七月在线公开课笔记(二十六)
人工智能—机器学习公开课(七月在线出品) - P18:世界杯数据分析案例 - 七月在线-julyedu - BV1W5411n7fg
然后我们来做个分析吧,所以大家喜欢做一些比赛的分析,对吧?然后大家最关注的当然是决赛半决赛啊,可能也多多分析一下,分析到4分之1决赛对吧?好,所以然刚才已经抓了一些数据下来。我留了一个小任务。
我抓下来的那个数据呢是son格式的。然后用方式下来。大家可以去整理一下,你可以把里头的even词把even那一个项那个key对应的value拿出来做一个data frame做一个CSV文件。
这个你们自己去做好吧,我没有把这一行就它其实就是一行命令就可以做完的事情,我没有把它放在我的ipad当中,所以你们你们先自己去试。如果有问题的话再问我好吧。
所以这个地方大家会在这个连人夹里头会看到有一个CSV啊,我这数据有点大,我没有放在da大家代码我希望大家自己去跑一下那个抓取的过程,然后自己去把比如说德国和阿根廷比赛的这个比赛数据存一个SV原本是一个。
格式这个事情是不太难做的,其实还比较简单。所以对这个工作留给大家自己去练练手吧,好吧,至少把这个我们这个。给了这个东西跑一遍OK所以这个地方的话依旧要用到一些库嘛。我们想对世界杯的决赛去做一个分析。
注意啊,我现在做的事情真的是数据分析啊,这是data analysis呃,比较分析师们会做的一些事情的一个小小小的一个例子,你可以看得到。所2014年世界杯的一个决赛的分析啊。
这大概是我们需要做一些预处理。所以你要把相应的数据准备好了,你要把要的包import,所以importPD。是方便用in nonineSNP。
okK方便用把m plot live拉拉进来这个PLT啊拍pl。呃,这个地方有个文件有一个文件。如果你有兴趣的话,大家自己去看一下这个文件在spriet写了一个东西,封装了一个东西。
这个东西呢会对各种各样的场景。实际上啊你看啊这个地方有这么多的事件evens词,你去看它里头有typepe,它是有type name的,是是对应这些编号是有对应的类型的。比如说这是一个传球。
它会编号成一。比如说这是一个这个。okK这这这东西啊,这是一个犯规。你你这些都这些的话,大家简单的理解成你在一场足球比赛当中可能有很多很多的场景,你会传球,你会断球,你会有犯规。
你会有这个角球等等coner啊等等。有这么多种类型啊,有一个进球,我看看在哪进球啊,第一101是带着球跑,然后is a ball。OK然后。那还有一些。啊,好吧好吧,这有一些编码的问题,可能是。
oklost control of the ball失求了等等啊,就是我们我写的这样一个脚本,会把刚才的ID对应成具体的事件。能明白吧?这我是有个d有个字典,好吧,然后我需要去把这些事件画出来。
所以写了一个函数叫joaw event。这个函数完全是一个画图的一个函啊,一个一个画图的一个函数,所以我会去jo一个even。一会大家会看到我会掉这个东西啊,具体的具体这里面的这个详细的细节呢。
我不会给大家一行一行说,但我会告诉大家这个事情,它就是在把这样一个事件画出来。比如说传球,我会把这个我会用一个箭头指明从哪个位置传到了哪个位置。然后因为这是一个足球场里头的比赛。
所以我们需要确定这个箭头到底是在足球场的什么样的一个位置。所以大家会在这里看到很多的XYDXDY它表示说离我的左侧球场到底有多远,离我的。上面那一侧啊,上边界到底有多远等等啊。
然后这个地方你会看到有不同的颜色,有不同类型的箭头,我只是为了区分这些evenmens,为了区分不同的一些事件,到底是传球还是射门还是射没射进,好吧。然后可以看到这里面有array。
可以看到这里面有scatter闪点啊,等等等等啊。这里头有所以jo events大家有概念啊,joeven具体的细节下去看jo events,你看啊它的底色是黑色,一会儿你会看箭头,你可以去看箭头。
它的基本的那些箭头颜色是黑色,然后会有进球的红色的箭头等等啊。jo events,大家有个基本的概念,这个东西是用来画发生的那个事情,事箭,传球断球丢了球进球等等OK。带球跑等等。
然后就有个jopach,这个的话是把足球场画出来,我需要去画一个高级一点的足球场,不是刚才那个一片绿色。所以这个地方大家可以看到我会画一些。禁区。然后会有中场。
然后会有一些中场这个这个ecclipse这个这个椭圆这个啊中场这个场场地里头的一些对标记啊,所以所以这是一个自己封装的,这个不是一个库啊,不要不要下去以后问我说这个库,老师我在哪里装。
这是我们自己封装的一个小的。一个工具用来画图的。好吧,因为你做分析,做分析,你需要给人更直观的一个。印象,而不要说我我我给你一堆的数字,很枯燥的数数字,你最好能把这个东西做成一个可视化可很好的一个东西。
OK所以好,我们回来啊,我们看看这个分析。好了,开始做分析吧。所以把数据读进来吧。这个数据我刚才已经说过了,大家自己去用这个jason的那个格式去生成一下。好吧。
所以germanwe、阿genina、这个德国和germany,德国和阿根廷的一个比赛。把数据读进来,用UTF81个编码。然后我们会设定一些标准的一些数据。比如说这个球场。
球场应该是X应该横的是是多长啊,Y应该是多长size。然后这有个boxhate box y我这个宽度和高度。大家这个box大家能理解大家知道足球里和box指的是什么吗?
大家知道在球场的两侧会有一些有一些禁区,对吧?叫penity box。OK指的是这样一个东西啊,所以一会儿我们要对对进区我们一会儿需需要画的啊。O所以有同学知道啊。
所以这个地方有y box start box and ok ok进区的对,所以是近区从什么地方开始,从什么地方到什么地方结束结束,对吧?然后你会啊做一些这些东西我就不说了啊。
因为你得把足球大小变更到哦要把它画出来,但是我要保证这个比例,能明白吧?所以我把我把它这些数据做一个sca做一个幅度的一个变换O。😊,下面这些东西的话是我们自己想做的一些统计啊。
所以这个地方有counts,就是这个你可以理解成它是一个技数。然后会有DFDY啊DFDY你看这个表达式你都看得出来,就表示我在球场的什么位置嘛,我得确定它离左边球场左边边界多远,离下边界多远。
在我画的这个球框里头,明白吧?这个distance是一个距离,离我的离我的。求门有多远,你看他是怎么求的,画了一个圆嘛,把X和Y的坐标平方和加起来,开了一个根号,怎么就是一个圆吗?下面节我不说了啊。
这些tto box到禁区有多远,对吧?是不是在在呃进攻阶段。是不是在进攻阶段,这个能理解吧?你看他它的处理这些东西都是我们自己要根据具体的场景出来的。当你越过了自己的这半场,你不就是处于进攻状状态吗?
所以这个地方on offense。在进攻阶段,就是你现在所处的位置已经超过了半个球场,自己的这半个球场,所以我就是在进攻嘛,所以很理很好理解,对吧?
to box和 from box就是指的两侧的禁区到底有多远嘛。这个你自己去看就好了啊。我我已经给大家解释到这了啊。如果这个东西你去看这个data frame,你觉得还有问题的话。
那去把把padas把这个data frame的一些。基本的操作,基本运算都自己去熟悉一下。好吧,所以我们采集了一些数据,我们想知道它现在是在进攻阶段还是在防守阶段。我们想知道它离进区到底有多远。
我们想知道它离这个球门到底有多远。因为你对你能理解吧?因为一球门的话,它是一个一个弧线嘛。OK好,所以这是我们自己做出来的数据啊,注意这是在原始数据上做出来的一些数据。我们一会儿统计的时候要用。好。
可以开始了。那我们看一下上半场吧,我们快速的过一下上半场吧,我们来做一个图标好了,看看进攻和防守的一个状态。所以你可以理解成大于零的部分呢,表示德国队的进攻小于零的部分表示德国队的防守。
然后在图里头标出来了射门的一些点,这个很好看吧。这个图好,所以我们先给大家看一眼图,图大概长这样。这是上半场的一些资料,first half profile。这张图大家能看得到吗?能看得行吧。
所以我用不同的颜色表示出来了,上面的话是蓝色,下面是紫色。OK我们想看看大家控球的一个能力到底有多强。所以其实控球的强能力有多强,你就是看一看这个球在谁手里嘛。然后你看一看这个啊sorry。
这个地方是这个地方是那个呃各自在进攻的阶段有有多长啊,那我们刚才不是大家看到了有一个量吗?叫all offense吗,越过了自己的半场,我就是已经是进攻到他对方的半场了吗?所以这个地方没问题啊。
我们用这样一个东西,我们用这个啊一会儿大大大大家这个往后拖,你是可以看得到的O。好,所以你你是可以去做一个统计的啊,你是可以去做一个统计的。这个地方的统计的话,我。不给大家一行一行念了吧。
首先我们要找我们要找到我们要找到德国队germany和阿根廷队对吧?的数据找出来,这是一个data frame的一个选择。我把这德国队的数据选出来,把阿根廷队的数据选出来。
然后我做一个排序groupod by。然后我去看一看。我去把他们两个的X做一个减法,这个能明白吗?当它大于零的时候,表示德国队的。你你自己去自己仔细去理解一下,你就你你就能能体会得到了。
就是它其实说明的就是我现在德到底是德国比较强势,在我进攻阶段还是阿根廷在我进攻进攻阶段,这和我在的位置是有关系的吧。因为我到了对方的半场,我是进攻嘛,那那对方到我的半场,我现在就是防守嘛。
大概就是这样一个意思啊,所以我我画我的我的这个数值是这样求出来的。像大家会看到有个tackpropro有同学知道是什么吗?mat。你可以简单理解成是。Stack什么意思?层叠。对吧。
所以我把所有的这么一些,刚才对啊,是一种图。对这个特别算的很对,是一种图。但我我刚想问你到底是什么样的一种图啊,这个AVGX啊,刚才我们求得的所有的这些啊,有偶尔偶尔是我进攻到你这道了。
偶尔是你进攻到我这了啊,我把这个东西给它串起来画了一些类似于。😊,这个直方图啊或者什么样的一个图啊,这个叫steppl step plot。然后你在steppl里头呢,你可以。注意啊,到这个位置为止。
你是可以画出来你现在如果去。画一下的话,你是可以得到这幅图的,是没有这些箭头。大家看到这幅图上有箭头吗?我们想把所有的射门的点都标记出来。我们把想把所有的设明的点标记出来。所以OK好。
这个时候的话大家会看到我把我的上方和下方分别是。上方是德国队在进攻的阶段,下方是阿根廷队在进攻阶段,也就是阿帮阿根廷队攻击到了德国队这一侧,明白吧?然后我要画些箭头,大家别忘了啊,我要把我射门的点。
上半球射门呃,不是上半场射门的点全都标记出来,用什么样的东西啊?你可以用ar,你也可以用一些其他的一些标记。比如说这个地方的话啊,当然这些这些工具的话,其实我自己用着也不一定特别熟。
我也要去查它对应的这个参数。所以呃我我自己认为啊,如果你做数据分析,你做做可视化的话,如果你天天做的话,你可能会比较熟,如果你不天天做的话,你你要知道这个东西在哪,你要知道我上哪里可以查。
但是没有地方会要求你说你需要把这里面每一个参数都记下来,这个很难的,反我自己反正我自己是做不到这个事情的,好吧,所以我们我们去画这样一个箭头,你看这里头会有一些property嘛?
这个箭头property,它的属性,对吗?你看我设的是black,我要求是黑色箭头,你不信你把这个换成re这张图像就变红色了。所以参数我不给大家讲,我只是给大家讲一个,我们去做这样一个事情。
我们得知道我们需要什么东西。我们做这样个图,我们需要去画一个。这样一个分布的状况,所以我我可以去用一些pro对吧?比如说我这个地方我找到t,我觉得是比较合适的。那你现在需要把所有的点都标出来。
设门的点都时间点都标出来,你这个横轴不就是时间点嘛,你要把射门的时间点都找到的话,你就可以画出来它在哪里设门的那这个时候你要去做这个事情,刚才我们提了一个角叫呃叫 sorry就是那个箭头ROW对吧?
这个箭头是m的里头有这样一个工具,那这个地方我再给了第二个工具啊,这个你可以自己去用好吧,你可以自己去用我我也记不住这些参数,我也是查的,所以你也可以去查这个这个没有问题啊,你只需要知道我需要什么。
我在哪里可以找到它好吧,所以这个地方的话,我pro一下,我画出来了以后啊,注意啊这个横坐标啊,我把我的的横坐标设定成是按分钟来的min所以从左往右走是一分钟一分钟分钟ok好吧,然后。我把它画出来。
我给个标题,我标题是这个first half profile。第一上半场的一个情况。OK没有问题,对吧?好,所以你可拿到这样一个结果非常清晰吧。这个这个比我只我去看数据,你给我一个60%几。
70%几要清晰很多了。你一看你就知道上半场明显是德国占占据优势。因为德国持续处于进攻的状态。然后阿根廷就控球的不是控球,就是到对方半场的时间都没有那么多,对吧?大部分都是全都被蓝色的蓝色占据了。所以。
😊,而且你知道射门的点在哪?对吧。这个地方啊我不太清楚是不是有一次补设啊,我没有去看具体的这个对应到的这个这个结果。他你他那里面比较详细。你抓下来数据里头实际上是有有它相关的一些信息。
甚至会有带上这个这个的一个图片。当他刚没有看到嘛,对吧?有一些recall,有的reca啊O所以你可以自己去看,做数据分析师很多都是这样的,我说我分析东西完了,不一定不是说我分析完了。
我这个结果就放这了。我分析完了之后,我得去看为什么会有这样一个结果,对吧?所以你得回去再看看,比如说这个地方你看到你说啊这个德国队好像比较强势上半场,然后这个好像有一些射门,好像射门次数差不多。
或者说这个甚至阿根阿根廷的射门还多一点,然后你就你可能会有一些想法,你说是不是阿根廷这个好不容易到了对方的这个。区域,然后我我对方的这半场,我也很着急圣门或者怎么样。啊你可以自己去看这个东西,对吧?
所以上半场很有意思的地方在于说德国队基本上是主导的比赛,使得阿根廷大部分情况下都在自己的半场内溜达。对于这个有一个可视化,更可以说明问题。因为你刚才你不是想到这个吗?你从这个图里头你已经看到了。
你说这个德国队占占占占优势嘛,非常强势嘛,然后我把它画出来了,大家看到看得到这个图吗?

大家看得到这个图吗?这是一个传球,这幅图是一个传球,这是我们刚才给大家讲的joaw event,就是在这里用。我要把所有的传球全都画出来,用箭头。那这个很这个更好理解了吧。我从这个图里头啊。
我先不看怎么画的。大家从这个图里头,你看右边是阿根廷这这个半场,左边是德国的这这有半个球场啊,你看我自己我画了禁区,对吧?我画了这个box penalty box,我画了这个中场,对吧?
我画了我我我这个比刚才那个要稍微细致一点啊,因为它有有具体的,而且这个比例,这个比例是完全和足球场是一模一样的,因为我们自己做了scaling。ok。啊,不用,我们这个地方不需要去找起始点。
我们要找我们只是印证我们的想法,我们只是印证我们自己觉得这个。德国占优,德国有进攻攻势非常强,仅此而已。OK所以你去看这个地方。先画一个球场叫BPach。OK所以我把它画出来了,叫出来了。
然后就把所有的传球都画出来呀。你看大家还记得我那个typepe吗?大家还记得我刚才第一的type吗?我类型吗?我一是传球。啊,我记得我忘了我这个文件有没有打开。我忘了文件关了,好像那么一是传球。
我现在想看看传球在哪侧呢,所以一是传球,一是pass好好,所以。来看看啊,传球嘛,所以没问题,joeven我们把所有的传球都画出来啊,我们选出来了嘛,因为到data frame做了一个选择。
必须是要是传球。然后传球以后你就把它画出来了啊,画出来了以后,你把所有的传球都画出来了。你在这幅在这个球场上一看就一目了然。你看到大部分的传球都发生在这一侧,上半场,那显然就是德国公过来了呗。
这个阿根廷过去的就这么一些,而且离离进区都那么远,离进区那么远,只有阿根廷这一次,你看德国好好几次的这个传球或者射门都在禁区。对,都都已经到了禁区里边,阿根廷根本就攻不进进去。好。呃。
所以当然当然图可视化只是辅助,可视化只是辅助,你要你要给你的大boss看,他肯定老老实实是要求你提供具体的数据。所以说你就给我做份统计嘛。我说好做统计吧。所以这个地方用se frame做统计嘛。
group by做一个。分组按照team name,你看啊这个地方的team name就是德国和阿根廷嘛。好,做一个分组以后怎么办呢?做一个聚合,什么样的聚合呀?On offense。大家别忘了。
我刚才是不是产出了一个offence,是不是去自己造了一个。处于进攻的这么一个。一和零这么一个值。是吧,所以我这个值去求平均,不就是表示我有多大的概率,现在是在进攻阶段吗?它就是1个10值嘛。
大家一定要掌握这个技巧啊,所有的二分类的问题。10的时候,你求一个平均,其实表示的就是一的概率,表示的就是一的概率。所以我现在想知道我现在on fans,我在进攻阶段的概率有多高,我就是求一个平均。
对吧?我就是通过这样一个方式,我用一个。n派点 mean去做一个对这个onoff这样一个标记,这样一个for型的标记做一个平均。没问题吧,所以你拿出来你发现明显就是嘛,德国有0。
6161%的时间都是它占据了。公式。他在站着这个。offense在在进攻,然后27%的是阿根廷在进攻。然后有同学会问,还那还有10%的是什么呢?就是你自己去看一看你就明白了。我我这个这个问题留给大家。
你看看我们我们当时这个onoff是有没有哪些区域是遗漏的,或者说在那个区域,你看看可能是势均力敌的。啊,好,然后这个地方的话有一个传球,对吧?我们type等于一。
说明是在传球我go by tip name,说明我要分一下是阿根廷队还是德国队,我去看一看他们的一个outcom,他们的一个概率,也就是意思是什么呀?传球传媒成传传成功没传成功。传成功没传成功。呃。
去这个outcom变量是你自己造的啊,你可以自己去,你可以上上去看一下。你可以自己上去看一下outcom。out come指的就是说我有没有传成功啊,我们自己刚才定义的一个变量。
所以你对他用同样的方式啊MP点那呃命我我一直在说这是一个小技巧,我们可以拿到概率。所以你会发现明显上半场德国状态太好了,就是呃不是太好了,就实比阿根廷明显是要好的。它有83。5%的传球都是都是很顺利了。
没有没有没有被断掉。然后你会发现阿根廷只有69%,69。4%的传球是。成功的其他的被其他都被断了。呃,好啊,这个嗯。不说了,然后。底下这个东西啊底下这个东西画了一个图,就是射门的一个状况。
这个东西呢是大家可以看到to box two box指的是我离进去有多远。啊,不应该说我就离近禁区有多远,to box指的是在不在,应该是在不在进。
进区里面嗯这个地方OK你自自己去看一下上面的这个一个运算啊,因为这个这个ipad notebook也是有有有有一阵子了,但是。就是做这个东西还挺好玩的。
然后typeab等于一说明是一个呃在他现在想看的是在禁区里头的一个传球或者怎么样啊,所以这个地方type等于,反正type等于一的话,应该表示的是一个传球,对吧?如果刚才我们看到的话,pass。
From box。等于fse,然后periods等于一表示说我是上半场,大家去看一下的period总共有3个一和2,还有一个是加1,所以现在是一是表示在在上半场,然后outcome是等于零。
表示说成功了,outcome等于一表示没有成功我做了一个统计。然后我把它画了一下,所以这个地方有joeven啊啊joeven把它画出来了。所以你看到底下有不同的颜色,红色有黑色。
他们分别表示了就是这个有没有成功的,把这个求。就就是就是是是是那个有没有成功的进入,把这个球传到禁区。

进区内的一个表现啊,也是一个统计也是一个统计。这个我不给大家多说了,就是groupod by team name以后,刚才和刚才一模一样,outcom对outcom去做了一个做了一个统计,做了一个概率。
好吧啊,之下面有个分析,有个分析是这是看的,就我我也是看其他地方的一个分析啊,就是说这个克拉莫,这是一个。这这个是这怎么说呢?就是他是一个德国的球员。然后他中中途受伤了,但受伤了之后呢,你去看这幅图啊。
如果有细心的同学去看这幅图,你会发现有一段有一段时间就是简直就是就是德国队一直被压制。然后你就会在想这个东西他们会做分析,觉得这个东西的话,如果你不了解足球啊,你想这个东西肯定是有原因的?
就是原本德国一直都很强势。为什么突然有有一阵有一阵子他的这个进攻攻式是不行的。所以你会发现大概19分钟的时候,这个哥拉莫受伤了。但是一直到12分钟之后才换上真正的替补球员。


所以你会发现这12分钟就是很很煎熬,非常煎熬。然后。这位同学呢在受伤了之后呢,卡拉莫在受伤了之后呢,到到替补上场之前呢,他们说基本上他那个位置就是一个无功能状态的一个位置。啊,你去看那些报道啊。
外国外的报道是这样报道的,说唯一做的事情就是有一个接印啊。sorry,这个打错了字啊,传了一次球,然后结果他失掉了一次球。这个数据是可以统一次统计的。所以你看我从这个数据里头啊。
这个data frame,然后我特地把这个它的关于它的这么一些event,关于它的这么一些事件给它拿出来了。所以你从data frame里头把player name等于这个car莫的对吧?
这么一些data frame这么一些数据真的数据取出来了,然后我去画一个我做一个表嘛,所以你做了一个表,你可以看一下,这是第第0分钟第一分钟、第4分钟、第16分钟、第7分钟第80分钟。
你会发现从第19分钟开始啊,19分钟往后,你会发现它这个表里头一特别少。大家能看得到吗?这个这个表。啊,具体表怎么做的,自己去看代码,好吧,这个代码其实就是把就是把data frame喂进去。
然后就去去看一下就好了。所以这个地方的话大家可以看得到啊,从19分钟往后,你会看到这个19分钟之后这三列,你会甚至是包括19分钟的这一列,你会发现一非常少。19分钟之后吧,你看到一非常少。
只有一个传球pass,这是一对吧?然后这个地方有一个还失了一次球是吧?这个地方的话okK这个地方的话是替补。上场。所以提一个表格嘛,很你从你不就是看数据嘛,你你这些东西看表现嘛。
所以你直接把数据拿出来看呗。所以你看了,然后这个下面这个我不说了,就是把那些对应到刚才我们说的那样一些。场景的这么一些。event拿出来data frame和action行为。好吧。
然后下面这个地方做了一个柱状的一个统计,这个柱状统计我也不说了啊,柱状统计就是表明你看你看这个在这位同学在第19分钟之前,19分钟之前,你看还有这么多的这么多的行为呢,就是他至少他表现还是挺好的。
就是还是比较积极的,结果发现19分钟之后只有3123好OK。呃,没问题吧,这个没问题吧,它只是一个表示形式而已。你把它你把这个柱状图换成别的图没有问题。大家想换成什么样的表达方式都可以。因为可视化。
它就是一个它就是一个给人直观。可是这个mpro label去画图,做可视数据分析的可视化的话,就是只是给人一个直观的。一个展示方式,我看到这张图我就能知道发生了什么。
我看到这张图我就能知道现在是什么样的一个状况。啊,到目前为止,大家有问题吗?到目前为止,大家有问题吗?我代码给大家了,大家可以可以去啊自己run一下。呃,没有没有问题的同学回个一好吗?
表示每次上课都比较担忧我是不是?合适。好好好,我有看到三个一。好好嘞。😊,行好,然后。咱接着往后说啊,上半场分析完了,下半场就快一点吧。就是直接给了结论。我说下半场的话就势均力敌很多了。
我可以按照上半场的方式去画图啊。这个图我不给你解释了啊,下半场你会发现并没有并没有德国占据主要的攻式,而是德国和阿根廷是大大致上是。势均力敌的。对吧你看到阿根廷有这么多次到了德国的这个办场。
然后德国有这么多次到了阿根廷的办场。所以你去你再去做一个统计的话啊,你再去做一个统计,你就会发现这个时候。德国是0。59,阿根廷是0。41。呃,虽然还是有一些差距啊,你从这个图上也是能看出来。
还是有有一点点差距,但没有上半场那么。差那么多了嘛,上面场一个70%,另外一个只有30%都不到,对吧?好,所以一样的去看他们传球的一个。成功率你会发现传球的时候,成功率1个0点,德国是0。83。
德国是很严谨的球队啊,就是素质比较高。阿根廷是0。81,你发现差不太多,对吧?并没有差特别多。

哦,下面是一些同样的一些绘图,你可以看一下,你会发现这个时候呢呃阿根廷也能有一些还不错的这个射门或者是传球。虽然德国显然还是比他们要稍微稍微要要要强一些。

嗯,对,就是在这个。禁区禁区这个位置。除了上半场和下半场,其实还有一个加时的部分,也就是我们一个一补充嘛,加时的部分。
所以exual time data frame extra time里拿出取出来的东西呢,就是德国队和阿根廷队的一个。加室部分。加实部分到底是谁占据主导优势呢?来看一看。不是主主导优势。
就是你发现一个很有意思的事情啊,就是。开始的时候。德国队。一直都。站站着球呢,就有到后面的时候,阿根廷猛的出了几次,对吧?而且你你可以看看这个射射门的位置啊,你看。你可以发现德国队基本上就不勤于射门了。
这有一个射了一次OK这也射了一次。然后中间很长一段时间就是禁默期。这有一个很有意思的分析啊,就是你你要真的去对他们去做一个分析的话啊,做一个统计。比如说这个传球的次数啊,比如说这个呃射文的次数啊。
你就会发现说德国传球的次数就是这到第四阶到这个阶段啊,到这个阶段,德国队和其他阶段很不相同。德国队明显就减少了传球的次数。那那他是在干嘛呀?他在耗时间呗,试图控制比赛。因为现在如果比分已经领先了的话。
我就把节奏放慢一点了。这样的话就们能把把这个时间拖到最后,反正你也进不了球,球一直空在我自己脚底下就好了。所以你可以看看德国对上一级射门之后的数据,其实这一点就体现的比较明显了。就是上一个进球之后。
后面的东西的话,一些类似的可视化,我做了一些就是捕食阶段的一个情况啊。OK然后发现阿根廷也是比较比较惨,阿根廷只有一记圣门在大概是在这样一个位置。然后你去看一下,他会它出自于梅西梅西之手。但是。

呃,OK这个地方的话。哦,不对,这个这个图我我解释错了啊,这个图的话左边是jamany's defense,就是这是德国队的一个。这是德国队的一个防守区,这是阿阿根廷的一个 defenseense。
所以这个时候的话呃德国队是基本上不打算继续射门了,他只有一次是试图把球传进禁区的,就大概在这,大家可以看到这个图上啊,只有一次只有一次是试图把球传到禁区的。但他们防守的策略其实还蛮成功的。
以至于阿根廷的话,其实阿根廷比较难到他的禁区。你看他传他的各种。



就是球都都都没有到进去之内,就包括传传球的这个点啊或者各种东西。

你发现有2G的射门是红色的,红色这个是2G的射门。红色的这两级射门呢是全都是进区外设的门,就是没有到进没有没有突破,就是没有到进区内啊,进区外去做的射门。然后上完之后呢,就是也没有进。
所以梅西这个时候可能也比较绝望。哎,这个同学截的这个图是在哪儿?我不在是在啊。

哪个位置这个位置吗?你说什么?NP点min不太一致啊,我我没没太明白你的意思。我不是特别明白你的意思。你只需要保这是不同的阶段Pro就是上半场下半场补食阶段。那每个阶段的话,当然。
all offense应该是。不一样的呀。阿根廷的话上半场是0。27嘛,但是我统计住啊,德国上半场是0。61。然后你会发现上面的这个东西加上这个东西。基本上是。

对。是。呃,这个大家自己去看一下就好了。MP点 mean就是一个概率一个概率。然后我们可以看看它的一些看看关键的射门,你是可以用这个东西画的,你可以用jo pitch去把这个球场画出来。
所以整个球场你画出来了。然后你用jo events去把里头的事件画出来,但我只需要我我画这个事件的话,实际上我画我画这个。大家可以看到这个地方是一个传球,最后射门的这么一个。

整完整的一个路径,传的一个路径。呃,好,然后我们再往后看的话,做了一些其他的一些分析啊,无非就是一些运动员的一些分析了。
所以germany's player involved in the play德国的球员比赛中的一个情况啊,in the play在比赛里头的一个情况,所以就统计了一下这么多player这么多啊球员。
然后他们都这个有什么样的一些,比如说这个地方type name就是他是什么样的行为,传球对吧?这个带球跑带球跑,然后怎么怎么样,progresss progress是我们的一个统计值啊。
大家我大家去看一眼就好了。progresss啊sorry progress是我们刚才做出来的data frame里头的一个值啊。然后会有一些基础的一些数据,基础的一些数据。
然后大概是他们里头有多少个行为等等啊,然后有多少次是成功的等等等等等。啊,传球有多少有多少次传球有多少次是传球是成功的一系列的统计数据啊,每个球员。OK这是做了一个表。做了一个表。嗯,好。
下面的东西的话就是类似的,就主要看你主要看你关注什么点。比如说你关注的是这个有没有进球,对吧?这个有。ok然后然后这个有没有射门,对吧?然后等等等等等等。其他的一些。过人。啊,好。
然后这是这个呢这个ipad不我还是没有太明白这个问题。因为我现在不能把你这个图放大,因为我放大的话会出现在这个框里头影响其他同学。看这个课了。呃,咱们这样吧,咱那个下课下课以后下课以后我帮你看好吧。
这个问题这个同学,然后我们先往后讲,好吧。所以这是一个大致的一个分析,它是一个模板。所以有了这个东西之后呢,如果啊你可以去看看这个这个网上有没有其他的一些,比如说呃。一些甲级联赛啊或者其他的一些东西。
你可以你可以试着用这个东西做一个分析啊,可以做一个分析,还还挺好玩的。就是他还是能说明一些东西的。至少现在这个数据分析不是那么的枯燥啊,不是全是数字,我也有能做一些可视化,能看到一些图。


