ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
OLAP 为联机分析处理,专注于统计查询;OLTP 为联机事务处理,专注于增删改。
ClickHouse 的优势在于单表查询性能高,高吞吐的写入能力强,集群部署简单粗暴,比较适合海量数据存储、处理和查询。
ClickHouse 官网地址为:https://clickhouse.com
一、单机版快速部署
我的虚拟机是 CentOS7(IP 地址为 192.168.136.128),已经安装好了 docker 和 docker-compose
首先在 /data/single_ch 目录下创建好 clickhouse 的部署目录,结构如下所示:
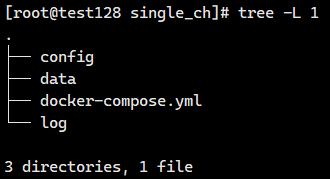
创建了 3 个目录,其中 config 目录用来存放配置文件;data 目录用来存放数据文件;log 目录用来存放日志
首先编写 docker-compose.yml 文件如下:
version: '3.2'
services:clickhouse:image: yandex/clickhouse-server:latestcontainer_name: clickhouserestart: alwaysports:- "8123:8123"- "9000:9000"
在 docker-compose.yml 所在目录下,运行 docker-compose up -d 启动 clickhouse,主要目的在于将 docker 内部 clickhouse 的 2 个配置文件(config.xml 和 users.xml)拷贝到外部我们创建好的 config 目录中:
docker cp clickhouse:/etc/clickhouse-server/config.xml /data/single_ch/config
docker cp clickhouse:/etc/clickhouse-server/users.xml /data/single_ch/config
针对 config.xml 文件,修改以下配置内容:
<!--默认情况下,ClickHouse 只允许本机访问,因此需要取消该行注释,目的在于允许任何外部机器访问-->
<listen_host>0.0.0.0</listen_host><!--明确配置时区,这里配置为中国的东八区-->
<timezone>Asia/Shanghai</timezone><!--将 remote_servers 配置节,以及其内部的内容,全部删掉-->
<!--默认情况下,官方提供了集群配置和数据分片存储的配置样例。对于单机部署没有意义,所以删掉-->
<remote_servers>....
</remote_servers>
默认情况下,clickhouse 有一个 default 用户(无密码)和一个 default 数据库(无任何表)。你可以在 users.xml 文件中,添加新用户以及配置其可访问的数据库。注意:为了安全性,最好在 users.xml 文件中把默认的 default 这个用户配置上密码。如下所示:
<users><default><!--为 default 用户配置密码,不要为空密码--><password>123456</password><networks><ip>::/0</ip></networks><profile>default</profile><quota>default</quota></default><!--自己可以添加新用户,配置该用户允许访问的数据库--><jobs><password>123456</password><networks><ip>::/0</ip></networks><profile>default</profile><quota>default</quota><allow_databases><database>default</database></allow_databases></jobs>
</users>
最后修改 docker-compose.yml 文件,添加对 docker 内部 clickhouse 的配置目录、数据目录、日志目录的映射:
version: '3.2'
services:clickhouse:image: yandex/clickhouse-server:latestcontainer_name: clickhouserestart: alwaysports:# Http 访问端口- "8123:8123"# ClickHouse 的客户端 tcp 访问端口- "9000:9000"volumes:# 配置文件- ./config/config.xml:/etc/clickhouse-server/config.xml:rw- ./config/users.xml:/etc/clickhouse-server/users.xml:rw# 运行日志- ./log:/var/log/clickhouse-server# 数据持久- ./data:/var/lib/clickhouse:rw
在 docker-compose.yml 所在目录下,运行以下命令销毁和启动 clickhouse 即可。
#销毁刚才启动的 clickhouse 实例
docker-compose down#启动 clickhouse 新实例
docker-compose up -d
下载并使用 dbeaver 工具,创建 clickhouse 数据库连接
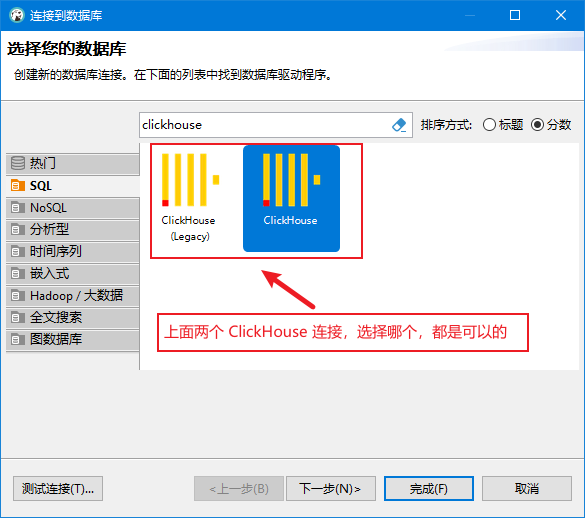
配置好连接参数,使用 http 端口 8123
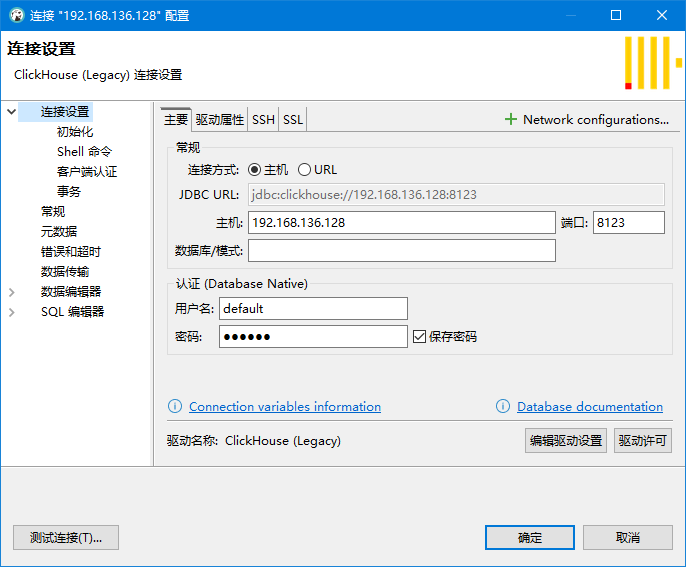
