1、不同batch_size时运行train_segmentor.py的cpu、gpu、内存使用情况和batch_size性能分析
任务管理器cpu、gpu参数
Windows 11最新版:任务管理器性能参数详解,什么是分页缓冲池和句柄-CSDN博客

| batch_size | cpu利用率 | gpu [专用、共享、GPU内存] | iter用时(s) | iters / epoch | mesh-segmentor-loss | acc | 总用时 |
|---|---|---|---|---|---|---|---|
| 60 | 22% | 5.8,8.7,14.5 | 3-6 | 245 | 0.1306 | 0.9059 | 13 h+ |
| 50 | 15% | 5.7,5.7,11.4 | 2.5-4 | 264 | 0.0341 | 0.9496 | 9-10 h |
| 40 | 62% | 5.7,4.1,9.8 | 1-3 | 368 | 0.0354 | 0.9614 | 4 h 28 m 47 s |
| 30 | 11% | 5.7,1.2,6.9 | 0.38 | 490 | 0.0184 | 0.9605 | 2 h 33 m 34 s |
| 25 | 11% | 5.8,0.5,6.3 | 0.25-0.5 | 588 | 0.0160 | 0.9853 | 1 h 41 m 49 s |
2、mesh anything2
论文阅读
-
mesh-gpt
-
mesh anything 1

1、编解码部分
遵循MeshGPT[55],我们首先训练一个VQ-VAE[61]来学习几何嵌入词汇表,以便更好地进行Transformer[62]学习。与使用图卷积网络[67]和ResNet[29]分别作为编码器和解码器的MeshGPT不同,我们采用具有相同结构的transformer来进行编码器和解码器。
2、transformer生成
为了给变压器增加形状条件,受到多模态大型语言模型[68, 37, 70, 25]成功的启发,我们首先使用点云编码器PP将点云编码成一个固定长度的令牌序列****,然后将它与来自TT VQ-VAE的嵌入序列的前端连接起来,作为transformer的最终输入嵌入序列:
T′=concat(P(S),T)
- mesh anything 2
M:=((v11,v12,v13),(v21,v22,v23),…,(v**N1,v**N2,v**N3))=SeqV(3)
