1、边缘检测示例(Edge Detection Example)
卷积运算(convolutional operation)是卷积神经网络最基本的组成部分,使用边缘检测(edge detection)作为入门样例。接下来,你会看到卷积是如何进行运算的。

在之前的人脸例子中,我们知道神经网络的前几层是如何检测边缘的,然后,后面的层有可能检测到物体的部分区域,更靠后的一些层可能检测到完整的物体。图片下方给了这样一张图片,让电脑去搞清楚这张照片里有什么物体,你可能做的第一件事是检测图片中的垂直边缘(vertical edges)和水平边缘(horizontal edges)。所以如何在图像中检测这些边缘?


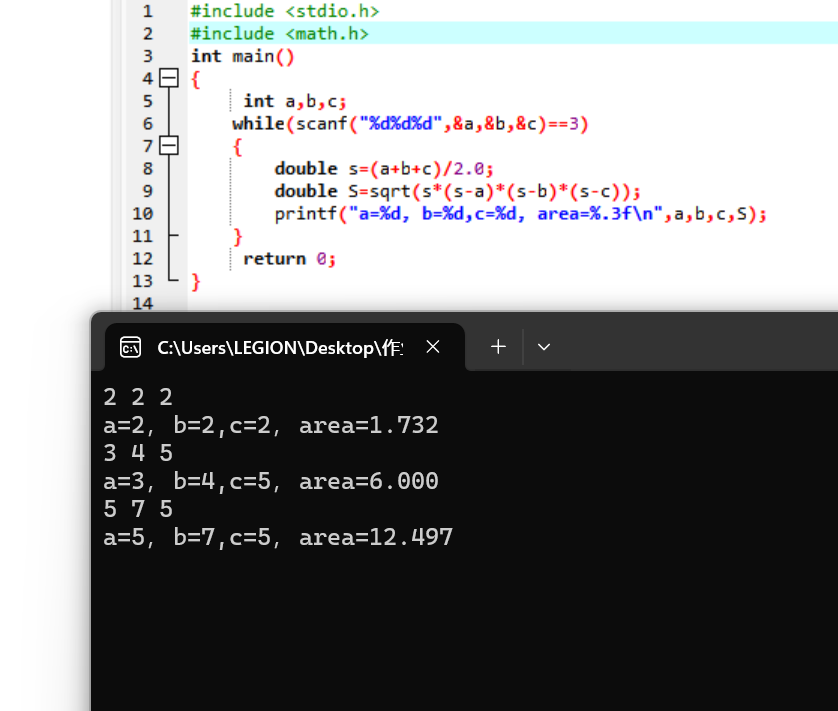
这是一个6×6的灰度图像(grayscale image)。因为是灰度图像,所以它是6×6×1的矩阵,为了检测图像中的垂直边缘,需要构造一个3×3矩阵。在共用习惯中,在卷积神经网络的术语中,它被称为过滤器(filter),也被称为核(kernel)。对这个6×6的图像进行卷积运算,卷积运算用星号“*”(在不同语言和框架中表示方法不一致)来表示,用3×3的过滤器对其进行卷积。
在过滤器覆盖的区域执行:每个元素对应相乘再求和,这个卷积运算的输出将会是一个4×4的矩阵,这个就是垂直边缘检测器。在图二中这个6×6图像的中间部分,明亮的像素在左边,深色的像素在右边,就被视为一个垂直边缘,卷积运算提供了一个方便的方法来发现图像中的垂直边缘。
2、更多边缘检测内容
如何区分正边和负边,这实际就是由亮到暗(light to dark)与由暗到亮(dark to light)的区别,也就是边缘的过渡(edge transitions)。

这张6×6的图片,左边较亮,而右边较暗,将它与垂直边缘检测滤波器进行卷积,检测结果就显示在了右边这幅图的中间部分。现在将图片进行翻转,变成了左边比较暗,右边比较亮。从结果可以看到这个过滤器确实可以区分这两种明暗变化的区别。

