1.首先安装第三方HTML数据过滤包 HtmlAgilityPack
我爬取的网站是一个树洞网站:https://i.jandan.net/treehole,他是一个单体网站,不通过api请求,所以只能根据HTML过滤,他的分页是通过base64加密的
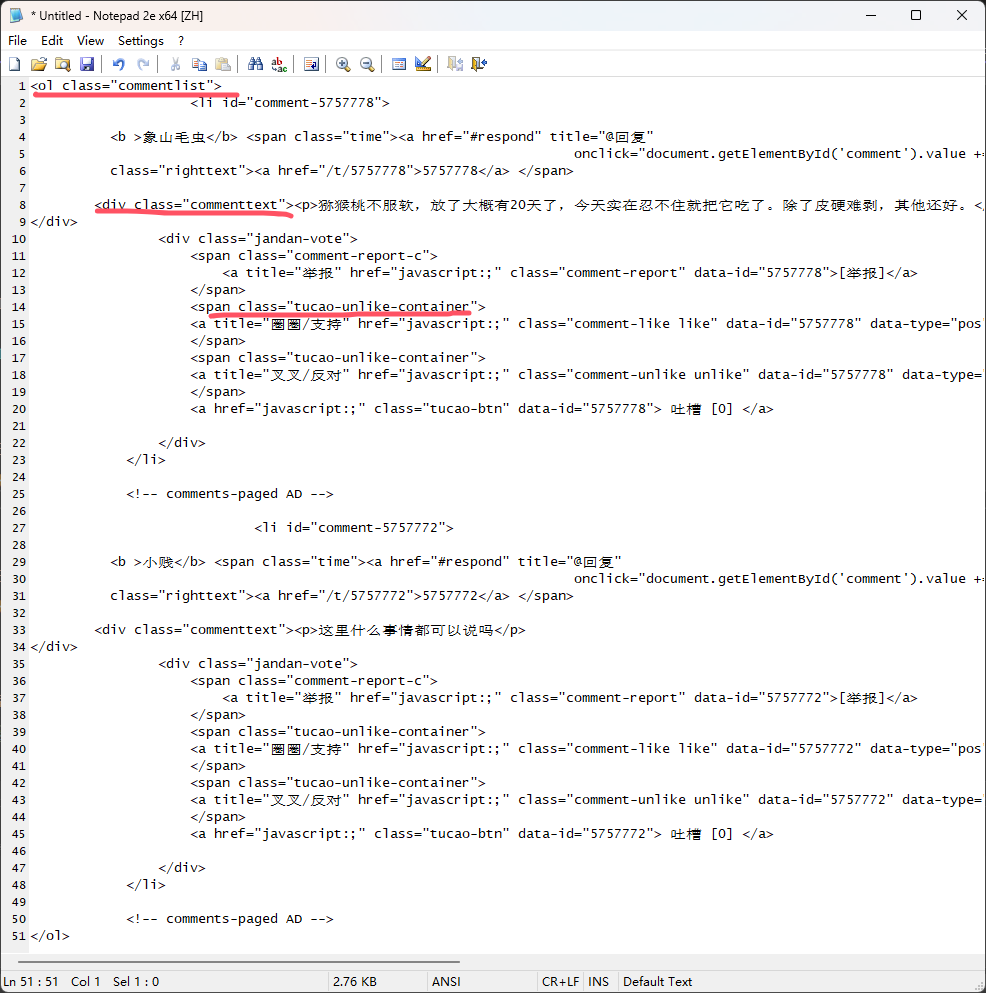
这是获取到的部分数据,这是我们需要的有效数据,他是有固定结构的,我们只要筛选这里面的数据显示出来就好了
以下是所有代码
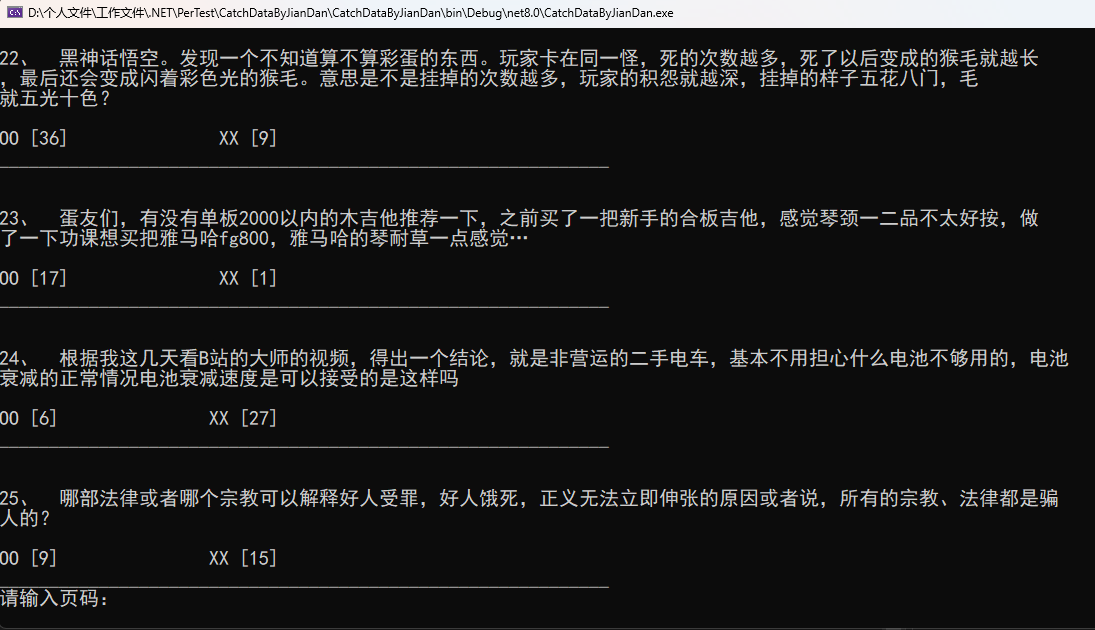
using HtmlAgilityPack; using System.Text; using System.Text.RegularExpressions;await ReadHtml();while (true) {Console.WriteLine("请输入页码:");var pageNumByNowDate = Console.ReadLine();if (!int.TryParse(pageNumByNowDate, out int pageNum)){Console.WriteLine("页码格式不正确,请重新输入数字");continue;}Console.Clear();byte[] buffer = Encoding.UTF8.GetBytes(DateTime.Now.ToString("yyyyMMdd") + "-" + pageNum);await ReadHtml("/" + Convert.ToBase64String(buffer)); }//读取html async Task ReadHtml(string url = "") {var client = new HttpClient();var request = new HttpRequestMessage(HttpMethod.Get, "https://i.jandan.net/treehole" + url);request.Headers.Add("Cookie", "PHPSESSID=38e64nulb56bqgl6e27b5sp31l");var response = await client.SendAsync(request);response.EnsureSuccessStatusCode();ClearData(await response.Content.ReadAsStringAsync()); }//清洗脏数据 void ClearData(string html) {HtmlDocument doc = new HtmlDocument();doc.LoadHtml(html);var commentTexts = doc.DocumentNode.SelectNodes("//div[@class='commenttext']");foreach (var comment in commentTexts){var commonText = comment.InnerText.Length > 30 ? string.Join("", comment.InnerText.Select((c, i) => (i > 0 && i % 50 == 0) ? $"{c}\r\n" : c.ToString().Trim().Replace("<br/>", "").Replace("<br />", ""))) : comment.InnerText.Trim().Replace("<br/>", "").Replace("<br />", "");var childrens = comment.ParentNode.SelectNodes(".//span[@class='tucao-unlike-container']");Console.WriteLine();Console.WriteLine();Console.WriteLine(commentTexts.IndexOf(comment) + 1 + "、 " + commonText);Console.WriteLine();Console.WriteLine(string.Join(" ", childrens.Select(c=>c.InnerText.Trim())));Console.WriteLine("_____________________________________________________________");} }
输出效果