人工智能—机器学习公开课(七月在线出品) - P19:特征处理与特征选择 - 七月在线-julyedu - BV1W5411n7fg

我们来说一下统计特征。那统计特征呢是历届的这个cago啊或者天池比赛呀,然后那个以及在天猫京东的排序啊,还有推荐业务里面经常会用到的一些特征啊,这个就是我们说的说和业务。贴贴合非常非常高的。
贴合度非常高的这样一些特征。比如说啊举个例子说,加减平均是最简单的了。呃,这个这个用户买的商品高于全部用户买的商品的一个平均价格高了多少,那可大概可以平衡可以权衡他的一个消费能力,对吧?
然后用户的连续登录天数超过了平均水平的多少,这个能够表明用户的一个年在这这个app对这个用户的一个粘性有多高,对吧?然后我们刚才说了分位数,对吧?商品处于售出商品价格的多少分位数分位数分位线数。
这个分位线呢可以体现它的一个购买能力,对吧?我们刚才说了,分位线是我们把所有的价格购买商品的这个价格从小到大做了一个排序。然后排序之后,它大概处在哪个位置?是这样一个东西啊。
比如说20%分位数就是20%的人。买东西都会低于这个价格。最最特最。底端的20%的。这个位置这个分位线,然后呢,还有排序型的对吧?还有比例型的,就是你已超过全国百分之多少的同学。
经常你会看到呃360会会会跳个框出来,说你已超过你的开机时间已超过全国多少多少的电脑,对吧?就是这种这种比例型的。这种特征也是非常非常有用的。呃,我们来看一个例子。
这个地方有一个天池的一个大数据的移动推荐算法大赛,然后给了两个表给了两个表。第一个表示。用户。商品,然后用户在这个商品上的行为,包括呃浏览、收藏呃,加车购买。他给了4个值啊,1234。
然后这个东西是一个你你不用管这个东西的话,实际上我们我们在电商里头自己是可以拿得到这个可以拿得到这个具体的用户的一个位置的。但是但是我们我们拿出来给大家比赛的时候,不能暴露这个信息啊。
这和个人隐私有关系。然后这个商品是什么类类目的?我刚才说了嘛,要按品类去切,所以。他会告诉你这些牛仔裤的品类,或者这是一个上衣的品类,他不会这么明确告诉你文本啊,他会给你一个品类的一个编号。因为脱敏了。
这也是一部分敏感的数据。然后会有一个时间,就是用户什么时候做了这样一个行为。第二个表呢是。商品相关的一个一个表,刚才是用户,对吧?现在是商品,也是这个商品一个编号。这个商品大概在哪个城市,对吧?
在在上海卖,还是在北京还是在深圳。然后这个商品的一个类别啊,也会有这样一个他提供了这样两份数据。然后呢。让你去给了你数据之后,让你去预测一个月的。最后两天把什么东西推荐给用户,用户最容易点。
我们看看他我们看看这些比赛的同学们造了什么样的特征,有用的特征啊。呃,他们先定了一些规则,他们认为前一天的购物车里头。的商品很有可能第二天会被购买。这个大家应该是自己也会有体会啊。
有些同学买东西的时候会会先不会习惯收藏,他会先习惯把这个东西先加到车里头,然后可能明天或者后天就买了。然后他会剔除掉在30天里头从来不买东西的人,这个是一个数据信息,对吧?
因为这部分数据对我们没有什么用。接着呢有一些同学他会加加车连续加4件,但他只买里面的一件。那我们认为剩下的这些他基本上是不会买了。好了,这这个东西是我们定了我们做了一些数据清洗,并且定了一些规则。
我们来看看我们做了哪刚才在刚才那个我们说的那个。连续值、离散值、时间维度,他们分别做了一些什么样的特征?购物车的一个购买转化率。大家想想,每个人肯定加车以后买的概率不一样嘛,对吧?
所以我我对每个用户产出了这样一个东西。有些人可能加车了就会历他历史所有的信息都是加了车,他就买了。所以呢我我那我转化率高的这这个这部分人我可能直接就用他加车的这个东西去做推荐了,对吧?
或者和家车相似的东西去做推荐吧。然后商品的热度这个很明显,对吧?因为因为比较热的东西肯定是大众比较喜欢的,所以它是商品维度的一个统计特征,热度嘛,而且是一个连续值,对吧?
你可能会用它的销量或者什么东西来来代替销量的话就是一个连续值嘛。然后第三个是对不同的item点击。这些这对不同的item的。呃,sorry,这个东西的话应该是商品维度。
但我我大家不知道我这个地方不知道说明白了没有啊,我我的意思是,现在有一个商品在这有一条牛仔裤在这儿,这条牛仔裤被点了多少次,被收藏了多少次,被加了多少次车。被多少人购买过,有4个连续值。
所以它是商品维度的统计特征,但它同时是一个连续值的特征。也就是一个时间段以内的一个连续统计的连续值特征。然后包括用户维度的会有些统计特征啊,那每个每个用户可能也会对不同的item。
不同的这个商品会有点击,会有收藏,会有购物,会有购买和加车的行为,对吧?我们把这个也统计出来了。包括。变热门的品牌和商品,这个的话是一个X值型的嘛,对吧?我们刚才说的统计里面做差嘛,你今天有多少人点了。
减掉昨天的。看看这个数有多大,今天有多少人买了,减掉之前一天的那这个数有多大。如果这个数非常非常大,意味着这个东西逐渐的在变热。最近的一天两天、三天、7天一周的行为数与平均行为数的一个比值。
大家可以看得出来,这是一个统计维度的一个一个特征,对吧?是一个用户维度,用户维度每个用户他有些用户他就是点,我就爱点,但我就不买。所以。所以他会从几个从几个每从总的行为数和每一个行为数上去看一个比值。
因为有这样的话,你可以分析出来不同用户之间的一个差距。因为有些用户就像我说的,他就爱点,他就不爱买。有些用户他点的非常少,我点了一定会买。所以。我们会拿到一些笔值的一些特征。
然后会有商品在类别中的一个排序。这个大概是你可以按照一些别的东西去排序啊,比如说热度或者是呃被点击量购买量。然后这个呃它有多新,上架的时间有多长等等去做一个排序。包括商品交互的总人数。
这又是商品维度的一个统计特征,对吧?是求和型的一个特征。也就是有多少人在这个项目商品上有有什么行为,你可能总人数有多少人在这个商品上有会有行为。然后会有些其他的,包括包括商品本身的一个转化率。
刚才我们说了人驾车以后会有个有个有个转化率,对吧?那商品的话,有些点进来了以后。或者说我展示出来之后,这个商品展示出来的次数和他被购买的次数之间是什么样一个状况,对吧?有些商品他可能基本上每次一出来。
有些人可能就买了。然后有一些商品的话是暴露说展示了很多次,但没人买。所以。这有个转化率。然后我们总的平均的这个类别,这个类别比如牛仔裤这个类别,它也会有一个转化率,对吧?然后这是一个比值。
所以也是比值型的一个统计特征。然后刚才说了很多统计型的连续值的统计一些特征。然后我们现在来看看它也会有一些。刚才这个还是一个比例型的啊,是商品的行为处以同类行为的一个均值。对我们需要开一个时间窗口。
我们只统计,比如说前一周或者是前最多拉到一个月呃,得看啊,如果是对全全个每个季度的东西去做推荐的话,是是你是可以拉到拉到3个月的。这个时间窗口你自己也会根据具体的情形会去定。然后我们看看最近几天。
每次我们约束最近几天的话,其实会有一个时间型的一个一个东约束在里面,对吧?我们看看我们对时间型也做了一些探讨。比如说最近的这个交互,离现在的时间。比如说对你在1小时之前加了一次车。
或者1小时之前点了3次,这样的话很有可能你对这个东西是感兴趣的对吧?所以是最近的这样一个交互到现在的时间,总交互的天数,总交互的天数呢可能代表的就是这个人的一个这个商品对和这个人之间的一个一个关联度。
呃,总总交互的天数表明这个用户对这个app的一个一个关联程度有多高。呃,后面是一些别的一些统统计特征,用户于对品牌币的总购买数除以收藏数、购物购物车数,这些都是一些。求和。然后平方。购买比一些比值。
对吧?我们看看他还还做了一些别的一些一些这个时间性的一些特征。比如说前一天最晚的交互行为时间。这个有什么用呢?这个和用户的习惯有关系啊。因为有些人他可能就是。夜猫子或者说他就喜欢扮夜购物。
然后还会有一些用户购买商品的一个时间。就是这个时间是到到也还还还是一天之内哈,就是平均他会在一天的哪个时段去去做去买这个东西。最早他最早一次是在比如说早上7点或早上6点买了,最晚一次是什么时候?
然后平均是什么时候这样一些时间型的一些特征。总共就是用这么一些特征去最后就分析出最后建模之后拿到了一个比较好的结果。你看它分析的维度非常非常的细。各种统计型的特征,包括连续值,包括。时间行。
然后我们刚才说了,这里头有类别嘛,品类嘛,所以它它有类类别型。呃,我们刚才说完了前前面那个例子,我们再说一下组合特征啊,组合特征最简单的组合特征是拼接型。什么意思呢?在逻辑逻辑回归这种模型里头。
你可以直接组一个U子 IDD和一个品类的。这样一个特征,也就是一个人买了一条牛仔裤啊,这个用用户10001的用户买了一条女裙,那我就直接组了一个特征。这样一个特征。如果这个人买了一条裙子。
那这个特征就是一没有买这个特征就是零。如果他买了男士牛仔裤,那就是一没有买,就是零。我加了一个维度,我在原始的数据上加了一个维度,这个维度填零还一。
或者是填每一条记录填零还是一取决于当前他有没有买这个品类。包括风格对吧?我们刚才说了全棉的对吧可能对材质会有要求。呃,那在实际的这个电商的点击率预估里头呢,它表明的东西实际上是一个。
正他的正负权重实际上表明是用户对这个东西喜欢不喜欢。比如说这个10002这个U子 IDD和这个男士牛仔裤组成的这样一个维度的特征,最后拿到了一个权重是0。5,是一个正的权重的话,表明什么呢?
表明这个用户很有可能他以前买了很多的男士牛仔裤,很喜欢男士牛仔。所以你可能会在去出现男士牛仔的时候。出现牛仔的时候,会把男士牛仔的东西排在前面。呃,然后这个是非常粗暴的方式啊。
就是我直接把两个维度的特征拼在一块儿,然后。有的话命中的话就是零,没有命中的话啊,命中的话就是一,没有命中就是零,多加了一个维度,丢进去做训练。另外一种一种方式呢是facebook最早在开始使用的。
很多家互联网公司现在也在用啊,一般是像像点击预估这种排序这种问题里头经常会用到的,我们会先用一个别的模型。比如说像GBDT它是一个树状的一个模型去产出一个特征的组合路径。然后呢用这些路径。
当做刚才的这个组合特征去判定。如果命中了这条路径,就是一没有命中取0。嗯,一般他们用的方式都是GPGT加LR。叫逻辑回归。呃,这个地方举一个例子是,你看这个树形的这个这个model。
这个模型做判定可能是这样做判定的性别省份,然后联网方式是用手机还是用用的电脑,那很可能是性别男性的,然后。上海市的。用手机上网的人可能会去做一个决定,做一个决策。那我现在就把这个性别。和这个省份。
和这个联网方式去做一个组合。如果命中了上海呃,命中了男性。上海用手机。大风。上网的这个人就给一,但凡他是女,或者说不在这个省,或者说联网方式不是用的手机的,我这个位置就给0。
所以用GPDT得到了这样不同的角色路径,然后每一条路径会把它视作一个特征去做这个事情。然后编码之后得到了一个向量,最后把这些样本向量放到逻辑册回归里头去做训练。嗯,然后我们说说特征选择啊。
特征选择的背景是这样的。呃,因为我们有荣誉,有荣誉的原因是部分特征相关性太高了。比如说你现在造了一个特征,他是表明这个人是年轻人还是呃表表明这个人年龄大还是小。然后你有一个特征是他年龄具体数值的大小。
所以呢这两个东西本身它就是很等同的对吧?因为年龄你数值你年龄的值非常小,其实它就非常年轻。所以呢这两个特征非相关性太高了,那你会消耗计算机的性能。同时呢。而且数据量大嘛,你消你你消耗它的性能。
它就会变慢,而且你提供不了额外的信息。另外一点是可能会有噪声。就是有部分特征对于这个预测的结果甚至是有负影响的,是有可能有这种情况的。然后我们说说特征选择和降维啊,呃特征选择是这样的。
原本可能有50个特征。如果做特征选择呢,是指的在这个特50个特征的基础上挑出来里面,比如说30个。只是我把另外20个不太好的踢掉了。减掉了这20。那降维他做的事情是什么呢?降维做的事情是。
去做去相关之后,把里面有用的成分拿出来了。呃,大家之后会会这个部分会会细讲啊,这个降为SVD和呃PC肯定是。会再拿出来细讲的一个一个算法。因为它是属于无监督学习里头比较重要的一类算法。
这个他们是用来做降维的那特征选择和降维的区别就在于说特征选择我不会改变原来的特征,我只是从这50个里头挑出30个了。那降维呢是会对原来的特征去做一些组合,做所谓不是组合做一些运算。做一些计算。
我们会拿到一些新的一些一些特征,但它是一个排好序的。我们可能会把一些后面一些相关度不太高的,会去掉。常见的特征选择的方式呢有3种。第一呃,第一种叫做filter型的过滤型的,它非常的简单。
非呃非常的粗暴。这种方式非常的粗暴。它会去评估每一个单个特征和结果值之间的一个相关度。然后平安,也就是说如果你有10个特征。你有十个特征的话,这是我的结果Y,对吧?这个是X1,这个是X2,一直到X10。
那他做的事情呢,就是我要看X一的时候,我就把X2到X是物主,我不看它了,我只看在这一维上和这个Y的一个相关度,相关程度有多高。然后我们评价的一些指标呢,包括皮皮尔逊相关系数啊、呼信息和距离相关相关度。
呃,这个的话,但是这个方式呢这个方式。他只评估了单个特征和最后结果的一个相关度相关程度。所以呢他缺点是因为特征之间可能会有关联的嘛。有时候你一个。年轻的20岁出头的女性和一个。
489岁的一个女性是不一样的对吧?那所以呢我们我们他就没有考虑到特征之间的一个关联程度。所以实际上嗯我们我们现在这个就是工业界并不会频繁的使用这个方法啊。所以这个地方的话。
你看比如说我们我们先我们就这个东西是一个平衡,是一个评价相关pearson是一个相关系数,评价他们相关度的。我们产出了一个X是什么呢?是一个正态的一个分布normal的一个随机的一个正态分布啊,然后呢。
我给它加了一部分东西,加了一部分。波动很小的一部分,一个正态分布加叠叠加叠加在这个上面,然后我们去评估一下他们的相关相关性。然后我又加了一个。方差非常大的一个正态分布加在上面,波动非常大的。
我们再去评估它相关性。你就会发现刚才你叠加小的这个正态分布的时候,它相关性是高的。也就是说,在原来X的基础上,我只有一个小的扰动。所以和原来的X之间的相关度是高的。
但现在呢如果你加了一个波动非常大的一个生态分布,在这的时候,你会发现相关度就变低了。所以这个时候它是比较高的noice。呃,也就是这种情况下,这个东西和这个东西之间的相关度是低的。呃。
那实际上我们在实实际评价特征和结果之间的一相关度的时候呢,很有可能你就把X一的这个向量直接丢进去了。作为一个向量把Y作为一个向量拿进来求一个相关度。如果这个相关度比较高的话。
我们就留下来相关度比较低就不要了。这是对单个单个特征的处理。过滤型的这个方式filter的这个方式。我们刚才说了啊,它是一个一个特征评估的。
我们在pyython里头syd learn sK learn里面会有一个会有包给大家去做这个事情,叫select key best。呃,然后select personal,我们说说这他们的一个区别啊。
s select k best是指的我现在总共有4个特征。比如说这有个数据集啊,这个是非常有名的一个数据集叫irris是画瓣数据集有4类呃,不是有4有4个观测维度,四个特征。
我select k best指定KV2意思是你跟我去评价一下这四个维度的特征和最后Y的一个相关度,然后把相关度最高的两个返还给我。对,所以这个函数。意思就是在这个X里面,我不管它有多少维。
我可给你指定一个K以后,你去每一维给我验证一下它和Y之间的一个相关度,然后把最高的。相关度最高的k给我返还回来,就这意思。然后perile呢,这个是一个比例啊,意思是什么呢?因为这因为你指定个数的话。
有时候会特别的特别的粗暴。如果他有50个特征,只取两个的话,那可很有只取相关度最高的两两个的话。很有可能就。那那你拿到这个特征就没用了,可能它的区分度是非常高,单个特征区分度非常高。
但有一部分有用的信息就被你刨掉了。所以呢怎么办呢?我们这个有一个函数叫personile,这个函数可以帮助我们去拿到百分比。比如你要预留0。5,我就会留下一。50%的特征。如果你要0。6。
它就会留下那60%的特征,它会去评估。比如10个特征,如果你设为0。5,在这个里头se selectlect personal这个函数里头会有一个参数啊,你设定这个参数是0。5的话,它会留下5个特征。
相关度最高的。如果是0。6,它就会留下零下留下6个。好,然后我们看看。第二类,刚才那个说完了啊,它的评价方式过滤型的评价方式就是一个一个特征看。第二种叫做包裹型rapper形式的特征选择。
他做的方式是什么呢?他把特征选择看作一个特殊的子集搜索的一个过程。大家想想啊,全部的X它是一个N维的一个向量嘛,对吧?那包裹型在做的事情就是我从这里头拿取一些维度出来组成一个子集,对吧?
看看这个子集的效果,我们会用模型去评估这个子集的效果,不再是跟像刚才啊刚才和模型完全没关系,刚才只是评估X和Y之间的一个相关度和模型完全没关系。好,现在的话我们会用模型,我们会去run一个model。
评估它的一个效果怎么样。所以呢。我们会。挑最有用的子机。但实际上我们。实际工业界会用的一个方法叫做递归特征删删除法啊,叫recursory feature eliminating algorithm。
那这个方法是怎么做的呢?注意看步骤是这样的。我们先会用全量的特征去跑一个模型,就是我你有N为对N个特征,对吧?那我不管全拿过来吧,我们跑一个模型吧,所以就出了一个模型。拿到这个模型之后呢。
我们肯定会有一个评估的标准,对吧?比如说点击率预估或者台序里面我会用到一个叫AUC。这样一个评估的标准,这个标准呢。不细讲了,它是会平衡准确度和召回的两个维度的一个特一个评估的准则。
我们会拿到这样一个值,这个值越高,表明它的效果越好。好,那我现在全量的跑了一个,那我怎么办呢?我会根据线性模型的系数,这个怎么理解呢?我们之前不是有逻辑回归这个算法吗?
逻辑回归不是西塔一乘以X1加西塔2乘以X2吗?大家想一想,如果前面这个西塔大,是不是表明它这个特征它的决定作用非常大呀?所以呢我会把这个西塔非常小的这一部分特征。制作相关度很小的特征。
也就是说总共有总共有100个特征,我会有100个特征,就有100个X,对吧?有100个西塔,我取出里面最小的5%到10%的西塔对应的这个特征,把它去了,不要它了,留下剩下的90个。
我我再放到这个模型里面去run一个。model再去评估1个AUC。这个时候呢,如果这90个比刚才这100个。要好,是真的是有要好的时候,有时候你删掉的一些噪声的一些特征。要好或者是。
不差与它没有太大的变化啊,那没关系,刚才这些说明是弱特征,我不要它了。紧接着呢它又循环去做一和2呃,我错了,循环做第二步,我在这90的基础上再删10个或者8个特征,C塔最小的10个或者8个特征。
再去跑原模型,看一看现在AUC的变化呢,直到。你看你的评估标准啊,如果是准确率,你就用准确率。如果是AOC,你就用AOC出现大的下滑。比如说你现在已经有50个特征了,你再给他减10个特征。
你突然发现减完这10个特征以后,你AOC挂一下掉特别多啊,那不行,那说明这10个特征是有用的,你该停了。所以你现在就停在这儿了。娶了50个特征。实呃我们回答一下问题啊,有同学问说。
实际项目中往往是先做特征工程,再做呃选我在做特征选择。呃,是这样的,一般一般的步骤是这样的。因为我们得先确定我们得明确有哪些特征,我们才知道要在哪个全集上去做一个做一个做一个删减嘛,对吧?
去做一个选择嘛。所以也确实是这样的,是是先做特征。工程,然后再做这样选择。然后我们来看看说有同学问到说这种方法对半监督学习适用吗?嗯,办监督学习的话。之后再提吧,班监督学习的话。
其实主要有用的作用还是前面那部分有有就是有间有外的那一部分数据,它只是。没有外的那部分是泛化出去的啊。呃,瑞有同学问到filter那个函实践函数里用的是什么算法啊,我们只是定义了一个相关相关系数。
然后会去评评估一下这个相关系数的一个大小,做一个排序啊。好,我们接着往下看,因为我们刚才说了,第一种是filter过滤型的,我们是评价单个模单个特征的一个相关度,而且和模型没有关系。
现在第二种是包裹型子机搜寻,而且它和模型有关系。我们看看包裹型的话cycl learn里头给的是一个 RFFE什么叫RE啊。
我们看看刚才我们这个东西的名字叫什么recursive eliminating algorithm RFFE对,就是这样一个算法。这个算法呢?实现的就是这样一个函数,这个函数里面会有几个参数。
第一个参数是你需要告诉他我用什么模型来评估。刚才我们这个算法以后,大家不是看到了吗?我们需要一个模型来需要先跑一个模型,对不对?那这个模型没有说剩点什么模型。所以你要在这告诉他,你说我要用逻辑斯的回归。
我要用SVM等等放在这。第二个是。Yi。需要选你需要。那最后要留下多少,最最少要留下多少个feature。比如说你填50,那可能100个特征,我跑了,我最后我逐步的删减,删到50个的时候就停了。
然后包裹型的fishature选择特征包我们看看这个地方有一个有大家稍微看一下就知道这有一部分数据啊,这个叫boston就是波斯顿房价的数据。这个数据呢我们X就是里头的一些特征。Y就是里面的结果,对吧?
就是房子的价格,然后我们会呃names是这个fisher呃这些特征的一些名字。紧接着呢我们用了一个逻辑回归lineal regression去对。你看啊大家看到RFE这就是我们刚才那个特征。
特我们刚才特征选择的那个函数,包包裹型的特征选择的那个函数。我们告诉他,我们要用的是逻辑斯特回归。我们告诉他我们。这个地方最。一直要重复,直到留下最后一个,对吧?就是我们一直用包裹型的这个方式去求子节。
每次删掉一定一些特征,删掉一些特征。直到最最多你可以只留下一个,然后我们现在去feate一下,意思就是呃猜迁论里头函数都是这样封装的啊,fate就是你可以理解成就是开始跑一下。
或者是开始 run一个模型。然后我们把他们之间的一个排序拿出来了,这个排序就是他们相关度相关度的一个排序。就是我们要最早删掉哪个,最晚删掉哪个。包裹型的特征选择会是会增加计算量。但包裹型的特征选择呢。
大家想想我们每次删的时候,我我这么跟大家说吧,你想想啊。我们刚才有很多特征是怎么得到的呀?是通过特征映射达到的对吧?不不管是one号 encodingone化的编码还是什么编法得到的。
所以它是突然从一个域,比如说价格这个段价格,单价格这个域,我们给它拿到拉当单pri这个域我们给它拿到一个特别长的向量,对吧?那我们实际上在做特征删减的时候,我们是按域来的。
比如说价格它映射的这个向量程度可能就有100维,那我就会直接把这100维都删掉,我们不会一个一个删啊。那样的话,太慢。可以在小数据器上做包裹型的特征选择。可以。呃,好,我们说说第三种。第三种是工业界。
反正我之前做的时候,我我我左用在用的方法叫做嵌入型。呃,这个翻译的不一定很精准啊,教恩。叫嵌入型嵌入型的这个特征选择方式,他是怎么做的呢?大家刚才知道我我我上节课说了罗辑斯的回归的形式是。
我们在soidoid函数里面是西塔0,再加西塔1X1,再加西塔2X2再加加加一直加到西塔NXN对吧?那我们训练完了之后,每一个特征X1X21到XN都会拿到一个权重,对不对?这个这是线形的模型。
linar的模型,对吗?线形的模型相关度、权重的大小直接能够表真这个东西的特征的一个相关度。所以如果C塔。非常的小的话。会说明这个东西没有太大的作用。C塔大的话作用会比较大。
我们会用非常极端的一个正则化的方式。大家还记得正则化吧,昨天说了LE正则化这个正则化会有什么样一个作用呢?叫做截断作用。也就是说,当你给我的特征非常非常多的时候,我用LE阵策话拿到的结果是什么呢?
如果你这个特征。你如果你这个特征没有什么用,我告诉你他的权重直接会拿到0,没有权重。直接会是零,没有权重,只有相关的才会拿到权重。
这个方式好这个办法好的方式好好的地方在于说我比如最早在电商电商里面如何用逻辑回归去做CTR预估点击率预估的话,我们当时在3到5亿维的这个系数,3到5亿维的这个。特征上去用LE政策化。
最后只会剩下2到3000万的feature是有权重了,其他权重都是0。如果你用L2正则化的话,是会在E级别。会会有权重,它是1个L2L1阵的话是阶段性效应。就是如果。没有什么相关性,我就不要它了。
拿到权重就是0。然后二阵则话是一个。缩放效应,也就是最后拿到的权重都会很小。嗯。我们看看嵌入型的这个pyython。刀啊。这个包呢叫做select from model。
也就是你给我一个linear的 model。大家注意看啊,这个地方这个model我们没有说过,它是SVM的一个有model,但它是linear的,是线性的,意味着我们不会去做线非线性的那些和那些特征的。
高次的特征的映射或者是其他的一些组合映射。我们只在这些特征前面加特征,只对这些特征就做一个线性组合,拿到拿到最后这个模型。凡但凡是这种线性的模型,我们都可以用这个方法叫select for model。
这个方法呢。就会根据LE政策化。和这个模型去拿去选出来里头权重大于零的那些特征,其他的那些特征他就不要了。呃,比如说还是刚才这个数据集叫艾瑞斯,大家记得对吧?它的维度是特征的维度是四维。
那如果我用一个线性的一个模型,liner的一个模型。我们用的LE正则化,我们用了这样一个函数select for model。然后。去做完之后,你就会发现我们挑出来了3个,我们告诉他这三个是有用的。
最后那个用处不太大,不要谈了,没有拿到权重。所以如果大家用pyython的话,可以用这个我们在s learn里面feature selection这个 package里头有个函数叫s叫select from model。
然后你配给他一个线性的一个model,比如说 linear S SVC比如这是SVM。比如说你配给他一个 lineararlog regression,对吧? linearar的逻辑回归。
那它就能从里头给你选出来权重不为0的这些特征。呃,好,这今天我们这个特征选择和特征工程的。

理这个理理论讲课的这部分就到这儿。

人工智能—机器学习公开课(七月在线出品) - P2:18分钟理解EM算法 - 七月在线-julyedu - BV1W5411n7fg

🎼,EM算法如何去做呢?这样哈就是说呃假定有M个样本。并且我们认为是独立的,我们想让里边去得出这个样本的概率是PX,但是呢可能有引变量Z。那这样我们想得到PXZ它的这个模型的参数。
比方说对于我们这个身高数据而言,X是身高Z就是性别,对吧?我们就要得到带引变量的概率分布,这就是EM算法哈,它怎么做呢?这么来考察哈。首先我们仍然是利用极大自然估解。然后呢,PX这么一个东西。
它的参数可能随塔了,对吧?反正总之是这么一个概率分布,然后呢对它乘积之后取对数,那就是先取对数再再加和嘛,对吧?因为M样本,所以写成这么个式子,这个是我们的目标函数自然函数对数自然,对吧?
对这样一个对数自然呢让这个Z暴露出来,怎么办呢?我们这是一个PX这是一个边缘分布,对Z做划分,因此这就是PXZ这么一个联合分布,对Z求积分,就是加和积分一个意思,对吧?对Z求积分把Z积掉,就是PX嘛。
所以说这是这样一个东西,这是把Z把它强制暴露出来得到这个数值,这个就是我们的对数自然函数,现在我们需要估计这么一个主题,对吧?怎么做呢?首先这个Z是一个引变量,直接做是不方便的。我们可以怎么做呢?
先对这么一个自然函数,如果能够得到这个自然函数严格大于等于某一个数。我们先说想法哈,先说思路,框架型的东西。如果这个东西它是大于等于某一个值。然后呢就是严格大于等于某个值某个函数哈。
就是大于等于某一个未知的一个简单的一个函数。并且我们方便求出那个我们大于等于那个函数,它的极大值。我们如果能求出这个事情来,那么那个新的函数的极大值总不于比它要小一点嘛,对吧?那么说我们用。
简单的那个函数极大值来代替它的极大值,就能够使当前这个极大值稍微变大一点。不停的把这个东西迭代下去,最终使他收敛下去,得到这个东西。这就是基本想法哈。好了,我们看看他怎么做的。呃。
左边这个图呢是我们在第一次课跟大家聊过的,就是用python写的代码,然后画这个图了,还记得吧?就第一次课跟大已说过的事情哈。然后呢,我们看看利用它怎么做事情哈。首先这个里边呢这个。呃。
我们还是把这个式子写出来哈,这个式子把它拿过来,得到这个就是这个PX这么一个分布,然后取对手加和,这不数然函数嘛,对吧?让这个Z暴露出来去得到这个东西。这是刚才那个东西啊,只不过把样本体现出来。
第I个样本第I个样都做一遍,因思是这个东西哈。假定说对于引变量Z而言,这个XI这个这个样本哈,它就带着1个ZI。比如说1。90那个样本,它就背后带着一个0。9倍的男,0。1倍的女对于1。
55那么一个样本,它带着0。2倍的男0。8倍的女,对吧?任何一个样本,它其实都背后带着一个引变量Z的,对不对?OK我们就假定第I个样本的背后的那个引变量Z,它的概率分布情况记作QIZ,可以吧?
这是第I个样本的那个分布QI把Z那个I值带进去,我们就认为是第I个样样本的引变量的分布,记作这个QI哈,是Z的一个分布,就这么个事情哈。那我总可以除上一个式子,乘上一个式子,它是一样的嘛,对不对?
就是这个东西没错吧。大家注意,还记得咱刚刚在这个PPT里面最开始给出一个jason不等式吗?jason不等式,这是什么?我们把这么一个分子,就是这个P除以这个QI这个式子哈,把它看作是一个整体。
相当于这个Q什么?Q是一个概率啊,相当于是对这么一个整体求期望。对不对?我们总得把这个Q把它拿到前边去,把这个log拿进来。那么这样的话,这样一个值本来按正常而言应该是小于等于的。
但是对数呢它是一个不是凸的,是一个严格凹函数。所以说本来是小于等于,这应该是凸这是凹的,所以是大于等于这么个东西。就把这个log放到里面去,把Q拿出来就得到这样一个东西。这个是EM算法的关键一步。
这一页哈理论层面的关键一步。大家再看这一页有问题吗?这一页其实跟刚才那个伽马IK那一页。两两页对应啊,这是两个最核心内容。大家看有问题吗?变符号。变符号指的是这个P这个Q吗?哦,就这对吧?
就是这从这一行到这一行哦,这个地方是吧?哦,这个怎么得到的哈?O我们再换个思路哈,刚才没听懂,对吧?换个思路哈。😊,我们这么来看哈。😊,嗯。我们来看这个东西哈呃。😊,我们现在把这个P什么时候东西除以Q。
什么时候东西,把它看作是一个数总可以吧,看的是个整体,是个数,这个数是什么呢?这个数对应着这个图上的某一个点,比如说这个值对应着五角星,这个点总可以吧。就是这个值对应的这五角星这个点。然后呢。
比方说这个这个Z啊,他可能是个男性,对吧?那我能求出来这么一个点。把Z2那个女性在带你用的求是一个点,对不对?那个点我对应着这么一个五角星这么一个点,总可以吧?这是两个点,对吧?这个Q是什么呢?
这个Q指的是它有0。8倍的女,0。2倍的男,对不对?那就相当于呃这么一条这个值,这是左边这个五角星,因这五角星,他们两个画条线段连出来之后呢,比方说左边这个是男哈,右边这个是女,我们让取0。8倍的男。
0。2倍的女,那这样意味着靠近于男的这个点在这个位置大概是有0。8倍的他0。2倍的他,对吧?所以更靠近他嘛,就这意思,对不对?所以说0。我们就对应着这样一个值,从它到它取位值出来,可能是在这儿,对吧?
就是大概是本来是这个点和这个点,它可能得到0。5左右的一个点,对不对?左右一个点哈,那对这么一个点取完了取对数,那不就是这个点取的是红色的点吗?这就是上面这个式子哈,红色这个点求出来的。
你再看底下这个什么意思,仍然是这个五角星在这儿啊,对不对?这五角星先取出来,然后这个再取出来,先取logg,那就是取完这条线段,用这个线段上靠近0。20。8,那就是在线段上取一个点。
那就是手标手在这个位置,在线段上一看这个图,线段在下边取线在上边嘛。那显然上面的大底下的小嘛。因此就得到大于等于了。对不对?😡,OK这样看有问题吗?呃。
所以这个咱机器学习班是我个人觉得哈就是还是有些价值的,真的有些价值的。就是说里面一些内容经过过我们的这个思索哈,就是说如何让大家看的更清楚。比方说这这个PP这这几页这这这几个公式哈。
大家在网上各种各样地方都能找到,这种资料是完全不缺的对吧?比方说这个我们等会有参考文献哈,是给出是在哪截出来的。这个图是我自己画的哈,为了配合这个东西来去解释的。但这个可能就在网上没有啊,对吧?
所以他还是或多或少有点用啊。这样,有人问为什么log没在Q的前边?哦。我们是什么?我们是一直把P除以Q这个这个分子这个是这个这个分式看作是一个我们的整体。对这个整体五角星在这,五角星在这去去去是对它求。
期望求Q,还是说对logg被的他求期望。对吧我们摆他那整体是对先对他求均值,再求log。还是先起logG再求均值,就这个东西,对不对?所以。呃我们一直是Q在前老在后哈,对吧?事实上。
你如果logg在前Q在后的话,相对就没了,它就光Q成Q就就消掉了,光手批了又回去了,对不对?嗯,为什么?为什么这个东西?是联合分布,而不是条件分布。
因为感觉PX givenZ在引变量Z出现的条件下出现X概率,这样解释似乎也行啊,注意这样解释是不行的哈。就说我们现在取的是联合分布。取的并不是比方说我们拿到个样本数据,拿到这个比方说1。
9米这么一个样本数据,不是说。如果是男的,他是1。9米的概率是多少,不是这么个意思。他指的是拿到1。9之后,看一下1。9这个样本和是男性联合分布起来概率是多少。比方说是0。9,他和女性是多少,是0。1。
只是干这个事情啊,不是干。当给定男女之后再看他的身高的这是两码事,对吧?OK哈,我想应该是解释清楚了,是吧?😊,就是包括这个有朋友问到是。哦,我在说哦我又又说了哈,就这个是对应哪个点是吧?呃。
他呃底下这个哈。你看哈这是一个数,这个分式我看的是个五角星总,可以吧?这是个点,对吧?他取对手,那就是这个蓝色点,这是男性的,他取对手是另外一个是女性的这个点对吧?然后让他取一个0。8倍的一个点和0。
2倍,这个点,就是一个男性在这,一个女性在这儿连起来取一个值就在这,对吧?所以说底下这个是是线段上在动,上面这个是红色的这个函数值上在动啊,对吧?所以是大于等于哈。好了,我们就完成了这么个操作,对不对?
好了哈,然后呢。😊,没错好的,没错,就这么看进去。红,因为红在这上,这个线在在下嘛,对吧?😊,下面呢我们就来解释一个事情了。那么说二者在什么情况之下可以取等号呢?这个和这个什么时候取等号呢?
只有一种情况,就是这两个五角星,它们完全重合的时候,这个线段才能够线段把它退化成一个点了,这个这个红色这条这个曲线也退化成一个点了,二者才能够取等号,只有这一种情况,对吧?这一种情况意味着什么呢?
就意味着这样一个值必须是一个常数。对吧这个值你你不能两五角星放在这儿,你得指这这五角星都得在一起,对不对?所以说这个值B是个常数P这个东西,除这个东西是个常数,也就是得到这样一个结论。
当二者相等的时候可以去等号,对吧?当二者相等的时候,可以取等号就什么意思呢?那就意味着这个东西哈,注意哈这个Qy哈,其实咱一直是假定出来的,它还不知道是啥呢,对吧?那是啥呢?
上面这个式子我们是大体上能猜出来,对不对?是X和Z的联合分布嘛,那我们想想哈PXZ这种情况给定了,想求QZ他们俩。他们俩是等于常数的那就意味着P和Q是成正比的关系嘛,对吧?也就是Q和P是成正比的嘛。
它俩是成正比的,并且我要求的是这个Q的若干值加起来得是一呀,这是我们的。那个那个那个呃。概率的加和为一,这是条件性质决定的,对不对?那这样的话,它俩还是成正比。
那我就用这个值做分子做一个规划不就可以了吗?把所有的加起来是底下做分子,然后做规划,上面这个用它做分母,分子不就够了吗?对吧?用分子出分母嘛。而这样这样一个式子对Z求加和,把Z就就积分积掉了,对吧?
因此这么一个联合分布就变成了边缘分布,Z没了,就变成它了。上面这个是X和Z的联合分布,底下是X,它的边缘分布。二者一出,显然是在X给定的时候,Z的条件概率。对吧。所以说哈我们的这个QZ哈它应该是什么呢?
这个QZ就直接取得当给定X的时候,Z的条件分布是什么?把这个作为我们Q的一个估计。就可以使得这个重要的式子取等号。对吧。😡,这就是我们这个QZ的含义。QZ是什么?
QZ就是样本给定的时候的引变量的条件分布。好了,我们现在就能够完整的给出EM算法的。标准描述了。就是说首先这个里边做的是什么事情?做的其实是对于这样一个式子,P除以Q这个东西,也就是五角星这个东西哈。
对他求期望,对不对?这不就是那个Q城期求期望吗?而这个东西把它求期望哈转化成为了对这个对数值取期望,对吧?而用哪个分布对它求期望呢?用的就是给定样本的条件分布。对吧。给定样本的条件分布。
用它对于样本值求期望,这就是那个E它的做法。所谓的意义。期望对吧?我们做的是这个期望,其实做的是这个对吧?我我是这样哈,就是说可能这一块对有些朋友听起来可能要比较难了。
我我感觉哈因为呃大家没有听过前面的我们的课程,所以大家会觉得这一块这是讲的什么玩意儿这么怪异是吧?但是呃其实这是一个很重要的一个内容哈,并且我在上这堂课之前,一直跟我们那个学员说。
咱这次课是很简单的一次内容。因为大家已经其实已经知道一些内容了哈呃。可能有些人听起来会稍微有点有点有点难。我我个人觉得哈。好了哈,这是关于EM上面的第一步哈。那下面一步应该做什么呢?
就应该使得让这样一个式子求最大就好了嘛。让它取得越大,那么说我就能够得到更好的值,再反带回去就可以了,对吧?因此我们就可以给出阳算法的整体框架了。第一步。
我们先对给定样本的时候的引变量的条件分布把它写出来,这就是。第1个QZ它的条件分布。第二个把这个QZ带到这么一个式子里面去求这么一个式子的极大值。不管你用任何一种求极值的办法,你把它求出来就是了。
这个咱们EM算法本身不去探讨如何求的问题,你可以用你知道的任何一种手段去求这个函数的极大值。当你求出了这个西塔值的时候,把西塔反带回到里面去就能求出这个Q来。新的Q得到了,再带回去得到新的这个函数值了。
再去求极大值,得到一个这个西塔值了,对吧?再带回去再带回来带回去带过来,总之最终收敛下去了,我们就能把这个西塔值最终估算出来了。好啦,这就是关于EM算法的整体的框架流程哈。😊,呃,大家走到这一步的话。
看。有什么问题吗?我们来说说具体问题哈,就说这里面哈,首先它们俩必须得是常数,也就是说两个五角星在一起嘛,所以是常数嘛,既然是常数,P和Q是成正比嘛?成正比的话,我们想去求里面的QQ和P是成正比的。
我们就利用P嘛,你和P是成正比。O我就让这个P做我的分子,它不是成正比了嘛?还得要求你的加和为一啊,所以除的是谁呀?除的是所有的分子的加和就好了嘛?这不就是保证了第一个和保证第二个嘛?
不就得到这个式子了嘛?得到它之后,对对基调就是它它除它显然是它嘛?就得道了哈,对吧?其实就几步的事。对吧。😊。

OK是吧,这个应该是星格,对不对?

