全网最适合入门的面向对象编程教程:56 Python 字符串与序列化-正则表达式和 re 模块应用
摘要:
Python 的 re 模块提供了强大的正则表达式操作功能,用于在字符串中搜索、匹配、替换等,正则表达式是一种匹配字符串的模式。通过正则表达式,可以轻松地查找特定模式的字符串片段,如匹配电子邮件地址、手机号、特定格式的日期等。
原文链接:
FreakStudio的博客
往期推荐:
学嵌入式的你,还不会面向对象??!
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一文搞懂 CM3 单片机调试原理
肝了半个月,嵌入式技术栈大汇总出炉
电子计算机类比赛的“武林秘籍”
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
Avnet ZUBoard 1CG开发板—深度学习新选择
SenseCraft 部署模型到Grove Vision AI V2图像处理模块
文档和代码获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc

本文档主要介绍如何使用 Python 进行面向对象编程,需要读者对 Python 语法和单片机开发具有基本了解。相比其他讲解 Python 面向对象编程的博客或书籍而言,本文档更加详细、侧重于嵌入式上位机应用,以上位机和下位机的常见串口数据收发、数据处理、动态图绘制等为应用实例,同时使用 Sourcetrail 代码软件对代码进行可视化阅读便于读者理解。
相关示例代码获取链接如下:https://github.com/leezisheng/Python-OOP-Demo
正文
正则表达式简介
我们常常需要判断一个给定字符串的合法性,比如一串数字是否是电话号码;一串字符是否是合法的 URL、Email 地址;用户输入的密码是否满足复杂度要求等等。
如果我们为每一种格式都定义一个判定函数,首先这种定义可能很复杂,比如电话号码可以为座机时表示为 010-12345678 ,也可以表示为 0510-12345678, 还可以是手机号 13800000000。这样代码的逻辑复杂度就线性增加。其次我们定义的函数功能很难重用,匹配 A 的不能匹配 B。能否有一个万能的函数,只要我们传入特定的参数就能实现我们特定的字符匹配需求呢?答案是肯定的。
在现实世界中,大部分编程语言通过正则表达式来处理字符串解析。正则表达式是一种被用于从文本中检索符合某些特定模式的文本,它们依赖特殊符号来匹配未知字符串。它可用于解决一个常见的问题:给定一个字符串,确定它是否能够匹配某个给定的模式,以及可以收集包含相关信息的子字符串。
正则表达式中有两个概念,一个字符串包含若干个字符,每个字符在内存中都有对应的二进制编码,以及字符先后关系构成的位置,比如字符串开始位置和结束位置如图所示表示为 ps 和 pe。包含 N 个字符的字符串有 N+1 个位置,位置不占用内存,仅用于匹配定位。
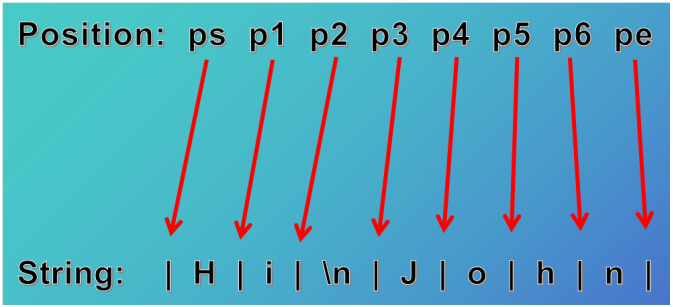
正则表达式使用一些特殊字符(通常以\开头,\是转义字符)来表示特定的一类字符集(比如数字 0-9)和字符位置(比如字符串开始位置)。它们被称为元字符(metacharacter)。元字符和其他控制字符构成的表达式被称为匹配模式(pattern)。匹配过程中有一个位置指针,开始总是指向位置 ps,根据匹配模式每匹配一次,就将指针移动到匹配字符的后序位置,并尝试在每一个位置上进行模式匹配,直至尝试过 pe 位置后匹配过程结束。‘.’在正则表达式中表示匹配除换行符\n 外的所有字符,如果要匹配‘.’自身,就要使用‘\ .’的形式。由于 Python 字符串本身也采用\作为转义符,所以正则表达式字符串前要加 r,表示原始输入,以防转义冲突。
在正则表达式中,如果直接给出字符,就是精确匹配。用’\d’可以匹配一个数字,’\w’可以匹配一个字母或数字,所以:
'00\d'可以匹配'007',但无法匹配'00A';
'\d\d\d'可以匹配'010';
'\w\w\d'可以匹配'py3';
'.'可以匹配任意字符,所以:
'py.'可以匹配'pyc'、'pyo'、'py!'等等。
要匹配变长的字符,在正则表达式中,用'*'表示任意个字符(包括 0 个),用'+'表示至少一个字符,用'?'表示 0 个或 1 个字符,用'{n}'表示 n 个字符,用'{n,m}'表示 n-m 个字符:
\d{3}\s+\d{3,8}
1. \d{3}表示匹配3个数字,例如'010';
2. \s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;
3. \d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用''转义,所以,上面的正则是\d{3}-\d{3,8}。
要做更精确地匹配,可以用‘[]’表示范围,比如:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;
[0-9a-zA-Z\__]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0__Z','Py3000'等等;
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
’A|B‘可以匹配 A 或 B:
(P|p)ython可以匹配'Python'或者'python'。
其他特殊符号还有:
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
?表示对它前面的正则式匹配0到1次重复,ab? 会匹配 'a' 或者 'ab'。
更多相关表达式使用方法可以查看如下链接:
https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
https://docs.python.org/zh-cn/3/howto/regex.html
https://pythonhowto.readthedocs.io/zh-cn/latest/regular.html
https://www.runoob.com/regexp/regexp-syntax.html

正则表达式的应用与 re 模块
Python 标准库中的正则表达式模块被称为 re。我们导入它之后创建一个搜索字符串和需要搜索的模式。
在下面的例子中,我们使用 re.compile()创建一个已编译正则表达式对象 re.Pattern,并使用 Pattern.match(string[, pos[, endpos]])方法:如果字符串开头的零个或多个字符与此正则表达式匹配,则返回相应的 Match。如果字符串与模式不匹配则返回 None。


由于要搜索的字符串和模式是相匹配的,条件判断会通过并且 print 语句会执行。示例代码如下:
import re
search_string = "hello world"
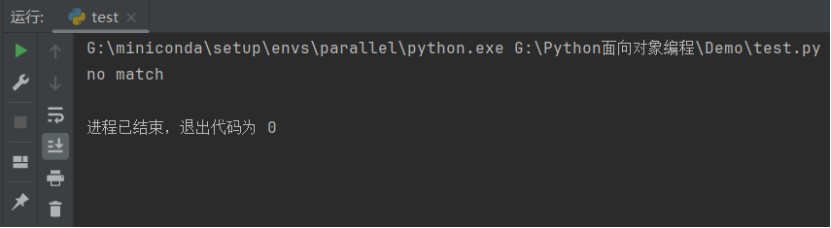
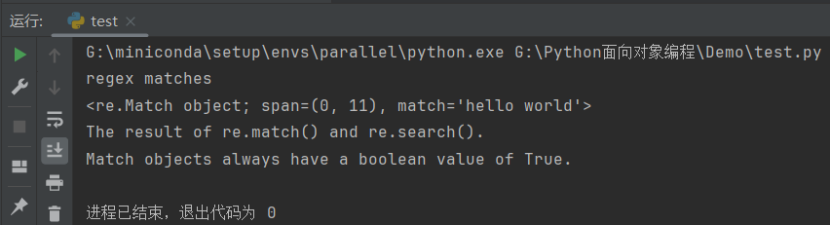
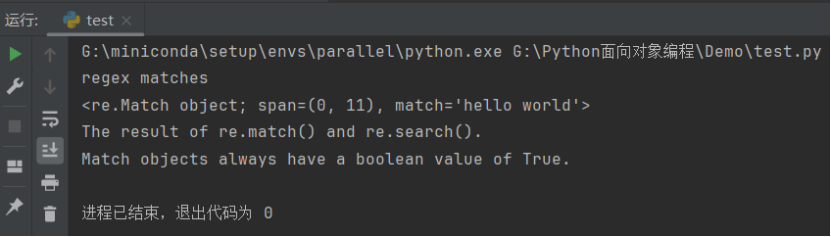
pattern = re.compile("hello world")
match = re.match(pattern, search_string)
if match:print("regex matches")print(match)print(match.__doc__)
运行结果如下:

由于 match 函数是从字符串的开头开始匹配模式,因此,如果模式改为"ello world",将无法匹配。
import re
search_string = "hello world"
pattern = re.compile("ello world")
match = re.match(pattern, search_string)
if match:print("regex matches")print(match)print(match.__doc__)
else:print("no match")
运行结果如下:
不同的是,一旦发现匹配,解析器将会立即停止搜索,因此模式"hello wo"也会成功匹配。如果我们只想要几个特定的字符被匹配可以将几个字符放到一个方括号中,以匹配其中的任何一个字符。因此,如果遇到一个[abc]的正则表达式模式字符串,我们就知道这 5 个字符(包括两个方括号)只会匹配搜索字符串中的一个字符,而且,这个字符只能是 a、b、c 中的一个。示例代码如下:
import research_string = "hello world"
pattern = re.compile("hell[lpo] world")
match = re.match(pattern, search_string)if match:print("regex matches")print(match)
运行结果如下,实际上,这些方括号应该被命名为字符集合,不过它们更常指代字符类。
通常,我们想要用更多字符,但逐个输入既单调又容易出错。幸运的是,正则表达式的设计者考虑到了这一点,并提供了简写方式。短画线符号可以代表一个范围。如果你想要匹配“所有小写字母”或“所有数字”,这就非常有用了,例如:
import re
search_string = "hello world"
pattern = re.compile("hell[a-z] world")
match = re.match(pattern, search_string)
if match:print("regex matches")print(match)print(match.__doc__)
else:print("no match")
运行结果如下:
正如前面我们说到的,我们也可以用反斜杠转义字符来匹配一些特殊符号,如‘.’、‘(’等,示例代码如下:
import research_string = "0.05"
pattern = re.compile("0\\.[0-9][0-9]")
match = re.match(pattern, search_string)
if match:print("regex matches")print(match)print(match.__doc__)
运行结果如下:
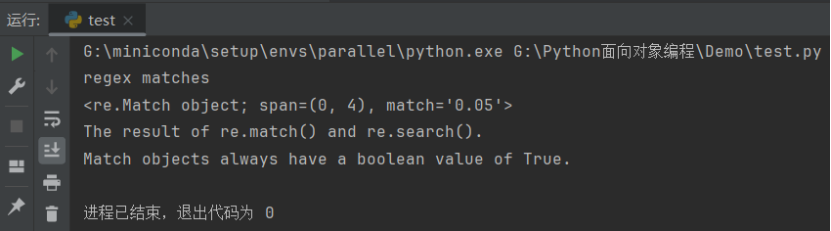
这里,需要注意的是我们传递给 re.compile() 的结果字符串必须是转义两个反斜杠“\section”,如果要匹配两个反斜杠的相关字符”\section“,则需要用四个反斜杠'\\'。也可以在 Python 正则表达式前加入 r 表示原生字符串,r 字符声明了引号中的内容表示该内容的原始含义,避免了多次转义造成的反斜杠困扰。
re 模块的 re.Pattern 类还具有如下方法,我们接下来进行尝试:
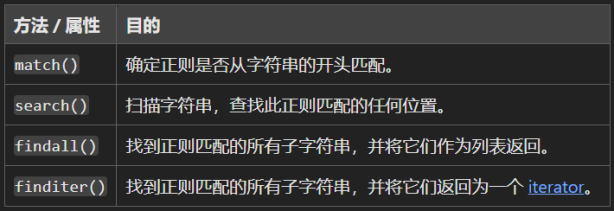
我们可以用 search 方法对字符串中的正则表达式进行搜索,它将返回与正则表达式产生匹配的第一个位置,具体用法如下:
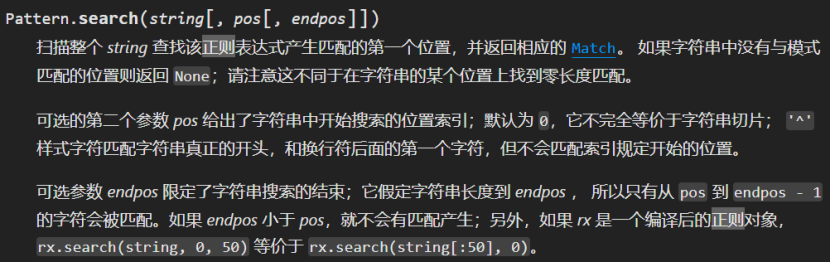
示例代码如下:
import repattern = re.compile("o")
locate = pattern.search("dog")
print(locate)

在正则表达式的第一个例子中,我们将整个正则表达式与字符串相匹配,实际上我们应该使用 fullmatch 函数而非 match 函数:

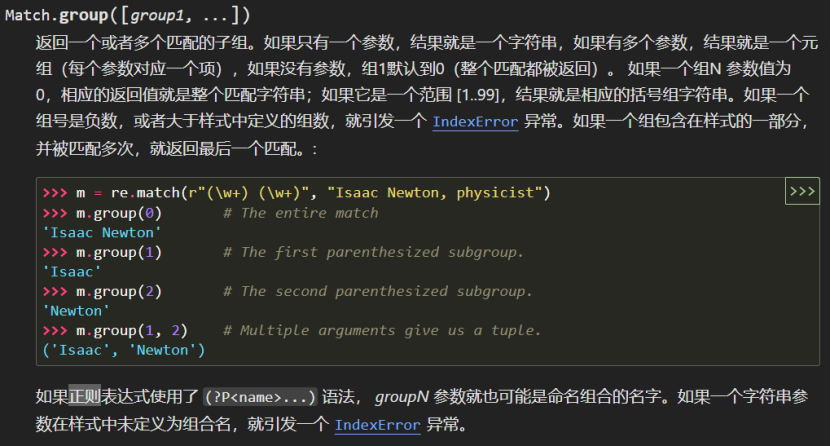

import repattern = re.compile("o[gh]")
_# Pattern.fullmatch(string[, pos[, endpos]])_
_# 第二个参数 pos 给出了字符串中开始搜索的位置索引_
_# 第三个参数endpos限定了字符串搜索的结束_
_# 从 pos 到 endpos - 1 的字符会被匹配,在本例中,为‘ogg’_
match = pattern.fullmatch("doggie", 1, 3)print(match)
_# 打印匹配到的子串_
print(match.group())
_# 打印匹配到的字符的起始位置_
print(match.pos)

你可以看到在这个例子中,我们使用 group 方法提取了子串。group(0)是与整个正则表达式相匹配的字符串,group(1)、group(2)……表示第 1、2、……个子串。
我们也可以利用正则表达式来切分字符串,该方法比用固定的字符更灵活。

示例程序如下:
import restr = 'a b c'
_# 普通split方法拆分字符串_
str_split = str.split(' ')
_# 输出['a', 'b', '', '', 'c']_
_# 无法识别连续的空格_
print(str_split)_# 使用re库中的split方法_
str_re_split = re.split(r'\s+', str)
print(str_re_split)
运行结果如下:
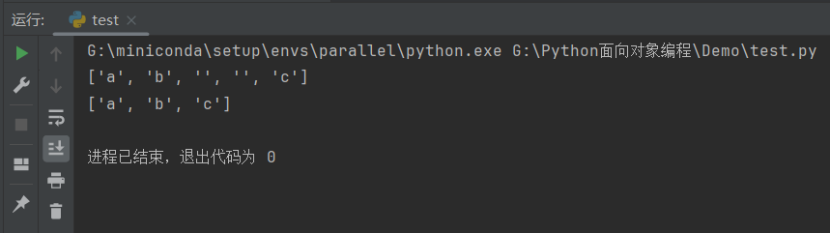
其中,\s 表示匹配任意的空白字符,+ 表示匹配前面的字符一次或多次,这个正则表达式可以匹配一个或多个空白字符,包括空格、制表符、换行符等。
至今为止,我们已经成功匹配了大部分已知长度的字符串。然而,在多数实际场景中,我们并不清楚需要匹配的确切字符数量。这时,正则表达式便能发挥巨大作用。我们可以通过对模式进行微调,添加一个或多个标点符号,从而实现对多个字符的有效匹配。这种灵活性使得正则表达式在处理复杂字符串匹配问题时具有显著优势。
星号()意味着前一种模式可以出现零次或多次。将星号和其他匹配多个字符的符号组合起来就会得到更有趣的结果,例如,‘.’将会匹配任何字符串,而’[a-z]*‘将会匹配任意数量的小写字母,包括空字符串;加号(+)和星号的行为类似,只不过它要求之前一种模式出现的次数必须是一次或多次,而不像星号一样是可选的;问号(?)要求前一种模式只能出现零次或一次,不能更多。
常见示例如下:
'0.4' matches pattern '\d+\.\d+'
'1.002' matches pattern '\d+\.\d+'
'1.' does not match pattern '\d+\.\d+'
'1%' matches pattern '\d?\d%'
'99%' matches pattern '\d?\d%'
'999%' does not match pattern '\d?\d%'
接下来,我们用一个示例更加深入地应用前面说明的相关知识点。一般来说,邮箱的用户名和域名都必须至少包含两个字符,并且只能使用字母、数字、点、下划线、百分号、加号或减号作为字符。用户名和域名中间有 @ 符号,域名格式为:xxx.com。
在下例中,我们来编写一个正则表达式,用于匹配有效的邮箱地址:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
其中:
- (1) ^ 表示字符串的开头;
- (2) [a-zA-Z0-9._%+-]+ 匹配一个或多个字母、数字、点、下划线、百分号、加号或减号,这些字符通常出现在电子邮件地址的用户名中;
- (3) @ 匹配 @ 符号;
- (4) [a-zA-Z0-9.-]+ 匹配一个或多个字母、数字、点或减号,这些字符通常出现在电子邮件地址的域名中;
- (5) . 匹配一个点符号;
- (6) [a-zA-Z]{2,} 匹配两个或更多个字母,这些字符通常出现在电子邮件地址的顶级域名中(如 .com、.org 等);
- (7) $ 表示字符串的结尾。
该正则表达式可以匹配类似于“example@example.com”这样的电子邮件地址。
在下面代码中,我们定义了一个复杂的正则表达式,用于匹配有效的邮箱地址。然后,我们定义了一个列表 emails,其中包含了一些邮箱地址。使用 search()方法逐个匹配邮箱地址,并输出结果。示例代码如下:
import re_# 定义正则表达式_
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'_# 定义目标字符串_
emails = ["user@example.com","user-1@example.co.uk","user.name@example.com","user@sub.example.co.in","invalid_email"
]_# 使用search()方法匹配有效的邮箱地址_
for email in emails:match = re.search(pattern, email)if match:print("有效的邮箱地址:", match.group())else:print("无效的邮箱地址:",email)
运行结果如下:

我们也可以用 findall 函数查询匹配模式的所有非重叠部分的结果,而不是像 search 函数一样只有第一个。基本上它首先找到第一个匹配,然后从该结果的结尾处重新设定字符串,再进行下一个搜索。
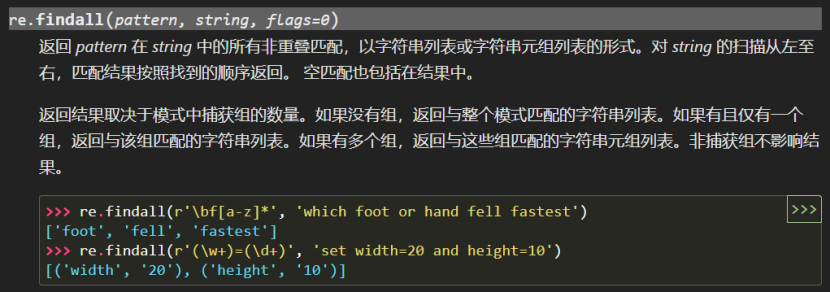
它不返回匹配对象,而是返回一个匹配字符串或元组的列表。返回结果的类型依赖于正则表达式中括号组合的数量:如果模式中没有组合,findall 将会返回字符串列表,其中每个值都是源字符串中与模式匹配的子字符串;如果模式中只有一个组合,findall 将会返回一个字符串列表,其中每个值都是该组中的内容;如果模式中存在多个组合,findall 将会返回一个元组列表,其中按照顺序每个元组包含的是一个组合中匹配到的结果。
import re
_# \b 表示单词边界,[a-z] 表示任意一个小写字母_
_# 可以匹配以f开头,后面跟着零个或多个小写字母的字符串。_
print(re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest'))
运行结果如下:

最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的 0:
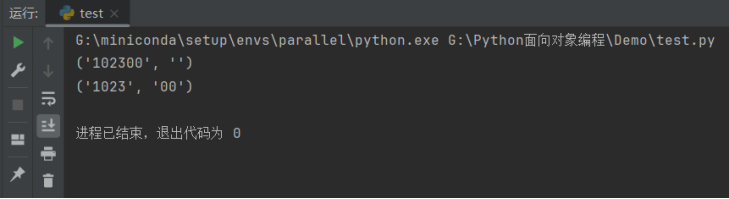
import re
_# 由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了_
print(re.match(r'^(\d+)(0*)$', '102300').groups())
_# 加个?就可以让\d+采用非贪婪匹配:_
print(re.match(r'^(\d+?)(0*)$', '102300').groups())
运行结果如下: