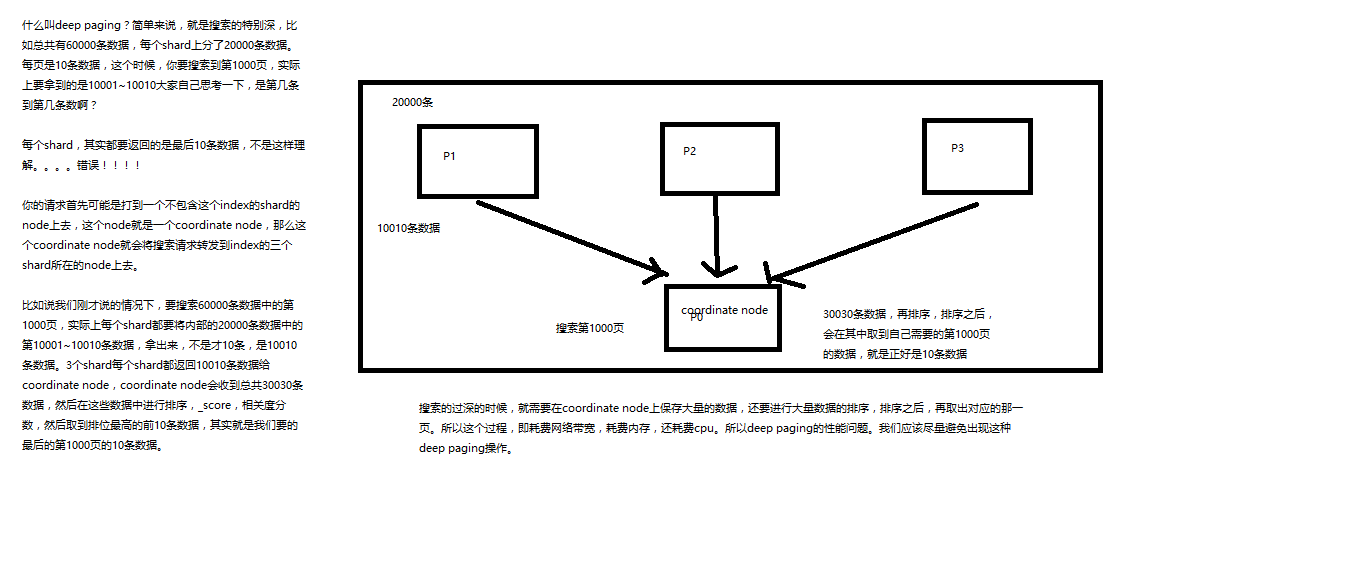
Java 图像处理秘籍(全)
原文:Java Image Processing Recipes
协议:CC BY-NC-SA 4.0
一、JavaVM 上的 OpenCV
几年前,在去上海的旅途中,我的一个非常好的朋友在 OpenCV 上给我买了一本大部头的书。它有大量的摄影操作、实时视频分析样本和非常有吸引力的深入解释,我迫不及待地想在我的本地环境中运行这些东西。
你可能知道,OpenCV 代表开源计算机视觉;这是一个开源库,为您提供了高级成像算法的即用型实现,从简单易用但高级的图像操作到形状识别和实时视频分析间谍功能。
OpenCV 的核心是名为 Mat 的多维矩阵对象。在这本书里,Mat 将会是我们最好的朋友。输入对象是 Mat,操作在 Mat 上运行,我们工作的输出也要 Mat。
尽管 Mat 将成为我们最好的朋友,但它是一个 C++对象,因此,它并不是最容易带去展示的朋友。无论你带他去哪里,你都必须重新编译,安装,并且对新环境非常温和。
但是垫子可以包装。
即使 Mat 是本地的(即本地运行),他也可以被打扮成在 Java 虚拟机上运行,而几乎没有人会注意到。
第一章希望向您介绍如何使用 OpenCV 和 Java 虚拟机的一些主要语言,当然是 Java,但也包括更容易阅读的 Scala 和 Google 大肆宣传的 Kotlin。
要以相似的方式运行所有这些不同的语言,您将首先获得(re-?)介绍了一个名为 leiningen 的 Java 构建工具,然后您将继续使用它来使用简单的 OpenCV 函数。
这第一章的道路将把你带到类似的基于 JVM 的语言 Clojure 的门口,它将为你的 OpenCV 代码提供巨大创造力的即时视觉反馈。那将是第二章的内容。
1.1 莱宁根入门
问题
您还记得“编写一次,随处运行”这句名言,您希望编译 Java 代码,并在不同的机器上以简单和可移植的方式运行 Java 程序。显然,您总是可以使用普通的 javac 命令来编译 Java 代码,并在命令行上使用纯 Java 来运行您编译的代码,但是我们已经进入 21 世纪了,嘿,您正在寻找更多的东西。
无论使用哪种编程语言,手动设置工作环境都是一项艰巨的任务,当您完成后,很难与其他人共享。
使用构建工具,您可以用简单的方式定义处理项目所需的内容,并让其他用户快速入门。
您想从一个易于使用的构建工具开始。
解决办法
Leiningen 是一个构建工具,主要针对 JavaVM。在这个意义上,它与其他著名的类似(还记得吗?蚂蚁,(哦,我的上帝)Maven,和(它曾经工作)Gradle。
一旦 leiningen 命令安装完毕,您就可以使用它来创建基于模板的新 JavaVM 项目,并运行它们,而不会遇到通常的麻烦。
这个食谱展示了如何快速安装 Leiningen 并使用它运行你的第一个 Java 程序。
它是如何工作的
首先,您只需在需要的地方安装 Leiningen,然后用它创建一个空白的 Java 项目。
注意
安装 Leiningen 需要在您的机器上安装 Java 8。还要注意的是,由于 Java 9 通过打破当前的解决方案来解决老问题,我们现在将选择保留 Java 8。
安装 Leiningen 雷宁根
Leiningen 网站本身是托管的,可以在
leiningen.org/
在 Leiningen 页面的顶部,您可以找到自己手动安装该工具的四个简单步骤。
So here it goes, on macOS and Unix :
-
1.下载 lein 脚本
raw . githubusercontent . com/technomancy/leiningen/stability/bin/lein网站
-
将它放在您的 shell 可以找到它的$PATH 中(例如,~/bin)
-
将其设置为可执行(chmod a+x ~/bin/lein)
-
从终端 lein 运行它,它将下载自安装包
在 Windows 上:
-
1.下载 lein.bat 批处理脚本
raw . githubusercontent . com/technomancy/leiningen/stable/bin/lein . bat
-
使用管理员权限将它放在 C:/Windows/System32 文件夹中
-
打开一个命令提示符并运行它,lein,它将下载自安装包
在 Unix 上,您几乎总是可以使用包管理器。macOS 上的 Brew 有一个给莱宁根的包。
在 Windows 上,也有一个不错的 Windows installer,位于djpowell.github.io/leiningen-win-installer/。
如果你是巧克力迷,Windows 也有巧克力套装:chocolatey.org/packages/Lein。
如果您在终端或命令提示符下成功完成了安装过程,您应该能够检查已安装工具的版本。在第一次运行时,Leiningen 下载它自己的内部依赖项,但是任何其他后续运行通常会很快。
NikoMacBook% lein -v Leiningen 2.7.1 on Java 1.8.0_144 Java HotSpot(TM) 64-Bit Server VM
用 Leiningen 创建一个新的 OpenCV-Ready Java 项目
Leiningen 主要围绕一个名为 project.clj ,的文本文件工作,这些项目的元数据、依赖项、插件和设置在一个简单的映射中定义。
当您在项目上执行调用 lein 命令的命令时,lein 将查看 project.clj 以找到它需要的关于该项目的相关信息。
Leiningen 附带了现成的项目模板,但是为了正确理解它们,让我们先一步一步地看一个例子。
For a leiningen Java project, you need two files:
-
描述项目的文件 project.clj
-
一个包含一些 Java 代码的文件,这里是 Hello.java
第一个项目的简单目录结构如下所示:
. ├── java │ └── Hello.java └── project.clj 1 directory, 2 files
为了省心,我们将保持第一个 Java 示例的代码非常简单。
public class Hello { public static void main(String[] args) { System.out.println("beginning of a journey"); } }
现在让我们更详细地看看名为 project.clj 的文本文件的内容:
(defproject hellojava "0.1" :java-source-paths ["java"] :dependencies [[org.clojure/clojure "1.8.0"]] :main Hello)
这实际上是 Clojure 代码,但让我们简单地把它看作一种领域特定语言(DSL),一种用简单的术语描述项目的语言。
For convenience, each term is described in Table 1-1.Table 1-1
Leiningen 项目元数据
|单词
|
使用
|
| --- | --- |
| Defproject | 定义项目的入口点 |
| 你好 java | 项目的名称 |
| Zero point one | 描述版本的字符串 |
| :java 源路径 | 相对于项目文件夹的目录列表,您将在其中放置 Java 代码文件 |
| :依赖关系 | 运行项目所需的外部库及其版本的列表 |
| [[org.clojure/clojure "1.8.0"]] | 默认情况下,该列表包含 Clojure,运行 leiningen 需要它。稍后您将把 OpenCV 库放在这里 |
| :主 | 默认情况下将执行的 Java 类的名称 |
现在继续创建前面的目录和文件结构,并相应地复制粘贴每个文件的内容。
完成后,运行您的第一个 leiningen 命令:
lein run
根据您的环境,该命令将在终端或控制台上生成以下输出。
Compiling 1 source files to /Users/niko/hellojava/target/classes beginning of a journey
呜呼!旅程开始了!但是,等等,刚才发生了什么?
这涉及到一点魔法。leiningen run 命令将使 leiningen 执行一个编译好的 Java 类 main 方法。要执行的类是在项目的元数据中定义的,正如您所记得的,应该是 Hello 。
在执行 Java 编译的类之前,需要…编译它。默认情况下,Leiningen 在执行 run 命令之前进行编译,因此这就是“正在编译…”消息的来源。
在这个过程中,您可能已经注意到在您的项目文件夹中创建了一个目标文件夹,其中有一个 classes 文件夹和一个 Hello.class 文件。
. ├── dev ├── java │ └── Hello.java ├── project.clj ├── src ├── target │ ├── classes │ │ ├── Hello.class
默认情况下,编译后的 Java 字节码放在 target/classes 文件夹中,然后将同一个目标文件夹添加到 Java 执行运行时(classpath)中。
随后是由“lein run”触发的执行阶段,执行来自 Hello 类的 main 方法的代码块;然后打印出消息。
beginning of a journey.
您可能会问:“如果我有多个 Java 文件,并且想运行一个不同于主文件的文件,该怎么办?”
这是一个非常有意义的问题,因为在第一章中,您可能会多次这样做,以编写和运行不同的代码示例。
假设您在同一个 Java 文件夹中的一个名为 Hello2.java 的文件中编写了第二个 Java 类,以及一些更新的旅程内容。
import static java.lang.System.out; public class Hello2 { public static void main(String[] args) { String[] text = new String[]{ "Sometimes it's the journey that ", "teaches you a lot about your destination.", "--", "- Drake"}; for(String t : text) out.println(t); } }
要从 Hello2.java 文件中运行这个 main 方法,可以使用可选的–m 选项调用 lein run,其中 m 代表 main,然后是要使用的主 Java 类的名称。
lein run –m Hello2
这将为您提供以下输出:
Compiling 1 source files to /Users/niko/hellojava/target/classes Sometimes it's the journey that teaches you a lot about your destination. -- - Drake
太好了。有了这些说明,您现在已经了解了足够的知识,可以继续运行您的第一个 OpenCV Java 程序了。
1.2 编写您的第一个 OpenCV Java 程序
问题
您希望使用 Leiningen 来设置一个 Java 项目,在这里您可以直接使用 OpenCV 库。
您希望利用 opencv 运行 Java 代码,但是您已经感到头疼了(当您自己编译 OpenCV 包装器时),所以您希望使这一步尽可能简单。
解决办法
莱宁根的食谱 1-1 帮助你完成所有基本的设置。从那里,您可以添加对 OpenCV C++库及其 Java 包装器的依赖。
它是如何工作的
对于第一个 OpenCV 示例,我们将使用 Leiningen 项目模板进行设置,其中已经为您定义了 project.clj 文件和项目文件夹。Leiningen 项目模板不必单独下载,并且可以使用 Leiningen 的集成 new 命令来创建新项目。
为了在您的本地机器上创建这个项目,在命令行中,让我们调用 lein 的命令。
无论是在 Windows 还是 Mac 上,该命令都会给出
lein new jvm-opencv hellocv What the preceding command basically does is
-
创建一个名为 hellocq 的新项目文件夹
-
基于名为 jvm-opencv 的模板,用文件夹的内容创建目录和文件
运行该命令后,将创建以下相当简单的项目文件:
. ├── java │ └── HelloCv.java └── project.clj
这看起来不太令人印象深刻,但实际上它们与前一个配方中的两个文件几乎相同:一个项目描述符和一个 Java 文件。
project.clj 的内容是之前的一个略微修改的版本:
(defproject hellocv "0.1.0-SNAPSHOT" :java-source-paths ["java"] :main HelloCv :repositories [ ["vendredi" "http://hellonico.info:8081/repository/hellonico/"]] :dependencies [[org.clojure/clojure "1.8.0"] [opencv/opencv "3.3.1"] [opencv/opencv-native "3.3.1"]])
你可能马上就注意到了三条你以前从未见过的新线条。
首先是 repositories 部分,它指示一个新的存储库位置来查找依赖项。这里提供的是作者的公共存储库,在这里可以找到 opencv(和其他)的定制版本。
opencv 核心依赖项和本机依赖项已经编译并上传到公共存储库中,为您提供方便。
The two dependencies are as follows:
-
中文版
-
opencv-原生
你可能会问,为什么是两个依赖关系?
其中一个依赖因素是用于 macOS、Windows 或 Linux 的 c++ opencv 代码。opencv 核心是独立于平台的 Java 包装器,它调用依赖于平台的 c++代码。
这实际上是当你自己编译 opencv 时,OpenCV 代码的交付方式。
为了方便起见,打包的 opencv-native 依赖项包含 Windows、Linux 和 macOS 的本机代码。
位于 Java 文件夹中的文件 HelloCv.java 中的 Java 代码是一个简单的 helloworld 类示例,它将简单地加载 OpenCV 本地库;其内容如下所示。
import org.opencv.core.Core; import org.opencv.core.CvType; import org.opencv.core.Mat; public class HelloCv { public static void main(String[] args) throws Exception { System.loadLibrary(Core.NATIVE_LIBRARY_NAME); // ① Mat hello = Mat.eye(3,3, CvType.CV_8UC1); // ② System.out.println(hello.dump()); // ③ } } What does the code do?
-
①它告诉 Java 运行时通过 loadLibrary 加载原生 opencv 库。这是使用 OpenCV 时的一个必需步骤,需要在应用的生命周期中完成一次。
-
②然后可以通过 Java 对象创建原生 Mat 对象。
-
Mat 基本上是一个图像容器,就像一个矩阵,这里我们告诉它的大小为 3×3:三个像素的高度,三个像素的宽度,其中每个像素都是 8UC1 类型,这是一个奇怪的名称,只表示八位(无符号)整数(8U)的一个通道(C1)。
-
③最后,打印 mat (matrix)对象的内容。
该项目已经准备好可以像您之前所做的那样运行了,无论您在哪个平台上运行,相同的 leiningen run 命令都会完成这项工作:
NikoMacBook% lein run
命令输出如下所示。
Retrieving opencv/opencv-native/3.3.1/opencv-native-3.3.1.jar from vendredi Compiling 1 source files to /Users/niko/hellocv2/target/classes [ 1, 0, 0; 0, 1, 0; 0, 0, 1]
您看到的打印的 1 和 0 是创建的矩阵的实际内容。
1.3 自动编译和运行代码
问题
虽然 lein 命令非常通用,但是您可能希望在后台启动这个过程,并在您更改代码时让代码自动运行。
解决办法
Leiningen 自带自动插件。一旦启用,该插件将监视文件模式的变化并触发一个命令。让我们使用它!
它是如何工作的
当您使用 jvm-opencv 模板创建一个项目时(见方法 1-2),您会注意到 project.clj 文件的内容比方法中显示的稍长。实际上更像这样:
(defproject hellocv3 "0.1.0-SNAPSHOT" :java-source-paths ["java"] :main HelloCv :repositories [ ["vendredi" "http://hellonico.info:8081/repository/hellonico/"]] :plugins [[lein-auto "0.1.3"]] :auto {:default {:file-pattern #".(java)$"}} :dependencies [[org.clojure/clojure "1.8.0"] [opencv/opencv "3.3.1"] [opencv/opencv-native "3.3.1"]])
突出显示了两条额外的线。一行是在项目元数据的 a :plugins 部分添加 lein-auto 插件。
第二行是:auto 部分,它定义了文件模式来监视变化;这里,以 Java 结尾的文件将激活 auto 子命令的刷新。
让我们回到命令行,现在我们将在通常的 run 命令之前添加 auto 命令。您现在需要编写的命令如下:
lein auto run
第一次运行它时,它会给出与前一个配方相同的输出,但是增加了一些额外的行:
auto> Files changed: java/HelloCv.java auto> Running: lein run Compiling 1 source files to /Users/niko/hellocv3/target/classes [ 1, 0, 0; 0, 1, 0; 0, 0, 1] auto> Completed.
好听;请注意,leiningen 命令尚未完成运行,实际上正在监听文件更改。
从那里开始,用不同大小的 Mat 对象更新 HelloCv 的 Java 代码。所以替换下面一行:
Mat hello = Mat.eye(3,3, CvType.CV_8UC1);
随着
Mat hello = Mat.eye(5,5, CvType.CV_8UC1);
更新后的代码表明 Mat 对象现在是一个 5×5 的矩阵,每个像素仍然由一个一字节的整数表示。
查看运行 leiningen 命令的终端或控制台,查看正在更新的输出:
auto> Files changed: java/HelloCv.java auto> Running: lein run Compiling 1 source files to /Users/niko/hellocv3/target/classes [ 1, 0, 0, 0, 0; 0, 1, 0, 0, 0; 0, 0, 1, 0, 0; 0, 0, 0, 1, 0; 0, 0, 0, 0, 1] auto> Completed.
请注意,这次 mat 对象的打印矩阵是由五行五列组成的。
1.4 使用更好的文本编辑器
问题
到目前为止,您可能已经使用了自己的文本编辑器来输入代码,但是您想要一个稍微好一点的工作环境来使用 OpenCV。
解决办法
虽然这不是最终的解决方案,其他不同的环境可能对您更有效率,但我发现使用基于 Github 的 Atom 编辑器的简单设置非常有效。在实时输入代码时,这个编辑器也非常有用。
喜欢在 Atom 中工作的一个主要原因是图片可以动态地重新加载,因此当处理一个图像时,该图像的更新会自动直接反映在您的屏幕上。据我所知,这是唯一一个有这种支持的编辑器。让我们看看它是如何工作的!
它是如何工作的
安装基本的 Atom 编辑器应该是一件简单的事情,只需访问网站并下载软件,因此只需继续下载安装程序即可。
atom.io/
atom 不仅在默认情况下是一个很好的编辑器,而且很容易添加插件来匹配您的工作风格。
Here for OpenCV, we would like to add three plug-ins:
-
一个通用 IDE 插件
-
一个用于 Java 语言的插件,利用
-
编辑器中的最后一个终端。
The three plug-ins are shown in Figures 1-1, 1-2, and 1-3. Figure 1-1
Figure 1-1
Atom ide-ui 插件
 Figure 1-2
Figure 1-2
Atom Java 语言插件
 Figure 1-3
Figure 1-3
atom ide-终端插件
在底部打开的终端将允许您键入相同的“lein auto run”命令,因此您不需要单独的命令提示符或终端窗口来运行 Leiningen 的自动运行功能。让你所有的代码都写在一个窗口里。
Ideally, your Atom layout would look something like either Figure 1-4 or Figure 1-5. Figure 1-4
Figure 1-4
Atom IDE 标准布局
 Figure 1-5
Figure 1-5
Atom IDE 简洁布局
Note that autocompletion for Java is now enabled through Atom’s Java plug-in too, so typing function names will show a drop-down menu of available options, as shown in Figure 1-6: Figure 1-6
Figure 1-6
Atom IDE 自动完成
最后,虽然不能实时看到图像的更新,但可以在保存文件时看到,如果你在后台打开该文件,每次保存时都会刷新,保存是通过 OpenCV 的函数 imwrite 完成的。
因此,leiningen auto run 命令在后台运行,当 Java 文件被保存时,编译/运行周期被触发,映像被更新。
Figure 1-7 shows how the picture onscreen is visually updated, even without a single user action (apart from file save). Figure 1-7
Figure 1-7
Java 文件保存时自动更新图像
你将在本章的后面看到,但是现在作为参考,这里是使用 submat 函数改变 Mat 对象的一个子部分的颜色的代码片段。
import org.opencv.core.Core; import org.opencv.core.CvType; import org.opencv.core.Mat; import org.opencv.core.Scalar; import static org.opencv.imgcodecs.Imgcodecs.imwrite; public class HelloCv { public static void main(String[] args) { System.loadLibrary(Core.NATIVE_LIBRARY_NAME); Mat hello = new Mat(150,150, CvType.CV_8UC3); hello.setTo(new Scalar(180,80,250)); Mat sub = hello.submat(0,50,0,50); sub.setTo(new Scalar(0,0,100)); imwrite("dev/hello.png", hello); } }
现在,您已经有了享受 OpenCV 全部功能的设置。让我们使用它们。
1.5 学习 OpenCV Mat 对象的基础知识
问题
您将会更好地理解 OpenCV 对象矩阵,因为它是 OpenCV 框架的核心。
解决办法
让我们回顾一下如何创建 mat 对象,并通过几个核心示例检查它们的内容。
它是如何工作的
该制作方法需要与前一制作方法相同的设置。
要创建一个每个“点”只有一个通道的非常简单的矩阵,您通常会使用 Mat 类中的以下三个静态函数之一:0、eye、1。
It easier to see what each of those does by looking at each output in Table 1-2.Table 1-2
静态函数为每个像素创建一个通道
|函数名
|
密码
|
使用
|
输出
|
| --- | --- | --- | --- |
| 零 | 零材料(3.3,CV_8UC1) | 当您希望新的 mat 全为零时 | [0, 0, 0;0, 0, 0;0, 0, 0] |
| 眼睛 | 材质眼(3,3,CV_8UC1) | 当除了 x=y 之外都需要 0 时 | [ 1, 0, 0;0, 1, 0;0, 0, 1] |
| 二进制反码 | Mat.ones(3,3,CV_8UC1) | 当你想要所有的 1 | [ 1, 1, 1; 1, 1, 1;1, 1, 1] |
| (上述任何一项) | Mat.ones(1,1,CV_8UC3) | 每个像素有 3 个通道 | [ 1, 0, 0] |
如果您以前使用过 OpenCV(如果您还没有使用过,请相信我们),您会记得 CV_8UC1 是 OpenCV 的俚语,表示每个通道八位无符号,每个像素一个通道,因此一个 3×3 的矩阵有九个值。
它的表亲 CV_8UC3 ,正如你已经猜到的,为每个像素分配三个通道,因此一个 1×1 的 Mat 对象将有三个值。在处理红色、蓝色、绿色或 RGB 图像时,通常会使用这种类型的垫子。这也是加载图像时的默认格式。
第一个示例简单地展示了加载每像素一个通道的 Mat 对象的三种方法和加载每像素三个通道的 Mat 对象的一种方法。
import org.opencv.core.Core; import org.opencv.core.Mat; import static java.lang.System.loadLibrary; import static java.lang.System.out; import static org.opencv.core.CvType.CV_8UC1; import static org.opencv.core.CvType.CV_8UC3; public class SimpleOpenCV { static { loadLibrary(Core.NATIVE_LIBRARY_NAME); } public static void main(String[] args) { Mat mat = Mat.eye(3, 3, CV_8UC1); out.println("mat = "); out.println(mat.dump()); Mat mat2 = Mat.zeros(3,3,CV_8UC1); out.println("mat2 = "); out.println(mat2.dump()); Mat mat3 = Mat.ones(3,3,CV_8UC1); out.println("mat3 = " ); out.println(mat3.dump()); Mat mat4 = Mat.zeros(1,1,CV_8UC3); out.println("mat4 = " ); out.println(mat4.dump()); } }
最后一个 Mat 对象 mat4 是每个像素包含三个通道的对象。如您所见,当您尝试转储对象时,会创建一个三零数组。
CV_8UC1 和 CV_8UC3 是两种最常见的每像素格式类型,但还有许多其他类型,它们在 CvType 类中定义。
当进行 mat-to-mat 计算时,您可能最终还需要使用每个通道的浮点值。以下是实现这一目标的方法:
Mat mat5 = Mat.ones(3,3,CvType.CV_64FC3); out.println("mat5 = " ); out.println(mat5.dump());
和输出矩阵:
mat5 = [1, 0, 0, 1, 0, 0, 1, 0, 0; 1, 0, 0, 1, 0, 0, 1, 0, 0; 1, 0, 0, 1, 0, 0, 1, 0, 0]
在许多情况下,您可能不会自己从头开始创建矩阵,而只是从文件中加载图像。
1.6 从文件加载图像
问题
你想加载一个图像文件,将它转换成一个 Mat 对象进行数字操作。
解决办法
OpenCV 有一个从文件中读取图像的简单函数,名为 imread。它通常只采用本地文件系统上的文件路径到映像,但也可能有一个类型参数。让我们看看如何使用不同形式的 imread。
它是如何工作的
imread 函数位于同名包的 Imgcodecs 类中。
它的标准用法是简单地给出文件的路径。假设你已经从谷歌搜索下载了一张小猫的图片,并存储在 images/kittenjpg (图 1-8 )中,代码给出如下内容:
Mat mat = Imgcodecs.imread("images/kitten.jpg"); out.println("mat ="+mat.width()+" x "+mat.height()+","+mat.type());  Figure 1-8
Figure 1-8
奔跑的小猫
如果找到并正确加载了小猫图像,控制台的输出中将显示以下消息:
mat =350 x 234,16
注意,如果找不到文件,不会抛出异常,也不会报告错误消息,但是加载的 Mat 对象将是空的,因此没有行也没有列:
mat =0 x 0,0
根据您的编码方式,您可能会觉得需要用大小检查来包装加载代码,以确保找到文件并正确解码图像。
也可以黑白模式加载图片(图 1-9 )。这是通过向 imread 函数传递另一个参数来实现的。
Mat mat = Imgcodecs.imread( "images/kitten.jpg", Imgcodecs.IMREAD_GRAYSCALE);  Figure 1-9
Figure 1-9
灰度加载
另一个参数来自同一个 Imgcodecs 类。
在这里,im read _ gray 在加载时强制对图像进行重新编码,并将 Mat 对象转换为灰度模式。
Other options can be passed to the imread function for some specific handling of channels and depth of the image; the most useful of them are described in Table 1-3.Table 1-3
图像读取选项
|参数
|
影响
|
| --- | --- |
| im read _ REDUCED _ gray _ 2IMREAD_REDUCED_COLOR_2im read _ REDUCED _ gray _ 4IMREAD_REDUCED_COLOR_4im read _ REDUCED _ gray _ 8IMREAD_REDUCED_COLOR_8 | 将加载的图像尺寸缩小 2、4 或 8 倍。这意味着宽度和高度除以这个数。同时,指定彩色或灰度模式。灰度表示单通道灰度模式。颜色是指三通道 RGB。 |
| IMREAD_LOAD_GDAL | 使用 GDAL 驱动程序加载光栅格式的图像。 |
| IMREAD _ 灰度 | 以单通道灰度模式加载图片。 |
| im read _ ignore _ orientation-im read _ ignore _ orientation-im read _ ignore _ orientation-im read _ ignore _ orientation-im read _ ignore _ orientation-im read _ ignore _ orientation | 如果设置,不要根据 EXIF 的方向标志旋转图像。 |
Figure 1-10 shows what happens when the image is loaded in REDUCED_COLOR_8. Figure 1-10
Figure 1-10
减小尺寸装载
您可能已经注意到,用 imread 加载图像时,不需要图像格式的指示。OpenCV 根据文件中找到的文件扩展名和二进制数据的组合进行所有的图像解码。
1.7 将图像保存到文件中
问题
您希望能够使用 OpenCV 保存图像。
解决办法
OpenCV 有一个用于写文件的 imread 的兄弟函数,名为 imwrite,同样由 Imgcodecs 类托管。它通常只需要本地文件系统上指向存储图像位置的文件路径,但是它也可以使用一些参数来修改图像的存储方式。
它是如何工作的
函数 imwrite 的工作方式类似于 imread,当然它也需要 Mat 对象来存储路径。
第一个代码片段简单地保存了彩色加载的猫图像:
Mat mat = imread("images/glasses.jpg"); imwrite("target/output.jpg", mat); Figure 1-11 shows the content of output.jpg picture. Figure 1-11
Figure 1-11
磁盘上 JPEG 格式的图像
现在,您还可以在保存 mat 对象时更改格式,只需指定不同的扩展名。例如,要保存为可移植网络图形(PNG)格式,只需在调用 imwrite 时指定不同的扩展名。
Mat mat = imread("images/glasses.jpg"); imwrite("target/output.png", mat);
没有编码和疯狂的字节操作,您的输出文件确实以 PNG 格式保存。
可以给 imwrite 保存参数,最需要的是压缩参数。
For example, as per the official documentation:
-
对于 JPEG,可以使用参数 CV_IMWRITE_JPEG_QUALITY,取值范围为 0 到 100(越高越好)。默认值为 95。
-
对于 PNG,它可以是从 0 到 9 的压缩级别()。较高的值意味着较小的大小和较长的压缩时间。默认值为 3。
使用压缩参数压缩输出文件是通过另一个名为 MatOfInt 的 opencv 对象完成的,它是一个整数矩阵,或者更简单地说,是一个数组。
MatOfInt moi = new MatOfInt(CV_IMWRITE_PNG_COMPRESSION, 9); Imgcodecs.imwrite("target/output.png", mat, moi);
这将在 png 上启用压缩。通过检查文件大小,您实际上可以看到 png 文件至少小了 10%。
1.8 使用 Submat 裁剪图片
问题
您希望只保存图像的给定部分。
解决办法
这个简短食谱的主要重点是介绍 submat 函数。Submat 返回一个 mat 对象,它是原始对象的子矩阵或子部分。
它是如何工作的
We will take a cat picture and extract only the part we want with submat. The cat picture used for this example is shown in Figure 1-12. Figure 1-12
Figure 1-12
一只猫
当然,你可以用任何你喜欢的猫图片。让我们从正常读取文件开始,用 imread。
Mat mat = Imgcodecs.imread("images/cat.jpg"); out.println(mat);
正如你可能注意到的, println 提供了一些关于 Mat 对象本身的信息。大部分是信息性的内存寻址,所以你可以直接黑掉内存,但是它也显示了 Mat 对象是否是 submat。在这种情况下,由于这是原始图片,所以它被设置为 false。
[ 12001600CV_8UC3, isCont=true, isSubmat=false, nativeObj=0x7fa7da5b0a50, dataAddr=0x122c63000 ] Autocompletion in the Atom editor presents you the different versions of the submat function as shown in Figure 1-13. Figure 1-13
Figure 1-13
不同参数的 Submat
现在让我们使用第一种形式的 submat 函数,其中 submat 接受开始和结束参数,每行和每列一个:
Mat submat = mat.submat(250,650,600,1000); out.println(submat);
打印该对象表明新创建的 Mat 对象确实是 submat。
Mat [ 400400CV_8UC3, isCont=false, isSubmat=true, nativeObj=0x7fa7da51e730, dataAddr=0x122d88688 ]
您可以像普通垫子一样直接在 submat 上操作,因此您可以从保存它开始。
Imgcodecs.imwrite("output/subcat.png", submat); With the range nicely adapted to the original cat picture, the output of the saved image is shown in Figure 1-14: Figure 1-14
Figure 1-14
子猫
好的一面是,您不仅可以在 submat 上操作,而且它还可以在原始 mat 对象上反射。所以如果在 submat 上对猫的脸应用模糊效果,保存整个 mat(不是 submat),只有猫的脸看起来会模糊。看看这是如何工作的:
Imgproc.blur(submat,submat, new Size(25.0, 25.0)); out.println(submat); Imgcodecs.imwrite("output/blurcat.png", mat);
模糊是类org . opencv . imgproc . imgproc的一个关键函数。它将一个大小对象作为参数,指定应用模糊效果时每个像素要考虑的表面,因此大小越大,模糊效果越强。
See the result in Figure 1-15, where if you look carefully, only the face of the cat is actually blurred, and this is the exact face we saved earlier on. Figure 1-15
Figure 1-15
可怜的模糊猫
正如您在 submat 函数的上下文助手菜单中所看到的,还有两种获取 submat 的方法。
一种方法是使用两个范围,第一个是行范围(y 或高度),第二个是列范围(x 或宽度),这两个范围都是使用 range 类创建的。
Mat submat2 = mat.submat(new Range(250,650), new Range(600,1000));
另一种方法是使用矩形,首先给出左上角的坐标,然后给出矩形的大小。
Mat submat3 = mat.submat(new Rect(600, 250, 400, 400));
使用 submat 的最后一种方法是最常用的方法之一,因为它是最自然的。此外,在图片中查找对象时,可以使用该对象的边界框,该对象的类型是 Rect 对象。
请注意,正如您所看到的,更改 submat 会对底层 mat 造成附带损害。因此,如果您决定将 submat 的颜色设置为蓝色:
submat3.setTo(new Scalar(255,0,0)); Imgcodecs.imwrite("output/submat3_2.png", submat3); Imgcodecs.imwrite("output/submat3_3.png", submat2); Imgcodecs.imwrite("output/submat3_4.png", mat); Then Figure 1-16 shows the blue cat face of both submat3_2.png and submat3_3.png. Figure 1-16
Figure 1-16
蓝猫脸
But those changes to the submat also update the underlying mat, as shown in Figure 1-17!! Figure 1-17
Figure 1-17
大图蓝猫脸
所以这里的想法是要小心 submat 的使用地点和时间,但大多数时候这是一种强大的图像处理技术。
1.9 从子 mats 创建 Mat
问题
您希望从零开始手动创建一个由不同子 Mat 组成的 Mat。
解决办法
setTo 和 copyTo 是 OpenCV 的两个重要功能。setTo 会将 mat 的所有像素的颜色设置为指定的颜色,copyTo 会将现有的 Mat 复制到另一个 Mat。使用 setTo 或 copyTo 时,您可能会使用 submats,因此只会影响主 mat 的一部分。
要使用 setTo,我们将使用 OpenCV 的标量对象定义的颜色,目前,它将使用 RGB 颜色空间中的一组值来创建。让我们看看这一切是如何运作的。
它是如何工作的
第一个示例将使用 setTo 创建一个由子 mat 组成的 mat,每个子 mat 都有不同的颜色。
彩色提交的垫子
首先,让我们用 RGB 值来定义颜色。如上所述,颜色是使用一个标量对象创建的,有三个 int 值,每个值在 0 到 255 之间。
第一种颜色是蓝色强度,第二种是绿色强度,最后一种是红色强度。因此,要创建红色,绿色或蓝色,你把它的主要颜色值的最大强度,所以 255,其他的为 0。
看看红色、绿色和蓝色的效果如何:
Scalar RED = new Scalar(0, 0, 255); // Blue=0, Green=0, Red=255 Scalar GREEN = new Scalar(0, 255, 0); // Blue=0, Green=255, Red=0 Scalar BLUE = new Scalar(255, 0, 0); // Blue=255, Green=0, Red=0
为了定义青色、品红色和黄色,让我们将这些颜色视为 RGB 的补色,因此我们将其他通道的最大值设置为 255,并将主通道设置为 0。
青色与红色互补,因此红色通道值设置为 0,其他两个通道设置为 255:
Scalar CYAN = new Scalar(255, 255, 0);
洋红色是绿色的补色,黄色是蓝色的补色。这些定义如下:
Scalar MAGENTA = new Scalar(255, 0, 255); Scalar YELLOW = new Scalar(0, 255, 255);
好吧。我们已经设置好了所有的颜色;让我们用它们来创建一个所有定义的颜色的垫子。下面的 setColors 方法使用主 mat 对象并用主 RGB 颜色或互补色 CMY 填充一行。
查看如何使用带有标量颜色的 submat 上的 setTo 函数填充 submat 内容。
static void setColors(Mat mat, boolean comp, int row) { for(int i = 0 ; i < 3 ; i ++) { Mat sub = mat.submat(row100, row100+100, i100, i100+100); if(comp) { // RGB if(i0) sub.setTo(RED); if(i1) sub.setTo(GREEN); if(i2) sub.setTo(BLUE); } else { // CMY if(i0) sub.setTo(CYAN); if(i1) sub.setTo(MAGENTA); if(i2) sub.setTo(YELLOW); } } }
然后,调用代码以三通道 RGB 颜色模式创建 mat,并填充第一行和第二行。
Mat mat = new Mat(200,300,CV_8UC3); setColors(mat, false, 1); setColors(mat, true, 0); Imgcodecs.imwrite("output/rgbcmy.jpg", mat); The result is a mat made of two rows, each of them filled with the created colored submats , as shown in Figure 1-18. Figure 1-18
Figure 1-18
彩色提交的垫子
提交图片的 mat
颜色很棒,但是你可能会用到图片。第二个例子将向您展示如何使用填充了图片内容的子模板。
首先创建一个 200×200 的 mat 和两个子 mat:一个用于主 mat 的顶部,一个用于主 mat 的底部。
int width = 200,height = 200; Mat mat = new Mat(height,width,CV_8UC3); Mat top = mat.submat(0,height/2,0,width); Mat bottom = mat.submat(height/2,height,0,width);
然后,让我们创建另一个小的 Mat,方法是将一张图片加载到其中,并将其大小调整为顶部(或底部)submat 的大小。这里向您介绍了 Imgproc 类的 resize 函数。
Mat small = Imgcodecs.imread("images/kitten.jpg"); Imgproc.resize(small,small,top.size()); You are free to choose the picture, of course; for now, let’s suppose the loaded small mat is like Figure 1-19: Figure 1-19
Figure 1-19
小猫力量
然后,小猫咪贴图被复制到顶部和底部的子贴图中。
请注意,前面的调整大小步骤至关重要;复制成功是因为 small mat 和 submat 大小相同,因此复制时不会出现问题。
small.copyTo(top); small.copyTo(bottom); Imgcodecs.imwrite("output/matofpictures.jpg", mat); This gives a matofpictures.jpg file of two kittens as shown in Figure 1-20. Figure 1-20
Figure 1-20
双倍小猫力量
If you forget to resize the small mat, the copy fails very badly, resulting in something like Figure 1-21. Figure 1-21
Figure 1-21
小猫迷路了
1.10 突出显示图片中的对象
问题
你有一张图片,上面有一组你想突出显示的物体、动物或形状,也许是因为你想对它们进行计数。
解决办法
OpenCV 提供了一个名为 Canny 的著名函数,可以突出显示图片中的线条。在本章的后面你会看到如何更详细地使用 canny 现在,让我们关注使用 Java 的基本步骤。
OpenCV 的 canny 对灰度 mat 进行轮廓检测。虽然您可以让 canny 为您做这件事,但是让我们明确地将输入面板的颜色空间更改为灰色空间。
在 OpenCV 中,使用核心类中的 cvtColor 函数可以很容易地改变颜色空间。
它是如何工作的
Suppose you have a picture of tools as shown in Figure 1-22. Figure 1-22
Figure 1-22
工作中的工具
像往常一样,我们首先将图片放入垫子中:
Mat tools = imread("images/tools.jpg");
然后,我们使用 cvtColor 函数转换工具贴图的颜色,该函数采用一个源贴图、一个目标贴图和一个目标颜色空间。颜色空间常量位于 Imgproc 类中,并且有一个类似 COLOR_ 的前缀。
所以要把 mat 变成黑白,可以用 COLOR_RGB2GRAY 常量。
cvtColor(tools, tools, COLOR_RGB2GRAY); The black-and-white picture is ready to be sent to canny. Parameters for the canny function are as follows:
-
源材料
-
目标垫
-
低门槛:我们将使用 150.0
-
高阈值:通常约为低阈值2 或低阈值3
-
光圈:3 到 7 之间的奇数值;我们将使用 3。光圈越大,找到的轮廓越多。
-
L2 梯度值,目前设置为真
Canny 使用中心像素和相邻像素的卷积矩阵来计算每个像素的梯度值。如果梯度值高于高阈值,则将其保留为边缘。如果它在两者之间,如果它有一个高梯度连接到它,它就保持不变。
现在,我们可以调用 Canny 函数。
Canny(tools,tools,150.0,300.0,3,true); imwrite("output/tools-01.png", target); This outputs a picture as shown in Figure 1-23: Figure 1-23
Figure 1-23
精巧的工具
对于眼睛、打印机和树木来说,有时可能更容易画出白色变成黑色、黑色变成白色的反转垫子。这是使用核心类中的 bitwise_not 函数完成的。
Mat invertedTools = tools.clone(); bitwise_not(invertedTools, invertedTools); imwrite("output/tools-02.png", invertedTools); The result is shown in Figure 1-24. Figure 1-24
Figure 1-24
倒置的 canny 工具
You can of course apply the same Canny processing to ever more kitten pictures . Figures 1-25, 1-26, and 1-27 show the same code applied to a picture of kittens. Figure 1-25
Figure 1-25
准备好成为精明的小猫了吗
 Figure 1-26
Figure 1-26
机灵的小猫
 Figure 1-27
Figure 1-27
倒置的机灵小猫
1.11 使用 Canny 结果作为掩码
问题
虽然 canny 在边缘检测方面非常出色,但另一种使用其输出的方式是作为遮罩,这会给你一个漂亮的艺术图像。
让我们试着在另一张图片上绘制一个巧妙操作的结果。
解决方法
执行复制操作时,可以使用所谓的掩码作为参数。遮罩是常规的单通道遮罩,因此值为 0 和 1。
当使用遮罩执行复制时,如果该像素的遮罩值为 0,则不复制源遮罩像素,如果该值为 1,则将源像素复制到目标遮罩。
它是如何工作的
在前面的配方中,我们从 bitwise_not 函数的结果中获得了一个新的 Mat 对象。
Mat kittens = imread("images/three_black_kittens.jpg"); cvtColor(kittens,kittens,COLOR_RGB2GRAY); Canny(kittens,kittens,100.0,300.0,3, true); bitwise_not(kittens,kittens);
如果你决定转储小猫(可能不是一个好主意,因为文件相当大……),你会看到一堆 0 和 1;这就是面具的制作过程。
现在我们有了遮罩,让我们创建一个白色的 mat,命名为 target,作为复制函数的目标。
Mat target = new Mat(kittens.height(), kittens.width(), CV_8UC3, WHITE );
然后,我们为拷贝加载一个源,正如您所记得的,我们需要确保它的大小与拷贝操作的另一个组件的大小相同。
让我们对背景对象执行调整大小操作。
Mat bg = imread("images/light-blue-gradient.jpg"); Imgproc.resize(bg, bg, target.size());
给你。你已经准备好复制了。
bg.copyTo(target, kittens); imwrite("output/kittens-03.png", target); The resulting Mat is shown in Figure 1-28. Figure 1-28
Figure 1-28
蓝色背景上的小猫
现在你能回答以下问题了吗:为什么猫被画成白色?
