-
排序
sorted(data,reverse=True or False) -
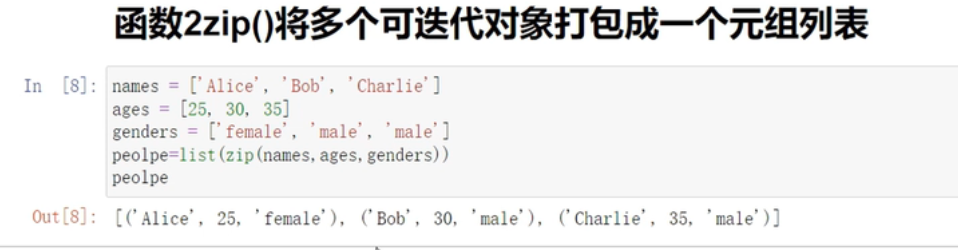
zip()将多个可迭代对象打包成一个元组列表
list or set (zip())
-
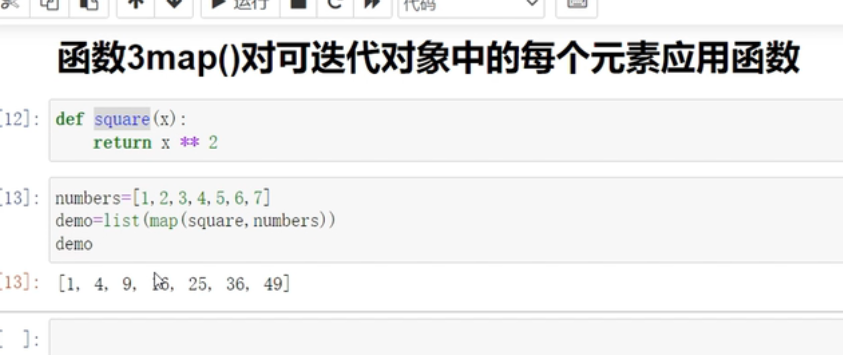
map()对可迭代对象中的每个元素应用函数
map(data,func)
-
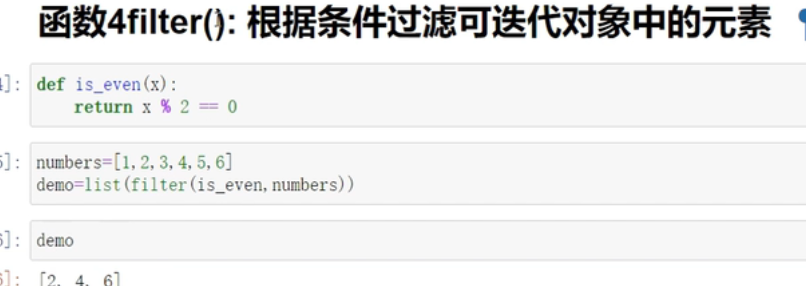
filter() 跟map类似的用法
-
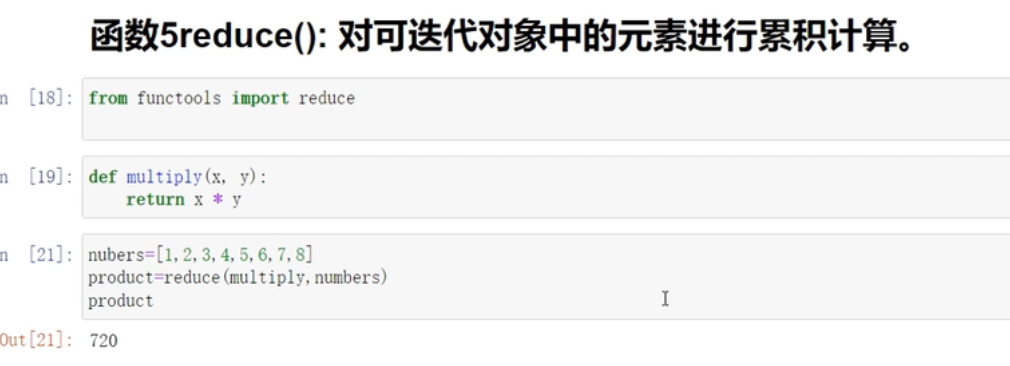
reduce()对可迭代对象中的元素进行累计计算
from functools import reduce
用法跟filter()一样
-
