0 引言
- GoogLeNet,它是一种深度卷积神经网络,由Google研究人员在2014年提出,用于图像识别任务。
- CIFAR-10是一个常用的图像识别数据集,包含10个类别,每个类别有6000张32x32的彩色图像。
- 本文使用Pycharm及Pytorch框架搭建GoogLeNet神经网络框架,使用CIFAR10数据集训练模型。
- 笔者查阅资料时发现绝大多数文章仅仅给出代码而没有训练信息、模型参数文件。在CSDN社区出现收费情况,下载后可能是智商税,笔者认为十分不友好,故写此随笔。
1 GoogLeNet
- 论文下载网址:Going deeper with convolutions
- 发表期刊网址:IEEE
- 网络架构图片:
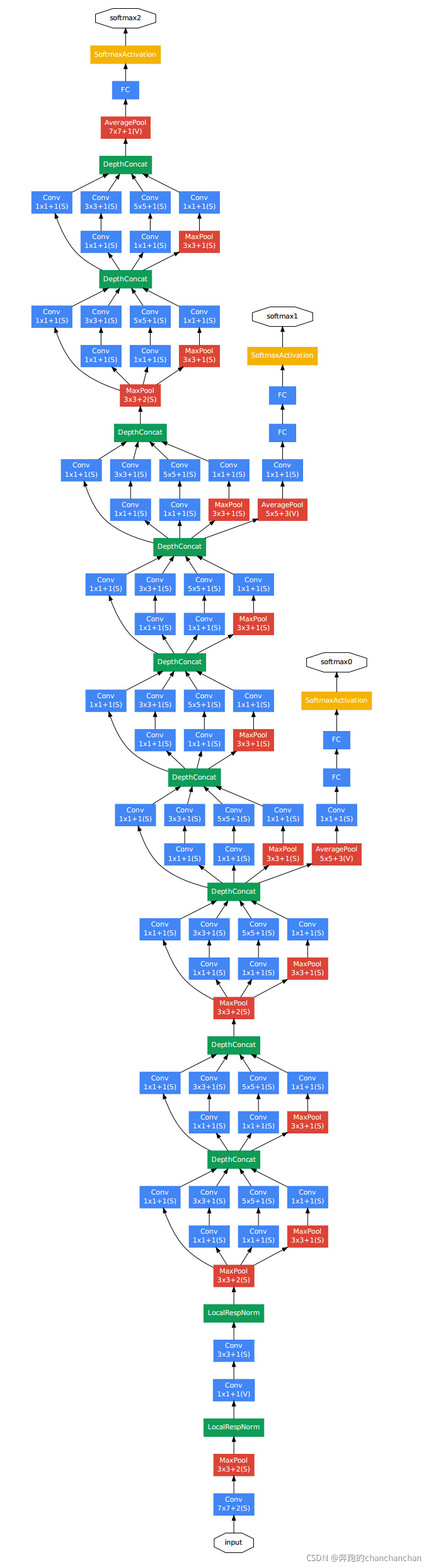
2 CIFAR-10数据集
- 数据集网址:CIFAR10

