消息队列前世今生
1.1 案例一: 系统崩溃
首先大家跟着我想象一下下面的这个的场景,
看到新出的游戏机,太贵了买不起,这个时候你突然想到,今天抖音直播搞活动,打开抖音搜索,找到直播间以后,你点开了游戏机详情页,看到价格只要500。
这个时候我们分析一下,就我们上面这几步操作,在我们的程序背后,做了什么事情。

首先,请求会先到搜索商品这个服务上,并记录下你的搜索行为;
然后点击商品的时候,又记录了我们的点击商品,这些数据最终都会通过计算分析;
目的是为了下一次给你更准确的信息,这个时候问题来了,如果这个时候,负责记录存储的数据库被一个小哥删库跑路了。我们的所有操作都动不了了,这个时候我们应该怎么办,带着这个问题,我们继续往下看
1.2 案例二:服务能力有限
看到这个价格,你非常心动,商品即将在3分钟后开抢,这个价格必须要抢到啊!但此时在无数台手机的后面,藏着无数和你一样饥渴的同学,再来看看,后面的程序又做了哪些事情呢?

一堆人都发起了订单请求,可是公司给的预算不够,服务器的配置太弱,订单服务只能同时处理10个订单请求。这个时候我们又该怎么办呢。继续往下看
1.3案例三:链路耗时长尾
在我们点击提交订单之后,这个怎么一直转圈圈,卡在这个页面啊,等了半分钟后,
啊终于抢到了,不过这个app也太慢了,下次不用了。我们进一步看一下这次问题出在哪里了

一通分析,发现,库存服务和订单服务都挺快的,但是最后通知商家(30s)这一步咋这么慢,是不是还可以进行优化呀?
1.4 案例四:日志存储
在字节跳动的会议室里传出了悲伤的声音,因为刚刚有服务器坏掉了,我们的本地日志都丢掉了,没有了日志,我们还怎么去修复那些刚刚出现的那些问题,周围一片寂静,突然小张站出来缓缓的说了一句话,众人才露出了微笑准备下班离开,大家能猜到小张到底说的什么吗
1.1.1 案例一 解决方案

1.2.1
既然 服务器等其他原因导致 处理能力有限 ,我们可以把大量请求放到消息队列;每次拿10个处理

1.3.1
把“发起订单”请求放到《消息队列》,异步做那三个事,逻辑上在库存-1的时候就可以返回;下单成功,剩下的时候做商家通知,不用等他完事了再return 成功;

1.4.1

2.0 消息队列

2.1消息队列发展历程
消息中间件其实诞生的很早,早在1983年互联网应用还是一片荒芜的年代,有个在美国的印度小哥Vivek就设想了一种通用软件总线,世界上第一个现代消息队列软件The Information Bus(TIB),TIB受到了企业的欢迎,这家公司的业务发展引起了当时最牛气的IT公司IBM的注意,于是他们一开始研发了自己消息队列软件,于是才有了后来的wesphere mq,再后来微软也加入了战斗。
接近2000年的时候,互联网时代已经初见曙光,全球的应用程序得到了极大地丰富,对于程序之间互联互通的需求越来越强烈,但是各大IT公司之间还是牢牢建立着各种技术壁垒,以此来保证自己的商业利益,所以消息中间件在那个时候是大型企业才能够用的起的高级玩意。
但是时代的洪流不可逆转,有壁垒就有打破壁垒的后来者,2001年sun发布了JMS技术,试图在各大厂商的层面上再包装一层统一的java规范。java程序只需要针对jms api编程就可以了,不需要再关注使用了什么样的消息中间件,但是jms仅仅适用于java。
2004年AMQP(高级消息队列协议)诞生了,才是真正促进了消息队列的繁荣发展,任何人都可以针对AMQP的标准进行编码。有好的协议指导,再加上互联网分布式应用的迅猛发展成为了消息中间件一飞冲天的最大动力,程序应用的互联互通,发布订阅,最大契合了消息中间件的最初的设计初衷。
除了刚才介绍过的收费中间件,后来开源消息中间件开始层出不穷,常见比较流行的有ActiveMQ、RabbitMQ 、Kafak、阿里的RocketMQ,以及目前存算分离的Pulsar,在目前互联网应用中消息队列中间件基本上成为标配。