正确答案确实是底层地垫被初始化为全白;请参见新的 Mat(…,白色)声明。当遮罩阻止复制像素时,也就是说,当该像素的值为零时,垫子的原始颜色将显示出来,这里是白色,这就是小猫在图 1-28 中以白色显示的方式。你当然可以试着用黑色的垫子,或者你选择的图片。
我们将在接下来的章节中看到更多这样的例子。
1.12 用轮廓检测边缘
问题
从 canny 操作的结果中,您可能希望找到一个可绘制轮廓的列表,并在垫子上绘制它们。
解决办法
OpenCV 有一组两个函数,通常与 canny 函数一起使用:这些函数是 findContours 和 drawContours 。
寻找轮廓拿一个垫子,在垫子上寻找边缘,或者定义形状的线条。由于原始图片可能包含大量来自颜色和亮度的噪声,您通常使用预处理图像,即应用了 canny 函数的黑白垫。
drawContours 获取 findContours 的结果,这是一个轮廓对象列表,并允许你用特定的特征来绘制它们,比如用来绘制的线条的粗细和颜色。
它是如何工作的
As presented in the solution, OpenCV’s findContours method takes a preprocessed picture along with other parameters:
-
预处理的垫子
-
将接收轮廓对象(MatOfPoint)的空列表
-
等级席;你可以暂时忽略它,让它成为一个空垫子
-
轮廓检索模式,例如是否创建轮廓之间的关系或返回所有轮廓
-
用于存储轮廓的近似类型;例如,绘制所有点或仅关键定义点
首先,让我们包装原始图片的预处理,和寻找轮廓,在我们自己的自定义方法,寻找 _ 轮廓。
static List find_contours(Mat image, boolean onBlank) { Mat imageBW = new Mat(); Imgproc.cvtColor(image, imageBW, Imgproc.COLOR_BGR2GRAY); Canny(imageBW,imageBW,100.0,300.0,3, true); List contours = new ArrayList
该方法返回找到的轮廓列表,其中每个轮廓本身是一个点列表,或者用 OpenCV 术语来说,是一个 MatOfPoint 对象。
接下来,我们编写一个 draw_contours 方法,该方法将使用原始的 Mat 来找出在上一步中找到的每个轮廓的大小,以及我们希望每个轮廓被绘制的厚度。
要绘制轮廓à la opencv,通常使用 for 循环,并将要绘制的轮廓的索引赋予 drawContours 方法。
static Mat draw_contours(Mat originalMat, List contours, int thickness) { Mat target = new Mat(originalMat.height(), originalMat.width(), CV_8UC3, WHITE); for (int i = 0; i < contours.size(); i++) Imgproc.drawContours(target, contours, i, BLACK, thickness); return target; }
太好了;这个食谱的组成部分已经写好了,所以你可以把它们付诸行动。可以用和之前一样的小猫图片作为基础图片。
Mat kittens = imread("images/three_black_kittens.jpg"); List contours = find_contours(kittens, true); Mat target = draw_contours(kittens, contours, 7); imwrite("output/kittens-contours-7.png", target); The draw_contours result is shown in Figure 1-29. Figure 1-29
Figure 1-29
小猫轮廓,厚度=7
Go ahead and change the thickness used when drawing contours . For example, with the thickness set to 3, the slightly different result, with thinner lines, is shown in Figure 1-30. Figure 1-30
Figure 1-30
小猫轮廓,厚度=3
从那里,我们可以再次使用产生的垫作为遮罩时,做背景复制。
下面的代码片段摘自前面的菜谱;该函数获取一个掩码,并使用该掩码进行复制。
static Mat mask_on_bg(Mat mask, String backgroundFilePath) { Mat target = new Mat(mask.height(),mask.width(),CV_8UC3,WHITE); Mat bg = imread(backgroundFilePath); Imgproc.resize(bg, bg, target.size()); bg.copyTo(target, mask); return target; } Figure 1-31 shows the result of a copy with the mask created while drawing contours on thickness set to 3. Figure 1-31
Figure 1-31
蓝色背景上的白色小猫
值得注意的是,在第三章中,你将会看到使用蒙版和背景来获得一些艺术效果的更酷的方法,但是现在,让我们来总结一下这个方法。
1.13 处理视频流
问题
您希望在视频流上使用 OpenCV 并实时进行图像处理。
解决办法
OpenCV 的 Java 版本提供了一个 videoio 包,特别是一个 VideoCapture 对象,它提供了直接从连接的视频设备读取 Mat 对象的方法。
您将首先看到如何从视频设备中检索给定大小的 Mat 对象,然后将 Mat 保存到文件中。
使用一个框架,您还将看到如何在实时图像采集中插入先前的处理代码。
它是如何工作的
拍摄静态照片
下面介绍一下 do_still_captures 函数。需要抓取若干帧,每帧之间要等待多长时间,从哪个 camera_id 拍照。
camera_id 是连接到您机器的捕获设备的索引。您通常会使用 0,但您可能会插入并使用其他外部设备,在这种情况下,请使用相应的 camera_id。
首先创建一个 VideoCapture 对象,参数为 camera_id。
然后创建一个空白的 Mat 对象,并传递它来接收来自 camera.read() 函数的数据。
Mat 对象是您到目前为止使用过的标准 OpenCV Mat 对象,因此您可以轻松地应用您所学的相同变换。
现在,让我们简单地用带时间戳的文件名一个接一个地保存这些帧。
完成后,您可以使用 VideoCapture 对象上的 release 方法将相机返回待机模式。
看看下面的清单。
static void do_still_captures(int frames, int lapse, int camera_id) { VideoCapture camera = new VideoCapture(camera_id); camera.set(Videoio.CV_CAP_PROP_FRAME_WIDTH, 320); camera.set(Videoio.CV_CAP_PROP_FRAME_HEIGHT, 240); Mat frame = new Mat(); for(int i = 0 ; i <frames;i++) { if (camera.read(frame)){ String filename = "video/"+new Date()+".jpg"; Imgcodecs.imwrite(filename, frame); try {Thread.sleep(lapse*1000);} catch (Exception e) {e.printStackTrace();} } } camera.release(); }
调用新创建的函数只是填充参数,因此下面将从 ID 为 0 的设备中拍摄 10 张照片,并且在每张照片之间等待 1 秒钟。
do_still_captures(10,1,0); As is shown in Figure 1-32, ten pictures should be created in the video folder of the project. And, indeed, time flies; it is already past midnight. Figure 1-32
Figure 1-32
迷你——静止卧室的延时
实时工作
好吧。因此,这里的坏消息是 OpenCV Java 包装器没有包括将 Mat 转换为 BufferedImage 的显而易见的方法,buffered image 是处理 Java 图形包中图像的实际对象。
这里不做过多的详细说明,假设您实际上需要这个 MatToBufferedImage 在 Java 框架中实时工作,通过将 Mat 对象转换为 BufferedImage,从而能够将其呈现为标准的 Java GUI 对象。
让我们快速编写一个方法,将 OpenCV Mat 对象转换为标准的 Java BufferedImage。
public static BufferedImage MatToBufferedImage(Mat frame) { int type = 0; if(frame==null) return null; if (frame.channels() == 1) { type = BufferedImage.TYPE_BYTE_GRAY; } else if (frame.channels() == 3) { type = BufferedImage.TYPE_3BYTE_BGR; } BufferedImage image = new BufferedImage(frame.width(), frame.height(), type); WritableRaster raster = image.getRaster(); DataBufferByte dataBuffer = (DataBufferByte) raster.getDataBuffer(); byte[] data = dataBuffer.getData(); frame.get(0, 0, data); return image; }
一旦你有了这个代码块,它实际上会变得更容易,但是你仍然需要更多的代码块;扩展 Java Panel 类 JPanel 的自定义面板。
这个自定义面板,我们称之为 MatPanel ,是由一个字段组成的,该字段是要绘制的 Mat 对象。然后 MatPanel 以这样的方式扩展了 Java JPanel 类: paint() 方法现在使用您刚才看到的方法直接转换 Mat:MatToBufferedImage。
class MatPanel extends JPanel { public Mat mat; public void paint(Graphics g) { g.drawImage(WebcamExample.MatToBufferedImage(mat), 0, 0, this); } }
好吧。默认 OpenCV 包中不知何故丢失的代码现在已经被重新实现,您可以创建一个 Java 框架来接收 Mat 对象。
MatPanel t = new MatPanel(); JFrame frame0 = new JFrame(); frame0.getContentPane().add(t); frame0.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE); frame0.setSize(320, 240); frame0.setVisible(true); frame0.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
本练习的最后一步是简单地使用类似于 do_still_captures 方法的代码,但不是在几帧后停止,而是编写一个永久循环来给视频流留下印象。
VideoCapture camera = new VideoCapture(0); camera.set(Videoio.CV_CAP_PROP_FRAME_WIDTH, 320); camera.set(Videoio.CV_CAP_PROP_FRAME_HEIGHT, 240); Mat frame = new Mat(); while(true){ if (camera.read(frame)){ t.mat=frame; t.repaint(); } } Figure 1-33 gives a real-time view of a Japanese room at 1 am, painted in real time in a Java frame. Figure 1-33
Figure 1-33
Java 框架下的实时流
Obviously, the goal of this is to be able to work with the Mat object in real time, so now a good exercise for you is to write the necessary code that leads to the screenshot seen in Figure 1-34. Figure 1-34
Figure 1-34
实时清晰的图片
答案显示在下面的代码片段中,正如您已经猜到的,这是一个将已经看到的 canny 转换应用到从摄像机读取的 Mat 对象的简单问题。
if (camera.read(frame)){ Imgproc.cvtColor(frame,frame, Imgproc.COLOR_RGB2GRAY); Mat target = new Mat(); Imgproc.Canny(frame,target,100.0,150.0,3,true); t.mat=target; t.repaint(); }
1.14 用 Scala 编写 OpenCV 代码
问题
现在您可以用 Java 编写一点 OpenCV 代码了,您开始喜欢它了,但是希望使用 Scala 来减少样板代码。
解决办法
到目前为止,您已经完成的当前 OpenCV 设置使得运行为 JavaVM 编译的任何类变得容易。因此,如果你设法编译 Scala 类,并且有一个 Leiningen 插件专门用于此,那么其余的几乎是相同的。
也就是说,使用你目前使用的 Leiningen 设置,你只需要在几个地方更新项目元数据,在 project.clj 中。
这分两步进行。首先,添加 scala 编译器和库,然后更新包含 scala 代码的文件所在的目录。
它是如何工作的
基本设置
The project.clj needs be updated in a few places as highlighted in the following.
-
项目名称;当然,这是可选的。
-
主类;你可以保留相同的名字,但是如果你这样做了,确保用 lein clean 删除旧的 Java 代码。
-
接下来,lein-zinc 插件是 Leiningen 的一体化 scala 插件,需要添加。
-
lein-zinc 插件需要在 lein 执行编译之前被触发,因此我们将在项目元数据的 prep-tasks 键中添加一个步骤。prep-tasks 键负责定义在类似命令运行之前需要执行的任务。
-
最后,scala 库依赖项被添加到 dependencies 键中。
生成的 project.clj 文件可以在下面找到。
(defproject opencv-scala-fun "0.1.0-SNAPSHOT" :java-source-paths ["scala"] :repositories [["vendredi" "http://hellonico.info:8081/repository/hellonico/"]] :main SimpleOpenCV :plugins [ [lein-zinc "1.2.0"] [lein-auto "0.1.3"]] :prep-tasks ["zinc" "compile"] :auto {:default {:file-pattern #".(scala)$"}} :dependencies [ [org.clojure/clojure "1.8.0"] [org.scala-lang/scala-library "2.12.4"] [opencv/opencv "3.3.1"] [opencv/opencv-native "3.3.1"] ]) Your new project file setup for scala should look something like the structure shown in Figure 1-35. Figure 1-35
Figure 1-35
Scala 项目目录结构
正如你所看到的,Java 设置没有太大的变化,但是要确保你的源文件现在在 scala 文件夹中。
为了确认所有的东西都就位并正确设置,让我们再次尝试一个简单的 OpenCV 例子,但是这次是在 Scala 中。
您将需要像之前在 Java 示例中所做的那样加载 OpenCV 本地库。如果您将 loadLibrary 调用放在 scala 对象定义中的任何地方,它将被视为 JVM 的静态调用,并将在加载新的 Scala 编写的 SimpleOpenCV 类时加载库。
其余的代码是 Java 代码的直接翻译。
import org.opencv.core._ import org.opencv.core.CvType._ import clojure.lang.RT.loadLibrary object SimpleOpenCV { loadLibrary(Core.NATIVE_LIBRARY_NAME) def main(args: Array[String]) { val mat = Mat.eye(3, 3, CV_8UC1) println("mat = \n" + mat.dump()) } }
编译前面的代码时,一些 Java 字节码是从 scala 源代码中生成的,在目标文件夹中,就像处理 Java 代码一样。
因此,您可以像使用 Java 一样运行 scala 代码,或者使用命令:
lein auto run
控制台中的输出显示了预期的 OpenCV 3x3 眼罩被转储到屏幕上。
NikoMacBook% lein auto run auto> Files changed: scala/DrawingContours.scala, scala/SimpleOpenCV.scala, scala/SimpleOpenCV1.scala, scala/SimpleOpenCV2.scala, scala/SimpleOpenCV3.scala auto> Running: lein run scala version: 2.12.4 sbt version: 0.13.9 fork java? false [warn] Pruning sources from previous analysis, due to incompatible CompileSetup. mat = [ 1, 0, 0; 0, 1, 0; 0, 0, 1] auto> Completed. An overview of the updated setup in Atom for scala can be found in Figure 1-36. Figure 1-36
Figure 1-36
Scala 设置
模糊不清的
同意,第一个 Scala 例子有点太简单了,所以现在让我们使用一些 Scala 中 OpenCV 模糊效果的力量。
import clojure.lang.RT.loadLibrary import org.opencv.core._ import org.opencv.imgcodecs.Imgcodecs._ import org.opencv.imgproc.Imgproc._ object SimpleOpenCV2 { loadLibrary(Core.NATIVE_LIBRARY_NAME) def main(args: Array[String]) { val neko = imread("images/bored-cat.jpg") imwrite("output/blurred_cat.png", blur_(neko, 20)) } def blur_(input: Mat, numberOfTimes:Integer) : Mat = { for(_ <- 1 to numberOfTimes ) blur(input, input, new Size(11.0, 11.0)) input } }
如您所见,连续多次调用模糊效果,以在同一个 Mat 对象上增量应用模糊效果。
And the bored cat from Figure 1-37 can be blurred to a blurred bored cat in Figure 1-38. Figure 1-37
Figure 1-37
无聊的猫
 Figure 1-38
Figure 1-38
模糊又无聊
当然,您已经在本地机器上尝试过了,并且发现 scala 设置有两个非常好的地方。
编译时间减少了一点,而且实际上可以更快地看到 OpenCV 代码的运行。scala 编译器似乎从增量代码变更中决定了所需的编译步骤。
此外,静态导入,即使它们已经存在于 Java 中,也似乎更自然地与 scala 设置集成在一起。
坎尼效应
为了进一步减少样板代码,Scala 不仅简化了类的导入,还简化了方法的导入。
scala 配方中的第三个例子将展示如何在改变加载的 OpenCV Mat 的颜色空间后应用 canny 变换。
代码相当干净;唯一遗憾的是,OpenCV 函数 vconcat 需要一个 java.util.Array,并且不能将原生 scala 对象作为参数,因此您需要使用 Arrays.asList Java 函数来代替。
import java.util.Arrays import org.opencv.core._ import org.opencv.core.CvType._ import org.opencv.core.Core._ import org.opencv.imgproc.Imgproc._ import org.opencv.imgcodecs.Imgcodecs._ import clojure.lang.RT.loadLibrary object SimpleOpenCV3 { loadLibrary(Core.NATIVE_LIBRARY_NAME) def main(args: Array[String]) { val cat = imread("images/cat3.jpg") cvtColor(cat,cat,COLOR_RGB2GRAY) Canny(cat,cat, 220.0,230.0,5,true) val cat2 = cat.clone() bitwise_not(cat2,cat2) val target = new Mat vconcat(Arrays.asList(cat,cat2), target) imwrite("output/canny-cat.png", target) } } The canny parameters have been taken to output something in the simple art space, and this time it’s not really effective to find out edges at all. Figures 1-39 and 1-40 show the before/after of the canny effect on a loaded cat image. Figure 1-39
Figure 1-39
不怕 Scala
 Figure 1-40
Figure 1-40
我已经被警告了
为 Java 编写的绘制等高线示例也已经移植到 Scala,并且可以在本书的示例源代码中找到;目前,这是留给读者的一个简单练习。
1.15 用 Kotlin 编写 OpenCV 代码
问题
用 Scala 编写 OpenCV 转换非常令人兴奋,但是现在 Google 正在推动 Kotlin,你可能会像新手一样用 Kotlin 编写 OpenCV 代码。
解决方法
当然,还有雷宁根的 Kotlin 插件。至于 scala 设置,您需要更新项目元数据,再次更新文件 project。 clj
您通常需要添加 Kotlin 插件,以及 Kotlin 源文件的路径。
它是如何工作的
基本设置
project.clj 文件中需要更新的地方与 scala 设置所需的更新非常相似,并在下面的代码片段中突出显示。
(defproject opencv-kotlin-fun "0.1.0-SNAPSHOT" :repositories [ ["vendredi" "http://hellonico.info:8081/repository/hellonico/"]] :main First :plugins [ [hellonico/lein-kotlin "0.0.2.1"] [lein-auto "0.1.3"]] :prep-tasks ["javac" "compile" "kotlin" ] :kotlin-source-path "kotlin" :java-source-paths ["kotlin"] :auto {:default {:file-pattern #".(kt)$"}} :dependencies [ [org.clojure/clojure "1.8.0"] [opencv/opencv "3.3.1"] [opencv/opencv-native "3.3.1"]])
因为 Kotlin 类是由插件透明地编译成 JavaVM 字节码的,所以您可以像到目前为止所做的那样引用编译后的类。
显然,第一个测试是要找出您是否可以加载一个 Mat 对象并转储它的 0 和 1 值。
以下简短的 Kotlin 片段就是这样做的。
import org.opencv.core.* import org.opencv.core.CvType.* import clojure.lang.RT object First { @JvmStatic fun main(args: Array
在运行通常的 Leiningen run 命令之前,First.kt 文件应该位于 Kotlin 文件夹中。
lein auto run –m First
命令输出也是必要的,它显示了正确创建并打印在控制台上的 OpenCV 对象。
auto> Files changed: kotlin/Blurring.kt, kotlin/ColorMapping.kt, kotlin/First.kt, kotlin/ui/World0.kt, kotlin/ui/World1.kt, kotlin/ui/World2.kt, kotlin/ui/World3.kt, kotl in/ui/World4.kt auto> Running: lein run -m First [ 1, 0, 0; 0, 1, 0; 0, 0, 1] auto> Completed.
这很简单。让我们看看如何用 Kotlin 和 OpenCV 做一些稍微复杂的事情。
颜色变换
下面的新例子展示了如何使用 Imgproc 的 applyColorMap 函数在不同的颜色贴图之间切换,现在所有的东西都用 Kotlin 编码。
import org.opencv.core.* import org.opencv.imgproc.Imgproc.* import org.opencv.imgcodecs.Imgcodecs.* object ColorMapping { @JvmStatic fun main(args: Array
您可能知道,Kotlin 中的构造函数调用不需要冗长的 new 关键字,就像在 Scala 中一样,方法可以静态导入。
You can see this in action and with the original input image in Figure 1-41. Figure 1-41
Figure 1-41
猫准备好了吗
You can see three files being created; those three output files are shown in Figures 1-42, 1-43, and 1-44. Figure 1-42
Figure 1-42
骨猫
 Figure 1-43
Figure 1-43
冬天的猫
 Figure 1-44
Figure 1-44
热猫,改变了它的大小
在 Kotlin 中,正确的类型转换似乎有点困难,但是代码还是非常紧凑,就像在 Scala 中一样,删除了相当多的样板代码。
用户界面
您可能想使用 Kotlin 的一个主要原因是因为它有令人难以置信的 tornadofx 库,这使得在 JVM 底层 GUI 框架 JavaFX 中编写简单的用户界面更加容易。
像这样的小应用非常有用,可以让用户有机会更改 OpenCV 参数并实时看到结果。
Kotlin Setup
可以将 tornadofx 库添加到 dependencies 部分的 project.clj 文件中,如下所示:
(defproject opencv-kotlin-fun "0.1.0-SNAPSHOT" ... :dependencies [ [org.clojure/clojure "1.8.0"] [opencv/opencv "3.3.1"] [no.tornado/tornadofx "1.7.11"] [opencv/opencv-native "3.3.1"]])
因为这个食谱的目标是给你创造性的想法,我们不打算深入学习如何写 Kotlin 代码和用 tornadofx 写 Kotlin 代码。但是您将很快喜欢上几个 Kotlin 示例,了解如何将它们与 OpenCV 集成。
接下来的第一个例子向您展示了如何引导您的 Kotlin 代码在一个帧中显示一幅图像。
虚拟用户界面
A simple tornadofx application basically follows a given Launcher ➤ App ➤ View structure, as shown in the graph of Figure 1-45. Figure 1-45
Figure 1-45
Tornadofx 应用图表
With this diagram in mind, we need to create three classes .
-
HelloWorld0:用户界面应用的主视图
-
MyApp0:要发送到 JavaFX 启动器的 JavaFX 应用对象
-
World0:仅创建一次的主类,因此使用对象而不是类来定义它,以启动基于 JVM 的应用
A view in tornadofx is made of a root panel, which can be customized with the javafx widgets as you want.
-
下面的代码创建了一个视图,该视图由嵌入了 imageview 小部件的图像组成。
-
imageview 的图像大小在定义小部件的块中设置。
-
视图初始化在 init {..} 块,而根对象,由于不能再次实例化,正在用神奇的函数搭配。
package ui; import tornadofx.* import javafx.application.Application import javafx.scene.layout.* class HelloWorld0 : View() { override val root = VBox() init { with(root) { imageview("cat.jpg") { fitHeight = 160.0 fitWidth = 200.0 } } } }
剩下的代码是标准的 tornadofx/javafx 样板文件,用于正确启动基于 javafx 的应用。
class MyApp0: App(HelloWorld0::class) object World0 { @JvmStatic fun main(args: Array
在自动模式下用 leiningen 运行前面的代码,就像到目前为止用
lein auto run –m ui.World0 And a graphical frame should show up on your screen (Figure 1-46). Figure 1-46
Figure 1-46
帧中的图像
实际上,代码和框架略有不同。在根块中设置了一个标题,并在适当的位置添加了以下代码片段。你应该找出在哪里!
title = "Image in Frame"
带有反应式按钮的用户界面
下一个示例建立在前一个示例的基础上,并添加了一个按钮,当单击该按钮时,内部计数器的值会递增,然后该计数器的值会实时显示在屏幕上。
可以使用 SimpleIntegerProperty 或 javafx.beans 包中的 SimpleXXXProperty 来创建反应值。
然后,该反应值可以绑定到一个小部件,在接下来的示例中,它将绑定到一个标签,因此标签的值等于属性的值。
按钮是一个简单的 UI 小部件,您可以在其上定义操作处理程序。处理程序代码可以在块内部,也可以在不同的 Kotlin 函数中。
有了目标和解释,让我们来看下面的代码片段。
package ui; import tornadofx.* import javafx.application.Application import javafx.scene.layout.* import javafx.beans.property.SimpleIntegerProperty import javafx.geometry.Pos class CounterView : View() { override val root = BorderPane() val counter = SimpleIntegerProperty() init { title = "Counter" with (root) { style { padding = box(20.px) } center { vbox(10.0) { alignment = Pos.CENTER label() { bind(counter) style { fontSize = 25.px } } button("Click to increment") { action {increment()} }}}}} fun increment() {counter.value += 1} } class CounterApp : App(CounterView::class) object Counter { @JvmStatic fun main(args: Array Figure 1-47
Figure 1-47
简单的计数器应用
And after a few clicks on the beautiful button, you will get something as in Figure 1-48. Figure 1-48
Figure 1-48
点击几个按钮来增加计数器
模糊应用
嗯,这很酷,但它看起来像是一门创建 GUI 的课程,与 OpenCV 没有太大关系。
没错。
因此,这最后一个 Kotlin 应用建立在前面两个例子的基础上,并展示了如何构建一个模糊应用,其中模糊量由反应属性设置。
你必须在 Java 领域的 Image 对象和 OpenCV 领域的 Mat 对象之间来回切换。下面的例子展示了一种快速的方法,通过使用 OpenCV 中的 imencode 函数,将 Mat 对象编码成字节,而不是将所有这些转换成文件。
模糊应用有一个 SimpleObjectProperty 类型的 val,它随着图形视图的更新而改变。
较长的导入列表有点烦人,但是对于您自己的定制应用,您可能不需要太多的导入列表。
package ui.cv; import org.opencv.core.* import org.opencv.imgproc.Imgproc.* import org.opencv.imgcodecs.Imgcodecs.* import clojure.lang.RT import tornadofx.* import javafx.application.Application import javafx.scene.layout.* import javafx.scene.paint.Color import javafx.application.Platform import javafx.beans.property.SimpleIntegerProperty import javafx.beans.property.SimpleObjectProperty import javafx.geometry.Pos import javafx.scene.image.Image class CounterView : View() { override val root = BorderPane() val counter = SimpleIntegerProperty(1) val imageObj = SimpleObjectProperty(Image("/cat.jpg")) val source = imread("images/cat.jpg") init { title = "Blur" with (root) { style { padding = box(20.px) } center { vbox(10.0) { alignment = Pos.CENTER label() { bind(counter) style { fontSize = 25.px } } imageview(imageObj) { fitWidth = 150.0 fitHeight = 100.0 } button("Click to increment") { action { increment() randomImage() } } button("Click to decrement { action { decrement() randomImage() } } } } } } fun blurImage() { val result_mat = Mat() blur(source, result_mat, Size(counter.value.toDouble(),counter.value.toDouble())) val mat_of_bytes = MatOfByte() imencode(".jpg", result_mat, mat_of_bytes) imageObj.value = Image(java.io.ByteArrayInputStream(mat_of_bytes.toArray())) } fun increment() { counter.value += 6 } fun decrement() { if(counter.value>6) counter.value -= 6 } } class MyBlurApp : App(CounterView::class) object Blur { @JvmStatic fun main(args: Array Figure 1-49
Figure 1-49
模糊应用
当您点按增量按钮时,猫图像变得更加模糊,当您点按减量按钮时,它又变得更加平滑。
There are a few more tornadofx examples in the code samples along with this book, so do not hesitate to check them out. You will probably get more UI with OpenCV ideas; for example a drag-and-drop panel of images, when images can be blurred at will. Doesn’t sound that out of reach anymore, does it?
第一章充满了诀窍,从在 JavaVM 上用 OpenCV 创建一个小项目开始,逐步完成更复杂的图像操作示例,首先用 Java,然后最后享受 JavaVM 运行时环境,从而使用 Scala 工作,然后用富于表现力的 tornadofx 库编写 Kotlin 代码。
The door is now wide open to introduce the origami library, which is a Clojure wrapper for OpenCV. The environment will bring you even more concise code and more interactiveness to try new things and be creative. Time to get excited.
我对未来有一种普遍的兴奋感,但我还不知道那会是什么样子。但无论我做什么都会是。
阿曼达·林德豪特
二、OpenCV 和 Origami
盯着 Origami 说明书看了足够长的时间后,你就会和它们融为一体,并开始从内部理解它们。
祖伊·德佳内尔

Origami 库诞生的动机是,计算机视觉相关的编程应该易于设置、易于运行和易于实验。
这些天,当人工智能和神经网络风靡一时时,我的任务是为各种神经网络准备和生成数据。很快就清楚了,你不能只是将任何类型的图像或视频数据转储到网络,并期望它高效地运行。你需要按照大小、颜色或内容来组织所有这些图像或视频,并尽可能自动处理图像,因为手动整理这十亿张图像可能会非常耗时。
因此,在这一章中,我们将展示 Origami、Clojure 包装器、项目模板和用于 JavaVM 上 OpenCV 库的示例,所有这些都使用一种简洁的语言。
这些示例将通过 Clojure 向您介绍 OpenCV 代码。
您在上一章中看到的设置几乎可以完全原样重用,因此不会浪费时间去学习已经学过的内容。主要是,您只需要将这个库作为一个依赖项添加到一个新创建的项目中。
一旦这个简单的附加设置完成,我们将通过 Origami 库的视角来回顾 OpenCV 的概念。
2.1 开始用 Origami 编码
生活本身很简单……只是不容易。
史蒂夫马拉博里
问题
您已经听说过这个库将 OpenCV 包装在一个名为 Origami 的轻量级 DSL 中,并且您想安装它并在您的机器上尝试一下。
解决办法
如果您已经阅读或翻阅了本书的第一章,您会记得 Leiningen 用于创建项目模板并在简单的项目布局中布局文件。
这里,您将使用一个名为 clj-opencv 的不同项目模板,它将下载依赖项并为您复制所需的文件。
然后,您将看到可用于这个新设置的不同编码风格。
它是如何工作的
当 Leiningen 仍然安装在您的机器上时,您可以使用与创建基于 Java opencv 的项目相同的方式创建一个基于模板的新项目。
使用 Leiningen 模板的项目设置
这一次,项目模板被命名为 clj-opencv,并使用 Leiningen 在终端或控制台上调用:
lein new clj-opencv myfirstcljcv
这将下载新模板,并创建一个 myfirstcljcv 文件夹,其内容大致如下:
├── notes │ ├── empty.clj │ └── practice.clj ├── output ├── project.clj ├── resources │ ├── XML │ │ ├── aGest.xml │ │ ├── closed_frontal_palm.xml │ │ ├── face.xml │ │ ├── fist.xml │ │ ├── haarcascade_eye_tree_eyeglasses.xml │ │ ├── haarcascade_frontalface_alt2.xml │ │ └── palm.xml │ ├── cat.jpg │ ├── minicat.jpg │ ├── nekobench.jpg │ ├── souslesoleil.jpg │ └── sunflower.jpg └── test └── opencv3 ├── ok.clj ├── simple.clj ├── tutorial.clj └── videosample.clj 6 directories, 19 files In the preceding file structure
-
notes 是一个包含代码的文件夹,以 notes 的形式提供给 gorilla 和 lein-gorilla。我们将回顾如何使用这两个野兽。
-
project.clj 是已经看到的 leiningen 项目文件。
-
参考资料包含用于练习和 opencv 识别特性的示例图像和 XML 文件。
-
测试包含示例 Clojure 代码,展示如何开始使用 opencv 和 origami。
如您所知,project.clj 文件保存了几乎所有的项目元数据。这一次我们将使用一个版本,它比你在第一章中看到的版本稍有更新。
与前一章的主要区别在下面重点介绍,所以让我们快速回顾一下。
(defproject sample5 "0.1-SNAPSHOT" :injections [ (clojure.lang.RT/loadLibrary org.opencv.core.Core/NATIVE_LIBRARY_NAME)] :plugins [[lein-gorilla "0.4.0"]] :test-paths ["test"] :resource-paths ["rsc"] :main opencv3.ok :repositories [ ["vendredi" "https://repository.hellonico.info/repository/hellonico/"]] :aliases {"notebook" ["gorilla" ":ip" "0.0.0.0" ":port" "10000"]} :profiles {:dev { :resource-paths ["resources"] :dependencies [ ; used for proto repl [org.clojure/tools.nrepl "0.2.11"] ; proto repl [proto-repl "0.3.1"] ; use to start a gorilla repl [gorilla-repl "0.4.0"] [seesaw "1.4.5"]]}} :dependencies [ [org.clojure/clojure "1.8.0"] [org.clojure/tools.cli "0.3.5"] [origami "0.1.2"]])
正如所料,origami 库已经作为依赖项添加到依赖项部分。
还增加了一个名为 gorilla 的插件。这将帮助你运行 python 的笔记本风格代码;我们将在后面的食谱中介绍这一点。
注入部分一开始可能有点晦涩,但它主要是说本地 OpenCV 库的加载将在启动环境时完成,所以您不必像第一章中的问题那样在所有示例中重复它。
一切都好
要运行的主名称空间是opencv 3 . ok;让我们现在运行它,以确保设置就绪。这一点从第一章开始就没有改变,您仍然可以在终端或控制台上使用相同的命令来加载代码:
lein run
在一小段输出之后,您应该能够看到类似这样的内容
Using OpenCV Version: 3.3.1-dev .. #object[org.opencv.core.Mat 0x69ce2f62 Mat [ 12001600CV_8UC1, isCont=true, isSubmat=false, nativeObj=0x7fcb16cefa70, dataAddr=0x10f203000 ]] A new gray neko has arisen! The file grey-neko.jpg would have been created in the project folder and be like the picture in Figure 2-1. Figure 2-1
Figure 2-1
Grey Neko(消歧义)
opencv3.ok 名称空间的代码完整编写如下:
(ns opencv3.ok (:require [opencv3.core :refer :all])) (defn -main [& args] (println "Using OpenCV Version: " VERSION "..") (-> (imread "resources/cat.jpg") (cvt-color! COLOR_RGB2GRAY) (imwrite "grey-neko.jpg") (println "A new gray neko has arisen!")))
你会认出前一章中使用的 imread 、 cvtColor 、 imwrite opencv 函数,事实上 java opencv 函数只是简单地包装在 Clojure 中。
This first code sequence flow written in the origami DSL is shown in Figure 2-2. Figure 2-2
Figure 2-2
第一个 Origami 示例的代码流
网络摄像头检查
如果你有一个网络摄像头插入,有另一个启动摄像头和视频流的例子。运行这个的文件在 samplevideo.clj 中。
和前面一样,您可以通过为 lein run 命令指定名称空间来启动示例。
lein run -m opencv3.videosample When the command starts, you will be presented with a moving view of the coffee shop you are typing those few lines of code in, just as in Figure 2-3. Figure 2-3
Figure 2-3
东京咖啡店
虽然这只是运行项目模板中包含的示例,但是您已经可以开始在自己的文件中编写自己的实验代码,并使用 lein run 命令运行它们。
自动插件反击了
你很快就会明白为什么这通常不是使用 origami 的最佳方式,因为这每次都会重新编译你所有的源文件。然而,这是一种可以用来检查所有代码编译和运行都没有错误的技术。
所以这里有一个关于如何为 Java、Scala 和 Kotlin 设置第一章中介绍的自动插件解决方案的快速提示,这次是针对 Clojure/Origami 代码。
修改 project.clj 文件以添加 lein-auto 插件,使其与以下代码匹配:
:plugins [[lein-gorilla "0.4.0"][lein-auto "0.1.3"]] :auto {:default {:file-pattern #".(clj)$"}}
默认情况下,这不在项目模板中,因为大多数时候可能不需要它。
一旦添加了这个,您就可以通过在想要执行的命令前面加上 auto 来运行通常的 auto 命令。这里:
lein auto run
这将执行主名称空间,并等待文件更改编译并再次执行。
因此,在修改了 ok.clj 文件的 main 方法后,如下所示:
(defn -main [& args] (-> (imread "resources/cat.jpg") (cvt-color! COLORMAP_JET) (imwrite "jet-neko.jpg") (println "A new jet neko has arisen!"))) You can see a new file jet-neko.jpg created and a new fun-looking cat, as in Figure 2-4. Figure 2-4
Figure 2-4
喷气猫
现在,虽然这个带有自动插件的设置非常好,但是让我们看看如何通过使用 Clojure REPL 来最小化代码输入和处理输出之间的延迟。
在 REPL
我们刚刚回顾了如何以类似于 Java、Scala 和 Kotlin 的方式运行示例和编写一些 Origami 代码,并再次看到了如何包含和使用自动插件。
更好的是,Clojure 带有一个读取-评估-打印-循环(REPL)环境,这意味着你可以一行一行地输入代码,比如命令,然后立即执行。
为了启动 Clojure REPL,Leiningen 有一个名为 REPL 的子命令,可以用
lein repl
在终端/控制台上打印一些启动行之后:
nREPL server started on port 64044 on host 127.0.0.1 - nrepl://127.0.0.1:64044 REPL-y 0.3.7, nREPL 0.2.11 Clojure 1.8.0 Java HotSpot(TM) 64-Bit Server VM 1.8.0_151-b12 Docs: (doc function-name-here) (find-doc "part-of-name-here") Source: (source function-name-here) Javadoc: (javadoc java-object-or-class-here) Exit: Control+D or (exit) or (quit) Results: Stored in vars *1, *2, *3, an exception in *e
然后,您将看到 REPL 提示:
opencv3.ok=>
opencv3.ok 是项目的主名称空间,您可以在提示符下键入代码,就像在 opencv3/ok.clj 文件中键入代码一样。例如,让我们通过打印版本来检查底层 OpenCV 库是否正确加载:
(println "Using OpenCV Version: " opencv3.core/VERSION "..") ; Using OpenCV Version: 3.3.1-dev ..
该库确实被正确加载,并且通过 Leiningen 的魔法找到了原生绑定。
让我们现在就开始吧。下面两行从 utils 名称空间获取一些函数,主要是打开一个框架,然后加载一个图像并将其打开到那个框架中:
(require '[opencv3.utils :as u]) (u/show (imread "resources/minicat.jpg")) The cute cat from Figure 2-5 should now be showing up on your computer as well. Figure 2-5
Figure 2-5
可爱的猫
Origami 艺术鼓励图像处理流水线的概念。因此,要读取图像,转换加载图像的颜色,并在一个帧中显示结果图像,您通常会使用 Clojure 线程宏-->,一个接一个地流水线化所有的函数调用,就像下面的一行程序一样:
(-> "resources/minicat.jpg" imread (cvt-color! COLOR_RGB2GRAY) (u/show)) Which now converts the minicat.jpg from Figure 2-5 to its gray version as in Figure 2-6. Figure 2-6
Figure 2-6
灰色可爱的猫
->无非是重新组织代码,使第一个调用结果进入下一行的输入,依此类推。这使得图像处理代码非常快速和简洁。
请注意,这些行是直接执行的,所以您不必等待文件更改或任何事情,只需按 Enter 键就可以在屏幕上得到结果。
Instant gratification.
即时满足需要太长时间。
凯丽·费雪
原子公司的 REPL
Leiningen 开发的 REPL 相当不错,通过文档可以发现许多其他特性,但是它很难与标准文本编辑器提供的自动完成功能竞争。
使用来自 project.clj 文件的所有相同的项目元数据,Atom 编辑器实际上可以通过插件提供即时和可视化的完成选择。
The plug-in to install is named proto-repl. Effectively, you will need to install two plug-ins
-
prot-repl 所需的油墨插件
-
原始复制插件
to get the same setup on your atom editor, as shown in Figure 2-7. Figure 2-7
Figure 2-7
在 Atom 中安装两个插件:ink 和 proto-repl
The same Leiningen-based REPL can be started either by the atom menu as in Figure 2-8 or by the equivalent key shortcut. Figure 2-8
Figure 2-8
从 Atom 内部启动 REPL
启动 REPL 时,Atom 编辑器的右侧会打开一个名为 Proto-REPL 的窗口。这与您直接从终端执行 lein repl 命令时使用的 REPL 完全相同。所以,你也可以在那里输入代码。
But the real gem of this setup is to have autocompletion and choice presented to you when typing code, as in Figure 2-9. Figure 2-9
Figure 2-9
即时完成
You can now retype the code to read and convert the color of an image directly in a file , let’s say ok.clj. Your setup should now be similar to that shown in Figure 2-10. Figure 2-10
Figure 2-10
Atom 编辑器+ Clojure 代码
输入代码后,您可以使用 Ctrl-Alt+s(在 Mac 上,Command-Ctrl+s)来选择代码并执行选定的代码行。
您还可以通过使用 Ctrl-Alt+b(在 Mac 上,Command-Ctrl+b)来执行光标前的代码块,并获得即时满足感。
After code evaluation, and a slight tab arrangement, you can have instant code writing on the left-hand side, and the image transformation feedback on the right-hand side, just as in Figure 2-11. Figure 2-11
Figure 2-11
基于编辑器的理想计算机视觉环境
jet-set cat 现在显示在 output.jpg 文件中,可以通过在打开的编辑器选项卡中更新和执行代码来更新。
比如自己看看添加 resize 时会发生什么!处理流程中的函数调用,如下面的代码所示。
(-> (imread "resources/cat.jpg") (resize! (new-size 150 100)) (cvt-color! COLORMAP_JET) (imwrite "output.jpg"))
很好。一只新调整大小的喷气机猫现在立刻出现在你的屏幕上。
大猩猩笔记本
为了完成这个食谱,让我们展示一下如何在一个 Origami 项目中使用 gorilla。
Gorilla 是一个 Leiningen 插件,你可以在其中编写和运行笔记本,就像 python 的 jupyter 一样。
这意味着你可以在编写文档的同时编写代码,更好的是,你还可以与外界分享这些笔记。
这是怎么回事?Gorilla 接受您的项目设置,并使用它在后台 REPL 中执行代码。因此,它将找到取自 project.clj 文件的 origami/opencv 设置。
它还将启动一个 web 服务器,其目标是提供笔记或工作表。工作表是您可以编写代码行并执行它们的页面。
您还可以在表单中以 markdown 标记的形式编写文档,该标记呈现为 HTML。
结果,每一个笔记,或者工作表,实际上都是一个迷你博客。
clj-opencv 模板附带的 project.clj 文件定义了一个方便的 leiningen 别名来通过笔记本别名启动 gorilla:
:aliases {"notebook" ["gorilla" ":ip" "0.0.0.0" ":port" "10000"]}
这有效地告诉 leiningen 将 notebook 子命令转换为下面的 gorilla 命令:
lein gorilla :ip 0.0.0.0 :port 10000
让我们通过在控制台或终端上使用以下命令来尝试一下:
lein notebook
几秒钟后,大猩猩 REPL 启动了。您可以在以下位置访问它:
http://localhost:10000/worksheet . html?filename=notes/practice.clj
You will be presented with a worksheet like in Figure 2-12. Figure 2-12
Figure 2-12
大猩猩笔记本和一只猫
In a gorilla notebook , every block of the page is either Clojure code or markdown text. You can turn the currently highlighted block to text mode by using Alt+g, Alt+m (or Ctrl+g, Ctrl+m on Mac) where m is for markdown, as in Figure 2-13. Figure 2-13
Figure 2-13
降价文本模式
You can also turn back the highlighted block into code mode by using Alt+g, Alt+j (or Ctrl+g, Ctrl+j on Mac), where j is for Clojure, as in Figure 2-14. Figure 2-14
Figure 2-14
代码块
To execute the highlighted block of code , you would use Shift+Enter, and the block turns into executed mode, as in Figure 2-15. Figure 2-15
Figure 2-15
Clojure 代码已执行
它所做的是从代码块中读取,通过 websocket 将输入发送到后台 REPL,检索结果,并将其打印到代码块的底层 div 中。
To make it easy to navigate a worksheet, the most used shortcuts have been gathered in Table 2-1.Table 2-1
大猩猩 REPL 最常用的快捷键
|快捷方式 Windows/Linux
|
快捷 Mac
|
使用
|
| --- | --- | --- |
| -好的 | -好的 | 去上面的街区 |
| ↓ | ↓ | 去下面的街区 |
| Shift+Enter | Shift+Enter | 评估突出显示的块 |
| Alt+g,Alt+b | Ctrl+g, Ctrl+b | 在当前块之前插入块 |
| Alt+g,Alt+n | Ctrl+g, Ctrl+n | 在当前块旁边插入块 |
| Alt+g、Alt+u | Ctrl+g, Ctrl+u | 将当前块上移一个块 |
| Alt+g,Alt+d | Ctrl+g, Ctrl+d | 将当前块向下移动一个块 |
| Alt+g、Alt+x | Ctrl+g, Ctrl+x | 删除当前块 |
| alt+空格 | ctrl+空格键 | 自动完成选项 |
| Alt+g, Alt+s | Ctrl+g,Ctrl+s | 保存当前工作表 |
| Alt+g,Alt+l | Ctrl+g, Ctrl+l | 加载一个工作表(一个文件) |
| Alt+g,Alt+e | Ctrl+g、Ctrl+e | 用新文件名保存当前工作表 |
好吧。现在你知道了在大猩猩 REPL 中开始输入代码所需要的一切。我们现在就来试试这个。在工作表的新代码块中,尝试键入以下 Clojure 代码。
(-> "http://eskipaper.cimg/jump-cat-1.jpg" (u/mat-from-url) (u/resize-by 0.3) (u/mat-view)) And now… Shift+Enter! This should bring you close to Figure 2-16 and a new shot of instant gratification . Figure 2-16
Figure 2-16
瞬间跳跃猫
请记住,所有这些都发生在浏览器中,这有三个直接的积极后果。
第一个是远程人员实际上可以查看您的工作表,他们可以通过直接连接到 URL 直接从自己的机器上提供文档。
第二,他们也可以直接逐块执行代码,了解流程。
第三,工作表的保存格式使得它们可以用作标准名称空间,并且可以通过正常的代码编写工作流来使用。相反,这也意味着标准的 Clojure 文件可以打开,文档可以通过大猩猩 REPL 添加。
从现在开始,我们不会强制使用大猩猩 REPL 或 Atom 环境,甚至不会简单地在 REPL 上打字。实际上,这是同一个项目设置的三个不同视图。
现在只需记住,要显示一张图片,根据你是在大猩猩 REPL 还是在标准的 REPL,所用的函数会略有不同。
在大猩猩 REPL:
(u/mat-view)
在标准 REPL 中:
(u/show)
在 atom 中,您可以保存文件:
(imwrite mat “output.jpg”)
好吧,这次你真的准备好了!是时候学习一些计算机视觉基础知识了。
2.2 使用垫子
问题
正如你在第一章中所记得的,Mat 是你在使用 OpenCV 时最好的朋友。您还需要记住 new Mat()、setTo、copyTo 等函数来操作 Mat。现在,你想知道如何使用 Origami 库进行基本的 Mat 操作。
解决办法
因为 Origami 主要是 OpenCV 的包装器,所以所有相同的功能都存在于 API 中。这个菜谱再次展示了基本的 Mat 操作,并通过展示使用 Clojure 可能实现的代码技巧进一步展示了这些操作。
它是如何工作的
创建垫子
记住你需要一个高度,一个宽度和一些通道来创建一个垫子。这是使用新材料功能完成的。下面的代码片段创建了一个 30×30 的 Mat,每个像素一个通道,每个值都是一个整数。
(def mat (new-mat 30 30 CV_8UC1)) If you try to display the content of the mat, either with u/mat-view (gorilla repl) or u/show (standard repl), then the memory assigned to the mat is actually left as is. See Figure 2-17. Figure 2-17
Figure 2-17
没有指定颜色的新垫子
让我们指定一种颜色,对垫子的每个像素都一样。这可以在创建垫子时完成,或可以通过设置为来完成,这是对的调用。OpenCV 的 Java 函数 setTo 。
(def mat (new-mat 30 30 CV_8UC1 (new-scalar 105))) ; or (def mat (new-mat 30 30 CV_8UC1)) (set-to mat (new-scalar 105)) Every pixel in the mat now has value 105 assigned to it (Figure 2-18). Figure 2-18
Figure 2-18
指定颜色的垫子
为了理解 OpenCV 的大多数底层矩阵概念,使用检查底层 mat 的值通常是一个好主意。转储或简单的转储。
这将在本章中重复几次。要使用它,只需在您想要查看其内部的垫子上调用 dump。
(->> (new-scalar 128.0) (new-mat 3 3 CV_8UC1) (dump))
预期的输出如下所示,mat 点的值都设置为 128。
[128 128 128] [128 128 128] [128 128 128]
。dump 调用原始的 OpenCV 函数,并将在一个字符串中打印所有的行和列像素值。
"[128, 128, 128;\n 128, 128, 128;\n 128, 128, 128]"
制作彩色垫子
对于每个像素一个通道,您只能指定每个像素的白色强度,因此,您只能创建灰色垫。
要创建一个彩色垫,你需要三个通道,默认情况下,每个通道的值代表红色,蓝色和绿色的强度。
要创建一个 30×30 的红色 mat,下面的代码片段将创建一个空的三通道 mat,mat 中的每个点都设置为 RGB 值 255 0 0:
(def red-mat (new-mat 30 30 CV_8UC3 (new-scalar 0 0 255)))
以类似的方式,创建蓝色或绿色的垫子:
(def green-mat (new-mat 30 30 CV_8UC3 (new-scalar 0 255 0))) (def blue-mat (new-mat 30 30 CV_8UC3 (new-scalar 255 0 0))) If you execute all this in the gorilla REPL, each of the mats shows up, as in Figure 2-19. Figure 2-19
Figure 2-19
红色、绿色和蓝色垫子
使用 Submat
你会记得我们已经在第一章看到了如何使用 submat 让我们回顾一下如何使用 Origami 来使用这些 submats。
这里,我们首先创建一个每个像素有三个通道的 RGB mat,并将所有像素设置为青色。
然后可以使用 submat 函数和一个矩形来定义 submat 的大小,从而创建一个 submat。
这给出了以下代码片段:
(def mat (new-mat 30 30 CV_8UC3 (new-scalar 255 255 0))) (def sub (submat mat (new-rect 10 10 10 10))) (set-to sub (new-scalar 0 255 255)) The resulting main mat, with yellow inside where the submat was defined, and the rest of the mat in cyan color, is shown in Figure 2-20. Figure 2-20
Figure 2-20
用 Origami 提交
在这个阶段,看看一行 Origami 代码能做什么,通过使用 hconcat!,一个将多个地垫连接在一起的函数,以及 clojure.core/repeat ,创建一个相同项目的序列。
(u/mat-view (hconcat! (clojure.core/repeat 10 mat3))) The resulting pattern is shown in Figure 2-21. Figure 2-21
Figure 2-21
Origami 乐趣
至此,你已经可以自己琢磨出一些有创意的生成模式了。
设置一种像素颜色
使用 set-to 设置垫子的所有颜色。使用 Java 方法 put 将一个像素设置为一种颜色。 put 函数获取 mat 中的一个位置,以及一个表示该像素的 RGB 值的字节数组。
因此,如果您想创建一个 3×3 的 mat,它的所有像素都是黄色的,您可以使用下面的代码片段。
(def yellow (byte-array [0 238 238])) (def a (new-mat 3 3 CV_8UC3)) (.put a 0 0 yellow) (.put a 0 1 yellow) (.put a 0 2 yellow) (.put a 1 0 yellow) (.put a 1 1 yellow) (.put a 1 2 yellow) (.put a 2 0 yellow) (.put a 2 1 yellow) (.put a 2 2 yellow)
遗憾的是,3×3 的 mat 对于这本书来说有点太小了,所以你应该自己输入代码。
转储函数在这里工作得很好,您可以在下面看到黄色 mat 的内容:
[0 238 238 0 238 238 0 238 238] [0 238 238 0 238 238 0 238 238] [0 238 238 0 238 238 0 238 238]
不过逐行输入这些内容有点累,所以这里需要使用 Clojure 代码根据需要遍历像素。
调用 Clojure core doseq 可以方便地减少样板文件。
(doseq [x [0 1 2] y [0 1 2]] (prn "x=" x "; y=" y))
前面简单的 doseq 片段简单地遍历了一个 3×3 mat 的所有像素。
"x=" 0 "; y=" 0 "x=" 0 "; y=" 1 "x=" 0 "; y=" 2 "x=" 1 "; y=" 0 "x=" 1 "; y=" 1 ...
因此,为了更有趣一点,让我们为 100×100 彩色垫的每个像素显示一些随机的红色变体。手动操作会很累,所以我们在这里也使用 doseq 序列。
(def height 100) (def width 100) (def a (new-mat height width CV_8UC3)) (doseq [x (range width) y (range height)] (.put a x y (byte-array [0 0 (rand 255)]))) Figure 2-22 gives one version of the executed snippet. Figure 2-22
Figure 2-22
随机填充的红色像素变体垫子
滚边工艺和一些生成艺术
您已经可以看到 Origami 是如何让生成性工作与 OpenCV mats 的集成变得非常简单和有趣的。
这一小段也将快速介绍 Origami 所鼓励的流水线制作过程。
Clojure 有两个主要的构造(称为宏),名为->和-> >他们通过流水线在连续的函数调用中传递结果。
第一个函数调用的结果作为参数传递给第二个函数,然后第二个函数调用的结果传递给第三个函数,依此类推。
第一个宏-->,将结果作为第一个参数传递给下一个函数调用。
第二个宏--> >,将结果作为最后一个参数传递给下一个函数调用。
例如,可以通过以下方式创建随机灰色遮罩:
(->> (rand 255) (double) (new-scalar) (new-mat 30 30 CV_8UC1) (u/mat-view)) Which, read line by line, gives the following steps:
-
用 rand 生成随机值;该值介于 0 和 255 之间。
-
生成的值是一个 float,所以我们把这个值变成 double。
-
new-scalar 用于创建 OpenCV 可以方便处理的等效字节数组。
-
然后,我们创建一个新的 30×30 通道的 mat,并将标量传递给 new-mat 函数,以将 mat 的颜色设置为随机生成的值。
-
Finally, we can view the generated mat (Figure 2-23).
