基本概念
- Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
Spark vs Hadoop
- Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘
| Hadoop | Spark | |
|---|---|---|
| 类型 | 分布式基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API较为底层, 算法适应性差 | RDD组成DAG有向无环图, API较为顶层, 方便使用 |
| 数据存储结构 | MapReduce中间计算结果存在HDFS磁盘上, 延迟大 | RDD中间运算结果存在内存中 , 延迟小 |
| 运行方式 | Task以进程方式维护, 任务启动慢 | Task以线程方式维护, 任务启动快 |
Spark核心模块
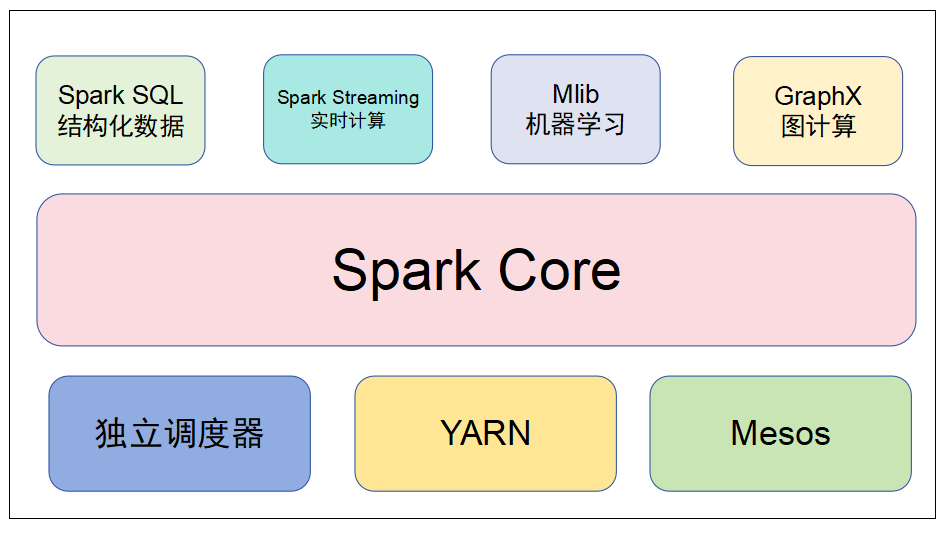
- Spark Core:实现了Spark的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块
- Spark SQL:Spark用来操作结构化数据的程序包,通过Spark SQL,我们可以使用SQL操作数据
- Spark Streaming:Spark提供的对实时数据进行流式计算的组件,提供了用来操作数据流的API
- Spark MLlib:提供常见的机器学习(ML)功能的程序库,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能
- GraphX(图计算):Spark中用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法
- 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算
- Structured Streaming:处理结构化流,统一了离线和实时的API
Spark运行模式
local本地模式(单机)
- 学习测试使用
- 分为local单线程和local-cluster多线程
standalone独立集群模式
- 学习测试使用
- 典型的 Mater/slave 模式
standalone-HA高可用模式
- 生产环境使用
- 基于standalone模式
on yarn集群模式
- 生产环境使用
- 运行在yarn集群之上,由yarn负责资源管理,Spark负责任务调度和计算
- 计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移
on mesos集群模式
- 国内使用较少
- 运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算
on cloud集群模式
- 中小公司未来会更多的使用云服务
- 比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3