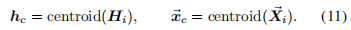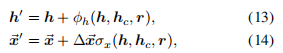1. 数据及代码中的变量
初始化变量
B: 存储每个 block(残基)的类型,来自VOCAB.symbol_to_idx。A: 存储原子的类型,来自VOCAB.get_atom_global_idx()和block.to_data()。X: 存储原子的坐标信息。atom_positions: 存储原子位置的索引,用于进一步计算原子的几何信息。block_lengths: 记录每个 block(残基)包含的原子数量。segment_ids: 记录这些 block 属于哪个分子或片段(即哪一个blocks_list)。
2. 坐标的扰动
protein-protein的数据,选择其中一个protein进行扰动
3. 生成每个蛋白质global的坐标
每个蛋白质的首节点为global node
4. Embedding的方式
原子的embedding + 残基的embedding
5. 生成边
三种节点
- 基于蛋白质的全局节点:这个全局节点可以表示整个蛋白质的中心或代表整个蛋白质的全局信息。
- 基于每个
block(残基)的全局节点:每个block(通常对应于蛋白质中的一个残基或一组残基)有一个对应的全局节点,这个节点表示该block的几何中心,主要用于局部信息的聚合和传播。 block中的普通节点:这些是block内的普通节点,通常代表实际的原子或残基。
block-level的边 (残基-残基)
intra_edges: 块内部的边,代表同一块(残基)内原子之间的连接。inter_edges: 块之间的边,代表不同块(残基)之间的连接。global_global_edges: 全局节点之间的边,连接全局节点(每个残基的中心节点)之间的边。global_normal_edges: 全局节点和普通节点之间的边,连接全局节点和残基中的普通节点。
edge attr这个变量
不同种类的边会有不同的embedding,四种边,四种embedding
unit-level的边 (原子-原子)
从函数 _unit_edges_from_block_edges 的逻辑来看,它主要是基于 残基级别的边(block_src_dst)来生成 原子级别的边。因此,这个函数处理的边仅限于跨残基(block)的边,不包含同一个残基内部的原子之间的边。
unit-level映射到block-level
xxx
6. 使用rbf实现距离的映射
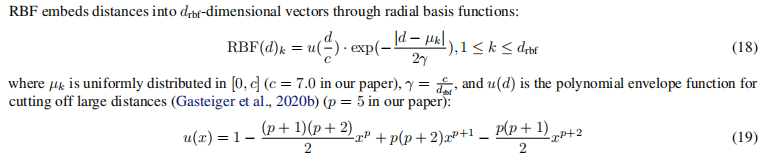
1 维到 16 维,再到 4 维分组处理:
- 1 维距离变成 16 维向量:首先,通过 RBF 嵌入,1 维的距离信息被映射到 16 维的向量空间。
- 多头注意力中的 4 维分组:接着,这个 16 维的向量会被分成 4 份,每个头会负责其中的 4 维信息。这是多头注意力的常见做法,多个头可以在不同的特征空间上并行处理输入信息。
这个设计的好处是,通过 RBF 嵌入,模型可以从简单的 1 维距离中提取更丰富的特征,然后通过 多头注意力 将这些特征并行处理,进而捕捉到不同的特征维度中的相关性。
7. 多头注意力机制的计算
unit-level的注意力机制
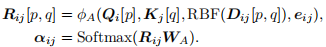
由于公式中有下标 \(i,j\),这意味着是以 block 为单位 来计算每个 block 中所有原子对(即 \(p\) 和 \(q\))之间的关系。换句话说,公式中的 \(R_{ij}[p, q]\) 表示的是 block \(i\) 和 block \(j\) 中所有原子对之间的关系。
- 是以 block 为单位,在每两个 block \(i\) 和 \(j\) 之间计算它们内部所有原子对 \(p\) 和 \(q\) 的关系。
block-level的注意力机制
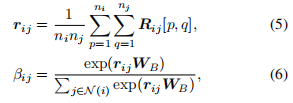
- 代码中的这部分逻辑实现了论文中的公式 (5) 和 (6)。它首先通过
scatter_mean计算两个 block 间所有原子对关系的平均值 \(r_{ij}\),然后通过scatter_softmax对 block 间的权重进行 softmax 归一化,得到最终的 block 级别的注意力权重 \(\beta_{ij}\)。
8. 更新的计算
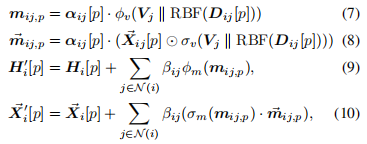
9. 坐标的标准化
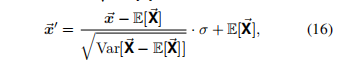
处理过程就是 对每个 block 求 均值 和 方差,然后对每个 block 中的数据进行标准化和缩放处理。这与公式 (16) 非常类似。
在 每个 block 的维度上 进行均值和方差的计算,并基于此进行数据的标准化处理。这确保了数据在每个 block 内部被标准化处理,消除不同 block 间的分布差异。
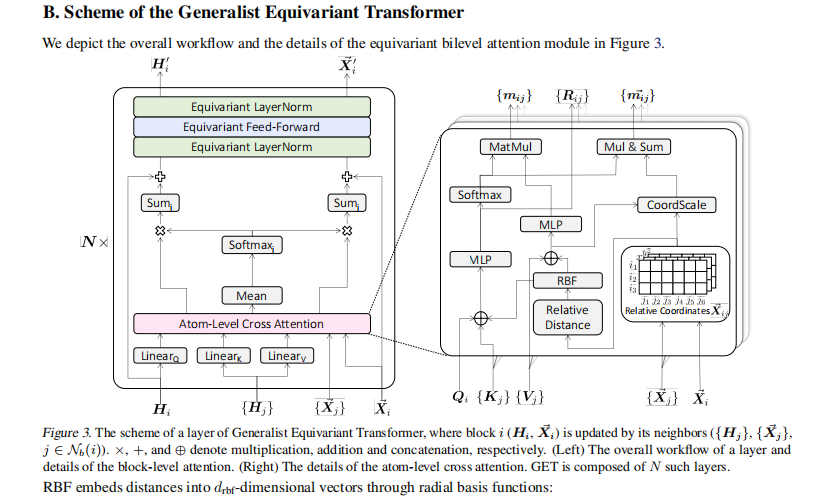
10. GET中transformer的图
11. Equivariant Layer Normalization
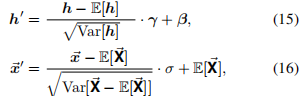
12. Equivariant Feed-Forward Network