人工智能—机器学习公开课(七月在线出品) - P20:微分流形在机器学习中的应用 - 七月在线-julyedu - BV1W5411n7fg

今天内容呢就是微分流行在机器学习中的应用。好,这个主要内容简简介啊,就是说那个内容的PPT已经发在群里了,大家可以看一下。然后今天主要内容呢是这个介绍一下啊流行学习基本概念和一些传统的方法啊。
给简单介绍一个呃这个ch欧ola他呃关于这个深度学习和拓补学的一个关系。他的一个看法。一个文章。我觉得这还还是很有意思的一个文章,可以有提供一些啊比较有趣的直觉,让大家理解。
就深度学习其实在做一件什么事情,它原理上会有时会有一些什么样的局限性。然后在这个基础之上呢,我们是不是可以。把当前的这个架构进行一些改进,利用这个啊更深用的数学。好,那么这个呃。
首先呢我们说这个呃微分流行在机器学习中的应用啊,主要是在这个流行学习里面出现。他们流行学习是干什么用的呢?他是做这个降低数据的维度来用。那降低数据维度。你提到这个事情。
大家首先想到的其实就是这个PCA对吧?就主成分分析,这是我们最常用的降低数据维度的方法。所以我们首先简简单的说一下这个PCA和这个MDSMDS呢就是说。这个好像叫做多维度标注。
就miple multiple dimensional呃 scalinging就是。他其实也是跟PC有点,就是他的想法有点类似的一种东西。就他们他们的收入不一样,他们都是做这个整体上降维的。
那他们都会有一些局限性,就是说他们基本上是。一种线性方法。他不太能够啊。揭示我们数据点中的这些非线性的结构。就是说你的数据可能就如果你数据是组成了一个平面,哎,那你用PCA或者这个MDS这都是非常好的。
那如果你的数据呢它组成的一个曲面。那么啊你可能就要我们后面第二部分说的这个流行学习,就是一些非线性降维的方法啊去做。然后当然我们会提到一下,为什么我们会。做这个流行的学习。那如果要是这个所谓流行啊。
就是大家说一下流行是什么呢?就曲面。就是二维的话就曲面,也就是面,对吧?一维的话叫曲线。那在高维呢。咱们现实生活中不太好不太好描述。那就是说你的数据可能是现在咱们的这个大数据学习啊。
的数据可能是上千维的对吧?就是有好多个feature就那个。比这点那个。啊,就是那那个参数的维度对吧?就身高、体重啊,什么年龄啊,这些那可能上千个。
那个呢就意味着你每一个数据点都是那个很高维空间中的一个点。那么这里面所说流行是什么?就是你那高维空间中的一个低维的曲面。你可能是这个曲面为数可能也不小。你比如说几十维的或者几维的啊,不见得是两维的。
但反正。二维的叫曲面了,高维的就管叫流行,这只是个词儿啊嗯。那么。如何去。通过数据我们去寻找他的这些。曲面的结构,而不仅仅是这个线象的结构,这个是流行学习所需要解答的一个问题。
那我们今天呢主要给大家介绍一下这个第一个叫等机同购这方法,就ISO卖这种方法。然后啊这当然这种方法其实基本上就是说可以展示出这流行学习这几种方法,就几种常用的方法吧。他们的一个核心思想。
然后我们在最后呢再给大家就是列一下这个局部现性化的这种这种就叫做local linear emdding这种方法。还有这个拉不拉斯的这个推征方程。啊,特征特征映射这种方法。
他们和这个艾 back呢这是在最后一步上不太一样。他们就是。他们背后的几何这个几何直观不太一样。但是从这个算法角度来说呢,他就是说最后一步的不太一样,给大家都会简单的介绍一下。那在这个基础之上,就说啊。
一旦我们熟悉了这个流行,在机器学习中的这个。啊,他这个地位。他这个他这个概念以后呢,我们哎我们进入我们今天说的,简单介绍一下这篇啊文章,就是说这个深度学习。他从托普的角度看,他在干件什么事情,他为什么。
能够产生这种非线性分类的这种效果。那如果我们了解这个以后,它有些什么样的局限性啊,然后我们会有个开放的问题,就是我们如何去改进,深度学习,有没有一些方向去改进啊,深度学习这个架构。好,那咱们开始啊。呃。
同学有同学说那个屏幕的问题,我们这个屏幕是这样的,就是左边呢是这个PPT然后右边呢等会儿我会给大家写一些草稿。有原件。Yeah。好。😊,好,我们先这个介绍我们最常见的啊这个。数据的一个线性降配方法。
就说。😊,我们通常说啊我们这个输入的数据就是啊每个数据点它有好多个features,对吧?就是说我们一般来讲。啊,我们输入的这个数据矩阵呢,就是比如说你有N个数据点,那每一个数据呢它其实是一个向量啊。
当然我们。通常我们写那个矩阵的时候都是呃数通常我们写那矩阵的时候是那个每一个数据点是一个横向量。然后那个一般是这样的吧?成K的这这个这种感觉是吧?那正我们这个里边写的时候呢,我们这个每一数点是列向量的。
就是说这个X。这全部数据是吧,它等于X1到XN啊。啊这每一个X。这个东西呢它是一个对向量。啊。就是长这个身高。啊,这是体重类似的啊,这个比如年龄之类的啊,这个这个是什么啊,这个牛幼肿瘤啊,肿瘤大小啊。
这反正这是好多好多的数据了,就出来是吧?就这个意思。好,那么这个PCA是在干一件什么事啊?就是说你这数据维度可能这个非常大。
就是说每一个X都是一个就是特别高维数供电里边一个点为纤维的那我们西我们知道这个有些数据之间呢,它是有相关性。我们不希望这个相关性太特别高的数据同时出现在这个数据T里。因为那样的话,他们重复了。
重复了之后,你在做训练的时候,他们之间这个噪音呢会给你再造成很大的影响,容易造成这个over飞啊,这个是我们那机器学习里面的一个。特别常见的问题啊,那那如何去降低你这个维度,使得那些重复的数据。
把他们放在一块,当成一个来看啊,这这不是就降低了嘛,然后让他们这个。尽可能的让你这些数据能够很好的体现你这个啊数据点特点,而不是让他们去做这个。相似不让他引引入这个噪音。那怎么办呢?那一个办法。啊。
利用数据的这个斜方斜方差矩阵。啊,你不是刚才不是说了吗?我们认为这个数据有种于数据的原因是有些数据之间相关性太高。那怎么去寻找相关性,怎么去判断数据之间的相关性呢?哎。
这个一个斜花差矩阵是一个很长明的办法。对吧嗯有些相关性高的那些,你就给他。就是拍拍在一起,变成一后啊这样。然后这个后续的分析就会更好一些。那什么叫拍在一起呢?那就是这个作谓主成分了。比如说嗯。对。
具体的我们今天就因为这个不是今天重点嘛,我们就不会把这个新代收那分都讲完。但是呢我们就说当你输入是这一堆这个高维数据的时候。的输出是什么?输出是你得到若干个主成分,前K个主成分。
这K组成分呢差不多代表了你这个数据最重要的那K方向。然后你这些每一点呢?我们把它在这些方向做投影。啊。我们也当然也稍微画个图啊。同款。就是说你那个数据可能是数据点,大概是这样子,是吧?这样。
然后我们发现那可能高维这是二维的。那我发现在这个方向上。比较重要啊,这比较区分度。对你数据比较区分度。在这个方向上呢,这比较窄,那可能是这个数据呢区分度不高啊,它这个有可能噪音引起。
你每次你取样的时候都会噪音,对吧?那所以呢你把你每一个数据啊都投影到这条线上去。其实咱们做正焦投影,应该是既混往这边,又投影投影到这边。然后这边因为是比较小嘛,就比较,所以只只保留这个重要的这部分。
然后这部分就就叫做Y。是吧。那呃。那当然我这是一个简单的例子,这是一个K。1的情况。是不等于了。啊,不好意思,这地方应该是YK啊。唉sorry,没没没关系,没有错没有错。就说这个如果K不等于的话呢嗯。
这个每个Y呢,这就是一个K位的下。所以说所以你就把一个呃N嗯一个很高维的空间中的N个点变成了一个低维空间中。跟买店对吧?那当然。做这件事情的时候,我们希望什么呢?我们希望这个。我们不是说舍弃了一部分嘛。
对吧?这部分不舍去了吗?舍去这部分就是XI减去YI乘以这个电程上这个F这个F是主成分,YI是在主成分上的那个向量。那个坐标这一点程就变成了主成非常坐那个那个位置。那呃就产生了误差,误差就是丢弃那部分。
我希望这个误差呀越小越好。是这个意思。这个是呃主成外分析的方法去做这个呃降维啊。那么主成分分析它是一种线性交易方法,它有它的局限性。比如说我们在这样的数据中,我们左边这个图啊,大家如果要屏幕小的话。
也许看的不是特别清楚啊。其实左边这个图呢是个立体的图。啊,它是一个这个呃三维图,它这好这个是你可以认为这XYZ这样是吧?然后它是什么形状?它是一个。Yes。他大概是一个。这个面包卷儿的那个形状。
就大家吃那个呃那种奶油面包卷,就是这这个你可以认为这是中间那个奶油啊,是那个那种卷是吧,这种形状。然后这种如果是你的数据点是个三维数据啊。好多数据点,因为数据点它形成了这样的一种形状的话。
如果你用当然我们就想做降维嘛,对吧?我们就可以考虑,比如说哎我用PCA做个降维试试看,我可不可以把数据搞得更简单一点,对吧?哎,PCA一搞,其实PCA刚才讲了什么意思?就是你要把你原来这个数据点数据啊。
给它投影投影到一个低纬一点空间上面去。这就是我们刚才说的画这个图。把这二维的数据啊投影到这个一味的上面去。那我们现在这个PPT里面这个图呢。是把这个三维数据呢啊投影到这个二维的里面去。
我们看到这个颜色呢,就是说你这个卷的头和尾这个大概颜色不太一样。所以我们其实在这样的数据上面,我们想知道的是。比如我们做分类吧,我们想知道的是卷的内部和卷的外部可能要做个分类,对吧?
就因为这个数据其实长这种形状,只是因为我们观察它的时候所采取的所选择的那些个特征,导致它形成了这样一种形状。但是数据其实是它本身是有这个结构的。那么呃。比如说你这个数据代表的是某种生物。
它的某种这个状态,对吧?那可能。这个深蓝色的部分和这个深红色的部分,他们应该代表是很不同的状态。它是在这个条形的呃两端嘛,对吧?但是你在这个数据空间中啊,它离得就很近。
而且如果你要是做了一个这个咱们之前所说的PCA的话。这种简单投影。你就发现你看这个深蓝的部分和这个黄的部分。干脆就被粘在一起了。那你做完这个投影以后,那这两部分可就再也区分不开了。
对吧就是说你这个曲面的这种非线性这种曲弯弯的这种曲面的结构啊。经过了投影之后就被破坏掉。没有。这要照不来。那也就是说如果你第一步出去处理,采取这种方法,那基本上可以告诉你你这个分类你可能做不了,对吧?
这个意思。这个意思那这个就是说一种线性的降维方法呢,当你面对的是一个有曲面结构的数据的时候啊,它就有问题了,不太好使是吧?这样。那。那另外一种常见的这个呃。线性的这个呃降维的方法,就是这个多维度标注。
那它的区别在于什么呢?我们说刚才PCA这个输入啊。是那些点在原本你选择的那个呃特征上面的坐标啊,每一个X都是一个很高维数的这个向量。D大D位的向量,这个X于大D位向量。然后你对它进行这个降维。然后这个。
作为标注呢,他说的是因为有时候你问题不一样,有些问题给你的时候啊,他没有给你那个在高维面上的向量。他给你的是每个数据点之间的这个不同的程度。就是说。我们我们就距离吧,就他给你的是距离。
每两个数据点它不一样。然后他告诉你两这两个数据点有多不一样,就给你个数,比如是从0到1之间给你一个数,每两个数据点都之间都给你个数。这种呢你就可以把它理解成是一种距离,但是呢它没给你一个大的坐标。
那这个时候你就你甚至连那个大空间都没有,你只有距离。那这种情况下,你怎么去还原?你这个数据点啊这个数据数据集啊,它自身所带的那个啊曲面的结构。那怎么去做这件事情?
或者说当然我们现在作为一个标注还没有没有考虑到全面的问复杂。他想说的是你能不能把这个导出一个坐标来,你不是没坐标,我们能不能搞出一个坐标来。然后将来我做这个比如说叉值啊,什么都比较方便,对吧?
或者说生成啊那什么的,都比较方便。那,他的做法什么呢?哎,因为你输入不是距离嘛,对吧?那你输出上是你希望是一组坐标,那损失函数就是一旦你有坐标之后,你就可以重新算一个距离。
这个是你在你的这个新的坐标值基础之上重新算的距离。然后这个D呢是人家输入的距离,你看看他们俩之间的差别有多大啊,对吧?就这种做这种,就它损失还说是这么东西。这个是这个啊多维度标注的一种做法。
那这个呢我们之所以在这介绍一下,他其实因为。他将会在后面这个流行学习中。他会有些定会。虽然说他不能他自己不能够揭示这个呃曲面的结构,但是。在流行后面的这个内容中啊,也还是会回来去用到它。
对他进行一些改动嘛。这些这事。好,大家有没有问题?这是我们首先回顾一下这个线性的一些降维的方法。对,因为我们今天这个讲的没有讲这个具体的一些计算啊,具体的或者甚至推导什么都没有。
所以说啊技术上问题呢比较少。但主要是让大家理解。这是在做一件什么事情,就稍微这个high level一点。好。第二部分呢,我们就讲这个介绍流行学习。啊,首先我们说。为什么要搞这东西?
我们不跟之前那个线性都挺好的啊,那个数据之间不就是有点相关性吗?那吃掉之后弄个PC也挺好的,何必搞这什么流行学习啊,还挺挺神的这种东西啊,没什么意思。那同学会很多人会这么觉得,那为什么要有这个。
流行学习啊首其实他在机器学习中出现这种东西。那最基本的原因呢是我们啊现在我们有这用流行假设。啊,就是说。我们倾向于认为我们地维的地位空间中数值点,它通常会集中在一个。维数更低的曲面附。二维的叫曲面。
高维的人叫流行,这种叫磁流行。指就指的意思就是。小的,比如说你。高危空间不是大的啊,那个流行是在你的高危空间里边的一些切出来的,所以就是这叫子流行。哎,比如说我们这个啊面包卷这个数据店。就这个数据点。
你看左边这个图呢有好些个点,它们大概形成了这么一个形状。那它背后的。那个流行右边就这个曲面。就是我们倾向于这样认为,为什么这样认为?你可以给大家举下例子,就比如说我们。通常说那个。比如说图像识别吧。
对吧?我们看的是这个,比如说你是一个。100乘100的一个图像,就是1万个像素,对吧?在那图像里边。那么你这个。那你一张图就是一个1万倍的向量。对吧就是因为1万个像素,1万枚的项链。那。
我们就有好多数据点,每每张图是一个数据点。那如果你要是。这些。图啊它是在这个空间中随意出现,就是这个1万维每每一个图,它就是一个1万维空间中一个点。如果你这些点是在这个1万维空间中随意出现的话。
那其实你这个图里面。就应该出现很多这种类似于白噪音的这种。就是我们就换句话说,就是我们通常看到的图片啊,它它都是有它结构的。它并不是那些每一个数据点上,你啊每一个像素上你随便给一个数,然后组成一张图。
这样展停给我们看。我们通常我们输入的这个数据不是这样的形式。我们输入的数据,比如说你研究的是这个。啊,手写数字这样的数据。其实他只是占了这个所有可能的图像,图片中的很小的一部分。他都是。那这个类型对吧?
那这种类型的所有这些手写数字,所有手写数字的这些。图片放在一起,它只占了所有图片的一小部分。那这一小部分它是堆成了一堆呢,还是它其实是相当一片状的在这个高位空间中的一个子流形呢。其实它更像是自流星。
因为为什么呢?如果它堆成一堆的话,就意味着你在一个手写数字的图片上面随便加个噪音,它应该出来另外一个手写数字这个图像。其实不是这样,因为一加噪音马上它就变成一个不是数字。
它就变成一个就是那个你可以想象咱们看电视的时候出现了雪花,出现那种情况,对吧?就是说哎那个不是这样,就更像是。这个所有的数写数字啊,它们构成了整个图片空间中的一个自流型。更像是这样。
那还有一种例子是什么呢?就是说啊比如说人的这个。嗯。呃,动作。就是说比如说我们做这个也是图样识别啊,就大。你就打比说你做的是这个。视频里面的图像,那你这个每一个人他动他行动的时候,其实你看他这个。
他那个脸这个肉什么是软的对吧?他其实是可以有很多很多的方向可动的。你这个。很所有软的地方都可以玩,都可以动。但是人其实并不是。会采取所有的职些动作,他基本上常用的就是抬胳膊抬腿啊,走路这些。
那这些动作在所有的可能动作当中,那空间里,它又形成了一个色流形。就说我们学习之所以能够用,很大程度上就是因为。我们没有随便的乱动,我们输入的数据是有是有结构的。啊这些学习呢就是在揭示这些结果。
这个东西这种假设。其实就是所谓的流行假设,就是说我们。接收到的数据,因为我们没有办法,我们只能通过各个维度去各个这个角度去观察这个啊你的数据点啊。所以说每个数据点呢你就得到好多的数据。
好多的这个feature。那嗯。但是。真正我们关心的东西通常是这个大巨大的fishature空间里面的一个自由性是这样的一个假设,就基于此种假设。当我们拿到一数据以后。我们就希望。
怎么着能够还原它背后的那个曲面的结构。对吧。如果能做这件事情,那对我们很多的分类问题,很多的这个。差值问题。啊,或者是甚至是生成模型的问题,那都是很。对吧。那么第一个方法。介绍第一个方法叫做等距映射。
啊,这个这个方法我们提供了一个原始论文。那后面那个方法我没提供,但是大家其实这个随便网上搜一搜呢,很容易搜到。邓俊的说,那我们刚才说了。啊。就是说你这个。你刚才说那个讲前面那个例子的时候?哎。
讲这个例子上,我们说了,就是说你在这个大空间中,你看比如说这个深蓝色的点和这个黄色的点,他们距离其实还是蛮近的对吧?但是你从这个数据本身结构来看呢,这个点和这个点其实一个处于。这个端点处。
一个处于这个中段处,其实他们代表的可能是两种不同的非常不同的状态。就做分类的时候,其实他们俩可能会分到不同类点去,对吧?那换句话说就是你这个大的特征空间,就feature空间里头的这个距离呀。
可能会误导我们。对数据的认识对吧?我们希望找到它原始的这个距离,就是说这个点到这个点,它距离不应该直接这么来的,因为。你穿越了对吧?你不能穿越这个呃呃fisher这个空间,你得从这走。从这过。
对吧其实这距离还蛮长的,我希望找到这个东西。那就是说距离其实是一个很重要的概念。在我们这个。啊啊流行学习里其实是很重要的概念,对吧?那所以我们第一个方法呢,其实是这个啊就是利用距离直接利用距离。
来重构这个流行结构的,就是说叫邓居英式。好,我们来具体看一看。啊,有同学问说那个直播有没有回放啊,有的,我们这个直播的时候都有录像,然后等这个嗯。可能应该下个礼拜吧,一般下个礼拜嗯。啊,不不不。
你们现在礼拜一,就是那个过几天吧,通常我们就有那个。这个录像上传了,大家可以在PP上里面就可以看到公开课啊,sorry就是那个APP上就可以看到我们的公开课的视频。好,那说到距离呢,我们就稍微多讲一点。
就是说什么叫做曲面上的距离。因为我们刚才说了半天了,我们我们说的就是曲面,然后说这个又说大空间中的距离啊,又说了曲面上的距离啊,呃说了半天,对吧?那我们稍微给大家介绍一些背景知识。什么叫做曲面上的距离?
啊。曲面上距离呢。我们通常接触到曲面,其实都是这个。一个欧基里德高维的欧基里德空间里面的这个子曲面啊,比如说这个球球面这个东西啊,它就是一个三维的欧基里德空间里面的二维的曲面。对吧我们地球嘛。
地球的表面其实就是一个球面,对吧?然后。我们通常如果大家看这个关于几何的文章,或者看这个礼曼几何或者微分几何的文章。你经常会看到这个侧地啊。在。测地线测地距离啊,这些东西它其实说了什么事儿呢?
就说如果你限你把自己限制在这个曲面上。那么两个点之间,他们最短的那个路径和那个路径的长度是多少?那这个最短的路径呢叫测地线。那这个步径长度呢就叫做测地距离啊,是这样的。那打比方说平面上的测底线就是直线。
我们不说了吗?平面上两点之间这个线段最短,就那直的线段最短,这是我们。最早接触到的这个。集合的概念。就是也是那个OT里德写在这个。几个人每上面一公里。好,那这个曲面上这事儿就不对了啊。
打比方说咱们说这个你要坐飞机啊,你要从比如说你想从北京啊飞到这个。纽约怎么办?应该沿着什么路线,路线飞。那其中一个路线呢就是横着飞。因为他们两个城市几乎在这个呃地球上这个纬度差不多,所以你横着这样飞。
就是往东飞。基本上你飞飞飞到对面去就就到了北京和纽约几乎也是这么对着,其实咱们就这种情况,很多同学在北京,其实我现在在这样。那。那个其实实际航线那就不是这么飞的了。他们其实飞的是一个偏偏的路线。
那个跟这个地形有关系。他们希望这个飞机下面最好有一些陆地,这样迫降的时候,万一出什么问题可以破降,这个意思。但是如果要是抛却这个这些问题不谈。只考虑远近,只考虑距离的话,其实应该怎么飞呢?哎。
其实你应该从北极飞。直接顺着北极上头种下去。这条线才是最短的距离。当然那么飞,中间这个北极舱他没有没有机场,你万一出点什么事,就只能调片通用,对吧?这个就比较危险,所以他不那么飞。嗯。啊。
这个就球面上的测底线啊,就是这个球面上的大圆。所有的图案再测一下。啥这个方向是最好。就是当我们说曲面上距离的时候,我们说的就是把自己限制在曲面上,那最短的距离是什么样。但是如果你放弃这个假设。
如果你说你可以在地这个这个这个呃地下行走,那怎么办呢?应应该在这打个洞。把这个直线连去。是这个。直线这个叫做。在大空间里边的那个那个最短距离的距离,而上面这个弯弯的这个绿色的,这个是侧底线测底距离。
对吧?那回到我们刚才说的这个例子里头啊。你看你从深蓝色的到这个黄色的。打通烟的距离是什么呢?你是直接把它打通。这是大空间决定。但是如果你打比方说你现在这个数据点说的是这个。啊。
每一个点都是一个人的一个表情吧,对吧?奶了一一人一人的一个表情,然后呢。这个表情可能是笑,这个表情可能是哭。上面这个表情呢可能是愤怒,对吧?那你从笑到哭,他俩的这个直线距离可能是很近的。其实。😊。
这事儿可能是真的,就是说笑的动作和哭动作呀。还其实挺像的,如果你只看都咧嘴,对吧?都闭眼睛对吧?都都都都这些东西其实蛮像的。但是呢你一眼就能看出那个是笑,那个是哭,能区分开。为什么?
就是说你并不完全是通过这种直线这个距离来区分。这个表情其实你是在你的脑子里已经形成了一个咱们大脑里边已经形成了,已经学习完了这么多生活了几十年之后,咱们已经学习完了。
其实你知道他这两个表情距离不是这么看的,应该是这么看。你立刻大脑理就可以形成这两个表情之间的距离有这么远。你知道他们是在做事情,对吧?但是你怎么让机器去干这件事,这是我。对吧。好。😊,哎,就是对。
这里这里我们还有一个更好一点图啊,就是这两个点那这个红色的和这个嗯淡蓝色的地方。他这个。欧式距离就是你如果你可以穿越的话,你的穿越距离很近。但是呢哎你这个侧底距离啊。应该是整测底率这么做。
你得把自己限制在曲面上这样做。唰从这上过来到这这是这个距离是侧的距离,那就下面画这个其实是很长的,就欧式距离非常小,就slluclan distance对吧?
large geodiic distance这个意思。She。那么。OK所以所以换句话说,如果我们能够很好的描述曲面上的测定距离的话。那我们其实一定程度上就揭示出了这个曲面的一些非线性的性质。对吧。
所以如果所以我们你就完整的重构这曲面,那肯肯定是非常困难的。你肯定是要用这个曲面的某些特点去描述它的这些性质。比如说测底距离就是其中一个重要特点啊,这是可以算的。好。那么。如何用这个。就是这种方法。
iso map。这种方法。去对曲面的啊。测底距离进行估计呢。怎么说呀,如果你直接看这个。坐标的话,那它俩距离就只你就只能这么算,你怎么去你怎么让告诉机器从这个角度去找这测底距离呢?怎么做怎么去做这件事。
哎,一个办法就是说啊。你让那个机器。让他更加的短视一点。你降低点他的这个能力。就是说机器通常他一看他直接看到他们俩离这么近了,也没办法。你降低机器的能力,怎么降低呢?你只给你只提供给机器一些具体信息。
你不要全都提供给他,你提供给他什么呢?你你对每一个点旁边画一小圈。这小圈里也有好多个点,对吧?这些点之间的距离,你告诉这些等于多少。而至于这别的地方点的距离,你不跟他说,他也不知道对。
然后你提供给他数据什么呢?就是一个一个的小圈,你把这个整个数据数值集啊分割成6根小份儿,然后每一小份内部的那些点之间距离,你告诉他那外头的你不跟他说,这样呢这个机器啊。这样的话,你就会形成一个图啊。
就是咱们那个。图论的那个图对吧?就是说。两点之间有距离的话,就连条线,然后距离长短呢就是那个线的长。你就会形成一张一张图,就是下面一张图。你从这个三点闪点数据,首先你构建一个下边这个图。But。啊。
就应该右边这个图,sorry,你右边这个图,你你有坐标吗?就每个点,它并不能跟你并不把它所有的这个距离都都都提供一个算D。比如这个点和这个点之间它是有距离的,请,你可以算出来。但因为它比较远。
你就不提供这个,你只体提供它附近的。然后你就构成了一个图,就是一个网格用解构。那当你想算这两个点之间距离的时候,测力距离的时候,你怎么算呢?你把自己限制在这个格点图上面。你看看这个格点图里面。
它从这点到这点,它的最短路径是什么?哎,这就变成一个图论里面的一个经典问题了,对吧?给你一个图,一个无像图,然后那个图的边上呢有这个距离,有权重。那你如何去找到一个最短路径?
那这个最短途径一定程度上就近似了我们所说的那个测定距离。我们看到下边这个就是如果你把这个图围展开啊,我们用人就是我们从上帝视角来看一眼,你把它展开。展开之后呢,你就发现这条红线弯弯曲曲。
这个红线却就是沿着这个图的方向,你找一条哎能把两点点起来的。最短的一个路径。那这条蓝线呢是真实的那个彻底线,那条最短路径。所以这红线其实是对它进行了一个。就束。哎,是这么个意思。走么。😊。
所以说啊如果你。我们再回顾一下,如果你一开始的时候,计算机就可以算所有这些,比如这虚线距离,所有点之间的距离都有。你这个那上面的图就巨复杂了,对吧?每两个点全到连条连条线你这个。你就甩他出来。
我那样都不行,那怎么办呢?就是怎么办比较好呢?就是说你只提供那计算机。每个点附近的一点的信息。然后你构建一个网格,一个图。然后呢,你再通过解决一个图论的问题,你去寻找啊每两个点之间的这个彻题距离的问题。
这样这样的方法。那么当然了,这个我们说你找到测定距离了,对吧?那。你不是说刚才我们还想说想那个还更有野心一点,我们想把这个曲面给它重构一下。就换句话说,就是我想把这个曲面给它展开。
就得到下面这个图怎么办呢?就是说如果你每点附近都有距离,有这网格了。你可以做一件什么事呢?有距离以后,如果你想在局部上重构一个呃。一个一个小片,一个一个坐标片。我们就可以用刚才说这个多维标准。
对吧如果你把所有的数据一次丢进去,任何两点之间的距离你都给他了。那这个多位标注我们刚才说了,就是个线性的,它是一种很这个线性的方法,不老使,对吧?如果你给他这些距离的时候,你只给他部分的信息,只给他。
就我们刚才说的网格里面那些信息,网格之外,那些你不给。嗯,那个距离你是认为是无声大。你用那种数据输入进去,你再做多位标注,你就可以把它给。还原成这个样子。就是这么一个意思。
就是说你可以认为这种算法呢是对之前的那个多余标注呢改进。你也可以认为。多位标注呢只是在这个里面做了一个简单的应用,就在最后一步。你前面这部分是它的几何背景,你是为什么要搞这网格。
你这是有几何直观的最后一步具体计算你用的那个对位标注啊,都可以,你怎么想都行,就是看你觉得哪个好,那哪个重要,这个意思。所以说哎这是第一个方法,它的这个呃算法流程呢就是这样。先用聚类算法寻找淋域啊。
就是说我们说什么叫做这个点附近的点,你得弄个聚类的算法,去寻找一些淋域对吧?其实这个不需要太复杂的方法。一般比如说你这个点离它距离小于一个epon,你现在epon比如说0。1,你就你这个是你手工的了。
就是参数是你自己调的。X小于0。1的那些点就就算在一个类头啊,在这个类里头呢,你把这个边给连上那可以啊。你也可以说我们不设那0。1那种我就说跟我距离最近的这个前这个10个点,我就考虑这10个点。
别的我不考虑,哎,那样也行啊,就是反正你你设定一种标准,什么样的点是离得近的。这第一步。用一个啊之类的算法去把淋域给它都定下来。然后呢,并开之后,你就可以知道哪些地方要连线,哪些地方不连线了。
你就构建了这个图,这 graph就构建出来,对吧?在这个基础之上,你再使用这个MDS。仅仅考虑。这个淋浴中这些电的距离啊,然后你就可以做一个重构,你可以重构这个啊。这个曲面。这样。这是第一个。
但这个方算法有一个不好的地方,就是这个MDS这个算起来可能是比较花时间啊,这个计算计算计算复杂度呢稍微高一些,算的比较慢。就是。好么?那,还有一种办法啊。
就是叫做呃local linear em这个LLE就是第一个L是local这局部的。然后第二个L呢是linear。第三个E呢是inbidding,就是局部线性嵌入的意思。他的第一步。和之前那个。
等军营社是一样的,你先聚类。寻找一个淋浴,寻找完淋浴之后呢,你怎么去把这个。小淋域里面给它进行重构,使用了跟刚才不同的方法。刚才因为我们想用这个距离,所以我们使用MDS,对吧?就是说。
我们这个呃把淋域里面每两个点连条线连连一个线,然后把这距体写出来,形成一个图然后做这种事情。那这回呢我们采取的是这个啊局部先法。这个方法是一个什么样的想法?就他用的不是距离了,他用的说什么呀?
还有呢说吧,就是说如果你真的认为自己的数据。在空间中是一个曲面的话。就说这个数据长一样。比如在这附近上。那远处可能是这个弯过去了,是吧?曲面啊。在局部上,他一定是几乎是一个局面。这个是曲面的一个特点啊。
就是说当你那个范围小的时候,能曲面几乎就是一个。所以说你在局部上,如果你能平面给它做一个近似,不是就很好吗?对吧?那怎么做平面上的近似呢?就是你需要寻找他们之间的线性关系。啊。
我们如果有同学对新代说很熟悉的话,知道如何去描述一个平面或超平面或者是这个反高于什么样的。怎么描述呢?其实你就是去寻找它这些点之间的线性关系。几乎就你可以认为这是在做一个有点像是那个线性回归那种感觉。
平面去解合这一点。那这具体做法啊,我们这里就不说,但是他其实说的是既然你们之间是有线性相关的关系。那比如这个点,它应该可以用它旁边的点啊作为线性组合给它组出来。如果他们之间没有这个线任关系的话。
你这件事做不了。所以说如何去抓住。你这个线性关系呢?哎,你就说我只要知道这每一个点是如何用它旁边的点线性组合组出来的。我有这个信息,那我其实就等价于抓住了啊这个这些点之间的线性关系。对吧所以说。
当他做完剧类寻找完领域以后,他没有去找那剧离。他是。上面因为用度量来做,所以要找距离,下面想用线性关系来做。所以他就采取另外一个做法,就是寻找如何每一每一点。
如何用其他的旁边这个淋域里面的点去做成功这种模式。哎,也得到了一个嗯。内容。其实是一个图了,就是也是一个也是一个矩阵,表示一个图。然后在那个基础之上啊。啊,他就。他他在做整体的优化。
那这就可以把那个训练透露出来。就说最后这一步我们采取的这个几何的。特征不一样。第一个方法我们采取的是使用了几何中的距离的概念。第二方法,我们采取使用了几何中的这个呃直线的概念,就是平面的概念。那那好。
sry这个地方。这个地方写错了啊。这个地方是拉普拉斯。第三个方法啊。啊,我们等会儿我们稍后那个呃。讲完课之后,会给大家这个改一个。改一个这是。呃,修改一下,然后上传1个PPT。这种方法叫做嗯。
拉普拉斯的这个那分子的这个特征因素。对特征设的方法。那这种方法呢,它又是另外一种办法,就是他其实也是用度量,但他没有直接用度量。因为他认为可能直接用度量的话这个。噪音也比较大,他用的是一种。
稍微更深刻一点的数学就是说你通过度量可以去计算这个曲面上的呃这个嗯。所谓的拉法斯算子。的特征函数。啊,这个曲面上如果你就一个对于一个这个封闭局面来说啊,如果你知道这个曲面上所有拉pl。
它拉普拉甚至所有的特征函数的话,你其实就等于可以把这个曲面重曲面给重构出来。嗯。之所以我们采取这种方式呢,是因为这个特征函数它比较容易进行数值计算啊,可以算。那这样你可以算。
那你可以近似的得到一些特征函数。那你把这些特征函数当成是这个曲间坐标,也是可以也是可以的。因于他也用了度疗。那这种方法呢比较有趣的一个地方是他的思想跟这个度量可能关系更大。但是他这个具体实现呢。
哎他跟这个第二个这个局部现性化的方法嗯,可能更更类似。所以。第三种方法都是我们做这个流行学习的时候啊,常用的一些办法。好,那么。这方法虽然不一样了,那他们这个。核心其实是很类似的。
就说你如何在一个高维空间中去重构一个低维的曲面。我们第一步他都用了对曲面进行了局部化。我们只考虑这个曲面。每一点附近的其他店的性质。因为要是一旦你要考虑所有点这个特点啊,这个性质啊,你就容易被误导是吧?
就刚才说这个问题,嗯这个点和这个点之间距离很近啊,大家可以看到我这个鼠标。这两个点呢距离很近是吧?但是呢。他们其实在曲面上不应该是。很近,应该很远的。所以说你要。叫么字段双闭啊,让这个计算机。
对对视力更差一点。原来只能看到附近的,不能看到远的。然后在这个基础之上。你再用不同的啊几何的背景去重构这个曲面。就第一步都是一样的,对曲面进行局部化。然后通过曲面的就个局部特性来重构曲面。
当然你可以用各种不同的局部特性。那我想对于不同的问题,你可能这不同的方法,也许就有些问题对第一方法好使,有些问题是第二方法好使,那取决于你的问题本身。这个地方呢就是说你就需要你的专业知识。
比如你是做这个方向的,你是做这个。啊,保险的或者你是做这个啊图像识别的,或者你是做这个。啊,声音识别的或者你做什么别的。各种不同领域的人呢啊通过你的专业知识,你可以去做适当的选择。哦。
这个地方有一个重复的。页面好,对,所以就是总结一下,就是流行学习的核心啊,就是说先对曲面进行局部化,然后通过局部特性来重构曲面,这是流行学习的核心。好。好,那这是我们的第二部分。那同学们有没有什么问题?
好,那那个我们今天这个可能。讲的就是呃。用的这个数学的概念稍微深了一点啊,就大家如果要是。但是我希望大家能够明白这个就是。通过我们这些图啊,能够明白这个的核心的思想是什么。
然后如果大家对这个具体的细节很感兴趣呢,我们就是可以啊更多的反应。对,我们将来可以给大家准备一些课程啊这样。对。好啊,有朋友问题是吧?这个流行学习呃主要用到哪些问题呢?就是说嗯。
其实他这个呃你不太好说它是应用在哪些具体问题上,应该说是你只要是你的数据。它不是一个散点,它是有这个呃曲面结构的。那么我们就可以把应用。呃比如说一个比比如说一个什么应用。就说。唉。
这个还是比较有意思的一个。就说。就我们刚才那个表情的问题。Yeah。啊。哎呀,我们那个花的话可能难画,就是说比如说呃比如说你做这个什么差值的问题,就是做生成生成问型,就是大板说,你现在。
你你有一个人很多的数据,你有你有这个人平时各种表情,就是把他这很多表情。拍下来。然后现在呢呃你有了他呃。然后现在你你你比如说他要跟别人做一个这个视频视呃视频聊天,打比方说吧。然后呢。啊。
视频聊天就不太好,比如他录了个视频吧,然后呢,这个视频呢,他可能这个resolution比较差,就是说。他这个截截图次数比较少,就帧数比较少。然后你希望你做差值,把那些没有的那些帧数给它补。
那这个用问字吗?对吧?也就是说等于你有这个人的。Yeah。一个表情。有声意。😊,啊。然后呢,你有他第二个表情表情。你怎么把他个表情一。5味的不去?对吧那如果要是像我们以前做线象差值,很简单,你把这个。
两个表情,你这个表情不就是个向量吗?你把两个表情加起来除以2,然后你得到一个平平均值,你把那个当成那个中间那个差值,但那样就发生什么问题?比如说他刚才那表情那个是嘴。张了一嘴刚要张开。
然后表情二呢是嘴已经完全张开了。然后如果你要做个线差实,你会得到那容有两张嘴,一张嘴是闭着的,一张嘴是张开的,然后你都比较虚。那就是你查出的结果。但如果你要是。那就意味着什么?就意味着我们做了件事情。
哎呀,你做这样事。他是嘴刚要张开在这儿呢,然后嘴完全张开在这儿呢。它真正的路径是这样过去的对吧?但如果你做个线性开始,你会在这儿找出一个点,那点根本就不可能存在,人是不可能做出两张嘴的表情。对吧那我们。
怎么才能做的更好呢?就是如果你能把就是你在之前当然那容很多数据了啊,你有那人其他的数据,你这个流这个这个曲面已经被你训练出来了。那你就你知道哦,这有个点,这有个点,你怎么连起来,你在那找一找测底店。
你就把中间这个给找到,你就找到的话,他不是应该两张嘴,他应该是有一张张开了一半的嘴,在这儿你就可找,这个意思。这个意思。不知道这个有没有回答你的一些问题,就是说哎就这个意思。好,然后。
另外一个同学问说那个PCA是可以用来找到曲面结构吗?PC是不行的。就刚才我们前面其实讲的这个例子里面说。比如你这数据点本来是有曲面结构的,你这一个PC啪给压成一个饼嘛,对吧?压成饼之后。
你看这个本来这两个点应该距离很大,但是没压到一块。好,这个意思。呃呃然后有同学问说,除了图形学习之外,嗯,在别的方面还有没有什么?嗯,就是说他。只要是你的这个数据,它是形成了这个。这个呃在数据空间中啊。
它形成了曲面的话,就是有它有结构的话啊,都是有用的。你的图形是可以用的,那声音也是可以用,对吧?你可以想象,那嗯分类问题其实也是可以用的。比如说我们现在这个是一个分类问题嗯。
你这部分是一类啊这部分是一类。比如说你现在你的每一个点可以是个图形,你的每一个点呢也可以是。比如说你要医疗里面,每一个点是一个肿瘤的这个肿瘤的这个呃。状态啊,肿瘤大小啊,肿瘤的这个颜色啦。
肿瘤的种种特点吧。状态。那这个其实现在在这个医学中已经是有有这种应用了。就是我们之前嗯之前有有一个。做这方面。这个数据to结构的一个公司,他们给我们做过一个这个presentation啊。
他们就是研究这个。某种疾病的这个。嗯,死亡概率的大概这这个意思,就说啊。你去你比如说这个红色的这区域是基本上你就离死亡不远,就是很严重的区这个。深蓝色区域呢其实就是这个病的初期状态。啊,比如说这种情况。
然后你现在你当你探测完一个人状态之后,你希望对他的这个状态进行一个分析。你希望知道他在什么状态啊,希望知道该怎么治疗。如果说你测完的病人在这儿。就在这个浅蓝色的位置。
如果你要是不考虑它这流行这个曲面结构的话,你就会发现它跟你这红色已经很近了,你可能觉得套板期了。对吧你可能就得不能治了,或者说你可能就采取一些这个非常有伤害性的治治疗方法。那实际上不是那么回事。
它可能快好了。你这个对吧?所以你这个分类也很重要。那如果你没有这个流向结构,你就分不好。有了之后呢,你就会分好一些。那究竟说你这个数据中有没有这种结构,那这个就跟你的这个具体情况有关系了啊。
那事实上这种情况是有啊,这个我们之前看到过一些例子。对,然后。还有没有其他问题?好,那这个正好啊,我们第一个小时讲完第一部分,然后我们这个。进入第二部分。