split()&replace()&range()&all()判断任一元素&open()打开文件&round(data)对数字四舍五入&abs(data)绝对值&find()找数据所在的索引开始位置
简单 -
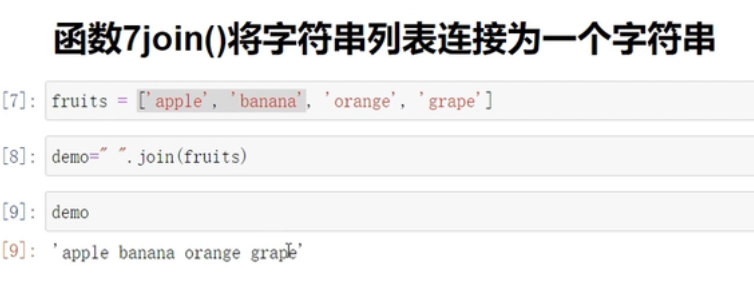
join()将字符串列表连接成一个字符串
“ ”.join(words)
-
strip()去除字符串两端的符号
默认是去除空格;可以指定
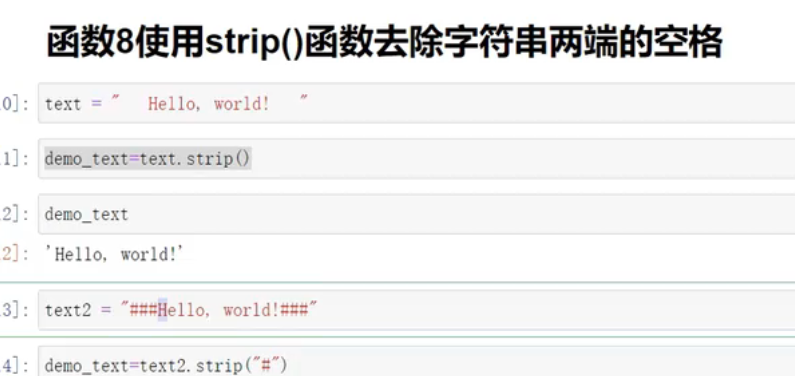
-
enumerate()枚举可迭代对象,并返回索引和元素
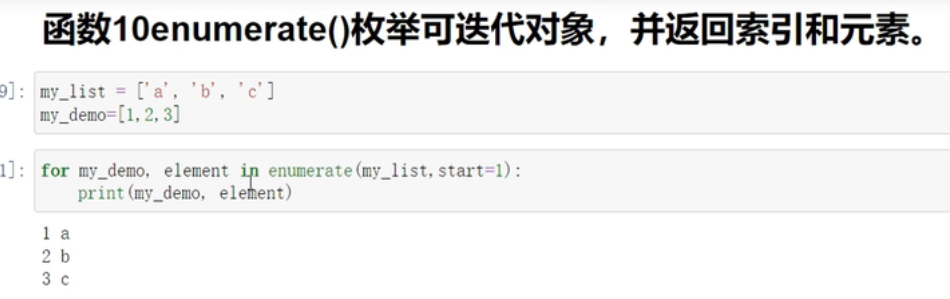
-
eval()可以执行其中的代码或者可执行表达式
result = input(eval(data)) -
reversed()反转序列
reversed(data) -