 Figure 2-23
Figure 2-23生成随机灰色垫
你也可以用随机颜色的垫子做同样的事情。这次调用 rand 函数三次(图 2-24 )。
(->> (new-scalar (rand 255) (rand 255) (rand 255)) (new-mat 30 30 CV_8UC3) (u/mat-view))
或者,结果相同,但使用了更多的 Clojure 核心函数:
(->> #(rand 255) (repeatedly 3) (apply new-scalar) (new-mat 30 30 CV_8UC3) (u/mat-view)) where
-
创建一个匿名函数
-
重复调用前面的函数三次,以生成由三个随机值组成的数组
-
apply 使用数组作为新标量的参数
-
如您之前所见,new-mat 创建了一个垫子
-
u/mat-view displays the mat (Figure 2-24) in the gorilla REPL

图 2-24。
现在,您可以看到如何在这些迷你代码流的基础上构建不同的 mat 生成变体。你也可以组合那些垫子,当然是用 hconcat!或者 vconcat!OpenCV 的功能。
下面的新代码片段使用 range 生成一个 25 个元素的序列,然后通过缩放范围值在 0–255 的范围内创建灰色垫(图 2-25 )。
(->> (range 25) (map #(new-mat 30 30 CV_8UC1 (new-scalar (double (* % 10))))) (hconcat!) (u/mat-view))  Figure 2-25
Figure 2-25
25 个垫的灰色渐变
您还可以通过生成 255 个值的范围来使事情变得平滑,并使创建的垫子稍微小一些,每个垫子的大小为 2×10(图 2-26 )。
(->> (range 255) (map #(new-mat 20 2 CV_8UC1 (new-scalar (double %)))) (hconcat!) (u/mat-view))  Figure 2-26
Figure 2-26
255 色垫的平滑灰色渐变
2.3 装载、展示、保存地垫
问题
您已经看到了如何创建和生成地垫;现在您想要保存它们,重新打开它们,并打开位于 URL 中的 mats。
解决办法
Origami 包装了两个主要的 opencv 函数来与文件系统交互,即 imread 和 imwrite。
它还提供了一个名为 imshow 的新函数,如果您以前使用过标准 opencv,您可能会看到这个函数。这里将会更详细地介绍它。
最后,u/mat-from-url 是一个 origami 实用函数,它允许您检索托管在网络上的 mat。
它是如何工作的
装货
imread 的工作方式与 opencv 完全相同;这主要意味着您只需给它一个来自文件系统的路径,文件就会被读取并转换成一个随时可用的 Mat 对象。
在最简单的形式中,可以像下面的简短代码片段那样加载图像:
(def mat (imread "resources/kitten.jpg"))
文件路径 resources/kitten.jpg 是相对于项目的,也可以是文件系统上的完整路径。
The resulting loaded Mat object is shown in Figure 2-27. Figure 2-27
Figure 2-27
“这不是猫。”
Following the opencv documentation, the following image file formats are currently supported by Origami :
-
Windows 位图.bmp、.dib
-
JPEG 文件- 。jpeg、。jpg、*。jpe(日本)
-
便携式网络图形- *。png
-
sun grid-* . Sr、*.ras
The following are also usually supported by OpenCV but may not be supported on all platforms coming with Origami:
-
JPEG 2000 文件- *.jp2
-
webp。web 页
-
便携式图像格式- 。多溴联苯醚。PGM . *。ppm(ppm)
-
TIFF 文件- 。tiff,。标签图像文件格式。
加载图像时,可以参考表 1-3 指定用于加载图像的选项,如灰度,同时调整大小。
要加载灰度并将图像大小调整为其大小的四分之一,您可以使用下面的代码片段,该代码片段是使用您刚刚看到的流水线样式编写的。
(-> "resources/kitten.jpg" (imread IMREAD_REDUCED_GRAYSCALE_4) (u/mat-view)) It loads the same picture, but the mat looks different this time , as its color has been converted, like in Figure 2-28. Figure 2-28
Figure 2-28
“这不是灰猫。”
节约
Origami 的 imwrite 函数取自 opencv 的 imwrite,但是颠倒了参数的顺序,使得该函数在处理流水线时易于使用。
例如,要将先前加载的灰色猫写入一个新文件,您可以使用
(imwrite mat "grey-neko.png") A new file, grey-neko.png , will be created from the loaded mat object (Figure 2-29). Figure 2-29
Figure 2-29
灰色 neko.png
您可以观察到生成的文件图像实际上已经从 jpg 转换为 png,只需在文件名中将其指定为扩展名。
更改参数顺序的原因是,在这种情况下,您可以从流水线代码流中保存图像。
请参见下面在转换流程中图像是如何保存的。
(-> "resources/kitten.jpg" (imread IMREAD_REDUCED_GRAYSCALE_4) (imwrite "grey-neko.png") (u/mat-view))
该垫将被保存在文件图像 grey-neko.png,并处理将继续到下一步,在这里垫查看。
表演
Origami 提供了一种快速预览图像的方式,并以来自 opencv3.utils 名称空间的 imshow 函数的形式传输。
(-> "resources/kitten.jpg" (imread) (u/imshow)) The imshow function takes a mat as the parameter and opens a Java frame with the mat inside, as shown in Figure 2-30. Figure 2-30
Figure 2-30
被陷害的猫
The frame opened by imshow has a few default sets of key shortcuts, as shown in Table 2-2.Table 2-2
快速视图中的默认键
|钥匙
|
行动
|
| --- | --- |
| Q | 关闭框架 |
| F | 全屏边框;再次按下返回窗口模式 |
| S | 快速保存当前显示的图片 |
这还不是全部;当使用 imshow 来定义从框架的背景颜色到其大小等等的各种设置时,您可以传递一个贴图。此外,可以将处理程序部分添加到地图中,您可以在其中定义自己的快捷键。
请参见以下帧的配置图示例。
{:frame {:color "#000000" :title "image" :width 400 :height 400} :handlers { 85 #(gamma! % 0.1) 86 #(gamma! % -0.1)}}
在处理程序部分,映射的每个条目都由一个 ASCII 键码和一个函数组成。该函数接受一个 mat,并且必须返回一个 mat。在这里,你可以假设伽玛!是根据亮度参数改变垫子亮度的功能。
Figure 2-31 shows the mat after pressing u. Figure 2-31
Figure 2-31
深色猫
Figure 2-32 shows the mat after pressing v. Figure 2-32
Figure 2-32
明亮的猫
这不是本书最重要的部分,但是在第四章中,快速帧在播放视频流时变得非常方便。
从 URL 加载
虽然通常情况下可以从运行代码的文件系统访问图片,但是很多时候需要处理远程托管的图片。
Origami 提供了一个基本的 mat-from-url 函数,该函数获取一个 url 并将其转换为 OpenCV mat。
在 origami 中完成这项工作的标准方法如下面的代码片段所示:
(-> "http://www.hellonico.info/static/cat-peekaboo.jpg" (u/mat-from-url) (u/mat-view)) And the resulting image is shown in Figure 2-33. Figure 2-33
Figure 2-33
来自互联网的猫
直到最近,这还是加载图片的唯一方式。但是,大多数时候,你会做一些像
(-> "http://www.hellonico.info/static/cat-peekaboo.jpg" (u/mat-from-url) (u/resize-by 0.5) (u/mat-view))
加载图片后立即调整其大小。现在,u/mat-from-url 也接受 imread 参数。因此,要加载灰色的远程图片,并减小它的大小,可以直接传入 IMREAD_*参数。注意,这有在文件系统上创建临时文件的副作用。
(-> "http://www.hellonico.info/static/cat-peekaboo.jpg" (u/mat-from-url IMREAD_REDUCED_GRAYSCALE_4) (u/mat-view)) The same remote picture is now both smaller and loaded in black and white, as shown in Figure 2-34. Figure 2-34
Figure 2-34
黑白猫归来
2.4 使用颜色、色彩映射表和色彩空间
颜色是我们大脑和宇宙相遇的地方。
保罗·克莱尔
问题
您想学习更多关于如何在 OpenCV 中处理颜色的知识。到目前为止,我们只看到了使用 RGB 编码的颜色。肯定还有!
解决办法
Origami 提供了两个简单的名称空间,opencv3.colors.rgb 和 opencv3.colors.rgb,来创建用于基本着色的标量值,因此我们将首先回顾如何使用这两个名称空间来将颜色设置为 mat。
颜色贴图的工作原理类似于颜色过滤器,根据您的心情,您可以使垫子变得更红或更蓝。
应用-颜色-贴图!和变身!是用来实现颜色切换的两个 opencv 核心函数。
最后,cvt-color!是另一个核心 opencv 函数,它将一个 mat 从一个颜色空间带到另一个颜色空间,例如从 RGB 到黑白。这是 OpenCV 的一个重要的关键特性,因为大多数识别算法不能在标准 RGB 中正确使用。
它是如何工作的
简单的颜色
需要来自 origami 包的颜色,因此当您使用它们时,需要更新笔记本顶部的名称空间声明。
(ns joyful-leaves (:require [opencv3.utils :as u] [opencv3.colors.html :as html] [opencv3.colors.rgb :as rgb] [opencv3.core :refer :all]))
使用名称空间 rgb,您可以为 RGB 值创建标量,而不是猜测它们。
So, if you want to use a red color , you can get your environment to help you find and autocomplete the scalar you are looking for, as shown in Figure 2-35. Figure 2-35
Figure 2-35
颜色
因此,在实际应用中,您确实可以使用下面的代码片段来创建一个 20×20 的红色垫子。
(-> (new-mat 20 20 CV_8UC3 rgb/red-2) (u/mat-view ))
请注意,由于 rgb/red-2 是一个标量,您可以通过打印来转储每个通道的值:
object[org.opencv.core.Scalar 0x4e73ed0 "[0.0, 0.0, 205.0, 0.0]"]
这是很好的快速找到颜色代码。
创建了opencv3.colors.html名称空间,以便您也可以使用 css 中使用的传统十六进制符号。对于一个漂亮的浅绿色带一点蓝色,你可以用这个:
(html/->scalar "#66cc77")
在全样本模式下,使用线程--> >,这将给出
(->> (html/->scalar "#66cc77") (new-mat 20 20 CV_8UC3 ) (u/mat-view )) which creates a small mat of a light green/blue color (Figure 2-36). Figure 2-36
Figure 2-36
使用 HTML 代码的颜色
打印颜色本身会为您提供指定的 RGB 值:
(html/->scalar "#66cc77") ; "[119.0, 204.0, 102.0, 0.0]"
你确实可以通过自己创建 RGB 标量来检查颜色是否匹配。
(->> (new-scalar 119 204 102) (new-mat 20 20 CV_8UC3 ))
这将给你一个具有完全相同的基于 RGB 的颜色的垫子。
彩色地图
使用简单的滤镜,通过简单的颜色变化就可以理解彩色地图,这与您最喜欢的智能手机照片应用类似。
有一些默认的地图可以和 OpenCV 一起使用;让我们尝试其中的一种,比如 COLORMAP_AUTUMN,它将垫子变成了一种相当秋天的红色。
To apply the map to a Mat, for example the cat from Figure 2-37, simply use the apply-color-map! function . Figure 2-37
Figure 2-37
要上色的猫
下面的代码片段显示了如何依次使用通常的 imread 和 apply-color-map。
(-> "resources/cat-on-sofa.jpg" (imread IMREAD_REDUCED_COLOR_4) (apply-color-map! COLORMAP_AUTUMN) (u/mat-view)) The resulting cat is shown in Figure 2-38. Figure 2-38
Figure 2-38
秋猫
Here is the full list of standard color maps available straight out of the box; try them out!
-
COLORMAP_HOT
-
COLORMAP_HSV
-
COLORMAP_JET
-
色彩映射表 _ 骨骼
-
COLORMAP_COOL
-
COLORMAP_PINK(彩色贴图 _ 粉红色)
-
COLORMAP_RAINBOW(彩虹色)
-
COLORMAP_OCEAN
-
COLORMAP_WINTER
-
COLORMAP_SUMMER(颜色映射 _ 夏天)
-
colormap _ 秋季
-
COLORMAP_SPRING
您也可以定义自己的色彩空间转换。这是通过矩阵乘法来完成的,这听起来很怪,但实际上比听起来简单。
我们将以 rgb/yellow-2 为例。你可能不记得了,所以如果你把它打印出来,你会发现这实际上被编码为,没有蓝色,一些绿色,一些红色,翻译成 RGB 给出如下:[0 238 238]。
然后,我们定义一个由三列三行组成的变换矩阵;由于我们使用的是 RGB 色板,因此我们将在三通道模式下执行此操作。
[0 0 0] ; blue [0 0.5 0] ; green [0 1 0.5] ; red
这个矩阵是做什么的?请记住,我们希望对每个像素应用颜色转换,这意味着在输出中,我们希望每个像素都有一组 RGB 值。
For any given pixel , the new RGB values are such that
-
蓝色为 0 ×输入蓝色+ 0 ×输入绿色+ 0 ×输入红色
-
绿色为 0 ×输入蓝色+ 0.5 ×输入绿色+ 0 ×输入红色
-
红色为 0 ×输入蓝色+ 1 ×输入绿色+ 0.5 输入红色
因此,由于我们的垫子都是黄色的,我们有以下输入:
[0 238 238]
并且每个像素的输出如下:
[0x0 + 0x238 + 0x238, 0x0 + 0.5x238 + 0 x 238, 0x0 + 1x238 + 0.5x238]
或者,由于 255 是通道的最大值:
[0 119 255]
在 Origami 代码中,给出了以下内容:
(def custom (u/matrix-to-mat [ [0 0 0] ; blue [0 0.5 0] ; green [0 1 0.5] ; red ])) (-> (new-mat 3 3 CV_8UC3 rgb/yellow-2) (dump))
这里,mat 内容与 dump 一起显示:
[0 238 238 0 238 238 0 238 238] [0 238 238 0 238 238 0 238 238] [0 238 238 0 238 238 0 238 238]
然后:
(-> (new-mat 30 30 CV_8UC3 rgb/yellow-2) u/mat-view) (-> (new-mat 3 3 CV_8UC3 rgb/yellow-2) (transform! custom) (dump))
转换的结果如下所示,如预期的那样由[0 119 255]个值的矩阵组成。
[0 119 255 0 119 255 0 119 255] [0 119 255 0 119 255 0 119 255] [0 119 255 0 119 255 0 119 255] (-> (new-mat 30 30 CV_8UC3 rgb/yellow-2) (transform! custom) u/mat-view)
确保一个接一个地执行语句,以查看输出中不同的 RGB 值,以及彩色垫。
你可以在文献中寻找,但一个好的棕褐色转换将使用以下矩阵:
(def sepia-2 (u/matrix-to-mat [ [0.131 0.534 0.272] [0.168 0.686 0.349] [0.189 0.769 0.393]])) (-> "resources/cat-on-sofa.jpg" (imread IMREAD_REDUCED_COLOR_4) (transform! sepia-2) (u/mat-view )) With the resulting sepia cat in Figure 2-39. Figure 2-39
Figure 2-39
棕褐色猫
是时候出去制作自己的过滤器了!
我们已经看到了如何将变换应用于 RGB 中的每个像素。稍后,当切换到其他色彩空间时,您也可以记住,即使这些值不再是红色、蓝色、绿色,这个变换!功能仍然可以以同样的方式使用。
彩色空间
到目前为止,你一直在 RGB 色彩空间中工作,这是最简单的一种。在大多数计算情况下,RGB 不是最有效的,因此过去已经创建了许多其他颜色空间,可供使用。对于 Origami,要从一个切换到另一个,通常使用函数 cvt-color!
色彩空间开关有什么作用?
这基本上意味着每个像素的三个通道值具有不同的含义。
例如,RGB 中的红色可以在 RGB 中编码为 0 0 238(其图形表示如图 2-40 ):
(-> (new-mat 1 1 CV_8UC3 rgb/red-2) (.dump)) ; "[ 0, 0, 238]" (-> (new-mat 30 30 CV_8UC3 rgb/red-2) (u/mat-view))  Figure 2-40
Figure 2-40
RGB 颜色空间中的红色
但是,当您更改颜色空间并将其转换到另一个名称空间时,比如 HSV,Hue-Saturation-Value,矩阵的值会发生变化。
(-> (new-mat 1 1 CV_8UC3 rgb/red-2) (cvt-color! COLOR_RGB2HSV) (.dump)) (-> (new-mat 30 30 CV_8UC3 rgb/red-2) (cvt-color! COLOR_RGB2HSV) (u/mat-view)) And of course, the simple display of the mat content is not really relevant anymore; as shown in Figure 2-41, it turned to yellow!! Figure 2-41
Figure 2-41
HSV 颜色空间中的红色
改变色彩空间并不意味着改变垫子的颜色,而是改变这些颜色在内部的表现方式。
你为什么想要改变色彩空间?
虽然每种颜色空间都有自己的优点,但是颜色空间 HSV 被广泛使用,因为它很容易使用范围来识别和找到垫中给定颜色的形状。
如你所知,在 RGB 中,每个通道的每个值代表红色、绿色或蓝色的强度。
在 opencv 术语中,假设我们希望看到红色的线性级数;我们可以增加或减少绿色和蓝色这两个通道的值。
(->> (range 255) (map #(new-mat 20 1 CV_8UC3 (new-scalar % % 255))) (hconcat!) (u/mat-view)) That shows the line of Figure 2-42. Figure 2-42
Figure 2-42
RGB 中红色的线性强度
但是,如果在一张图片中,我们试图寻找橙色的形状呢?嗯…那个橙色在 RGB 下看起来怎么样?
是的,它开始变得有点困难。让我们采取不同的方法,看看 HSV 颜色空间。
As mentioned, HSV stands for Hue-Saturation-Value :
-
Hue 就是你所理解的颜色:它通常是 0 到 360 之间的值,代表 360 度,即使我们使用最多的 OpenCV 八位图片实际上使用的范围是 0 到 180,或者一半。
-
饱和度是灰度的数量,它的范围在 0 到 255 之间。
-
Value 代表亮度,范围在 0 到 255 之间。
在这种情况下,让我们看看会发生什么,如果我们自己画这个,用我们到目前为止学到的东西。
函数 hsv-mat 从一个色调值创建一个 mat。
正如你所看到的,代码切换了两次色板的颜色空间,一次是将颜色空间设置为 HSV 并设置色调,然后返回到 RGB,这样我们就可以稍后用常用函数 imshow 或 mat-view 来绘制它。
(defn hsv-mat [h] (let[m (new-mat 20 3 CV_8UC3)] (cvt-color! m COLOR_BGR2HSV) (set-to m (new-scalar h 255 255)) (cvt-color! m COLOR_HSV2BGR) m))
我们已经在 OpenCV 中看到了从 0 到 180 的色调范围,所以让我们在它上面做一个范围,并用 hconcat 创建一个所有小垫子的连接垫子。
(->> (range 180) (map hsv-mat) (hconcat!) (u/mat-view)) The drawn result is shown in Figure 2-43. Figure 2-43
Figure 2-43
色调值
首先,您可能会注意到,在条形的末尾,颜色又变回红色。因此,它通常被认为是圆柱体。
你可能注意到的第二件事是,通过提供一个范围,可以更容易地分辨出你要找的颜色。例如,20-25 通常用于黄色。
Because it can be annoying to select red in one range, you can sometimes use the reverse RGB during the color conversion: instead of using COLOR_BGR2HSV, you can try to use COLOR_RGB2HSV (Figure 2-44). Figure 2-44
Figure 2-44
倒置色调光谱
这样更容易选择红色,色调范围在 105 到 150 之间。
让我们在一只红色的猫身上试试。在自然界很难找到一只红色的猫,所以我们用一张图来代替。
猫加载了下面的代码片段(图 2-45 )。
(-> "resources/redcat.jpg" (imread IMREAD_REDUCED_COLOR_2) (u/mat-view))  Figure 2-45
Figure 2-45
天然红猫
然后,我们定义一个范围的下红和上红。剩余的饱和度和值被设置为 30 30(有时 50 50)和 255 255(有时 250 250),因此从非常暗和灰色到完全成熟的色调颜色。
(def lower-red (new-scalar 105 30 30)) (def upper-red (new-scalar 150 255 255))
现在,我们使用 opencv 的范围内函数,我们将在后面的配方 2-7 中再次看到,说我们想在指定的范围内找到颜色,并将结果存储在一个蒙版中,该蒙版被初始化为一个空的 mat。
(def mask (new-mat)) (-> "resources/redcat.jpg" (imread IMREAD_REDUCED_COLOR_2) (cvt-color! COLOR_RGB2HSV) (in-range lower-red upper-red mask)) (u/mat-view mask) Et voila: the resulting mask mat is in Figure 2-46. Figure 2-46
Figure 2-46
图片中红色的遮罩
我们将在后面看到寻找颜色技术的更多细节,但是现在你明白为什么你想要把颜色空间从 RGB 转换到更容易处理的东西,这里还是 HSV。
2.5 旋转和变换垫子
我现在要回想一下,天体的运动是圆周运动,因为球体的运动是圆周旋转。
尼古拉斯·哥白尼
问题
你想开始旋转垫和应用简单的线性变换。
解决办法
OpenCV 中有三种实现旋转的方法。
在非常简单的情况下,您可以简单地使用 flip,它将水平、垂直或同时水平和垂直翻转图片。
另一种方法是使用旋转函数,这是一个简单的函数,基本上只取一个方向常数,并根据该常数旋转垫子。
全明星的方式是使用函数 warp-affine。使用它可以做更多的事情,但是要掌握它稍微困难一些,需要利用矩阵计算来执行转换。
让我们看看这一切是如何运作的!
它是如何工作的
我们将在整个教程中使用一个基础图像,所以现在就开始加载它以供进一步参考(图 2-47 )。当然,是的,在这个阶段你已经可以加载你自己的了。
(def neko (imread "resources/ai3.jpg" IMREAD_REDUCED_COLOR_8)) (u/mat-view neko)  Figure 2-47
Figure 2-47
小猫准备翻转和旋转
轻弹
好吧。这一个相当容易。你只需要在图像上调用 flip,用一个参数告诉你想要怎样翻转。
请注意在图像处理流程中第一次使用克隆。
一边翻转!在适当的位置进行变换,从而修改传递给它的图片,克隆创建一个新的垫子,因此原始的 neko 保持不变。
(-> neko (clone) (flip! 0) (u/mat-view)) And the result is shown in Figure 2-48. Figure 2-48
Figure 2-48
翻转的猫
大多数 Origami 功能都是这样工作的。标准版,这里是 flip,需要一个输入垫和一个输出垫,而 flip!就地转换,只需要一个输入/输出垫。还有,虽然 flip 没有返回值,但是 flip!返回输出 mat,以便在流水线中使用。
同样的,你已经看过 cvt-color 了,还有 cvt-color!,还是 hconcat 和 hconcat!,等等。
让我们用 Clojure 玩一会儿,用一个序列显示垫子上所有可能的翻转。
(->> [1 -1 0] (map #(-> neko clone (flip! %))) (hconcat!) (u/mat-view)) This time, all the flips are showing (Figure 2-49). Figure 2-49
Figure 2-49
触发器
循环
功能旋转!也采用一个旋转参数,并根据它旋转图像。
(-> neko (clone) (rotate! ROTATE_90_CLOCKWISE) (u/mat-view)) Note again the use of clone to create an intermediate mat in the processing flow, and the result in Figure 2-50. Figure 2-50
Figure 2-50
顺时针旋转的猫
还要注意如何使用 clone 和--> >从一个源创建多个垫子。
(->> [ROTATE_90_COUNTERCLOCKWISE ROTATE_90_CLOCKWISE] (map #(-> neko clone (rotate! %))) (hconcat!) (u/mat-view)) In the final step, the multiple mats are concatenated using hconcat! (Figure 2-51) or vconcat! (Figure 2-52). Figure 2-51
Figure 2-51
使用 hconcat!在旋转垫上
 Figure 2-52
Figure 2-52
使用 vconcat!在旋转垫上
由于使用了 clone,原来的垫子保持不变,仍然可以在其他加工流水线中使用,就像刚刚装载一样。
弯曲
最后一个,正如承诺的,是稍微复杂一点的版本,使用 opencv 函数 warp- affine 和旋转矩阵来旋转图片。
The rotation matrix is created using the function get-rotation-matrix-2-d and three parameters:
-
一个旋转点,
-
旋转角度,
-
缩放值。
在第一个例子中,我们将缩放因子设为 1,旋转角度为 45 度。
我们还将旋转点作为原始垫子的中心。
(def img (clone neko)) (def rotation-angle 45) (def zoom 1) (def matrix (get-rotation-matrix-2-d (new-point (/ (.width img) 2) (/ (.height img) 2)) rotation-angle zoom))
matrix 也是一个 2×3 的 Mat,由浮点值组成,打印出来就可以看到。然后,旋转矩阵可以传递给扭曲函数。Warp 还需要一个尺寸来创建具有适当尺寸的最终垫子。
(warp-affine! img matrix (.size img)) (u/mat-view img) And the 45-degrees-rotated cat is shown in Figure 2-53. Figure 2-53
Figure 2-53
45 度
现在让我们用一些自动生成技术来增加一些乐趣。让我们创建一个垫子,它由旋转的猫的多个垫子串联而成,每个猫以不同的旋转因子旋转。
为此,让我们创建一个函数 rotate-by! ,使用 get-rotation-matrix-2d 获取图像和角度,并在内部应用旋转
(defn rotate-by! [img angle] (let [M2 (get-rotation-matrix-2-d (new-point (/ (.width img) 2) (/ (.height img) 2)) angle 1)] (warp-affine! img M2 (.size img))))
然后,您可以在小型流水线中使用该函数。流水线采用 0 到 360°之间的旋转范围,并按顺序将每个角度应用于原始 neko 垫。
(->> (range 0 360 40) (map #(-> neko clone (rotate-by! % ))) (hconcat!) (u/mat-view)) And the fun concatenated mats are shown in Figure 2-54. Figure 2-54
Figure 2-54
范围和旋转
此外,让我们增强轮换!函数还可以使用可选的缩放参数。如果未指定缩放因子,其值默认为 1。
(defn rotate-by! ([img angle] (rotate-by! img angle 1)) ([img angle zoom] (let [M2 (get-rotation-matrix-2-d (new-point (/ (.width img) 2) (/ (.height img) 2)) angle zoom)] (warp-affine! img M2 (.size img)))))
然后,zoom 参数被传递给 get-rotation-matrix-2d 函数。
这一次,该代码片段只是在七个随机缩放值上做了一个范围。
(->> (range 7) (map (fn[_] (-> neko clone (rotate-by! 0 (rand 5))))) (hconcat!) (u/mat-view)) And the result is shown in Figure 2-55. Also note that when the zoom value is too small, default black borders can be seen in the resulting small mat. Figure 2-55
Figure 2-55
七只随机缩放的猫
同样,许多其他图像变换也可以使用 warp-affine 来完成,方法是传递使用 get-affine-transform、get-perspective-transform 等变换矩阵创建的矩阵。
大多数转换采用点的源矩阵和点的目标矩阵,并且每个 opencv get-**函数创建一个转换矩阵,以相应地从一组点映射到其他点。
当 OpenCV 需要一个“东西”的 mat 时,您可以使用 util 包中的 origami 构造函数 matrix-to-matofxxx。
(def src (u/matrix-to-matofpoint2f [[0 0] [5 5] [4 6]])) (def dst (u/matrix-to-matofpoint2f [[2 0] [5 5] [4 6]])) (def transform-mat (get-affine-transform src dst))
应用变换的方式与扭曲仿射相同。
(-> neko clone (warp-affine! transform-mat (.size neko)) u/mat-view) Figure 2-56 shows the result of the affine transformation . Figure 2-56
Figure 2-56
猫仿射变换
2.6 过滤垫
问题
与形状变形和点移动的 mat 变换相反,过滤对原始 mat 的每个像素应用一个操作。
这个食谱是关于了解不同的过滤方法。
解决办法
在这个食谱中,我们将首先看看如何创建和应用手动滤镜,通过手动改变每个像素的值。
由于这很无聊,我们将继续使用乘法!通过应用每个通道值的系数来有效地改变垫子的颜色和亮度。
接下来,我们将使用 filter-2-d,进行一些实验,该实验用于将定制的滤镜应用于垫子。
该菜谱将以如何使用阈值和自适应阈值来在 mat 中仅保留部分信息的例子来结束。
它是如何工作的
手动过滤器
第一个示例是一个函数,它将三通道图片中除一个通道值之外的所有通道值都设置为 0。这具有完全改变垫子颜色的效果。
请注意该函数如何在内部创建 mat 中所有字节的完全有序的字节数组。此处使用 3 是因为我们假设我们正在使用由每个像素三个通道组成的 mat。
(defn filter-buffer! [image _mod] (let [ total (* 3 (.total image)) bytes (byte-array total)] (.get image 0 0 bytes) (doseq [^int i (range 0 total)] (if (not (= 0 (mod (+ i _mod) 3))) (aset-byte bytes i 0))) (.put image 0 0 bytes) image))
mod if 语句实现了这一点,因此我们为 mat 中的所有像素将该通道的所有值都设置为 0。
We then use a new cat picture (Figure 2-57). Figure 2-57
Figure 2-57
美丽的法国猫
只需将我们的功能付诸行动。参数中的值 0 意味着除了蓝色通道之外的所有通道都将被设置为 0。
(-> "resources/emilie1.jpg" (imread) (filter-buffer! 0) (u/mat-view)) And yes, the resulting picture is overly blue (Figure 2-58). Figure 2-58
Figure 2-58
蓝猫
在这里,我们再次使用 Clojure 代码生成功能,在通道范围内创建所有三个 mat 的串联 mat(图 2-59 )。
(def source (imread "resources/emilie1.jpg")) (->> (range 0 3) (map #(filter-buffer! (clone source) %)) (hconcat!) (u/mat-view))  Figure 2-59
Figure 2-59
三只猫
乘;成倍增加;(使)繁殖
手动创建一个过滤器来查看其过滤器如何工作的细节是很好的,但实际上,OpenCV 有一个名为 multiply 的函数已经为你完成了所有这些工作。
该函数使用 origami 的 mat-to-mat-of-double 创建的 mat 对像素中每个通道的值进行乘法运算。
So, in an RGB-encoded picture, using matrix [1.0 0.5 0.0] means that
-
蓝色通道将保持原样;蓝色通道值将乘以 1.0
-
绿色通道值将减半;其值将乘以 0.5
-
红色通道值将被设置为 0;其值将乘以 0。
将此直接付诸行动,我们使用下面的简短片段将白猫变成醇厚的蓝色图片(图 2-60 )。
(-> "resources/emilie1.jpg" (imread) (multiply! (u/matrix-to-mat-of-double [ [1.0 0.5 0.0]] )) (u/mat-view))  Figure 2-60
Figure 2-60
醇厚的猫
光度
结合您在第二章中已经学到的关于更改通道的知识,您可能会记得,虽然 RGB 在更改特定颜色通道的强度方面非常出色,但在 HSV 颜色空间中更改亮度值也很容易。
这里,我们再次使用 OpenCV 的乘法函数,但是这一次,mat 的颜色空间在乘法之前被改变为 HSV。
(-> "resources/emilie1.jpg" (imread) (cvt-color! COLOR_BGR2HSV) (multiply! (u/matrix-to-mat-of-double [ [1.0 1.0 1.5]] )) (cvt-color! COLOR_HSV2RGB) (u/mat-view)) Note how the matrix used with multiply only applies a 1.5 factor to the third channel of each pixel, which in the HSV color space is indeed the luminosity . A bright result is shown in Figure 2-61. Figure 2-61
Figure 2-61
明亮的猫
高光
前面的小片段实际上为您提供了一种突出 mat 中的元素的好方法。假设你创建了一个 submat,或者你可以通过一些寻找形状的算法来访问它;您可以应用发光度效果来仅高亮显示整个垫子的该部分。
This is what the following new snippet does:
-
它将主 mat 加载到 img 变量中
-
它创建了一个处理流水线,专注于 img 的一个子表
-
颜色转换和乘法运算仅在 submat 上完成
(def img (-> "resources/emilie1.jpg" (imread))) (-> img (submat (new-rect 100 50 100 100)) (cvt-color! COLOR_RGB2HLS) (multiply! (u/matrix-to-mat-of-double [ [1.0 1.3 1.3]] )) (cvt-color! COLOR_HLS2RGB)) (u/mat-view img) The resulting highlight mat is shown in Figure 2-62. Figure 2-62
Figure 2-62
猫脸
过滤器 2d
filter-2d****,这里介绍的新 OpenCV 函数,也是对字节进行运算的。但是这一次,它根据 src 像素的值和周围像素的值来计算目标 mat 的每个像素的值。
为了理解什么都不做是怎么可能的,让我们举一个例子,通过应用将当前像素的值乘以 1 的过滤器,乘法保持像素的值不变,并忽略其邻居的值。对于这种效果,3×3 滤镜矩阵在中心(目标像素)的值为 1,在所有其他像素(周围的相邻像素)的值为 0。
(-> "resources/emilie4.jpg" (imread) (filter-2-d! -1 (u/matrix-to-mat [[0 0 0] [0 1 0] [0 0 0]])) (u/mat-view)) This does nothing! Great. We all want more of that. The filter-2-d function call really just keeps the image as is, as shown in Figure 2-63. Figure 2-63
Figure 2-63
未受干扰的猫
让我们回到矩阵和原始像素值上来,通过一个简单的灰色矩阵的例子,更好地理解事情是如何进行的。
(def m (new-mat 100 100 CV_8UC1 (new-scalar 200.0))) The preceding snippet, as you know by now, creates a small 100×100 gray mat (Figure 2-64). Figure 2-64
Figure 2-64
灰色垫子
现在,我们将使用 submat 来关注灰色贴图的一部分,并仅在 submat 上应用 filter-2d 函数。
我们采用 3×3 矩阵进行运算,并对主中心像素使用 0.3 的值。这意味着当我们应用滤镜时,目标矩阵中对应像素的值将是 200×0.25=50。
(def s (submat m (new-rect 10 10 50 50))) (filter-2-d! s -1 (u/matrix-to-mat [[0 0 0] [0 0.25 0] [0 0 0]])) Here, that means the entire submat will be darker than the pixels not located in the submat, as confirmed in Figure 2-65. Figure 2-65
Figure 2-65
Submat 已更改
如果您在一个小得多的 mat 上查看像素值本身,您会看到中心像素(submat)的值被正好除以 4。
(def m (new-mat 3 3 CV_8UC1 (new-scalar 200.0))) (def s (submat m (new-rect 1 1 1 1))) (filter-2-d! s -1 (u/matrix-to-mat [[0 0 0] [0 0.25 0] [0 0 0]])) (dump m) ; [200 200 200] ; [200 50 200] ; [200 200 200]
你还能用 filter-2-d 做什么?它也可以用于艺术效果;您可以使用自定义值创建自己的过滤器。所以,继续尝试吧。
(-> "resources/emilie4.jpg" (imread) (filter-2-d! -1 (u/matrix-to-mat [[17.8824 -43.5161 4.11935] [ -3.45565 27.1554 -3.86714] [ 0.0299566 0.184309 -1.46709]])) (bitwise-not!) (u/mat-view)) The preceding filter turns the cat image into a mat ready to receive some brushes of watercolors (Figure 2-66). Figure 2-66
Figure 2-66
巧妙的猫
阈值
阈值是另一种过滤技术,当 mat 中的值最初高于或低于阈值时,它会将这些值重置为默认值。
呃,你说什么?
为了理解这是如何工作的,让我们回到一个像素级的小垫子,一个简单的 3×3 垫子。
(u/matrix-to-mat [[0 50 100] [100 150 200] [200 210 250]]) ; [0, 50, 100 ; 100, 150, 200 ; 200, 210, 250] We can apply a threshold that sets the value of a pixel to
-
0,如果原始像素低于 150
-
250 否则
这是如何工作的。
(-> (u/matrix-to-mat [[0 50 100] [100 150 200] [200 210 250]]) (threshold! 150 250 THRESH_BINARY) (.dump))
得到的矩阵是
[0, 0, 0 0, 0, 250 250, 250, 250]
如您所见,只有值大于 150 的像素被保留为非零值。
您可以使用 THRESH_BINARY_INV 创建互补矩阵,如下所示。
(-> (u/matrix-to-mat [[0 50 100] [100 150 200] [200 210 250]]) (threshold! 150 250 THRESH_BINARY_INV) (.dump)) ; [250, 250, 250 250, 250, 0 0, 0, 0]
现在,将这种技术应用到一张图片上,只留下垫子内容的有趣形状,使事情变得非常有趣。
(-> "resources/emilie4.jpg" (imread) (cvt-color! COLOR_BGR2GRAY) (threshold! 150 250 THRESH_BINARY_INV) (u/mat-view)) Figure 2-67 shows the resulting mat after applying the threshold to my sister’s white cat. Figure 2-67
Figure 2-67
阈值猫
作为参考,也是为了下一章的冒险,还有另一个名为 adaptive-threshold 的方法,它根据周围像素的值来计算目标值。
(-> "resources/emilie4.jpg" (imread) (u/resize-by 0.07) (cvt-color! COLOR_BGR2GRAY) (adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY 9 20) (u/mat-view))
-
如果验证了阈值,则结果值为 255。
-
你刚刚看到了 THRESH_BINARY 或 THRESH_BINARY_INV
-
9 是要考虑的邻近区域的大小
-
20 是从总和中减去的值
Figure 2-68 shows the result of the adaptive threshold. Figure 2-68
Figure 2-68
适应性猫
自适应阈值通常在配方 2-8 中与模糊技术一起使用,我们将很快研究它。
2.7 应用简单的掩蔽技术
问题
遮罩可以用在各种情况下,在这些情况下,您只想将遮罩功能应用到遮罩的某个部分。
你想知道如何创造面具,如何将它们付诸行动。
解决办法
我们将再次回顾使用范围内的来创建基于颜色的蒙版。
然后,我们将使用 copy-to 和 bitwise- 在主贴图上应用函数,但只在蒙版选择的像素上。
它是如何工作的
让我们从从花园里采摘一朵浪漫的玫瑰并装载 imread 开始。
(def rose (-> "resources/red_rose.jpg" (imread IMREAD_REDUCED_COLOR_2))) (u/mat-view rose) Figure 2-69 shows the flower that will be the source of this exercise. Figure 2-69
Figure 2-69
玫瑰
为了搜索颜色,正如我们已经看到的,让我们首先将玫瑰转换到一个不同的颜色空间。
你现在知道如何实现这一点了。因为我们要寻找的颜色是红色,所以让我们从 RGB 转换到 HSV。
(def hsv (-> rose clone (cvt-color! COLOR_RGB2HSV))) (u/mat-view hsv)  Figure 2-70
Figure 2-70
HSV 色彩空间中的玫瑰
然后让我们过滤红色,因为玫瑰也有点暗,让我们在下限红色上设置低的饱和度和亮度值。
(def lower-red (new-scalar 120 30 15)) (def upper-red (new-scalar 130 255 255)) (def mask (new-mat)) (in-range hsv lower-red upper-red mask) (u/mat-view mask)
我们在配方 2-4 中使用了这种方法,但是我们忘记看一下创建的蒙版。基本上,遮罩是一个与范围内输入大小相同的 mat,当源像素不在范围内时,像素设置为 0,当源像素在范围内时,像素设置为 1。事实上,在这里,范围内的工作有点像一个阈值。
The resulting mask is shown in Figure 2-71. Figure 2-71
Figure 2-71
红玫瑰的面具
掩码现在可以和一起使用了!原始源上升,因此我们只复制蒙版 mat 值不等于 0 的像素。
(def res (new-mat)) (bitwise-and! rose res mask) (u/mat-view res) And now you have a resulting mat (Figure 2-72) of only the red part of the picture. Figure 2-72
Figure 2-72
只有玫瑰
作为一个小练习,我们将使用 convert-to 来更改 mat 的亮度,并对每个像素应用以下公式:
原始*alpha+ beta
因此,下面的代码片段只是通过调用 convert-to 来实现这一点。
(def res2 (new-mat)) (convert-to res res2 -1 1 100) (u/mat-view res2) The resulting masked rose is a slightly brighter version of the original rose (Figure 2-73). Figure 2-73
Figure 2-73
明亮的玫瑰
让我们把产生的亮玫瑰复制回原图,或者是它的复制品(图 2-74 )。
(def cl (clone rose)) (copy-to res2 cl mask) (u/mat-view cl)  Figure 2-74
Figure 2-74
走到一起
这些概念很好地融合在一起。
最后,让我们尝试一些不同的东西,例如,复制一个完全不同的垫代替玫瑰,再次使用面具。
我们可以重用在前面创建的遮罩,并以类似的方式使用 copy-to 来仅复制某个贴图的特定点。
为了执行复制,我们需要 copy-to 中的源和目标具有完全相同的大小,以及掩码。如果不是这样的话,你会得到一个非常糟糕的错误。
第一步是调整垫子的大小。
(def cl2 (imread "resources/emilie1.jpg")) (resize! cl2 (new-size (cols mask) (rows mask)))
然后,在原始 rose 图片的克隆上,我们可以执行复制,将 mask 指定为 copy-to 的最后一个参数。
(def cl3 (clone rose)) (copy-to cl2 cl3 mask) (u/mat-view cl3) The cat mat is thus copied onto the rose, but only where the mask allows the copy to happen (Figure 2-75). Figure 2-75
Figure 2-75
猫和玫瑰
2.8 模糊图像
我屈服于自己想要模糊和融合艺术与生活之间界限的倾向[…]
利亚冰
问题
正如所承诺的,这是一个审查模糊技术的食谱。模糊化是一种简单而常用的技巧,可用于各种场合。
你想看看不同种类的模糊可用,以及如何使用 Origami。
解决办法
OpenCV 中的模糊主要有四种方法: 模糊 、 高斯模糊 、 中值模糊 、 双边过滤 。
让我们逐一回顾一下。
它是如何工作的
像往常一样,让我们加载一个基本的猫图片,以便在整个练习中使用。
(def neko (-> "resources/emilie5.jpg" (imread) (u/resize-by 0.07))) (u/mat-view neko) Figure 2-76 shows another picture of my sister’s cat. Figure 2-76
Figure 2-76
猫在床上
简单模糊和中间模糊
应用简单的模糊的流程相对简单。像许多其他图像处理技术一样,我们使用内核,一个主像素位于中心的正方形矩阵,比如 3×3 或 5×5。核是矩阵,其中每个像素被赋予一个系数。
在其最简单的形式中,我们只需要给它一个区域的内核大小来考虑模糊:内核区域越大,得到的图片就越模糊。
基本上,输出的每个像素是其核邻居的平均值。
(-> neko (clone) (blur! (new-size 3 3)) (u/mat-view)) The result can be seen in Figure 2-77. Figure 2-77
Figure 2-77
床上的模糊猫
而且内核越大,画面会越模糊。
图 2-78 显示了使用模糊功能的不同内核大小的结果。
(->> (range 3 10 2) (map #(-> neko clone (u/resize-by 0.5) (blur! (new-size % %)))) (hconcat!) (u/mat-view))  Figure 2-78
Figure 2-78
更大的内核
高斯模糊
这种类型的模糊赋予内核中心更多的权重。我们将在下一章看到这一点,但这种类型的模糊实际上很好地消除了图片中的额外噪声。
(-> neko clone (gaussian-blur! (new-size 5 5) 17) (u/mat-view)) The result of the gaussian blur is shown in Figure 2-79. Figure 2-79
Figure 2-79
高斯模糊猫
双边过滤器
当您想要平滑图片,但同时又想保留边缘时,可以使用这些滤镜。
什么是边缘?边缘是定义图片中可用形状的轮廓。
第一个例子展示了双边过滤器的简单用法。
(-> neko clone (bilateral-filter! 9 9 7) (u/mat-view))  Figure 2-80
Figure 2-80
高斯模糊
第二个例子展示了一个我们想要保留边缘的例子。使用著名的 opencv 函数 canny 可以很容易地找到边缘。我们将在下一章花更多的时间和 canny 在一起。
现在,让我们关注图 2-81 的输出和线条。
(-> neko clone (cvt-color! COLOR_BGR2GRAY) (bilateral-filter! 9 9 7) (canny! 50.0 250.0 3 true) (bitwise-not!) (u/mat-view))  Figure 2-81
Figure 2-81
高斯模糊和精明
第三个例子快速展示了为什么你想使用双边过滤器,而不是简单的模糊。我们保持同样的小处理流水线,但这次使用简单的模糊,而不是双边过滤器。
(-> neko clone (cvt-color! COLOR_BGR2GRAY) (blur! (new-size 3 3)) (canny! 50.0 250.0 3 true) (bitwise-not!) (u/mat-view)) The output clearly highlights the problem: defining lines have disappeared, and Figure 2-82 shows a disappearing cat … Figure 2-82
Figure 2-82
台词和猫都消失了!
中值模糊
中间模糊是简单模糊的朋友。
(-> neko clone (median-blur! 27) (u/mat-view))
值得注意的是,在内核长度较高的情况下,或者内核长度大于 21 的情况下,我们得到的东西更有艺术性。
It is less useful for shape detection, as seen in Figures 2-83 and 2-84, but still combines with other mats for creative impact, as we will see in chapter 3. Figure 2-83
Figure 2-83
艺术猫(内核长度 31)
 Figure 2-84
Figure 2-84
使用内核 7 的中值模糊使线条消失
瞧啊。第二章介绍了 Origami 及其易用性:设置、简洁性、处理流水线和各种转换。
This is only the beginning. Chapter 3 will be taking this setup to the next level by combining principles and functions of OpenCV to find shapes, count things, and move specific parts of mats to other locations.
未来属于今天为它做准备的人。
马尔科姆·Ⅹ
三、成像技术
最完美的技巧是根本不会被注意到的。
帕布罗·卡萨尔斯
前一章介绍了 Origami 以及如何在简单的垫子和图像上进行单步处理操作。
虽然这已经很好地展示了该库的易用性,但第三章希望通过将简单的处理步骤结合起来,向更大的目标迈进一步。从执行内容分析、轮廓检测、形状发现和形状移动,一直到基于计算机的素描和景观艺术,只要你能想到的,这里都有许多冒险等待着你。
我们将从熟悉的地方开始,通过在字节级操作 OpenCV mats,更详细地掌握图像操作的细节。
学习将分为两大部分。首先将是一个稍微侧重于艺术的部分,在这里我们用线条、渐变和 OpenCV 函数从现有的图像中创建新的图像。你将会使用已知的 origami/opencv 函数,但是一些其他的函数也将会根据需要引入到创作流程中。
这是 Origami 术最初的计划之一,用来创作图画。碰巧的是,为了理解简单的概念是如何组合在一起的,我不得不玩图像合成和线框,它们实际上比我想象的要好。更重要的是,添加你自己的风格并在以后重复使用这些作品是很容易的。所以第一部分是为了分享这个经验。
然后,在第二部分,我们将转移到更侧重于图像处理的技术。在回顾了来自艺术部门的即时反馈后,处理步骤在那个阶段将更容易掌握。
OpenCV 中的处理步骤大部分时间都很简单,但是 C++中的原始样本使得阅读指针行变得相当困难。我个人发现,即使包括 Clojure 学习曲线,Origami 也是一种更容易开始使用 OpenCV 的方法:您可以专注于代码行的直接影响,并尝试以不同的方式编写每一步,而不必每次都通过获得即时反馈来重新开始,直到它最终很好地到位。希望这一章的第二部分会让你足够舒服,你会想去挑战这些例子。
请注意,线性阅读本章可能是一个好主意,这样您就不会错过新功能或新技巧。然而,当然,没有什么能阻止你跳进你喜欢的地方。它毕竟是一本食谱!
3.1 玩颜色
问题
在前一章中,你已经看到了改变垫子颜色的各种技术。
你想要控制如何指定和影响颜色,例如,通过在垫子上应用特定的因素或功能来增加或减少它们的强度。
解决办法
在这里,您将了解以下内容:如何组合操作,如使用已知的 cvt-color 转换图像颜色通道;如何使用其他 OpenCV 函数像 threshold 来限制通道值;如何创建遮罩并使用功能设置为;以及如何使用函数来组合不同版本的 mat。
您还将更详细地回顾如何使用变换!创建基本艺术效果的功能。
它是如何工作的
为了玩垫子,我们将使用另一套猫和花,但是你当然可以随时尝试在你自己的照片上应用这些功能。
本章的名称空间头,以及所有的名称空间依赖项,将使用上一章中所需的相同名称空间,即 opencv3.core 和 opencv3.utils 以及来自 origami 的 opencv3 原始名称空间的 opencv3.colors.rgb。
所需的部分类似于下面的代码片段。
(ns opencv3.chapter03 (:require [opencv3.core :refer :all] [opencv3.colors.rgb :as rgb] [opencv3.utils :as u]))
通常为每个实验创建一个新的笔记本,并分别保存它们是一个好主意。
在彩色垫上应用阈值
回到基础。您还记得如何在 mat 上设置阈值,并且只保留矩阵中大于 150 的值吗?
是的,你是正确的:使用阈值函数。
(-> (u/matrix-to-mat [[100 255 200] [100 255 200] [100 255 200]]) (threshold! 150 255 THRESH_BINARY) (dump))
输入矩阵包含各种值,有些低于阈值 150,有些高于阈值 150。应用阈值时,下面的值设置为 0,上面的值设置为阈值的第二个参数值 255。
这导致了以下矩阵(图 3-1 ):
[0 255 255] [0 255 255] [0 255 255]
这是一个单通道的垫子,但如果我们在三通道垫子上做同样的事情会怎么样呢?
(-> (u/matrix-to-mat [[0 0 170] [0 0 170] [100 100 0]]) (cvt-color! COLOR_GRAY2BGR) (threshold! 150 255 THRESH_BINARY) (dump))
将颜色转换为 BGR 会将单通道贴图的每个值复制为同一像素上的相同三个值。
之后立即应用 OpenCV 阈值函数,将阈值应用于每个通道上的所有值。因此得到的 mat 丢失了原始 mat 的 100 个值,只保留了 255 个值。
[0 0 0 0 0 0 255 255 255] [0 0 0 0 0 0 255 255 255] [0 0 0 0 0 0 0 0 0]
一个 3×3 的矩阵太小了,不能在屏幕上显示,所以让我们先在输入矩阵上使用 resize。
(-> (u/matrix-to-mat [[0 0 170] [0 0 170] [100 100 0]]) (cvt-color! COLOR_GRAY2BGR) (resize! (new-size 50 50) 1 1 INTER_AREA) (u/mat-view))  Figure 3-1
Figure 3-1
黑白垫子
对前面的遮罩应用类似的阈值会保持浅灰色,浅灰色的值高于阈值,但会通过将深灰色变为黑色来移除深灰色。
(-> (u/matrix-to-mat [[0 0 170] [0 0 170] [100 100 0]]) (cvt-color! COLOR_GRAY2BGR) (threshold! 150 255 THRESH_BINARY) (resize! (new-size 50 50) 0 0 INTER_AREA) (u/mat-view)) This gives us Figure 3-2. Figure 3-2
Figure 3-2
阈值!
请注意,resize、 INTER_AREA、使用了一个特定的插值参数,它很好地清晰地切割了形状,而不是插值和强制模糊。
Just for some extra info, the default resize method gives something like Figure 3-3, which can be used in other circumstances , but this is not what we want here. Figure 3-3
Figure 3-3
使用默认插值调整大小
无论如何,回到这个练习,你可能已经做到了:应用一个标准的阈值来推动鲜艳的颜色。
让我们看看它是如何在一个从图像加载的垫子上工作的,让我们加载该章节的第一个图像(图 3-4 )。
(def rose (imread "resources/chapter03/rose.jpg" IMREAD_REDUCED_COLOR_4))  Figure 3-4
Figure 3-4
有人说爱是一条河
我们首先应用从矩阵加载的 mat 上应用的相同阈值,但这次是在 rose 图像上。
(-> original (clone) (threshold! 100 255 THRESH_BINARY) (u/mat-view)) You get a striking result! (Figure 3-5) Figure 3-5
Figure 3-5
鲜艳的颜色
在一张拍得很好的照片中,这实际上给了你一种艺术感,你可以在此基础上制作卡片和圣诞礼物!
现在让我们在一个完全不同的图像上应用类似的技术。我们先把图片转成黑白,看看效果如何。
这次的图片是贪玩的小猫,如图 3-6 所示。
(-> "resources/chapter03/ai6.jpg" (imread IMREAD_REDUCED_COLOR_2) (u/mat-view))  Figure 3-6
Figure 3-6
顽皮的猫
如果你应用一个相似的阈值,但是在灰度版本上,会发生一些有趣的事情。
(-> "resources/chapter03/ai6.jpg" (imread IMREAD_REDUCED_GRAYSCALE_2) (threshold! 100 255 THRESH_BINARY) (u/mat-view)) The two cats are actually standing out and being highlighted (Figure 3-7). Figure 3-7
Figure 3-7
顽皮、突出的猫
爽;这意味着我们想要突出的形状已经被突出显示。
类似这样的东西可以用来找出形状和移动的物体;更多信息请见配方 3-6 和 3-7。
现在,为了保持事物的艺术性,让我们开发一个小函数,将低于给定阈值的所有颜色转换为一种颜色,将高于阈值的所有值转换为另一种颜色。
We can achieve this by
-
首先,转向不同的颜色空间,即 HSV
-
从应用了 THRESH_BINARY 设置的阈值创建遮罩
-
从应用了 THRESH_BINARY_INV 设置的阈值创建第二个掩码,从而创建与第一个掩码具有相反值的掩码
-
将两个遮罩转换为灰色,因此它们仅由一个通道组成
-
使用 set-to 设置工作垫的颜色,遵循第一个遮罩
-
再次使用设置来设置工作垫的颜色,但是遵循第二个遮罩
-
就是这样!
在编码快乐时,我们将创建一个低-高!执行上述算法的函数。
低-高!功能由 cvt-color 组成!、threshold 和 set-to,所有的函数你都已经见过了。
(defn low-high! ([image t1 color1 color2 ] (let [_copy (-> image clone (cvt-color! COLOR_BGR2HSV)) _work (clone image) _thresh-1 (new-mat) _thresh-2 (new-mat)] (threshold _copy _thresh-1 t1 255 THRESH_BINARY) (cvt-color! _thresh-1 COLOR_BGR2GRAY) (set-to _work color1 _thresh-1) (threshold _copy _thresh-2 t1 255 THRESH_BINARY_INV) (cvt-color! _thresh-2 COLOR_BGR2GRAY) (set-to _work color2 _thresh-2) _work)))
我们将在玫瑰图上调用它,阈值为 150,白烟到浅蓝色分裂。
(-> (imread "resources/chapter02/rose.jpg" IMREAD_REDUCED_COLOR_4) (low-high! 150 rgb/white-smoke- rgb/lightblue-1) (u/mat-view)) Executing the preceding snippet gives us Figure 3-8. Figure 3-8
Figure 3-8
浅蓝色玫瑰上的白色
太好了。但是,你会问,我们真的需要为此创建两个遮罩吗?事实上,你不知道。你可以在第一个遮罩上完美地进行位元运算。为此,只需注释掉第二个遮罩创建并使用位非!第二次调用 set-to 之前。
;(threshold _copy _thresh-2 t1 255 THRESH_BINARY_INV) ;(cvt-color! _thresh-2 COLOR_BGR2GRAY) (set-to _work color2 (bitwise-not! _thresh-1))
在此基础上,您还可以对不同的颜色映射应用阈值,或者创建用作阈值的范围。
很明显,这里的另一个想法是对任何图片进行热空间皇后化。
如果你想知道,下面的代码片段可以帮你做到。
(def freddie-red (new-scalar 26 48 231)) (def freddie-blue (new-scalar 132 46 71)) (def bryan-yellow (new-scalar 56 235 255)) (def bryan-grey (new-scalar 186 185 181)) (def john-blue (new-scalar 235 169 0)) (def john-red (new-scalar 32 87 233)) (def roger-green (new-scalar 72 157 53)) (def roger-pink (new-scalar 151 95 226)) (defn queen-ize [mat thresh] (vconcat! [ (hconcat! [(-> mat clone (low-high! thresh freddie-red freddie-blue)) (-> mat clone (low-high! thresh john-blue john-red))]) (hconcat! [(-> mat clone (low-high! thresh roger-pink roger-green )) (-> mat clone (low-high! thresh bryan-yellow bryan-grey))] )]))
这真的是叫低-高!四次,每次都是 1982 年皇后乐队专辑 Hot Space 中的颜色。
And the old-fashioned result is shown in Figure 3-9. Figure 3-9
Figure 3-9
猫和皇后
你真会设置 的情绪
你真的进入了最佳状态
时尚弄潮儿
女王——“时尚弄潮儿”
手动通道
每当你要处理一个垫子的通道时,记住 opencv split 函数。该功能将通道分隔在一系列独立的垫子中,因此您可以完全只关注其中一个。
然后,您可以将变换应用到该特定的 mat,而不触及其他 mat,完成后,您可以使用 merge 函数返回到多通道 mat,该函数执行相反的操作,获取一个 mat 列表,每个通道一个,并创建一个目标 mat,将所有通道合并到一个 mat 中。
为了看到这一点,假设你有一个简单的橙色垫子(图 3-10 )。
(def orange-mat (new-mat 3 3 CV_8UC3 rgb/orange-2))  Figure 3-10
Figure 3-10
橙色 mat
如果你想把橙色的垫子变成红色的,你只需要把绿色通道的所有值都设置为 0。
所以,你从把 RGB 通道分成三个垫子开始;然后,将第二个 mat 的所有值设置为 0,并将所有三个 mat 合并为一个。
首先,让我们把垫子分成几个通道,看看每个通道的内容。
在快乐编码中,这给出了
(def channels (new-arraylist)) (split orange-mat channels)
这三个频道现在被分成列表中的三个元素。只需使用 dump 就可以查看每个频道的内容。
例如,转储蓝色通道:
(dump (nth channels 0)) ; no blue ;[0 0 0] ;[0 0 0] ;[0 0 0]
或者转储绿色通道:
(dump (nth channels 1)) ; quite a bit of green ;[154 154 154] ;[154 154 154] ;[154 154 154]
最后,转储红色通道:
(dump (nth channels 2)) ; almost max of red ;[238 238 238] ;[238 238 238] ;[238 238 238]
接下来,让我们将绿色通道中的所有 154 个值都变为 0。
(set-to (nth channels 1) (new-scalar 0.0))
然后,让我们将所有不同的垫子合并成一个垫子,得到图 3-11 。
(merge channels red-mat)  Figure 3-11
Figure 3-11
红马特
mat 中所有像素上的绿色强度都统一设置为 0,因此所有蓝色通道值都已设置为 0,结果 mat 是一个完全红色的 mat。
我们可以将这个小练习的所有不同步骤结合起来,创建函数 update-channel!,它接受一个 mat、一个函数和应用该函数的通道,然后返回结果 mat。
让我们尝试使用 u/mat-to-bytes 和 u/bytes-to-mat 的第一个版本!在 mat 和 byte 数组之间来回转换。
这变得很复杂,但实际上是我能想到的解释转换流程的最简单的版本。
The code flow will be as follows:
-
将频道分成一个列表
-
检索目标通道的 mat
-
将 mat 转换为字节
-
将该函数应用于通道模板的每个字节
-
将字节数组转换回 mat
-
将 mat 设置到列表中相应频道
-
将通道合并到生成的垫子中
现在,至少应该按如下顺序阅读:
(defn update-channel! [mat fnc chan] (let [ channels (new-arraylist)] (split mat channels) (let [ old-ch (nth channels chan) new-ch (u/bytes-to-mat! (new-mat (.height mat) (.width mat) (.type old-ch) ) (byte-array (map fnc (u/mat-to-bytes old-ch) )))] (.set channels chan new-ch) (merge channels mat) mat)))
现在让我们回到我姐姐的猫,它已经在沙发上睡了一段时间了。是时候逗逗他,叫醒他了。
(def my-sister-cat (-> "resources/chapter03/emilie1.jpg" (imread IMREAD_REDUCED_COLOR_8)))
在更新频道的帮助下!函数,让我们将所有的蓝色和绿色通道值转换为它们的最大可能值 255。我们本来可以编写一个同时应用多个函数的函数,但是现在让我们一个接一个地调用同一个函数。
(-> my-sister-cat clone (update-channel! (fn [x] 255) 1) (update-channel! (fn [x] 255) 0) u/mat-view) This is not very useful as far as imaging goes, nor very useful for my sister’s cat either, but by maxing out all the values of the blue and green channels, we get a picture that is all cyan (Figure 3-12). Figure 3-12
Figure 3-12
青色 cat
这个新创建的函数也可以与转换色彩空间结合使用。
因此,在调用 update-channel 之前切换到 HSV 色彩空间!让您完全控制垫子的颜色。
(-> my-sister-cat clone (cvt-color! COLOR_RGB2HSV) (update-channel! (fn [x] 10) 0) ; blue filter (cvt-color! COLOR_HSV2RGB) (u/mat-view))
前面的代码应用蓝色滤镜,保持饱和度和亮度不变,从而仍然保持图像的动态。
当然,您可以尝试使用粉红色滤镜,将滤镜的值设置为 150,或者红色滤镜,将滤镜的值设置为 120 或任何其他可能的值。试试吧!
For now, enjoy the blue variation in Figure 3-13. Figure 3-13
Figure 3-13
蓝滤猫
就个人而言,我也喜欢 YUV 开关与最大化所有亮度值(Y)相结合。
(-> my-sister-cat clone (cvt-color! COLOR_BGR2YUV) (update-channel! (fn [x] 255) 0) (cvt-color! COLOR_YUV2BGR) (u/mat-view)) This gives a kind of watercolor feel to the image (Figure 3-14). Figure 3-14
Figure 3-14
巧妙的猫
改变
如果您还记得 transform,您还可以使用 opencv transform 函数应用不同种类的转换。
为了稍微了解一下 transform 的背景,让我们再一次回到通常的逐字节矩阵操作,首先是单通道 3×3 矩阵,我们想让它稍微暗一点。
(def s-mat (new-mat 3 3 CV_8UC1)) (.put s-mat 0 0 (byte-array [100 255 200 100 255 200 100 255 200]))
这可以通过以下代码查看(图 3-15 )。
(u/mat-view (-> s-mat clone (resize! (new-size 30 30) 1 1 INTER_AREA)))  Figure 3-15
Figure 3-15
黑白旗帜
然后我们定义一个 1×1 的变换矩阵,一个值为 0.7。
(def t-mat (new-mat 1 1 CV_32F (new-scalar 0.7))
接下来,我们就地应用转换,并转储结果以查看转换的结果。
(-> s-mat (transform! t-mat) (dump))
调用 transform 函数的效果是将输入矩阵的所有值转换为其原始值乘以 0.7。
结果如下表所示:
[70 178 140] [70 178 140] [70 178 140]
这也意味着垫子的视觉效果变暗了(图 3-16 ):
(u/mat-view (-> s-mat (resize! (new-size 30 30) 1 1 INTER_AREA)))  Figure 3-16
Figure 3-16
深色旗帜
This is a simple matrix computation, but it already shows two things:
-
源 mat 的字节都乘以 1×1 mat 中的值;
-
应用自定义转换实际上很容易。
对于具有多个通道的垫子,这些变换的工作方式大致相同。因此,让我们抓住一个例子,并使用 cvt-color 移动到一个彩色的颜色空间(是的,我知道)!
(def s-mat (new-mat 3 3 CV_8UC1)) (.put s-mat 0 0 (byte-array [100 255 200 100 255 200 100 255 200])) (cvt-color! s-mat COLOR_GRAY2BGR)
因为 mat 现在由三个通道组成,所以我们现在需要一个 3×3 的变换矩阵。
下面的变形垫子会给蓝色通道更多的力量。
[ 2 0 0 ; B -> B G R 0 1 0 ; G -> B G R 0 0 1] ; R -> B G R The transformation matrix is made of lines constructed as input-channel -> output channel, so three values per row, one for each output value of each channel, and three rows , one for each input.
-
[2 0 0]将蓝色通道的值提高 2 倍,不影响绿色或红色输出值
-
[0 1 0]保持绿色通道不变,不会影响输出中的其他通道
-
[0 0 1]保持红色通道不变,同样不会影响输出中的其他通道
(def t-mat (new-mat 3 3 CV_32F)) (.put t-mat 0 0 (float-array [2 0 0 0 1 0 0 0 1])) Applying the transformation to the newly colored mat gives you Figure 3-17, where blue is prominently standing out. Figure 3-17
Figure 3-17
蓝色标志
既然我们肯定没有办法让我姐姐的猫安静下来,那就让我们对它应用一个类似的变换。
该代码与前面的小 mat 示例完全相同,但是应用于一个图像。
(-> my-sister-cat clone (transform! (u/matrix-to-mat [ [2 0 0] [0 1 0] [0 0 1]]))) And Figure 3-18 shows a blue version of a usually white cat. Figure 3-18
Figure 3-18
蓝米乌夫
如果您想让输入中的蓝色也影响输出中的红色,您可以使用与下图稍微类似的矩阵:
[2 0 1.1 0 1 0 0 0 1 ]
你现在应该明白为什么了吧?[2 0 1.1]表示输入中的蓝色强度增加,但它也会增加输出中红色的强度。
您可能应该自己尝试几个转换矩阵来感受一下。
那么,现在,你如何使用类似的技术来增加垫子的亮度呢?
是的,没错:首先将矩阵转换到 HSV 色彩空间,然后乘以第三个通道,并保持其他通道不变。
下面的示例以同样的方式将亮度增加 1.5。
(-> my-sister-cat clone (cvt-color! COLOR_BGR2HSV) (transform! (u/matrix-to-mat [ [1 0 0] [0 1 0] [0 0 1.5]])) (cvt-color! COLOR_HSV2BGR) u/mat-view) Figure 3-19 shows the image output of the preceding snippet. Figure 3-19
Figure 3-19
夜光猫
巧妙的转变
总结这个食谱,让我们玩一点亮度和轮廓来创造一点艺术。
我们希望通过最大化亮度来创建输入图片的水彩版本。我们还想创建一个“轮廓”版本的图像,通过使用 opencv 的轮廓检测的精明的快速功能。最后,我们将结合这两个垫的铅笔水彩效果。
首先,让我们在背景上工作。背景是通过连续执行两个变换来创建的:一个是最大化 YUV 颜色空间中的亮度,另一个是通过增加蓝色和红色来使其更加生动。
(def usui-cat (-> my-sister-cat clone (cvt-color! COLOR_BGR2YUV) (transform! (u/matrix-to-mat [ [20 0 0] [0 1 0] [0 0 1]])) (cvt-color! COLOR_YUV2BGR) (transform! (u/matrix-to-mat [[3 0 0] [0 1 0] [0 0 2]]))))
如果你得到一个太透明的结果,你也可以在流水线的末端添加另一个变换来增加对比度;这在另一个色彩空间 HSV 中很容易做到。
(cvt-color! COLOR_BGR2HSV) (transform! (u/matrix-to-mat [[1 0 0] [0 3 0] [0 0 1]])) (cvt-color! COLOR_HSV2BGR) This gives us a nice pink-y background (Figure 3-20). Figure 3-20
Figure 3-20
背景是粉红色的猫
接下来是前景。前面的猫是通过调用 opencv 的 canny 函数创建的。这一次,这是在单通道灰色空间中完成的。
(def line-cat (-> my-sister-cat clone (cvt-color! COLOR_BGR2GRAY) (canny! 100.0 150.0 3 true) (cvt-color! COLOR_GRAY2BGR) (bitwise-not!))) The canny version of my sister’s cat gives the following (Figure 3-21): Figure 3-21
Figure 3-21
卡通猫
然后,使用对函数按位 and 的简单调用将两个 mat 组合在一起,该函数通过简单的“and”位操作将两个 mat 合并在一起。
(def target (new-mat)) (bitwise-and usui-cat line-cat target) This gives the nice artful cat in Figure 3-22. Figure 3-22
Figure 3-22
粉色、艺术和猫
虽然粉红色可能不是你最喜欢的颜色,但你现在有了所有的工具来根据你的喜好修改这个食谱中的流程,以创建许多不同的巧妙的猫,有不同的背景颜色,也有不同的前景。
但是拜托了。没有狗。
3.2 创作漫画
做你自己。没人能说你做错了。
查尔斯·米·舒尔茨
问题
你已经看到了使用 canny 制作卡通艺术作品的非常简单的方法,但是你想掌握更多制作卡通艺术作品的变化。
解决办法
大多数卡通外观的转换可以使用灰度、模糊、canny 和通道滤镜功能的变化来创建,这些功能在前面的配方中已经介绍过。
它是如何工作的
您已经看到了 canny 函数,它以在图片中轻松突出显示形状而闻名。它实际上也可以用来画一点漫画。让我们看看我的朋友约翰。
Johan is a sharp Belgian guy who sometimes gets tricked into having a glass of good Pinot Noir (Figure 3-23). Figure 3-23
Figure 3-23
乔安
在这个菜谱中,Johan 加载了以下代码片段:
(def source (-> "resources/chapter03/johan.jpg" (imread IMREAD_REDUCED_GRAYSCALE_8)))
一个天真的 canny 调用应该是这样的,其中 10.0 和 90.0 是 canny 函数的底部和顶部阈值,3 是光圈,true/false 表示基本上是超高亮度模式或标准(false)。
(-> source clone (canny! 10.0 90.0 3 false)) Johan has now been turned into a canny version of himself (Figure 3-24). Figure 3-24
Figure 3-24
天真的 canny 用法
你已经知道我们可以使用 canny 函数的结果作为蒙版,例如在白色上复制蓝色(图 3-25 )。
(def colored (u/mat-from source)) (set-to colored rgb/blue-2) (def target (u/mat-from source)) (set-to target rgb/white) (copy-to colored target c)  Figure 3-25
Figure 3-25
将蓝色复印在白色上
图中显示了相当多的线条。通过减小两个阈值之间的范围,我们可以使图片明显更清晰,看起来不那么杂乱。
(canny! 70.0 90.0 3 false) This indeed makes Johan a bit clearer (Figure 3-26). Figure 3-26
Figure 3-26
更清晰的约翰
结果不错,但似乎还是多了不少不该画的线。
通常用来移除这些多余线条的技术是在调用 canny 函数之前应用一个中值模糊或者一个高斯模糊。
高斯模糊通常更有效;毫不犹豫地放大,将模糊的大小增加到至少 13×13,甚至 21×21,如下所示:
(-> source clone (cvt-color! COLOR_BGR2GRAY) (gaussian-blur! (new-size 13 13) 1 1) (canny! 70.0 90.0 3 false)) That code snippet gives a neatly clearer picture (Figure 3-27). Figure 3-27
Figure 3-27
更好的约翰
你还记得双边过滤功能吗?如果你在调用 canny 函数后使用它,它也会给出一些有趣的卡通形状,通过在 canny 效果中出现更多线条的地方进行强调。
(-> source clone (cvt-color! COLOR_BGR2GRAY) (canny! 70.0 90.0 3 false) (bilateral-filter! 10 80 30))) Figure 3-28 shows the bilateral-filter! applied through a similar processing pipeline. Figure 3-28
Figure 3-28
应用双边过滤器
你应该记得双边过滤器的重点是加强轮廓。事实上,这就是我们在这里取得的成就。
Note also that the bilateral filter parameters are very sensitive, increasing the second parameter to 120; this gives a Picasso-like rendering (Figure 3-29). Figure 3-29
Figure 3-29
约翰松
所以,试试参数,看看什么对你有用。无论如何,整个 Origami 设置都是为了提供即时反馈。
还有,canny 不是唯一的选择。再来看看其他实现动漫效果的技巧。
双边卡通
双边过滤器实际上做了大量的卡通工作,所以让我们看看我们是否可以跳过狡猾的处理,坚持只使用双边过滤器的步骤。
We will create a new function called cartoon-0. That new function will
-
将输入图像变成灰色
-
应用非常大的双边过滤器
-
应用连续平滑函数
-
然后转回到一个 RGB 垫
一种可能的实现如下所示:
(defn cartoon-0! [buffer] (-> buffer (cvt-color! COLOR_RGB2GRAY) (bilateral-filter! 10 250 30) (median-blur! 7) (adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY 9 3) (cvt-color! COLOR_GRAY2BGR)))
卡通的输出-0!应用于 Johan 使其达到图 3-30 。
(-> "resources/chapter03/johan.jpg" (imread IMREAD_REDUCED_COLOR_8) cartoon-0! u/mat-view)  Figure 3-30
Figure 3-30
没有精明的卡通
同样,双边滤波器的参数几乎可以完成所有工作。
改变(双边过滤!10 250 30) 到(双边-过滤!9 9 7) 给人完全不同的感觉。
(defn cartoon-1! [buffer] (-> buffer (cvt-color! COLOR_RGB2GRAY) (bilateral-filter! 9 9 7) (median-blur! 7) (adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY 9 3) (cvt-color! COLOR_GRAY2BGR))) And Johan now looks even more artistic and thoughtful (Figure 3-31). Figure 3-31
Figure 3-31
体贴的约翰
更新频道变灰
这个食谱的最后一个技巧将带我们回到使用更新频道!前一个配方中编写的功能。
This new method uses update-channel with a function that
-
如果原始值小于 70,则将灰色通道的值变为 0;
-
如果原始值大于 80 但小于 180,则将其转换为 100;和
-
否则就变成 255。
这给出了以下稍微长但简单的流水线:
(-> "resources/chapter03/johan.jpg" (imread IMREAD_REDUCED_COLOR_8) (median-blur! 1) (cvt-color! COLOR_BGR2GRAY) (update-channel! (fn[x] (cond (< x 70) 0 (< x 180) 100 :else 255)) 0) (bitwise-not!) (cvt-color! COLOR_GRAY2BGR) (u/mat-view)) This is nothing you would not understand by now, but the pipeline is quite a pleasure to write and its result even more so, because it gives more depth to the output than the other techniques used up to now (Figure 3-32). Figure 3-32
Figure 3-32
深度约翰
流水线的输出看起来很棒,但是像素经过了相当多的处理,所以很难判断在这个阶段每个像素内部有什么,之后的后处理需要一些小心。
比如你想增加前面输出的亮度或者改变颜色;通常,在对颜色进行任何更改之前,最好再次切换到 HSV 颜色空间并增加亮度,如下所示:
(-> "resources/chapter03/shinji.jpg" (imread IMREAD_REDUCED_COLOR_4) (cartoon! 70 180 false) (cvt-color! COLOR_BGR2HSV) (update-channel! (fn [x] 250) 1) (update-channel! (fn [x] 5) 0) (cvt-color! COLOR_HSV2BGR) (bitwise-not!) (flip! 1) (u/mat-view)) The final processing pipeline gives us a shining blue Johan (Figure 3-33). The overall color is blue due to channel 0’s value set to 5 in HSV range, and the luminosity set to 250, almost the maximum value. Figure 3-33
Figure 3-33
翻转和蓝色
作为奖励,我们也只是水平翻转图像,以前瞻性的图片结束这个食谱!