总而言之,对于这个3×3的过滤器(左边)来说,这是其中的一种数字组合。也可以使用Sobel过滤器(中间),它的优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。或者Scharr过滤器(右边),它有着和之前完全不同的特性,实际上也是一种垂直边缘检测。
随着深度学习的发展,我们学习的其中一件事就是当你真正想去检测出复杂图像的边缘,你不一定要去使用那些研究者们所选择的这九个数字,但你可以从中获益匪浅。把这矩阵中的9个数字当成9个参数,并且在之后你可以学习使用反向传播算法,其目标就是去理解这9个参数。
3、Padding
为了构建深度神经网络,你需要学会使用的一个基本的卷积操作就是padding,下面来看看它是如何工作的。

你用一个3×3的过滤器卷积一个6×6的图像,你最后会得到一个4×4的输出,也就是一个4×4矩阵。这背后的数学解释是,如果我们有一个n×n的图像,用f×f的过滤器做卷积,那么输出的维度就是(n - f + 1) × (n - f + 1)。
这样的话会有两个缺点,第一个缺点是每次做卷积操作,你的图像就会缩小。第二个缺点是那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。为了解决这两个问题,你可以在卷积操作之前填充这幅图像。在这个案例中,你可以沿着图像边缘再填充一层像素。如果你这样操作了,那么6×6的图像就被你填充成了一个8×8的图像。
习惯上,你可以用0填充,如果p表示填充的数量,在这个例子中,p=1,因为在周围都填充了一个像素点。输出维度变成了(一般向下取整):(n + 2p - f + 1) × (n + 2p - f + 1)。这样一来,丢失信息或者更准确来说角落或图像边缘的信息发挥的作用较小的这一缺点就被削弱了。

如果你想的话,也可以填充两个像素点。至于选择填充多少像素,通常有两个选择,分别叫做Valid卷积(不填充)和Same卷积(填充后图像大小不变)。Same卷积中P是通过n+2p-f+1=n求解,p = (f - 1)/2。习惯上,计算机视觉中,f通常是奇数,甚至可能都是这样。
4、卷积步长(Strided Convolutions)
卷积中的步长(strided convolutions)是另一个构建卷积神经网络的基本操作,看下面一个例子。

如果你想用3×3的过滤器卷积这个7×7的图像,和之前不同的是,我们把步幅设置成了2。注意一下左上角,这个点移动到其后两格的点,跳过了一个位置。然后你还是将每个元素相乘并求和,你将会得到的结果是100。如果你使用一个f x f的过滤器卷积一个n x n的图像,padding为p,步幅为s,这样输出的大小变为:![]() 。
。
需要注意:如果商不是一个整数,则向下取整。这个原则实现的方式是,你只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算。
5、三维卷积(Convolutions Over Volume)
现在看看如何执行卷积不仅仅在二维(2D)图像上,而是三维立体(three dimensional volumes)上。

假如说你不仅想检测灰度图像的特征,也想检测RGB彩色图像(红、绿、蓝)的特征。彩色图像如果是6×6×3,这里的3指的是三个颜色通道(可以想象成三个6×6图像的堆叠)。为了检测图像的边缘或者其他的特征,这里跟一个三维的过滤器,它的维度是3×3×3,这样这个过滤器也有三层,对应红绿、蓝三个通道。
注意这些名字,第一个6代表图像高度(height),第二个6代表宽度(width),这个3代表通道的数目(channels)。同样过滤器(filter)也有高,宽和通道数,并且图像的通道数必须和过滤器的通道数相同。

为了计算上图中卷积操作的输出,你要做的就是把这个3×3×3的过滤器先放到最左上角的位置(upper left most position),这个3×3×3的过滤器有27个数,27个参数就是3的立方。依次取这27个数,然后乘以相应的红绿蓝通道中的数字。先取红色通道的前9个数字,然后是绿色通道,然后再是蓝色通道,乘以左边黄色立方体覆盖的对应的27个数,然后把这些数都加起来,就得到了输出的第一个数字。

当不仅仅想要检测垂直边缘时,也即想同时用多个过滤器时,如上图所示(第一个黄色表示)这可能是一个垂直边界检测器或者是学习检测其他的特征。第二个过滤器橘色表示,它可以是一个水平边缘检测器。这样的输出是一个4×4×2的立方体,这里的2的来源于用了两个不同的过滤器。
6、单层卷积网络(One Layer of a Convolutional Network)
如何构建卷积神经网络的卷积层(convolutional layer),看一个例子。

假设使用第一个过滤器进行卷积,得到第一个4×4矩阵,形成一个卷积神经网络层,然后增加偏差(bias),它是一个实数(real number),通过Python的广播机制给这16个元素都加上同一偏差。然后应用非线性函数,它是一个非线性激活函数ReLU,输出结果是一个4×4矩阵。对另一个矩阵重复上述操作,把这两个矩阵堆叠起来,最终得到一个4×4×2的矩阵。我们通过计算,从6×6×3的输入推导出一个4×4×2矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。

最后总结一下,用于描述卷积神经网络的一层,例如l层的各种标记。


输出图像中的通道数量就是神经网络中这一层所使用的过滤器的数量。因此,输出通道数量就是输入通道数量,所以过滤器维度为:

采用批量梯度下降(batch gradient descent),变量的排列顺序如下:首先是索引(index)和训练示例(training examples),然后是其它三个变量。该如何确定权重参数(weights parameters),即参数W呢?权重也就是所有过滤器的集合再乘以过滤器的总数量,即![]()
最后我们看看偏差参数(bias parameters),每个过滤器都有一个偏差参数,它是一个实数。偏差包含了这些变量,它是该维度上的一个向量。后续为了方便,偏差表示为一个的四维矩阵或四维张量,即![]()
注意:在线搜索或查看开源代码时,关于高度,宽度和通道的顺序并没有完全统一的标准卷积,有些作者会采用把通道放在首位的编码标准。实际上在某些架构中,当会有一个变量或参数来标识计算通道数量和通道损失数量的先后顺序。
7、简单卷积网络示例


在上图中,一个卷积网络通常有三层,一个是卷积层(convolution layer),我们常常用Conv来标注。一个是池化层(pooling layer),我们称之为POOL。最后一个是全连接层(fully connected layer),用FC表示。
8、池化层(Pooling Layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性,下面来看一下。

上图中池化层类型为最大池化(max pooling),执行过程非常简单,把4×4的输入拆分成不同的区域(不同区域用不同颜色来标记)。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。其主要目的是减少特征图的尺寸(降低计算复杂度),同时保留了显著的局部特征(具有一定的抗干扰性)。此方法在很多实验中效果都很好。
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。在实际操作中,一旦确定f和s,就是一个固定运算,梯度下降无需改变任何值。还有一种类型的池化,平均池化(average pooling),但是并不常用,运算时选取的不是每个过滤器的最大值,而是平均值。

现在总结一下,如上图,池化的超级参数包括过滤器大小和步幅,常用的参数值为f = 2,s = 2,应用频率非常高,其效果相当于高度和宽度缩减一半。也有使用f =3,s=2的情况。至于其它超级参数就要看你用的是最大池化还是平均池化了。最大池化时,往往很少用到超参数padding,当然也有例外的情况。假设没有padding,最大池化的输入和输出分别为:
![]()
需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数(f,s),可能是手动设置的,也可能是通过交叉验证设置的。
9、卷积神经网络示例


补充内容:人们发现在卷积神经网络文献中,卷积有两种分类,这与所谓层的划分存在一致性。(1)一类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的Layer1。(2)另一类卷积是把卷积层作为一层,而池化层单独作为一层。人们在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。
此例中的卷积神经网络很典型,看上去它有很多超参数,关于如何选定这些参数,常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
在神经网络中,另一种常见模式就是一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax。
10、为什么使用卷积?
卷积在深度学习,尤其是图像处理领域中非常常用,原因在于它带来了多方面的优势。以下是使用卷积(尤其是卷积神经网络,CNN)的主要原因和好处: