensionData dimensionData : dimensionDataList) {trackDataCalculator.setPrecomputeTrackDataList(dimensionData.getTrackDataList());trackDataCalculator.setDimensionData(dimensionData);trackDataCalculator.setMetricSetting(metricSetting);trackDataCalculator.setTrackParameterList(trackParameterList);Double metricValue = (Double) METRIC_FORMULA_CALCULATOR_INSTANCE.calculate(trackDataCalculator);String formatValue = MathUtils.doubleToPercent(metricValue, metricSetting.getMaximumFractionDigits());// 其它代码}}
// MathUtil.java
public class MathUtils {private static final ConcurrentHashMap<Integer, String> FORMAT_PATTERN_CACHE = new ConcurrentHashMap<>();private static final ConcurrentHashMap<String, DecimalFormat> DECIMAL_FORMAT_CACHE = new ConcurrentHashMap<>();public static String doubleFormat(double num1, int maximumFractionDigits) {return numberFormat(getFormatPattern(maximumFractionDigits), num1);}public static String doubleToPercent(double num1, int maximumFractionDigits) {String formatPattern = getFormatPattern(maximumFractionDigits);if (!StringUtils.hasLength(formatPattern)) {formatPattern = ".#";}return numberFormat(formatPattern + "%", num1);}private static String getFormatPattern(int maximumFractionDigits) {String formatCache = FORMAT_PATTERN_CACHE.get(maximumFractionDigits);if (StringUtils.hasLength(formatCache)) {return formatCache;}StringBuilder format = new StringBuilder("#.");for (int i = 0; i < maximumFractionDigits; i++) {format.append("#");}formatCache = format.toString();FORMAT_PATTERN_CACHE.put(maximumFractionDigits, formatCache);return formatCache;}private static String numberFormat(String pattern, double num) {DecimalFormat decimalFormat = DECIMAL_FORMAT_CACHE.get(pattern);if (decimalFormat == null) {NumberFormat numberFormat = NumberFormat.getInstance(Locale.CHINA);if (!(numberFormat instanceof DecimalFormat)) {throw new XcyeOtherException("Unexpected NumberFormat implementation");}decimalFormat = (DecimalFormat) numberFormat;decimalFormat.setRoundingMode(RoundingMode.DOWN);decimalFormat.applyPattern(pattern);DECIMAL_FORMAT_CACHE.put(pattern, decimalFormat);}return decimalFormat.format(num);}
}
优化2
核心计算指标数据的方法是calculate,该方法代码为:
public class TrackFormulaMetricCalculator {
public Double calculate(TrackDataCalculatorDTO trackDataCalculator) {// 指标计算公式String formula = metricSetting.getFormula();List<String> formulaElementList = metricSetting.getFormulaElementList();// 根据公式组合Aviator参数Map<String, Object> env = new HashMap<>();Map<String, String> adapterAviatorFormulaElementMap = adapterAviatorFormulaElementMap(formulaElementList);for (String formulaElement : formulaElementList) {// 判断是否是内置的公式元素if (INTERNAL_FORMULA_ELEMENT_SET.contains(formulaElement)) {continue;}// 解析公式表达式FormulaExpression formulaExpression = resolveFormulaExpression(formulaElement);// 计算Double computeValue = computeFormulaResult(formulaExpression, dimensionData, trackDataCalculator);env.put(adapterAviatorFormulaElementMap.get(formulaElement), computeValue);}formulaElementList.sort((s1, s2) -> {boolean s1Status = s1.contains("{");boolean s2Status = s2.contains("{");if (s1Status && s2Status) {return