FCN是全卷积网络,用于做图像语义分割。通常将一般卷积网络最后的全连接层换成上采样或者反卷积网络,对图像的每个像素做分类,从而完成图像分割任务。
网络结构如下:
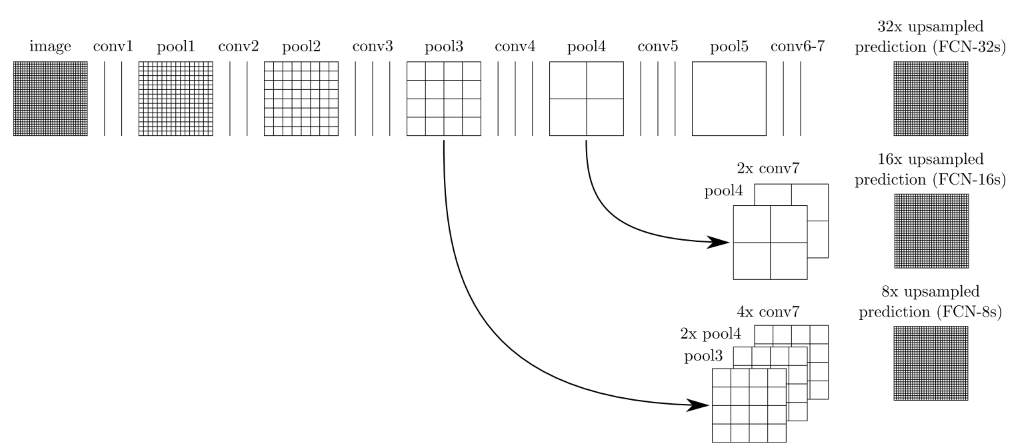
这里并没有完全按照原始网络结构实现,而是尝试upsample和convTranspose2d结合的方式,看看有什么效果。
下面代码是用VOC数据集做的语义分割,一共2000多张图片,21种类别,还是有一些效果的。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset,DataLoader from torchvision import transforms import os from PIL import Image import numpy as nptransform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])device = torch.device("cuda" if torch.cuda.is_available() else "cpu")colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],[64,128,0],[192,128,0],[64,0,128],[192,0,128],[64,128,128],[192,128,128],[0,64,0],[128,64,0],[0,192,0],[128,192,0],[0,64,128]]class VOCData(Dataset):def __init__(self, root):super(VOCData, self).__init__()self.lab_path = root + 'VOC2012/SegmentationClass/'self.img_path = root + 'VOC2012/JPEGImages/'self.lab_names = self.get_file_names(self.lab_path)self.img_names=[]for file in self.lab_names:self.img_names.append(file.replace('.png', '.jpg'))self.cm2lbl = np.zeros(256**3) for i,cm in enumerate(colormap): self.cm2lbl[cm[0]*256*256+cm[1]*256+cm[2]] = iself.image = []self.label = []for i in range(len(self.lab_names)):image = Image.open(self.img_path+self.img_names[i]).convert('RGB')image = transform(image)label = Image.open(self.lab_path+self.lab_names[i]).convert('RGB').resize((256,256))label = torch.from_numpy(self.image2label(label))self.image.append(image)self.label.append(label)def __len__(self):return len(self.image)def __getitem__(self, idx):return self.image[idx], self.label[idx]def get_file_names(self,directory):file_names = []for file_name in os.listdir(directory):if os.path.isfile(os.path.join(directory, file_name)):file_names.append(file_name)return file_namesdef image2label(self,im):data = np.array(im, dtype='int32')idx = data[:, :, 0] * 256 * 256 + data[:, :, 1] * 256 + data[:, :, 2]return np.array(self.cm2lbl[idx], dtype='int64')class convblock(nn.Module):def __init__(self, in_channels, out_channels):super(convblock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.relu1 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.relu2 = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu1(x)x = self.conv2(x)x = self.bn2(x)x = self.relu2(x) x = self.maxpool(x)return xclass Fcn32s(nn.Module):def __init__(self, num_classes):super(Fcn32s, self).__init__()self.conv_block1 = convblock(3,64)self.conv_block2 = convblock(64,128)self.conv_block3 = convblock(128,256)self.conv_block4 = convblock(256,512)self.conv_block5 = convblock(512,512)self.conv = nn.Conv2d(512,4096,kernel_size=1)self.up16x = nn.Upsample(scale_factor=16)self.convTrans2x = nn.ConvTranspose2d(4096, num_classes, kernel_size=4, stride=2, padding=1)def forward(self, x):x = self.conv_block1(x)x = self.conv_block2(x)x = self.conv_block3(x)x = self.conv_block4(x)x = self.conv_block5(x)x = self.conv(x)x = self.up16x(x)x = self.convTrans2x(x)return xclass Fcn16s(nn.Module):def __init__(self, num_classes):super(Fcn16s, self).__init__()self.conv_block1 = convblock(3,64)self.conv_block2 = convblock(64,128)self.conv_block3 = convblock(128,256)self.conv_block4 = convblock(256,512)self.conv_block5 = convblock(512,512)self.conv1 = nn.Conv2d(512, num_classes, kernel_size=1)self.conv2 = nn.Conv2d(512,4096,kernel_size=1)self.convTrans2x = nn.ConvTranspose2d(4096, num_classes, kernel_size=4, stride=2, padding=1)self.up8x = nn.Upsample(scale_factor=8)self.convTrans2x2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)def forward(self, x):x = self.conv_block1(x)x = self.conv_block2(x)x = self.conv_block3(x)x1 = self.conv_block4(x)x2 = self.conv_block5(x1)x1 = self.conv1(x1)x2 = self.conv2(x2)x2 = self.convTrans2x(x2)x = x1+x2x = self.up8x(x)x = self.convTrans2x2(x)return xclass Fcn8s(nn.Module):def __init__(self, num_classes):super(Fcn8s, self).__init__()self.conv_block1 = convblock(3,64)self.conv_block2 = convblock(64,128)self.conv_block3 = convblock(128,256)self.conv_block4 = convblock(256,512)self.conv_block5 = convblock(512,512)self.conv1 = nn.Conv2d(256, num_classes, kernel_size=1)self.conv2 = nn.Conv2d(512, num_classes, kernel_size=1)self.conv3 = nn.Conv2d(512,4096,kernel_size=1)self.upsample2x1 = nn.ConvTranspose2d(4096, num_classes, kernel_size=4, stride=2, padding=1)self.upsample2x2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)self.up = nn.Upsample(scale_factor=4)self.upsample2x3 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)def forward(self, x):x = self.conv_block1(x)x = self.conv_block2(x)x1 = self.conv_block3(x)x2 = self.conv_block4(x1)x3 = self.conv_block5(x2)x1 = self.conv1(x1)x2 = self.conv2(x2)x3 = self.conv3(x3)x3 = self.upsample2x1(x3)x3 = x2 + x3x3 = self.upsample2x2(x3)x3 = x1 + x3x3 = self.up(x3)x = self.upsample2x3(x3)return xdef train():train_dataset = VOCData(root='./VOCdevkit/')train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)#net = Fcn32s(21)#net = Fcn16s(21)net = Fcn8s(21)optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)criterion = nn.CrossEntropyLoss()net.to(device)net.train()num_epochs = 100for epoch in range(num_epochs):loss_sum = 0img_sum = 0for inputs, labels in train_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = net(inputs)loss = criterion(outputs, labels) optimizer.zero_grad()loss.backward()optimizer.step()loss_sum += loss.item()img_sum += inputs.shape[0]print('epochs:',epoch,loss_sum / img_sum )torch.save(net.state_dict(), 'my_fcn.pth')def val():net = Fcn8s(21)net.load_state_dict(torch.load('my_fcn.pth'))net.to(device)net.eval()image = Image.open('./VOCdevkit/VOC2012/JPEGImages/2007_009794.jpg').convert('RGB')image = transform(image).unsqueeze(0).to(device)out = net(image).squeeze(0)ToPIL= transforms.ToPILImage()maxind = torch.argmax(out,dim=0)outimg = torch.zeros([3,256,256])for y in range(256):for x in range(256):outimg[:,x,y] = torch.from_numpy(np.array(colormap[maxind[x,y]]))re = ToPIL(outimg)re.show()if __name__ == "__main__":train()val()