基于WIN10的64位系统演示
一、写在前面
上期内容基于Tensorflow环境做了误判病例分析(传送门),考虑到不少模型在Tensorflow环境没有迁移学习的预训练模型,因此有必要在Pytorch环境也搞搞误判病例分析。
本期以SqueezeNet模型为例,因为它建模速度快。
同样,基于GPT-4辅助编程,后续会分享改写过程。
二、误判病例分析实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
from torch.nn.functional import softmax
import os
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.8 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义SqueezeNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels# 根据分类任务修改最后一层
model.classifier[1] = nn.Conv2d(num_ftrs, len(class_names), kernel_size=(1,1))# 修改模型最后的输出层为我们需要的类别数
model.num_classes = len(class_names)model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 5# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'SqueezeNet_model-1.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
# 导入 os 库
import os# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]: # 在这里添加 pathsinputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i, path in enumerate(paths): # 在这里添加 path 和 enumerate 函数# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(path) # 使用 os.path.basename 函数获取图片名称original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result-2.csv", index=False)跟Tensorflow改写的类似,主要有两处变化:
(1)导入数据集部分:而在误判病例分析中,我们需要知道每一张图片的名称、被预测的结果等详细信息因此需要加载图片路径和图片名称的信息。
(2)误判病例分析部分:也就是需要知道哪些预测正确,哪些预测错误。
(b)调教GPT-4的过程
(b1)咒语:请根据{代码1},改写和续写《代码2》。代码1:{也就是之前用tensorflow写的误判病例分析部分};代码2:《也就是修改之前的SqueezeNet模型建模代码》
还是列出来吧:
代码1:
# 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):for images, labels, paths in dataset:# 使用模型对这一批图片进行预测probabilities = model.predict(images)predictions = tf.math.argmax(probabilities, axis=-1)# 遍历这一批图片for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):# 获取图片名称和真实标签image_name = path.numpy().decode("utf-8").split('/')[-1]original_label = class_names[label]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到dataframe中result_df = result_df.append({"原始图片的名称": image_name,"属于训练集还是验证集": dataset_name,"预测为Tuberculosis的概率值": probability[1],"判定的组别": group}, ignore_index=True)# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)代码2:
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
import os# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占80%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes###############################定义TNT模型################################
# 导入必要的库
import torch.nn as nn
import timm# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))# 将模型移至指定设备
model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 20# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'tnt_dit_model.pth')GPT-4回复:
代码2的改写版本如下:
首先,我们需要为PyTorch添加类别名称,以便我们在生成结果时可以进行映射,然后创建一个列表来存储预测结果。
################################导入数据集#####################################
...
# 获取数据集的类别
class_names = full_dataset.classes
# 保存预测结果的列表
results = []接着,我们在进行预测时,为了获取每个样本的概率,我们需要使用torch.nn.functional.softmax()函数,同时还需要将预测值与0.5比较,以判定组别。最后,我们使用Pandas将预测结果保存为CSV文件。
import pandas as pd
from torch.nn.functional import softmax# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i in range(inputs.size(0)):# 获取图片的名称、标签、预测值和概率image_name = dataloaders[phase].dataset.dataset.samples[i][0].split('/')[-1]original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result.csv", index=False)我们看看“result.csv”文件是否符合我们的要求:
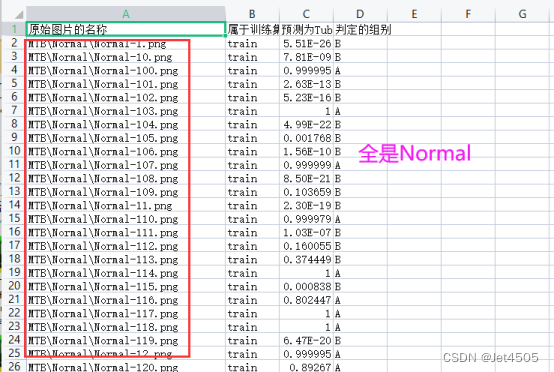
问题很明显,分组全是“Normal”!!!
(b2)咒语:为什么输出的“原始图片的名车”全部是“MTB\Normal\”,完全没有“Tuberculosis”?
GPT-4回复:
在PyTorch中,当我们使用torchvision的datasets.ImageFolder载入数据时,数据被按照文件夹的顺序进行排序,所以获取图片名称时,我们只是在循环中按顺序获取了数据集中的图片路径。这可能会在对验证集进行预测时出现问题,因为我们使用了random_split函数对数据进行了随机划分,而获取图片路径的方式并未考虑到这个随机性。
为了解决这个问题,你可以试试将图片路径也保存在数据加载器中。在这里,我假设你的训练集和验证集是以文件夹的形式存储的,每个文件夹的名字就是类别的名称。以下是一个简单的自定义数据集类,它可以在加载数据的同时获取每个图片的路径:
from torch.utils.data import Dataset
from PIL import Imageclass ImageFolderWithPaths(Dataset):def __init__(self, image_folder, transform=None):self.image_folder = image_folderself.transform = transformself.image_paths = list(map(lambda x: x[0], image_folder.imgs))def __getitem__(self, index):original_tuple = self.image_folder.imgs[index]path = original_tuple[0]image = Image.open(path).convert("RGB")if self.transform is not None:image = self.transform(image)return (image, original_tuple[1], path)def __len__(self):return len(self.image_folder.imgs)你可以这样使用这个数据集类:
# 创建原始的ImageFolder数据集
original_dataset = datasets.ImageFolder(data_dir, transform=data_transforms['train'])# 使用我们的自定义数据集类,获取图片路径
full_dataset = ImageFolderWithPaths(original_dataset, transform=data_transforms['train'])# 现在,你的数据加载器在每次迭代时都会返回图片、标签和图片路径
for images, labels, paths in dataloader:...
看得懂怎么改写代码不?看不懂也不要紧,继续:
(b3)咒语:帮我在这个代码上改写和更新,并展示所有代码:{复制代码}
GPT-4回复:
import torch
from torchvision import datasets, transforms
from torch.nn.functional import softmax
import os
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义TNT模型################################
# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))# 将模型移至指定设备
model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 4# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'bonet_dit_model-1.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i in range(inputs.size(0)):# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(paths[i])original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别if original_label == class_names[prediction]:group = 'correct' # 正确预测的图片else:group = 'misclassified' # 错误预测的图片# 将结果保存为字典result = {'image': image_name,'label': original_label,'prediction': class_names[prediction],'probability': probability,'group': group}# 将字典添加到结果列表中results.append(result)# 将结果列表保存为数据框,并输出为csv文件
results_df = pd.DataFrame(results)
results_df.to_csv('classification_results.csv', index=False)运行,报错,哈哈哈:
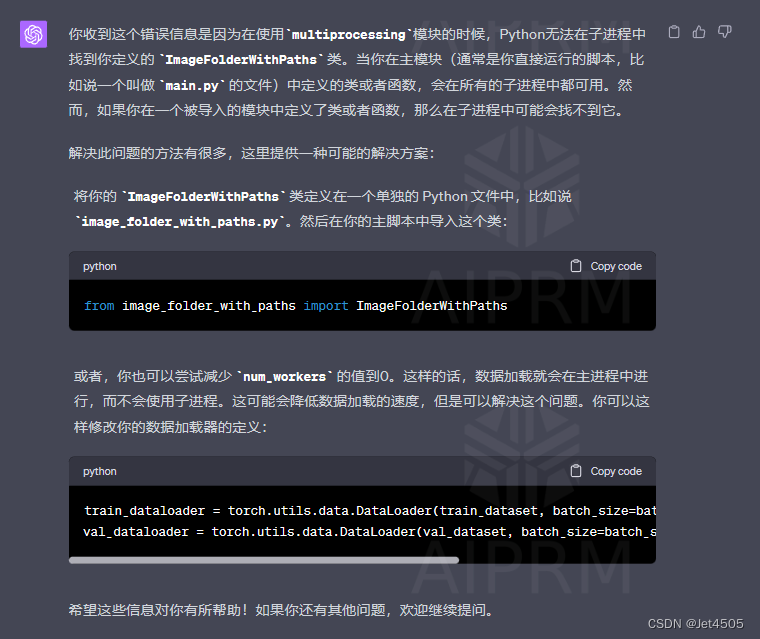
(b4)咒语:报错:Traceback (most recent call last): File "<string>", line 1, in <module>File "C:\ProgramData\Anaconda3\envs\Pytorch\lib\multiprocessing\spawn.py", line 116, in spawn_main exitcode = _main(fd, parent_sentinel)
File "C:\ProgramData\Anaconda3\envs\Pytorch\lib\multiprocessing\spawn.py", line 126, in _main self = reduction.pickle.load(from_parent)
AttributeError: Can't get attribute 'ImageFolderWithPaths' on <module '__main__' (built-in)>
GPT-4回复:
继续报错,继续问:Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Temp\ipykernel_19344\1832509689.py", line 146, in <cell line: 131>
for inputs, labels in dataloaders[phase]:
ValueError: too many values to unpack (expected 2)
GPT-4回答:
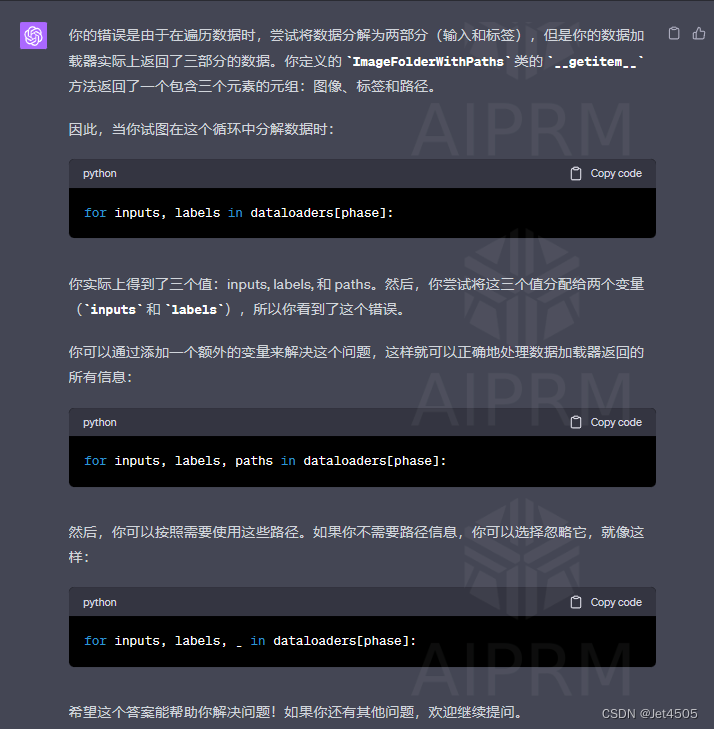
最后能运行了,又回到(b2)的问题:为什么输出的“原始图片的名称”全部是“MTB\Normal\”,完全没有“Tuberculosis”???一脸蒙蔽,无奈我又问了TA一次。
(b4)咒语:为什么输出的“原始图片的名车”还全部是“MTB\Normal\”,完全没有“Tuberculosis”????请显示完整的代码以解决这个问题。
GPT-4这回给出正确答案:
# 导入 os 库
import os# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]: # 在这里添加 pathsinputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i, path in enumerate(paths): # 在这里添加 path 和 enumerate 函数# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(path) # 使用 os.path.basename 函数获取图片名称original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result-2.csv", index=False)总结:现在来看,改写过程中出问题大概率是图片的路径提取中出了问题。核心咒语还是一样的:{以0.5为阈值,因此可以样本分为三份:(a)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测正确,判定为A组;(b)本来就是Normal的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为B组;(c)本来就是Normal的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测错误,判定为C组;(d)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为D组;},剩余的就跟GPT-4对线,出了问题及时且准确的进行反馈,这很重要!!!
三、输出结果
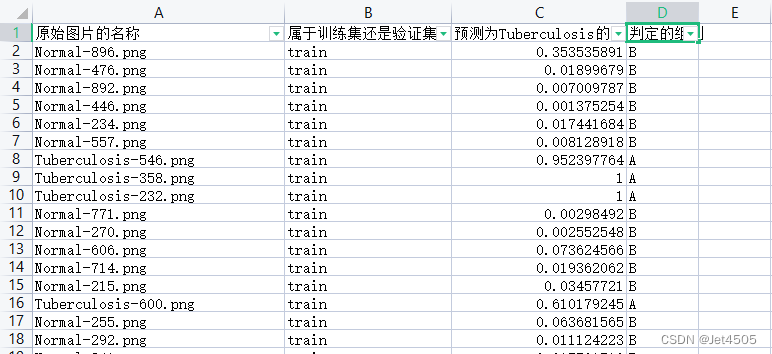
有了这个表,又可以水不少图了。
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf