使用Google Colab需要谷歌账号和一点点魔法。注册好账号,找到我的云盘,可以点击右上角的log 跳转。
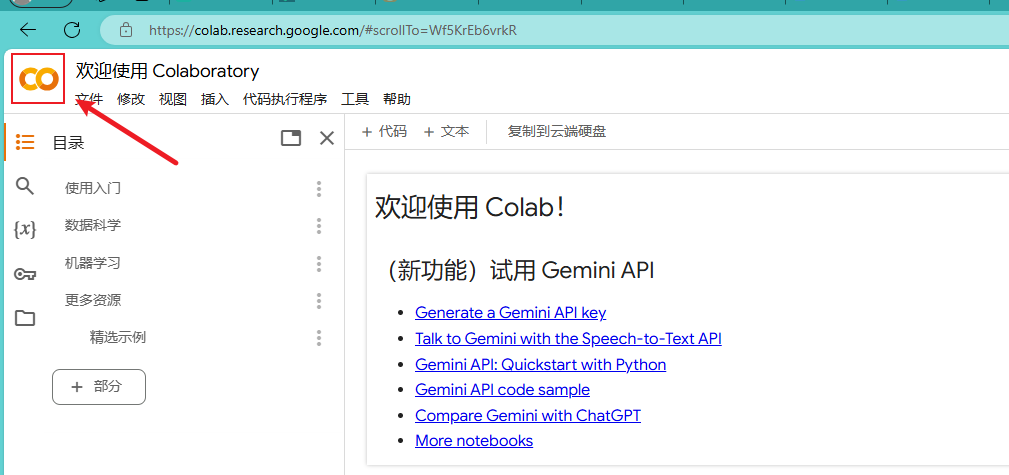
我的云端银盘这里可以选择上传文件还是文件夹,还可以新建文件夹然后在这个文件夹中选择你要上传的文件。
例如我这创建了一个train_test 的文件夹,然后上传了 test_ScVgIM0.zip 和 train_LbELtWX.zip 两个压缩文件,以及sample_submission_I5njJSF.csv(下面要用到这个,可以在analyticsvidhya 下载)
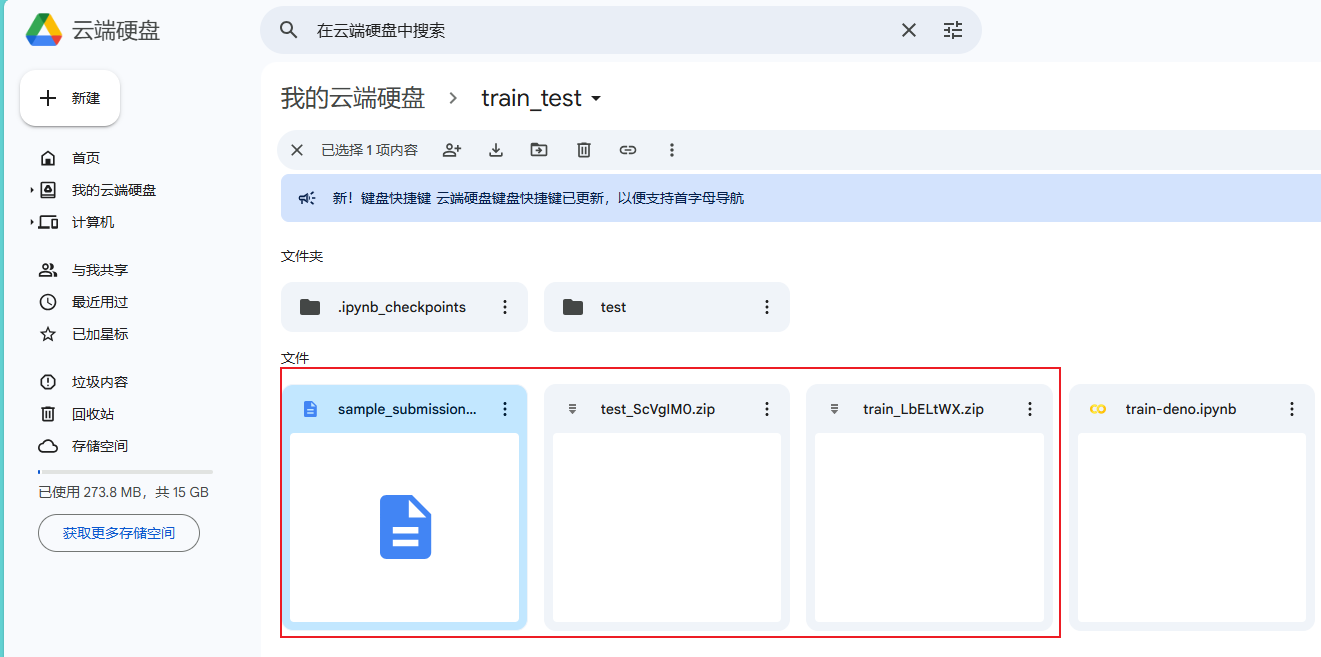
然后右键-->选择更多--->Googel Colaboratory,如果没有,选择关联跟多应用,安装一下Googel Colaboratory
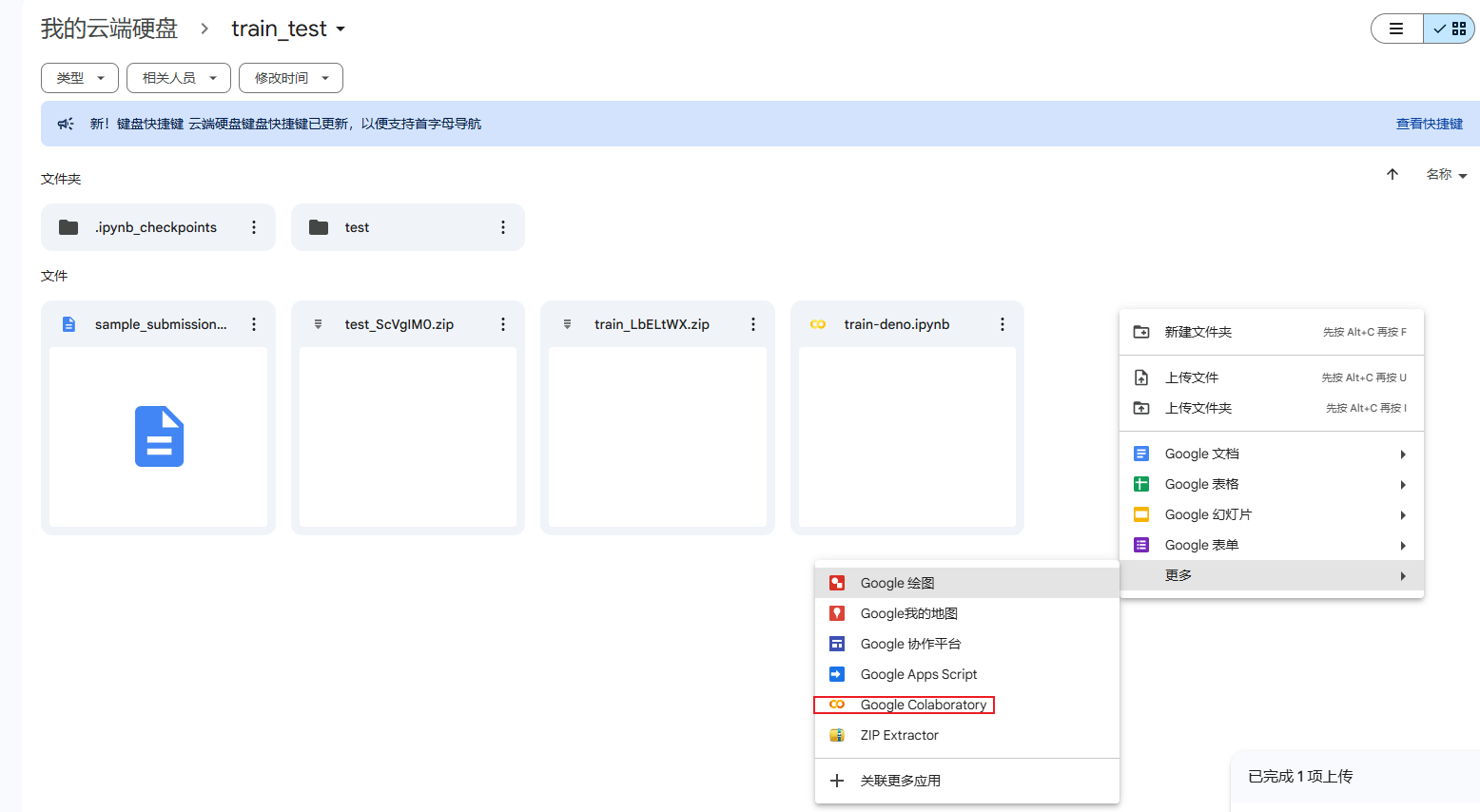
然后可以看到这个界面,这个就是和jupyter notebook 差不多的功能。

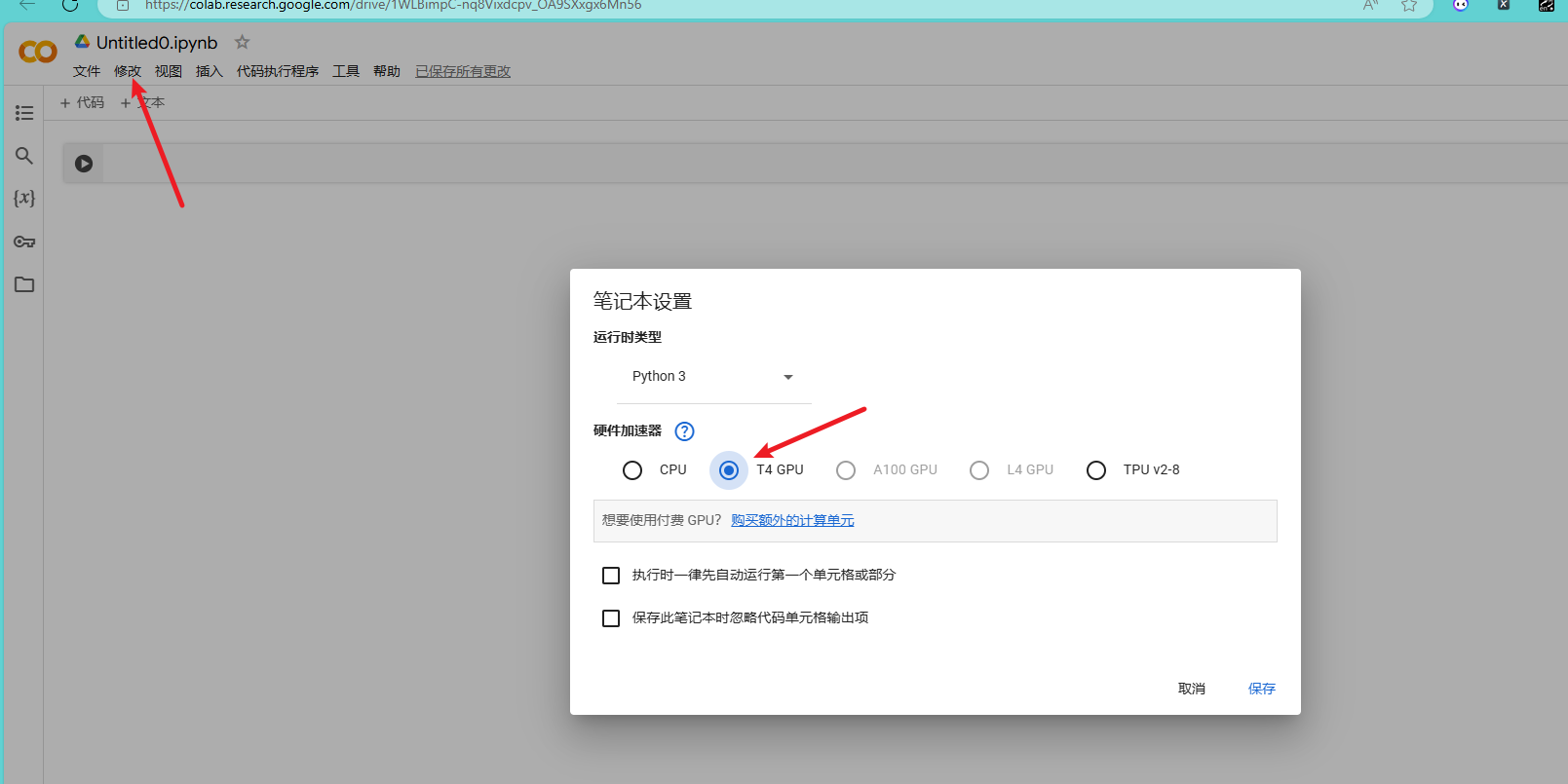
右上角 修改-->笔记本设置----> 选择GPU。
接下来就可以操作了。
1.挂载云盘
from google.colab import drive
# 挂载云盘
drive.mount('/content/drive/')
出现以下输出就证明挂载好了。

2.选择目录,可以在右侧看到云盘中的文件目录。
import os
# 选择哪一个文件夹
os.chdir("/content/drive/My Drive/train_test")
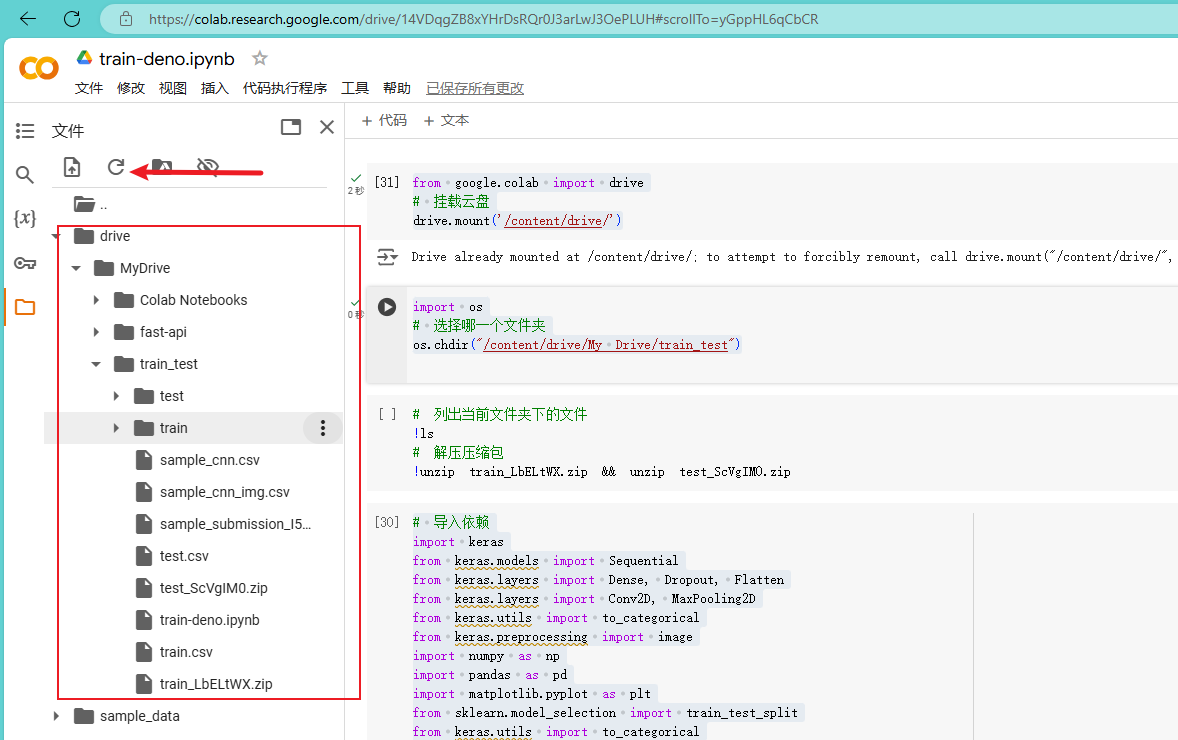
3.查看文件夹下的文件以及解压文件,这一步时间稍微要长一点。
# 列出当前文件夹下的文件
!ls
# 解压压缩包
!unzip train_LbELtWX.zip && unzip test_ScVgIM0.zip
4.导入必要的依赖文件
# 导入依赖
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import to_categorical
from keras.preprocessing import image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from tqdm import tqdm
5.主体代码,生成预测模型。
# 加载数据集
train = pd.read_csv('train.csv')
train_image = []
for i in tqdm(range(train.shape[0])):img = image.load_img('train/' + train['id'][i].astype('str') + '.png', target_size=(28, 28, 1),color_mode='grayscale')img = image.img_to_array(img)img = img / 255train_image.append(img)X = np.array(train_image)
y = train['label'].values
y = to_categorical(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
6.加载测试文件数据集.