len()返回可迭代数据的长度
len(data) -
type()返回数据类型
type(data) -
lambda 表达式
lambda x : len(x) or type(x) or x**2 or eval(x) -
bytes()
有些时候,读取文件需要改变编码,这就派上用场了
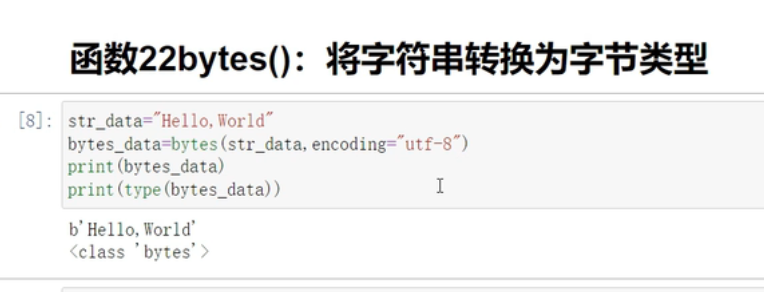
-
time库
time_now = time.time()返回当前时间的时间戳
time.ctime(time_now)可以返回可读格式的时间 -
re.findall()正则库的使用
re.findall("\w+",str) -
isinstance()判断某个数据是否是某个类型
isinstance(data,type) -
os.mkdir()创建目录
机器学习大概率用到