3.3 创建铅笔草图
问题
你已经看到了如何为肖像做一些漫画,但想通过结合正面素描和深背景色来赋予它更多的艺术感。
解决办法
为了创建有冲击力的背景,你将会看到如何使用 pyr-down 和 pyr-up 结合你已经看到的平滑方法。
为了合并结果,我们将再次使用位与。
它是如何工作的
My hometown is in the French Alps, near the Swiss border, and there is a very nice canal flowing between the houses right in the middle of the old town (Figure 3-34). Figure 3-34
Figure 3-34
夏天的法国安纳西
这里的目标是创建该图片的绘画版本。
The plan is to proceed in three phases.
没有计划的目标只是一个愿望。
安托万·德圣军
第一阶段:我们通过平滑边缘和循环降低图片的分辨率来完全去除图片的所有轮廓。这将是背景图片。
第二阶段:我们反其道而行之,也就是说我们把注意力放在轮廓上,运用和卡通食谱中相似的技术,把图片变成灰色,找到所有的边缘,并赋予它们尽可能多的深度。这将是前面的部分。
第三阶段:最后,我们结合第一阶段和第二阶段的结果,以获得我们正在寻找的绘画效果。
背景
pyr-down!对你来说可能是新的。这会降低图像的分辨率。让我们比较应用以下代码片段所做的分辨率更改前后的地垫。
(def factor 1) (def work (clone img)) (dotimes [_ factor] (pyr-down! work))
之前:
object[org.opencv.core.Mat 0x3f133cac "Mat [ 431431CV_8UC3...]"]
之后:
object[org.opencv.core.Mat 0x3f133cac "Mat [ 216216CV_8UC3...]"]
基本上,mat 的分辨率除以 2,四舍五入到像素。(是的,我以前听过 1/2 像素的故事,但是要注意……那些都不是真的!!)
Using a factor of 4, and thus applying the resolution downgrade four times, we get a mat that is now 27×27 and looks like the mat in Figure 3-35. Figure 3-35
Figure 3-35
更改分辨率
为了创建背景效果,我们实际上需要一个与原始大小相同的垫子,因此需要将输出的大小调整为原始大小。
第一个想法当然是简单地尝试通常的调整大小!功能:
(resize! work (.size img)) But that does result in something not very satisfying to the eyes. Figure 3-36 indeed shows some quite visible weird pixelization of the resized mat. Figure 3-36
Figure 3-36
嗯…调整大小
让我们试试别的东西。有一个 pyr-down 的反向函数,名为 pyr-up,可以将一个 mat 的分辨率提高一倍。为了有效地使用它,我们可以在一个循环中应用 pyr-up,并像使用 pyr-down 一样循环相同的次数。
(dotimes [_ factor] (pyr-up! work)) The resulting mat is similar to Figure 3-36, but is much smoother, as shown in Figure 3-37. Figure 3-37
Figure 3-37
平滑模糊
通过在 pyr-down 和 pyr-up 舞蹈之间的垫子中应用模糊来最终确定背景。
所以:
(dotimes [_ factor] (pyr-down! work)) (bilateral-filter! work 11 11 7) (dotimes [_ factor] (pyr-up! work))
输出留到以后,后台就这样了;让我们移动到前景的边缘发现部分。
前景和结果
前景将主要是前一个食谱的复制粘贴练习。你当然可以在这个阶段创造自己的变体;这里我们将使用一个由中值模糊和自适应阈值步骤组成的卡通化函数。
(def edge (-> img clone (resize! (new-size (.cols output) (.rows output))) (cvt-color! COLOR_RGB2GRAY) (median-blur! 7) (adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY 9 7) (cvt-color! COLOR_GRAY2RGB))) Using the old town image as input, this time you get a mat showing only the prominent edges, as shown in Figure 3-38. Figure 3-38
Figure 3-38
到处都是边缘
为了完成这个练习,我们现在使用按位 and 将两个垫子组合起来。基本上,由于边缘是黑色的,按位 and 运算使它们保持黑色,它们的值将被复制到输出 mat。
这将具有将未改变的边缘复制到目标结果上的结果,并且由于边缘垫的剩余部分是由白色构成的,按位与将是另一个垫的值,因此背景垫的颜色将优先。
(let [result (new-mat) ] (bitwise-and work edge result) (u/mat-view result)) This gives you the sketching effect of Figure 3-39. Figure 3-39
Figure 3-39
像专业人士一样素描
使用“自适应阈值”步骤,可以调整正面草图的外观。
(adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY edges-thickness edges-number)
在第一张草图中,我们用 9 作为边厚,7 作为边数;让我们看看如果我们把这两个参数设为 5 会发生什么。
This gives more space to the color of the background, by reducing the thickness of the edges (Figure 3-40). Figure 3-40
Figure 3-40
较薄的边缘
现在就看你的发挥了,从那里随机应变!
摘要
Finally, let’s get you equipped with a ready-to-use sketch! function. This is an exact copy of the code that has been used up to now, with places for the most important parameters for this sketching technique:
-
用于降低分辨率然后再次提高分辨率的因素,例如舞蹈中的循环次数
-
背景双边滤波器的参数
-
前景的自适应阈值的参数
素描!函数是由平滑构成的!还有棱角!。首先,让我们使用平滑!来创造背景。
(defn smoothing! [img factor filter-size filter-value] (let [ work (clone img) output (new-mat)] (dotimes [_ factor] (pyr-down! work)) (bilateral-filter work output filter-size filter-size filter-value) (dotimes [_ factor] (pyr-up! output)) (resize! output (new-size (.cols img) (.rows img)))))
然后边缘!来创造前景。
(defn edges! [img e1 e2 e3] (-> img clone (cvt-color! COLOR_RGB2GRAY) (median-blur! e1) (adaptive-threshold! 255 ADAPTIVE_THRESH_MEAN_C THRESH_BINARY e2 e3) (cvt-color! COLOR_GRAY2RGB)))
终于可以用素描了!,背景和前景的结合。
(defn sketch! [ img s1 s2 s3 e1 e2 e3] (let [ output (smoothing! img s1 s2 s3) edge (edges! img e1 e2 e3)] (bitwise-and output edge output) output))
召唤素描!是比较容易的。您可以尝试下面的代码片段:
(sketch! 6 9 7 7 9 11) And instantly turn the landscape picture of Figure 3-41 … Figure 3-41
Figure 3-41
树
into the sketched version of Figure 3-42. Figure 3-42
Figure 3-42
风景素描
其他几个已经放入了示例中,但是现在确实是时候拍摄您自己的照片并尝试这些功能和参数了。
3.4 创建画布效果
问题
创造景观艺术对你来说似乎没有更多的秘密,但你想在它上面浮雕一块画布,使它更像一幅画。
解决办法
这个简短的食谱将重复使用你已经看到的技术,以及两个新的 mat 函数:乘和除。
使用 divide,可以创建一个垫子的燃烧和躲闪效果,我们将使用它们来创建想要的效果。
有了乘,就有可能将垫子组合成一个漂亮的深度效果,因此通过使用一个看起来像纸一样的背景垫子,就有可能在画布上产生一个特殊的绘制输出。
它是如何工作的
我们将在法国阿尔卑斯山再拍一张照片——我是说为什么不呢!—因为我们想让它看起来有点复古,我们将使用一个古老城堡的图像。
(def img (-> "resources/chapter03/montrottier.jpg" (imread IMREAD_REDUCED_COLOR_4))) Figure 3-43 shows the castle of Montrottier, which you should probably visit when you have the time, or vacation (I do not even know what the second word means anymore). Figure 3-43
Figure 3-43
向星星许愿
我们首先从应用一个位非开始!,然后在源图片的灰色克隆上进行高斯模糊;用 Origami 流水线很容易做到这一点。
我们将需要一个灰色的版本,所以让我们保持两个垫子灰色和 gaussed 分开。
(def gray (-> img clone (cvt-color! COLOR_BGR2GRAY))) (def gaussed (-> gray clone bitwise-not! (gaussian-blur! (new-size 21 21) 0.0 0.0))) Figure 3-44 shows the gaussed mat, which looks like a spooky version of the input image. Figure 3-44
Figure 3-44
幽灵城堡
我们将使用这个 gaussed 垫作为一个面具。神奇的事情发生在函数道奇!,在原图上使用 opencv 函数 divide,以及 gaussed mat 的反转版本。
(defn dodge! [img_ mask] (let [ output (clone img_) ] (divide img_ (bitwise-not! (-> mask clone)) output 256.0) output))
嗯……好吧。除法是做什么的?我的意思是,你知道它划分事物,但是在字节水平上,真正发生的是什么?
我们举两个矩阵,a 和 b,对它们调用 divide 作为例子。
(def a (u/matrix-to-mat [[1 1 1]])) (def b (u/matrix-to-mat [[0 1 2]])) (def c (new-mat)) (divide a b c 10.0) (dump c)
divide 调用的输出是
[0 10 5]
哪个是
[ (a0 / b0) * 10.0, (a1 / b1) * 10.0, (a2 / b2) * 10.0]
这给了
[ 1 / 0 * 10.0, 1 / 1 * 10.0, 1 / 2 * 10.0]
那么,鉴于 OpenCV 认为除以 0 等于 0:
[0, 10, 5]
现在,让我们打电话给道奇!在灰色垫子和格纹垫子上:
(u/mat-view (dodge! gray gaussed)) And see the sharp result of Figure 3-45. Figure 3-45
Figure 3-45
锋利的铅笔
应用画布
现在,主画面已经变成了蜡笔风格的艺术形式,把它放在一个看起来像帆布的垫子上会很好。如前所述,这是使用 OpenCV 中的乘函数完成的。
We want the canvas to look like a very old parchment, and we will use the one from Figure 3-46. Figure 3-46
Figure 3-46
旧羊皮纸
现在我们将创建应用画布!函数,接受前端草图和画布,并在它们之间应用乘法函数。(/ 1 256.0)是用于相乘的值;因为这里是灰色字节,值越大越白,所以这里(/ 1 256.0)使得最终结果上的黑线非常明显。
(defn apply-canvas! [ sketch canvas] (let [ out (new-mat)] (resize! canvas (new-size (.cols sketch) (.rows sketch))) (multiply (-> sketch clone (cvt-color! COLOR_GRAY2RGB)) canvas out (/ 1 256.0)) out))
呜呼。差不多了;现在让我们调用这个新创建的函数
(u/mat-view (apply-canvas! sketch canvas)) And enjoy the drawing on the canvas (Figure 3-47). Figure 3-47
Figure 3-47
旧羊皮纸上的城堡
现在显然是你去寻找/扫描你自己的旧论文的时候了,用这种技术尝试一些事情;或者为什么不重用以前食谱中的卡通功能来覆盖不同的纸张呢?
3.5 突出显示线条和圆圈
问题
这个食谱是关于如何在一个加载的垫子中找到并高亮显示线条、圆圈和线段的。
解决办法
通常需要一点预处理来准备图像,以便用一些谨慎和平滑的操作进行分析。
一旦第一步准备工作完成,就可以用 opencv 函数 hough-circles 找到圆。
查找线条的版本称为 hough-lines,其兄弟 hough-lines-p 使用概率来查找更好的线条。
最后,我们将看到如何使用线段检测器来绘制找到的线段。
它是如何工作的
用霍夫线寻找网球场的线
本教程的第一部分展示了如何在图像中寻找线条。我们将以网球场为例。
(def tennis (-> "resources/chapter03/tennis_ground.jpg" imread )) You have probably seen a tennis court before, and this one is not so different from the others (Figure 3-48). If you have never seen a tennis court before, this is a great introduction all the same, but you should probably stop reading and go play a game already. Figure 3-48
Figure 3-48
网球场
为 hough-lines 函数准备目标是通过将原始网球场图片转换为灰色,然后应用简单的 canny 变换来完成的。
(def can (-> tennis clone (cvt-color! COLOR_BGR2GRAY) (canny! 50.0 180.0 3 false))) With the expected result of the lines standing out on a black background, as shown in Figure 3-49. Figure 3-49
Figure 3-49
漂亮的网球场
在 opencv 的底层 Java 版本中,行被收集在一个 mat 中,因此,无法避免这一点,我们也将准备一个 mat 来接收结果行。
hough-lines 函数本身是用一组参数调用的。可以在 OpenCV 网站上找到霍夫变换的完整的基本极坐标系统解释:
docs . opencv . org/3 . 3 . 1/d9/db0/tutorial _ Hough _ lines . html
你真的不需要现在就阅读所有的东西,但是意识到什么可以做什么不可以做是很好的。
现在,我们将只应用链接教程中建议的相同参数。
(def lines (new-mat)) (hough-lines can lines 1 (/ Math/PI 180) 100)
得到的线条矩阵由一列行组成,每行有两个值 rho 和 theta。
创建从 rho 和 theta 画线所需的两个点有点复杂,但在 opencv 教程中有描述。
现在,下面的函数为您完成了工作。
(def result (clone parking)) (dotimes [ i (.rows lines)] (let [ val_ (.get lines i 0) rho (nth val_ 0) theta (nth val_ 1) a (Math/cos theta) b (Math/sin theta) x0 (* a rho) y0 (* b rho) pt1 (new-point (Math/round (+ x0 (* 1000 (* -1 b)))) (Math/round (+ y0 (* 1000 a)))) pt2 (new-point (Math/round (- x0 (* 1000 (* -1 b)))) (Math/round (- y0 (* 1000 a)))) ] (line result pt1 pt2 color/black 1))) Drawing the found lines on top of the tennis court mat creates the image in Figure 3-50. Figure 3-50
Figure 3-50
霍夫线结果
请注意,当调用 hough-lines 时,将值为 1 的参数更改为值为 2 会得到更多的行,但是您可能需要在之后自己过滤这些行。
同样根据经验,将数学/圆周率舍入从 180°更改为 90°会产生更少的行,但结果会更好。
霍夫线 P
hough-lines 函数的另一个变体,名为 hough-lines-p,是一个添加了概率数学的增强版本,它通常通过执行猜测来给出一组更好的线。
为了用 P 来尝试霍夫线,我们这次将以…一个足球场为例。
(def soccer-field (-> "resources/chapter03/soccer-field.jpg" (imread IMREAD_REDUCED_COLOR_4))) (u/mat-view soccer-field)
按照最初的 hough-lines 示例,我们将足球场变成灰色,并应用轻微的高斯模糊来消除源图像中可能的缺陷。
(def gray (-> soccer-field clone (cvt-color! COLOR_BGR2GRAY) (gaussian-blur! (new-size 1 1) 0 ) )) The resulting grayed version of the soccer field is shown in Figure 3-51. Figure 3-51
Figure 3-51
灰色足球场
现在让我们制作一个巧妙的球场来创建边缘。
(def edges (-> gray clone (canny! 100 220)))
现在,我们调用 hough-lines-p. 在下面的代码片段中解释了所使用的参数。预计将从新创建的边垫中收集线。
; distance resolution in pixels of the Hough grid (def rho 1) ; angular resolution in radians of the Hough grid (def theta (/ Math/PI 180)) ; minimum number of votes (intersections in Hough grid cell) (def min-intersections 30) ; minimum number of pixels making up a line (def min-line-length 10) ; maximum gap in pixels between connectable line segments (def max-line-gap 50)
参数准备好了;让我们调用 hough-lines-p,结果存储在 lines mat 中。
(def lines (new-mat)) (hough-lines-p edges lines rho theta min-intersections min-line-length max-line-gap)
这一次,线条比常规的 hough-lines 函数更容易绘制。结果矩阵的每一行都由四个值组成,这四个值对应于绘制该行所需的两个点。
(def result (clone soccer-field)) (dotimes [ i (.rows lines)] (let [ val (.get lines i 0)] (line result (new-point (nth val 0) (nth val 1)) (new-point (nth val 2) (nth val 3)) color/black 1))) The result of drawing the results of hough-lines-p is displayed in Figure 3-52. Figure 3-52
Figure 3-52
足球场上的线
在台球桌上找口袋
不再在球场上跑来跑去;让我们移动到…台球桌!
以类似的方式,opencv 有一个名为 hough-circles 的函数来寻找看起来像圆的形状。更重要的是,这个功能很容易实现。
This time, let’s try to find the ball pockets of a billiard table. The exercise is slightly difficult because it is easy to wrongly count the regular balls as pockets.
你不能在没有准备好的情况下敲开机会的大门。
布鲁诺·马尔斯
我们先把台球桌准备好。
(def pool (-> "resources/chapter03/pooltable.jpg" (imread IMREAD_REDUCED_COLOR_2)))
使用 hough-circles,似乎可以通过绕过预处理中的谨慎步骤来获得更好的结果。
下面的代码片段显示了要在源 mat 中查找的圆的最小和最大半径值的位置。
(def gray (-> pool clone (cvt-color! COLOR_BGR2GRAY))) (def minRadius 13) (def maxRadius 18) (def circles (new-mat)) (hough-circles gray circles CV_HOUGH_GRADIENT 1 minRadius 120 10 minRadius maxRadius)
这里,圆被收集在一个垫子中,每条线包含圆心的 x 和 y 位置及其半径。
最后,我们简单地用 opencv circle 函数在结果 mat 上画圆。
(def output (clone pool)) (dotimes [i (.cols circles)] (let [ _circle (.get circles 0 i) x (nth _circle 0) y (nth _circle 1) r (nth _circle 2) p (new-point x y)] (circle output p (int r) color/white 3))) All the pockets are now highlighted in white in Figure 3-53. Figure 3-53
Figure 3-53
白色台球桌的口袋!
Note that if you put the minRadius value too low, you quickly get false positives with the regular balls, as shown in Figure 3-54. Figure 3-54
Figure 3-54
假口袋
因此,精确定义要搜索的内容是大多数 OpenCV 工作(也许还有其他工作)成功的秘诀。
因此,为了避免这里的假阳性,在接受和画线之前过滤颜色可能也是一个好主意。接下来看看怎么做。
寻找圆圈
在这个简短的例子中,我们将寻找垫子中的红色圆圈,在垫子中可以找到多种颜色的圆圈。
(def bgr-image (-> "resources/detect/circles.jpg" imread (u/resize-by 0.5) )) The bgr-image is shown in Figure 3-55. Figure 3-55
Figure 3-55
彩色圆圈
如果你直接阅读这本书的黑白版本,你可能看不到它,但我们将把注意力集中在左下角的大圆圈上,它是一个鲜艳的红色。
如果你还记得以前食谱中的经验,你已经知道我们需要将色彩空间转换为 HSV,然后过滤 0 到 10 之间的色调范围。
下面的代码片段展示了如何使用一些额外的模糊来实现这一点,以方便以后的处理。
(def ogr-image (-> bgr-image (clone) (median-blur! 3) (cvt-color! COLOR_BGR2HSV) (in-range! (new-scalar 0 100 100) (new-scalar 10 255 255)) (gaussian-blur! (new-size 9 9) 2 2))) All the circles we are not looking for have disappeared from the mat resulting from the small pipeline, and the only circle we are looking for is now standing out nicely (Figure 3-56). Figure 3-56
Figure 3-56
红色圆圈显示为白色
现在,我们可以应用与之前看到的相同的霍夫圆调用;同样,圆圈将被收集在圆圈垫中,这将是一个 1×1 的垫,具有三个通道。
(def circles (new-mat)) (hough-circles ogr-image circles CV_HOUGH_GRADIENT 1 (/ (.rows bgr-image) 8) 100 20 0 0) (dotimes [i (.cols circles)] (let [ _circle (.get circles 0 i) x (nth _circle 0) y (nth _circle 1) r (nth _circle 2) p (new-point x y)] (circle bgr-image p (int r) rgb/greenyellow 5))) The result of drawing the circle with a border is shown in Figure 3-57. The red circle has been highlighted with a green-yellow color and a thickness of 5. Figure 3-57
Figure 3-57
突出显示的红色圆圈
使用绘制线段
有时,最简单的方法可能是简单地使用所提供的片段检测器。它对 Origami 不太友好,因为使用的方法是直接的 Java 方法调用(所以前缀是点“.”),但是片段比较自成一体。
让我们在之前看到的足球场上试试。这次我们将它直接加载到 gray,并观察分段检测器的行为。
(def soccer-field (-> "resources/chapter03/soccer-field.jpg" (imread IMREAD_REDUCED_GRAYSCALE_4))) (def det (create-line-segment-detector)) (def lines (new-mat)) (def result (clone soccer-field))
我们在线段检测器上调用 detect ,现在使用 Clojure Java Interop。
(.detect det soccer-field lines)
在这个阶段,lines mat 元数据是 1611CV_32FC4,意味着 161 行,每行由 1 列和每个点的 4 个通道组成,意味着每个值 2 个点。
检测器有一个有用的 drawSegments 函数,我们可以调用它来获得结果 mat。
(.drawSegments det result lines) The soccer field mat is now showing in Figure 3-58, this time with all the lines highlighted, including circles and semicircles. Figure 3-58
Figure 3-58
第一季第一集
3.6 查找并绘制轮廓和边界框
问题
由于识别和计算形状是 OpenCV 使用的前沿,您可能想知道如何在 Origami 中使用轮廓查找技术。
解决办法
除了传统的清理和图像准备,这个方法将引入 find-contours 函数来填充轮廓列表。
一旦找到轮廓,我们需要应用一个简单的过滤器来去除非常大的轮廓,如整个图片,以及实在太小而无用的轮廓。
一旦过滤完成,我们可以使用手工绘制的圆形和矩形或者提供的函数绘制轮廓来绘制轮廓。
它是如何工作的
索尼耳机
它们不再那么新了,但我爱我的索尼耳机。我只是带着它们到处走,你可以满足你的自恋,并通过简单地穿着它们获得你需要的所有关注。无论是在火车上还是在飞机上,它们都能带给你最好的声音…
让我们来玩一个快速寻找耳机轮廓的游戏。
(def headphones (-> "resources/chapter03/sonyheadphones.jpg" (imread IMREAD_REDUCED_COLOR_4)))
我的耳机仍然有一根电缆,因为我更喜欢声音,不管一些大公司怎么说。
Anyway, the headphones are shown in Figure 3-59. Figure 3-59
Figure 3-59
带线缆的索尼耳机
首先,我们需要准备耳机,以便更容易分析。为此,我们创建了一个有趣的部分,耳机本身的面具。
(def mask (-> headphones (cvt-color! COLOR_BGR2GRAY) (clone) (threshold! 250 255 THRESH_BINARY_INV) (median-blur! 7))) The inverted thresh binary output is shown in Figure 3-60. Figure 3-60
Figure 3-60
蒙面耳机
然后,通过使用蒙版,我们创建了一个蒙版输入 mat,它将用于简化轮廓查找步骤。
(def masked-input (clone headphones)) (set-to masked-input (new-scalar 0 0 0) mask) (set-to masked-input (new-scalar 255 255 255) (bitwise-not! mask))
你注意到了吗?是的,创建输入有一种更简单的方法,首先简单地创建一个非反转遮罩,但第二种方法为准备输入垫提供了更多的控制。
所以这里我们基本上分两步走。首先,当蒙版的相同像素值为 1 时,将原始 mat 的所有像素设置为黑色。下一步,设置所有其他的值为白色,在相反版本的面具。
The prepared result mat is in Figure 3-61. Figure 3-61
Figure 3-61
输入垫的准备
现在,用于查找轮廓的 mat 已经准备好了,您几乎可以直接在它上面调用 find-contours。
find-contours 有几个明显的参数,还有两个,最后两个,有点模糊。
RETR _ 列表是最简单的一种,将所有轮廓作为列表返回,而RETR _ 树是最常用的,表示轮廓是分层有序的。
CHAIN_APPROX_NONE 表示找到的轮廓的所有点被存储。不过,通常在绘制这些轮廓时,并不需要定义它们的所有点。如果不需要所有的点,可以使用 CHAIN_APPROX_SIMPLE ,减少定义轮廓的点数。
这最终取决于你如何处理之后的轮廓。但是现在,让我们保持所有的点!
(def contours (new-arraylist)) (find-contours masked-input contours (new-mat) ; mask RETR_TREE CHAIN_APPROX_NONE)
好的,现在让我们画矩形来突出每个找到的轮廓。我们在轮廓列表上循环,对于每个轮廓,我们使用 bounding-rect 函数来获得一个包围轮廓本身的矩形。
从 bounding-rect 调用中获取的矩形几乎可以原样使用,我们将用它来绘制我们的第一个轮廓。
(def exercise-1 (clone headphones)) (doseq [c contours] (let [ rect (bounding-rect c)] (rectangle exercise-1 (new-point (.x rect) (.y rect)) (new-point (+ (.width rect) (.x rect)) (+ (.y rect) (.height rect))) (color/->scalar "#ccffcc") 2))) Contours are now showing in Figure 3-62. Figure 3-62
Figure 3-62
头电话轮廓
没错。还不错。从图中可以很明显地看出,覆盖整个画面的大矩形并不是很有用。这就是为什么我们需要一点过滤。
Let’s filter the contours, by making sure they are
-
不要太小,这意味着它们应该覆盖的面积至少为 10,000,也就是 125×80 的表面。
-
也不能太大,也就是说高度不能覆盖整个画面。
下面的代码片段完成了过滤。
(def interesting-contours (filter #(and (> (contour-area %) 10000 ) (< (.height (bounding-rect %)) (- (.height headphones) 10))) contours))
所以,这次只画出有趣的轮廓就相当准确了。
(def exercise-1 (clone headphones)) (doseq [c interesting-contours] ...) Figure 3-63 this time shows only useful contours. Figure 3-63
Figure 3-63
耳机有趣的外形
画圆而不是矩形应该不会太难,所以我们在有趣的轮廓上做同样的循环,但是这次,基于边界矩形画一个圆。
(def exercise-2 (clone headphones)) (doseq [c interesting-contours] (let [ rect (bounding-rect c) center (u/center-of-rect rect) ] (circle exercise-2 center (u/distance-of-two-points center (.tl rect)) (color/->scalar "#ccffcc") 2))) The resulting mat, exercise-2, is shown in Figure 3-64. Figure 3-64
Figure 3-64
在它上面盘旋
最后,虽然它很难用于检测处理,但您也可以使用 opencv 函数 draw-contours 来很好地绘制轮廓的自由形状。
我们仍将在有趣轮廓列表上循环。请注意,参数可能感觉有点奇怪,因为绘制轮廓使用的是索引和列表,而不是轮廓本身,所以在使用绘制轮廓时要小心。
(def exercise-3 (clone headphones)) (dotimes [ci (.size interesting-contours)] (draw-contours exercise-3 interesting-contours ci (color/->scalar "#cc66cc") 3)) And finally, the resulting mat can be found in Figure 3-65. Figure 3-65
Figure 3-65
耳机和粉色轮廓
事情并不总是那么容易,那我们再举一个天上掉馅饼的例子吧!
在天空中
第二个例子以天空中的热气球为例,希望在上面绘制轮廓。
The picture of hot-air balloons in Figure 3-66 seems very innocent and peaceful. Figure 3-66
Figure 3-66
热气球
不幸的是,使用与前面所示相同的技术来准备图片并不能达到非常性感的效果。
(def wrong-mask (-> kikyu clone (cvt-color! COLOR_BGR2GRAY) (threshold! 250 255 THRESH_BINARY) (median-blur! 7))) It’s pretty pitch-black in Figure 3-67. Figure 3-67
Figure 3-67
有人在上面吗?
所以,让我们试试另一种技术。为了得到更好的口罩,你会怎么做?
是的——为什么不呢?让我们过滤所有这些蓝色,并从中创建一个模糊的面具。这将为您提供以下代码片段。
(def mask (-> kikyu (clone) (cvt-color! COLOR_RGB2HSV) (in-range! (new-scalar 10 30 30) (new-scalar 30 255 255)) (median-blur! 7))) Nice! Figure 3-68 shows that this actually worked out pretty neatly. Figure 3-68
Figure 3-68
有用的面具
我们现在将使用补充版本的面具来寻找轮廓。
(def work (-> mask bitwise-not!))
使用查找轮廓功能,没有更多的秘密向你隐藏。或许是吧?参数表中的新点在做什么?不用担心;它只是一个偏移量,这里我们没有指定偏移量,所以 0 0。
(def contours (new-arraylist)) (find-contours work contours (new-mat) RETR_LIST CHAIN_APPROX_SIMPLE (new-point 0 0))
轮廓在里面!让我们过滤尺寸,并在它们周围画圆。这只是上一个例子的重复。
(def output_ (clone kikyu)) (doseq [c contours] (if (> (contour-area c) 50 ) (let [ rect (bounding-rect c)] (if (and (> (.height rect) 40) (> (.width rect) 60)) (circle output_ (new-point (+ (/ (.width rect) 2) (.x rect)) (+ (.y rect) (/ (.height rect) 2))) 100 rgb/tan 5))))) Nice. You are getting pretty good at those things. Look at and enjoy the result of Figure 3-69. Figure 3-69
Figure 3-69
在热气球上盘旋
接下来,让我们在绘图之前进行过滤,并再次使用 bounding-rect 来绘制矩形。
(def my-contours (filter #(and (> (contour-area %) 50 ) (> (.height (bounding-rect %)) 40) (> (.width (bounding-rect %)) 60)) contours))
的确,如果你检查它的内容,我的轮廓只有三个元素。
(doseq [c my-contours] (let [ rect (bounding-rect c)] (rectangle output (new-point (.x rect) (.y rect)) (new-point (+ (.width rect) (.x rect)) (+ (.y rect) (.height rect))) rgb/tan 5))) Now drawing those rectangles results in Figure 3-70. Figure 3-70
Figure 3-70
热气球上的长方形
3.7 关于轮廓的更多信息:使用形状
问题
继续上一个食谱,您将会看到函数 find-contours 返回了什么。用所有的点绘制轮廓是不错的,但是如果你想用不同的颜色突出不同的形状呢?