s2.length() - s1.length();}if (s1Status) {return -1;}if (s2Status) {return 1;}return s2.length() - s1.length();});// 公式替换for (String formulaElement : formulaElementList) {if (INTERNAL_FORMULA_ELEMENT_SET.contains(formulaElement)) {continue;}formula = formula.replace(formulaElement, adapterAviatorFormulaElementMap.get(formulaElement));}Expression expression = null;try {expression = instance.compile(formula, false);} catch (Exception e) {log.error(e.getMessage(), e);throw new XcyeOtherException("编译公式: " + formula + "失败!");}Object executeResult = expression.execute(env);// 将值转换为Double类型return parseDouble(executeResult);}
}
上面代码所执行的方法比较多,我们无法一眼就看出问题所在,这里可以借助阿里巴巴的Arthas工具,查看类中每个方法的耗时。
启动Arthas之后,通过trace命令对calculate,computeFormulaResult,filterTrackDataByConditionalExpress这几个方法进行跟踪。
`---ts=2024-07-06 18:23:38;thread_name=xxx-track-event-metric-compute-7;id=508;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@50a095cb`---[0.7025ms] xxx.calculator.TrackFormulaMetricCalculator:calculate()`---[99.19% 0.6968ms ] xxx.calculator.TrackFormulaMetricCalculator:calculate() #39`---[99.17% 0.691ms ] xxx.calculator.TrackFormulaMetricCalculator:calculate()+---[0.41% 0.0028ms ] xxx.entity.dto.MetricSettingDTO:getFormula() #100+---[0.30% 0.0021ms ] xxx.entity.dto.MetricSettingDTO:getFormulaElementList() #101+---[0.96% 0.0066ms ] xxx.calculator.TrackFormulaMetricCalculator:adapterAviatorFormulaElementMap() #105+---[8.41% min=0.0117ms,max=0.0318ms,total=0.0581ms,count=3] xxx.calculator.TrackFormulaMetricCalculator:resolveFormulaExpression() #113+---[29.87% min=0.0409ms,max=0.1144ms,total=0.2064ms,count=3] xxx.calculator.TrackFormulaMetricCalculator:computeFormulaResult() #116| `---[90.99% min=0.0349ms,max=0.1079ms,total=0.1878ms,count=3] xxx.calculator.TrackFormulaMetricCalculator:computeFormulaResult()| +---[2.77% min=0.0017ms,max=0.0018ms,total=0.0052ms,count=3] xxx.entity.analyse.DimensionData:getTrackDataList() #282| +---[58.15% min=0.0078ms,max=0.0935ms,total=0.1092ms,count=3] xxx.calculator.TrackFormulaMetricCalculator:filterTrackDataByConditionalExpress() #281| | `---[84.34% min=0.0024ms,max=0.0873ms,total=0.0921ms,count=3] xxx.calculator.TrackFormulaMetricCalculator:filterTrackDataByConditionalExpress()| | +---[2.06% 0.0019ms ] xxx.entity.dto.MultiConditionExpressDTO:getConditionList() #315| | +---[78.39% 0.0722ms ] xxx.util.TrackDataFilterUtil:filter() #322| | `---[2.71% 0.0025ms ] xxx.xxx.service.platform.po.TrackParameter:getType() #324| +---[3.19% min=0.0019ms,max=0.0022ms,total=0.006ms,count=3] xxx.entity.dto.TrackDataCalculatorDTO:setFinallyComputeTrackDataList() #283| +---[3.57% min=0.0032ms,max=0.0035ms,total=0.0067ms,count=2] xxx.calculator.FormulaCalculateFactory:createFormulaCalculateFactory() #291| `---[10.06% min=0.0047ms,max=0.0142ms,total=0.0189ms,count=2] xxx.calculator.strategy.FormulaCalculateStrategy:calculate() #292+---[49.58% 0.3426ms ] com.googlecode.aviator.AviatorEvaluatorInstance:compile() #145+---[2.13% 0.0147ms ] com.googlecode.aviator.Expression:execute() #150`---[0.82% 0.0057ms ] xxx.calculator.TrackFormulaMetricCalculator:parseDouble() #152
如何通过Arthas寻找到突破口?
