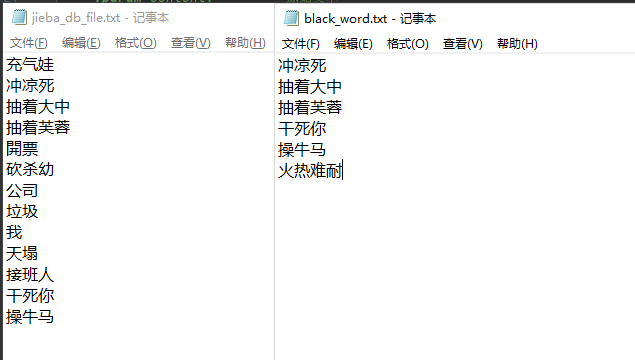
定义词库
1、敏感词库(black_word.txt)
2、jeiba 分词库(jieba_db_file.txt)
(我这简单的就用文本来记录了,可以将这些词库都通过数据库来存储,对企业来说通过可视化页面去增删改可能会更方便运营处理)
代码示例
import os
import jiebablack_word_list = list()def load_word(file_path):# fixme: 有条件的通过数据库来缓存,将敏感词库加载到缓存数据库中,而不是内存缓存,这样能减少资源占用assert os.path.isfile(file_path), "load_word fail. [{}] file not exist!".format(file_path)with open(file_path, 'r', encoding='utf-8') as wf:_lines = wf.readlines()tmp_list = [w.strip() for w in _lines if w.strip() != '']return tmp_listdef set_jieba_db_cache(jieba_db_file):jieba.load_userdict(jieba_db_file)def algorithm_word_jieba_cut(content, replace_word="***"):"""敏感词识别算法结巴分词:param content: 原始文本:param replace_word: 敏感词替换的字符:return: (识别到的敏感词列表, 原始文本被处理后的内容)"""global black_word_listfilter_word_list = []content_word_list = jieba.cut(content) # 将内容通过jieba库进行分词tmp_rnt_content = ''last_not_black = True # 记录上一次是否敏感词for word in content_word_list:if word in black_word_list: # 跟敏感词库进行比较print("black_word = {}".format(word))filter_word_list.append(word)if last_not_black:tmp_rnt_content += replace_wordlast_not_black = Falseelse:tmp_rnt_content += wordlast_not_black = Truereturn list(set(filter_word_list)), tmp_rnt_contentdef _init():global black_word_list# 设置jieba词库jieba_db_file = r"G:\info\jieba_db_file.txt"set_jieba_db_cache(jieba_db_file)# 加载敏感词库file_path = r"G:\info\black_word.txt"black_word_list = load_word(file_path)def main():_init() # 初始化content_str = ""result = algorithm_word_jieba_cut(content_str, replace_word="***")if __name__ == '__main__':main()