概述
- Hive是将SQL转为MapReduce
- SparkSQL可以理解成是将SQL解析成:“RDD+优化”再执行
- SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快
- Spark SQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象,DataFrame和DataSet,类似Spark Core中的RDD
1. SparkSQL特点
- 易整合:无缝的整合了SQL查询和Spark编程
- 统一的数据访问:使用相同的方式连接不同的数据源
- 兼容Hive:在已有的仓库上直接运行SQL或者HiveSQL
- 标准数据连接:通过JDBC或者ODBC来连接
2. 数据分类
| 定义 | 特点 | 举例 | |
|---|---|---|---|
| 结构化数据 | 有固定的Schema | 有预定义的Schema | 关系型数据库的表 |
| 半结构化数据 | 没有固定的Schema,但是有结构 | 没有固定的Schema,有结构信息,数据一般是自描述的 | 指一些有结构的文件格式,例如JSON |
| 非结构化数据 | 没有固定Schema,也没有结构 | 没有固定Schema,也没有结构 | 指图片/音频之类的格式 |
- RDD主要用于处理非结构化数据、半结构化数据、结构化
- SparkSQL是一个既支持SQL又支持命令式数据处理的工具
- SparkSQL主要用于处理结构化数据(较为规范的半结构化数据也可以处理)
SparkSQL数据抽象
1. DataFrame
- 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格
- DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型
- DataFrame支持嵌套数据类型(struct、array和map)
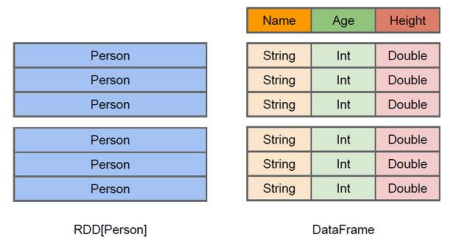
DataFrame和RDD的区别
- 左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构,而右侧的DataFrame却提供了详细的结构信息
- DataFrame是为数据提供了Schema的视图,可以把它当做数据库中的一张表来对待
- DataFrame也是懒执行的,但性能上比RDD要高
2. DataSet
- DataSet是分布式数据集合,是DataFrame的一个扩展
- DataSet也可以使用功能性的转换(操作map,flatMap,filter等等)
- DataFrame是DataSet的特列,DataFrame=DataSet[Row],所以可以通过as方法将DataFrame转换为DataSet,Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。获取数据时需要指定顺序