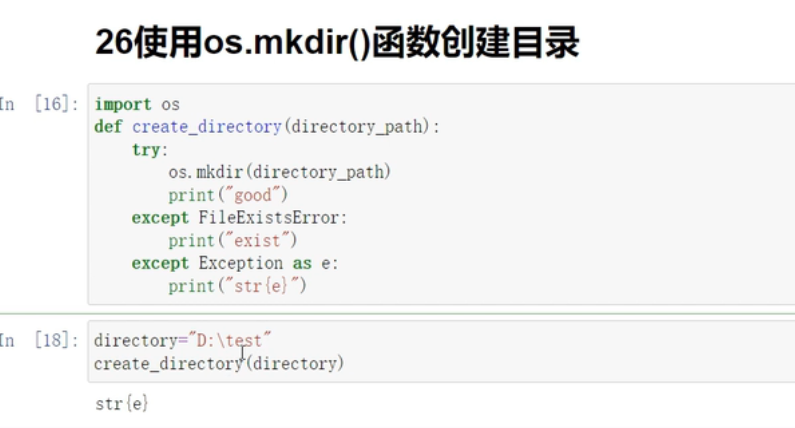
-
json库
-
requests库
对网络请求的库 -
object没说清楚
-
id(data)返回数据的内存地址
-
divmod(a,b)返回(a/b,a % b)
-
ord(data)返回data的Unicode码值
-
encode("utf-8")将使用的数据转为指定格式的数据
data.encode("utf-8") -
count()统计出现次数
data.count(数据) -
index(数据)返回索引位置,从0开始
data.index(数据) -
update更新或合并字典
dict1 = {..}
dict2 = {...}
dict1.update(dict2) -
numpy库
import numpy as np
一般使用np.array([])比直接使用【】更好,因为已经封装好了
可以直接对数字进行加减乘除;或者多个【】加减乘除;data.shape()
根据条件筛选,并且选出那些内容
np.where()找出索引
data_array > 10 是条件
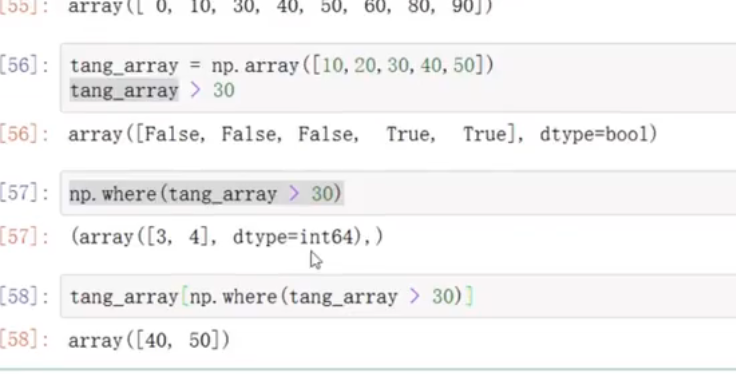
dtype指定数据的类型

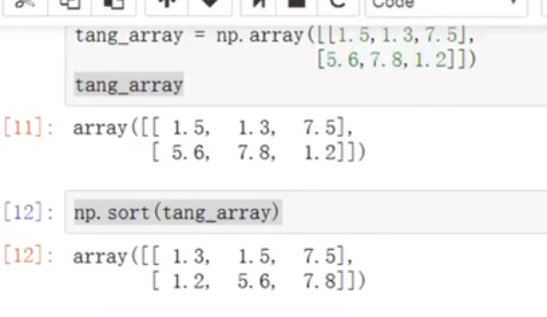
对矩阵排序,排序函数
np.sort(data_array)
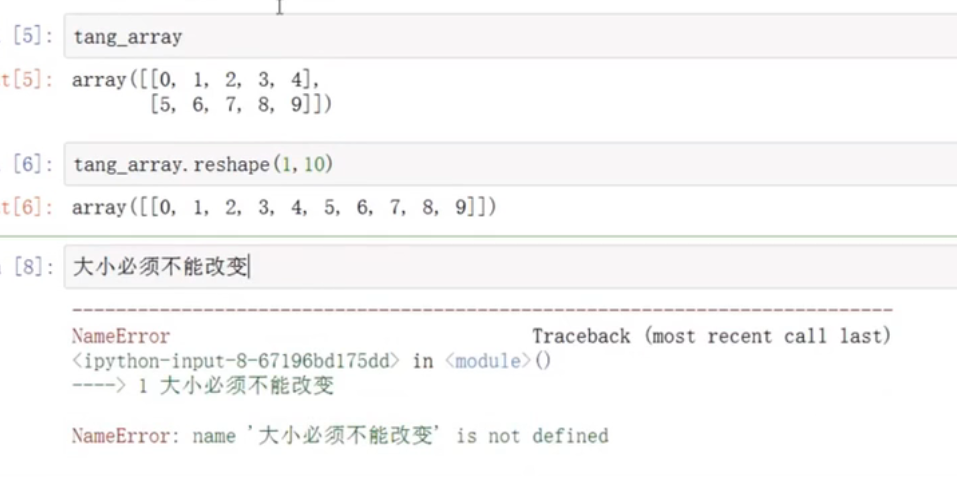
改变矩阵的形状--注意,必须一样大小
矩阵的转置
data_array.T 即可
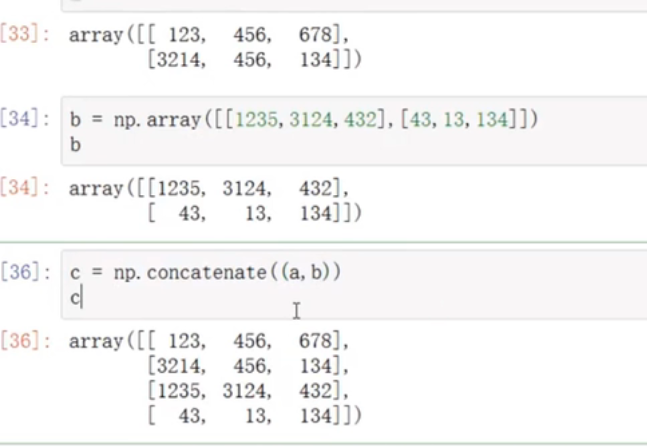
矩阵的连接或者拼接
#格式一定要正确
c = np.concatenate((a,b))
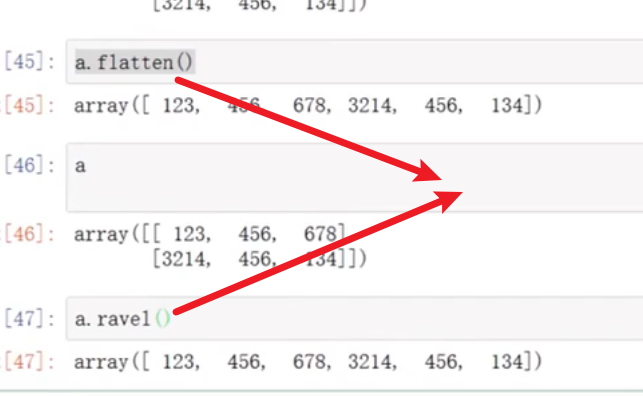
将矩阵拉成一行
array.flatten();array.ravel()
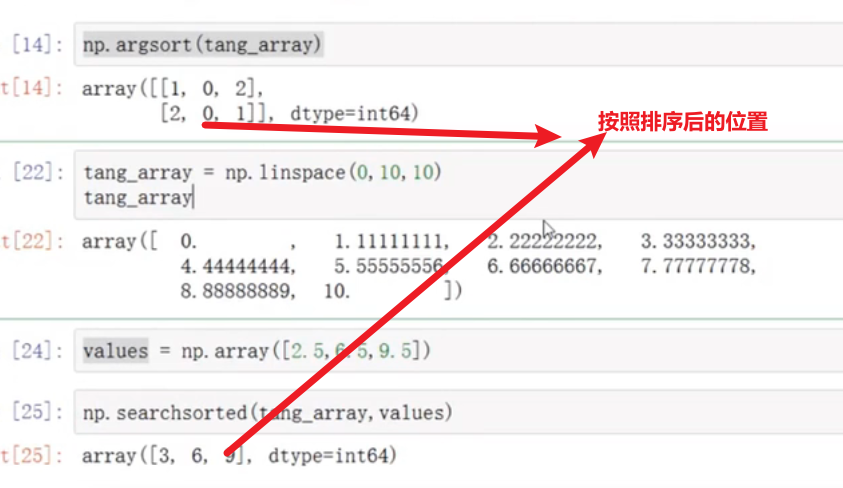
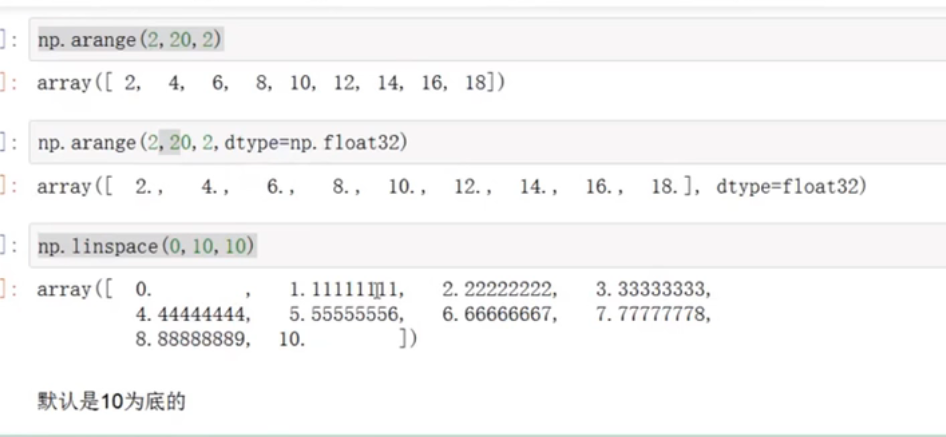
按照一定的规律生成一个数组
np.linspace(from,start,much)--从开始到结尾根据much自动等距生产数组
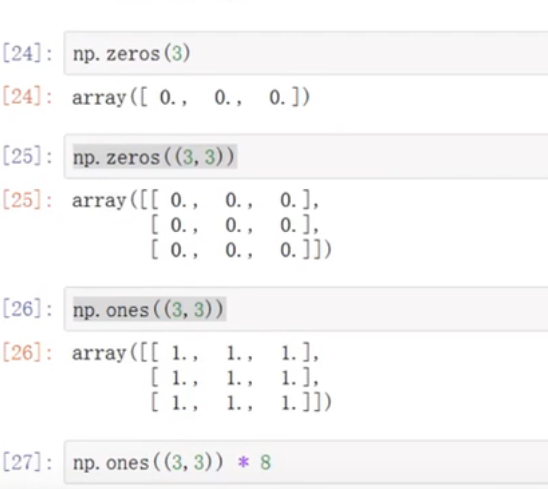
常用函数:
np.zeros()
np.ones()
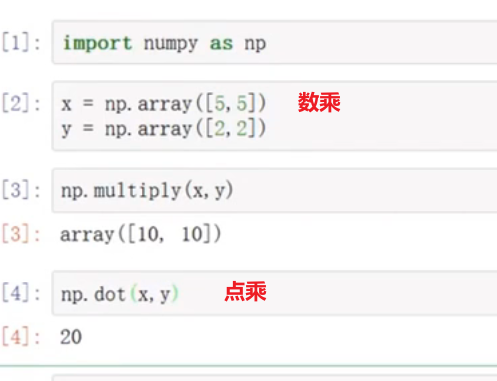
矩阵的四则运算
数乘与点乘
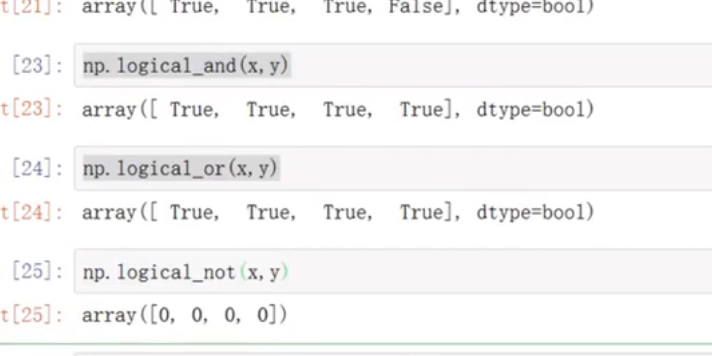
两个矩阵间的逻辑操作
& | or