CIFAR-10数据集由10个类别的60000张32x32彩色图像组成,每个类别有6000张图像。有50000个训练图像和10000个测试图像。数据集分为五个训练批次和一个测试批次,每个批次有10000张图像。测试批次包含从每个类别中随机选择的1000张图像。训练批包含随机顺序的剩余图像,但某些训练批可能包含来自一个类的图像多于另一个类。在它们之间,训练批次包含来自每个类的5000张图像。[百度翻译]
3 搭建GoogLeNet网络框架
点击查看GoogLeNet.py
import torch
from torch import nnclass Inception(nn.Module):# type [batch channel height width]def __init__(self,cov_in,p1_1_cov_oc,p2_1_cov_oc,p2_2_cov_oc,p3_1_cov_oc,p3_2_cov_oc,p4_2_cov_oc):super(Inception, self).__init__()self.path1=nn.Sequential(# in [1,cov_in,224,224]nn.Conv2d(in_channels=cov_in, out_channels=p1_1_cov_oc, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(p1_1_cov_oc),nn.ReLU(inplace=True)# out [1,p1_1_cov_oc,224,224])self.path2 = nn.Sequential(# in [1,cov_in,224,224]nn.Conv2d(in_channels=cov_in, out_channels=p2_1_cov_oc, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(p2_1_cov_oc),nn.ReLU(inplace=True),# out [1,p2_1_cov_oc,224,224]# in [1,p2_1_cov_oc,224,224]nn.Conv2d(in_channels=p2_1_cov_oc, out_channels=p2_2_cov_oc, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(p2_2_cov_oc),nn.ReLU(inplace=True)# out [1,p2_2_cov_oc,224,224])self.path3 = nn.Sequential(# in [1,cov_in,224,224]nn.Conv2d(in_channels=cov_in, out_channels=p3_1_cov_oc, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(p3_1_cov_oc),nn.ReLU(inplace=True),# out [1,p3_1_cov_oc,224,224]# in [1,p3_1_cov_oc,224,224]nn.Conv2d(in_channels=p3_1_cov_oc, out_channels=p3_2_cov_oc, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(p3_2_cov_oc),nn.ReLU(inplace=True)# out [1,p3_2_cov_oc,224,224])self.path4 = nn.Sequential(# in [1,cov_in,224,224]nn.MaxPool2d(kernel_size=3,stride=1,padding=1),# out [1,cov_in,224,224]# in [1,cov_in,224,224]nn.Conv2d(in_channels=cov_in, out_channels=p4_2_cov_oc, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(p4_2_cov_oc),nn.ReLU(inplace=True)# out [1,p4_2_cov_oc,224,224])def forward(self,x):p1=self.path1(x)p2=self.path2(x)p3=self.path3(x)p4=self.path4(x)r1=torch.cat(tensors=[p1,p2,p3,p4],dim=1)return r1class GoogLeNet(nn.Module):def __init__(self):super(GoogLeNet, self).__init__()#type [batch channel height width]self.block1=nn.Sequential(#in [3,32,32]nn.Conv2d(in_channels=3,out_channels=192,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(192),nn.ReLU(inplace=True),# out [192,32,32]# in [192,32,32]nn.MaxPool2d(kernel_size=3,stride=1,padding=1),# out [192,32,32])self.block2=nn.Sequential(# in [192,32,32]Inception(192,64,96,128,16,32,32),# out [256,32,32]# in [256,32,32]Inception(256,128,128,192,32,96,64),# out [480,32,32]# in [480,32,32]nn.MaxPool2d(kernel_size=3,stride=2,padding=1)# out [480,16,16])self.block3 = nn.Sequential(# in [480,16,16]Inception(480,192,96,208,16,48,64),# out [512,16,16]# in [512,16,16]Inception(512,160,112,224,24,64,64),# out [512,16,16]# in [512,16,16]Inception(512,128,128,256,24,64,64),# out [512,16,16]# in [512,16,16]Inception(512,112,128,288,32,64,64),# out [528,16,16]# in [528,16,16]Inception(528,256,160,320,32,128,128),# out [832,16,16]# in [832,16,16]nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# out [832,8,8])self.block4 = nn.Sequential(# in [832,8,8]Inception(832,256,160,320,32,128,128),# out [832,8,8]# in [832,8,8]Inception(832,384,192,384,48,128,128),# out [1024,8,8]# in [1024,8,8]nn.AvgPool2d(kernel_size=8,stride=1,padding=0),# out [1024,1,1])self.block5=nn.Sequential(# in [1024,1,1]nn.Flatten(),# out [1024]# in [1024]nn.Linear(in_features=1024, out_features=10),# out [10]nn.Softmax(dim=0))#模型参数初始化for m in self.modules():if isinstance(m,nn.Conv2d):nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias,0)elif isinstance(m,nn.Linear):nn.init.normal_(m.weight,0,0.001)if m.bias is not None:nn.init.constant_(m.bias,0)def forward(self,x):x=self.block1(x)x=self.block2(x)x=self.block3(x)x=self.block4(x)x=self.block5(x)return x
-
初始卷积模块进行改动

-
删除了辅助分类器(Auxiliary Classifier)

改动后使得每个EPOCH训练耗时300秒左右。
4 主程序
4.1 数据预处理

上图为数据预处理的代码,大致操作是将图像转为张量格式再将图像数据进行标准化处理,设置每批次的数据量是40张图像,训练数据集打乱,测试数据集不打乱。
transforms.Normalize是一个预处理步骤,用于对图像数据进行标准化处理。这个步骤通常在图像输入到神经网络之前进行,目的是使得模型训练更加稳定和高效。Normalize的两个参数mean和std分别代表数据的均值和标准差,这两个参数需要提前计算。
- mean:这是一个长度与图像通道数相同的列表或元组,表示每个通道的均值。例如,对于RGB图像,mean可能是[0.485, 0.456, 0.406],表示红色、绿色和蓝色通道的均值。
- std:这同样是一个长度与图像通道数相同的列表或元组,表示每个通道的标准差。例如,std可能是[0.229, 0.224, 0.225],表示红色、绿色和蓝色通道的标准差。
4.2 加载模型及初始化

上图为加载模型及初始化的代码,大致操作是实例化GoogLeNet模型并设置损失函数、优化器、学习率优化器。损失函数为交叉熵损失,优化器是随机梯度下降,使用余弦退火学习率。
如果你已经有训练好的模型,想要继续训练提升精度,需要使用torch.load加载模型参数文件。
4.3 训练代码

上图是训练代码,每训练一批数据(40张图像一次性放入显存)就更新神经网络参数,所有训练集图像(50000张)训练完后输出训练信息及更新学习率,这样一共重复执行EPOCH_CNT次(for循环嵌套)。
4.4 测试代码

上图为测试代码,大致操作是将之前训练的模型用测试集(10000张)测试一遍,统计预测正确的占比并输出相关信息,保存模型。
点击查看MAIN.py
import torch
import time
import torchvision
import sys
from tqdm import tqdm, trange
from torch import nn
from torch.utils.data import DataLoader
from torchsummary import summary
from torchvision import transforms
from torch.nn import functional as F
from Package_1.Pytorch.GoogLeNet.CIFAR10.GoogLeNet import GoogLeNetEPOCH_CNT=200
LEARN_RATE=1e-2if __name__ == '__main__':#CIFAR-10 is a subset of the Tiny Images dataset with 60000 32x32 color images of 10 classes#均值:[0.49139968 0.48215841 0.44653091] 标准差:[0.24703223 0.24348513 0.26158784]transform_train=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.49139968,0.48215841,0.44653091],std=[0.24703223,0.24348513,0.26158784]),])transform_test=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.49139968,0.48215841,0.44653091],std=[0.24703223,0.24348513,0.26158784]),])data_train=torchvision.datasets.CIFAR10(root="../../dataset/dataset_CIFAR10",train=True,download=False,transform=transform_train)data_test=torchvision.datasets.CIFAR10(root="../../dataset/dataset_CIFAR10",train=False,download=False,transform=transform_test)loader_train=DataLoader(dataset=data_train,batch_size=40,shuffle=True,drop_last=False)loader_test=DataLoader(dataset=data_test,batch_size=40,shuffle=False,drop_last=False)#损失函数model=GoogLeNet().cuda()lossfun_cross=nn.CrossEntropyLoss().cuda()optimer=torch.optim.SGD(model.parameters(),lr=LEARN_RATE,momentum=0.9, weight_decay=1e-6,nesterov=True)scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimer,T_max=EPOCH_CNT)#训练for iEpoch in range(0,EPOCH_CNT,1):#重复EPOCH_CNT次tm_start = time.time()model.train()accurate_train=0f_loss_total_train=0.0for img,label in tqdm(loader_train,desc='train'):img=img.cuda()label=label.cuda()img1=model(img)ret_loss=lossfun_cross(img1,label)f_loss_total_train+=float(ret_loss)accurate_train += (torch.argmax(input=img1, dim=1) == label).sum()optimer.zero_grad()ret_loss.backward()optimer.step()print("epoch={} lr={:.6f} Train-Avg-Loss={:.3f} 训练集准确率={:.3f}%".format(iEpoch,scheduler.get_last_lr()[0],f_loss_total_train/len(loader_train),accurate_train/len(data_train)*100),end=" ")scheduler.step()model.eval()accurate_test=0f_loss_total_test=0.0with torch.no_grad():for img,label in loader_test:img = img.cuda()label = label.cuda()img1=model(img)ret_loss=lossfun_cross(img1,label)f_loss_total_test+=float(ret_loss)accurate_test+=(torch.argmax(input=img1,dim=1)==label).sum()#保存模型torch.save(model,"./GoogLeNet_CIFAR10_epoch_{:d}_acc_{:.3f}_.pth".format(iEpoch,accurate_test/len(data_test)*100))tm_end = time.time()print("Test-Avg-Loss={:.3f} 验证集准确率={:.3f}% 共耗时={:.3f}s".format(f_loss_total_test/len(loader_test),accurate_test/len(data_test)*100,tm_end-tm_start))5 训练模型
5.1 设定参数
训练过程中的参数设置:
批量大小:40,每次40张图像一次性放入GPU显存计算
学习率:初始学习率为0.01,根据余弦退火自动调整学习率。
迭代次数:设定为200次,但笔者并没有运行到200。
5.2 学习率曲线

笔者在训练期间电脑出现蓝屏、训练中断情况,笔者又加载训练好的模型继续训练,在EPOCH=70和EPOCH=91出现学习率异常。EPOCH=45~53为拟合出来的数据。
5.3 损失曲线

由于设备出现问题,EPOCH=45~53数据是笔者拟合出来的替代数据,在后文所给EXCEL文件中已标注。
5.3 准确率曲线

准确率值并未丢失(保存的模型命名上含有准确率)。
5.4 耗时曲线

EPOCH=45~53数据是笔者拟合出来的替代数据,在后文所给EXCEL文件中已标注。
6 结论
笔者模型训练耗时大概7~8小时,读者可以自行修改训练,例如数据增强、修改网络架构、调整超参数等
附录
完整代码+训练信息+pth模型参数见百度网盘链接: