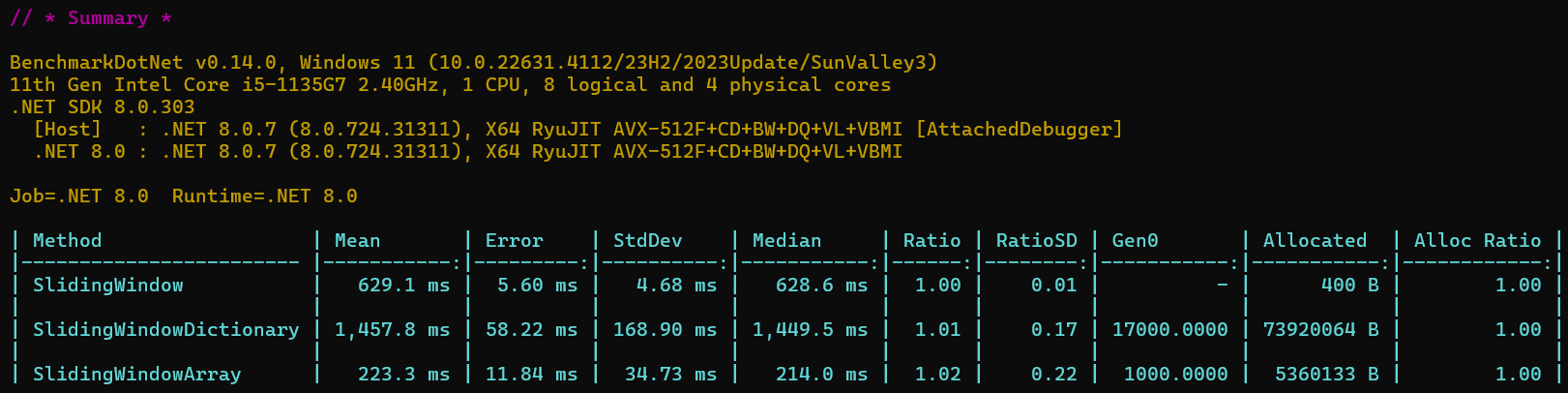
@
目录
- 前言
- 爬虫步骤
- 确定网址,发送请求
- 获取响应数据
- 对响应数据进行解析
- 保存数据
- 完整源码
- 共勉
- 博客
前言
本文写了一个爬取视频的案例,使用requests库爬取了好看视频的视频,并进行保存到本地。后续也会更新selenium篇和DrissionPage篇。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
爬虫步骤
确定网址,发送请求
我们打开我们需要爬取的网站后,按f12进行检查,因为页面采用的懒加载,所以我们需要往下滑加载新的视频,这时候就会出现新的数据包,这个数据包大概率就是这些新视频加载出来的来源,我们也可以在下图中的①中搜索视频数据包中可能出现的内容,例如视频的后缀,如MP4,m4s,ts等,然后再从中筛选正确的数据包,这个可能就需要有一定的经验。

当我们往下滑刷新的时候,再②中就会加载出新的数据包,点击数据包后,就会出现右边的窗口,在③标头中会看到我们要请求的url地址,以及cookie和一些加密后参数。
代码如下
import requests # 数据请求模块
url='https://haokan.baidu.com/haokan/ui-web/video/feed?time=1723964149093&hk_nonce=915ae0476c308b550e98f6196331fd2a&hk_timestamp=1723964149&hk_sign=93837eec50add65f7ca64a95fb4eb8de&hk_token=aRYZdAVwdwNwCnwBcHNyAAkNAQA' # 请求地址
headers={# UA伪装
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
html=requests.get(url,headers=headers)
获取响应数据
在响应里我们可以看到响应的json数据,里面有封面照片地址,标题,视频地址等等,我们只需要获取其中的图片名字(title)和图片地址(previewUrlHttp)即可。

respnose=html.json()
对响应数据进行解析
json数据是字典,所以我们只需要取其中的键就可以了。
data=html['data']['apiData'] # 取照片地址
for li in data:video_name=li['title'] # 照片名字video_url=li['previewUrlHttp'] # 照片地址
保存数据
获取到图片的url后只需要再对url进行请求,获取二进制数据,然后进行保存到本地。
video=requests.get(video_url,headers=headers).content # 对照片地址进行发送请求,获取二进制数据with open('./videos/'+video_name+'.mp4','wb') as f: # 保存视频f.write(video)
完整源码
import requests # 数据解析模块
import os # 文件管理模块if not os.path.exists("./videos"): # 创建文件夹os.mkdir("./videos")
url='https://haokan.baidu.com/haokan/ui-web/video/feed?time=1723964149093&hk_nonce=915ae0476c308b550e98f6196331fd2a&hk_timestamp=1723964149&hk_sign=93837eec50add65f7ca64a95fb4eb8de&hk_token=aRYZdAVwdwNwCnwBcHNyAAkNAQA' # 请求地址
headers={# UA伪装
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
html=requests.get(url,headers=headers).json()
data=html['data']['apiData'] # 取照片地址
for li in data:video_name=li['title'] # 照片名字video_url=li['previewUrlHttp'] # 照片地址video=requests.get(video_url,headers=headers).content # 对照片地址进行发送请求,获取二进制数据with open('./videos/'+video_name+'.mp4','wb') as f: # 保存视频f.write(video)print(video_name+'.mp4')多页爬取的就要多去观察数据包,有什么规律,再这个案例中,就涉及到了时间戳js加密。
共勉
少就是多 慢就是快
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。