np的随机模块
随机小数
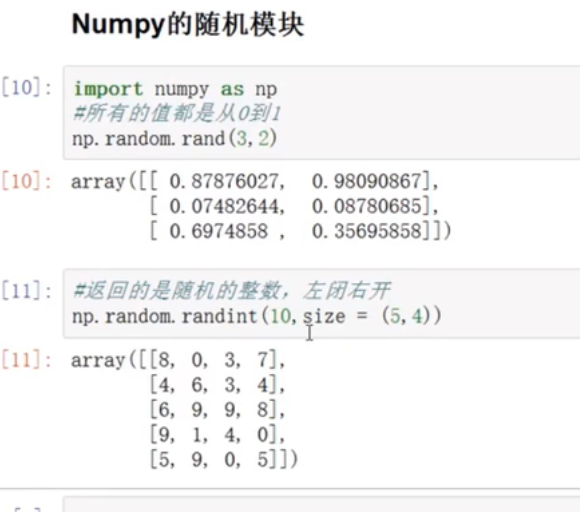
随机整数

修改随机数的精度

对数组重新随机排序

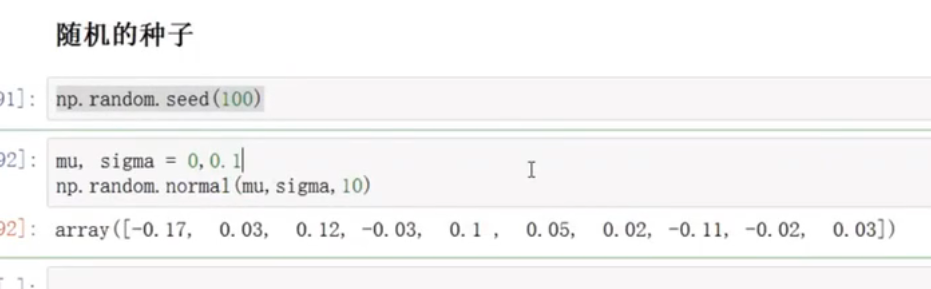
随机的种子
随机的,但每个种子下都是一样的
对文件操作——用到就查
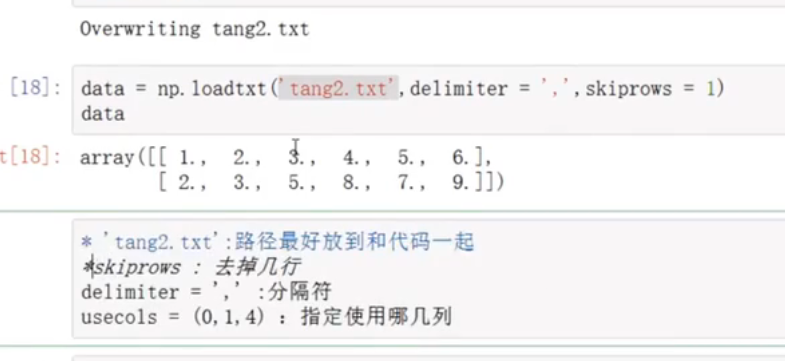
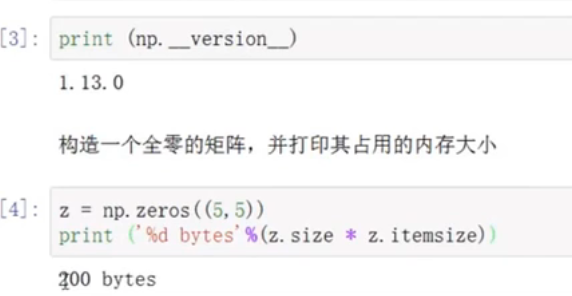
np的版本及其矩阵的内存大小
找出数组中的最大值、最小值
array.min() max()

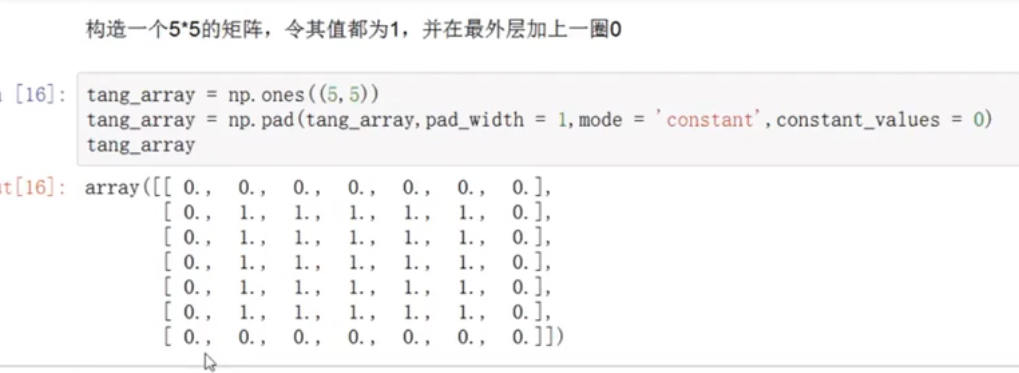
在一个矩阵的外面一圈填充指定的数字
np.pad(...)
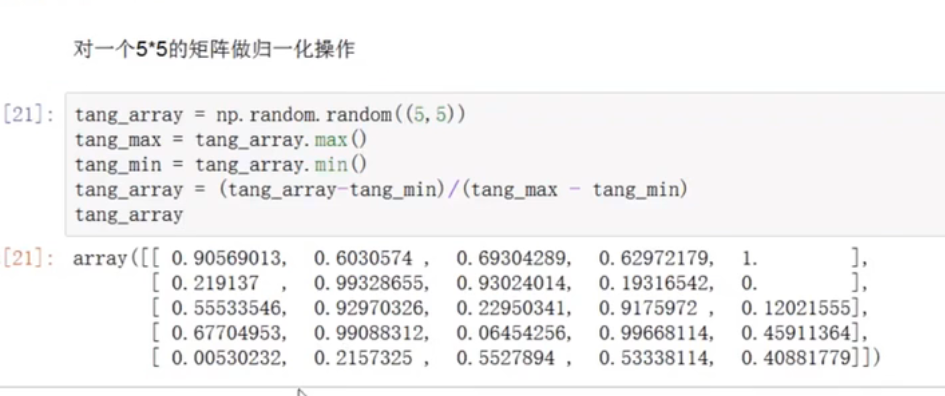