由于排序,得到的SeqVSeqV是唯一的,并且其长度是网格中面数的三倍。很明显,SeqVSeqV包含大量冗余信息,因为每个顶点出现的次数与其所属的面数相同。
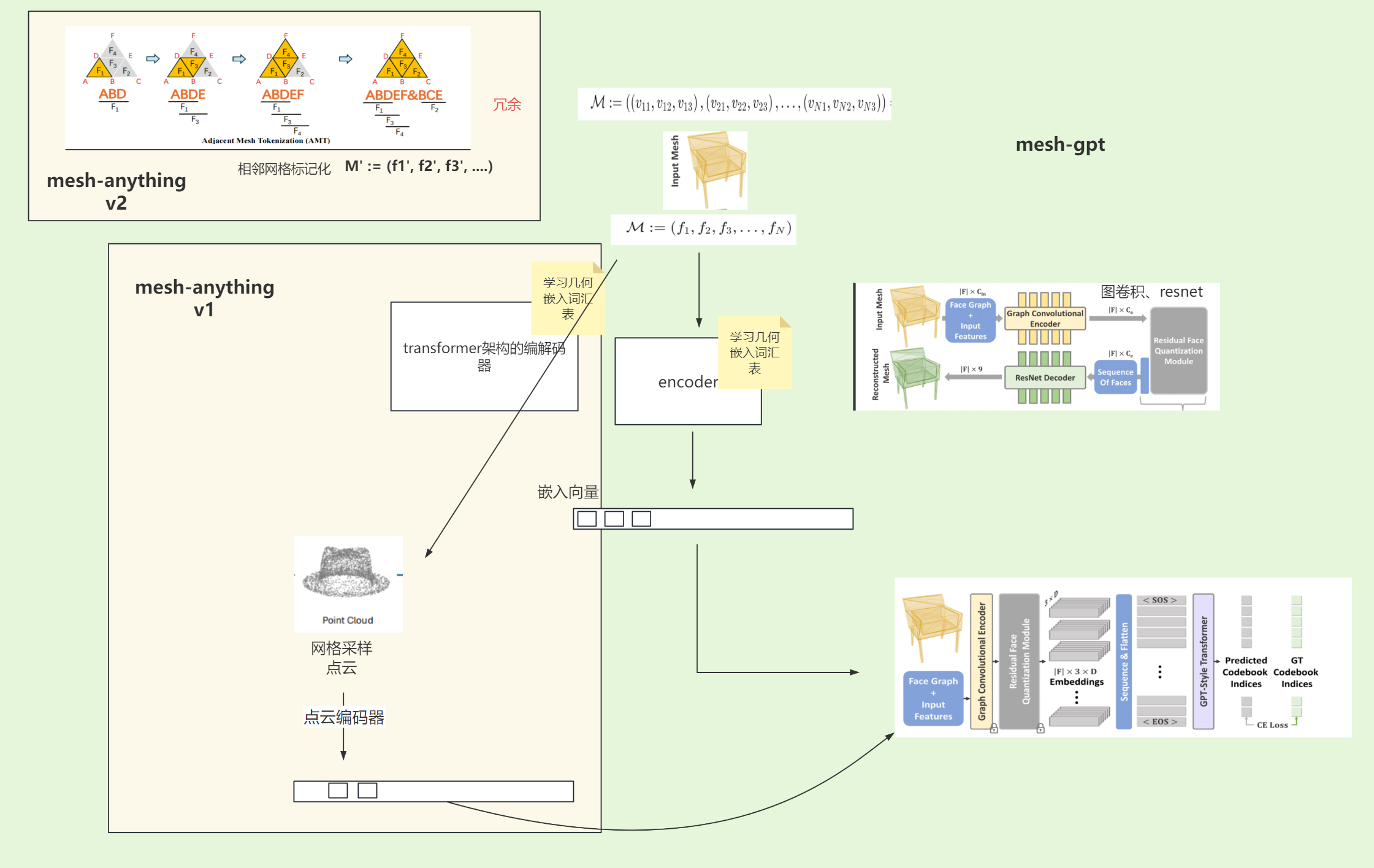
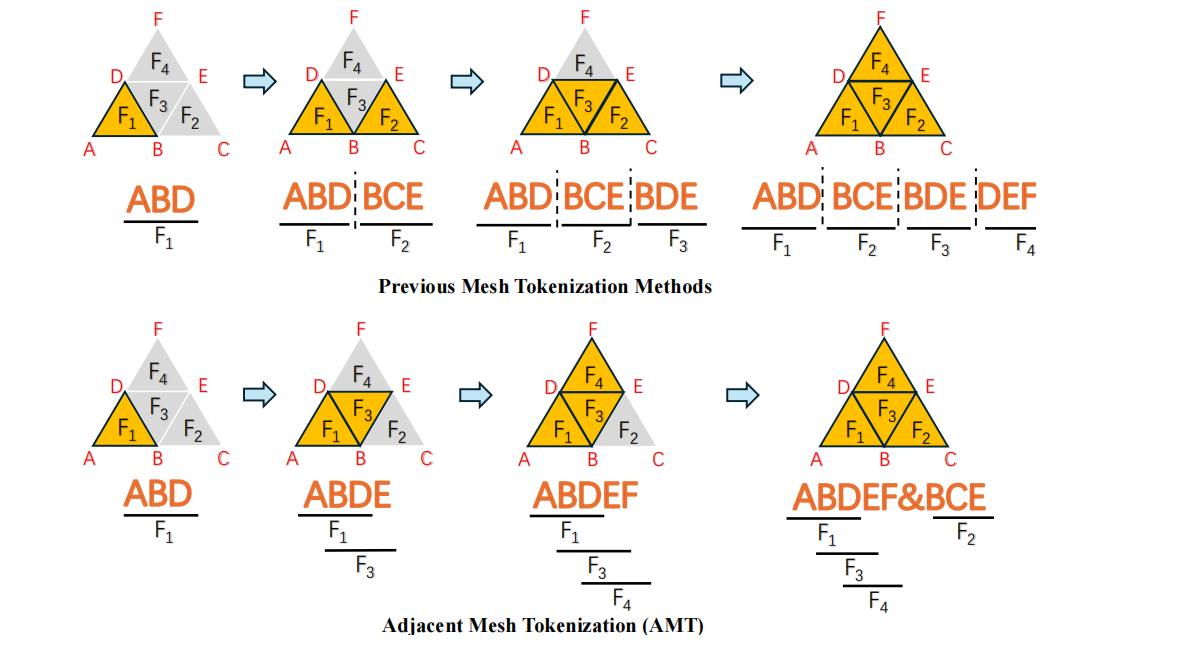
为了解决这个问题,我们提出了相邻网格标记化(AMT),以获得比之前方法更紧凑、结构更好的SeqVSeq**V。我们的关键观察是,SeqVSeq**V的主要冗余来自于用三个顶点表示每个面,如方程2所示。这导致已经访问过的顶点在SeqVSeq**V中重复出现。因此,AMT旨在尽可能使用单个顶点来表示每个面。如图2和算法1所示,AMT在标记化过程中有效地编码了相邻的面,只使用了一个额外的顶点。当没有可用的相邻面时,如图2的最后一步所示,AMT会在序列中插入一个特殊标记,并从尚未编码的面重新开始过程。要解码,只需按照算法1描述的顺序反转标记化算法即可
环境配置(err)
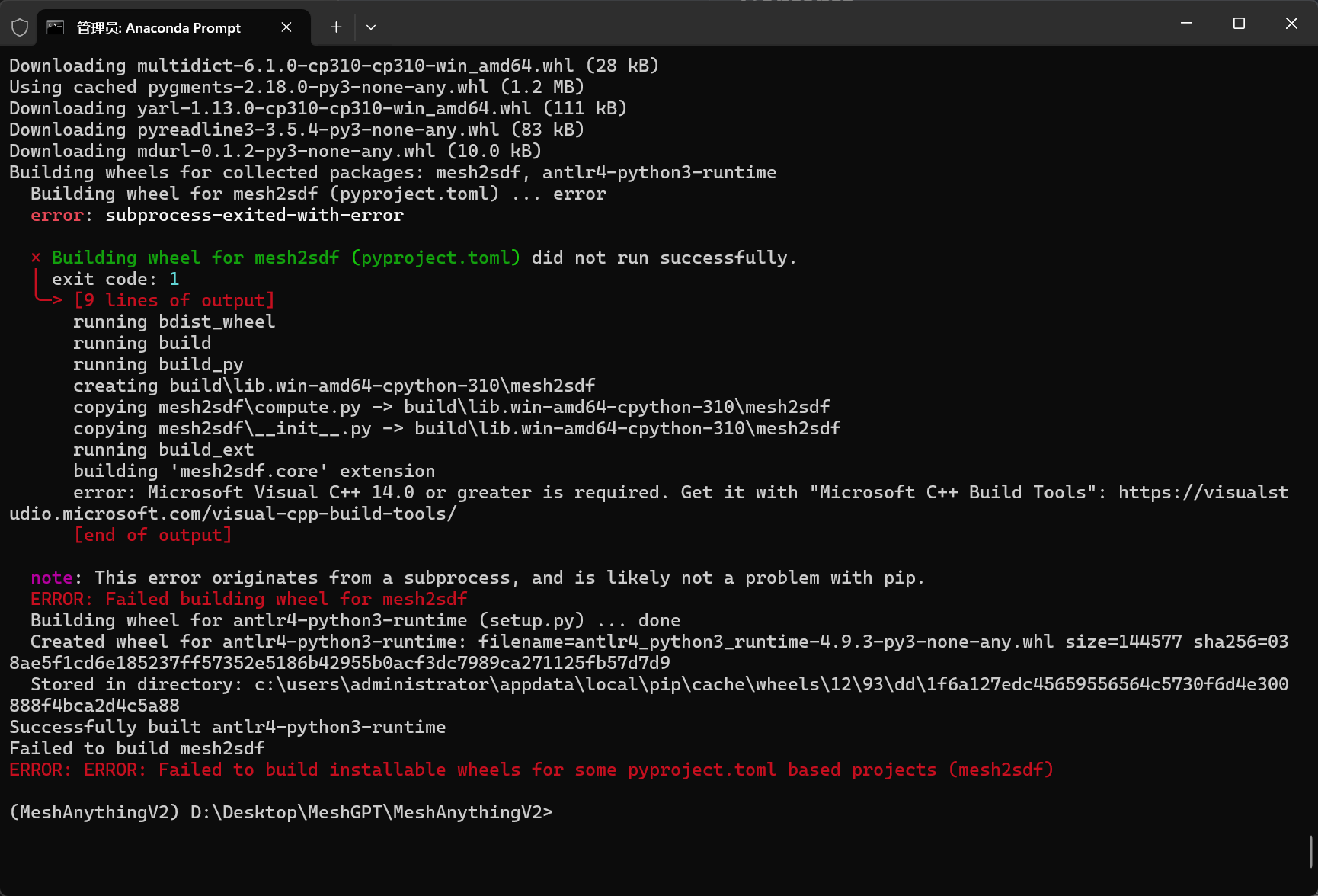
`: Microsoft Visual C++ 14.0 or greater is required.
下周任务:
nlp中的gpt encoder-decoder、pytorch学习
rplan数据集准备训练