那进入第二部分之前,我们这个。休息5分钟我去。好,我们回来继续啊。

那,大家有个问题说这个流行说数据是在呃第位空间,不一定是在二维中是吧?这个是的,就是啊他说的是。是很高维的空间中的一个自流型,就是说可能低倍数低一些,但不见得是二维。你二维的线率就太高,那就就太小。
这样。Yeah。但是当然有一点啊,就是通常咱们呃人比较好观察的这还是。二维的就是如果你想把它画出来,让你自己看,那可能就是二维的还比较好画,三维的勉强也能画。嗯,在高维的可能基本上是画不了。对。
所以同学问说,那你如何知道你现在这个呃问题应该选择。哪一个维度呢?这个其实跟我们这个具体方法有些是有关系的。比如说。我个。这好这页这也吧是,比如说我们这个呃拉查斯这种算法的话。它最后一个参数调整。
就是说你可以选你选择就他这个是选择用啊若干个这个特征方程特征函数,就每一个特征函数都是一个坐标。那你选NK个,那就是K尾的,你选K加一个就K加一尾。那这个这这就可以变成一个模型参数,就是说。
你肯你显M是一开始你不知道到底应该多多少倍的,你只能是把它放到你的模型中。去解决你的问题,你看你到多少维的时候能够解决问题。就那就多少位就比较比较合适了对吧?那通常比如说你要是嗯100维和101维都行。
那你可能会选择更低一点的100。这个意思。然后至于与人个人视觉相关的呢,他其实不见得是二维的,就那个图像是二维的。但是那个图像所代表的空间中那个点可不是二维的。你想图像,比如说100乘100的图像。
那它其实是1个1万的空间中的一个点,是这样。所以其实你就得想办法找这个1万枚空间中的这些点,他们有没有形成一种。比较特殊的曲面,对吧?然你在那个曲面上去做这个事情。就是你可能做不同问题的时候。
你会找到的是不同的曲面。做这个手写这个输字的时候,可能是一个曲面。你做这个嗯。比如小车,这个有些有些同学做那个呃。视频中的那个。抓取嘛,对吧你要抓取一个车,抓取一个人。比如说那个照相机那抓取人俩个,哎。
那可能是另外一个问题。这这样。好,那咱们这个okK好。咱们进入这个今天的第二阶段啊,就是。深度学习和这个托普流行啊,托普学的一些概念。就是怎么去。就是深度学习啊,是一个就是在很多领域都做出了很好的结果。
对吧?包括我们之前说的图像识别呀、声音识别呀,甚至咱们下围棋啊等等很多很多的事情都有非常好的结果。就显然他是很有用的那。究竟如何理解呢,就它为什么有用,就它为什么好使。
因为这个想法像这个比如说多层感知器这种想法,那是早就有的对吧?好几十年以前就有的。那当然当时的技术技术不成熟,就是咱们显卡也不行,这个计算机可能也不行,它实现的比较困难。
那后来呢也并不是说计算机的能力刚刚一提高,马上就有人把那个神经网络给建起来了,然后把它给弄好,不是那样。其实你像咱们这个呃计算机一见就是。这个这个摩尔经利用是吧,已经又发展这么多年了,直到这个前几年。
才有人。把这个啊就神经网络给搞出来了,然后做出这个深深透深度学习的模型。🤧做出这个深动模型,然后才才发现原样它是有用的。就说这不是说一个从理论上我们看出来它有用,我们才去用的,而是我们真的用了。
然后发现它有用。然后这个大家就这么用。那不知道为什么没有人知道为什么可以目前为止是吧?那嗯那我们这个这次课的第二部分呢,我们就简单介绍一下嗯。这个chris这个他的一篇文章中的一个观点就是说。
他大概解释一下说当你的这个深度。深度模型的宽度比较窄的时候,它其实是在做一件什么事情。那。呃,他有没有一些局限性啊,嗯,就是他为他到底是怎么去把你这个他举这个例子是一个分类问题啊。
就是说怎么去把这个分类个分类问题给完成的,就就是中间都已经都经历了经历了一些什么。当然这个最终发现。他这经历东西呢其实是跟这个曲面啊,跟我们前面讲的这个呃流行呢是有点关系的。
所以说我们把前面部分放在第一部分。然后我们接下来在这基础之上,我们去看看啊,如何理解这篇文章里的观点是如何理解啊。深度学习在一定程度上在做一件什么事情。好。
把这个原文大家可以在这个PPT上一点链接就找到了哈嗯。好,首先稍微就是回顾一下这个深度模型就是。这来查下。深动模型的这个最基础的形式呢就是这样,就是你的输入。是一个向量啊,比如说你图片的话。
你就是一个1万维的一个向量。然后呢呃。这个是最基础形式啊,就是说。你这个向量它就会。啊,比如说它就会被这个投输入到这个中间的每一个节点中去。那节点是什么东西呢?就是比如这个节点嘛。
他接收了前面这三个东西的书,你得到了一个三个数对吧?然后他把这三个数呢先做一个性的变换啊,就是节点训练的时候,中间有一个首先它有性的变。那线性变化完了之后,就是线性函数完了之后得到个数吧。
他把那个数呢再用一个激活函数啊,以前的话经常使用这种。就是。就是这这个这个。这说。啊,或者是你可使用tcht就是形状画的话跟很像啊,tch就是这样tch。To?这个文章写的时候好像大家用碳纸表较多。
所以经常拿碳纸做例子。啊,这个是那个国际回归的那个那个那个函数。然后现在还有很多别的嘛,就是说比如说这个。这种这边给个现象。这边给一个属性,这个叫做exential linear unit。然后。
然后还有这个。呃,是更简单一点的。比如说这个线性的这边直接取零啊,就这样,然后还有一些比如说。就最近出来了一个比较火的啊,就那个呃。就叫什么self normalmalization,就是字。
那我来再选。规范化的自规范化的一个这个计函数就是。跟这三像就是等于。把它基础上乘一栏杆,就这边呢。这现性的呢是比一大一点。然后这边呢这可能也更深一些,这排出。总之就是有各种各样不同的东西。
就是它是先做一个线性变换,然后呢再做一个这样的个变换。这个变换呢,它基本上它是个增函数啊,就是首先它是增函数,然后呢嗯。啊,他可能两边有借或者无借,这就是有不同的选取。但是他是一个。
递增了这形状还是比较简单的一个函数。就是啥。你先做先情先做一个事情,然后再做这个。然后每一个节点都做同样的事情。把它们的输出像这个呢从一个三维向量变成一个四维向量,然后把他们的每一个输出再跑到。
下一个下一层去就是你从输入输入层进入第一个隐藏层。那中间可能还有好多个隐藏层啊,从第一个隐藏层进入第二个隐藏层也是做同样的事情。你把这个思维强调,又变又输入到下一层,下一层再做一个新线性函数。
然后对应的线性函数结果呢哎再做一个这种。激活变换,然后就不断的一层一层一层一层,最后到最后这个输出层。比如说你这做一个事二分呃,比如说你做的是一个。呃。你的输出是一个嗯有两个。参数的输出对吧?啊。
那你就输出可能留两个节点,然后你这个节点输出一个数,这个点输出一个数。啊,这个阶点做一个第一个方向的分类。比如这个阶段做为第二个方向。你就分成四类吧。比如说就打个比方说啊,你分成四类做这个事情。对。
基本的那个深度学习模型的基础形式是这样。啊,那。这个呃那最简单最简单的是什么呢?就是干脆就没有这个隐藏层。就是隐藏层能就没有一个一层能没有,从输入直接就输出了。那这是最简单的形式,是吧?
那这种形式的深度模型是什么呢?那就不是深度模型,而极浅的啊极浅的这种模型是吧?这个网络模型是什么呢?它其实就是一个线性线性分类器。啊,你刚才不说了吗?比如说打比说最简单的情况吧。
你们画一个简单最简单的一个网络。Yeah。最简单的网络。就是比如说。哎,你输入是一个二维的向量。然后直接就进入输出。数就是1个XY。输出呢就是这个一个0到1的一个数啊,-1到1的一个数。感一水。
那其实他在做一件什么事情呢?你不等于是在一个平面上。那,就就首先是一个作为线性函说,对吧?线上之后呢,再把那个线下函数这出这结果呀再给它压一下,别能压到负1到1。比如说那个就用刚才那种。
这这最最最原始的这个这个这个呃逻辑回归的这个。这个计活函数对吧?那其实他做件什么事情呢?他就是把你这个二维空间XY。就是其实就是做了一个逻辑回归。呃我们最简单的这个时间往后就是问规归。
把这东西切了一条线。然,这边呢是输出值代言的。这边呢是输出值小于零。你就做了一个分类对吧。对其实所以他其实就是做了一个线性分类器。那打比方说。我们现在所研究的问题是这样这样一个问题,一条蓝线,一条红线。
那这蓝线和红线分别代表两种不同的啊数据啊,比如说蓝线是那个。Yeah。嗯。比如说蓝线就是这个哭的表情,这红线就是那个笑的表情之之类的这种这种东西啊那。如果我们做一个。
就是我们右边那个图里面画的这个最简单的。指接网络的话啊其实它就做了一个线性累系,就他需要找到一条河一条直线去把蓝线和红线给它分割开。而这个问题当中呢,你这直线其实是不存在这样的完美的直线。
你就这条直线就算不错了。你画在这儿啊,这蓝线有一些错误的地方,红线有一些错误的地方,错误多不多错合。那如果你要画的再差一点就,或者你画到这儿,那你就是蓝线都对,但是红线就基本上都错,那也不行,对吧?
所以说。哎,经过训练,你发现这个线放在这儿就挺好,就就就行了,最好经也就如此了。单层模型那其它其实就实现了一个线性分理器。那为什么我们要使用深层模型?就是因为呀这每一层当中我们说啊先做一个限性函数。
再做一个激活函数变换。这每一层当中都会引入一些非线性的。啊,非线性的变化。然后你再综合起来。你这个分类器呢这个这个输出呢,它就不会再是一个线性分类器了,它就会变成一个具有非线性特点的分类器。你打比方说。
就刚才那个问题,如果你要是采取两层的模型。基本上你就可以得右边的结果,一个抛物线。就给它分开了。那这个分类那可定比刚才的好多了,对吧?你刚才这样一分,那将来比如说你再有一个新的点,一个这个嗯。
带点噪音的点嘛,就是本来你的红线这块也没分好,你在这再有一些点。那其实基本上我们如果肉眼看,你知道基本上还是应该属于红线这个范畴。但是你这个发电器可就。他就会认为它是属于蓝线的一个范畴,对吧?
那如果要是嗯多加一层,你得到一个二次曲线。那你就可以把这个就分的比较好了啊,基本上你就。就成这样了,即便你加一点噪音,好像问题不大,对吧?你在这有时点,你还知道它是。你在这有一页,你知道他是。
对吧就是这个当你加深的这个呃。模型的层述之后。你会有这样的效果。那这个如果我们只听到了这一点上,我们知道那层数越深这个效果越好,这好像也是。意义不是特别大,那我们基本上知道的,你想你如果100层。
如果你十层能解决的,你11层基本上也应该是。不是可能训练更复杂一些,参数更多,有可能会增加你这个over face的风险。但是。你不考虑那个问题了,是吧?你肯定是参数越多,你这个模型训训练结果越好。
对吧?就你如果只考虑你这个inscentcle对吧?那那个说明表什么太多的问题,那后面这个。就说我们为什么加了一层之后。它会产生这个效果,就是他为什么加一层之后。我们直接从初始到截局看。
我们知道效果变好了。那中间发生了些什么,这个时我们想看,我们想知道深层模型到底在干什么。所以我们想看它中间发生了么,对吧?好,看一下。如果我们考虑的是一个不是单层,是多层的话。那么其实呢。我们是把。
这个原始数据啊。就是说这是我们可以这个具体的可视化吧,就是我们可以把那个数据给它画出来。那呃这里面我们就举这个例子啊,就是说。原始数据这两条曲线是这样的,它是线性不可分的。但是呢我们说经过了第一层输入。
输入到第二层,就是这个隐藏层进进行一次变换以后。我们这个图里面画的三维到4维,啊,其实我们这个例子里举的都是二维到二维的对吧?我们就是。啊,你就考虑这个这只有两个节点,这呢也只有两个节点这样情况啊。
最后呢应该是一个节点。差右边。就是说出入是两个节点。隐藏层是两个节点。输出是一个节点,正确。这样就是。Input。是黑的。就是 output。这好,那么。输入是一个二维的平面里边的好多个点,对吧?
两个曲现。那进入隐藏层之后。它隐藏和变换之后,它会变成什么呢?它还是一个二维的曲面,呃,二维的平面对吧?你为说你只有两个阶点,它输出还是两个数。那这个平面里边那些点和刚才那平面里那些点它就应该不一样了。
变成什么呢?哎,它就变成了我们现在右边那图画这个样子。他把这条缆线。给推推推推到这儿去了,把红线推推推推到这儿去。这个时候就是说经过了隐藏层变换之后,这两条线它就变成了什么线性可分的。
所以在最后一个隐藏能输出的时候。他才能够形成一个啊比较完美的森林。就是这个图是我们在隐藏层的最后一层和输出层之间看到的图。而如果我们直接看了。这个初始的图和这个分类结果,我们看到的是这样一个分类。
这最后一步,它一定要是个线性分类。这就是一个线性分类。但是之所以最后一部分线性分类分类能好使,是因为前面这些隐藏层对你这个呃。平面里面这些线啊点啊进行了若干的变换,使得他们。信情可分。
其实是这么一个过程。啊。所以说呢。就是这个大概告诉我们说,我们深度模型的前面那些部分,他在做什么。它其实是就是到目前为止,我们就认为他做了变化嘛。他把这本来心情不可分的,变得心情可分。
我们可以先听到到这个程度。然后呢。我们可以看看这个啊更复杂的情况。是螺旋线,就刚才那个两个线。这个还是比较好的,就是你这个分还是相对好分一点,对吧?是。更复杂情况是螺旋线。那现在如果你拿线性分离器。
基本上你就没辙了,怎么分都是特别讨厌,对吧?你这个误差都极大。Now。这个时候如果我们用深层模型的话,它给我们的其实是一个什么什么过程?就深层模型。当然可以把它分分清了,这也没有那么复杂,是吧?但是。
深层的情其实做了什么事情把它给分清了呢?他是怎么去去呃对这样的数据进行分类的呢?哎,我们可以看一下这个动态的图就是说。文也是在这个文章里面节选。对。你看。嗯大家可以看到这个。这里面的动态图吗?哎。
你看一开始的时候是这样的。他先做为性性变换。然后呢,做一个探。然后做再做一线变压缩了一下,再做探势,然后又拉了一下,还是线线变换,又做一探势。然后再拉一下。嗯,现在它这个已经是线性和奋斗。
它是这样一个过程,就它把你这个本来的平面进行不断的扭曲压缩变形。使得本来现性不可分的东西呢变得啊就是现性可分了。是这样一个过程。那这样的变换。这样的变换,我们说它其实是从我们top的角度来说呢。
它其实叫做啊同培变换。就是说啊它不改变空间中数据点的拓扑性质,那什么意思呢?就是它不改变那些。点。点和点之间的位置关系,哪些点是相连的,哪些点是不相连的,他不会把这个空间撕裂。
就当你做深用这个深层模型对这个图形图形进行变换的时候,它并没有产到产生撕裂的效果。它不可以把你这空这个图形中间切一刀,然后撕开一半放地边一半放里边,它它不能做这种事,它只能对你先压缩压缩拉伸。
就是哪个方向拉一拉压一压,然后呢。非线象的部分呢就是把那个你看这个压完之后,他把那个边角的地方啊给弄弯了一下,然后再重新拉,再重新变变弯。通过这些操作来使得你本来心情不可分的变成心性可分,是做这种事情。
那这样的事情其实并不是十分的就是它并不是包治百病的,它并不是十分的总是有效的。他可以将刚才我们说这种情况里面原本套在一起的不同类别所对应的流行进行一种解套。就是有点套在一块儿,然后他这个你拽一拽也。
拽开是吧,这个意思变得相艳可分,然后进行完美的分类,对吧?但是对于一些不是那么好的数据,你刚才那种方法可能就不太好使了。那为什么呢?比如我们现在这个数据。这个数据里面啊它是两个圈啊,一个圈儿,一个点。
里边这个红点对吧?外边这个蓝色的圈,那它们代表着不同的类型。比如说你现在做一个分类模型嘛,代表不同类型。那对于这样的数据,如果你还做刚才的那个拉伸或者旋转,或者这个加入点飞间影象这种。
我们说同配变换的话,你是永远都不可能把红点和蓝蓝圈把它变得心灵可分的啊,就是说。

应该有一个。例子啊,就是说。哎,你看这里面一开始呢它是一个红面,红圈还蓝圈,对吧?然后它你这个压缩,反正你可以用各种方式去去蹂躏它了。你是你是怎么压是怎么扭啊,怎么怎么动,但是你永远改变不了这个蓝的。
把蓝圈,把红点包在其内部的这个这个事实。就是你在这种情况下,我们刚才这种模型。

这我后右边画成这种模型。就是。输入两个节点,然后每一个隐藏层都是两个节点。这种模型你永远不管你用多深的模型,你永远都不可能把你现在这个分类问题解决,你就做不到。原因是什么呢?就是因为。我们的身这个。
当你这个宽度比比较窄的时候哈。从二维到二维,你一直都在做这个同类变换。你永远不可能通过这种变换去把套在一块,完全套在一块的啊,两个结合给它分开,也是做不到的。
所以说我们知道对于某些数据宽度较窄的这种模型啊,从原理上你就不可能跟成完成分类。就当你训练一个模型的时候,你发现它总是不行,有可能是因为你的。有一些计算的问题啊,参数调整不好啊,你的这个呃。
这这超参数可能调整不好啊,或者你的这个嗯。收敛的那个优化这个算法不好啊,等等有可能有那些原因。但是呢也存在你这个结构的问题。有可能其实结构上你就解决不了这个问题。甭管你用什么样的优化,你都做了。
这是一个从我们这个角度来看,可以找到的就是深度学习,在某些情况之下是有局限性。

那么要解决这个问题呢。一个办法就是增加你的这个模型的宽度。你增加宽度以后呢,你就可以把这个低位的空间投影到更高一点。比如我们刚才说这个一般这种形式。这里边从三维到4维了,就你可以想象。
我们也可以从二维到三维,对吧?就是说你从一个二维的平面,你投影到一个。


三维的空间中去。那在这个时候。比如说这个例子里,你就把这二维平面投影到3维空间中去。投影完之后,你发现这个红色的区域和蓝色的区域,你就可以用一个斜着的这样的平面是把它分开了。
那这个时候他们就哦线性可测了。所以说我们知道在这种情况下,我们可以通过增加你的模型的宽度的方式。唉,从这完完成这个分类,对吧?

那。当然就还有一些呃更复杂的情况。比如说这个鸟结啊,就是这个是本身是个三维的问题,对吧?就是你红的和蓝的形成了一个纽结。他们俩你怎么拽转。就是这个也是在拓普学上说。你你使用这个同坯或甚至同轮的方式。
你都无法将这个红的和蓝的。一种方法是说,反正他俩勾在一块,有些有些勾在一块,对吧?那你把它尽可能的拽开吧,就是说嗯你让他俩形成一个。小小的勾在一起,放在这个图的角落里,然后红的在上面,蓝的在下面。
然后最后你分类点时候中间那有点误差也无所谓了。那也行,但是那种方法显然就是不能完美的解决你这问题,对吧?那所以如果有你有节奏,那其实你原来来说你还是必须。走到更高位的空间中去,你才能解决这个部分。
这是一个。就说。😊,所以这两个例子呢就是说。在某些数据比较。奇特的情况下就是比较这个嗯不是那么友好的情况下那。你使用宽度角胶窄的这个深物模型,你永远都解决不了你的问题。但是呢。
在你这个嗯比如像前面那个问题里,当你这个。没有那么严重啊,就是他们俩最终拧一拧,还是可以可分的时候,他其实也不见得好办。因为你看我们刚才这个就这么一个简单的图吧,我们这个模型其实也是经过了。若干的挣扎。
Sure。给我们上面好多这个链接,一点。我们目前也是经过了这个。若干的挣扎呢,他才最终哎变成这个陷阱分,对吧?甚至这里面还有个例子,就是说有些时候呢,你这个如果训练没训练好的话。
你就刚才这种简单的情况啊,你这个。扯来扯去扯来扯去,他可能最终也没有能够把你这个两条线给它分开。就说。其实这个例子已经并不是很复杂了,吧,但是。你想把他们两蒙灭也不是太容易这个意思。好。好。
那么这个时候就提出了一些啊开放性的问题。就说除了使用较宽的宽度较宽的深度模型外,我们是不是还可以结合流行学习的方式来改进我们的这个深度模型呢?打比方说。刚才这个问题里头。就是说。他也他其实已经很简单了。
但是。从肉边来看,其实很简单。但是呢。从渗能模型的角度来说,呃,因为你最终要构建出一个。极具飞线性的那个。区分线。所以说你需要好多层才能解决这个问题。但是。如果你本身就知道一些它的这个流行结构。
如果你能够在这个流行内部给它进行一些收缩,那你是不是就可以更好的解决这个问题呢?比如说你先把他们两个流行重构一下。然后呢,你在这个做深度模型的时候,你不要对整个空间进行控制,因为整个空间。你进行压缩啊。
拉伸啊或者是旋转啊扭曲啊。你对里边的影响都比较小,所以你要弄半天才能弄好。那如果你要是能够啊针对这个流行自身,你先做一些先。比如说你把这红色的。把它往这边推一点,这个往这边推一点。
这蓝色的呢往这边推一点,往这边推一点。然后在这个基础之上,你再去使用我们刚才新的模型,那它可能就很容易就可以做的先这这个先性可分,对吧?就是第一个问题,我们是否能够啊。
结合这个啊流行学习的方法来改进我们现有的这个深度深度学习的模型。嗯,第二个就是否可以借助这个流行学习来增加。深度模型的可显释度。那比如说。我们刚才说了那个生成模型是吧?就是说有人的表情的这个问题。
那你有了这个。你了表情之后,你如何在中间插入一些中间过度的表情。那深层模就有一些比如说我们我们后面老师可能会讲那个呃深度的这个生态模型就是。啊嗯。就那个G因这个模型。然后我们以前呃翻译文章也做了很多那。
这样的人这样的模型,他可以给你做生成。但是他为什么可以做生成?可能你就不见得看那么清楚。也许你是不是可以借助流行学习呢?来增加我们对我们已有的这些深层模型的这可解释程度。那还有呢。
当然反过来我们是不是是不是可以借助这个深层模型来改进这个流行学习的效果啊,这个其实是现在已经有很多这个结果了。我在那个查找文献的时候也可以看到一些啊,等等还有其他的问题。就说。
我们当我们对这个深度学习的模型呢有了更多的理解以后,我们是不是可以找到。更好的机器学习的架构。我们是不是可以啊。解解除我们现在当前这种依赖于一个。黑盒子这种境地。将来若干点可能需要去解决的问题。
那也是啊我们现在。就是我们自己包括我们现在听课的同学啊,我们将来是不是可以在这个领域中做出更多的贡献,做出更多的事情。好,这时候开放现问题。好,那这个今天我们主要的内容就这么多,感谢大家。
然后啊我们还是继续这个。宣传一下我们这个呃接下来的呃这是礼拜一哈,礼拜一中午。然后接下来礼拜二到礼拜5呢,每天晚上都会有一些公开课,就由我们的老师啊给大家准备的,当然可能。公开课嘛都是每个老师只样一节。
所以他不会把这个东西讲的非常系统。但是呢会给大家介绍一个有意思的主题。希望欢迎大家来听。然后我们还有很多的宣传,很多的活动啊,就是这个啊后面我们啊下半年的课程有很多优惠的活动,也是在店在这个中年庆期间。
欢迎大家关注。好,今天我们主体内容就到此为止。然后大家还有没有什么问题?好嘞,谢谢大家。😊,呃,同学问那个流行学习的应用层面,有没有现在可以用的工具?
那个呃我看到那个SK learn里面其实就有一些工具,大家可以去看一下,他们它好像还有他不但有工具,他应该也有一些这个。就那个文就是文档他写的也蛮好的,就大家可以看一看,好像这个。呃,他terflow。
orflow有没有,这个我还不认清楚。嗯,大家再找一下看看。好,那这个好就是听老板的话,大家准备去抽奖吧。我有好好像我们还有好多这个奖品没有抽出来,大家祝大家好运。😊,好。

已经到此为止。
人工智能—机器学习公开课(七月在线出品) - P21:用pandas完成机器学习数据预处理与特征工程 - 七月在线-julyedu - BV1W5411n7fg

OK那么我们接着往下来讲啊。那么第二个知识点呢,也就是呢伙团的一个分组,还有一个合并啊,分组跟合并。那么分组跟合并什么意思呢?那么它肯定是对于我们一个表里面有多个这样的一个行跟列来进行这样的一个操作啊。
其实呢你可以简单的理解,比如说我们现在有一个很大的一个表格是吧?里面数据太多了,我想把这些里面的数据呢给它啊拆分一下,那么我们就可以用什么分组的方式啊。
这个给我们srcle里面是不是啊这个什么where heavy啊,是不是类似的是吧?然后合并,也就是说你拆完了以后分完了以后进行处理了以后是吧?最终是不是还要把它合并成一个啊de frame啊。
de frame那么这里面举一个呃例子是吧?啊比如说我们来。创建了一个啊d frame是吧?这里面有哪一些内容呢?比如说我们有这个name对吧?有year,还有我们的啊sary。
还有我们的 bounce是吧?有对应的我们的姓名年龄啊,还有这个工资啊,跟这个啊奖金啊,那么当我们创建完这样的一个d frame啊,或者说我们拿到这样的一个数据啊,我们来运行一次啊。
你看到当我们拿到这样的一个这样的一些数据的时候啊,那么更多的啊,其实呢像这个里面你看到是不是年份,2016年你的工资,你的奖金是吧?又是2016年是不是老宋就这么多了,对不对?
那么其实我们更想知道是不是做一个统计类的啊,统计类的。比如说我要把老王这2016年或者是2016年跟2017年是不是所有的这样的一个工资给他。呃,加在一起啊,对吧?来求一个和对吧?哎。
那么这个时候呢我们该怎么去操作呢?我们可以先把它给分出来啊,要不然这个是不是不好操作啊,是吧里面又有老王,又有老宋,对不对?还有容 name啊,你不好操作。
那么这个时候我们可以先分啊分那么分可以怎么办呢?我们可以用啊g by来进行我们的一个分组啊分组那么分组非常简单啊,我们直接去调用group by这样的一个函数啊,就O了啊,就O。
那么如果说你们对这个srcle有了解的话,其实这个g by啊,其实它就相当于什么对于某一列来进行什么呢?相当于进行呀汇总啊,比如说我们这里面你可以传一个什么name是吧?你可以对啊name呀吧?
或者year啊或者我们sary啊等等来进行这样的一个汇总啊,但是在这里面一定要注意我们得到的是什么呢?是一个de frame grow by啊,这样的一个什么呢?对象啊就是将相同的名字汇在一起呢。
其实不同的名字给他干嘛呢?分开啊,不同的能字给他分开啊,这样一个其是单纯的比如说我们这样的一个啊group by,其实没什么太多的一个意义啊,也就是说我们只是通过这样的一个方式。
这样的一个group by来帮我们去构造了一个group by object。是吧那么我们可以通过这样的一个group by object呢来帮我们去进行什么呢?后续的一些操作啊,后续的一些操作啊。
比如说我们往下面来走是吧?这里面是吧?比如说有这个呃aggregate是吧?O那么首先我们比如说针对于这个name来进行什么呀?求和是吧?是不是刚才我们在这上面已经对于这个name来进行分组了呀。
要分组了以后,比如说我们要来进行这样的一些统计,比如说哎直接去调一个这样的一个summer啊,那么这个summer。上面我们来运行一下啊。OK那么通过调这个summer这个方法呢。
其实我们获取上面的这样的一个object啊,g by objectject来进行这样的一个求和。也就是将各个列的信息呢,给我们加在一起啊,各个列的信息加在一起,而且是按照什么name啊。
按照name的方式已经给我们分好组了,然后把对应的是不是年是不是工资是吧?奖金啊全部的进行的一个累加啊,但是这里面是不是y它也给你累加了呀,对吧?这个 year累加是不是没有什么太多的意义啊。
这里面只是做一个啊演示啊演示。OK那么看到它的结果呢,其实呢你会发现是吧?其实它没有什么一个啊规律啊,只是根据这个name来显示后面所对应的数据啊,那么呃其实在这里面呢,我们可以么用它来进行一些。
比如说啊其实它内部有很多这样的一些属性啊啊属性。其实可以看我们对应的这样的一个啊gr by它的一个什么呀。源码啊可以看一下它的源码在这里面啊,我们来打开可以看一下对吧?它这里面其实有很多啊。
比如说有很多的参数啊,还有什么两个星号的KWX是不是可以写很多的这样的一些值啊,对吧啊,分别表示什么样的一些含义啊,在这里面啊,其实呢有相对比较详细的一个呃介绍啊,先比较详细介绍啊。
一会我们后面啊我们用到我们再来讲啊,那么比如说排序这个啊排序这个那么默认呢其实这里面啊,它是有这样的一个排序。那么你也可以选择不排序。那么如果说你要选择不排序的话,干嘛呢?
比如说我们把这个啊shot设置为什么forse啊,设置为forse是吧?那么啊这样一来呢,就可以完成啊完成。OK那么往下面来走啊,往下两面走是吧?呃,除了可以通过这个g by来帮我们完成以外,是吧。
还可以通过什么呢?我们的一个aggregate是吧?哎,它也可以来完成我们刚才所实现的这样的一个内容是吧?那么这个表示什么样的一个含义呢?其实呢就相当于呢哎我们的一个呃这个搞定是吧?
O我们来看一下这个函数它表示什么样的一个意思是吧?或者说我们来看一下它里面的一个参数啊,参数。那么第一个是不是FUNC是吧,我们的一个。哎,也就是说这个函数它之所以强大,就其实呢第一个参数非常留地是吧?
它可以传函数啊,传函数,而且这个函数还可以是什么呢?啊可以是stream是吧?可以是list还可以是什么字典是吧?也就是说你不光可以传一个函数的一个名字,你可以把函数名字是吧?用字串的形式。
或者用列表的形式啊,往里面传都是。ok了啊O了。比如说我们在这里面啊呃通过go by杠 name点上一个我们的aggregate对吧?传了一个summer。那么summer是不是相当于一个求和的呀。
对吧?啊?相当于一个求和。你在这里面来进行我们的一个运算啊,肯定是没问题。对吧,那么如果说我现在把它给改一下啊,也就是说把这个summer呢给大家换一下啊,我来copy一下。在这下面啊哎在这个下面啊。
我们再来加一个,我把这个summer换成什么str类型,也就是什么?哎,我在这个前后给大加一个引号,我再来运行一次。就实呢结果跟上面是一模一样。啊,结果跟上面是一模一样。OK啊。
也就是说它啊支持这个函数的呃种类呢是很多的。那么这个summer呢是不是python里面的一个内置函数啊,我们可以什么直接去调,而且可以换成字符串啊,同样呢它是识别啊。
也就是么这个AGG这个函数呢功能啊非常强大。那么除了这个以外呢啊可以往下来走是吧?还有呃它里面常见的一些内容啊,比如说我们可以呃还可以什么?比如说你想要去那么求平均啊啊,都行啊。
在这里面啊不光是这个呃summer是吧?你求和啊求平均啊,都行啊,我们在这里面也可以写一下吧。比如说在这里面我们把这个summer呢换成我们的一个平均。
那么平均是不是命你不能直接调人是不是用用n派下面的我们的一个命对吧?O啊,这个也是O了啊,可以拿到它的一个什么对应的平均的啊,平均值是吧?那么还可以干嘛呢?比如说你要求标准差,对不对?
那么是不是也可以直接去调我们n派下面的STD啊,O啊,哎哎哎哎点STDO也可以什么样拿到对应的我们这样的一个啊标准差是吧?OK这是它的一些常见的啊常见的。那么我们对应的这样的一个group by呢。
还有哪一些。比如说呃可以看看它的一个啊group是吧?那么比如说呃他会告诉你每个name的一个什么呢?index其实在这里面我们可以看一下是吧?它的一个index是什么呢?是不是对应的呃。
相当于什么这个索引index它所在的一个位置啊,是吧?我们老宋在哪几个位置,是不是126这样的一个位置是老宋啊,你可以往上去翻对比一下啊,看一下最上面是吧?你老宋的一个位置,是不是哎12是吧?
索引为一的索引为二的是吧?还有索引为呃这个六的是吧?对应的值是吧?那么往下面来走,其实都是什么呀一一对应的一个关系。也就是说在这个里面啊,我们可以干嘛呢?呃,查看通过他的一个这样的一个groups啊。
来告诉我们所对应的name啊,的一个index啊,除了这个以外,还可以查看它的长度是吧?比如说哎到底有多少个是不是就三个呀,对吧?老王老宋还有一个鲁妹是吧,就这三人啊。OK那么除了这个以外呢。
我们还可以比如说呃针对于我们这样的一个呃group by,就是说我们上面啊呃使用这个group by呢来做限定以外,其实还可以用下面这个 columns啊来做这样的一个呃group by。
也就是嘛你可以按行的方式也可以按什么呢列的方式来进行我们这样的一个分组的一个操作啊,比如说我们还是以这个为例啊,我们通过什么呢?这样的一个呃gr by对吧?然后在这里面。你可以传递什么呢?对应的啊。
我们刚才是不是对应的name,那么现在我想要俩了,对吧?我又想name就想一一页,那么你就传两个,然后呢对它进行一个什么呢?求和啊,也是什么呢?OK啊,可以呢拿到对应的这样的一个纸。と image。
OK那么比如说在这里面哈啊我们就针对于这个吧,比如说我们现在拿到这个name year,把name所对应的是吧?老王老宋龙妹是吧?对应的年份也引出来了啊,那么这些值出来了以后,比如说我嗯我想看到啊。
这这里面相当于什么我们每一位员工看到自己每一个年份所拿到的这样的一个工资跟奖金是不是现在都展示出来了,对吧啊,很清晰对吧?那么展示出来了以后呢,比如说我们除了这个summer之外啊。
我们可以其实它这里面有很多属性啊啊,不光只有summer,你还有一些比什么size呀me啊,还有一些什么中间值啊啊等等,对吧啊,都可以来啊,帮我们去达到自己的一个需求。
比如说你想看一下对应的它的一个啊size是吧?这下面啊也已经给你们显示出来了,对吧?还有什么me对吧?还有一些我们的一个啊面点对吧?这样的一个中位数啊中位数。O这些都比较常见啊。
你把它的一些呃对应的属性记住就O了啊。那么还有一个就是这个discript啊,这个要跟大家讲一讲啊,这个呃频率还是比较高的啊,应该把它放在什么?最上面来讲是吧啊。
你可以看到我们直接调这个group by name然后点上一个descript以后呢是不是显示的信息它比较全啊,对吧?
哎这里面就是把我们常见的一些属性都显示出来是吧count meanD mean什么25575max这些是什么鬼对不对啊?其实呢呃比较好理解啊,这个count呢表示基数啊。
也就是说对应的这个name它在整个这个表里面所出现的次数是吧?老宋是不是三次老王是不是4次是吧?容们出现一次啊,那么这个me呢它表示什么呢?平均值啊,平均值啊。
也就是这个还SG表示呢标准差这个命呢表示最小值max呢表示。最大值啊,那么什么2550,这个其实呢就是50是中位数是吧?这个25呢是25%是下四位数,然后呢75%是上四位数啊,那么一般我们在分析数据。
最开始的时候呢,经常使用这样的一个啊discript啊,来帮我们去查看一些基本的信息。其实这样呢呃会更加的方便一些啊,会更加的方便一些啊。把它给缩了啊,这样会看得更清楚一些。OK啊。
那么呃其实呢我们通过这个describe呢,就可以了解每一个cloown啊,它的一个基本的一个情况啊情况。🤧OK那么像以后你在呃用的时候是吧,可以最开始的时候就discript一下。
然后呢啊大致的就能查看大概的一个信息啊信息。OK那么往下面去走是吧?往下面去走,有一个什么呢?我们的一个啊迭代对象是吧?迭代这样一个group by这样的一个对象是吧?
那么啊在这个里面是吧我们怎么去迭代这样的一个对象啊,上面啊这个啊这个没给你们分是吧,应该变成我们的一个呃呃这样的一个编程模式是吧?那么在这里面呢。
我们可以对这样的一个group by呢把name啊来进行一个便利。那么得到什么呢?这里面的name还有什的group啊,我们来就是说显示一下,那么也就什么针对于我们这样的一个name啊。
还有对应的我们的group啊来进行这样的一个细分啊,那么如果说啊其实呢我们通过这个结果啊,通过这个结果,那么这个结果呢,其实就将什么?比如说我们的老王老宋罗们就是这三个哥们给他分开啊。
那么拿到这些单独的数据了以后,是不是我们就可以对每一个进行。单独操作了对吧啊,就相当于什嘛先把它给什么分开啊,分开。那么分开以后呢,其实呢下一步你就可以什么哎选择一个了,你想对哪一个进行操作。
你就可以直接选对吧?哎,选择一个对应的group来进行操作。比如说你想选什么呢?老宋的对吧?哎,你就看一下老宋的,然后呢,可以看一下,这是啊它的一个什么类型。那么你看它的类型是什么呢?啊。
注意来看它是一个de frame。啊, get from。那么我们现在对这个老宋这个哥们进行操作,也就是通过什么呢?这个get啊,这里面又一个新的函数是吧?
get group也就说获取对应的group是吧?来指拿到指定的数据。那么然后呢,我们通过type这样的一个函数呢,来查看一下它的一个类型,发现它是一个dt frame。
那么这里面啊其实每一个group它都是一个d frame。啊,都是一个d词。那么这里面其实呢就是将一个大的表格啊,比如说我们上面是不是相当于一个比较大的表格。
那么把一个大的表格呢拆分成几个小的这样的一个表格,然后呢对它进行单独处理。那么这样会方便一些啊,会方便一些是吧?那么我们拿到这样的一个内容了以后是吧?我们怎么来进行这样的一个操作呢?是吧?啊。
比如说我们又可以通过ag是吧?又可以通过它啊,那么呃这个方法你可以简写,可以简写成什么呢?AEGG啊,AGG是吧?比如说我想要去显示一个求和的是吧?比如说你要对谁来进行求和是吧?
这里面啊这里面写的可能比较多,又能求和,又能求平均,又能求什么这样的一个呃。标准标准差对吧?那么在这里面如果说你只想去单独的拿一个这样的一个球盒啊,也是呢肯定是可以的是吧?你既然可以多个了。
你肯定这个呃单个肯定也是呢OK我们来试一下是吧?你可以拿到对应的是吧?老王老宋荣威啊,他的一个球和。那么也就是嘛通过这个呃。aggregate是吧,来完成什么呢?完成这样的一个呃内容。
那么通过这个AGG其实相当于呢它的一个别名啊,你可以直接去代替去使用。那么一个是ok的,多个呢也是OK的。那么需要用一个什么呢?list来包裹一下。啊,这里面加一个list来进行包裹一下就。
OK了啊OK。那么现在我们知道怎么去拿到每一个啊group。那么接着呢,比如说我们想要对这里面的某一列来进行这样的一个操作,该怎么来去操作,是吧?
也就是说我们可以采用不同的我们的appric get来进行操作。那么操作的时候在这里面就需要去注意了,是吧?它的一个基本的格式是怎么去写的啊,基本的格式是怎么去写的,是不是这里面我们传的是一个字典呀。
传的是个字典啊,比如说我们这里面。是不是选择我们的工资,还有什么呀?奖金是吧?那么对每一列来进行干嘛呢?是不是来了一个求和呀,是不是对工资跟奖金这两个列来进行了一个求和是吧?那么求和以后的一个结果是吧?
我们来看来看一下是吧,它的一个结果是不是对应的就这两列是吧?来进行求和啊,求和。那么啊因为我们对这个 year呢并没有什么呃对他求和没有什么太大意义。但是呢比如说你又想要是吧?这里面是不是。
没有显示年份啊对吧?没有显示年份,那么你又想要它,那么该怎么办呢?是吧?你可以把它给加进来,但是你不要加求和了啊,不用把这个年份给它加进来,你可以选择什么呢?选择呃索引为一的或者是索引为零的对吧?
也对应的是2016呢,还是2017呢,那么这个里面怎么去写啊,你可以用一个匿面函数的方式啊,从这个里面去取啊,比如说根据你的索引啊来进行拿啊,比如说你拿零,那么对应的,我们就拿201116年的对吧?
那么如果你想拿2017年的啊,给它改一下,就O了啊,O那么下面呢同样啊这个呃也可以嘛通过啊我们这个di来显示对应的啊这个里面的一些信息。
那么这个其实就是我们呃比较常见的这样的一个什么呢分组跟聚合的一个操作。我们使用这个什么group by将一个表格,比如说我们拆分成若干个这样的一个部分啊,然后呢。
我们使用这个appric进行一个一个的汇总啊,比如说你到底是求和求平均,到底是干嘛啊,操作完了以后呢。相当于什么?你是不是又得到了这样的一个相当于汇总到以后,其实呢他还是一个d夫人。
或者说你可以这样去理解我们pas呢其实提供我们行跟列的这样的一个啊聚合操作。那么你可以把这个gr by呢就简单的理解为是行的这样的一个基于行的这样的一个操作。
那么这个 aggregateate呢理解为是什么?基于我们的一个列的啊,而且我们从上面的这些例子来看呢,g by呢返回的是一个de frame grow by这样的一个什么结构。
那么这个结构呢其实呢它必须要去调用我们的一聚聚合函数,对吧?比如说我们的一个summer啊,你调了summer了以后才能够得到结构为saries这样的一个什么数据的一个呃相当于什么结果。
那么而我们这个aggregate它是不一样。它呢是de frame的一个什么直接方法,它返回的就是一个de frame它本身就是一个de frame啊,那么它的功能啊就有很多了。
比如说我们的什么summer啊命啊,它是都可以呢实现的,也可以实现它的一个简洁版,你可以直接用什么AAGG来进行。期待啊更加的简洁。而且呢你传给它的函数是不是可以是什么呀?字助串的,也可以什么呀?
是自定义的对吧?啊,参数我们的一个啊con啊是对应的这样的一个。比如说我们的一个啊dad frame啊,这是我们针对于这样的一个呃。grow by。
还有呢我们的一个ag它俩的一个描述啊描述O那么除了这个以外,那么后面其实还有两个常见的是吧,一个是transform,一个什么fieldelt啊f。那么这个transform呢就比较灵活了啊。
应该是它应该是这几个里面相对来说啊最灵活啊,其实这个transform呢主要就是表示对一张表格呢,我们来进行转换啊来进行转换啊。
但是它的特点呢呃也就是说它可以根据我们呃比如说各自的特征来进行单独的这样的一个转换。也就是说它可以把我们这个group里面这样的一个比如说每一个记录吧。
都按照比如说同样的这个规则来进行这样的一个转啊来转来达到我们想要的这样的一个效果。我下面走了吧。我们来看一下是吧,看一下这个呃trans是吧。
这里面呃用了一个呃NVDA啊一个这个股票的啊股票的这样的一个数据是吧?那么用这样的一个数据你显示了以后是吧?你会发现有什么呢?啊,就相当于开市的闭势的最高的最低的啊等等这样的一些数据。
然后对应的这里面是不是还有一个dt?d那么这个读这个CSV文件是吧?这个就没什么好讲啊,这里面传什么呢啊,你读入文件的一个位置是吧?不管是相对的绝对的啊,都行啊。
然后这里面呢啊还有一个什么index啊扣是吧?那么这个表示什么意思呢?用作啊我们这个呃行索引的一个列编号或者是列表啊,比如说这里面你写零是吧?其实呢这里面就一个d是吧?或者说你可以呢直接写d也可以啊。
O我来试一下是吧?O给。转一下,我把它给注释掉了。注释掉啊,然后在下面我们给大家重新换一下,把这个零呢你就可以直接换成我们的一个dt。然后呢,对应的这个里面啊,我们的一个解析是吧?
paris death是不是?哎,你对应的indes gone啊,我们的一个啊collog是吧,是啥?你解析的就是啥,是吧?来一个dt。OK那么这两个主要呢匹配上了是吧?
OK那么同样啊操作是啊得到的结果是一模一样啊,这个根据你的一个需求啊都行。那么这样一来呢,我们就拿到了比如说呃这个呃股票的一些信息啊信息。那么我们拿到了这样的一个信息了以后呢,我需要比如说对这个股票。
我现在想要干嘛呢?按照年份来进行分类啊,分类那么其实按照年份来进行分类,我们这个年份啥呀,是不是就是一个一个的index呀。那么也就是说我想要拿到这里面所有的index该怎么去拿呢?啊,最简单是吧?
就来一个。拿到我们这个NVDA对不对?拿到它点上一个什么呢?点上一个index啊,非常简单啊,我们直接吧拿到这样的一个index啊就可以了。O来运行一次,那么就是所有的年份。
但是这个拿的时候是不是好像里面还带月份的,对吧对?然,我们把它给过滤一下对吧?啊,过滤一下,在这里面我们给它一个比如说再加一个什么呢?加一个year,点上一个我们的一个ear。是。OK我们再来运行一次。
那么这样一来呢,就把就过滤出什么所有的年了啊,所有的年是吧,基本上就拿到了。那么呃除了这种方式以外呢,其实我们还可以通过什么呢?这个年来,比如说拿到其他的一些的值。
比如说我们的平均值啊等等吧比如说我们现在啊想要拿到这个股票对吧?每年的一个啊平均情况啊,你就可以直接把它作为参数传给我们的group by,然后呢调一下我们的命这样的一个函数,可以拿到啊。
针对于年这样的一个什么呃股票的一个平均的一个情况啊,O这是这样的一个内容。那么除了这种方式以外啊,其实啊还有啊比如说我给他换一个,其实我不用这个什么呢?不用这样的一个呃。
g by或者我用刚才我们呃才学的这样的一个什么呢呃AGG啊,其实也可以啊,或者用group by加AG也可以先把它分分完了再定对不对啊,也可以啊?比如说我们把它前面呢copy一下。
或者整个的copy一下,后面呢命呢我们就不要了,对吧?啊我就可以不要命了,我可以什么把它是么作为参数啊,来个什么呢?AGG对吧?然后呢在这里面我把这个命是吧拿到我们的n派点上一个命OK啊。
把它作为参数那乘进来啊,其实这样呢也可以什么实现这样的一个啊,我也可以拿到什么呢?对应年份啊,每只股票它可能它的一些啊具体的一些情况对吧,它的一个平均值啊。OK那么这个是我们对应的是吧。
怎么去根据某一列的值是吧?来求呢?比如说我们对应的这样的一个平均值啊,那么除了这个以外啊,比如说我们按照下面的是吧?呃,其实还可以。比如说我们可以把刚才内容,你可以拿画个图吧来显示一下是吧?
这个呃用图呢来显示,其实呢相对来说更加的直观一些,是吧?比如说我们就拿它吧copy一下了啊,拿它点上一个我们blat。🤧点上一个plO啊,然后呢我们来运行一次。呃,这里面拿不到拿一个平均值啊。
我拿平均值了,点撞一个命。啊,调上给他OK那么这样一来呢,我们就可以呢呃拿到这个图片,但是拿到这个图片。好像只有这个咖啡色的吧,咖啡色的这个呃man是吧,对我们的意义没有什么太大。
应该是什么open啊hi呀,是吧?这些参数对我们更加的有意义一些。但是好像没有显示出来是吧?那么这个时候呢,我们可以呃过滤一下,我们把最后这个根们给它干掉,在这上面再给它过滤一遍。
把最后这给大家给大家删掉,那么删掉是不是过滤我们之前用哪个方法呀,是不是可以用这个Iloc啊,是吧?Ioc,然后呢,比如说我们给它剪掉,对不对啊,减掉那么剪的时候呢,我们比如说去剪最后一个吧。
来一个冒号是吧?来个逗号来个冒号,比如说到啊-一吧,负一给它给干掉啊,OK然后在这里面我们再来去呃显示一下啊。O那么这样一来就啊比上面要好多了啊好多了。那么这样对于什么我们的open high呀。
low啊,clo啊,这样的一些值呢描述就很清楚了。是吧下面有对应的个年份啊,可能我这儿黑色的背景这看的不太清楚啊。OK这是对应的一些纸啊。OK那么针对于上面的这个方式呢。
我们到底是比如说是使用这个g by呢,还是呃这样的一个aggreg呢?其实呢根据你的一个需求啊,其实我觉得哪一种呢?其实啊都可以啊都可以啊,哪一种熟呢,你用哪一种啊。
OK那么接下来呢我们来学习第呃第二个是吧?啊,第二个。那么第二个呢我们的transform啊,那么这个transform呢呃比较常见的里面有哪几个呢?比如说第一个我们的一个呃theq啊。
O啊一个是它啊那么这个呃Z core呢,其实上呢它是对数据做归一化的这样的一个操作。那么这种方法呢啊这里面写了一个小式子啊,其实它是基于我们的原始数据的一个均值跟这个标准差。
然后呢进行数据的一个啊标准化啊标准化。🤧OK那么这是一个是吧?那么还有什么呢?还有我们的一个什么呀这个呃op是吧?哎,它呢也可以起到这样的一个呃同样的一个效果啊,那么这个方法呢,我们来简单看一下啊。
我把它运行一次。OK啊再来运行一下它。那么这个opplay这个方法,我们来看一下它的一个源码。在。找到。Yeah。OK我们来讲一下吧。其实这个op这个函数呢,其实它就是tens里面呃。
我认为啊应该是所有函数里面自由度最高的一个函数是吧?那么啊它是属于我们的一个啊de frame啊,de。那么我们可以通过d frame呢第二一个什么 plane来完成是吧?这样的一些呃操作,对吧?
那么这个 plane这里面有哪一些常见的一些内容,其实呢主要的跟我们刚才这个acgreg呢其实类似啊,里面第一个参数呢也是传的是一个啊方啊,也是一个方啊,那么呃其实这个方向呢。
其实你可以理解为函数的一个比如说指针是吧?那么这个函数啊需要我们自己去实现啊,函数传入的一个参数呢啊,我记得这里面好像还有个什么accesacces等于一的话啊。
比如说可以作为我们这样的一个嗯比如说sris的一个数据啊,把它传入给我们这样的一个函数啊来实。啊OK那么我们只需要记住什么?第一个啊第一个就是一个什么呢方形就OK了啊,传入对应的一个内容啊。
那么在这里面我们来御结此。OK那么呃通过它呢能够根据啊,比如说我们还是这个年份啊来显示对应的一些内容是吧?OK那么下面比如说你要想把它给画出来啊,也是一样的一个啊操作是吧?比如说你根据哪一些内容画出来。
比如说你想要画它画它是吧?根据谁呢?你的ADG啊close是吧,来完成啊,分别是比如说这两种是吧?一个是呃NVDA,还有一个什嘛。う。OK啊,可以拿到对应的这样的一个内容。那么当我们拿到这个内容了以后。
到底要干嘛啊?比如说我们可以查看这个呃一年中是吧它的一个最大值啊或者最小值啊,或者说哎我们可以呃求一下它的一个什么最大跟最小的一个什么差值啊,价格啊。
价格的一个差值那么这里面我们就可以直接调用什么的命啊,跟这个max这样的一个函数,然后通过什么呢?我们的transform啊,把我们对应的价格re range是吧传进来OK啊。
我们通过它来进行这样的一个内容的一个什么显示啊,这显示。OK啊后面可以吗?单独的,比如说你也想求最大的啊,也可以吗?直接传什么max,而不是传啊,比如说算完以后的是吧?OK啊,这也是可以的。
那么命呢同理是OK了。呃,这是我们的一个啊transform是吧?那么还有什么呢?常规的,还有一个常见的啊fieldil是吧?我们的一个过滤啊过滤。
那么啊其实这个过滤呢呃跟我们之前在讲python里面的高级函数,是不是也有一个filelter,对吧?哎,他俩其实呢如果从原理上来讲啊,基本上是啊一模一样的了,对吧?啊,都是完成我们的一个过滤对吧?啊?
符合条件的我就要不符合条件的呢,我就不要啊。OK那么下面我们来举一个例子,比如说我们啊搞一个简单的是吧,来一个什么呢s是吧?来创建个s是不是这是一个一维的是吧?里面是一个列表。
那么列表里面的内容是不是一22什么3445,这个呢随便去写都行啊,没有什么要求啊,然后呢我直接把这个啊赋值给一个变量S,然后把这个S呢传给group by。
是不是相当于对这个一维数组里面的数据进行了一个分组啊,是吧?那么分组有哪些呢,是不是就变成了一是吧?有这个R有这个三有这个四有这个5是不是有这样的几个内容啊,O啊,那么你拿到了这几个内容了以后是吧?
或者说我们在上面可以加一个吧,这个可能写这样看的不太清晰是吧?比如说在上面我们把这个呢给它copy一下。copy一下,然后呢,我们在这里面呃先不过滤啊,比如说我们先对它做一个求和吧,来一个summer。
来做一个求和是吧?你们来看一下是不是分完了以后,是它12345啊,那么对应的一有几个,一是不是加在一起是2啊,对应的是2,那么二有几个啊,是不是123是不是三个加在一起是6啊。
三是不是就一个啊四不是加起来是8我是不是就一个,那么对起来是不是对应的分组,然后呢拿到对应的这样的一个summer,那么拿到这个summer呢以后,是不是下面这个是属于什么呀过滤,通过什么呢?
这样的一个函数来完成一个过滤,那么这里面是不是第一个又是一个我们的方对吧?啊,只是用了一个匿名函数的方式啊来完成吧?那么在这里面我们怎么去理解呢?其实这个XX就相当于什么?我们传进来的这个值。
你要对哪一个来进行过滤,那么就传这个X呢就相当于什么?我们这段对吧?对的,你拿到这个值了以后,求了一个呃和,那么如果大于四呢,我们就干嘛呢?留下来对不对?留下来,那么小于四呢?就不要了。那么。
大于四的有哪一些尺呢?是不是61个对不对啊?61个,那么还有谁呢?是不是81个,还有一个呢?5是1个,对不对?那么谁留下来是不是3个2?两个4一个5啊,这前面是什么呀?它所对应的索引啊。
默认的一个索引是吧?OK啊,这是过滤啊,这个是比较简单的一个啊。那么还有什么呢?比如说下面我们创建了个二维的是吧?上面是一个s一维的。
那么下面来一个二维的de frame那么d frame这里面呢我们用一个字典的形式呢,给它搞了一个A搞了一个B吧?呢具体的一个内容是吧随机生成0到8的数是吧?这里面是什么AABBCC是吧?
具体的几个呃一个几个字符啊,然后呢我们通过啊一样的一个方式啊,来先给它分组,然后进行过滤,那么过滤的时候呢,我们来判断它的长度是吧?通过它的长度如果大于二的时候呢,哎,我们就干嘛呢?保留是吧?
反之呢就pass掉是吧?那么二哪一些大于二呢?是不是这里面是不是ABBCC是不是CC就排出来,是不是留下来的就是什么呀?这个AAABBB这三个对应的这样的一个值对这值吧?OK那么呃这是对于什么呢?
B来进行什么呢?过滤的啊,你也可以对应么呢A来进行过滤啊,这个无所谓了啊,这个无所谓了。OK呃,那么下面是吧,比如说我们对于刚才的这样的一个股票是吧,你想要去查看一下我们当前的这样的一个。
比如说均价超过100的,有哪一些这样的一个呃月份是吧?啊,可以我们在这里面也可以演示一下啊,来先显示一下,然后呢。哎,这个这个月这个可以不要了啊。
然后呢在这里面你就可以嘛直接通过这个fieldel这个方式来完成什么呢?过滤对吧?啊,O那么100它必须要干嘛呢?啊,超过100,那么在这里面我们可以啊把这个条件改一下吧,改成什么100大于100。
因为平均值大于100的,我给他什么显示出来。那么根据谁呢?根据我们某一年里面的什么某一月啊,那么这这里面要注意一个问题啊,就是说啊有的同学可能在思考的吧,我要不要写这个年是吧我只写一个月行不行呢?啊。
最好是要写上年啊,否则可能会出问题,但不是一定啊,因为这个呃月份每年有12个月,它有可能会跨年是吧?有可能会跨年啊,可能中间咔啊,这个对。那么所以说一般在这里面啊。
我们最好写上啊写上OK那么完事了以后是吧?呃,100以上的是不是都给我们咔咔咔显出来了啊,相当于啊我们过滤的这样的一个结果啊,过滤这样的一个结果。
OK那么啊这是我们针对于啊这个啊分组跟合并啊几个常见的一个内容。那么这里面啊最后给了一个小的一个总结是吧?啊,它的一个顺序就是什么呢?先splate在op plane是吧?在我们的一个啊comp是吧?
也这么第一步是分离我们的一个数据,然后按照规则是吧,你怎么去分啊,这个根据你的需求,那么第二步呢。就是啊比如说把这些数据啊都做一些什么我们的操作。这个操作呢,你可以是汇总啊。
比如说我们用什么aggreg,你可以什么变换一下,用什么trans也可以过滤是吧?用我们的啊,这个根据你的业务需求啊,那么最后呢把这些处理的数据呢再合起来啊,变成一个什么呢?啊,其实可以简单这样去理解。
那么比如说现在我们有一个比较大的一个表格是吧我们通过这个group呢把它给切开对不对?切开以后是不是我们就可以通过是吧?gregtrans等等来进行处理,处理完了以后再合一下是吧?哎合完以后生成一个啊。
其当于什么相当于什么原来一个什么总分这样的一个格式啊总分种这样的一个格。

OK我们来看一下。🤧呃,问题啊嗯。0126。往上翻一下。你说的这是。그。呃,容妹就一行数据啊不应该存在这个标准差哦,它这里面会就是说你即使不存在,它也会显示出来啊。
discript中间缩裂的部分怎么去展示出来啊,因为这个是这个怎么出来?这个 book它本身就有这种机制啊,就是说你数据可能太大,它就会自动的把你去缩起来啊,那么像这种呃你可以用其他的一些内容啊。
其他工具把它给展示出来。255075取值。还是所有的值区总以后再去。啊,这个根据你的需求啊。变成这个OK也就是你如果直接呃想要把这个什么1999-1-1变成1999,那么直接啊在后面点上。
比如说你要对你,那么就点y就可以啊。transform跟app plane的一个区别啊,其实这个区别呢呃。首先哈这个app plane啊相当于什么底层一些啊,底层。
那么transform呢在它的一个基础上相当于封装了一次啊,那么其实他俩呢呃。用法呢基本上没有什么一个太大的区别。全form针对某些列。嗯,是的啊,可以这样去理解啊。对于过滤一年越过大于50,小于50。

也可以看。🤧ok啊。😊,呃。那么这个是对于我们的一个分组,还有一个合并里面的几个知识点是吧?你就记住什么呢?几个常见的函数是吧?go by,然后呢,我们的一个啊这个这个transform呀。
filter呀啊,还有一个aggregate是吧?还有里面比如说我们的obin是吧等等。

Right。

人工智能—机器学习公开课(七月在线出品) - P22:【公开课】最大熵模型原理推导21年6月 - 七月在线-julyedu - BV1W5411n7fg
🎼,🎼,喂喂喂嗯,如果声音和视频没有问题的话,我们就准备开始好吗?那么按照我们的安排啊,今天呢我们和大家一起这个。讨论一下关于最大商模型的一个内容。那么关于最大商模型呢。
我们首先从这个模型的关联关系图当中啊,找一下它的位置。最大商模型出现在这里啊嗯。大家可以看到啊最大商模型的一个作用啊,是为了啊后面我们会介绍这个呃推荐随机场模型CRF的时候。
会使用最大商模型解决A呃CRF的这个模型学习问题啊,所以在这个地方啊也首先把这个最大商模型做一个介绍。啊,大家也可以看到啊,在呃最大商模型当中呢,它也是需要进行大量的概率计算啊。
所以呢我们也把之前介绍到的关于加法规则和乘绩规则也做一个介绍。首先我们看一下加法规则,加法规则啊呃说的是我们PX啊,边缘概率等于someYPXY啊,它和联合概率之间的一个关系的等式。那么很显然。
边缘概率和联合概率不相等。那么。我们只需要在s啊在Y上进行一个全概率累加,这个时候我们就可以得到我们的边缘概率和联合概率的相等的一个等式。那么这个地方需要注意的是两点。第一点。
我们有的时候是使用啊加法规则把边缘概率啊,一个随机变量的边缘概率展成两个随机变量的联合概率的形式啊,这是一种方式。那么还有的时候呢,我们还可能会这样来使用啊,把两个随机变量的。联合概率啊。
通过萨姆求和啊还原回一个随机变量的边缘概率的形式啊,这两个方向呢,我们都经常会使用到。那么下面关于乘积规则啊,乘积规则说的是两个随机变量XY的联合概率啊,它等于P在X条件之下。
Y的条件概率乘以PX很显然啊,后面是两个啊概率分布的乘积的形式。其中一个是条件概率,当X已知啊作为条件的时候,随机变量Y的条件概率。那这时候很显然随机变量X的不确定性啊,就没有了。
因为它是已知的随机变量。那这个时候很显然它和两个随机变量联合概率之间已经不再相等啊,不相等的原因就在于这里的随机变量X啊,它的不确定性或者说随机性没有了,那怎么办?再把它的随机性啊,再乘回来啊。
乘以PX的边缘概率这样的话条件概率和边缘概率的乘积就等于它的联合概率的形式。那么同样使用的方向也是两个方向。第一个。方向。两个随机变量联合概率展成条件概率变现概率的乘积啊,这是扩展啊。
把它一一个随概率分布,展成两个概率分布的乘积的形式。那么还有另外一个用户呢,就是相对应的啊,条件概率和变缘概率的乘积等于联合概率。那这个时候呢就是类似于一个吸收啊,在进行这个复杂的概率计算过程当中啊。
这是两条非常重要的规则啊,加法规则和乘绩规则。用到的时候,我们会头头来再看一下。那么下面就开始介绍啊所谓的这个最大商模型啊,最大商模型。最大商模型呢是最大商原理在模型推导过程当中的一个具体应用啊。
具体应用。那么首先介绍一下最大商原理。最大商原理呢可以认为是一种方法论啊,我是认认为是种价值观啊,认为是一种价值观,就是当我们怎么去认识这个所谓最优模型的时候啊,最大商模型给出了一个指导性的原则啊。
或者价值判断的一个依据。也就是说在进行概率模型的学习的时候,在所有可能的概率分布当中。啊,所有可能的模型当中,我们认为啊最大商最大的模型是最好的模型,很显然这个地方我们做了一个价值判断,对吧?啊。
所有满足我们的条件的模型有很多。那么这么多的模型当中,我们选择什么样的模型作为所谓的最优模型的时候,我们选择商最大的模型啊,表述为在满足约束条件的模型集合当中,选取商最大的模型。呃。
这是所谓的最大商免理。那么。把这条原理啊把这条原理和我们这个信息论里面的商的概念啊进行一个结合。那么我们假设啊离散的随机变量X的概率分布为PX啊,随机变量X的概率分布为PX。
那么当前概率分布P的商被定义为负的s XPX乘以logPX啊呃。这是呃信息论里面给出的关于商的一个标准定义。那么关于PHP的一个取值范围呢,它是大于等于0,小于等于log X的模啊。
其中呢X的模呢是X里面取值的个数,因为X在这里是随机变量,它可以取多个啊不同的值。那么有多少个,那么啊我们根据它当前可能取值的个数啊,作为log X模的一个计算。那么很显然。
这里的log X的模是HP的一个上界啊,HP的一个上界。那换句话说,当什么时候HP取得最大值的时候,那么当随机变量X啊取得它啊任呃。在所有可能取值当中是等概率取值的时候,取到HPX的上界。
这也表述了啊关于商模型的关于商这个概念的含义。比如说商描述的是随意变量X的不确定性啊,当随机变量X在所有取值上等概率取值的时候啊,它的不确定性是最大的取到它的上界上界的值是logX的啊。
这是在呃信息论里面啊有深入的讨论。那么在这里我们直接拿过来当做一个数学工具使用也就可以了。那么下面正式的啊把一些这个最大商模型当中的一些呃概念给出来。首先X和Y啊分别标对应的我们的输入和输出的集合啊。
就是我们的输入空间X和输出空间Y那么这个模型呢表示是对给定的输入X以条件概率的形式给出它的输出Y啊,这个时候大家应该清楚,我们的模型表示形式有两种,一种方式呢是根据我们的决策函数的形式啊。
直接Y等于FX。来给出啊,而后面呢我们可能会见到啊越来越多的以条件概率的形式给出的模型表示啊呃那这时候很显然,X是作为已知条件,输入进来以后,得到关于它标签啊对应标签的一个概率值啊。
这是关于我们的以条件概率的形式表述的啊模型。那么这个时候我们就需要有训练集啊,有训练数据集,对我们的模型加以训练和学习。这个时候数据集T等于X1Y1X2Y2一直到XNYN那是我们的数据集。
有了数据集以后,我们就可以把一些数据集上的一些概率分布啊,首先使用它的频率值来进行表示啊,后面当使用到这些经验分布的时候,我们直接拿过来用就可以了。首先哈首先我们可以得到的是。就点PXY啊。
在数据集T上随机变量XY的联合概率啊,随机变量XY的随机变量啊,就是X等于XY等于Y的联合概率分布啊,在数据集上的联合概率分布等于什么?那么很显然啊,我们是使用整个数据集上的频率来表示这个概率分布。
那么很显然我们就说需要遍历一下整个数据集把那些X等于XY等于Y啊,满足这两个条件的所有的元素的个数啊进行一个统计啊,统计在小V里面。那这样再除以整个数据集的元素总个数啊,很显然有大N的元素。
那这样的话我们用这个比值啊频率值来表示X等于XY等于Y的联合概率,在数据集上的联合概率好吧。那么类似的随机变量X的在数据集上的变量概率等于等于什么?
等于X等于X满足这个条件的所有的数据的元素个数比上整个数据集上的元素个数啊,同样。得到的是关于啊边缘概率X等于X的一个经验分布。
那这样的话后面啊后面当我们使用到啊当我们使用到数据集上的联合分联合分布和数据集上的边缘分布的时候,我们直接拿这两个频率值来使用就可以了。那么另外一个概念呢这做特征函数啊。
特征函数呢是关于XY的啊关于随机变量X和随据变量Y的。如果XY满足某一事实,那么它特征函数返回一否则的话返回零啊,关于特征函数的理解啊,是需要根据就是呃首先在一般意义上你可以把它理解成是一个条件啊。
当XY满足某个条件或者某一个事实的时候,特征函数返回一啊,当不满足这个条件或者不满足这个事实的时候,返回的就是零啊,这是一般意义上的一个表示。那么同样啊也可以根据啊最大商模型在解决一些实际问题的时候啊。
把那实际问题当中或者实际环境场景当中的一些情况啊。对应到我们特征函数当中来加以分析啊。比如说后面我们会讲到CRF的时候啊,那个时候的特征函数啊,就定义的是CCRF上的特征函数啊。
但是一般意义上同样是XY满足某一事时的时候返回一,否则返回0啊,这是关于特征函数的表示。那么有了上述的呃一些准备以后呢。
我们就可以给出哈关于特征函数上啊分别呃它的经验分布和它的这个呃经验分布呃PQ点XY的期望以及关于模型和经验分布PX的期望的两个期望的表示形式。首先特征函数FX关于经验分布Q点PXY的数学期望。
我们可以表示为EQ点PF等于sXYQ点PXYFXY啊,这首先是个数学期望啊,这一点首先关关注一点,这是数学期望。那么只是呢它的期望的这个概率分布是经呃是数据集上的经验联合分布啊。
Q点PXY然后呢乘以FXY然后在XY上进行一个累加啊,这是呃EQ点PF那么同样特征函数FX啊,呃FXY关于模型以及。边缘概率的数学期望EPF等于sum XYQ点PX乘以PX条件之下。
Y的条件概率再乘以FX同样这也是个期望啊,同样这也是个数学期望。嗯,只不过呢它的。希望分布不一样啊。上面的期望分布是我们联合概率XY的经验经验分布。
那么下面这个期望呢是我们的模型和我们的边缘概率的这个呃期望。那么有了这两个期望值以后,下面是非常重要的一点。是这样说的,如果模型能够获取到训练数据集当中的信息,那么就可以假设这两个期望值相等。
及下面这两个期望值相等。呃,为什么这么说啊,为什么这么说,那么我们看一下我们反过来啊,我们对应的假设这两个期望是相等的啊,假设这两个期望值相等,我们看看能得到什么结论,那么假设这两个期望相等。
我们就把这两个期望的形式啊进行展开啊,一个是在边缘概率和我们条件概率上的期望。另外一个是在我们联合概率上的期望给它展开。展开以后呢,我们再把后面这个联合概率上的期望进一步的得到一个表达式。
我们前面讲到过啊,联合概率啊,联合概率可以写成边缘概率和条件概率的乘积的形式啊,按照我们的乘绩规则。那这样的话,我们把这个地方的就点PXY写成。Q点PX乘以9点P。X条件之下,Y的条件概率。
然后再乘以一个FX。FXY那么这个时候我们看可以看到啊,我们可以看到这个式子就等于这个式子。比较一下这两个式子,你会发现其中啊其中。形式上啊其其中形式上非常类似,只是。可以得到。这里的PX啊。Yeah。
这里的屁。X条件直下Y等于等于Q点PX条件之下的Y。那么得到这个式的含义,大家可以看到啊,我们知道上面带包装号的这个呃。条件概率分布是我们在数据集当中学习得到的,而右面就是我们的模型。那么很显然。
也就是说当我们假设这两个数学期望相等的时候,那么我们得到的一个结论就是数据集上的条件概率或者条件分布,就等于我们的模型分布。反过来,如果我们说啊就像刚才那个就像刚才上面一句话,如果我们说我们的模型。
我们的模型在数据集上已经学习到了。数据规律的话,那么很显然意味着啊很显然意味着两上述两个数学期望的值也是相等的。因为这个地方都是都是用个等号表述对吧?等号表述。所以那么很显然啊,刚才我们是假设啊。
我们刚才是假设这两个数学期望相等,得到了上述这个式子。那么相应的,如果我们认为这两个式子相等,同样我们也可以得到上述两个期望相等。那么也就是说,而我们会会发现。上面这个式子的相等。
意味着我们在数据集上的条件概率就是我们的模型,意味着我们的模型能够获取到数据集当中的信息。那么上述两个期望相等。好吧,啊这个地方啊是非常重要的一点理理解。那么另外呢需要注意。
另外一点就是关于我们的特征函数啊,关于我们的特征函数有是有N个啊,是有N个FI等于X啊FIXY是I从一到N啊,N个条件啊,N个特征函数这N个特征函数都需要代入到我们的期望值当中使两上述两个期望值相的。
那么因此我们可以看到啊,我们得到下面。关于。最大上模型的一个呃。分析。首先我们假设所有满足约束条件的模型啊,所有满足约束条件的模型为下数的集合啊,为下数这个集合用花C来表示。花C呢是一个集合啊。
它是由那些。在我们所有的特征函数上,FIF1F21到FN在所有的特征函数上均满足上述两个期望相等的那个条件下的我们的模型。或者我们的条件来分播。好,再重复一遍啊,这里的C啊。
这里的花C是那些在我们所有的特征函数上啊,在所有的特征函数上都可以使上述两个期望值相等的啊,满足这样的条件的。模行啊,就是我们全应该的分布。那么很显然哈。😊,当前这个花C集合换是换换句话说。
满足上述两个期望值相等的。条件概率分布并不唯一,集合里面的元素有多的若干个。同样的问题就在于在当呃在当前这么多个啊满足条件的模型当中,我们选择什么样的模型作为所谓的最优模型呢?看下面。
那么刚才我们说过使用所谓的最大商原理啊,就是使就是那些能够使得啊我们的条件商啊我们的条件商。最大的那些模型作为当前的最优模型,而条件上的规律下面式子已经给出来了,HP等于负的sXY。
拖者PX乘以PX条件之下,Y的推应概率乘以logPX条件之下Y的推应概率。那么这就是哈就像刚才我们所说的则模型集说C当中条件上HP最大的模型称为最大上模型啊,当前我们的最优模型。
把它形式化描述一下把它形式化描述一下。首先。最大商模型可以形式化为待约束条件的最优化问题啊,带约束条件的最优化问题。那么对于所有的特征函数FXY啊。
对于所有的特征函数XFXY那么上述问题等价为待约束条件的最优化问题,什么条件?就像刚才我们所说的,你所有的特征函数必须要满足上述两个期望相等啊,在此条件之下的模型有很多。那么满足这个条件的模型里面。
再保证保证什么商HP取得最大的模型作为最优模型?啊,这就是最大上模性的一个形式化表示。当然这个地方需要注意的是,s yP在X条件之下,Y的条件概率的和为一啊,这个也应该好理解啊,也应该好理解。
我们知道sP啊some y。PY是等于一。当然我们知道X作为已知条件的时候,其实并不影响这个结论。是吧好了,这是。我们已经把整个的最大商模型啊形式化的表述出来了。但是我们一般情况下啊。
一般情况下习惯上的话,我们把习惯上都是求极小啊,把所有的问题都是求转换成它的极小问题。所以呢这个时候我们做一个做一个转换啊,做一个转换啊,约束条件不变啊,约束条件不变。
就是把刚才的HP的去极大转变为负的HP的求极小啊,这个跟显然是等价的关系不一样。这里是。这样来看啊。我那看。原来是HP这个问题的极大化,现在呢等价的转换成了啊负的HP的极角化啊,这是。等价的一个转转换。
那么有了这个问题以后,下面的问题就转变为了待约束条件的最优化问题的求点了。那么很显然使用的还是我们的拉杆网式乘除法,拉杆网的乘除法。拉布朗的乘子法呢分这么三步啊,分为三步。
第一步呢是构建或者定义我们的拉布朗尔函数啊,LPW等于什么?拉布朗尔函数的构建啊分为这么两部分啊,拉布朗式函数分为两部分,第一部分是原优化函数啊,原优化函数。那么很显然,原优化函数就是负HP啊。
原优化函数就是负HP。那么第二部分是把所有的约束条件啊,是把所有的约束条件。每一个条件分配一个所谓的拉格朗尔成子啊,每一个约的条件分配一个拉格朗尔成子,然后拉格朗式乘子乘以对应的约数条件啊。
作为拉格朗尔函数的第二部分。那么在这个地方我们看可以看到我们的约数条件一共是N加一个条件,注意这里是N个条件。N个IFIXY啊,那么这个地方还有一个条件是N加一个条件。
那么所以我们需要分配N加一个喇叭拉充子,我们把它分别定义为。W0和W1一直到。WN。那这样的话,刚才所说的W0乘以一减去s yPX条件之下Y的概率作为拉朗尔函数的一部分。
那么剩下的那N个W1一直到WN分别乘以EPFI减去1就这PFI。啊,呃是N个条件,也作为我们拉格拉程度,拉格网函数当中一部分。所以。就得到下面的拉完函数。那么这是刚才啊这是刚才我们那个。
W0乘以1减去sYPX方向之下Y的条点标率。然后下面这个。W1乘以1求点PF1减去EPF1这样的。条件我们有N个,所以我们要进行s姆I从1到N的一个累加啊,这样的话我们就构建完了拉拉的函数。
那么这个拉拉构建完成以后,我们把HP和这两个期望也展开,得到下述两个式子。可以看到啊,这就是我们的。啊。条件商的赋值啊条件上的赋值那个负号,因为这个地方有负号就。对冲掉了是吧,这是条件上的那个复制函数。
然后呢,这还是原来那个W0乘1减于sYPX推荐出下Y平应概率。而下面这个式子啊,这就是刚才我们的E。to点PFI这是我们的EPFI啊,两个期望展开。那么下面的问题。就在于啊当拉布朗的函数构建完成以后啊。
下面的求极值问题啊,求极值问题就转换成了拉布朗的函数的极大极小化问题啊,极大极小化问题。而拉布朗乘子法又告诉我们,拉布朗的函数的极大极小问题等价于它所对应的极小极大问题啊,极小极大问题。
所以下面的问题就转换成了。第一步,定义拉布朗式函数,第二步求极小,第三步求极大啊,这是我们的套路。那么我一步一步的来,首先求拉格朗式函数的极小问题。啊,这是我们刚才看到的啊。
原拉格网的函数L的最极大极小问题,等价于或者转化为拉格网函数的极小极大问题啊,极小极大问题。那下面呢给出几个符号哈,给出几个符号,后面用的时候我们拿出来用可以。第一个符号呢是CW啊。
我们把啊我们假设这个时候已经把拉格网上函数的极小已经求出来了啊,已经求出它的极小。来了,那这个极小呢,我们把它定义为poCW啊proCW注意这里poCW是关于W的函数啊,是关于W的函数。
那么它定义为LPWW。首先这个地方注意这里的PW就是我们的模型啊,就是在当前拉布朗的函数求极小的条件之下,我们的模型啊,这个地方就是PW等于啊当前使得拉布朗的函数极小的那个。模型啊。
同样我们另外一个形式PWX穿线之下Y的天移概率,因为它本身我们的模型就是个天线概率。那好,有了这个学习目标以后啊,求极小。那我们的。这个工具啊求求偏导等于0是吧?求偏导等于0。那么首先是我们的拉网函数。
对我们的模型PX特件下Y的概Y的特性概率求偏导啊,这个地方呢特别需要仔细一些。为什么?因为我们的拉网上函数在形式上还是比较复杂的。就是下面这个式子啊。就下面这个式子要对我们的模型。图偏老了。
那么很显然我们要在这个形式上。为我们的模型求偏导。能于是么?那么等于什么?很显然就一项一项的对我们的模型去偏倒吧,我们分别来看一下。首先是这一项,这一项当中是包含着我们的模型的是吧?
是包含着我们的模型P存线之下Y的概率,而且还有一项是logPX线之下Y的平移概率。那么很显然,乘积的形式啊,乘积的形式塌倒塌不倒加上他不倒塌倒是吧?注意这个地方的log就导是PX线之下Y分之1。
所以呢调整一下。做到下面这个式子啊做到下面这个式子。sXYQ点PX乘以log PX所应之下Y平形概率加一啊,是作为我们的第一项对模型求偏导的结果。那么再看第二项。在第二项当中啊,也有关于我们的模型啊。
也有我们的推这个推延代路。那这个时候还好在什么?还好在我们就开一球啊一球偏倒就变成了变成了一是吧?那么这个时候是W0,就是所以它sYW0化简一下就可以得到下面这个数s yW0。那么这是第二项了。
那么第三项啊,第三项可以看到这一项里面哈,这一项里面其实并没有包含我们的模型啊,所以这一项的求偏导也就等于0。那么第四项那么第四项当中带着我们的。片导呃。
带着我们的模型求片导之后是smXY求的PX乘以FIXY。所以再化简一下,我们得到啊,可以看到第三项啊,第三项是sFYwo点PX乘以sY从1到NWI乘以FIXY。啊这样因为只有一项。我们的特性概率啊。
一旧偏少就变成了一。那这样的话我们稍微再调整一下,因为这个地方可以看到这个地方带着s XY这个地方带着s XY。所以我们啊这一项虽然没有sm XY,但是我们知道s啊s。呃,s马X是呃s马XPX是等于一。
所以这个时候呢我们把这个地方啊同样啊同样把这个PX就点PX往前提,变成sXY就点PX乘以logPX乘以之下Y的增应概率加一减去W0啊,减去W0再减去就这PX往前提了这个地方减去s马Y从1到NWFI乘以。
是吧,就做到下面这个式。下面这个式子啊,使用的就是。啊,这个很显然成立的s马X tu点PX是等于一的啊,这一项变成了s马 XYPX啊,t点PX乘以W0对吧?这样的话。
这三项里面就都包含啊都包含s马XYto点PX往前一提。那么这一项剩下的是啊这一部分,然后这一项剩下的是。W0这一项剩下的是sI乘1到NWIFXY。好吧,那这样的话呢,我们令这个偏导等于0啊。
令这个偏导等于0,把谁表达出来,把这个我们的成定概率啊,把平形概率表达出来。因为如果这个是等于零的话,这一部分啊,这一部分我们除过去啊,除过去还是那么得到的是这个是不是等于0。这个是等于0以后。
把这一项啊把这一项移到右边去啊,移到右边去以后变成sY从EWIFXY加上W0减1是吧?加上W0减1,因为这个是代log,我们左右两边的。同时指数次幂啊。
这样的话我们得到PX限之下Y的分行概率等于一的sI从1到NWIFRXY加上W0减1啊,这是。从上述的偏导等于零得出的一个结果。然后呢,我们这个地方我们把它转变一下。
把这个式再把它写成sMI从E到NWIFIXY。减去一个一减去1个W0。然后呢,我们这个时候就可以得到啊E的负次幂啊,E的负次幂等于E的幂次分之1,所以就可以得到上面这个式了啊,得到上面这个式。
我们把这里的一减去W0放到了分母上面啊,所以这地拆成两项了是吧?拆成了两项。得到上面这个式以后呢,得到上面这个式位以后,我们其实就可以已经得到啊已经得到关于我们模型的一个表达式啊。
已经得到了关于模型的一个表达式。但是这个地方但是这个位置里面呢,带着这个W0啊,带着这个W0是我们不希望看到的一个情况。因为W0是那一个月的核型里面,那怎么办?我们看下面啊,你看下面。你想个办法。
这个时候呢哎我们借助另外一个啊借助另外一个这个条件。我们知道someYP还测验一下外边概率的和是等于一的。那么很显然,这个地方我们已经得到了这个条件概率的表达式了。那么这个时候我们就可以。
那我们就可以对它进行一个s外上的求合吗?sub外象的球和。那么很显然这个地方也是s外上的一个球和,那么这里是s外上的一个球和。那么这个式子呢是等于一好了,重点我们看后面这个式子啊,后面这个式子。啊。
你会发现这个地方是对Y的一个累加。那么分母部分上是没有关于Y的。表达式的对吧?没有关于Y的表达式的。所以说这个关于Y的累加,我们只需要把它放到分子部分上就可以了。这样吧,那那就变成了。这样一个形式。
因为对整个式子的Y上的累加,而分母部分上不包含随机边Y,就只变成了对分子部分上的关于Y的一个累加。而我们知道这个式子是等于一的啊,而这个式子是等于一的,那么就可以得到。关于一减去W0的意次幂等于什么?
等于someY。意的。I从一,然后WIFI。2。F I XY。那也就是说这个式子或者这个表达式,我们得到了关于它的一个在Y上的一个全概率累加的一个形式。我们用这个式。而我们知道后面这个式子里面是不波。
是不包含W0。对吧所以我们就可以从这里啊得到下面这个式子。下面这个设备就是刚才我们说的分子部分上还是关于一的sY从1的NWFIXY而分母部分上变成了在Y上对刚才的E次幂进行全全格类零加的一个形式。sY。
然后E的sI从一个N啊WIFIXY。啊,就说这个式的为什么由由哪一个等你一个条件可以得到下市呢?就是刚才我们所说的啊,我们对外进行一个累加。那这样的话,分母部分上不包含Y,那只在分子上进经包含。
而这个表达式等于一,我们就可以得到关于W0的啊关于E的一减去W0的这个式子的一个。另外一个表达式。而这个时候我们既然它那两个相等,我们用这个新的啊在Y上的累加把它进行一个替换,就得到了啊。
就得到了关于在W下面啊,在W下面,我们模型的一个表达式的形式。那么这个形式刚才我们所说了啊,这就是在当前啊,因为我们已经对大出极小了是吧?在极小的条件之下啊,在极小的条件之下。
我们找到的关于模型的一个表达式。第二部意义出来了。那么很显然。下面的工作我们需要进行什么求及大是吧?第三步了该求集大。第三步求极大。那么第三步的极大问题的求解呢呃是这样,我们需要用到IS就是那个。呃。
改进的迭代手法啊改进的迭代处手法,把这个呃极大问题进行求解。其实这个逻辑啊这个逻辑就像我们在SVM当中啊,在SVM当中使用那个SMO啊。
序列最小的优化对我们那个已经求完极小以扣的那个呃SVM的拉个网函数求极大化的问题是一样的,对吧?所以只不过啊他们能用的方法不一样啊,在SVM里面是使用的SMO啊,在这个最大商当中啊。
是用的改进的迭代处法S啊。这个地方呢这个ES啊还没有介绍啊,这个地方我们就把问题放在这儿啊,放在这。其实我们逻辑上也应该能够接受的。
就是在于啊这些问题都是可以通过我们的各种各样的这个数学计算能够解决的就可以了。🤧好吧,那么那么以上那么以上我们回过头来看一下,我们到此得到的一些结论。首先第一个结论就是关于最大商模型的一个。
定义啊或者它的一个基最大商原理的一个使用。那么首先我们可以看到,我们满足约束条件的集合构建出来了,而满足当前约束条件的集合里面的元素并不为一,或者说模型很多。那么在这么多个模型当中。
我们认为那些或者那个啊,或者那个满足所谓商最大的啊商最大这么一个价值判断的模型是所谓的最优模型。啊,这就是商最大原理。在我们当前啊最大商业模型当中使用的一个基本的逻辑。有了这个逻辑以后。
我们就可以把最大商模型形式化的表述为在约束条件啊,那个期望值相等的约束条件之下,商最大的啊商最大的求解的最优化问题。那么转换成它的负HP的提效问题。
那么剩下的问题其实就转换成了啊约束条件的最优化问题的9点。约束问题的最优化啊带着约束条件的最优化问题个求解无非就是拉个网求法,它的套路就是三步啊,第一步固定拉个板的函数,第二步求极小,第三步求极大。
那么拉格朗函数这个构建呢需要仔细一些,因为这里的条件比较多啊,一个条件呢是那个sYPX乘它Y的价值等于1啊,这个呢我们给了一个拉格朗乘就是用W的0卖表示。那么呢还有剩下有N个条件啊,还剩下有N个条件。
这N个条件都保证了都保证了EPFI和我们的EQ的PFI是相等的啊,或者说他们的差是0啊这么一个条件。所以说这个地方就N个条件。那这个时候为每一个条件都需要给它一个拉网程序。
那这个地方需要有WE到WN这N个W网的。有了这些分析以后,那么拉格朗的函数就可以构建为原优化目标负HP加上每一个啊约束条件分别和它的对应的拉格朗乘序个相乘的形式。
那么首先是W01减去sYPX全之下Y条限概率,加上一个sY乘1到NWY乘以1ttor。PFI减去EPFI。啊,这是。N加一个条件啊N加一个条件分别乘以他们所对应的蜡网充组。啊。
体现在我们的拉拉孩子当中啊,同样这个地方的HP以及后面的这两个期望分别我们把它展开,得到一个相对来说啊相对来说形式上比较啊比较复杂的一个拉拉函数。稍微复杂一点是吧?那么下面需要注意的是。
我们需要根据第二步和第三步分别求极小和求极大。那么求极小的时候啊,求极小的时候我们。啊,认为啊为了后面极大化的时候,缺点有个符号哈,有个符号表示,我们认为那个极小化之后的结果用和CW来表示啊。
这个可能有的同学。一开始接受不了,为什么你跟那连求都没求,为什么找这个火CW?就是因为后面我们求出来以后啊,求出来以后,那里的那个。模型我们需要有一个符号来进行表示啊。
这个地方我们就拿doCW来进行表示。🤧那它所定的拉格朗孩数就是PW啊,那个模型缺件之下的拉格朗孩。那么同样那么模型就等于PW就等于使得啊,使得在最优呃在极角化之后啊。
在极角化之后的那个拉格郎函数所对应的那个推荐概率作为我当前的啊极角化以后的最优的模型。啊,计划最后我。我们继续往下看,那么下面的问题其实就是求极小了嘛,求极小偏导等于0。那么求偏导的时候呢。
需要特别仔细的一点,你的求偏导的目标一定是我们的模型进行求偏导啊,仔细一下每一项里面。把这个条件概率认为是个啊随机变量啊,认为是个变量啊求导就可以了。按照我们的求道规则啊。
按照求导规则之后展开展开呢另偏导等于0啊,另偏导等于0。这个时候我们得到关于模型的一个表达式啊,关于模型的表达式。在模型表达式当中啊有一项是关于W0的内容啊。
这个时候呢我们借助另外一个条件sYPX它Y的概率是等于一啊,借助这个条件,我们可以得到它在sY上累呃累加和的另外一个形式。而这个形式是不包含W0的,果我们后面的求解呢,至少我们削去消除了一个W0是吧?
消除了一个W只需要求解W1一直到WN就可以。那么下面啊我们就可以把。这个极小化问题求解出来了,求解完极角化问题以后,下面一部分就是求极大啊,对应的把那个所谓的最优W啊最优的。参数W求出来啊。
那N个参数求出来,那这个时候需要使用到啊,我们后面会介绍。这是关于啊刚才我们介绍的嗯追大商模型啊的定义,以及它的这个待约束条件的。等约属条件的啊机制问题的求解的过程。那么。另外一部分呢是关于一个结论啊。
后面我们再。在什么在那个极大化过程当中啊,会使用到这个结论,先把结论给出来。什么结论呢?就是对偶函数的极大化啊,就是刚才我们极小化问题的极大化啊,等价于最大上模型的极大自然估计啊。
这个结论是嗯后面会用到的一个结论。比如说我们既然得到这个结论以后,我们就把这个啊刚才的那个极大化问题,你不要求极大嘛啊,既如果它能够等价于极大自然估计的话,我们直接把极大自然估计的那个最优解解出来啊。
它所得到的就是我们的我们的什么我们的那个刚才那个极大化目标的结。啊,这个结论如果有了以后,我们后面的优化目标就转换成到最大上模型的最大自然估计上去。而其他自然估计的套路还是很成熟的,是吧?
那我们看一下这个这个这个这个结论是不是成立啊,我们需要证明一下这个结论成立。看下面。首先。原那个这个问题的极大化,我们已经得到了。嗯。啊,已经得到这个原论题的极代化了。那么很显然,下面的问题就在于。
我们需要把它个极大自然那个那个自然函数先构选出来。啊,看一下这个自然函数的极大化是不是和我们呃原目标函数的极大化是不是等价的也就可以了。那么下面呢我们看一下它的。啊。呃,这个这个自然函数啊。
特别是对数自然函数啊,对数自然函数已知确定数据集的经验概率分布就点PXY以及条件概率分布PIX全之下Y的概率的对数自然函数为LQ点PW呃PW等于。
我们知道啊对数自然函数那特别是自然函数部分就是把我们的条件概率啊,就是把我们的模型在整个数据集上啊,在整个数据集上进行垒成就可以了,是吧?进行垒成就可以了。
那么得到的是log product xXYPX权件之下Y的概率。对啊Q点PXY幂啊,这是标准的啊这数。这是我们标准的这个呃对数自然函数啊,对数自然函数。然后呢调整一下,因为这个地方有log是吧。
它有它的作用,那么幂次往前提变成了那个求机变成求和,变成sXYQ点PXY啊,求这PX往前提乘以log PX条线之下Y的调应标度。从这从这一步。嗯。从这一步到这一步是定义。
从这一步到这一步是log函数的计算。那下面从这一步到这一步,看看是怎么得到的。啊,得到上述这个表达式以后啊,得到上述这个表达式以后,我们看看怎么样从它得到下面这个式。🤧那么很显然。
这个时候我们知道我们知道这个PXY啊,PX3之下Y的概率,上面已经有一个拉是在这儿。这个是,然后呢,我们要对它进行log啊去取对数。如果log取对数的时候,我们可以很显然知道分子减去分母就可以了。
而分子呢。正要这个意次幂,所以得到是sY乘1的NWI乘以FYXY,然后减去分母分母就log的ZWX。那么很显然得到的就是这个式了啊得到式就是,直接就是直接就是对我们的模型求对付就可以了。
然后再看这个从这儿到这儿得到。う嗯。这一步呢看看前面这一部分是相同的,没有变。后面这一部分是关于萨马XY的。盒嗯,这里为什么已经没有了关于随机变量Y的求盒?很显然是因为我们使用到了什么?
我们使用到的是那个。啊,加法规则啊加法规则。为什么呢?前面我们讲到过。PX等于上。Y PXY。对吧很显然这个地方我们这里的sam XY是可以写成s xs y,而s yPXY很显然就等于Q点PX。
那么这个时候就变成了sam X two点PX。加上规则的使用。那这样的话我们可以得到啊,那这个时候我们的对数自然函数啊,对数自然函数LQ点PPW等于下面这个表达式啊,我们放在这儿啊。
一会儿我们看一下我们刚才得到的那个极大呃极大化的那个极大的等价问题是不是和这里的对数自然函数有某种关系,那就可以了。继续往下。那么这个时候呢,我们可以看到啊,我们现在哎比如使用到的这个符号啊CW。
那么我们刚才说过,这里的poCW就是在刚才机械化问题以后得到的那个优化目标函数。我们看一下这个优化目标函数的形式上啊,等于什么,我们再和刚才得到的那个对数对数自然函数进行一个比较就可以了。
那这个时候的这个极角化这种这个目标函数啊,我们把它关于P。在X圈限之下,Y的这个同圆概率啊,那个极角化以后的PWX圈之下Y的概率回带回到我们的拉格朗的函数里面去。啊。
就是这个地方哈回再回到我们的拉格朗的函数,哎,就在这儿啊,回再回到我们的拉格朗的函数。那么这个时候啊仔细一点仔细一点,但凡是这个地方碰到了PX算一下Y的概率,就用PWX算下Y的概率进行替换。
就得到了关于得个什么对。把所有的模型都用我们的这个已经计算化以后的最优模型进行替换啊,再回到原版的函数中去得到下面这个式子。嗯。可以看到啊,这是我们刚才得到的那个负商啊,负HP啊。
其中的模型已经用这个PWX存下Y的这个天线概率已经替换了。那么下面这两个式的是我们那两个什么,是我们那两个那个那个。呃,期望相等啊期望不相等。有同学说哎,你那个你那个沙漠外。PWXY减一呢。
那个条件上哪去了?因为我不知道。上YPWX乘之下Y的概率的和为11减一等于0,所以那一项正好是个0啊,那一项就没有了。那么带带进来以后,我们化简一下,这个地方稍微需要仔细一。从这一项到这一项。
就是把我们刚才的。鸡角化的模模型。再入到拉网还是得到的。啊,那么从这一项到这一项是怎么得到的?我们看一下嗯,不是嗯嗯。从这一项到这一项,我们看看怎么得到的。啊,上述呃表达式里面有三项求和啊,有三项求和。
我们分别看一下。其中看一下这一项球和。就是这一项。对吧这是萨Y乘1的NWY乘以sXYQ点PXY乘以FYXY。那么这个时候我们把这里的sXYQ点PXY往前提啊。
然后呢把这个萨Y从1的NWY往里啊往里移动一下,就变成了sXYQ点PXY乘以萨乘1的NWIFYXY啊,这这两项是完全相等的。那么再看上面这第一项和后面这个第三项,在这两项当中啊,都有包含s XY的部分。
对吧?还有PQ点PX部分。啊,还包括PWYX条限之下Y的平应概率的。那么很显然把它往前提往前提以后,剩下的是log个PWX条限之下Y的概率以及FXY。那么很显然变成了下发然这个地方还需要注意。
前面还有个萨法从1到NWI。所以下面这两项呢。把其中这一部分,还有这一。部分往前提提之后变成了。下面这一部分啊,这其实就是一个啊。同类项的提取是吧?同类项这个提取。那么这个时候我们再往下看。啊。
第一项这里没有变化,还是到这儿。我们看下面这个式子啊,这里的smXY two点PXPWX算之下Y转移表率。那后面这一项这一项是怎么来?为什么这一项等于这一项?啊,前面我们已经得到了PW表达式。
我们对PW表达式求一下log,然后减去这一项,看看得不到能不能得到这个logZWX就可以啊,我们看一下。哎,找到刚才我们看到的这个PWX乘加Y乘应概率。我们刚才说过,我们左边求一个log。
看看它等你什么。左边求一个log以后,那么意味着右面也需要求一个loglog这个。比值,那么很显然就是log分子减log分母。还有我们前在已经知道啊log分组,其实这里有个一次幂啊。
和logg一乘就变成s乘1的NWFRHNXY。而log分母就是那个logZWX啊。化简一下就可以得到啊下面这个表式。是吧我们可以看到。刚才我们得到了s蚂从1到NWIFRXY正好被减掉了。
剩下的那部分就是logZWX。好了,然后再从这一步到这一步,我看一下,那么同样的道理啊,这里是s XY那么这个地方只有一个丢点PX啊。
那这个时候我们知道呃借助我们刚才那个sYPWX全之下外部概率等一的形式啊,就把。外部的一加啊就约掉了,那么剩下的就是s马XPQ点PX乘以loggoZWX。那么好了。
我们再看看现在我们得到的这个CW等于下面这个式。而我们刚才得到的是我们对数自然函数等于这个是。这个时候你会发现啊得了一个什么结论,这两个式子是完全相等的啊,完全相同的。完全相同。
我们就可以得到一个结论就在于。我们这里的。倍数自然函数和我们的那个proW。是相等的。那么刚才我们说过。可CW是我们的极小化以后的呃模型。我们下一步第三步是要干什么呢?第三步我们要求极大化啊,要求极大。
那么很显然。既然它俩相等,那么也就意味着需要对我们的对有自然函数去最大化。那这个时候我们就得到刚才所所谓那个结论,什么结论?对偶函数的极端化和CW的极端化。等价于最大商模型的极大自然估点。
等等价于我们的极大自然估体。那如果这个呃。结论是成立的话,那下面的极大化的问题啊,对我们圆啊对我问题的极大化就等价转化为了。最大商模型的极大自然估计啊,其实你会发现最后中变成了极大自然估计的问题。
那么基大三项估计那就很其实类似的啊,其实类似的还是求于我们基大值嘛啊,只不过还是刚才我们所说的,我们使用的是IS啊,迭代采印的迭代制否法。啊,这个结论后面我会好了。以上以上啊。

那,就刚才我们得到那个结论。以上就是我们关于啊今天我们关于日大商模性的一个呃内容的一个介绍。我们做一个简单的一个回顾。

🤧。首先啊我们的目的是干什么?像最大商模型啊,最大商模型是一个一般意义上的模型。现在我们回到头来再看再。换一个角度去体会一下,你会发现它就是在满足若干个条件的模型里面啊,怎么去找所谓最优模型的问题啊。
呃,如果联想一下,我们在SVM里面,最优模型是通过边呃间隔的最大化来完成的。而这个地方我们是通过商的最大化来完成的啊,找那个商值最大的模型作为我当前的最优模型。对吧呃。
这是关于最最大商模型的一个一般意义上讨论。那么他呢。呃,可以解决哈一系列的一些模型学习问题。比如说。在CRF当中啊,这个时候我们就会碰到一个很麻烦的问题,在于满足CRF条件里面的模型有多个。
怎么去找所谓的最优解啊。这个时候我们的策略就是找那个商最大的模型来解决模型学习问题。是吧这是作用。加法规则和乘序规则,我们现在也可以体会到了,频繁的使用到这里两的规则是吧?那么首先要给出最大商原理啊。
商最大的模型是最好模型啊,商的定义在信息论里面有完整的讨论。那么这个时候注意啊注意这里面的这些这些数据集里面的经验分布啊,这数据集里面的经验分布,我们是可以首先把它计算出来的。
后面在IS里面会使用到这些经验分布值。那么首先是两个期望啊,首先是两个期望,这两个期望的构建哈,一直是有同学会有疑惑是吧?为什么要构建这么两个期望?
你会发现构建这两个期望的目的就在于得到刚才我们那个非常重要的结论,就是如果模型能够获取到数据确定数据集里面的信息。那么这两个数学期望是相等的。为什么是因为我们刚才已经分析了,就是我们可以得到发现。
当这两个数学期望相等的时候,我们得到这个结论就在于我们数据集上的经验分布就等于我们的模型。换句话说,我们的模型就是数据集里面所蕴含的数据规律。这是我们一直希望得到的一结论。好吧。
那么既然啊既然我们模型就等于数据集的规律了,那么它所等价的就是我们的两个数学期望值相等。那么下面满足上述两个期望值相等的模型有很多,我们使得其中的商最大的作为我们的最优模型。
那么问题就转化成了待约束条件的最待约束条件的最优化问题。而待约束条件的最优化问题,我们就很成熟的拉格拉生字把它进你解决三步啊构建拉个拉函数就最大就极小啊,转化为它的极小最大化问题。
达网数函数的这个构建啊,特别需要注意仔细的就在于你用N加一的优置条件。这个时候达朗函数形式上相对比较复杂一些啊,其中一个难理解的地方就在于这一步啊就在这一步就在于我们借助啊最后那个条件啊。
sYPS调件之下再可调零一这个形式把其中的W0那个。拉格朗的成子在形式上约掉了啊,在形式上约掉了。那么怎么约了?其实就是一些呃基本的数学计算。求出它的极小化问题以后啊。
我们得到了关于极小化的一个表示形式,就是proCW啊,后面你很显然和到最大自然估质的时候会使用啊,这个时候就是问题转换成了对PCW的极大化问题。
而所谓的所有解就是使得proC函数取得极大化的时候做对应的W物值。那么怎么求解就是使用IS。那么呃优化目标呢,我们可以得到一个结值在于。呃,当前的这个呃PCW的极小化啊。
极大化问题等价于呃最大商模型的极大方应估计啊,通过它的。对数自然函数啊对数自然函数的表达式,我们会发现它和poCW的形式量是完全相同的。
那么也就意味着啊也就意味着你对poCW的最大化就等价于你对对数自然函数的最大化,那就说就最大自然估的了。好,以上内容啊以上内容是我们关于这个最大商模型的一个介绍。其中啊呃两点啊第一点。这个呃。
信息量很大啊,具体的。你推导过程还是需要或者要求大家回去后啊,这个嗯一行一行的,你需要知道它是怎么来的啊,为什么原因。他的。已知啊到底是哪些?第二点呢,其实这个问题并没有完整已经解决。
是因为它的那个极大化问题并没有解给出解。而极大化问题呢会使用IS。那么很显然,我们的下一步的工作啊,下一步的工作就使用优化算法,特别是IS的种优化算法,把那个极大化问题,就是极大自然估计也好。
还是对我们的那个W的极大化,反正把它极大值解出来也就可以了啊。上述两点呢是作为呃这个后续的那种的一个安。O以上内容是我们今天的全部内容,好吧。

谢谢大家。

人工智能—机器学习公开课(七月在线出品) - P23:【公开课】机器学习中几点注意——以HMM及CRF模型为例 - 七月在线-julyedu - BV1W5411n7fg
🎼。

喂喂嗯。呃,如果声音和视频没有问题的话,我们就准备开始,好吧。

嗯。啊,大家好啊,这个。我们下面的时间呢,这个就关于机器学习当中的几点注意的事情和大家有一个交流和学习。啊,为什么要组织这样的一次活动啊?是因为啊当然原因很多哈,主要原因有这么几个。
一个呢是我们最近在这个就是嗯学习的过程当中啊,很多同学都会呃学习了很多这个模型啊,掌握了很多的一些技术和技巧。当在进入到深入的学习阶段的时候呢,会发现。嗯。本来有一些不应该是问题的问题。
可能越越来越暴露和突出出来啊,这是一方面的原因。另外一方面呢,还有一些呃新开始学习的同学。怎么去进入到这个方向,可能也会有很多的问题。呃,虽然说哈以上两点呢好像不是同样的呃,不是同一类问题。
但是有一些共性的特点,也在总结和思考这方面的一些问题。那么所以呢希望能够组织这么一次和大家的一次交流,就是把我们在机极学习当中的一些呃需要注意的几点,或者说我们在学习的过程当中,应该引起足够重视的几淀。
那么和大家有一个交流和分享,所以呢组织了这么一次的这个活动啊,这是一个起因,和大家介绍一下。那么呃。这几点内容呢也是我们在不断的就是学习的过程当中,算是有一些感觉,或者说有一些体会。那么呃。
会以这个HMM和CRF啊,这两个模型呢做一个介绍啊,以它俩作为一个切入点啊,当然今天不会讲解这两个模型啊,因为这两个模型相对来说还都是呃基于大量的概率计算的模型,所以还是比较复杂的。
我们后面会有专门的课程会讲解HMXRF只是以这两个模型为例哈,把几点注意的事项和大家有一个介绍。呃,这是关于今天组织这个活动的一个目的。呃,下面呢我们就分三部分内容和大家有一个讨论。