2.1.1 业界消息队列对比

3.0 Kafka
3.1使用场景
一般是 离线的消息处理、Metrics(程序运行当中程序状态的采集)数据、用户行为;
3.2 如何使用
引入Kafka 的SDK 实现上游的生产逻辑,消费者拉取

第一步:首先创建一个Kafka集群,但如果你在字节工作,恭喜你这一步消息团队的小伙伴已经帮你完成了
第二步:需要在这个集群中创建一个Topic,并且设置好分片数量
第三步:引入对应语言的SDK,配置好集群和Topic等参数,初始化一个生产者,调用Send方法,将你的Hello World发送出去
第四步:引入对应语言的SDK,配置好集群和Topic等参数,初始化一个消费者,调用Poll方法,你将收到你刚刚发送的Hello World
3.3 基本概念

Topic:Kakfa中的逻辑队列,可以理解成每一个不同的业务场景就是一个不同的topic,对于这个业务来说,所有的数据都存储在这个topic中
Cluster:Kafka的物理集群,每个集群中可以新建多个不同的topic
Producer:顾名思义,也就是消息的生产端,负责将业务消息发送到Topic当中
Consumer:消息的消费端,负责消费已经发送到topic中的消息
Partition:通常topic会有多个分片,不同分片直接消息是可以并发来处理的,这样提高单个Topic的吞吐,对于每一个Partition来说,每一条消息都有一个唯一的Offset,消息在partition内的相对位置信息,并且严格递增
3.3.2 Offset

3.3.3 Replica:分片的副本,分布在不同的机器上,可用来容灾
Leader对外服务,Follower异步去拉取leader的数据进行一个同步,尽量保持同步
如果leader挂掉了,可以将ISR的Follower提升成leader再对外进行服务
ISR(In-Sync Replicas):
意思是同步中的副本,对于Follower来说,始终和leader是有一定差距的,但当这个差距比较小的时候,我们就可以将这个follower副本加入到ISR中;差距大就提出ISR;不在ISR中的副本是不允许提升成Leader的

3.4 数据复制
下面这幅图代表着Kafka中副本的分布图。
图中Broker代表每一个Kafka的节点,所有的Broker节点最终组成了一个集群。
整个图表示,图中整个集群,包含了4个Broker机器节点,集群有两个Topic,分别是Topic1和Topic2,Topic1有两个分片,Topic2有1个分片,每个分片都是三副本的状态。
这里中间有一个Broker同时也扮演了Controller的角色,
Controller是整个集群的大脑,负责对副本和Broker进行分配,再告诉各个Broker怎么去处理

3.5 Kafka架构
在集群的基础上,还有一个模块是ZooKeeper,这个模块其实是存储了集群的元数据信息,和Controller配合
比如副本的分配信息等等,Controller计算好的方案都会放到这个地方

3.6 一条消息的自述
从一条消息的视角来看看完整的处理流程,了解一下Kafka为什么可以支撑如此高的吞吐

一秒几千万条数据 吞吐量达不到要求 不能等

3.7.1 Producer-批量发送

3.7.2 Producer-数据压缩
默认选择 Snappy压缩算法;当前 经过测试 ZSTD算法在计算性能、压缩率等更加优秀

3.8 Broker-数据存储
如何写入到磁盘呢,我们先来看一下Kafka最终存储的文件结构是什么样子的

在每一个Broker,都分布着不同Topic的不同分片,不同副本以Log形式 写入磁盘;Log会切分成不同的有序的LogSegment;.log存真实数据;.index 日志具体位置的映射;

