很少关注360开源的代码,最近360AI团队开源了最新视频模型FancyVideo,据说RTX3090可跑。可以在消费级显卡 (如 GeForce RTX 3090) 上生成任意分辨率、任意宽高比、不同风格、不同运动幅度的视频,其衍生模型还能够完成视频扩展、视频回溯的功能,一种基于 UNet 架构的视频生成模型。OK,让我们开始吧
一、模型介绍
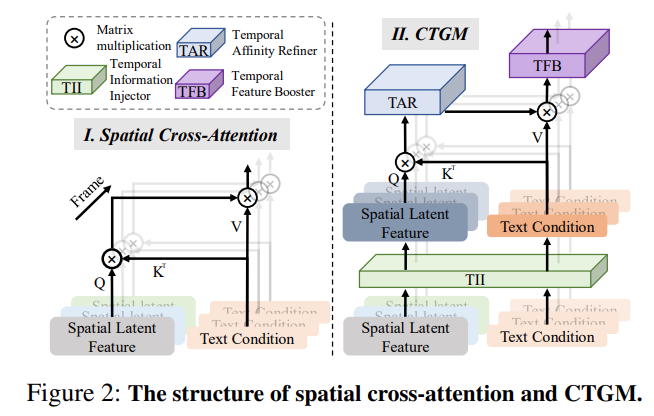
作者在进行视频生成研究过程中,发现现有的文本到视频(T2V)工作通常会采用空间交叉注意力(Spatial Cross Attention),将文本等价地引导至不同帧的生成过程中,缺乏对不同帧灵活性的文本引导(如下图左)。这会导致模型理解提示词所传达的时间逻辑和生成具有连续运动视频的能力受到限制。FancyVideo 正是从这一角度切入,特殊设计了跨帧文本引导模块(Cross-frame Textual Guidance Module, CTGM, 如下图右)改进了现有文本控制机制。
具体来说,CTGM 包含 3 个子模块:
(1)时序信息注入器(Temporal Information Injector, TII)-- 将来自潜在特征的帧特定信息注入文本条件中,从而获得跨帧文本条件;
(2)时序特征提取器(Temporal Affinity Refiner, TAR)-- 沿时间维度细化跨帧文本条件与潜在特征之间的相关矩阵;
(3)时序特征增强器(Temporal Feature Booster, TFB)-- 增强了潜在特征的时间一致性。
二、环境搭建
模型下载
目录结构如下:
📦 resouces/
├── 📂 models/
│ └── 📂 fancyvideo_ckpts/
│ └── 📂 CV-VAE/
│ └── 📂 res-adapter/
│ └── 📂 LongCLIP-L/
│ └── 📂 sd_v1-5_base_models/
│ └── 📂 stable-diffusion-v1-5/
├── 📂 demos/
│ └── 📂 reference_images/
│ └── 📂 test_prompts/
代码下载
git clone
环境安装
docker run --rm -it -v /datas/work/zzq/:/workspace --gpus=all pytorch/2.2.2-cuda12.1-cudnn8-devel bash
cd /workspace/FancyVedio/FancyVideo-main
修改requirements.txt包版本

pip install -r requirements.txt -i
三、推理测试
1、图生视频
CUDA_VISIBLE_DEVICES=0 PYTHONPATH=./ python scripts/demo.py --config configs/inference/i2v.yaml
2、文生视频
CUDA_VISIBLE_DEVICES=0 PYTHONPATH=./ python scripts/demo.py --config configs/inference/t2v_pixars.yaml

具体视频可在CSDN上查看,https://blog.csdn.net/zzq1989_/article/details/142062501?spm=1001.2014.3001.5502