- Dataset简介及用法
- Map-style datasets类型
- Iterable-style datasets类型
- DataLoader简介及用法
Dataset 和 DataLoader 都 是 用 来 帮 助 我 们 加 载 数 据 集 的 两 个 重 要 工 具类。 Dataset 用来构造支持索引的数据集。
在训练时需要在全部样本中拿出小批量数据参与每次的训练,因此我们需要使用 DataLoader ,即 DataLoader 是用来在 Dataset 里取出一组数据 (mini-batch)供训练时快速使用的。
Dataset简介及用法
Dataset 本质上就是一个抽象类,可以把数据封装成 Python 可以识别的数据结构。Dataset 类不能实例化,所以在使用 Dataset 的时候,我们需要定义自己的数据集类,也是 Dataset 的子类,来继承 Dataset 类的属性和方法。Dataset 可作为 DataLoader 的参数传入 DataLoader ,实现基于张量的数据预处理。Dataset 主要有两种类型,分别为 Map-style datasets 和 Iterable-style datasets 。
Map-style datasets类型
该类型实现了 getitem() 和 len() 方法,它代表数据的索引到真正数据样本的映射。也就是说,使用这种方式读取的数据并非直接直接把所有数据读取出来,而是读取数据的索引或者键值。其中,列表或者数组类型的数据读取的就是索引,而字典类型的数据读取的就是键值。在访问时,用dataset[idx]访问idx对应的真实数据。这种类型的数据也是使用最多的类型。
Iterable-style datasets类型
该类型实现了 iter() 方法,与上述类型不同之处在于,他会将真实的数据全部载入,然后在整个数据集上进行迭代。如果随机读取的情况不能实现或者代价太大就用这种读取方式。这种读取数据的方式比较适合处理流数据
Dataset 作为一个抽象类,需要定义其子类来实例化。所以需要自己定义其子类或者使用已经定义好的子类。
(1)自定义子类
- 必须要继承已经内置的抽象类 dataset
- 必须要重写其中的 init() 方法、 getitem() 方法和 len() 方法
- 其中 getitem() 方法实现通过给定的索引遍历数据样本, len() 方法实现返回数据的条数
定义一个MyDataset类继承Dataset抽象类,其中pass为占位符,并且改写其中的三个方法
import torch
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self):passdef __getitem__(self, index):passdef __len__(self):pass
这里定义了一个MyDataset类继承Dataset抽象类,并且改写其中的三个方法。在创建的dataset类中可根据用户本身的需求对数据进行处理。可独立编写的数据处理函数,在__getitem__()函数中进行调用;或者直接将数据处理方法写在__getitem__()函数中或者__init__()函数中,但__getitem__()函数必须根据index返回响应的值,该值会通过index传到DataLoader中进行厚涂的Batch批量处理。
在创建的dataset类中可根据自己的需求对数据进行处理,以时间序列使用为示例,输入3个时间步,输出1个时间步,batch_size=5
import torch
from torch.utils.data import Datasetclass GetTrainTestData(Dataset):def __init__(self, input_len, output_len, train_rate, is_train=True):super().__init__()# 使用sin函数返回10000个时间序列,如果不自己构造数据,就使用numpy,pandas等读取自己的数据为x即可。# 以下数据组织这块既可以放在init方法里,也可以放在getitem方法里self.x = torch.sin(torch.arange(0, 1000, 0.1))self.sample_num = len(self.x)self.input_len = input_lenself.output_len = output_lenself.train_rate = train_rateself.src, self.trg = [], []if is_train:for i in range(int(self.sample_num*train_rate)-self.input_len-self.output_len):self.src.append(self.x[i:(i+input_len)])self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])else:for i in range(int(self.sample_num*train_rate), self.sample_num-self.input_len-self.output_len):self.src.append(self.x[i:(i+input_len)])self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])print(len(self.src), len(self.trg))def __getitem__(self, index):return self.src[index], self.trg[index]def __len__(self):return len(self.src) # 或者return len(self.trg), src和trg长度一样
实例化定义好的Dataset子类GetTrainTestData
data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True)
data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False)

(2)已经定义好的内置子类
除了自己定义子类继承Dataset外,还可以使用PyTorch提供的已经被定义好的子类,如TensorDataset和IterableDataset。
对 于 给 定 的 tensor 数 据 , TensorDataset 是 一 个 包 装 了 Tensor 的Dataset 子类,传入的参数就是张量,每个样本都可以通过 Tensor 第一个维度的索引获取,所以传入张量的第一个维度必须一致。
PyTorch官方给出的TensorDataset类的定义:
class TensorDataset(Dataset[Tuple[Tensor, ...]]):r"""Dataset wrapping tensors.Each sample will be retrieved by indexing tensors along the first dimension.Args:*tensors (Tensor): tensors that have the same size of the first dimension."""tensors: Tuple[Tensor, ...]def __init__(self, *tensors: Tensor) -> None:assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors), "Size mismatch between tensors"self.tensors = tensorsdef __getitem__(self, index):return tuple(tensor[index] for tensor in self.tensors)def __len__(self):return self.tensors[0].size(0)
所以这个类的实例化有两个参数,分别为data_tensor(Tensor)样本数据和target_tensor(Tensor)样本标签。
使用TensorDataset:
import torch
from torch.utils.data import TensorDatasetsrc = torch.sin(torch.arange(1, 1000, 0.1))
trg = torch.cos(torch.arange(1, 1000, 0.1))
于是可以直接实例化已定义好的Dataset子类TensorDataset
data = TensorDataset(src, trg)
DataLoader简介及用法
Dataset 和 DataLoader 是一起使用的,在模型训练的过程中不断为模型提供数据,同时,使用 Dataset 加载出来的数据集也是
DataLoader 的第一个参数。所以, DataLoader 本质上就是用来将已经加载好的数据以模型能够接收的方式输入到即将训练的模型中去。
几个深度学习模型训练时涉及的参数:
(1)Data_size:所有数据的样本数量。
(2)Batch_size:每个Batch加载多少个样本。
(3)Batch:每一批放进module训练的样本叫一个Batch。
(4)Epoch:模型把所有样本训练完毕一次叫做一个Epoch。
(5)Iteration:所有数据共分成了几个Batch,即训练几次才能够便利所有样本/数据。
(6)Shuffle:在抽取Batch之前是否将样本全部打乱顺序。
数据的输入过程如下图所示。

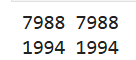
Data_size=10 , Batch_size=3 ,一次 Epoch 需要四次 Iteration ,第一列为所有样本,第二列为打乱之后的所有样本,由于 Batch_size=3 ,所以通过 DataLoader输入了 4 个 batch ,包括最后一个数量已经不够 3 个的 Batch4 ,里边只包含sample3
官方给出的DataLoader定义:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,batch_sampler=None, num_workers=0, collate_fn=None,pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None,*, prefetch_factor=2,persistent_workers=False)
参数说明:
dataset: 通过Dataset加载进来的数据集。
batch_size:每个Batch加载多少个样本。
shuffle: 是否打乱输入数据的顺序,设置为True时,调用RandomSample进行随机索引。
sampler: 定义从数据集中提取样本的策略,若指定,就不能用shuffle函数随机索引,其取值必须为False。
batch_sampler: 批量采样,每次返回一个Batch大小的索引,默认设置为None,和batch_size、shuffle等参数是互斥的。
num_workers: 用多少子进程加载数据。0表示数据将在主进程中加载,根据自己的计算资源配置选定。
collate_fn: 将一小段数据合并成数据列表以形成一个Batch。
pin_memory:是否在将张量返回之前将其复制到Cuda固定的内存中。
drop_last: 设置了batch_size的数目后,最后一批数据未必是设置的数目,有可能会小一些,这时需要丢弃这些数据。
timeout:设置数据表读取的超时时间,但超过这个时间还没读取到数据就会报错,不能为负。
worker_init_fn:是否在数据导入前和步长结束后根据工作子进程的ID逐个按照顺序导入数据,默认为None。
prefetch_factor:每个worker提前加载的Sample数量。
persistent_workers: 如果为True,DataLoader将不会终值worker进程,直到dataset迭代完成。
将Dataset读取的数据输入到DataLoader中。
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoaderclass GetTrainTestData(Dataset):def __init__(self, input_len, output_len, train_rate, is_train=True):super().__init__()# 使用sin函数返回10000个时间序列,如果不自己构造数据,就使用numpy,pandas等读取自己的数据为x即可。# 以下数据组织这块既可以放在init方法里,也可以放在getitem方法里self.x = torch.sin(torch.arange(1, 1000, 0.1))self.sample_num = len(self.x)self.input_len = input_lenself.output_len = output_lenself.train_rate = train_rateself.src, self.trg = [], []if is_train:for i in range(int(self.sample_num*train_rate)-self.input_len-self.output_len):self.src.append(self.x[i:(i+input_len)])self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])else:for i in range(int(self.sample_num*train_rate), self.sample_num-self.input_len-self.output_len):self.src.append(self.x[i:(i+input_len)])self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])print(len(self.src), len(self.trg))def __getitem__(self, index):return self.src[index], self.trg[index]def __len__(self):return len(self.src) # 或者return len(self.trg), src和trg长度一样data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True)
data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False)
data_loader_train = DataLoader(data_train, batch_size=5, shuffle=False)
data_loader_test = DataLoader(data_test, batch_size=5, shuffle=False)
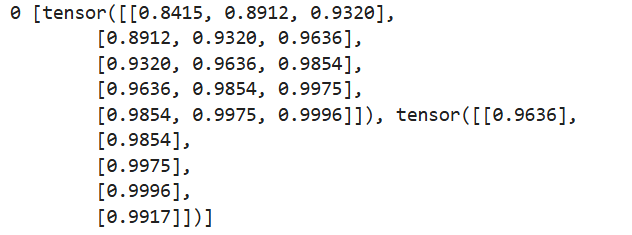
for idx, train in enumerate(data_loader_train):print(idx, train)break
文章推荐
| NumPy从入门到放弃 | https://mp.weixin.qq.com/s/EocThNWhQlI2zeLcUApsQQ |
|---|---|
| Pandas从入门到放弃 | https://mp.weixin.qq.com/s/mSkA5KvL1390Js8_1ZBiyw |
| SciPy从入门到放弃 | https://mp.weixin.qq.com/s/MulhzVRvWbaDUjfNPHN8qA |
| Scikit-learn从入门到放弃 | https://mp.weixin.qq.com/s/L0tKz9JFnsgrzSCXDswbRA |
| PyTorch从入门到放弃之张量模块 | https://www.cnblogs.com/kohler21/p/18392248 |
欢迎关注公众号:愚生浅末。