只看一个盘面,磁头->磁道->扇区 寻道成本高

3.8.2 顺序写
采用顺序写的方式进行写入,以提高写入效率

3.8.3如何找到消息
此时我们的消息写入到Broker的磁盘上了,那这些数据又该怎么被找到然后用来消费呢
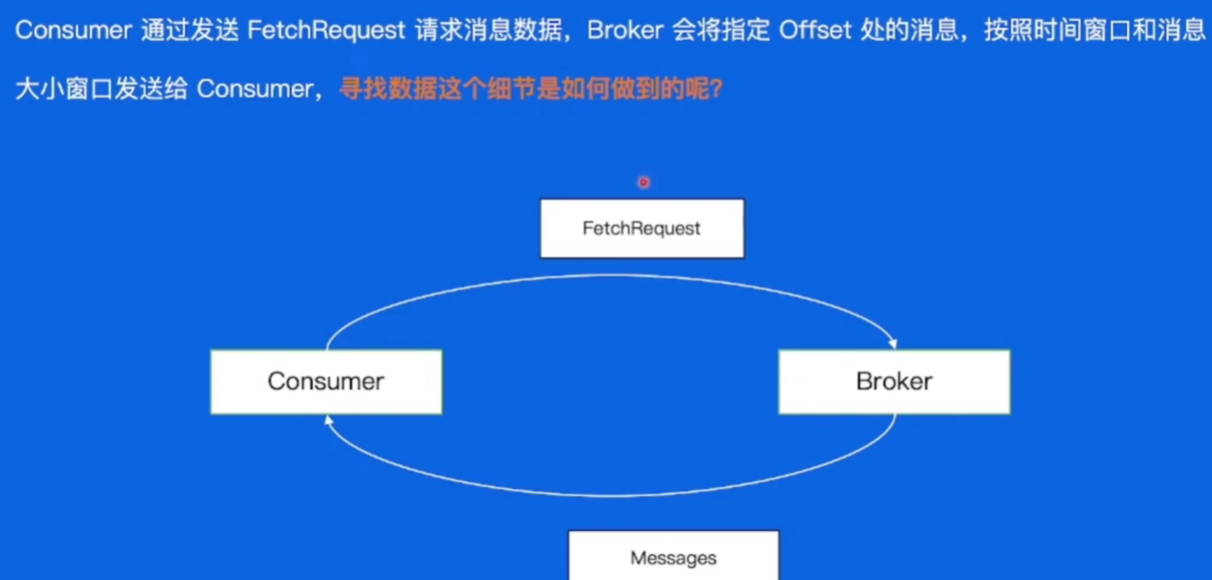
3.8.4偏移量索引文件
介绍文件:文件名是文件中第一条消息的offset
第一步,通过二分找到小于目标文件的最大文件

通过二分找到小于目标offset最大的索引位置,再遍历找到目标offset

3.8.5 时间戳文件索引
如果我们需要使用时间戳来寻找的时候,和offset相比只是多加了以及索引,也就是通过二分找到时间戳对应的offset,再重复之前的步骤找到相应的文件数据

3.8.6 传统数据拷贝& 零拷贝
从磁盘读到内核态 再拷贝到用户态的应用空间 然后 网卡发送到 消费者

零拷贝 :直接从内核空间 传到NIC网卡 ;减少三次传统拷贝

3.9 Consumer—消息的接收端
对于一个Consumer Group来说,多个分片可以并发的消费,这样可以大大提高消费的效率,
但需要解决的问题是,Consumer和Partition的分配问题, 也就是对于每一个Partition来讲,该由哪一个Consumer来消费的问题。
对于这个问题,我们一般有两种解决方法,手动分配和自动分配

3.9.1 Consumer—Low Level
第一,手动分配,也就是Kafka中所说的Low Level消费方式进行消费,
这种分配方式的一个好处就是启动比较快,因为对于每一个Consumer来说,启动的时候就已经知道了自己应该去消费哪个消费方式,好比图中的Consumer Group1来说,Consumer1去消费Partition 1,2,3 Consumer2,去消费456, Consumer3去消费78。
这些Consumer在启动的时候就已经知道分配方案了,但这样这种方式的缺点又是什么呢,想象一下,如果我们的Consumer3挂掉了,我们的7,8分片是不是就停止消费了。
又或者,如果我们新增了一台Consumer4,那是不是又需要停掉整个集群,重新修改配置再上线,保证Consumer4也可以消费数据
其实上面两个问题,有时候对于线上业务来说是致命的。

3.9.1 Consumer—High Level
所以Kafka也提供了自动分配的方式,这里也叫做High Level的消费方式,
简单的来说,就是在我们的Broker集群中,对于不同的Consumer Group来讲,都会选取一台Broker当做Coordinator(协调者),
而Coordinator的作用就是帮助Consumer Group进行分片的自动分配,也叫做分片的rebalance,
使用这种方式,如果ConsumerGroup中有发生宕机,或者有新的Consumer加入,整个partition和Consumer都会重新进行分配来达到一个稳定的消费状态

3.10 Consumer Rebalance


3.11 Kafka—数据复制问题
通过前面的介绍我们可以知道,对于Kafka来说,
每一个Broker上都有不同topic分区的不同副本,而每一个副本,会将其数据存储到该Kafka节点上面,对于不同的节点之间,通过副本直接的数据复制,来保证数据的最终一致性,与集群的高可用。
3.12 Kafka—重启操作

举个例子来说,如果我们对一个机器进行重启;
首先,我们会关闭一个Broker,此时如果该Broker上存在副本的Leader,那么该副本将发生leader切换,切换到其他节点上面并且在ISR中的Follower副本,
可以看到图中是切换到了第二个Broker上面 而此时,因为数据在不断的写入,对于刚刚关闭重启的Broker来说,和新Leader之间一定会存在数据的滞后,此时这个Broker会追赶数据,重新加入到ISR当中 当数据追赶完成之后,我们需要回切leader,
这一步叫做prefer leader,目的是为了避免:在一个集群长期运行后,所有的leader都分布在少数节点上,导致数据的不均衡
通过上面的一个流程分析,我们可以发现对于一个Broker的重启来说,需要进行数据复制,所以时间成本会比较大,比如一个节点重启需要10分钟,一个集群有1000个节点,如果该集群需要重启升级,则需要10000分钟,那差不多就是一个星期,这样的时间成本是非常大的。
有同学可能会说,老师可以不可以并发多台重启呀,问的好,不可以。
为什么呢,在一个 两副本(一个分片 有两个副本)的集群中,重启了两台机器,对某一分片来讲,可能两个分片都在这两台机器上面,则会导致该集群处于不可用的状态(影响整个Topic)。这是更不能接受的。
3.13-替换,扩容,缩容操作
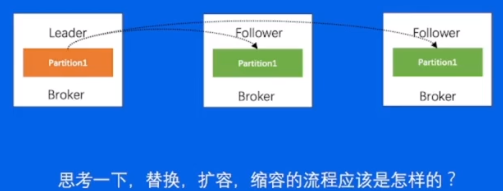
如果是替换,和刚刚的重启有什么区别?
其实替换,本质上来讲就是一个需要 追 更多数据的重启操作,因为正常重启只需要追一小部分,而替换,则是需要复制整个leader的数据,时间会更长
扩容呢,当分片分配到新的机器上以后,也是相当于要从0开始复制一些新的副本
而缩容,缩容节点上面的分片也会分片到集群中剩余节点上面,分配过去的副本也会从0开始去复制数据
以上三个操作均有数据复制所带来的时间成本问题,所以对于Kafka来说,运维操作带来的时间成本是不容忽视的
3.14 负载不均衡

这个场景当中,同一个Topic有4个分片,两副本,
可以看到,对于分片1来说,数据量是明显比其他分片要大的,当我们机器IO达到瓶颈的时候,可能就需要把第一台Broker上面的Partition3 迁移到其他负载小的Broker上面,接着往下看
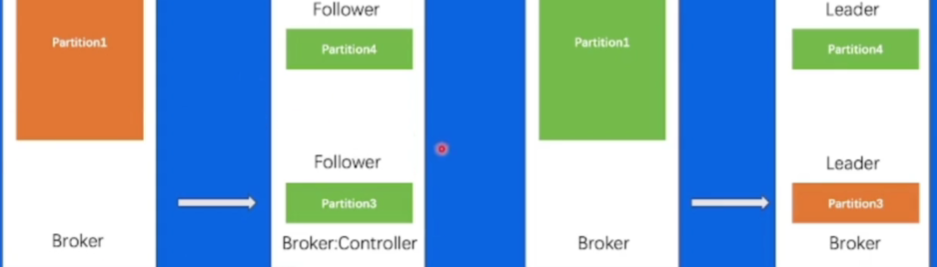
但我们的数据复制又会引起Broker1的IO升高,所以问题就变成了,我为了去解决IO升高,但解决问题的过程又会带来更高的IO,所以就需要权衡IO设计出一个极其复杂的负载均衡策略
问题总结

我们对以上两个问题进行总结,
第一,因为有数据复制的问题,所以Kafka运维的时间成本和人力人本都不低
第二,对于负载不均衡的场景,我们需要有一个较为复杂的解决方案进行数据迁移,从而来权衡IO升高的问题
除了以上两个问题以外,Kafka自身还存在其他的问题
比如,Kafka没有自己的缓存,在进行数据读取的时候,只有Page Cache可以用,所以不是很灵活
另外在前面的介绍当中,相信大家也了解到了,Kafka的Controller(负责分片方案)和Coordinator都是和Broker部署在一起的,Broker因为承载大量IO的原因,会导致Controller和Coordinator的性能下降,如果到一定程度,可能会影响整个集群的可用性
4.0 BMQ
字节自研的消息队列,ByteMQ,简称BMQ
BMQ兼容Kafka协议,存算分离,云原生消息队列,初期定位是承接高吞吐的离线业务场景,逐步替换掉对应的Kafka集群,我们来了解一下BMQ的架构特点
非常感谢您阅读到这里,如果这篇文章对您有帮助,希望能留下您的点赞👍 关注💖 收藏 💕评论💬感谢支持!!!