连接成功后,可以运行 show databases 查询有哪些数据库,默认情况下,系统提供了 default 这个数据库可以使用,其它数据库都是 clickhouse 自己用的。
二、使用 SpringBoot 访问 ClickHouse
首先在 default 数据库中,创建一张表:
CREATE TABLE user_info
(`id` UInt64,`user_name` String,`user_phone` String,`create_time` DateTime DEFAULT CAST(now(),'DateTime')
)
ENGINE = MergeTree
PRIMARY KEY id
ORDER BY id;
新建一个名称为 springboot_clickhouse 的 SpringBoot 工程,结构如下:
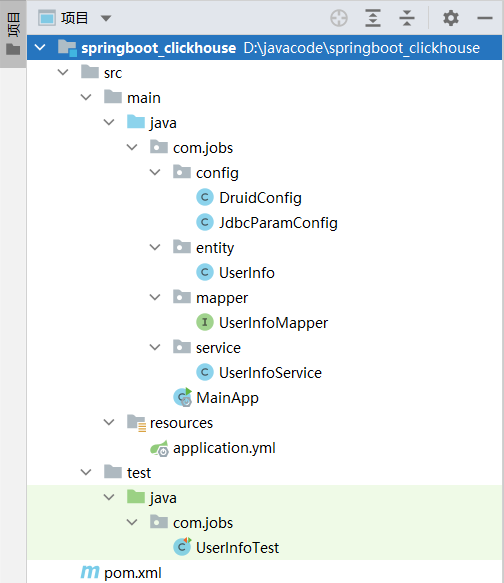
首先看一下 pom.xml 文件中引入的依赖包:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.jobs</groupId><artifactId>springboot_clickhouse</artifactId><version>1.0</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.5</version><relativePath/></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId><scope>compile</scope></dependency><!--引入官网提供的clickhouse的jdbc依赖包--><dependency><groupId>com.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.6.5</version></dependency><!--clickhouse的jdbc依赖,需要引入lz4依赖--><dependency><groupId>org.lz4</groupId><artifactId>lz4-java</artifactId><version>1.8.0</version></dependency><!--clickhouse的jdbc依赖,需要引入httpclient5依赖--><dependency><groupId>org.apache.httpcomponents.client5</groupId><artifactId>httpclient5</artifactId><version>5.3.1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.20</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><!--解决 IDEA 编写与配置项对应的实体类时,文件上方总是出现红色提示的问题--><!--导入该依赖后,在编写配置文件时,如果用到了实体类的属性,会有智能提示--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.4.5</version></plugin></plugins></build>
</project>
然后再看一下 application.yml 中有关 clickhouse 的访问链接配置,这里使用了阿里的 druid 连接池:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourceclick:driverClassName: com.clickhouse.jdbc.ClickHouseDriverurl: jdbc:clickhouse://192.168.136.128:8123/defaultusername: defaultpassword: 123456initialSize: 10maxActive: 100minIdle: 10maxWait: 6000mybatis-plus:configuration:# 开启 sql 打印日志,输出的控制台,方便开发过程中查看 sql 执行细节log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
其中 click 是我们自己编写的自定义配置,因此我们需要建立这些配置参数与 druid 之间的关联,首先建立实体类与配置进行关联:
package com.jobs.config;import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;@Data
@Component
@ConfigurationProperties(prefix = "spring.datasource.click")
public class JdbcParamConfig {private String driverClassName;private String url;private String username;private String password;private Integer initialSize;private Integer maxActive;private Integer minIdle;private Integer maxWait;
}
然后使用实体类的属性值(SpringBoot 启动后会使用配置文件的内容给实体类初始化值),配置 durid 连接池参数:
package com.jobs.config;import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;@Configuration
public class DruidConfig {@Autowiredprivate JdbcParamConfig jdbcParamConfig ;@Beanpublic DataSource dataSource() {DruidDataSource datasource = new DruidDataSource();datasource.setUrl(jdbcParamConfig.getUrl());datasource.setDriverClassName(jdbcParamConfig.getDriverClassName());datasource.setInitialSize(jdbcParamConfig.getInitialSize());datasource.setMinIdle(jdbcParamConfig.getMinIdle());datasource.setMaxActive(jdbcParamConfig.getMaxActive());datasource.setMaxWait(jdbcParamConfig.getMaxWait());datasource.setUsername(jdbcParamConfig.getUsername());datasource.setPassword(jdbcParamConfig.getPassword());return datasource;}
}
剩下的就是 mybatis 相关的代码了,首先根据数据库表字段,编写实体类:
package com.jobs.entity;import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserInfo {@TableId@TableField("id")private Long id;@TableField("user_name")private String userName;@TableField("user_phone")private String userPhone;@TableField("create_time")private String createTime;
}
根据实体类编写 mapper 数据库访问代码:
package com.jobs.mapper;import com.jobs.entity.UserInfo;
import org.apache.ibatis.annotations.*;
import java.util.List;@Mapper
public interface UserInfoMapper {//添加用户@Insert("insert into user_info(id,user_name,user_phone) values(#{id},#{userName},#{userPhone})")void addUser(UserInfo userInfo);//根据 id 获取用户(clickhouse 的主键允许重复,所以这里获取查询到的第一条数据)@Select("select id,user_name,user_phone,create_time from user_info where id=#{id} limit 1")UserInfo selectById(@Param("id") Long id);//查询所有用户(这里就不展示分页查询了,自己可以使用 mybatis plus 进行实现)@Select("select id,user_name,user_phone,create_time from user_info order by id")List<UserInfo> selectList();//修改用户(对于 clickhouse 来说,修改操作是比较重的操作,最好是大批量的修改,不要逐条修改)@Update("ALTER TABLE user_info update user_name=#{userName},user_phone=#{userPhone} where id=#{id}")void updateUser(UserInfo userInfo);//删除用户(对于 clickhouse 来说,删除操作是比较重的操作,最好是大批量的删,不要逐条删除)@Delete("ALTER TABLE user_info delete where id=#{id}")void deleteUser(@Param("id") Long id);
}
根据 mapper 编写 service 代码,这里图省事,没有写接口,直接写 service 类的实现了:
package com.jobs.service;import com.jobs.entity.UserInfo;
import com.jobs.mapper.UserInfoMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.List;//mybatis plus 要求给方法上增加 @Transactional 注解,否则日志中总是会出现以下内容:
//SqlSession was not registered for synchronization because synchronization is not active
@Transactional
@Service