此外,如果形状是手绘的,或者在源 mat 中显示不正确怎么办?
解决办法
我们仍然要像到目前为止所做的那样使用查找轮廓和绘制轮廓,但是我们要在绘制它们之前对每个轮廓做一些预处理,以找出它们有多少条边。
近似-多边形- dp 是用于近似形状的函数,从而减少点的数量,只保留多边形形状中最重要的点。我们将创建一个小函数,approximate,将形状转换成多边形,并计算它们的边数。
我们还将看看填充凸多边形,看看我们如何绘制手写形状的近似轮廓。
最后,另一个名为折线的 opencv 函数将用于只绘制找到的轮廓的线框。
它是如何工作的
突出轮廓
We will use a picture with many shapes for the first part of this exercise, like the one in Figure 3-71. Figure 3-71
Figure 3-71
形状
这里的目标是根据每个形状的边数,用不同的颜色绘制每个形状的轮廓。
shapes mat 只需加载以下代码片段:
(def shapes (-> "resources/morph/shapes3.jpg" (imread IMREAD_REDUCED_COLOR_2)))
正如在前面的配方中所做的,我们首先通过将输入的克隆转换为灰色来准备一个 thresh mat,然后应用一个简单的阈值来突出显示形状。
(def thresh (-> shapes clone (cvt-color! COLOR_BGR2GRAY) (threshold! 210 240 1))) (def contours (new-arraylist)) Looking closely, we can see that the shapes are nicely highlighted, and if you look at Figure 3-72, the thresh is indeed nicely showing the shapes. Figure 3-72
Figure 3-72
功能脱粒机
好了,thresh 准备好了,所以你现在可以调用 find-contours 了。
(find-contours thresh contours (new-mat) RETR_LIST CHAIN_APPROX_SIMPLE)
为了绘制轮廓,我们首先编写一个 dump 函数,它在轮廓列表上循环,并用洋红色绘制每个轮廓。
(defn draw-contours! [img contours] (dotimes [i (.size contours)] (let [c (.get contours i)] (draw-contours img contours i rgb/magenta-2 3))) img) (-> shapes (draw-contours! contours) (u/mat-view)) The function works as expected, and the result is shown in Figure 3-73. Figure 3-73
Figure 3-73
洋红色轮廓
但是,正如我们已经说过的,我们希望为每个轮廓使用不同的颜色,所以让我们编写一个函数,根据轮廓的边来选择颜色。
(defn which-color[c] (condp = (how-many-sides c) 1 rgb/pink 2 rgb/magenta- 3 rgb/green 4 rgb/blue 5 rgb/yellow-1- 6 rgb/cyan-2 rgb/orange))
不幸的是,即使将 CHAIN_APPROX_SIMPLE 作为参数传递给 find-contours,每个形状的点数仍然太高,没有任何意义。
8, 70, 132, 137...
因此,让我们通过将形状转换为近似值来减少点数。
opencv 中使用了两个函数:弧长函数和近似多边形函数。因子 0.02 是 opencv 提出的默认值;稍后我们将在这个食谱中看到不同值的影响。
(defn approx [c] (let[m2f (new-matofpoint2f (.toArray c)) len (arc-length m2f true) ret (new-matofpoint2f) app (approx-poly-dp m2f ret (* 0.02 len) true)] ret))
使用这个新的近似值函数,我们现在可以通过计算近似值的点数来计算边数。
下面是一个简单的多少边函数。
(defn how-many-sides[c] (let[nb-sides (.size (.toList c))] nb-sides))
一切就绪;让我们重写愚蠢的轮廓图!使用 which-color 函数变成稍微进化的东西。
(defn draw-contours! [img contours] (dotimes [i (.size contours)] (let [c (.get contours i)] (draw-contours img contours i (which-color c) 3))) img) And now calling the updated function properly highlights the polygons, counting the number of sides on an approximation of each of the found shapes (Figure 3-74). Figure 3-74
Figure 3-74
不同形状,不同颜色
请注意这个圆仍然有点过分,有太多的边,但这是意料之中的。
手绘形状
但也许你会说,形状已经很好地显示出来了,所以你仍然对近似是否真的有用有些怀疑。因此,让我们来看一幅美丽的手绘艺术作品,它正是为了这个例子而准备的。
(def shapes2 (-> "resources/chapter03/hand_shapes.jpg" (imread IMREAD_REDUCED_COLOR_2))) Figure 3-75 shows the newly loaded shapes. Figure 3-75
Figure 3-75
一件艺术品
首先,让我们调用 find-contours 并画出由它们定义的形状。
Reusing the same draw-contours! function and drawing over the art itself gives Figure 3-76. Figure 3-76
Figure 3-76
艺术上的轮廓
现在这一次,让我们尝试一些不同的东西,使用核心 opencv 包中的函数 fill-convex-poly 。
这与绘制轮廓没有太大的不同,我们实际上只是在列表上循环,并在每个轮廓上使用填充凸多边形。
(def drawing (u/mat-from shapes2)) (set-to drawing rgb/white) (let[ contours (new-arraylist)] (find-contours thresh contours (new-mat) RETR_LIST CHAIN_APPROX_SIMPLE) (doseq [c contours] (fill-convex-poly drawing c rgb/blue-3- LINE_4 1))) And so, we get the four shapes turned to blue (Figure 3-77). Figure 3-77
Figure 3-77
一件艺术品变成了蓝色
正如我们所看到的,轮廓和形状被发现并且可以被画出来。
另一种绘制等高线的方法是使用函数折线。幸运的是,函数折线隐藏了轮廓每个元素上的循环,您可以直接将轮廓列表作为参数传入。
(set-to drawing rgb/white) (let[ contours (new-arraylist)] (find-contours thresh contours (new-mat) RETR_LIST CHAIN_APPROX_SIMPLE) (polylines drawing contours true rgb/magenta-2)) (-> drawing clone (u/resize-by 0.5) u/mat-view) And this time, we nicely get the wireframe only of the contours (Figure 3-78). Figure 3-78
Figure 3-78
艺术线框
好的,但是现在这些形状都有太多的点。
让我们再次使用创建的近似函数,并增强它,以便我们可以指定近似聚合 dp 使用的因子。
(defn approx_ ([c] (approx_ c 0.02)) ([c factor] (let[m2f (new-matofpoint2f (.toArray c)) len (arc-length m2f true) ret (new-matofpoint2f)] (approx-poly-dp m2f ret (* factor len) true) (new-matofpoint (.toArray ret)))))
更高的系数意味着我们在更大程度上强制减少点数。因此,为了达到这个效果,让我们将通常的值 0.02 增加到 0.03。
(set-to drawing rgb/white) (let[ contours (new-arraylist)] (find-contours thresh contours (new-mat) RETR_LIST CHAIN_APPROX_SIMPLE) (doseq [c contours] (fill-convex-poly drawing (approx_ c 0.03) (which-color c) LINE_AA 1))) The shapes have been greatly simplified, and the number of sides has quite diminished: the shapes are now easier to identify (Figure 3-79). Figure 3-79
Figure 3-79
具有简单形状的艺术
3.8 移动形状
问题
这是基于堆栈溢出时发现的一个问题。
stack overflow . com/questions/32590277/move-area-of-a-image-using-opencv
问题是“将图像区域移动到中心”,基本图片如图 3-80 所示。
The goal is to move the yellow shape and the black mark inside to the center of the mat. Figure 3-80
Figure 3-80
移动形状
解决办法
我非常喜欢这个食谱,因为它引入了许多 Origami 功能,共同致力于一个目标,这也是本章的主题。
The plan to achieve our goal is as follows:
-
首先,给原图加边框,看边界
-
切换到 HSV 颜色空间
-
通过只选择黄色范围内的颜色来创建蒙版
-
从前一个蒙版的边界矩形在原始图片中创建一个 submat
-
创建与原始大小相同的目标结果材质
-
在目标 mat 中创建一个 submat 来放置内容。该子矩阵必须具有相同的大小,并且它将位于中心。
-
将目标垫的其余部分设置为任意颜色…
-
我们完了!
让我们开始吧。
它是如何工作的
好的,所以第一步是突出垫子的边界,因为我们不能真正看到它延伸到哪里。
我们将开始加载图片,同时添加边框。
(def img (-> "resources/morph/cjy6M.jpg" (imread IMREAD_REDUCED_COLOR_2) (copy-make-border! 1 1 1 1 BORDER_CONSTANT (->scalar "#aabbcc")))) Bordered input with the rounded yellow mark is now shown in Figure 3-81. Figure 3-81
Figure 3-81
黄色标记和边框
然后,我们切换到 hsv 颜色空间,并在黄色标记上创建一个遮罩,这就是 Origami 流水线使一个接一个地传递函数变得容易得多的地方。
(def mask-on-yellow (-> img (clone) (cvt-color! COLOR_BGR2HSV) (in-range! (new-scalar 20 100 100) (new-scalar 30 255 255)))) Our yellow mask is ready (Figure 3-82). Figure 3-82
Figure 3-82
黄色标记上的遮罩
下一步是在新创建的遮罩中找到轮廓。请注意 RETR _ 外部的用法,这意味着我们只对外部轮廓感兴趣,因此黄色标记内的线将不包括在返回的轮廓列表中。
(def contours (new-arraylist)) (find-contours mask-on-yellow contours (new-mat) RETR_EXTERNAL CHAIN_APPROX_SIMPLE)
现在让我们创建一个项目 mat,原始图片的子 mat,其中定义它的矩形是由轮廓的边界矩形构成的。
(def background-color (->scalar "#000000")) ; mask type CV_8UC1 is important !! (def mask (new-mat (rows img) (cols img) CV_8UC1 background-color)) (def box (bounding-rect (first contours))) (def item (submat img box)) The item submat is shown in Figure 3-83. Figure 3-83
Figure 3-83
由轮廓的边界矩形组成的 Submat
我们现在创建一个全新的 mat,与 submat 项大小相同,并复制到分段项的内容中。背景颜色必须与结果 mat 的背景颜色相同。
(def segmented-item (new-mat (rows item) (cols item) CV_8UC3 background-color)) (copy-to item segmented-item (submat mask box) ) The newly computed segmented item is shown in Figure 3-84. Figure 3-84
Figure 3-84
分段项目
现在让我们找到将作为复制目标的 rect 的位置。我们希望该项目被移到中心,rect 应该与原来的小盒垫大小相同。
(def center (new-point (/ (.cols img ) 2 ) (/ (.rows img) 2))) (def center-box (new-rect (- (.-x center ) (/ (.-width box) 2)) (- (.-y center ) (/ (.-height box) 2)) (.-width box) (.-height box)))
好了,一切就绪;现在,我们创建结果 mat,并通过 submat 在前面计算的中心位置复制分段项的内容。
(def result (new-mat (rows img) (cols img) CV_8UC3 background-color)) (def final (submat result center-box)) (copy-to segmented-item final (new-mat))
仅此而已。
The yellow shape has been moved to the center of a new mat. We made sure the white color of the original mat was not copied over, by specifically using a black background for the final result mat (Figure 3-85). Figure 3-85
Figure 3-85
获胜
3.9 看树
问题
这是另一个基于堆栈溢出问题的方法。这一次的兴趣是集中在一个树木种植园,在数树木之前,能够在航拍照片中突出显示它们。
参考问题在这里:
stack overflow . com/questions/31310307/best-way-to-segment-a-tree-in-plantation-air-image-using-opencv
解决办法
像往常一样,通过调用范围内的来识别树。但是结果,正如我们将看到的,仍然是相互关联的,这使得实际计数变得非常困难。
我们就来介绍一下形态学的用法——ex!来来回回地腐蚀所创建的掩模,从而形成更好的预处理垫,为计数做好准备。
它是如何工作的
We will use a picture of a hazy morning forest to work on (Figure 3-86). Figure 3-86
Figure 3-86
朦胧的树木
最终,你会想要数一数这些树,但是现在甚至很难用肉眼看到它们。(周围有机器人吗?)
让我们从在绿色的树木上创建一个遮罩开始。
(def in-range-pict (-> trees clone (in-range! (new-scalar 100 80 100) (new-scalar 120 255 255)) (bitwise-not!))) We get a mask of dots … as shown in Figure 3-87. Figure 3-87
Figure 3-87
白纸黑字
这个食谱的诀窍就在这里。我们将在图片范围内的 mat 上应用 MORPH_ERODE,然后是 MORPH_OPEN。这将有清理森林的效果,并给每棵树自己的空间。
变形是通过准备一个 mat 来传递一个由小椭圆创建的内核矩阵作为参数来完成的。
(def elem (get-structuring-element MORPH_ELLIPSE (new-size 3 3)))
如果在 elem 上调用 dump ,会发现它的内部表示。
[0 1 0] [1 1 1] [0 1 0]
然后我们使用这个内核矩阵,把它传递给 morpholy-ex!。
(morphology-ex! in-range-pict MORPH_ERODE elem (new-point -1 -1) 1) (morphology-ex! in-range-pict MORPH_OPEN elem) This has the desired effect of reducing the size of each tree dot, thus reducing the overlap between the trees (Figure 3-88). Figure 3-88
Figure 3-88
变形后树不重叠
最后,我们只需在原始垫子上应用简单的颜色来突出人眼看到的树的位置。(周围还是没有机器人?)
(def mask (-> in-range-pict clone (in-range! (new-scalar 0 255 255) (new-scalar 0 0 0)))) (def target (new-mat (.size trees) CV_8UC3)) (set-to target rgb/greenyellow) (copy-to original target mask)
这在视频流中实时进行是很棒的。
你也已经知道接下来等待你的是什么练习。通过快速调用查找轮廓来计算森林中的树木数量…
这当然是留给读者的自由练习!
3.10 检测模糊
问题
您有大量的图片要分类,并且您希望有一个自动化的过程来丢弃那些模糊的图片。
解决办法
该解决方案的灵感来自于 pyimagesearch 网站条目pyimagesearch . com/2015/09/07/blur-detection-with-opencv/,该条目本身指向了 Pech-Pacheco 等人的论文拉普拉斯的变体“硅藻在明场显微镜中的自动聚焦:比较研究”
它确实突出了将 OpenCV 和这里的 origami 快速转化为有用的东西的酷方法。
基本上,你需要对你的图像的单通道版本应用拉普拉斯过滤器。然后,计算结果与前面结果的偏差,并检查偏差是否低于给定的阈值。
滤镜本身应用了 filter-2-d!,而方差是用均值-标准差计算的。
它是如何工作的
用于滤波器的拉普拉斯矩阵/核将重点放在中心像素上,并减少对左/右上/下像素的强调。
这是我们将要使用的拉普拉斯核。
(def laplacian-kernel (u/matrix-to-mat [ [ 0 -1 0] [-1 4 -1] [ 0 -1 0] ]))
让我们用 filter-2d 来应用这个内核吧!,然后调用 mean-std-dev 来计算中值和偏差。
(filter-2-d! img -1 laplacian-kernel) (def std (new-matofdouble)) (def median (new-matofdouble)) (mean-std-dev img median std)
处理图片时,您可以使用 dump 查看平均值的结果,因为它们是矩阵。这显示在下面:
(dump median) ; [19.60282552083333] (dump std) ; [45.26957788759024]
最后,用于比较以检测模糊的值将是偏差的 2 次方。
(Math/pow (first (.get std 0 0)) 2)
然后我们将得到一个与 50 相比较的值。低于 50 表示图像模糊。大于 50 表示图像显示不模糊。
让我们创造一个模糊的图像?由前面所有步骤组成的函数:
(defn std-laplacian [img] (let [ std (new-matofdouble)] (filter-2-d! img -1 laplacian-kernel) (mean-std-dev img (new-matofdouble) std) (Math/pow (first (.get std 0 0)) 2))) (defn is-image-blurred?[img] (< (std-laplacian (clone img)) 50))
现在让我们把这个函数应用到一些图片上。
(-> "resources/chapter03/cat-bg-blurred.jpg" (imread IMREAD_REDUCED_GRAYSCALE_4) (is-image-blurred?)) And … our first test passes! The cat of Figure 3-89 indeed gives a deserved blurred result. Figure 3-89
Figure 3-89
模糊的猫
And what about one of the most beautiful cat on this planet? That worked too. The cat from Figure 3-90 is recognized as sharp! Figure 3-90
Figure 3-90
敏锐但困倦的猫
现在,也许是时候去整理你所有的海边夏日照片了…
但是,是的,当然,是的,同意,并不是所有模糊的图片都是垃圾。
3.11 制作照片拼版
问题
大约 20 年前,在一个项目实验室里,我看到了一张巨大的《星球大战》海报,由第一部电影《??:新的希望》的多个小场景组成。
这张海报很大,从稍远的地方看,它实际上是一张达斯·维德向卢克伸出手的照片。
海报给我留下了很好的印象,我一直想自己做一张。最近,我还知道这种创作的图片有一个名字:照片马赛克。
解决办法
这个概念比我最初想的要简单得多。基本上,最难的是下载图片。
你主要需要两个输入,一个最终的图片,和一组用作 subs 的图片。
这项工作包括计算每张图片的 RGB 通道的平均值,并从中创建一个索引。
第一步准备工作完成后,在要复制的图片上创建一个网格,然后对于网格中的每个单元格,计算两个平均值之间的范数:一个来自单元格,一个来自索引的每个文件。
最后,用具有最低平均值的索引中的图片替换大图片的子图片,这意味着该图片在视觉上更接近子图片。
让我们付诸行动吧!
它是如何工作的
第一步是编写一个函数来计算一个垫子颜色的平均值。为此,我们再次使用了 mean-std-dev ,因为我们只对这个练习的平均值感兴趣,所以这是函数返回的结果。
(defn mean-average-bgr [mat] (let [_mean (new-matofdouble)] (-> mat clone (median-blur! 3) (mean-std-dev _mean (new-matofdouble))) _mean))
让我们在任何图片上调用这个,看看会发生什么。
(-> "resources/chapter03/emilie1.jpg" (imread IMREAD_REDUCED_COLOR_8) get-averages-bgr-mat dump)
返回值如下所示。这些值是三个 RGB 通道的平均值。
[123.182] [127.38] [134.128]
让我们稍微回避一下,比较一下三个矩阵的范数:ex1、ex2 和 ex3。看它们的内容,你可以“感觉”到 ex1 和 ex2 比 ex1 和 ex3 更接近。
(def ex1 (u/matrix-to-mat [[0 1 2]])) (def ex2 (u/matrix-to-mat [[0 1 3]])) (def ex3 (u/matrix-to-mat [[0 1 7]])) (norm ex1 ex2) ; 1.0 (norm ex1 ex3) ; 5.0
计算矩阵之间距离的范数函数的输出结果证实了这一点。
这就是我们要用的。首先,我们创建所有可用文件的索引。该索引是通过将每个图像加载为 mat 并计算其均值-平均值-bgr 而创建的图。
(defn indexing [files for-size] (zipmap files (map #(-> % imread (resize! for-size) mean-average-bgr) files)))
该函数的输出是一个映射,其中每个元素是一组键,val 类似 filepath -> mean-average-bgr。
为了找到最接近的图像,现在我们有了一个索引,我们计算所考虑的 mat(或以后的 submat)的范数,以及我们的索引的所有可能的均值-bgr 矩阵。
然后我们进行排序,取尽可能低的值。这就是 find-closest 所做的。
(defn find-closest [ target indexed ] (let [mean-bgr-target (get-averages-bgr-mat target)] (first (sort-by val < (apply-to-vals indexed #(norm mean-bgr-target %))))))
apply-to-vals 是一个函数,它接受一个 hashmap 和一个函数,将一个函数应用于 map 中的所有值,其余的保持不变。
(defn apply-to-vals [m f] (into {} (for [[k v] m] [k (f v)])))
最难的部分完成了;让我们来看看照片拼图算法的实质。
tile 函数是创建输入图片的网格并检索子 mat 的函数,每个子 mat 对应网格的一个 tile。
然后,它逐个遍历所有子 mat,使用相同的函数计算子 mat 的平均颜色平均值,然后使用该平均值和之前创建的索引调用 find-closest 。
对 find-closest 的调用返回一个文件路径,我们从该路径加载一个 submat,然后替换目标图片中图块的 submat,只需用通常的 copy-to 复制加载的 mat。
在这里写的函数 tile 里看到这个。
(defn tile [org indexed ^long grid-x ^long grid-y] (let[ dst (u/mat-from org) width (/ (.cols dst) grid-x) height (/ (.rows dst) grid-y) total (* grid-x grid-y) cache (java.util.HashMap.) ] (doseq [^long i (range 0 grid-y)] (doseq [^long j (range 0 grid-x)] (let [ square (submat org (new-rect (* j width) (* i height) width height )) best (first (find-closest square indexed)) img (get-cache-image cache best width height) sub (submat dst (new-rect (* j width) (* i height) width height )) ] (copy-to img sub)))) dst))
主入口点是一个名为 photomosaic 的函数,它通过预先创建平均值的索引并将其传递给 tile 函数来调用 tile 算法。
(defn photomosaic [images-folder target-image output grid-x grid-y ] (let [files (collect-pictures images-folder) indexed (indexing (collect-pictures images-folder) (new-size grid-x grid-y)) target (imread target-image )] (tile target indexed grid-x grid-y))) Whoo-hoo. It’s all there. Creating the photomosaic is now as simple as calling the function of the same name with the proper parameters:
-
jpg 图像的文件夹
-
我们要镶嵌的图片
-
网格的大小
下面是一个简单的例子:
(def lechat (photomosaic "resources/cat_photos" "resources/chapter03/emilie5.jpg" 100 100)) And the first photomosaic ever of Marcel the cat is shown in Figure 3-91. Figure 3-91
Figure 3-91
一只熟睡的猫的马赛克
Another photomosaic input/output, this from Kenji’s cat, is in Figure 3-92. Figure 3-92
Figure 3-92
古贺圣猫
And, a romantic mosaic in Figure 3-93. Figure 3-93
Figure 3-93
福冈的猫
图片中使用的猫都包括在例子中,没有一只猫受到伤害,所以现在可能是你创造自己的令人敬畏的马赛克的时候了…享受吧!
四、实时视频
到目前为止,这本书一直专注于让读者快速处理图像和生成的图形艺术。您现在应该对介绍的方法非常有信心,并且您有很多想法的空间。
太好了!
我们可以继续扩展和解释 OpenCV 的其他方法,但我们将在第四章中做一些其他事情,因为我们切换到实时视频分析,将前几章学到的知识应用到视频流领域。
你可能会问:什么是实时视频分析,我为什么要这么做?OpenCV 使查看视频流和关注视频内容变得轻而易举。例如,现在有多少人在视频流上显示?这个视频里有猫吗?这是一场网球比赛吗,所有问题的根源,今天是晴天吗?
OpenCV 已经为您实现了许多这样的算法,更好的是,Origami 添加了一点甜蜜的糖,所以您可以直接开始,并以一种简单的方式将块放在一起。
在这一章中,我们将从第一个配方开始,它将向您展示为视频流做好准备需要多少东西。
然后,我们转移到更实质性的主题,像人脸识别,背景区分,寻找橙子,最重要的是,身体肥皂。
4.1 视频流入门
问题
你有图像处理的 Origami 装置;现在,你想知道视频处理的 Origami 设置。
解决办法
坏消息是没有额外的项目设置。所以,我们几乎已经可以关闭这个食谱了。
好消息是 Origami 提供了两个功能,但是在使用它们之前,我们将介绍底层处理是如何工作的。
首先,我们将从 origami opencv3.video 包中创建一个 videocapture 对象,并用它开始/停止一个流。
第二,既然我们认为这肯定更容易使用,我们将介绍为您做所有事情的函数: u/simple-cam-window 。
最后,我们将回顾 u/cams-window,它可以轻松地组合来自不同来源的多个流。
它是如何工作的
自己动手视频流
你可以跳过食谱中的这一小部分,但是知道幕后是什么实际上是非常有益的。
视频流操作的简单思想始于创建一个 opencv videocapture 对象来访问可用的视频设备。
然后,该对象可以返回一个 mat 对象,就像您到目前为止使用的所有 mat 对象一样。然后可以对 mat 对象进行操作,在最简单的情况下,在屏幕上的一个框架中显示 mat。
Origami 使用类似于 u/imshow 的东西来显示视频中的垫子,但是对于第一个例子,让我们简单地使用 u/imshow 来显示垫子。
这里,我们确实需要另一个名称空间: [opencv3.video :as v] ,但是稍后您将会看到这一步并不是必需的,只有在直接使用 opencv video 函数时,您才会需要额外的 video 名称空间。
让我们通过下面的代码示例来看看它是如何进行的。
首先,我们创建 videocapture 对象,它可以访问您的主机系统的所有网络摄像头。
然后我们打开 ID 为 0 的相机。这可能是您的环境中的默认设置,但是我们将在后面看到如何使用多个设备。
(def capture (v/new-videocapture)) (.open capture 0)
我们需要一个窗口来显示从设备记录的帧,毫无疑问,我们将创建一个名为 window 的绑定。该窗口将被设置为黑色背景。
(def window (u/show (new-mat 200 200 CV_8UC3 rgb/black)))
然后,我们创建一个缓冲区来接收视频数据,就像一个普通的 OpenCV mat 一样。
(def buffer (new-mat))
核心视频循环将使用捕获对象上的 read 函数将内容复制到缓冲区,然后使用 u/re-show 函数在窗口中显示缓冲区。
(dotimes [_ 100] (.read capture buffer) (u/re-show window buffer)) At this stage, you should see frames showing up in a window on your screen, as in Figure 4-1. Figure 4-1
Figure 4-1
我最喜欢的沐浴露
最后,当循环结束时,使用捕获对象上的释放功能释放网络摄像头。
(.release capture)
这也应该有关闭你的计算机的照相机 LED 的效果。在这个小练习的最后要考虑的一件事是…是的,这是一个标准的 mat 对象,它被用作显示循环中的缓冲区,所以,是的,你可以在显示它之前插入一些文本或颜色转换。
单功能网络摄像头
既然你已经理解了底层的网络摄像头处理是如何完成的,这里有另一个稍微短一点的方法让你得到同样的结果,使用 u/simple-cam-window 。
在这一小节中,我们想快速回顾一下如何获取流并使用该函数对其进行操作。
在其最简单的形式中,simple-cam-window 与作为参数的身份函数一起使用。如您所知,identity 接受一个元素并按原样返回它。
(u/simple-cam-window identity)
如果您连接了网络摄像头,这将启动相同的流视频,流的内容显示在一个框架中。
该函数采用单个参数,该参数是在垫子显示在框架内之前应用于垫子的函数。
太好了。我们将在几秒钟后回到它,但是现在,这里是你将发现的:简单地将记录帧转换成不同的颜色图,你可以只使用 apply-color-map 传递一个匿名函数!。
(u/simple-cam-window #(apply-color-map! % COLORMAP_HOT)) With the immediate result showing in Figure 4-2. Figure 4-2
Figure 4-2
热身体皂
在第二个版本的 u/simple-cam-window 中,您可以指定帧和视频录制的设置,所有这些都是作为第一个参数传递给 simple-cam-window 的简单映射。
例如:
(u/simple-cam-window {:frame {:color "#ffcc88", :title "video", :width 350, :height 300} :video {:device 0, :width 100, :height 120}} identity)
在映射中,视频键指定设备 ID、获取流的设备以及要记录的帧的大小。请注意,如果大小不符合设备的能力,设置将被忽略。
在同一个参数映射中,帧键可以指定参数,如前一章所见,包括背景颜色、标题和窗口大小。
好,太好了;一切都准备好了。让我们玩一会儿。
变换函数
identity 函数接受一个元素并按原样返回它。通过返回 opencv 框架记录的 mat,我们看到了 identity 在第一次使用 cam 时是如何工作的。
Now, say you would like to write a function that
-
拿个垫子
-
以 0.5 为因子调整垫子的大小
-
将颜色贴图更改为冬季
-
将当前日期添加为白色覆盖
以你目前所掌握的知识来看,这并不困难。我们在一个函数 my-fn 里写一个小 Origami 流水线吧!进行图像转换:
(defn my-fn![mat] (-> mat (u/resize-by 0.5) (apply-color-map! COLORMAP_WINTER) (put-text! (str (java.util.Date.)) (new-point 10 50) FONT_HERSHEY_PLAIN 1 rgb/white 1) ))
请注意,此处流水线返回转换后的 mat。现在让我们在一个静态图像上使用这个新创建的流水线。
(-> "resources/chapter03/ai5.jpg" imread my-fn! u/mat-view) And let’s enjoy a simple winter feline output (Figure 4-3). Figure 4-3
Figure 4-3
酷猫
然后,如果你在星巴克使用笔记本电脑摄像头,你可以使用新功能 my-fn!通过将它作为一个参数传递给 simple-cam-window。
(u/simple-cam-window my-fn!) Which would give you something like Figure 4-4. Figure 4-4
Figure 4-4
星巴克冰咖啡笔芯
来自同一输入源的两帧或更多帧
当试图从同一个源应用两个或多个函数时,这是一种方便的方法。这实际上只是使用克隆函数来避免与源缓冲区的内存冲突的问题。
这里,我们创建了一个函数,它将缓冲区作为输入,然后连接从同一个缓冲区创建的两个图像。左边的第一个图像将是流的黑白版本,而右边的图像将是缓冲区的翻转版本。
(u/simple-cam-window (fn [buffer] (vconcat! [ (-> buffer clone (cvt-color! COLOR_RGB2GRAY) (cvt-color! COLOR_GRAY2RGB)) (-> buffer clone (flip! -1)) ]))) Note that we use the clone twice for each side of the concatenation (Figure 4-5). Figure 4-5
Figure 4-5
灰色左,翻转右,但它仍然是身体肥皂
您可以通过任意多次克隆输入缓冲区来进一步推广这个方法;为了突出这一点,下面是另一个在同一个输入缓冲区上应用不同颜色映射三次的例子。
(u/simple-cam-window (fn [buffer] (hconcat! [ (-> buffer clone (apply-color-map! COLORMAP_JET)) (-> buffer clone (apply-color-map! COLORMAP_BONE)) (-> buffer clone (apply-color-map! COLORMAP_PARULA))]))) And the result is shown in Figure 4-6. Figure 4-6
Figure 4-6
黑玉,骨头和帕鲁拉,但这仍然是沐浴露
4.2 组合多个视频流
问题
您尝试从同一个缓冲区创建许多输出,但如果能够插入多个摄像机并将它们的缓冲区组合在一起,那就更好了。
解决办法
Origami 附带了一个 u/simple-cam-window 的兄弟函数,名为 u/cams-window,,这是一个增强版本,您可以合并来自相同或多个源的多个流。
它是如何工作的
u/cams-window 是一个获取设备列表的函数,每个设备从一个 ID 定义一个设备,并且通常是一个转换函数。
该函数还采用一个视频函数来连接两个或多个设备输出,最后采用一个帧元素来定义窗口的常用参数,如大小和标题。
(u/cams-window {:devices [ {:device 0 :width 300 :height 200 :fn identity} {:device 1 :width 300 :height 200 :fn identity}] :video { :fn #(hconcat! [ (-> %1 (resize! (new-size 300 200))) (-> %2 (resize! (new-size 300 200))) ])} :frame {:width 650 :height 250 :title "OneOfTheSame"}})
图 4-7 显示了两种针对同一种沐浴露的设备,但角度不同。
The left frame takes input from the device with ID 0, and the right frame input from the device with ID 1. Figure 4-7
Figure 4-7
更多人体香皂图片
请注意,即使为每个设备指定了大小,实际上仍然需要调整大小,因为设备可以使用非常特定的高度和宽度组合,因此使用不同的设备可能有点困难。
尽管如此,调整大小!调用合成视频功能并不觉得不合适,之后一切都很顺利。
4.3 扭曲视频
问题
这个方法是关于使用变换来扭曲视频流的缓冲区,但也是关于实时更新变换。
解决办法
扭曲转换本身将使用 opencv 的get-perspective-transform从核心名称空间完成。
实时更新将使用 Clojure atom 和软件事务内存来完成,在这里很适合更新进行转换所需的矩阵值,而显示循环正在读取该矩阵的内容,因此总是获得最新的值。
它是如何工作的
为了执行透视变换,我们需要一个扭曲矩阵。扭曲矩阵包含在一个原子中,并首先初始化为零。
(def mt (atom nil))
用于进行变换的扭曲矩阵可以从四个点创建,具有它们在变换之前和之后的位置。
我们将使用 reset 来更新 atom 值,而不是对本地绑定进行操作!。
(def points1 [[100 10] [200 100] [28 200] [389 390]]) (def points2 [[70 10] [200 140] [20 200] [389 390]]) (reset! mt (get-perspective-transform (u/matrix-to-matofpoint2f points1) (u/matrix-to-matofpoint2f points2)))
请记住,您仍然可以转储 warp matrix,它是一个常规的 3×3 mat,方法是对它使用一个解引用调用,使用@或 deref 。
(dump @mt)
利用前面定义的点,这给出了下面的双精度矩阵。
[1.789337561985906 0.3234215275201738 -94.5799621372129] [0.7803091692375479 1.293303360247406 -78.45137776386103] [0.002543030309135725 -3.045754676722361E-4 1]
现在让我们使用保存在 mt atom 中的矩阵创建一个扭曲垫子的函数。
(defn warp! [ buffer ] (-> buffer (warp-perspective! @mt (size buffer ))))
记住这个函数仍然可以应用于标准图像;例如,如果您想要扭曲猫,您可以编写以下 Origami 流水线:
(-> "resources/chapter03/ai5.jpg" imread (u/resize-by 0.7) warp! u/imshow) And the two cats from before would be warping as in Figure 4-8. Figure 4-8
Figure 4-8
扭曲的猫
现在让我们使用 warp 将该功能应用于视频流!作为 u/simple-cam 窗口的参数。
(u/simple-cam-window warp!)