对数组进行归一化处理
矩阵数据-最小值/(max-min)就是归一化
找到数组中相同的元素
np.intersectId(z1,z2)
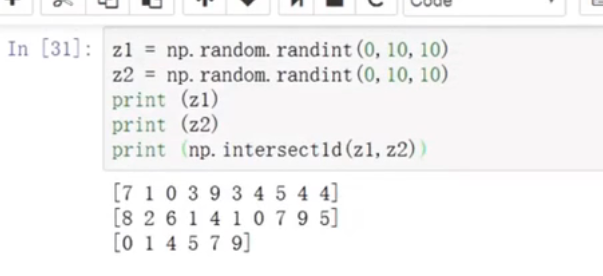
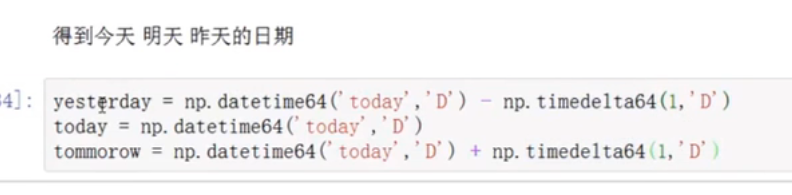
日期的相关操作
昨天、今天、明天
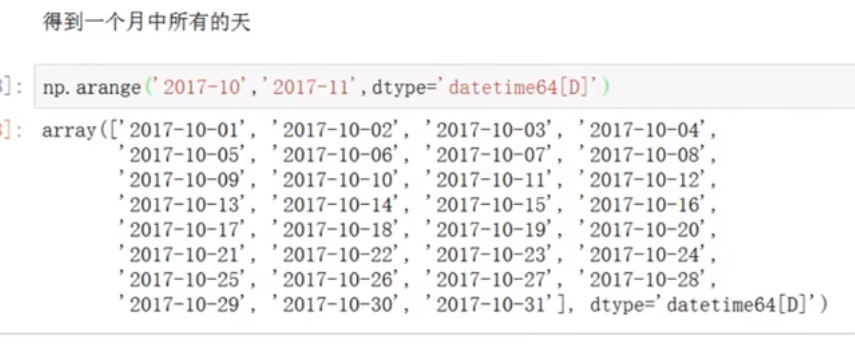
得到某个月
对小数进行取整

对数据类型进行转换
int32;float32

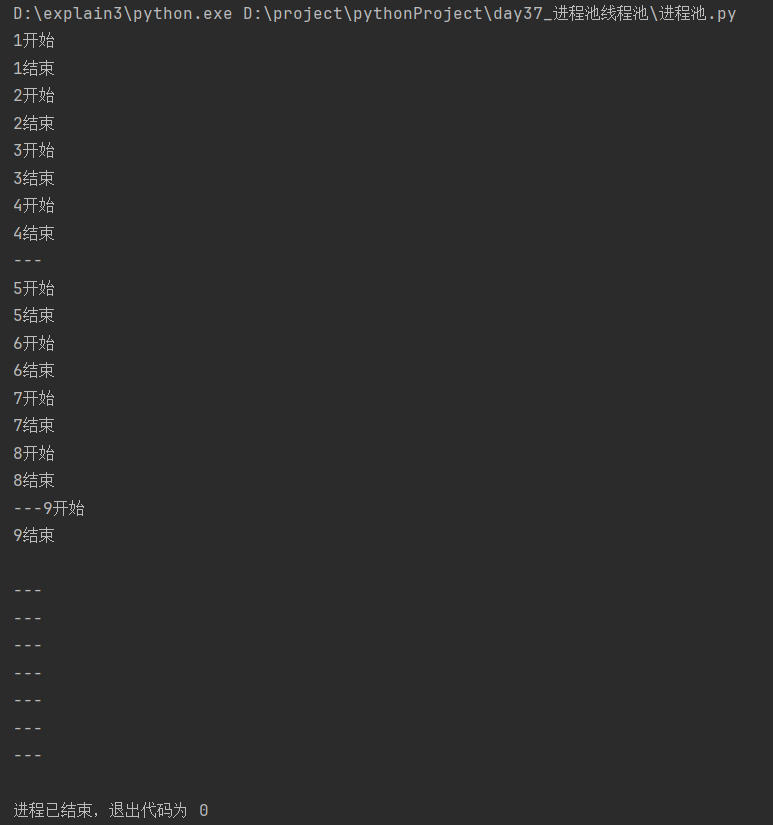
![[操作系统]进程同步](https://img2024.cnblogs.com/blog/1533409/202410/1533409-20241002214847342-804872587.png)