public class UserInfoService {@AutowiredUserInfoMapper userInfoMapper;public void addUser(UserInfo userInfo) {userInfoMapper.addUser(userInfo);}public UserInfo selectById(Long id) {return userInfoMapper.selectById(id);}//@Transactional(rollbackFor = Exception.class)public List<UserInfo> selectList() {return userInfoMapper.selectList();}public void updateUser(UserInfo userInfo) {userInfoMapper.updateUser(userInfo);}public void deleteUser(Long id) {userInfoMapper.deleteUser(id);}
}
由于本 demo 只是一个示例,不想写接口了,就直接编写测试代码,测试 service 中的方法了:
package com.jobs;import com.jobs.entity.UserInfo;
import com.jobs.service.UserInfoService;
import com.sun.xml.internal.ws.policy.privateutil.PolicyUtils;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.CollectionUtils;import java.text.SimpleDateFormat;
import java.util.Collections;
import java.util.List;
import java.util.Objects;@SpringBootTest
public class UserInfoTest {@Autowiredprivate UserInfoService userInfoService;@Testvoid test1() {UserInfo userInfo1 = new UserInfo(1L, "候胖胖", "1234567", "2024-09-22 19:00:00");UserInfo userInfo2 = new UserInfo(2L, "任肥肥", "2345678", "2024-09-22 19:01:12");UserInfo userInfo3 = new UserInfo(3L, "李墩墩", "3456789", "2024-09-22 19:02:23");UserInfo userInfo4 = new UserInfo(4L, "杨棒棒", "4567890", "2024-09-22 19:03:35");UserInfo userInfo5 = new UserInfo(5L, "乔豆豆", "5678901", "2024-09-22 19:05:26");userInfoService.addUser(userInfo1);userInfoService.addUser(userInfo2);userInfoService.addUser(userInfo3);userInfoService.addUser(userInfo4);userInfoService.addUser(userInfo5);System.out.println("添加成功");}@Testvoid test2() {Long id = 2L;UserInfo userInfo = userInfoService.selectById(id);if (!Objects.isNull(userInfo)) {System.out.println(userInfo);} else {System.out.println("未查询到数据");}}@Testvoid test3() {List<UserInfo> userInfos = userInfoService.selectList();if (!CollectionUtils.isEmpty(userInfos)) {for (UserInfo userInfo : userInfos) {System.out.println(userInfo);}} else {System.out.println("未查询到数据");}}@Testvoid test4() {Long id = 2L;UserInfo userInfo = userInfoService.selectById(id);if (!Objects.isNull(userInfo)) {userInfo.setUserName("马壮壮");userInfo.setUserPhone("6666777");userInfoService.updateUser(userInfo);System.out.println("修改成功");} else {System.out.println("未查询到数据,无法修改");}}@Testvoid test5() {Long id = 2L;userInfoService.deleteUser(id);System.out.println("删除成功");}
}
以上就是单机版 ClickHouse 的搭建,以及使用 SpringBoot 访问 ClickHouse 的简单介绍。
有关 ClickHouse 的详细使用,可以参考官方文档:https://clickhouse.com/docs/en/intro
本篇博客的 demo 下载地址为:https://files.cnblogs.com/files/blogs/699532/springboot_clickhouse.zip