可以对跟踪结果进行分析,重点关注,调用耗时高的那些方法。
从上面可以看到,在执行calculate方法时,在computeFormulaResult和AviatorEvaluatorInstance:compile()方法上花费了太多时间。
先来分析computeFormulaResult方法,该方法执行过程中,58%的时候花在filterTrackDataByConditionalExpress()方法上,而该方法最终调用TrackDataFilterUtil#filter()。
使用trace -E TrackDataFilterUtil ‘filter|getFilterTrackDataExpress’ -n 20对该方法及内部其它方法进行跟踪,跟踪结果如下:
---ts=2024-07-06 18:42:48;thread_name=xxx-track-event-metric-compute-4;id=501;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@50a095cb`---[0.0843ms] xxx.xxx.util.TrackDataFilterUtil:filter()+---[17.08% 0.0144ms ] xxx.xxx.util.TrackDataFilterUtil:getFilterTrackDataExpress() #66| `---[78.47% 0.0113ms ] xxx.xxx.util.TrackDataFilterUtil:getFilterTrackDataExpress()| +---[29.20% 0.0033ms ] xxx.xxx.util.MultiConditionExpressUtil:parseMultiConditionExpressMap() #198| +---[10.62% 0.0012ms ] org.slf4j.Logger:isDebugEnabled() #200| `---[14.16% 0.0016ms ] com.googlecode.aviator.AviatorEvaluatorInstance:compile() #206`---[73.55% 0.062ms ] xxx.xxx.util.TrackDataFilterUtil:createMultiKeyMap()+---[12.26% 0.0076ms ] xxx.xxx.utils.object.MapUtils:convertObjToMap() #122+---[11.13% 0.0069ms ] xxx.xxx.util.TrackDataFilterUtil:createParamValueMap() #123+---[1.61% 0.001ms ] xxx.xxx.service.platform.po.TrackData:getOtherData() #125+---[5.00% 0.0031ms ] xxx.xxx.utils.json.JSONUtils:parseJsonToObj() #126+---[2.10% 0.0013ms ] xxx.entity.dto.TrackOtherDataAdminDTO:getRequestAddressInfo() #128+---[2.10% 0.0013ms ] xxx.entity.dto.TrackOtherDataAdminDTO:getOperationSystem() #129+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #135+---[1.61% 0.001ms ] xxx.entity.dto.TrackOtherDataAdminDTO$OperationSystem:getName() #140+---[1.61% 0.001ms ] xxx.entity.dto.TrackOtherDataAdminDTO$OperationSystem:getVersion() #141+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getIp() #144+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #146+---[1.61% 0.001ms ] xxx.xxx.utils.http.IpLocationUtil$LocationAddress:getCity() #146+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #148+---[1.45% 9.0E-4ms ] xxx.xxx.utils.http.IpLocationUtil$LocationAddress:getIsp() #148+---[1.94% 0.0012ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #150+---[1.61% 0.001ms ] xxx.xxx.utils.http.IpLocationUtil$LocationAddress:getCountry() #150+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #152+---[1.61% 0.001ms ] xxx.xxx.utils.http.IpLocationUtil$LocationAddress:getRegion() #152+---[1.77% 0.0011ms ] xxx.entity.dto.TrackOtherDataAdminDTO$RequestAddressInfo:getLocationAddress() #154`---[1.61% 0.001ms ] xxx.xxx.utils.http.IpLocationUtil$LocationAddress:getProvince() #154
从上面可以得到,导致TrackDataFilterUtil#filter方法执行慢的原因主要是是由于createMultiKeyMap方法以及getFilterTrackDataExpress方法,所以我们可以尝试对这两个方法进行优化,减少执行这两个方法所花费的时间。
别看上面filter方法耗时很小(感觉时间不太对,耗时不止这点),但是filter方法会被调用很多次,积少成多,也会对系统的性能造成影响。
parseMultiConditionExpressMap和AviatorEvaluatorInstance:compile是影响getFilterTrackDataExpress的主要因素,而AviatorEvaluatorInstance:compile方法因为Avator内部已经使用LRU进行了优化,而parseMultiConditionExpressMap方法的主要逻辑是对参数进行解析,从中拼接出最终的表达式,如果要优化的话,就只能使用缓存的方式,我最终因为一些因素,并没有对该方法进行优化。
现在就只剩下createMultiKeyMap方法了,该方法代码为:
// 优化前
private static Map<String, Object> createMultiKeyMap(TrackData trackData,Map<String, TrackParameter> eventParameterMap) {Map<String, Object> resultMap = MapUtils.convertObjToMap(trackData);createParamValueMap(trackData, eventParameterMap, resultMap);String otherDataJson = trackData.getOtherData();TrackOtherDataAdminDTO otherData = JSONUtils.parseJsonToObj(otherDataJson, TrackOtherDataAdminDTO.class);// 其余代码
}// 优化后
private static Map<String, Object> createMultiKeyMap(TrackDataDTO trackData,Map<String, TrackParameter> eventParameterMap) {Map<String, Object> resultMap = MapUtils.convertObjToMap(trackData);createParamValueMap(trackData, eventParameterMap, resultMap);TrackOtherDataAdminDTO otherData = trackData.getTrackOtherDataAdmin();// 其余代码
}
上述优化的思想为,通过跟踪发现在将json反序列化为TrackOtherDataAdminDTO时,比较耗时,然后又因为TrackData对象,在从数据库加载到内存之后,后续的所有过程中都不会对TrackData中的数据进行修改,因为该类中的otherData和value字段的值都是json类型并且这两个json反序列化后的数据,在计算的过程会被经常使用但不会对其进行修改。
之前的逻辑都是在使用otherData和value数据时,执行反序列化操作,所以会存在重复的反序列化过程。
优化后,在数据从数据库加载到内存之后,便对TrackData中的otherData和value字段按需反序列化,将反序列后的值存储到TrackData的子类TrackDataDTO中,这样便减少了重复的反序列化过程。
通过上面的优化,优化前后变化如下:
数据库
限制单次查询最大条数
报表分析这个功能,我是一次性便将所有数据从数据库加载到内存中进行计算。测试发现,加载17万条数据大概要占用250多M堆内存,再加上后续计算过程中产生的新对象以及其它接口的使用,我们需要合理的分配堆内存的大小。必须要限制单次最大查询条数。
如果担心设置的最大查询条数和当前堆内存大小不匹配,可以试试动态的方式。通过公式最大条数 = (Xmx - 预留堆内存大小) * 1024 * 1024 / 单个SQL映射的实体类对象大小动态获取单次查询的最大条数,这样也不用担心,在堆内存很大但是单次查询条数很小的情况发生。
可以使用
ClassLayout类计算实体类对象大小,如果想要计算一个类的最终大小,还需要对实体类中的字段也进行计算(对象中的字段只存储引用值)。
使用其它数据库
我们目前是将埋点数据存储到MySQL中,并且在存储的时候,是将上报的数据序列化成JSON格式,保存在value字段中,在使用时,在进行反序列化操作。
这样就导致了在从数据库中查询埋点数据时,我们没办法利用SQL的方式,只返回JSON数据中的部分key(MySQL应该是可以在查询时将string转成JSON操作)。
如果我们可以做到这点的话,那么在查询数据时,便可以按需查询,在一定程度上,可以降低内存的开销。可以将埋点数据保存值非关系型数据库(MySQL也支持JSON存储),比如MongoDB。
响应体优化
响应体优化也是必不可少的一部分。特别是对于响应体比较大&服务器带宽小等情况,我觉得响应体优化是必须的。
响应体优化措施有:
- 选择合适的响应体格式。
- 使用分页。
- 如果是JSON等类似格式,如果存在大量相同的key时,可以减少key的长度。
- 移除不需要的字段。
对于报表分析来说,响应体格式我使用的时JSON,存在大量重复的key,所以我将这些重复的key尽可能的缩短(如果真这样做,就不必考虑可读性,在代码中把注释写好就行),以及移除了那些前端不会使用的key。
优化前后响应体对比(未开gzip压缩,ApiFox工具):
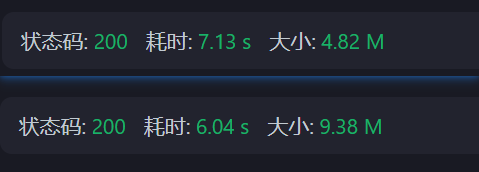
4.82M是将长key缩短为两三个字母的结果
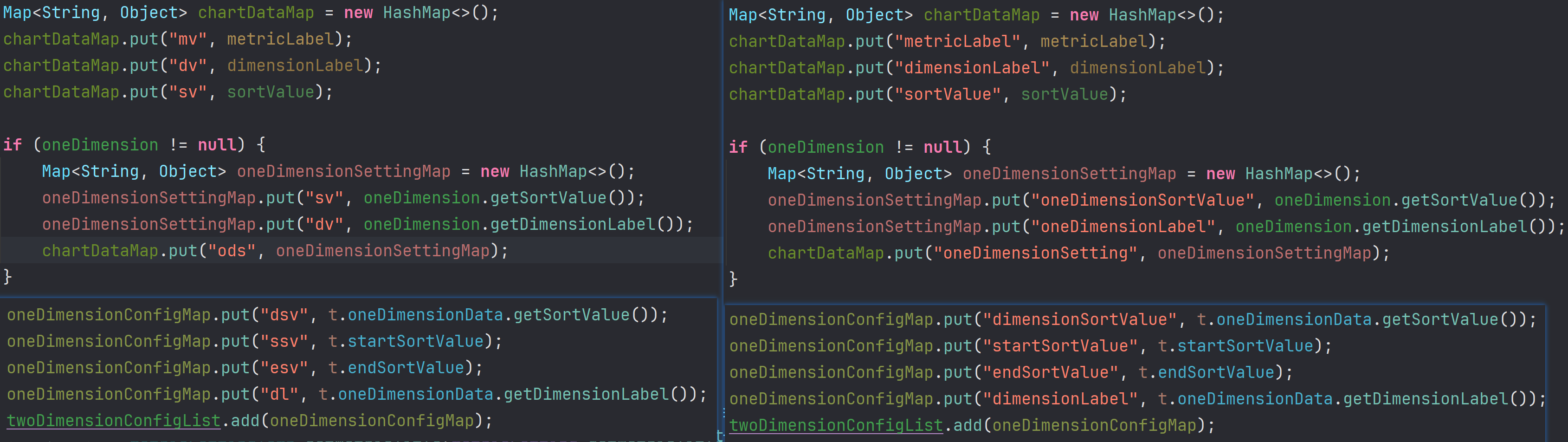
从上面可以看出,我们只是对响应体的key作一些改变,便可以将响应体大小降低50%左右,如果再加上响应体压缩,对响应时间的提升肯定是巨大的。
响应体优化这里,我还想到一个点,但是最终的收益可能就不好说。如果数据比较多,重复度也比较高的情况下,那是不是可以将多条重复的数据整合成一条,也就是后端只返回一条,通过使用其它数据比较小的字段向前端说明,但是这样,可能操作起来比较复杂。
启用自动压缩
因为报表分析结果需要发送给前端进行展示,响应体的内容也比较大。如果对几十万条数据进行分析,在不压缩情况下,响应体可能会有几十M。
在SpringBoot中,如果要开启响应体压缩,只需要在配置文件中加上
server:compression:enabled: truemime-types: application/jsonmin-response-size: 2097152 # 单位byte
并不需要在响应头上增加额外的配置。启用响应体压缩前后对比:

开启响应体压缩的情况下,响应体大小从5.1M降到654Kb。
缓存
缓存大家一定不会忘记,这里我就不多说了。
JVM
增大堆内存大小
如果需要从数据库加载大量的数据到内存中进行计算,我们必须要仔细的设置堆内存大小。如果堆内存设置得比较小,容易发生OOM,就算没有发生OOM,也可能会存在,90%以上时间都用于GC回收。
JVM字符串去重
在报表分析这个功能中,在计算维度和指标值时,会需要使用到埋点数据中的的某个字段值,然而目前是使用MySQL存储,存储的时候,是将埋点数据转成JSON字符存储的,在使用的过程中,再将JSON反序列化成其它对象,比如POJO,Map等。
反序列化这个过程可能会执行多次,也就是会存在将{\"name\": \"xcye\", \"age\": 12,\"site\" :\"www\"}进行多次解析,那么便会存在,相同字符存在多份的情况。这些重复的字符串同样会占据在堆内存中,在触发GC时,因为这些对象还在被使用,根据可达性原理,是无法被回收的。
既然如此,如果可以在GC的时候,能够对重复的字符串进行去重,那么在GC后,便可以释放更多的堆内存,特别是对于,频繁反序列化的场景。
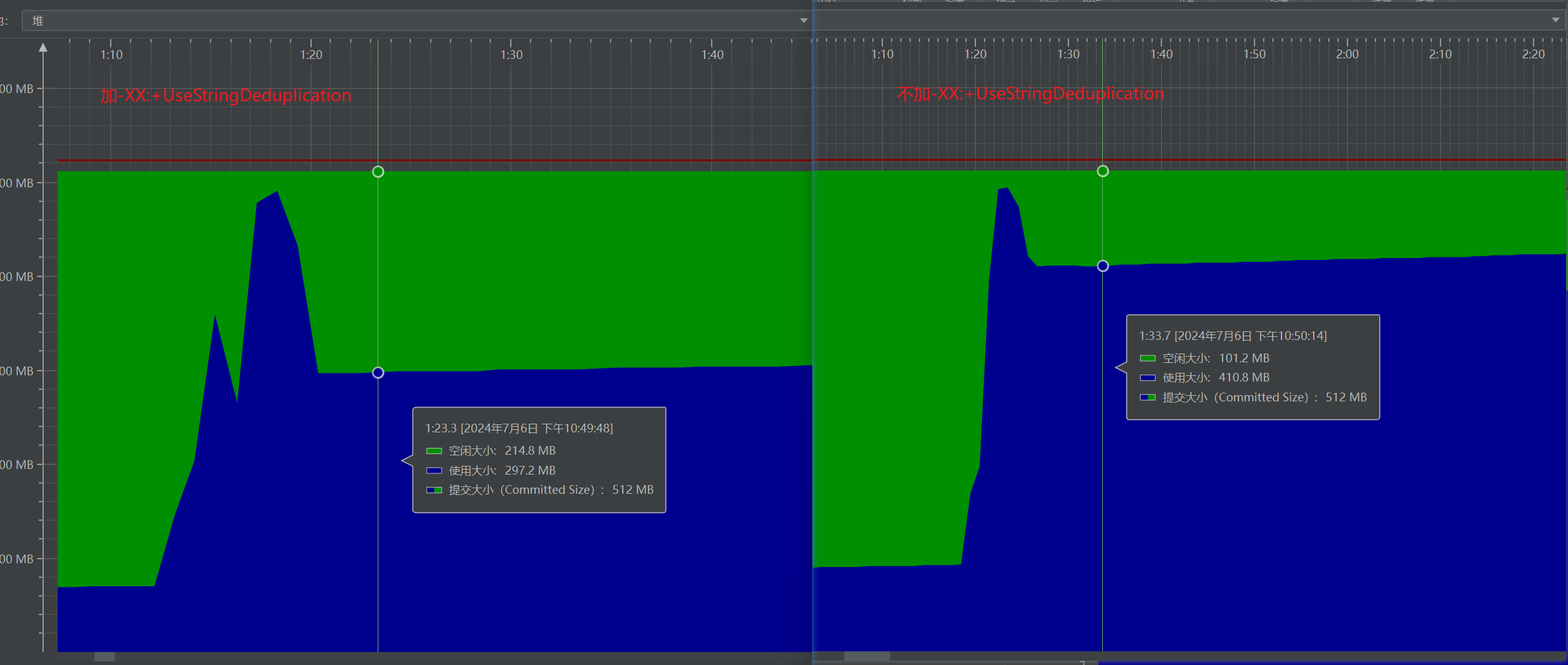
在G1收集器中提供了这个功能,可以使用-XX:+UseStringDeduplication参数开启这个功能,该选项默认情况下是被禁用的,-XX:+PrintStringDeduplicationStatistics参数可以打印字符串去重的统计信息。据介绍,字符串去重可以降低10%的堆内存压力。其基本原理是,许多字符串都是完全相同的,因此可以让这些字符串对象共享同一个字符数组,而不是每个字符串对象都有自己的字符数组。
https://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html
因为在这个功能中,在进行报表分析的时候,会存在很多重复的字符串,我选了其中一条去重结果,如下:
[GC concurrent-string-deduplication, 21.1M->2127.8K(19.0M), avg 79.6%, 0.0448218 secs][Last Exec: 0.0448218 secs, Idle: 0.1404486 secs, Blocked: 0/0.0000000 secs][Inspected: 224587][Skipped: 0( 0.0%)][Hashed: 224587(100.0%)][Known: 0( 0.0%)][New: 224587(100.0%) 21.1M][Deduplicated: 198174( 88.2%) 19.0M( 90.2%)][Young: 1( 0.0%) 24.0B( 0.0%)][Old: 198173(100.0%) 19.0M(100.0%)][Total Exec: 36/0.1176846 secs, Idle: 36/256.6703979 secs, Blocked: 35/0.0046191 secs][Inspected: 649023][Skipped: 0( 0.0%)][Hashed: 536577( 82.7%)][Known: 48610( 7.5%)][New: 600413( 92.5%) 70.3M][Deduplicated: 463019( 77.1%) 55.9M( 79.6%)][Young: 45391( 9.8%) 4292.6K( 7.5%)][Old: 417628( 90.2%) 51.8M( 92.5%)][Table][Memory Usage: 5256.4K][Size: 131072, Min: 1024, Max: 16777216][Entries: 180582, Load: 137.8%, Cached: 0, Added: 183780, Removed: 3198][Resize Count: 7, Shrink Threshold: 87381(66.7%), Grow Threshold: 262144(200.0%)][Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0][Age Threshold: 3][Queue][Dropped: 0]
上面这条去重记录发生在,首次对所有查询到的数据中的value和otherData(都是JSON)进行反序列化操作(转为Map和其它对象),存在大量的重复key和重复value。
通过上面的记录也可以看到,本次224587个字符串都是新产生的,其中88.2%的字符串都是重复的,去重结果为,从21.1M降低到2127.8K。【上述记录只代表一次去重,随着程序的执行,还会存在去重操作】
通过JProfiler我们也可以观察到启用和禁用-XX:+UseStringDeduplication时的堆内存情况:
总结
通过这次事故,让我认识到了平时开发时,增加新功能,修改代码过程中,一定要考虑全面,不能只考虑这部分代码的设计,还应该考虑到引入此功能或者修改,可能导致的影响。
在处理大数据量时(分析,导出等需求),如果功能自己测试已经通过了,一定要进行压测,在自己电脑上往死里测。看看极端情况下会发生什么,然后根据测试结果,进一步优化。
我自己在写工具类的时候,容易忽视此工具可能存在的性能或其它问题。所以,在编写工具类时,一定要考虑全面,至少要比写其它普通类更仔细(扩展问题,性能问题...)。