# 加载测试文件数据集
test = pd.read_csv('test.csv')
test_image = []
for i in tqdm(range(test.shape[0])):img = image.load_img('test/' + test['id'][i].astype('str') + '.png', target_size=(28, 28, 1), color_mode='grayscale')img = image.img_to_array(img)img = img / 255test_image.append(img)# Convert the list to a NumPy array
test = np.array(test_image)
7.生成结果
# Making predictions
predictions = model.predict(test)
predicted_classes = np.argmax(predictions, axis=1) # Get the class labels from the predictions
# 保存结果集
sample = pd.read_csv('sample_submission_I5njJSF.csv')
sample['label'] = predicted_classes
sample.to_csv('sample_cnn_img.csv', header=True, index=False)
运行之后在右侧文件夹中会生成 sample_cnn_img.csv文件,这个就是预测结果集。
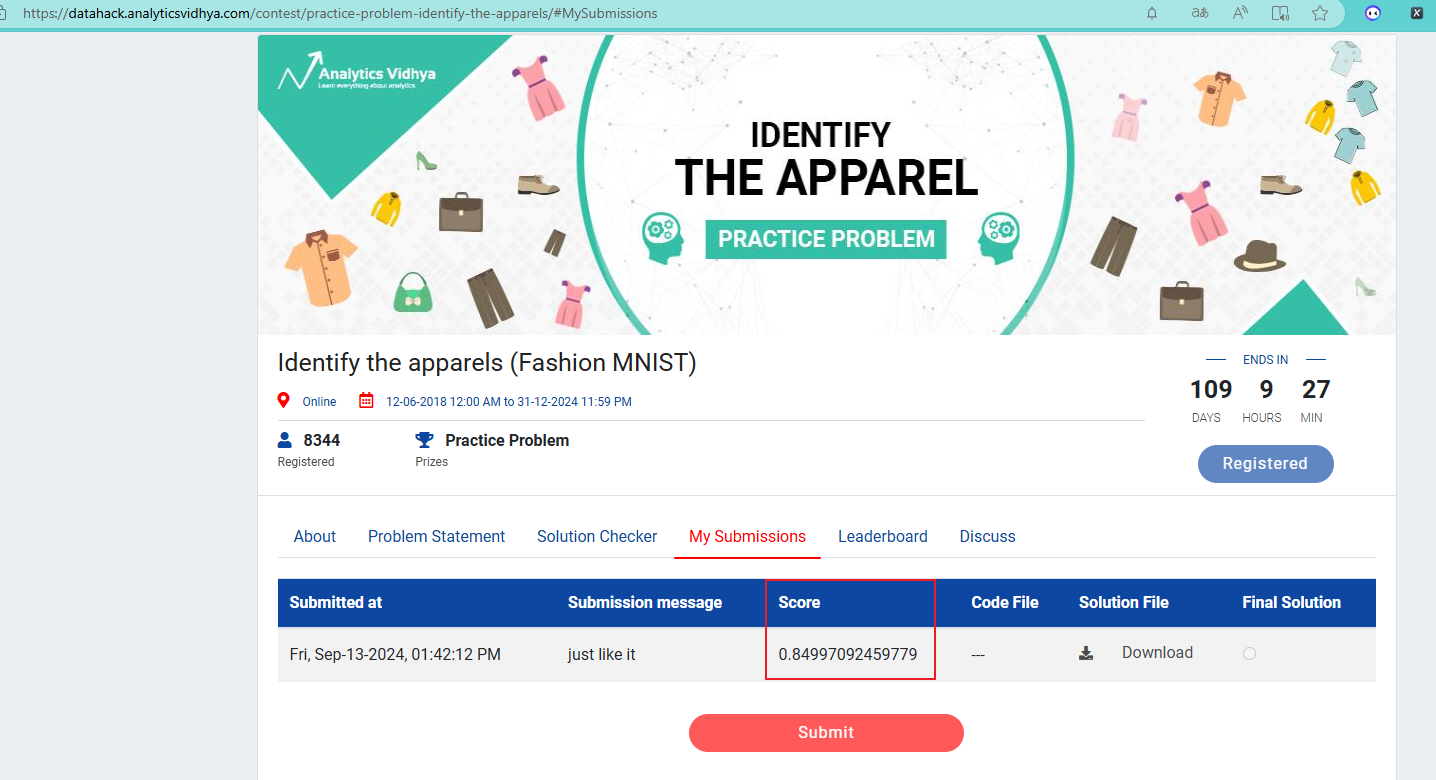
如果想要提交结果集看一下排名可以在这个连接下去 提交文件,score 就是你的分数。
参考链接:[Google Colab 基础操作](https://colab.research.google.com/notebooks/io.ipynb#scrollTo=bRFyEsdfBxJ9) 参考链接:[Google Colab免费GPU使用教程(一)](https://www.cnblogs.com/lfri/p/10471852.html) 参考链接:[10分钟搭建你的第一个图像识别模型(附步骤、代码)](https://www.jiqizhixin.com/articles/2019-02-20-9)