身体皂已经翘了!(图 4-9
Obviously, the book is not doing too much to express the difference between a still cat image and the body soap stream , so you can plug in your own stream there. Figure 4-9
Figure 4-9
扭曲的身体肥皂
4.4 使用人脸识别
问题
虽然 OpenCV 人脸识别功能在静态图片上工作得非常好,但在视频流上工作就不同了,因为要寻找实时显示的移动人脸,以及计算人数等。
解决办法
第一步是加载一个分类器:opencv 对象,它将能够找出 mat 上的匹配元素。
使用 origami 函数 new-cascadeclassifier 从 xml 定义中加载分类器。
然后,使用该分类器和 mat 调用 detectMultiScale 将返回匹配 rect 对象的列表。
然后,这些 rect 对象可以用于用矩形突出显示找到的面,或者用于创建 submat。
它是如何工作的
完成这项工作不需要额外的 Clojure 名称空间,因为 new-cascadeclassifier 函数已经在核心名称空间中。
如果 xml 文件在文件系统上,那么可以用
(def detector (new-cascadeclassifier "resources/lbpcascade_frontalface.xml"))
如果 xml 作为资源存储在 jar 文件中,那么可以用
(def detector (new-cascadeclassifier (.getPath (clojure.java.io/resource "lbpcascade_frontalface.xml"))))
需要绘制由分类器找到的矩形对象。分类器的 detect 函数返回一个矩形列表,所以让我们编写一个函数,简单地遍历 rect 对象列表,并在每个 rect 上绘制一个蓝色的边框。
(defn draw-rects! [buffer rects] (doseq [rect (.toArray rects)] (rectangle buffer (new-point (.-x rect) (.-y rect)) (new-point (+ (.-width rect) (.-x rect)) (+ (.-height rect) (.-y rect))) rgb/blue 5)) buffer)
然后让我们定义第二个函数, find-faces! ,调用分类器上的 detectMultiScale 方法并使用 draw-rects 绘制矩形!前面定义的函数。
(defn find-faces![buffer] (let [rects (new-matofrect)] (.detectMultiScale detector buffer rects) (-> buffer (draw-rects! rects) (u/resize-by 0.7))))
我们又把所有的积木都放在这里了,现在只需要简单地调用 find-faces 就可以了!通过u/简单凸轮窗口。
(u/simple-cam-window find-faces!) And if you find yourself in Starbucks one morning on a terrace, the image could be something like Figure 4-10. Figure 4-10
Figure 4-10
安静令人印象深刻的早晨咖啡脸
抽屉!函数实际上可以是任何东西,因为你可以访问一个缓冲对象。
比如这个第二版的 draw-rects!对找到的面的矩形创建的子贴图应用不同的颜色贴图。
(defn draw-rects! [buffer rects] (doseq [r (.toArray rects)] (-> buffer (submat r) (apply-color-map! COLORMAP_COOL) (copy-to (submat buffer r)))) (put-text! buffer (str (count (.toArray rects) ) ) (new-point 30 100) FONT_HERSHEY_PLAIN 5 rgb/magenta-2 2)) And reusing the created building blocks, this gives the cool face from Figure 4-11. Figure 4-11
Figure 4-11
凉爽的早晨咖啡脸
这最后一个画人脸的例子采用第一个找到的人脸,在视频流的右边画一个大特写。
(defn draw-rects! [buffer rects] (if (> (count (.toArray rects)) 0) (let [r (first (.toArray rects)) s (-> buffer clone (submat r) (resize! (.size buffer)))] (hconcat! [buffer s])) buffer)) Obviously, Figure 4-12 will quickly get you convinced that this should really only be used for house BBQs, in order to show everyone who has been eating all the meat. Figure 4-12
Figure 4-12
同一视频窗口上的概览和特写
4.5 与基础图像的差异
问题
您想要获取一个 mat 映像,将其定义为一个基础映像,并发现对该基础映像所做的更改。
解决办法
这是一个非常短的配方,但它本身对理解后面更复杂的运动配方很有帮助。
为了创建一个图像和它的基底的 diff,我们在这里首先创建两段视频回调代码:一个将背景图片存储在 Clojure 原子中,另一个将使用该基底原子进行 diff。
然后,结果的灰色版本将通过简单的阈值函数,以准备用于附加形状识别和/或进一步处理的结果。
它是如何工作的
为了计算一个图像与另一个图像的差异,你需要两个垫子:一个用于基底,另一个是更新版本,其中有(我们希望)新的额外形状。
我们首先定义 Clojure 原子,并启动一个视频流来创建一个引用背景图像的原子。
只要 cam-window 在运行,来自视频流的最新缓冲垫就会存储在 atom 中。
(def base-image (atom nil)) (u/simple-cam-window (fn [buffer] (swap! base-image (fn[_] buffer) ) ))
一旦你对背景满意了,你可以停止 cam 窗口,用 imshow 和 atom 的一个 deref 版本检查当前存储的图片背景。
(u/imshow @base-image) This time, the image is a typical one of a busy home workplace (Figure 4-13). Figure 4-13
Figure 4-13
心形和扬声器
现在,下一步是定义一个新的流回调来使用 simple-cam-window,它将与 Clojure 原子中存储的 mat 不同。
diff 是通过 opencv 函数 absdiff 完成的,它需要三个 mat,即 diff 的两个输入和输出。
(defn diff-with-bg [buffer] (let[ output (new-mat)] (absdiff buffer @base-image output) output)) (u/simple-cam-window diff-with-bg)
显然,在开始第二个流和引入新的形状之前,您应该停止第一个记录流。
This would give something like Figure 4-14, where the added body soap is clearly being recognized. Figure 4-14
Figure 4-14
办公室里的沐浴露!
现在通常,下一步是清理显示在背景顶部的形状,方法是将差异贴图变为灰色,并在模糊后应用非常高的阈值。
; diff in gray (defn diff-in-gray [buffer] (-> buffer clone (cvt-color! COLOR_RGB2GRAY) (median-blur! 7) (threshold! 10 255 1)))
对于同一个缓冲区,我们有两个处理函数,在 Clojure 中,将它们与 comp 结合起来实际上是相当容易的,所以现在让我们尝试一下。
记住 comp 从右到左组合函数,意味着第一个被应用的函数是最右边的一个。
(u/simple-cam-window (comp diff-in-gray diff-with-bg )) See the composition result and the shape of the body soap showing in Figure 4-15. Figure 4-15
Figure 4-15
添加的形状有助于更多处理
在这里,您可以编译所有的步骤,从前面添加的 shape mat 创建一个简单的遮罩,并使用该遮罩来突出显示不同的部分。
所有这些都不奇怪,除了按位非!来电,总结在亮点——新!功能。
(defn highlight-new! [buffer] (let [output (u/mat-from buffer) w (-> buffer clone diff-with-bg (cvt-color! COLOR_RGB2GRAY) (median-blur! 7) (threshold! 10 255 1) (bitwise-not!))] (set-to output rgb/black) (copy-to buffer output w) output)) And the body soap output shows in Figure 4-16. Figure 4-16
Figure 4-16
回到沐浴露
这些溪流是在凌晨 3 点左右的严重时差中拍摄的,因此光线条件会在身体肥皂的底部产生一点噪音,但你可以通过更新遮罩以不包括桌子木材的颜色来尝试消除这种噪音。轮到你了!
4.6 寻找运动
问题
您希望识别并突出显示视频流中的移动和移动形状。
解决办法
在清理缓冲区之后,我们从累加缓冲区的浮点值开始。这是通过函数累加加权完成的。
然后,我们在缓冲区的灰色版本和计算的平均 mat 之间做一个 diff,我们检索一个 delta 的 mask mat,就像在前面的配方中快速呈现的那样。
最后,我们在 delta 上应用一个阈值,用一点膨胀清理结果,并将 mat 转换回彩色模式以显示在屏幕上。
这其实比听起来容易!
它是如何工作的
在这里,我们想在垫子上展示运动产生的三角洲。
在黑白中寻找运动
第一步是取一个缓冲区,创建一个干净的(通过模糊)灰色版本。
我们对展示这张垫子不感兴趣,而只是对它进行算术运算;我们将 mat 转换为 32 位浮点 mat,或者用 opencv 语言 CV_32F 。
(defn gray-clean! [buffer] (-> buffer clone (cvt-color! COLOR_BGR2GRAY) (gaussian-blur! (new-size 3 3) 0) (convert-to! CV_32F)))
此功能将用于准备灰色版本的垫子。现在让我们来计算累计平均值以及平均值和最近缓冲区之间的差值。
我们将创建另一个函数, find-movement ,它将以黑白方式突出显示图片中最近的移动。
该函数将获得一个 Clojure 原子, avg ,作为跟踪视频传入 mat 对象平均值的参数。第二个参数是传递给回调的常用缓冲垫。该功能将显示帧增量。
在第一个 if 开关中,我们确保存储在 atom 中的 average mat 用来自传入流的适当值进行初始化。
然后使用 absdiff 计算 diff,我们在其上应用一个短的 threshold-explain-CVT-color 流水线来直接显示运动。
(defn find-movement [ avg buffer] (let [gray (gray-clean! buffer) frame-delta (new-mat)] (if (nil? @avg) (reset! avg gray)) ; compute the absolute diff on the weighted average (accumulate-weighted gray @avg 0.05 (new-mat)) (absdiff gray @avg frame-delta) ; apply threshold and convert back to RGB for display (-> frame-delta (threshold! 35 255 THRESH_BINARY) (dilate! (new-mat)) (cvt-color! COLOR_GRAY2RGB) (u/resize-by 0.8))))
我们最后定义一个函数,用一个内嵌的 Clojure 原子包装 find-movement 函数。该原子将包含 mat 对象的平均值。
(def find-movements! (partial find-movement (atom nil)))
是时候用 u/simple-cam-window 来实现这些功能了。
(u/simple-cam-window find-movements!) This is shown in Figure 4-17. Figure 4-17
Figure 4-17
检测到移动!
我们想在这里显示运动,但因为打印所需的黑色墨水量会吓到出版商,所以让我们添加一个按位运算来进行黑白转换,看看实时进展如何。
让我们用一个按位非来更新查找移动函数!呼叫框架-三角垫。在此之前,我们需要使用 opencv 的 convert-to 将矩阵转换回我们可以处理的内容。函数,类型 target CV_8UC3,这是我们通常使用的。
(defn find-movement [ avg buffer] (let [gray (gray-clean! buffer) frame-delta (new-mat)] ... (-> frame-delta (threshold! 35 255 THRESH_BINARY) (dilate! (new-mat)) (convert-to! CV_8UC3) (bitwise-not!) (cvt-color! COLOR_GRAY2RGB) (u/resize-by 0.8)))) Good; let’s call simple-cam again. Wow. Figure 4-18 now looks a bit scary. Figure 4-18
Figure 4-18
可怕的黑白运动
And if you stop getting agitated in front of your computer, the movement highlights are stabilizing and slowly moving to a fully white mat, as shown in the progression of Figure 4-19. Figure 4-19
Figure 4-19
稳定运动
查找并绘制轮廓
在这个阶段,很容易找到并绘制轮廓来突出显示原始彩色缓冲区上的运动。
让我们来看看你做的漂亮的运动垫的轮廓。
在查找移动函数中增加了几行,特别是在 delta mat 上查找轮廓和在 color mat 上绘图。
在前一章中,您已经看到了所有这些寻找轮廓的动作,所以让我们来看看更新后的代码。
(defn find-movement [ avg buffer] (let [ gray (base-gray! buffer) frame-delta (new-mat) contours (new-arraylist)] (if (nil? @avg) (reset! avg gray)) (accumulate-weighted gray @avg 0.05 (new-mat)) (absdiff gray @avg frame-delta) (-> frame-delta (threshold! 35 255 THRESH_BINARY) (dilate! (new-mat)) (convert-to! CV_8UC3) (find-contours contours (new-mat) RETR_EXTERNAL CHAIN_APPROX_SIMPLE)) (-> frame-delta (bitwise-not!) (cvt-color! COLOR_GRAY2RGB) (u/resize-by 0.8)) (-> buffer ; (u/draw-contours-with-rect! contours ) (u/draw-contours-with-line! contours) (u/resize-by 0.8)) (hconcat! [frame-delta buffer]) )) Calling this new version of the find-movement function gives something like Figure 4-20, but you can probably be way more creative from there. Figure 4-20
Figure 4-20
用蓝色突出显示移动部件
4.7 使用 Grabcut 将前景与背景分离
问题
Grabcut 是另一种 opencv 方法,可用于将图像的前景与背景分开。但它能像在视频流上一样实时使用吗?
解决办法
确实有一个抓取-剪切功能,可以轻松地将正面与背景分开。这个函数只需要一点点的理解就可以看到它运行所需要的不同的遮罩,所以我们将首先关注于理解静止图像上的事情是如何工作的。
然后,我们将继续讨论实时流解决方案。这将很快导致速度问题,因为抓取-剪切比实时处理花费更多的时间。
因此,我们将使用一个小技巧,通过调低工作区的分辨率来将 grab-cut 所用的时间降到最低;然后,我们将在执行其余处理时使用全分辨率,产生一个 grabcut。
它是如何工作的
在静止图像上
这里我们想调用 grabcut,将一个深度的图层从其他图层中分离出来。
grabcut 的想法是准备在输入图片上使用矩形或遮罩,并将其传递给 grabcut 函数。
存储在单个输出掩膜中的结果将包含一组 1.0、2.0 或 3.0 标量值,具体取决于 grabcut 认为哪些是每个不同图层的一部分。
然后我们使用 opencv 比较这个遮罩和我们想要检索的层的标量值的另一个固定的 1×1 遮罩上的。我们只为感兴趣的层获得一个掩模。
最后,我们使用步骤 2 中创建的蒙版在输出垫上复制原始图像。
准备好了吗?让我们举一个猫的例子。
首先,我们加载一个我们非常喜欢的猫图片,并将其转换为一个合适的工作大小的 mat 对象。
(def source "resources/chapter03/ai6.jpg") (def img (-> source imread (u/resize-by 0.5))) The loaded cat picture is shown in Figure 4-21. Figure 4-21
Figure 4-21
给你一个猫吻
然后,我们定义一个 mask mat,它将接收 grabcut 调用的输出,即关于图层信息的每像素信息。
我们还为感兴趣的区域(ROI)定义了一个矩形,我们希望在这个矩形中执行 grabcut,这里几乎是完整的图片,大部分只是删除了边界。
(def mask (new-mat)) (def rect (new-rect (new-point 10 10) (new-size (- (.width img) 30) (- (.height img) 30 ))))
现在我们有了 grabcut 所需的所有输入,让我们用掩码、ROI 和 grabcut 初始化参数来调用它,这里是 GC_INIT_WITH_RECT。另一个可用的方法是使用 GC_INIT_WITH_MASK ,正如您可能已经猜到的,它是用 MASK 而不是 rect 初始化的。
(grab-cut img mask rect (new-mat) (new-mat) 11 GC_INIT_WITH_RECT)
Grabcut 已被调用。为了了解输出中检索到的内容,让我们快速查看一下 mask 的一个小 submat 上的矩阵内容。
(dump (submat mask (new-rect (new-point 10 10) (new-size 5 5))))
如果你亲自尝试,你会看到这样的价值观
[2 2 2 2 2] [2 2 2 2 2] [2 2 2 2 2] [2 2 2 2 2] [2 2 2 2 2]
mat 中其他地方的另一个 submat 转储给出了不同的结果:
(dump (submat mask (new-rect (new-point 150 150) (new-size 5 5))))
反过来,这给了
[3 3 3 3 3] [3 3 3 3 3] [3 3 3 3 3] [3 3 3 3 3] [3 3 3 3 3]
我们可以从这个不同的矩阵中猜测出层是不同的。
这里的想法是检索由所有相同值组成的遮罩,所以现在让我们从第 3 层中包含的所有像素创建一个遮罩,这意味着它们由 3.0 值组成。
我们称之为 fg-mask,前景遮罩。
(def fg-mask (clone mask)) (def source1 (new-mat 1 1 CV_8U (new-scalar 3.0))) (compare mask source1 fg-mask CMP_EQ) (u/mat-view fg-mask) The cat foreground mask is shown in Figure 4-22. Figure 4-22
Figure 4-22
前景遮罩
然后,我们可以使用复制到原始输入图像,并在与输入相同大小的新黑色垫上使用 fg-mask。
(def fg_foreground (-> img (u/mat-from) (set-to rgb/black))) (copy-to img fg_foreground fg-mask) (u/mat-view fg_foreground) And we get the mat of Figure 4-23. Figure 4-23
Figure 4-23
只有猫吻的前景
请注意,我们是如何得到两只小猫相互交配的近似结果的,但总的来说,结果是相当有效的。
在继续之前,让我们通过聚焦在标量值为 2.0 的层上来快速检索互补蒙版,即背景蒙版。
首先,我们再次创建一个掩码来接收输出,这次是 bg-mask 。
(def bg-mask (clone mask)) (def source2 (new-mat 1 1 CV_8U (new-scalar 2.0))) (compare mask source2 bg-mask CMP_EQ) (u/mat-view bg-mask) The result for the background mask is shown in Figure 4-24. Figure 4-24
Figure 4-24
背景遮罩
然后,简单地复制一个类似的前景。
(def bg_foreground (-> img (u/mat-from) (set-to (new-scalar 0 0 0)))) (copy-to img bg_foreground bg-mask) (u/mat-view bg_foreground) And the result is shown in Figure 4-25. Figure 4-25
Figure 4-25
背景层的 Mat
既然你已经看到了如何分离静止图像上的不同层,让我们继续视频流。
在视频流上
您可能已经注意到,前面示例中的 grabcut 步骤非常慢,主要是因为为了实现不同层的清晰分离而进行了大量繁重的计算。但是有多糟糕呢?
让我们快速尝试一下第一个哑版本的实时 grabcut。
我们将调用这个函数在前面- 慢,基本上只是在一个函数中编译我们刚刚在静态例子中看到的步骤。
(defn in-front-slow [buffer] (let [ img (clone buffer) rect (new-rect (new-point 5 5) (new-size (- (.width buffer) 5) (- (.height buffer) 5 ))) mask (new-mat) pfg-mask (new-mat) source1 (new-mat 1 1 CV_8U (new-scalar 3.0)) pfg_foreground (-> buffer (u/mat-from) (set-to rgb/black))] (grab-cut img mask rect (new-mat) (new-mat) 7 GC_INIT_WITH_RECT) (compare mask source1 pfg-mask CMP_EQ) (copy-to buffer pfg_foreground pfg-mask) pfg_foreground))
然后,让我们使用这个函数作为对我们现在熟悉的 u/simple-cam-window 的回调。
(u/simple-cam-window in-front-slow) This slowly gives the output seen in Figure 4-26. Figure 4-26
Figure 4-26
慢点,慢点,慢点
您很快就会意识到,这不像在视频流中那样非常有用。
这里的技巧实际上是降低输入缓冲区的分辨率,在分辨率较低的 mat 上进行 grabcut,并获得 grabcut 掩码。然后,使用全尺寸图片和从 grabcut 获取的低分辨率蒙版进行复制。
这一次,我们将创建一个前置函数,这将是前面的一个略微更新的版本,但是现在包括一个围绕 grabcut 调用的 pyr-down-pyr-up 舞蹈(图 4-27 )。
为了使这更容易,我们将设置舞蹈的迭代次数作为回调的参数。
(defn in-front [resolution-factor buffer] (let [ img (clone buffer) rect (new-rect (new-point 5 5) (new-size (- (.width buffer) 5) (- (.height buffer) 5 ))) mask (new-mat) pfg-mask (new-mat) source1 (new-mat 1 1 CV_8U (new-scalar 3.0)) pfg_foreground (-> buffer (u/mat-from) (set-to (new-scalar 0 0 0)))] (dotimes [_ resolution-factor] (pyr-down! img)) (grab-cut img mask rect (new-mat) (new-mat) 7 GC_INIT_WITH_RECT) (dotimes [_ resolution-factor] (pyr-up! mask)) (compare mask source1 pfg-mask CMP_EQ) (copy-to buffer pfg_foreground pfg-mask) pfg_foreground))
然后,用这个新的回调函数调用 simple-cam-window。
(u/simple-cam-window (partial in-front 2))
仅仅通过阅读是很难获得速度感的,所以一定要在本地尝试一下。
Usually, a factor of 2 for the resolution-down dance is enough, but it depends on both your video hardware and the speed of the underlying processor. Figure 4-27
Figure 4-27
想多快就多快,宝贝
4.8 实时寻找橙子
问题
你想检测和跟踪视频流中的桔子。它也可以是一个柠檬,但是作者用完了柠檬,所以我们将使用一个橙子。
解决办法
在这里,我们将使用你以前见过的技术,像霍夫圆或寻找轮廓,并将它们应用于实时流。我们将在实时流上绘制移动的橙子的形状。
对于这两种解决方案,您可能还记得缓冲区需要一些小的预处理来检测橙色。这里,为了简单起见,我们将在 hsv 颜色空间中进行简单的范围内处理。
它是如何工作的
使用霍夫圆
首先,我们将通过拍摄橙子的一张照片来集中寻找合适的 hsv 范围。
First, let’s put the orange on the table (Figure 4-28). Figure 4-28
Figure 4-28
餐桌上的橘子,法国安纳西
我们首先切换到 hsv 颜色空间,然后应用范围内函数,最后将找到的橙色形状放大一点,以便更容易进行霍夫圆调用。
在 Origami 艺术中,这给了
(def hsv (-> img clone (cvt-color! COLOR_RGB2HSV))) (def thresh-image (new-mat)) (in-range hsv (new-scalar 70 100 100) (new-scalar 103 255 255) thresh-image) (dotimes [_ 1] (dilate! thresh-image (new-mat)))
现在,你会记得如何从第三章开始做霍夫循环,所以这里不需要花太多时间。这一部分最重要的是要有合适的半径范围,这里我们用 10-50 像素的直径来识别橙色。
(def circles (new-mat)) (def minRadius 10) (def maxRadius 50) (hough-circles thresh-image circles CV_HOUGH_GRADIENT 1 minRadius 120 15 minRadius maxRadius)
在这个阶段,你应该只有一个橙色的匹配圆。这一步非常重要,直到找到一个圆。
作为检查,打印圆形垫应得到 1×1 垫,如下所示:
object[org.opencv.core.Mat 0x3547aa31 Mat [ 11CV_32FC3, isCont=true, isSubmat=false, nativeObj=0x7ff097ca7460, dataAddr=0x7ff097c4b980 ]]
一旦你把垫子钉好了,让我们在原图上画一个粉红色的圆圈(图 4-29 )。
(def output (clone img)) (dotimes [i (.cols circles)] (let [ circle (.get circles 0 i) x (nth circle 0) y (nth circle 1) r (nth circle 2) p (new-point x y)] (opencv3.core/circle output p (int r) color/ color/magenta- 3)))  Figure 4-29
Figure 4-29
橙色和洋红色
所有的东西都在那里,所以让我们把我们的发现作为一个单一的函数来处理来自视频流的缓冲区;我们称这个函数为 my-orange!,是前面步骤的回顾。
(defn my-orange! [img] (u/resize-by img 0.5) (let [ hsv (-> img clone (cvt-color! COLOR_RGB2HSV)) thresh-image (new-mat) circles (new-mat) minRadius 10 maxRadius 50 output (clone img)] (in-range hsv (new-scalar 70 100 100) (new-scalar 103 255 255) thresh-image) (dotimes [_ 1] (dilate! thresh-image (new-mat))) (hough-circles thresh-image circles CV_HOUGH_GRADIENT 1 minRadius 120 15 minRadius maxRadius) (dotimes [i (.cols circles)] (let [ circle (.get circles 0 0) x (nth circle 0) y (nth circle 1) r (nth circle 2) p (new-point x y)] (opencv3.core/circle output p (int r) color/magenta- 3))) output))
现在只需再次将回调函数传递给简单的 cam 窗口。
(u/simple-cam-window my-orange!) Figures 4-30 and 4-31 show how the orange is found properly, even in low-light conditions. Winter in the French Alps after a storm did indeed make the evening light, and everything under it, a bit orange. Figure 4-30
Figure 4-30
打印机上的橙色
 Figure 4-31
Figure 4-31
梅和橘子
使用查找轮廓
不是寻找一个完美的圆,你可能会寻找一个稍微扭曲的形状,这是当使用查找轮廓实际上比霍夫圆给出更好的结果。
这里,我们结合几分钟前发现的相同 hsv 范围来选择橙色,并应用第三章中的轮廓查找技术。
寻找我的橘子!回调带回了熟悉的查找轮廓和绘制轮廓函数调用。请注意,只有当找到的形状比预期的最小橙子大时,我们才绘制它们的轮廓。
(defn find-my-orange! [img ] (let[ hsv (-> img clone (cvt-color! COLOR_RGB2HSV)) thresh-image (new-mat) contours (new-arraylist) output (clone img)] (in-range hsv (new-scalar 70 100 100) (new-scalar 103 255 255) thresh-image) (find-contours thresh-image contours (new-mat) ; mask RETR_LIST CHAIN_APPROX_SIMPLE) (dotimes [ci (.size contours)] (if (> (contour-area (.get contours ci)) 100 ) (draw-contours output contours ci color/pink-1 FILLED))) output)) Giving this callback to simple-cam-window shows Mei playing around with a pink-colored orange in Figure 4-32. Figure 4-32
Figure 4-32
梅和粉橙,在附近的剧院演出
4.9 在视频流中查找图像
问题
您希望在流中找到图像的精确副本。
解决办法
OpenCV 附带了您可以使用的特性检测功能。不幸的是,这些特性大多是面向 Java 的。
这个菜谱将展示如何在 Java 和 Origami 之间架起桥梁,以及使用 Clojure 如何通过减少样板代码有所帮助。
Here we will use three main OpenCV objects :
-
特征检测器,
-
DescriptorExtractor,
-
描述符匹配器。
特征提取通过使用特征检测器找到输入图片和待发现图像的关键点来工作。然后,使用描述符提取器从两组点中的每一组计算描述符。
一旦有了描述符,就可以将这些描述符作为输入传递给描述符匹配器,描述符匹配器给出一组匹配结果,每个匹配都通过一个距离属性给出一个分数。
然后,我们最终可以筛选出最相关的点,并将它们画在流上。
代码清单比通常要长一点,但是让我们把最后一个方法也用在您的机器上吧!
它是如何工作的
在这个例子中,我们将在静态图像和实时图像中寻找我最喜欢的沐浴露,桉树香水。
Figure 4-33 shows the concerned body soap. Figure 4-33
Figure 4-33
小马赛人
静止图像
The first test is to be able to find the body soap in a simple still picture, like the one in Figure 4-34. Figure 4-34
Figure 4-34
卡门,我的沐浴露在哪里?
首先,我们还需要几个 Java 对象导入,即检测器和提取器,我们将在进行任何处理之前直接初始化它们。
(ns wandering-moss (:require [opencv3.core :refer :all] [opencv3.utils :as u]) (:import [org.opencv.features2d Features2d DescriptorExtractor DescriptorMatcher FeatureDetector])) (def detector (FeatureDetector/create FeatureDetector/AKAZE)) (def extractor (DescriptorExtractor/create DescriptorExtractor/AKAZE))
基本设置完成;然后,我们通过一个短的 Origami 流水线加载人体肥皂背景,并要求检测器检测其上的点。
(def original (-> "resources/chapter04/bodysoap_bg.png" imread (u/resize-by 0.3))) (def mat1 (clone original)) (def points1 (new-matofkeypoint)) (.detect detector mat1 points1)
接下来的步骤并不是必须的,但是画出找到的关键点可以让我们知道匹配者认为重要的点在哪里。
(def show-keypoints1 (new-mat)) (Features2d/drawKeypoints mat1 points1 show-keypoints1 (new-scalar 255 0 0) 0) (u/mat-view show-keypoints1) This gives a bunch of blue circles, as shown in Figure 4-35. Figure 4-35
Figure 4-35
沐浴露背景要点
当然,在检索关键点之前清理和移除缺陷可能是有用的,但是让我们检查一下匹配是如何在 raw mat 上工作的。
注意点的强度在身体肥皂本身上已经相当强了。
我们现在对仅含沐浴露的垫子重复同样的步骤。
(def mat2 (-> "resources/chapter04/bodysoap.png" imread (u/resize-by 0.3))) (def points2 (new-matofkeypoint)) (.detect detector mat2 points2)
同样,这个绘图点部分不是必需的,但它有助于更好地理解正在发生的事情。
(def show-keypoints2 (new-mat)) (Features2d/drawKeypoints mat2 points2 show-keypoints2 (new-scalar 255 0 0) 0) (u/mat-view show-keypoints2) The detector result is in Figure 4-36, and again, the keypoints look to be focused on the label of the body soap. Figure 4-36
Figure 4-36
香皂的检测结果
下一步是提取两个特征集,然后用于匹配器。
这只是用上一步中找到的点集在提取器上调用 compute 的问题。
(def desc1 (new-mat)) (.compute extractor mat1 points1 desc1) (def desc2 (new-mat)) (.compute extractor mat2 points2 desc2)
现在,进入匹配步骤。我们通过 DescriptorMatcher 创建一个匹配器,并给它一个找出匹配的方法。
在这种情况下,强力总是寻找解决方案的推荐方法。尝试每一种解决方案,看看是否有匹配的。
(def matcher (DescriptorMatcher/create DescriptorMatcher/BRUTEFORCE_HAMMINGLUT)) (def matches (new-matofdmatch)) (.match matcher desc1 desc2 matches)
正如解决方案摘要中所述,每个匹配都是通过其距离值来评定的。
如果打印出来,每个匹配看起来如下所示:
object[org.opencv.core.DMatch 0x38dedaa8 "DMatch [queryIdx=0, trainIdx=82, imgIdx=0, distance=136.0]"]
对于距离值,匹配本身的分数通常显示为 0 到 300 之间的值。
所以现在,让我们创建一个快速的 Clojure 函数来排序和过滤好的匹配。这可以简单地通过过滤它们的距离属性来实现。我们将过滤低于 50 的匹配。根据录制的质量,您可以根据需要减少或增加该值。
(defn best-n-dmatches2[dmatches] (new-matofdmatch (into-array org.opencv.core.DMatch (filter #(< (.-distance %) 50) (.toArray dmatches)))))
draw-matches 方法是一场编码噩梦,但它可以被看作是 OpenCV 中噩梦般的 drawMatches Java 方法的包装。
我们通常使用 Java interop 和对每个参数的一些清理来传递参数。我们还创建了更大的输出 mat,这样我们可以将背景图片和人体肥皂放在同一个 mat 上。
(defn draw-matches [_mat1 _points1 _mat2 _points2 _matches] (let[ output (new-mat (* 2 (.rows _mat1)) (* 2 (.cols _mat1)) (.type _mat1)) _sorted-matches (best-n-dmatches2 _matches)] (Features2d/drawMatches _mat1 _points1 _mat2 _points2 _sorted-matches output (new-scalar 255 0 0) (new-scalar 0 0 255) (new-matofbyte) Features2d/NOT_DRAW_SINGLE_POINTS) output))
现在,有了所有这些,我们可以使用前面的函数绘制匹配器找到的匹配。
我们将第一个和第二个垫子,以及它们各自找到的关键点和匹配集传递给它。
(u/mat-view (draw-matches mat1 points1 mat2 points2 matches)) This, surprisingly after all the obscure coding, works very well, as shown in Figure 4-37. Figure 4-37
Figure 4-37
绘画比赛
视频流
与你刚刚经历的相比,视频流版本会让你感觉像呼吸了一口新鲜空气。
我们将创造一个我的身体在哪里的肥皂!函数将重用前面定义的匹配器,并在缓冲垫上的流回调中运行检测器、提取器和匹配。
之前定义的 draw-matches 函数也被重用来绘制实时流上的匹配。
(defn where-is-my-body-soap! [buffer] (let[ mat1 (clone buffer) points1 (new-matofkeypoint) desc1 (new-mat) matches (new-matofdmatch)] (.detect detector mat1 points1) (.compute extractor mat1 points1 desc1) (.match matcher desc1 desc2 matches) (draw-matches mat1 points1 mat2 points2 matches)))
你可以用这个回调函数来调用 simple-cam-window,但是……啊!似乎梅在配方特征检测可以运行之前已经找到了沐浴露!
Figure 4-38 shows both on the video stream. Figure 4-38
Figure 4-38
谢谢你找到沐浴露,梅!
这使得这份食谱,这一章,这本书的卑微的结束。我们真的希望这给了你很多想法,让你通过玩 Origami 框架来尝试,并为你的创作带来光明。
For now, “Hello Goodnight”:
搜索天空
我发誓我看到影子 坠落
可能是幻觉
一声暗藏的警告
名声将永远让我欲罢不能
想要
好了,没事了
我一直很好
你好你好晚安
妈妈枪“你好晚安”