第一个内容呢就是关于机器学习当中的符号表示和图形表示的问题。呃,即使是啊就是刚才也谈到了啊,新到这个方向,就是新进入这个方向的同学可能。呃,会越来越深深刻的体会到,就是我们的模型会越来越复杂。然后呢。
这个嗯计算逻辑或者计算过程会越来的越。呃呃数据结构呀、计算逻辑会越来越庞大,然后复杂。那么其中。最突出的一个特点就是我们需要使用大量的数学符号来表示这些复杂的逻辑计算。那这个时候对符号的使用。啊。
特别是数学符号的使用可能就会越来越重要。但是呃很多的同学哈对于这方面的这个掌握或者理解,可能还会有一些问题和偏差。所以呢这一部分需要有一个介绍。那么另外一方面呢,就像刚才所讲到的啊。
就是机器学习模型本身的这种复杂性啊,怎么样能够使用一种相对比较直观的方式能够理解它啊,能够更好的理解这些复杂的计算逻辑。那么可能就会体现出所谓的图形表示的问题。
就是你需要把这些复杂的符号逻辑啊映射成这种更形象,更直观的这种图形表示。反过来啊,再去进一步的去理解这些复杂逻辑,可能啊就会对大家的这个学习过程有这么一个帮助。所以第一部分啊需要介绍一下,关于就是其实。
我觉得在咱们上。中学的时候其实就所谓的数形结合的问题是吧?如果我们把这种呃数学符号理解成是呃计算逻辑,那么图形呢就是在此基础上用一种形形象化的方式把它表示出来。这两者之间啊更。
帮助我们对整个问题的有一个深刻的理解。那么第二部分呢就是关于概率模型与基本规则的问题。啊,大家也可以可能看到了啊,就刚才我们以HMMCRF为例的话啊。
这两个模型啊都是非常重要的概率图模型当中的呃非常重要的这个特例。那么既然讲到了这种所谓的概率模型。那么怎么去理解这种就是所谓呃基于概率计算之上的模型表示,可能就需要大家啊有一个更全面的认识。
因为哈因为我们知道当我们一提到模型的时候,我们更容易接受的是作为它的函数化表示形式,就是F等于FX的形式,对吧?你给我一个X,我给你一的应是F。啊,这样的话我就完成了一个从输入向输出的一个影视关系。
这个模型的理解可能大家都比较容易接受。那么怎么怎么去理解这种所谓的概率模型啊,就是用就是以这种条件概率的方式所体现出来这种模型,可能就是一个需要再进一步解释的问题。那么在此基础上呢。就可以发现啊。
就是像我们这个HMMCRF这么复杂的这种所谓的概率图模型。呃,其实哈就是。它也是基于几条或者基于呃一些基本的规则啊,再加上几条基本的假设之上啊,通过一系列的概率计算所得到的那这个时候呢,你会发现。
当我们有关于模概率模型的一个理解以后,那么再加上一些基本规则的一些理解。其实再复杂的概率模型,其实我们也可以啊能够啊逻辑上没有问题的把它一步一步的推导出来啊,这是第二部分啊。
就想和大家分享的就是所谓概率模型的问题。那么第三个话题呢,可能就是关于继续学习当中的模型关系的问题啊,就是我们很多的初学的同学啊,特别是有还有一些就是学了很就是很多模型的同学。呃,有会有一个问题。
我说困惑就在于这么多的模型啊,好像每天我们做了很多的工作,那么这些工作是。是割裂的嘛,或者说是是是彼此是独立的嘛。很显然不是啊,模型和模型之间是有很强的这种。呃,发展脉络的啊。
特别是啊我们现在讲到深度学习那非常繁杂的这个神经网络的时候,你会发现嗯,其实每一个工作都是在他的前续工作的基础上做了一些改进来得到的。那如果我们按照这个思路如有前后这种关系的话。
你会发现有很清晰的啊这种模型的发展脉络关系。如果当你掌握了这种所谓的模型脉络关系以后,你会发现你的复杂的问题就可以逐步啊一步一步的把它的复杂性降低下来啊,当你有这种视角以后,你会发现ok一个新的工作啊。
它是在原先的哪个工作的基础上,针对哪些问题做了哪些改进。你只需要把这个改进的部分能够解决掉啊,整个的复杂性也就降低下来了。所以说第三部分呢和大家讲一下关于这个模型关系的问题,好吧?以上呢是咱们。呃。
计划啊,今天我们把这三个部分做一个讨论。那我们先看第一部分。

就是关于机器学习当中的符号表示和图形表示的问题。

呃,首先我们看一下符号表示啊,先解释说明一下什么叫符号表示,其实就是我们的函数化表示形式啊,或者说是我们的就数学表示,以一种这种形式化的无二意的形式把我们的复杂模型进行一个表示。那么既然是符号表示。
那么其中就关于符号的问题需要特别重要的提出来啊,就是这一堆数学符号每一个符号都有它明确的标准的这种含义。你对它的理解和掌握啊,不能出问题啊,这是最基本的要求。呃,换一个思路啊。
如果你对这些基本的数学符号本身还有一些困惑的话,那么就更加的为后面的这种学习啊带来更大的一些隐患啊嗯。举个例子啊举个例子,比如说啊。符号表的问题啊,那为什么要提出这个来呢?嗯。
麻烦就麻烦在数学本身要求它的无二异性是吧?你不能出现两种不同的理解。但是呢对于同一个符号的使用,往往不同的场景啊,不同的课本啊,不同的这个这个作者使用起来呢还会或多或少有一些偏差和不同。
这个时候就麻烦了是吧?本来我们是要有要用要使用一个无二异性的工具。你这个时候呢,偏偏是在这么强的条件之下,那又带来一些变化,或者说是带来一些。呃,不同的符号理解啊,这本身就是矛盾的那怎么样解决这个矛盾?
其实非常重要的呢,就是关于符号表的问题啊,符号表。这种这个表哈,但凡是大家啊多看几本书啊,特别是理工科的书,你都会发现。嗯。好一些的教材。当然这个好是一个非常主观的一个判断啊。
就是就是一些权威的教材啊一些经典的教材啊在。这本书的前面或者后面啊都会有这么一个所谓符号表的东西。很少有同学去看,但是呢呃今天还是非常强调一下啊,非常非常希望大家啊就是在读一本专著的时候。
先看一下它的符号定义。呃,当然很多会啊列出来,嗯,90%甚至95%,甚至99%啊,都是和你之前的这种啊学习习惯是相一致的。但是啊就是哪怕可能那1%的不同。会对你今后对同一本书的理解啊。
同一本书里面同样内容的理解带来很大的困惑。有的时候你因为数学这种东西本身的这种逻辑自洽性要求,它是完全是逻辑统一的是吧?逻辑自洽的,没问题的东西。但是往往这种符号的这种他自己的这种定义啊。
和你自己的理解的不同,造成的这种困惑,就造成了这种很很很强的这种冲突,怎么解决,就是看一下他的符号表的问题。嗯,提到这个地方呢,这个符号表呢。也仅仅是个例子啊。
这张符号表呢是在呃积器学习方向非常重要的一本这个参考材料,叫做统计学习方法啊。我相信啊这个很多的同学也都是呃知道或者了解这本教材。非常好的一本教材啊。
呃如果细心的同学呢会发现在这本教材的第一版啊和第二版有非常非常大的不同。啊,因为第二版李航老师在第一版的基础上大量的补充了无监督学习的模型。啊,非常好的一个这个工作。呃。
但是哈这个我我我非常不能理解的就在于呃你仔细的发呃,仔细仔细一点,你会发现第二本教材里面把第一本教材里面的符号表删除掉了啊,没有了。呃,不能揣测原因哈,但事实上或者客观上确实是没有这张符号表了。
那么带来的一个呃问题呢就在于很多初学的同学,因为呃很多的同学都是以这本书作为一个入门入门的一个参考教材是吧?很多的初学的同学有的时候就会造成一些呃困惑,那我们就简单的看一下,好吧,呃,都有哪些符号。
可能需要我们特别注意一下,当然。呃。也也不全啊,就是把一些希望能够这个使用到的和大家看一下啊,比如说啊实数级R从这一点上就可以看到啊,在在在这本书里面的实数级R是使用的一个实体的,就是黑体的一个R。呃。
但实际上是呃这个很多的材料里面,你比如说我们经常会见到这样的。对吧我们经常会见到的这样的示入级的一个表示。当然它不是重点,但是你需要知道。呃,你需要猜了是吧?当你读到的时候,你就需要猜哦。
原来哦这个啊实数级R啊,就是我们这里的实数减R啊,这个时候如果有一张表告诉你,O我们在这本书里面实数集就是用这个R来表示的。至少我们就完全没有这种这种猜测的必要性了,是吧?这个就说明一下。呃。
我想说的一些比较重要的地方呢,就是这个东西。大家可以看到了,关于向量的问题。首先呢可以看到这里的X定义是个很很明显的是个向量啊,是个向量。一般意义上哈一般意义上我们我我们习惯,比如说如果你是这个这个啊。
印刷体啊,我们我我们希惯你加箭头,代表它是向量,否则的话呢我们可能会用这种。印刷体来表示它是一个向量是吧?很少用这种直接用小写字母来表示向量,因为我没有办法区别,这里的X和一个标量X的区别,对吧?
你放在这个地方,你说这是个标量这是个向量,那形式上又一样,我没有办法去区别。呃,但是呢如果你。你在符号表里面就直接定义了。在我这本书里面,所有的这种形式就表示了向量,那也OK了。
这是一个这是一个需要说明的地方,更需要说明的一点在后面啊,在后面大家可以看到啊,既然是个向量就免不了分行向量和列向量。我们在积极学习领域啊,有一个默认的,就是我们认为啊所有的向量都是都是列向量啊。
都是竖值,就是竖着的列向量。但是很显然啊,这种这种方式会太占这个太占纸张啊,一本书里面如果都是列向量,写不了几行公式就写满了,太占地方也浪费。所以呢往往我们会把它表示成行向量加转值的形式。
所以说啊你这个地方你经常会看到的是它形式上。它形式上是一个行向量,一行一横行。但是呢往往它在右上角加上一个转值符号啊,表示成一个列向量的。形式啊,就是列向量,我们用行向量加转制的方式来进行表示啊。
这个有初学的同学啊可能是会比较纠结啊比较纠结,为什么这。呃,首先如果你认为是个列向量的话,为什么非铁型行向加转制的形式啊,就是为了少占地方啊,就是这么一个原因啊。这其实还并不是最重要的啊并不是最重要的。
为什么这么说呢?因为我们是在所有的向量都是列向量的前提条件,除了假设之下,才用这种行向量加转置的形式来表示向量。但是事实上并不并不都是做这种假设的啊。另外一本书啊,比如说像这个。
周志华老师的那本西瓜书啊,就是那个也非常非常有名的那本西瓜书啊。作为我们的教材的话,在那本书里面,行向量和列向量是通过元素的分割符来表示的。比如说X1。X2所表示的向量,那这个时候是个列向量啊。
好像是啊具体清,我我也记不太清楚了,需要看一下它的符号表。但是你会发现完全是两种不同的符号表示形式。如果你对这个有困惑的话,或者说你不对这个符号表啊,这本书的符号表有一个认真的学习的话。
你会发现所有的一些计算逻辑。因为我们知道因为为什么我们要分行向量和列向量,因为我们后面会要做大量的内计计算是吧?向量的内计计算。这个时候。内机嘛就对应元素乘积求和嗯。这个时候需不需要加转制啊。
如果我们是都是列向量,当然做内机的时候,我们需要呃就直接定义内基计算就可以了。否则的话,我们还需要考虑一下它是不是需要再转制一下相乘的问题。啊,这个时候。就带来很多的一些困惑。呃。
这只还这还仅仅是在向量的这个语境之下去讨论。后面我们还会见到更复杂的结构,比如说像矩阵是吧?更夸张一些。我们深入学习里面还有各种各样形状的张量。所以说你会发现如果你不对。
这些数据结构啊有一个更清晰的结构上的认识啊,它到底是个几行几列的,甚至它是个几乘以几乘以几的一个张量。你后面的运算。呃,非常非常容易出错啊。
所以这个时候啊这些符号的定义是非常需要大家能够仔细的去掌握的啊。所以说啊这个这个符第一部分就符号表示当中的这个符号表啊也是建议大家今后再看到一些专注的时候,不要直接跳过去啊,跳过去的话呃。
风险还是有一定风险的啊,看一眼大体这些符号是不是我们所啊和我们之前掌握的理解的符号是是是相一致的。好吧,这是关于这个啊符号表示的问题。嗯,O啊。关于这部分,我们先停一下,看看有什么问题吗?
声音和视频应该都可以是吧?ok没问题,我们就继续啊。呃,这是关于符号表的问题。那么另外一部分呢,就是关于图形表示的问题啊,关于这个图形表示呢,就以刚才我们所说的哈。
就拿着这个伊马可夫模型来作为一个例子哈,来解释和说明一下。因为我们知道哈关于一马可夫模型mbda它是个三元组啊,是由AB派来组成的。当然有些同学说这个这个我我不太了解。如果同学不太了解的话。
我们在这个我们官方主页上应该有相应的一些课程哈,就一些公开课,有兴趣的同学可以看一下,就是一个一码夫模型是有所谓的状态转移矩阵啊,状态转移概率矩阵A就这类的A,还有这个状态观测。
观测矩阵啊观测概率矩阵B还有初始概率向量派来组成的三部分组成个三元组组成的。其中哈我们很多的同学学到这个地方就有点有些困惑啊。首先第一个就是lambda这个模型很复杂啊,三部分组成三个啊结构啊。
两个矩阵一个向量很复杂。怎么去理解这三部分就是一个很大的一个呃问题。怎么去理解,结合着图来表示,你把一个复杂的像尼马可夫模型这样的图,通过一个图形啊,把这个图形当中的所有的图形符号和我们在。符号啊。
数学符号来表示的这个模型当中所使用的这些数学符号,建立这种数形的这种结合关系。对同学们以后啊,你像啊后面我们举了一个例子啊,比如像后面进行这么复杂的逻辑计算啊,其实你就知道你在你在哪,你要到哪儿。
中间怎么去做,你只需要把逻辑填充上去就可以了啊,所以这种。复杂的数写表示和这种呃图形这种直观的图形结之间的结合也是非常重要的那我们就看一下怎么把它们映射起来,就是这个东西啊。
数学表示和下面这个图逻辑上是一样的,就它俩是一回事啊,问题就在于怎么把这个图映射到我们这个数学逻辑上去。我们仅以刚才所说的那个矩阵A啊,就是状态状态转移矩阵A来进行一个说明,好吧,呃。
状态转移矩阵A啊是一个是这么个东西,是个A啊,是个AA是个什么呢?是后面这个式子,这就刚才啊进一步的说明刚才那个符号的一个作用啊,就是你这一堆符号到底是个什么东西啊,很显然这个地方是个矩阵啊。
文字上也描述了,是这个矩阵啊,但凡是个矩阵,其实首先关心的不是这个矩阵里面的元素值的问题啊,这个矩阵的形状首先是需要搞清楚,弄明白的,就是这个这个矩阵是个几乘几的几行几列的一个矩阵。
就像刚才我们所讨论这个向量的这个这个逻辑是一样的。就是你先把这个向量是个行向量还是个列向量搞清楚啊,然后再讨论它是个几为向量,然后再讨论它的每一维里面的元素的组成的问题。同样在这个地方。
我们现在知道了它是个矩阵,那他说是是个几乘几的矩阵,你先搞清楚,然后再去讨论这个矩阵里面的每一个元素到底是谁的问题。好吧,那么他告诉我们,这是被称之为是状态转移概率矩阵啊,状态转移概率矩阵。
它是用不来啊记录时刻T处于状态QI的条件之下,在时刻T加一处于状态QG的概率。很显然,他说的是两个状态之间的转移概率的问题。既然是两个状态之间进行转移。那如果我们假设我当前有N种状态啊。
我现在有N种状态,任意两个状态之间都可能存在这种转移关系的话,那我们很显然能够知道,如果我要把这N个啊N个任意两者之间都可能发生转移的这个状态集合的这种转移关系进行完整的记录的话。
那么很显然这个矩阵A应该是一个N乘N的一个矩阵。是吧我们可以看到啊,他要来记录的是任意两个状态之间的转移关系,我又有N个状态。那这N个状态里面。
我任意找两个都必须要完整的能够在矩阵A里面清晰的知道它的转移关系。那这样的话,我们通过一个N乘N的矩阵就可以完成了。所以说啊第一步先搞清楚它是一个什么样的矩阵。然后在此基础上也更容易帮助我们去理解。
既然它是记录的是任意两个状态之间的转移关系。使用N乘N就表明了我第一个状态可以跳到。其中的任意。一个状态当中去。那么第二个状态。同样也可以跳到任意一个里面状态里面去。
所以你会发现这I点一直到N1234N。所以你会发现最终我们得到的是一个N长N的矩阵。那这样的话矩阵里面的每一个元素。如果这是第二行,如果这是DJ列,那其中的每一个元素记录的就应该是什么?
看照要求是在T时刻处以QY。在下一个时刻处以QG的概率。这个时候有些同学就反应不过来了,什么叫T时刻?什么又叫做T加一时刻,这个时候就不再像这个矩阵这么清晰的能够反映出这种规律性了。
那这个时候就不需要借助我们的图形表示了。好吧,既然说的是T时0刻和T加一时刻啊,既然是T时0刻和T加1时刻,我们就能很明显的就是。值道的在于T和T加一是两个紧邻的时刻关系。T时刻在T加一时刻的前面。
T加一时刻在T时刻的后面。所以你会发现啊最简单的一种符号表示方式哎。我就可以用两个圈来表示它们两个状态。前一个是T时刻,我们用IT来表示,后一个是T加一时刻是IT加1。
对吧就会你这这是一种很自然的一种一种一种啊一种。一种结果是吧你你就是前面和后面的关系嘛,T10刻和T加10刻,那就是前先有T10刻,然后再用T加10刻不就可以了吗。然后呢。
再看一下是在T10刻处于状态QI。然后T加1时刻是在。状态QG的时候,那这个时候很明显,IT是等于QI的IT加一是等于QG的。你会发现所有的信息啊,所有的已知信息都在我们的图上表示出来了。
这是前面一个状态,这是后面一个状态。在前一个状态是QI,后一个状态是QG的时候,我们定义的是什么?我们定义的是一个概率。那很显然是个什么概率,是一个在某某条件之下的概率,很显然是个条件概率。
所以你再看一下,进一步再再去理顺一下这个数学符号就比较清楚了。什么清楚呢?是在前一个时刻T等于QI。在前一个时刻,IT等于QI的条件之下,下一个时刻IT加一等于QG的。变率。我们把它定义为AIG。
AIG前一个时刻,我比如说是第二。二这个时刻,然后下一个时刻。跳到三这个时状态当中去的时候,那么这个A23啊,这个小A23这个数值代表的就是上一个时刻是2,下一个时刻是三的时候,我的这种跳转概率。
但是这个概率值是多少?我们需要根据啊需要根据呃你的数据集啊,根据你的数据集或者根据你的场景进行分析,再知道这个值是等于多少。但是刚才我们所说的,我们更关心的是它的逻辑含义是在这个结构当中,这个位置上。
这个值的含义代表的就是前一个时刻和后一个时刻状态和状态之间的转移关系。值至于这个状这个转转移该关系的值是多少,我们通过数分析我们的数据,通过分析我们的场景,就可以把这个值填充到我们矩阵当中去。
又得到了整个的矩阵A里面的任意两个状态之间的转移关系。还回头啊,再看一下。这到底我们要要干什么?当是我这些内容啊,这些内容可能有同学说还是还是还是一头雾水。嗯,这很正常。这个因为还有一些前虚知识啊。
大家可能不是特别清楚啊,那么。这段的分析的目的啊,其实核心就在于啊核心就在于我们当拿到。比如说我们拿到的是这个东西,或者课本上仅仅告诉我们的是这部分。一段文字或者一段文字,加上一段数学数学公式。那么。
有的时候确实是因为你看啊数学符号很多啊,呃其实文字描述。即使是非常准确,它的逻辑含义啊也并不是那么的直接啊,所以这个时候很有必要哈很有必要,及你首先需要对这些数学符号有一个清晰的认识,结合这符号表啊。
如果符数学符号你都搞不清楚,你知道这个中括号什么意思啊,这个N乘N什么意思啊,很显然,N乘N说的是这个矩阵的。形状是吧,这个矩阵的行列形状啊,这个你你首先不能有问题。如果这个搞不清楚,嗯。
就需要就需要找一些其他的教材补充一下是吧?这个搞清楚以后,再看一下它在整个模型当中的概念。这个矩阵里面定义的是时刻T和时刻T加一的一个条件之下的概率。所以你会发现文字描述啊和数学描述。
其实是逻辑上也是等价的,是吧?它俩其实也是一回事啊。麻烦就麻烦在,即使是有这种文字描述,即使是是有这种无二性的数学符号描述,你对这一段的理解其实还是有困惑就。他到底在说什么?
就不如哈把它更形式化的、更形象化的,通过一系列的符号来表示出来。无非说的就是时刻和时刻之间的跳转关系啊,或者说是跳转概率。那跳转从谁跳到谁,我总是可以表示出来的,拿个箭头表示着前后关系不就可以了吗?
那么这个时候。这是IT这是IT加一,它等于QI它等于QG。我就说的是这样的一个从啊QI跳到QG的这个跳转关系,用AIJ来表示。那么很显然,这个调转关系在任意的前后关系之间都是满足的。
对吧这如果是I大T减1,那么它俩之间也是可以通过从AIG当中找到相应的映射位置来来满足我们的这个。跳转关系计算的。那么他是需要知道上一个时刻,然后跳转到下一个时刻,很明显的就是一个条件概率嘛。
我在IT的时候是QI跳转到IT加一的时候是QG的。条件概率是AIG,然后你看看。逻辑上是没有问题的,形象形形更形象的把这这个逻辑表示出来了是吧?同样哈如果。如果按照这个思路啊,同学们可以回去之后。
你再找一下那个课本里面介绍介绍什么介绍这个关系。这个关系很显然是说的是什么?同一个时刻对吧?同一个时刻在IT等于QI的条件之下,我跳转到什么?我跳转到。我的O。一等于VK的这么一个观测。
就状态和观测之间的调整关系。所以很显然它应该我们现在有了图以后,我们把这个公式其实就很好能够写出来。首先它也是个条件概率,在IT等于QI,然后呢是OT等于VK。这个式子很显然。
说的就是从状态到我们的观测之间的调整概率。对吧,所以说你会发现哎他也是。点点他也是。你会发现这个图里面这个跳转关系我们也已经有了,还差谁呀?还差一个对I一就像我们的多米诺骨派一样是吧?
如果我们的AIG说的是状态和状态之间的跳转关系,这里呢我们给他起一个名字,叫个BJK它说的是状态和观测之间的关系。那么多米诺骨牌还需要有一个什么第一个骨派需要倒下去。这个时候很显然,我们只要找一个派。
来表示就可以了。他说的是第一个时刻,P1等于QI的这个。概率就在第一个时刻的。概率到底是多少?所以说你会发现啊再复杂的这个模这样的话,我们的兰姆达AB牌就已经有了哈。你会发现再复杂的模型。
我们只需要把这些。😊,输字符号和我们的图。对应起来,或者反过来把这些图里面的信息能够找一个数学符号进行表达。那这样的话这个模型。你现在在看其实就不再复杂了,他就是这么回事。是这样吧。
所以说我觉得第一个问题啊,就是关于符号和图形的表示啊,这个还是非常需要大家能够能够能够能够理解的。好吧,这是关于在HMM里面。我们下面比如说在CRF里面同样的东西啊,CRF这个条件随机场。呃。
怎么去理解这个条件啊,就一个东西这个条件到底在哪儿?它是在随机场的基础上加了一个条件。那首先随机场是谁来看看。这一块是我们的随机场,条件是谁?条件是我们的X下边这一块。
所以说我们的CRF其实本质上是个这么个东西。是在输入X条件之下,这是我们的输入X或者或者说是在这儿在输入X条件之下,Y的条件概率。一会儿我们会讲到啊,这其实就是模型啊,这其实就是模型。
就是当我们输入X作为输入以后得到的关于输出Y的一个概率值,当然我们的输出Y,就是使得这个概率值取得最大的那个时候的概率值,当然那是后话啊,一会我们会讨论这个问题。但是你会发现这就是条件随机场啊。
就是还是那个输心结合的问题啊,就是谁是条件,X在哪儿?X就在这儿,谁是输出Y就在这儿。当然这个地方需要注意的是这的Y啊,不是一个随机啊,不是一个随机变量,它是个随机向量。
它代表的是由若干个分量组成的一个联合概率。这个呢这个今天就不展开讲了,就是在。这个。具例讲模型的时候,其实这也是一个经常会出现困惑的地方。当然这今天这不是今天的重点。
重点就在于你同样也需要啊同样也需要把谁是条件啊,谁是输出啊,谁是输入,谁是输出能够搞清楚。然后输出的YYY之间。很显然,这个地方啊就不像HMM里面定义的是转移转移概率了。
它定义的是边上的特征以及节点上的特征的问题。边有边上的特征,我们一般是用TK来表示节点上有我们的特征,我们用SL来表示。所以你会发现啊,既然是边上的特征,就有前面一个就牵扯到两个节点。
前面一个节点YI减1,后面一个节点YI,这是边上的特征,每一个节点上还有特征,那是SL,所以说你会发现根据我们那个。呃,最大团的展那个最大团的那个联合概率的呃这个这个成绩的表示形式,你会发现它是E的。
指数次幂相加的形式,其实就是我们的特征和特征的之间的概这个指数词相乘。所以你会发现它是指数,它是这个E的指数次幂相加的形式。所以从这个时候你会发现哦,你再看那个式子的时候很复杂。
但是你会发现哦一个特征是定义在边上。那么我需要知道两个节点。另外一个特征是定义在节点上,那我只需要知道这一个节点就可以了。然后从指数次幂上,按照我们的最大最大团的那个公式展开就可以了。还是啊就是。
公式会很复杂啊,你会。接触越来越复杂的模型啊,模型的表示会越来越复杂。那这个时候借助这些形象化的工具,你才能知道你到底在哪儿。你分析的是哪一部分的问题,这部分问题会有哪些约束条件啊。
或者可用的一些公式和中间结果为你要解决的问题带来哪些帮助?所以说这个。第一个话题啊就是关于它的符号表示形式和图形表示形式。是非常重要的啊这个。如果我们。对吧经常我们会见到这种图是吧?我们这个。诶。呃。
约束的一个过程啊,优化的一个过程。那这个时候很显然这个这里如果是X1,这里是X2。那我们的损失函数在哪?损失函数是垂直于我们整个平面的一个直线。其实如果画清楚一点的话,它应该是三维的是吧?这是X1。
这是X2,这是我们的损失函数。所以你会发现我们的损失函数应该是这样的。它是把它投影到,你从这个角度上把它投影到整个平面里面,才是这样的一个形状。但是我们为了化简啊,只看到这个图。
所以说这个图形有的时候你还需要仔细的一个分析。啊,O。好,这是关于我们这个算是第一部分吧,就是关于我们这个。呃,怎么说?就是符号表示和我们的图形表示之间的关系的一个问题。诶。大家看看还有什么问题吗?
关于这一部分。O。啊,那如果。

没有问题的话,我们就继续好吧。那第二个问题啊就是关于概率模型和基本规则的问题。

首先哈是关于这个概率模型。还是啊第一个问题啊,我一直会就是上课的时候,一直会问同学什么什模型。因为我们积极学习方向啊,就各种各样的模型,我们都每天都在学是吧?各种各样的模型,这个到底什么是模型?
我们最容易接受的是这种形式。Y等于FX是吧?你给我一个X,我不管你是什么样的一个数值,我得到它所对应的一个结果就可以了啊。如果是个分类问题,你给我一个X特征,我得到它这个分类标签是吧?如果是个回归问题。
你给我一个输入X,我得到它的一个连续值啊,这是我们最容易理解的关于模型的一个定义本身啊,这就是模型哈,不管再复杂的。再复杂的模型,我们也可以通过这种方式来加以理解。除了这种方式。
我们一般把它称之为是函数模型。啊,以函数形式来表示的模型。那么另外一种呢就是概率模型啊,这种呢有也也常用啊也非常非常常用。但是呢我们没有那么把它直接的提出来,什么是概率模型。看下面啊。
首先概率模型也是一种模型啊,它是用概率的方式或者概率的形式来表示的模型。什么样的概率呢?就是条件概率。当然我们有的时候也用联合概率来表示,但是我们更常见的是所谓的条件概率的形式,就是这种方式。
这个可能对于有些同学来说,可能就有些困惑,就是这不是个概率值嘛,只是个概率啊。这个它怎么又是个模型呢?如果说啊上面的函数模型,我们是一个yes or no的结论,就是你给我一个X,我直接给你一个结论啊。
这个结论是几就是几啊,是分类结果还是一个连续值啊,那是几就是几的话,那么概率模型呢就不那么的直接啊,不是那么的直接。它是告诉你,当你输入一个X以后,得到相对应输出的一个概率值当然对应的输出可能有若干个。
比如说我们这个分类问题是吧?那分类标签的话,可能有多种分类标签,它得到的是关于每一个分类标签的那个概率值,当然是在X输入条件之下的那个概率值。那这个时候我们往往要得到那个Y标签的时候。
我们一定是使得当前概率值取得最大概率的时候呢,标签。比如说哈。明天我是出门还是不出门,我可以看一下天气预报是吧?比如说天气预报告诉我,明天下雨。啊,明天下雨,在明天下雨的条件之下,我出门的概率是10%。
当然同样我在下雨的条件之下,我出门的概率是90%。那你告诉我明天出门还是不出门,我当然是取那个十出门概率尽可能大的那个标签作为我的标签,哪个标签最大概率只是90%的那个不出门的标签的概率是最大。
所以我的最优解,就是我不出门。但是你会发现它呢不是那么直接告诉你。出门还是不出门,而是你需要自己加以判断使用那个概率最大的选择一下才能得到最优解。但是不妨碍它本身也是一个模型的问题。
所以说啊关于概率模型呢,是我们也需要。诶。能够能够能够理解的一个过程。那么更进一步的话,我们看一下它的这个。更一般这个表述看下没?假设空间也可以定义为条件概率的一个集合。啊嗯。就是使我们的条件概率啊。
使我们的条件概率来作为我们的模型啊,这样的模型有若干个啊,满足X输入条件之下,Y的这个条件概率有若干个这若干个条件概率组成我们的假设空间画F啊花体的F啊画F。
其中X和Y分别是定义在输入空间画X和输出空间画Y上的随机变量。这时我们的画F通常是由一个参数向量来决定的条件概率分布足啊。呃,这个地方免不了啊,又提到另外一个问题,就是关于输入空间和输出空间的问题。嗯。
多讲两句啊,就是这里。输入空间和输入空间一提一但凡是提到了空间。就是集合哈空间在我们现在的语境下面就是关于集合的问题,就是输入集合和输出集合的问题。输入集合和输出集合啊,很多同学都比较好理解啊。
就是我有输入嘛,有若干个输入是吧?X1X2、X3点点,这是Y1Y2、Y3点2点,所以说你会发现既然有这么多输入,这么多输出。那么当然有直接输入和输出所组成的集合,就是YX和YY,这是非常容易理解的。
不容易理解的地方在哪儿呢?就是关于这个假设空间的问题,我们的目标是要找到一个从X向外的一个映射的一个模型F啊,向外的映射的一个模型F。但是我们要清楚或者明白的是什么呢?就是这个映射F啊也不唯一。
这可能对有些同学来说就有些困惑啊,就是。就是我手头上有一堆数X还有一堆数Y,我要找一个映射过程,能够保证从X得到Y。大家能够想象的到的是这个映射过程啊,其实并不唯一啊。
我可以找到若干个能够满足从X向外映射的这个函数F。那么由这些能够满足从X向Y的映射的F又组成了一个集合啊,就是刚才所说的那个空间的问题,又组成了一个集合。
这个集合我们一般把它称之为是假设空间或者假设集合。啊,那这个时候就有一个问题就在于哎。所谓哪个最优的问题,那这个时候就用定义我们的模型选择策略。比如说我们的结构风险最化,这把经验分险最化。
大表是我们的这个呃。呃,那个我们用我们的这个概这个叫什么那个呃极大自然估计是吧?来完成我们的策略选择。那是另外一个问题。但是你会发现我们手头上就有了一个输入空间,有这个输出空间,还有一个什么?
就是所谓的假设空间,或者我们这个它称之为模型空间啊,有有有F组成的嘛?模型空间。但是这个时候呢。另一个话题啊,就是关于。这些模型空间怎么表示的问题啊,比如说我们一条直线啊,Y等于AX加B,你会发现。
即使是一条直线,决定当前直线的也是它的斜率和截距是A和B。我们往往把A和B啊称之为模型的参数是吧?所以说你会发现表征当前模型的是由AB这种参数来构成的。我们又知道这里个AB也也不为一。
是吧我们的模型我们的节距和斜率也不唯一,所以有若干个节距和斜率或者若干个参数。这个参数呢我们把它往往称之为是参数空间。你会发现最终的问题转化成了我要在参数空间里面找最右的参数。
把这个参数带入到我们的模型当中去来完成从输入向输出的映射。所以你会发现最终的问题落脚到了找参数的过程当中去了啊,这是我们的一般思路啊。所以说你会发现在下面的描述里面,才是在这个地方说到过。
它是由输入空间X向输入输出空间外上的一个随机变量。这时呢我们通常是由一个参数向量来决定的条件各类分布。所以这个地方啊就这里的F。或者说我们是用条件概率P来表示的话,那这个时候它是个它是个足。
所以说你会发现啊它是一个由西塔来代表的一个分布族,就若干个分布啊,就像刚才我们所讨论的那是一样的一个过程啊,嗯看下面其实也讲到了啊,我们有的时候是用决策函数啊,用函数来函数模型的形式是吧?你给我一个X。
我通过模型映射,得到相应的Y啊,另外一种方式呢,我们通过条件概率分布的形式。你给我一个X,我得到的是得到Y的一个概率值,那我当有一个新的数据XN加一来了以后。
我得到这个XN加一对应的那每一个标签或者每一个输出的概率值。我取那个是概率最大的那个标签作为我当前N加一次的输出啊,这是我们刚才所讲到的。好吧,就是关于啊就概率模型呢,今后也是一个非常重要的模模型形式。
就是一个条件概率啊就是一个条件概率。你给我一个X,我给你一个输出Y的一个概率值啊,至于哪个是外星,肯定是使得这个概率最大的那个所谓外星。那关于这一部分,看看大家有什么问题吗?嗯。没问题,那就继续啊。嗯。
那。嗯。嗯,啊不用求积分。啊。嗯。这个时候啊是个简单的,其实其实就是简单的。当我们能够得到这个条件概率以后啊,既然我们得到了条件概率。那么很显然当我们有了新的输入XN加一作为一个新的输入以后。
得到的就是关于每一个输出外的一个条件概率值。就像刚才我们所讲到的,比如说我们到底出门还是不出门啊,这是个问题。那么我需要根据当天的天气预报来决定是吧?如果当天的天气预报是下雨,那么我出门的概率。
因为我们知道得到的这个概率值,我出门的概率可能是10%。我。同样是在预报下雨的条件之下,我出门的不出门的概率,那很显然就是90%。那么当我们你会发现啊概率模型得到的结果啊。
就是概率模型本身得到的结果仅仅是在输入X条件之下,Y的那个概率值。他不会给你做决策啊,或者他不会给你做决错,他只能给你一个做决策的依据。就像白守龙所说的。Y一等于10%。我出门。Y2等于90%。
我不出门,至于你出门还是不出门,你自己看着办。当然啊当然我们有一个非常简单的逻辑在于,我们当然是选择那一个概率值大的那个状态,作为我当前的。最优输出。那在刚才那个语境里面,我到底是出门还是不出门啊?
不出门的概率是10%呃。下雨啊下雨出门的概率是10%,不出门的概率是90%。那你说出门还是不出门,我当然是在大概率上选择不出门了呗。一是因为这个90的概率值远大于我的10%的概率。所以说。
我们是根据这个条件概率。的大小来选择最优的输出就可以了。嗯,就这么一个逻辑。但是呢有的有些同学接受不了,就在于。他怎么能是模型?其实啊如果较个真儿,它本身真的还真不是模型。
如果我们说我们以最终的输出作为。是否是模型的判断的话,它是使得。这个模型取得概率最大值的那个输出作为我当前的模型输出,我还中间真的需要做一个转换。当然这个转换逻辑上非常简单,我得到的是个概率值。
我当然取得是那个概率最大的状态,作为我当前的状态。但是这个是需要有一个呃怎么说呢?需要有这么一步。哇。嗯,我看下面一个。就是呃呃这是关于第一个问题,有关于概率模型的问题。
第二个关关于这个基本规则的问题就是。呃,概率模型会很复杂。行?其实刚才我们也看到啊,像HMMCRF这种相对比较复杂的概率模型,其实会有大量的概率计算在里面。呃,比如说下面这个下面这个例子啊。
下面这个例子就是我们在计算前项概率当中的一个计算过程。这个计算过程呢呃。嗯,看你怎么说啊,猛就是第一眼看的时候啊,确实是挺复杂。从一个定义开始一直进行一个推导,最后得到一个递推结论。呃。
中间有若干个步骤啊,若干个规则的使用。但是啊如果把这些规则提炼出来啊,其实你会发现就是这两条规则就是所谓的加法规则和乘绩规则的不断的使用。嗯。怎么说呢?其实你会发现。
数学的这种抽象逻辑在这个地方体现的还是比较明显的。就是我们把一些规则提炼出来以后,当你反复的应用这些规则的时候,就可以得到一系列中间的一些结果啊,这些结果可能会对你的这个呃计算会带来很大的帮助啊。
首先我们看往往啊往往呃有的时候就忽略了这么一个非常简单的一个基本逻辑。呃,还是回到这个李航老师的那边统计学习方法。在这本书里面呃,在第二版里面啊就补充了这个。部分啊就补充这一部分。
我相信啊这个李航老师也是在呃第一版的时候,因为第一版里面就有HMXCF啊。但是没有这个这这部分,我相信啊也是很多的这个同学有反馈啊,李浩老师也觉得哎ay也是有必要哈,再把这一部分能够能够补充上去。诶。
啊,还有另外一本书叫做PRML可能有些同学也听说过,在那本书里面的第一章哈,其实反复的讲解的就是关于这两套基本逻辑的使用。其实在整本书哈,说实在的,PRML那本整本书其实就是这两套。😊。
就是这两条基本规则啊,呃当然是在不同的模型条件之下去使用这两套基本规则。如果你认识到这一点,其实那本书说简单也简单,说说复杂的也复杂,因为它中间的逻辑是比较复杂的,但是基本规则就是那几条规则的使用啊。
就是那条规则就是那些规则使用。所以说哈这个。呃,如果你能够把它这抽象的规则掌握清楚了,应用到具体语境当中去解决一些实际问题。也就是这样了。那我们先看看这两个规则啊,其实很简单。第一条规则是价法规则啊。
关于PX。很显然,我们把它称之为这边缘概率啊,就是关于一个随机变量X的概率的问题。这个时候呢我们要建立的是它和XY的这种联合概率的这种关系。很显然啊,联合概率是有两个随机变量,一个X1个Y。那么。
左右肯定是不相等啊,就这两边肯定是不能直接相等是吧?你左边只有一个随机变量,右边是两个随机变量,肯定不能直接相等。那不能直接相等的原因就在于。你右边这两个随机变量随机变量Y啊。
比左边这个一个随机变量X的不确定性增大了,为什么什么叫增大呢?就是你你右边这两个随机变量嘛?你就是说举个例子,你比如说你左边扔一个筛子是吧?只有6个6个面的,一个筛子扔再怎么扔也6就六个面取一种结果。
你你右边是两个筛子啊,两枚筛子一块扔。这个时候排在左的概率形式可能就更多了,所以说你可以发现右边肯定比左边复杂,复杂就是由这个随机变量Y所带来的不确定性来造成的那这个时候怎么办?
我只需要把你这没筛子的不确定性消除掉或者还原回去就可以了。那怎么叫消除掉,或者是还原回去呢?从理解的角度上去讲啊,数学上我们不证明啊,就是数学上我们就是有复杂的计算,就是不是复杂的计算,就有证明过程。
可以证明这两个式子是相等的。我我我们不去证明我们就是从字面意义上去理解,你不就是多了一个Y嘛?你不就多了一个随机变量Y嘛?我只需要把这个随机变量Y所带来的不确定性还原回去是不就可以了。怎么还原回去。
如果我们能够理解的是。这个式子是成立的是吧?随机变量Y的全概率累加是等于一的对吧?就像比如说我们还是那个扔骰子啊,Y也是一枚骰子,而且是个正经筛子,每一面的概率都是6分之1。6个6分之1加起来。
那不就是一嘛?所以按照这个讲按照这个逻辑啊,就是这个这种分析啊,这不是严谨的,这不是严谨的证明的话,你会发现当我把这个两个概率的联合概率当中的一个随机变量的通过这种概率累加的形式消除掉的时候。
它不就退化成为一个随机变量的概率的问题了吗。所以说这就是所谓的加法规则。那这个时候呢,我们。其实你会发现当我们有了这个规则以后,从左向右的功能啊。
从左向右的功能是你可以把一个随机变量展成两个个随机变量展开啊,这种有吗这个有用吗?非常有用啊,你凭空增加了一个随机变量。为这个随机变量。如果后面还跟着表达式,就是这边还跟着更复杂的表达式的时候。
这个时候的。这个手上往往可以带来一系列的这个化简,这是从左向右,从右向左呢同样也是这样,不要忘了,从右放从右向左就是一个基本的化简了,把两个随机变量化简成一个随机变量的形式,形式上就简单多了,是吧?
所以说这个公式还是非常有用的。我们看第二个公式啊,第二个公式称之为乘绩规则啊,乘绩规则。成积规则说的是PXY啊,它一上来就是一个两个随机变的联合概率的形式。它右面右面是个什么东西?右面是1个PX。
乘1个PYX。啊,交换一下顺序啊,交换一下顺序本就好看一下了。PY在X电之下乘以PX。呃,看一下左右两个式子,左边是联合概率啊,左边是两个数据变量联合概率,右边是什么?右边是条件概率和边缘概率的乘积。
很显然。怎么去理解?如果说我们先不考虑后面这个式子的话。左面联合概率和右面条件概率很显然不能直接相等,为什么不能直接相等呢?因为很显然左边是XY2个骰子一块扔是吧?联合概率嘛,两个骰子一块扔。
右面的是个条件概率。他说的是一个骰子扔完了以后,确定条件之下,另外一个筛子再扔的概率,这是两个不同的实验,很显然他们的概率也是不相等的。那么麻烦就麻烦在它是在X等于。一定的条件之下。
另外一个随机变量的条件概率的问题。那它的这种不确定性明显要比左边这个两个骰子一块扔的不确定性要小很多。因为你这个X已经被确定了嘛,那不确定性就在于你这个X作为条件已知了,那怎么办?你把这个X再作为一个。
不确定性还原回血是不是左右就可能相等了?那它的右边的不确定性。不就是PX吗?那这个时候我们就认为它俩是相等。当然还是那样啊,数学上的证明很显然不是这样来做的啊,不严非常不严谨,只是为了我们理解方便啊。
为了仅仅是为了我们理解方便。那同样它的使用。从左向右啊展开啊一个概率形式展成两个概率的乘积的形式。那这个时候哎分开这一部分可能和后面的就可以进行一个呃相应的组合。同样从右向左是个化简过程。
边缘概率和条件概率的乘积化简成两个随机变量的联合概率的形式啊,其实。呃,这两条规则啊是我们在就是。嗯。当初呃大家学这个概率统计的时候,应该是非常非常呃。就是深深入的理解的这么两条关系。
为为什么他在这个地方我们就把它强调出来呢?是因为看下面啊,就是你会发现即使像复杂到。HMM里面的这种牵向概率计算,其实就是这两条规则。当然免不了啊,还会再加上一些什么,加上一些那个假设关系。
你比如说我们的其次马尔可复性假设观测独立性假设是吧?这是HMM里面CRF里面的什么程就马可复性局部马可可复性,全局马可复性,这都是为了我们的计算方便啊,你作为规则可以直接用的一些工具。比如说在这个地方。
签盖率这一步。从这儿到这儿,其实这定义啊,这没什么可说的,这是个定义。从这一步到这一步,只是靠符号化简,这也没什么可说的啊,这两步啊其实就是一个是定义,一个是符号化简。重点看这一步到这一步怎么来的。
你上面啊上面说的是IT等于QI,然后是OE到OT对吧?啊,这都是可以看作是联合概率的形式。然后呢可以展成下面这个形式。那问题是这一步怎么来的问题。看看有同学能看看吗?就从上面就是个等号嘛,既然是个等号。
不能平白无故的就等相等是吧?怎么怎么相等的。如果我们分析的话,你会发现下面这个式子里面多了一个式子。多了哪个式子,多了一个这个式子。对吧多了一IT减E等于QG。这个是在上面这个抵压概率里面所没有的。
那么既然。硬生生的多了一部分。那么这个随机变量的这个随机性,就需要把它还原掉,怎么还原,通过累加还原回去,这使用的是哪条规则,使用的就是上面这条规则。PX是我们的原始式子对吧?现在呢我是在PX的基础上。
我又增加了一个随机变量Y。那这个时候我们只能是在Y上进行概率的加,得到它俩才能相等。所以有同学就会较真啊,你这个式子左边是个边缘概率,一个随机变量,你这个式子里面可是个联合概率啊,不影响,对吧?
灵活一点啊,它即使是联合概率,我们也把这些联合概率,可以是不是可以认为是一个随机向量的一部分呢?那这个时候我再增加一个随机变量,就是这里的IT等于一,是不是就变成联合概率的形式。
那这个时候把这个IT你会发现IT减一等于QG,所以它是s之从一到N,我有N个状态,所以把它进行。累加就还原成它的。年还概率的形式。没发现就是使用的加法规则嘛。对吧然后再仔细一点,从这条到这条是怎么来的?
本来都是联合概率是吧?本来都是联合概率,现在很显然变成了什么变成了条件概率和联合概率的乘积。有同学说这个怎么用啊?很显然,我们下面有1个PXY等于什么?等于PY在X条件之下乘以PX嘛?
这不就是条件概率乘以PX。你看啊前面这不就是个条件概率。然后这是个这不是PX吗?有人说哎呀这还是没想不清楚PX是一个随机变量,这是联合概率,也不影响是吧?它既然作为了条件,把它再还原回来是不是就可以了?
所以这是使用的加码规则,这是乘绩规则啊。其实后面哈仔细一点啊,仔细一点,就是这两条规则反复在用,反复在用,想不清楚了,回来看看这两条规则就可以了。这就是啊今天第二部分就是关于概率模型和基本规则的问题。
好吧,看看这一步还有什么问题吗?呃,这些内容啊是在我们吉灵课程里面都会有的。这个今天如果。啊,我文公会课里面好像也有啊,就是细节部分。呃,大家可以通过找公开课,找我们的一些课程里面自己再搞清楚。
我今天呢只是一些方法上的一些介绍,好吧,因为这些方法反复的有同学。呃,有问题啊,所以说呢今天和大家集中的零讨论一下。

如果没问题的话,我们继续啊。🤧嗯。呃,机于学习当中的模型关系的问题嗯。先记住或者今天接受这么一个观念啊,或者一个认识,就是模型和模型之间是一定是有关系的啊。
当然并不是意定意味着所有模型和所有模型之间都有关系,但是至少啊它是有一个。呃。发展过程的啊,什么叫发展过程呢?就下面这个图。

嗯。仅举几个例子啊仅举几个例子,比如说我们现在的深度学习是吧,dep learning。呃,各种各样的人工神经网络啊,CB方向的LP方向的五花八招的神神经网络。
但是大家要知道啊大家要知道再复杂的人工神经网络。它也是从最简单的线性回归开始的啊,或者说它一定和线性回归呃,可以溯源到这个位置上。为什么这么说呢?Y等于X加B,就是我们在。
X向Y的映射过程当中的一条直线。它是从一个实数轴X实数轴X向我们的实数轴Y的一个映射。实数轴向实数轴的映射,这没问题啊,它它是个回归问题是吧?回归问题。但事际上我们要知道的是。
我们在此基础上我们在此基础上把这个输出外啊,把这个输出外从实数轴压缩到01空间。这是0这是一压缩到01空间的话,它就变成了一个分类问题。怎么压缩?很简单,我们加上一个soft max。
对吧加上一个S函数,就是s max函数,把它压缩到我们的01空间里面去。它就由一个实数空间的输出变成了1个01空间的输出。而我们就可以从01空间的输出,这是一,这是0,中间这是0。5。
以灵1空间的输出作为它的输出概率,完成了从回归问题向分类问题的一个映射。这时候呢我们往往发现啊。这是Y,这是X。一因为我们的输输入啊,因为我们的输入一般都是多维的高维空间输入是吧?
那么这个时候全值是W1W2W3一直到WN。所以我们往往可以得到这么一个图形。刚才所说的数形结合嘛。你会发现这里就不再是一个X,而是一个向量X,这里是一个向量W全值向量W乘以向量X加偏执B。加上偏至B。
既然是向量,就是对应维度的W和对应维度的X相乘,就是X1乘以W1X2乘以W2一直乘的WN乘以呃XN,然后呢再加上B偏至B在这个地方先进行求和,求和用sm求和符号。
然后再进行一个西格ma映射就是我们的S函数映射,得到最应的输出外,我们这是常用的一个符号啊,呃,这个符号呢一般把把它称之为是神经元。比如说逻辑回归啊,逻辑回归就是我们的一个神经元。既然是一个神经元。
我们可以从横向和纵向两个方向上扩充它的结构。那我们再加上一个神经元,再加上一个神经元,这是纵向上我们堆叠横向上这个地方是Y1,我们得到第二个是Y2,得到第三个是Y3。
把Y1Y2和Y3再作为特征输入到新的神经元当中去,就可以组成一个新的神经元。新的神经元向后再进行扩展,这是横向上的一个扩展。你会发现横向和纵向两个方向都可以通过对堆叠和延展神经元的方式构建更复杂的模型。
而这种方式所构建的更复杂的模型,就是我们的人工神经网络。好吧,那么在人间神经神经网络的基础上,我们前面再加上所谓的赤化卷积,就是所谓的卷积神经网络,把我们的隐藏层进行一个时间维度上的一个递归。
就是我们的循环神经网络。然后呢,在此基础上我们就。各种各样的改进。就到了我们的DL领域去了,你会发现倒不来。再复杂的人工神经网络,它的基础也是神经网络。
神经网络的基本单元就是我们的神经元神经元基础再往前,其实就是我们的线象回归。好吧,所以说你会发现啊呃当然讲这个原因是或者目的是什么?就是你后面即使到了DR领域。你也一定要知道他他的前序模型是谁啊。
就这个工作到底是CV的还是NLP的,还是推荐的,还是什么这个生负对抗的,是吧?那。他的前续工作是谁?前续工作做了哪些工作,然后在前续工作上有哪些不足,针对这些不足。
又在当前的工作里面做了哪些有针对性的改进?啊,这是一个逻辑。然后呢,如果你前序工作不了解,哎,发现哦前面这个网络不熟,继续再往前倒。他这个前序这个网络的前序工作是谁?你倒着倒着。
你会发现啊八成就导到不一定导到哪个你熟悉的网络上去了哦,原来是这样,原来是个卷积上啊,对吧?卷积这个效率上不这个不高啊,或者说是性能上不好啊,做了哪些工作改进哦,原来是这样的一个工作啊。
针对它又做了哪些工作,又得到了新的一些结果。对吧。所以说啊通过这个方式上你也可以看到啊,模型和模型之间。把这个关系找到了,你的学习难度和学习曲线也相对低一些,是吧?那我再举一个例子啊,比如说决色树。
那们这个ID3C4。5咖的树这都很很很很早之前的上个世纪八九十年代的工作,但是它和集成网集成学习组合。啊,比如说我们的boasting对吧?前项分布概呃前项分布算法和我们的这个加号模型111一结合。呃。
这样的话我们通过。集成的方式啊,提升我们的模型性能。再通过。GBDT是吧?我们通过在。假设空间当中进行模型学习,就像刚才我们所说的,这个地方就不展开了啊,使用我们的一阶梯度信息来得到。残插的一个拟合。
那这个时候再往后啊,用我们的二阶残插,用我们的二阶梯度,再加上我们的这个呃所谓的政策化项的改进,再上工程上的一系列的改进,就得到了chdy boost啊,这是一个在呃cover路上这个非常好的一个模型。
就是性能上呃结果上都非常好的一个模型,对吧?你会发现再往前倒,其实就是它的改进,无非就是做了两点原理上的改进,就是用了二阶梯度,再加上正策化项。你说这这个东西不就是在GBDT基础上。
我们很自然的能够想到。GBDT如果是一阶梯度,那么二阶梯度或者高阶梯度的这个性能一定要比一阶梯度的性能要更好一些。那你为什么没有做出这个工作呢?就是因为你想不到吗?很显然不是是吧?
所以说这个地方如果换你换个角度哈,换个角度,当你学习叉Gbos的时候,如果你了解了GBDT会发现啊啊,确实是这么一个道理,没问题。当然呃这个工作还是做了很多的一些工作啊。
包括它的性能上的优化和这个工程上的优化还是非常重要的一个工作。我只是说在学习过程当中,对吧?如果你了解了GBDT再往前看还是很。很容易能够接受的。那么当然GBDT如果你不了解,那你需要搞一下BDT对吧?
它是怎么样使用所谓的集成方法,把这个卡数进行一个结合,构成BD题的。所以你才知道哦它在直接在函数空间里面进行模型学习来拟合我们的参如果你BDT不了解,那你需要看什么是ing是吧?么是加法模型。
什么分布算法。如果你卡数不了解,你需要看一下基本的数模型到底是怎么回事啊,如果你知道D3是用了信息用了我们的这个信息增益是吧?C4。5是信息增比卡数呢其实就是基行指数。
其实你会发现再往前就是基本的决得数嘛。所以说从前往后的学习过程一定是一步一步向前推进的。但是很明显的我们感觉到啊,很很多同学都是急功近利是吧?一上来就是奔着DL去了。学了大量的模型也很多的一些技巧。
这没问题啊,很好的一些一些工作。但是你会发现当你再往后再往后看的时候,你会发现方向在哪如果你不了解前面的工作。怎么来的以后的方向其实还是有问题的,是吧?呃,当然这些内容呢就不今天就不作为一个展开了。
其实你会发现像HMCF这么复杂的模型,它其实还是有前向前序工作的是吧?你比方普素毕耶斯模型这么简单,但是在普素毕亚斯的时候,你怎么去理解那个朴素对吧?呃,输入条件之下的。联合概率之间的彼此独立性。
如果你了解了这个,你其实就是加法规则成序规则比较熟悉了。你这个时候你再看HMMCF其实也就相应来说不能说是迎刃而解吧。至少我觉得还是有很大帮助的是吧?如果你比如说EM下法和最大商算法能够有了解的话。
那么在解决学模型学习问题的时候,直接把它们当工具用就可以了。所以我想说的基本结论就在于啊,就是模型的学习一定不是孤立的啊,一定不是孤立的,它一定是。嗯,和其他的模型有有有有若干关系的。
而这个关系是需要把它梳理出来的。啊,而这个梳理的工作呢可能就是。那需要有一个过程,好吧。来看看这一部分还有什么问题吗?🤧哦。以上哈一上这么三部分内容啊,是我们今天的。那是想。
想和大家能够集中讨论的地方啊,第一部分呢就是关于符号的问题。啊,回去以后,但凡是在学习新的模型,或者看一本新书的时候,先看一下它的符号表啊呃。如果没有,那只能去猜了啊,大概率呢当然不是太大问题。呃。
但是呢需要仔细一点啊,不要先入为主的。有一个先入为主的认识啊,仔细一点去确认它这本书里面每一个符号的具体含义啊呃当然。读论文其实也是这样啊,当然论文如果每个论文都附上一个符号表呢,很显然不太现实是吧?
这东西在占地方啊,一般情况下,我们写论文的时候也是这样,就是我们写论文的时候也是需要清晰的定义出我们使用的每一个符号的具体含义,这才是对自己和对读者的负责啊?符号表。
另外一个呢就是我们的数学公式和我们的图形的这种对应关系。一般情况下这个图你需要自己造,也没有一定的规则啊,就怎么容易帮助你理解当前的模型,你自己脑子里面或者印象里面,把它构建出来就可以了。
你说这个模型一定是长这样嘛。嗯,大家习惯上会有一个印象。但是你说我我这样记不住啊,你你你怎么能够把它记住,你怎么把它。这个记住就可以了。好吧,这个没有什么不像符号啊那么明确的一个定义规则。嗯。嗯。
第二部分就是关于概率模型的问题啊,概率模型其实就是条件概率所表示的模型。然后呢,它。基本的逻辑规这个规则其实就是加法规则和乘绩规则。这两套规则的反复的使用,再复杂的模型啊,也是这两条规则啊。
没有什么其他特别。嗯,不一样的地方。

第三部分就是模型脉络的关系了。刚才已经介绍了,好吧。🤧啊。

这是我们今天的。所有内容了,看还有什么问题吗?和大家沟通一下。啊,能够。能够有帮助,当然是最好的一个情况是吧?呃,今天这些内容呢也不一定说是嗯。肯定还会有错误啊,这是免不了的。
当然只是把一些想法能够和大家有一个交流和沟通。嗯。我不知道这个这个咱就是大家有没有加入一些,就是我们的课程群之类的。如果有什么问题的话,可以随时在课程群里面提出来,我们再进一步的交流,好吧。🤧嗯。嗯。
如果没有什么其他问题的话,我们今天就到这儿好吗?当然刚才说了,如果你觉得还有问题的话,找一下。呃,我们的客服给他们要一些群,我们有很多群,我也不知道具体哪一个啊,但是哪一个好像都不是问题哈。
就是你只要把问题提出来,客服的同学会把这些问题转转给我,我们再一块进行讨论。好吧,如果有什么问题的话,我也可以加入到课程群里面去啊,这都不是问题,还是。呃,目标只有一个啊。
就是希望大家能够在学习的过程当中,咱能效率高一点啊,也就仅此而已是吧?好吧,如果还有问题的话,我们就讨论一下。如果没什么问题的话,我们今天就到这儿,好不好?


人工智能—机器学习公开课(七月在线出品) - P24:【公开课】时间序列分类实战:心电图疾病识别 - 七月在线-julyedu - BV1W5411n7fg
🎼。

各位同学,大家晚上好。好,我们稍等一下啊。我们这个8点钟准时开始。对,我们先请大家稍等一下。大家之前有了解过时间序列吗?以及呃有过的相关的一些了解嘛,也可以啊就是么说一下。嗯。
有很多同学之前可能是没有学过呃时间训练啊。当然这个你也不用担心,我们在客人中间呢也尽可能的会讲的比较简单的一些案例。然后给大家讲清楚这些具体的一些时间区里的一些相关的一些细节以及。他到底能够做什么?
大家之前学习过时间训练吗?嗯对,嗯,或者说有什么相关的一些嗯。学过相关的一些继忆学习的模型吗?也可以打字说一下。好,嗯,各位同学大家晚上好啊,然后我们马上开始我们今天的一个课程。
然后各位同学可以现在在我们的一个,如果顺利能看到我们的屏幕的同学再扣个一好不好?我们就马上开始我们今天晚上的一个课程。对。好。嗯,已经有几位同学啊已经扣1了,那么我们就。嗯,开始我们今天的一个课程。
其实时间序列呢其实它是一个嗯比较小众的一个嗯任务啊,时间序列。那么我们今天呢就是聚焦到我们的时间序列的一个分类上面。那么我特别是会给大家讲解一个实践的一个案例。
用心电图的一个疾病都是一起来完成一个分类的一个实战。我是嗯企业在线的刘老师。然后我们今天呢就开始我们的从现在开始我们的一个学习。嗯,大家如果没有加我们的杨老师的微信呢,就是我们的右上角的杨老师的微信呢。
可以加一下我我们的课程的讲义,以及我们的代码都会呃发给我们的杨老师。然后呢,大家可以从杨老师的这微信里面领取到。

那么我们今天呢会给大家讲什么呢?我们今天呢这个时间应该是在1小时到1。5小时。在这个时间内呢,我们向希望各位同学呢如果是。顺利听课的话呢,可以掌握一下知识。
第一个部分呢就是你会可以掌握到时间序列的一个定义以及它的一些应用。第二个呢就是时间序列的一个特征的一个提取。第三个呢就是时间序列的分类和模型和回归模型。
当然我们也会给大家讲一个医学的一个心电图的疾病识别的一个案例。我们就开始学习今天的一个课程内容。当然,如果各位同学在学的过程中有什么问题,有任何学习相关的问题。
都可以在我们的一个直播间里面进行一个啊就是说打字啊,就是说直接提问就行了。我们就开始我们今天的一个课程内容。我们首先呢来看第一部分就是时序的一个数据的一个介绍。对于我们的时间序列的数据呢。
其实它是非常非常常见的一一类型的数据。而且呢它也是我们在嗯数据挖掘的一个领域里面最为重要的一类数据。持续的一个训练呢其实是无处不在的。比如我们现在经济领域的这种嗯就是说走势,比如我们的股票走势。
黄金的价格走势,或者说房价的一个走势,对吧?然后呢我们的一个具体的一个在电商领域的一个具体的有我们的一个呃用户每天的一个浏览量。每每月的浏览量以及我们的PVUV的等等相关的对吧?
这些都是我们的一个具体的一个走势,其次呢我们在一些工业领域,我们有这个传感器的信号,传感器的信号,在我们的一个某个机器,它随着时间推移,它有一定的温度的记录,对吧?这个都是可以来进行一个记录的。
那么这个地方我们拿到这么多序列之后呢,其实。你你有没思考这个时间序列这些。数据之间它也没什么相似性呢,其实它是存在一些相似性的。或者说什么样的一个序列它可以称作时间序列。什么样的序列不能称作时间序列呢?
我们一般情况下,我们的时间序列的数据呢就是由两列所组成。一列是我们的TS,就是我们的time。M scan或者说这个具体的一个time。然后呢,一个value就是这个时时刻所对应的值。我们所写一下啊。
这时刻一,我们对应的值是1010刻二对应的值是11,10刻三,对应的值是12,以此类推。就如说我们的具体的一个数据集中,可能是有我们的一个多。行两列所构成的这种数据,对吧?那么这个地方时间序练呢?
他有一个特点,就是说一方面它是有时间的一个维度的。这个记录是有时间的。其实我们在呃学习这个数据挖掘的时候。数据挖掘对吧?我们数据挖掘datamin。或者说我们的一个具体的一个机器学习算法的时候。
我是能你。我是那你对吧?其实我们在学这些算法的时候,其实我们在学什么?我们本着在学一个具体的一个输入一个样本,然后需要得到一个具体的一个映射,需要得到这个关系,对吧?所以说呢我们在原始的一个数据集里面。
其实我们的样本是怎么进行组织的呢?我们仍然是把原始的数据据给它换一下啊。在我们的传统的这种结构化的数据集里面,我们的一个数据集呢是以这种。航。列这种二维的这种形式组织的,它是结构化的数据。结构化的数据。
那么这个结构化的数据有什么优点呢?它是一个非常规整的数据非常规整的数据就是说一行是一个样本。一列。是一个字段,或者说是一个特征。对吧这是我们的结构化数据非常典型的一个特点。但是这场结构化的数据集它。
并不是一个就是说。完上全全能够描述所有信息的这种形态。因为我们的这个地方的一个样本。每行。第一行第一个样本第二行第二个样本在我们的传统的结构化的数据群里面,其实我们是以这种样本的独立性。
或者是说我们是从某一个样本的一个。概率空间采样得到这些样本,对吧?所以说这这个呢我们原始的一个结构化的数据集呢,样本与样本之间是独立存在的。但是呢如果我们是在行与行的这个。纬度呢加入这个时间。
也就是说我们有这个。仍然是。写这种这种两列的形式。第一个时间第二个时间第三个时间第四个时间。然后我们在不同时间的情况下,我们采用得到不同的值,对吧?10111213。
那么这个地方我们能不能称这每行是一个样本呢?我们这个地方每行它是不是一个样本呢?它就不是一个样本。他就不能说单纯是一样的,因为这个地方整体是一个sequence,或者说中文里面我们就叫做一个序列。
对吧这是这些序列。那么这个是我们的一个时间序列。和传统结构化数据。和统结构化数据它的一个区别啊。对,一个是序列数据,一个是结构化的数据。大家一定要记住这个他们的区别。序列是带有这种时间戳的时间戳的。
而且它是有这种先后次序的关系的。这是第一个点。第二个点呢就是说序列呢它的这个时间都是等间隔的。一般情况下都是等间隔,就是说他时间。比如说12345。是这种等间隔的,他不一般情况下不会说是。10101万。
一般情况下不会这样,一般情况下是等间隔的。也就是说我们是按照某种某种固定的一个频率去采样我们的一个信息,对吧。好,这个呢是时间区列它的原始的数据集的特点啊,跟结构化的对比。
以及它的一个时间是一般情况是等间隔的啊,也就是一个等差处理。那么这个时间序列它到底用有什么用途呢?其实时间序列呢,它其实在我们的结构化的数据挖掘里面是用途非常多的。主要有两种用途。第一种呢。
通过分析我们的时间序列,我们可以知道我们的时间序列它内部的一个规律。比如说我们画一个时间序列啊。X轴是我们的一个时间。Y轴呢是我们的value。随着我们的时间推移,我们的一个具体的值呢。
有可能是按照某种形态进行一个。就是说取值的。好,这个地方呢我们再进行一个取值的情况下呢,我们第一个用务或者第一种用途,就是说我们能不能理解这个序列它内在的一个规律。这个区列有什么规律啊?
第一个它是有周期的。对吧这个地方很明显,这是有一个周期的。这是有一个周期的对吧?三个周期,而且呢我们的一个样本呢,在这个周期内,它是有分成一个上升的一个小周期和一个下降的周期,对吧?然后呢。
我们再可以知道我们的这一个具体的一个序列,它是整体的一个。峰值以及它的低谷的值是在什么样的一个范围内?嗯,有同学问到有没有回放?嗯,有的啊回放呢我们的代码。
PPT以及回放的都可以加一下我们的杨老师的微信啊,拿出手机扫一扫。或者说大家现在嗯拍照一下,或者截图一下就行了啊,加一下我们杨老师的微信,然后我们录屏啊、代码啊和PPT啊都是嗯给我们的杨老师的对。好。
我们继续。第一个用途就是说我们能不能挖掘出数据内内部的规律。就是说我们用一些。分析的方法去分析得到我们的这个序列它的周期。它的一个变化的趋势,变化的规律,以及它的变化的幅度和范围。对吧这是第一个用途。
第二个呢就是说我们利用这个时间序列呢,我们可以去预测未来的走势或者说监控。这个数据的走势。比如说我们很多时候呢就在做这样一件事,对吧?我们做天气预报的,我们在听天气预报的时候说什么呃。
未来一天北京市的一个温度在什么范围内,对吧?呃,或者说这个杭州它的温度,在什么范围内,那么这个地方呢,其实它就是给定了一个序列的情况下。我们去需去需要预测下一段时间的一个序列。他的取值。
也就是这是我们的训练集,这是我们的一个测试集,对吧?那么这个地方有可能我们给它的一个训练集。就是从编号为一到编号为100的100个数值。我们的测试集呢是从我们的编号101开始到105的5个点。
就是我们的训练级,就是我们的测试集,它是按照我们的一个时间进行划分的。预测就是说我们预测一下未来的一个走势。就是说我们做一个嗯就是股票价格的一个嗯预测,对吧?我们预测一下未来股票的一个价格是怎么走的。
其实呢我们做一个监控。监控呢这个其实在工业类型的一个场景下面非常非常。场景。监控呢就是说我们一个。机器它的一个性就是说温度。我把这个再擦一下啊。举个例子,我们一台机器。
假如说它的一个随着时间的运行时间的一个推移,它的一个温度。分票券。应该是就是说不断不断这种。上升的对吧?缓慢上升的。但是呢突然有一有一下呢,你的一个温度飙升的很高。假如说实际标准很高。
对吧这个其实就是有问题的,就相当于是它的温度,就相当于是一下。嗯,到了一个。您就是相当于是零界指了。那么我们作一个预计。基于预测的监控呢,就是说我们预测一下未来这个地方我们应该是这样走的。
对吧但是呢你的一个具体的一个实际的情况和我们的一个预测的情况相差太大。那么我们就可以。做一次报警对吧?说明啊我这个机器它的温度呢异常过高,对吧?
很多的一些工业类型的一个场景都是基于这种预测和监控的这种思路啊。所以说呢我们在工业的类型的一些大数据里面,其实很多都是基于时间序列的这种数据啊。好,我们继续。那么对于我们的一个时间序列呢。
我们是可以分分解成以下三项。第一项呢是我们的趋势项,第二项是我们季节项,或者是说我们的一个周期项啊,第三项是我们的残差分别是什么意思呢?嗯。
三项分别的一个就是说是从不同的一个角度去描述我们的一个序列的趋势呢,它是描述我们的长期的一个规律。就是说我们的这个序列,它在进行一个推移的过程中,它是不断的进行一个缓慢的上升的对吧?
周就是相当于是一个波动的上升的。那么这个地方我们的一个具体的一个周期。是什么呢?我们周期就相当于是它在近随着时间的推移,我们这个地方随着月份的一个推移,它是有的,这种从小变从大变小以及从小变大。
然后再由大变小这种相当于是这种。特定频率的一个规律的。那么残差是什么?残差就是我们在去掉我们的一个趋势和季节之后的一个随机的波动。你这个一忘的残差,你可以理解它就是一个噪音,是你可以理解它就是噪音。
那么这个地方我们的一个趋趋势和季节是我们的持续数据里面最最重要的两项。趋势这个地方我们的一个橙色的这条线,就是反映的是我们整体的一个趋势。对吧这个黑色的线是实际的这个序列的一个波动情况。
但是呢它整体的趋势应该是一个。上升的对吧?整体的趋势是上升的。当然这个序列里面其实也是包含了一定的周期的对吧?一定有周期的项好。那么我们就继续啊我们的一个时序,我们是可以任意任意的一个序列。
我们是可以把它进行一个分解的啊分解的。那么我们在进行一个具体的一个分解的过程中呢,其实我们还可以根据我们的一个趋势,我们的周呃这种季节和我们的残差来构建。
就是说这三者构建一些对应的一些实间序列的一个组合模型。呃,这个组合模型呢其实也是非常简单的非常简单的。我们常见的呢就是一个加法模型和一个乘法模型。
加法模型呢它比较适合用在我们的一个季节和残差与趋势无关的情况下。也就是如右图所示啊,这个地方稍微挡挡住了一点,但是整体的是这样的啊。我们可以看到这个地方我们是可以用一条直线去理合得到的。
这个地方的直线呢就是我们的一个trend。整体的趋势下。那么在这个趋势的过程中呢,我们可以看到这里面还有一些波动,对吧?就是说我们的一个。这种季节项季节项。然后在波动的过程中,有一些点它可能是。
不那么有规律,那么就是我们的一个残差,对吧?所以说这个第一个情况是我们的季节项和残渣项,和我们的趋势无关的时候,也就是说这两者的一个具体的取值和我们的趋势是没有关系的。
不管我们的一个最终的一个趋势是如何进行变化的。我们的一个季节性化参差项,整体的大小是和它无关的。那么如果是这种情况,我们就可以用加法模型去描述。也就是我们的一个最终的一个。取值是由我们的趋势项。
加上我们的一个季节项,再加上我们的残量项。如果我们的一个。嗯,这个地方呢是沉几啊。打错了。如果你发现我们的一个具体的一个趋势项。和我们的一个周期或者季节是有存在这种乘法的模型。
或者是或者说他们并不是缺势无关的时候,那么你就可以考虑这种乘法模型。乘法模型是什么意思呢?我们先把这个具体图标里面的一个趋势项给它画出来,这是我们的一个趋势。那么我们在这个趋势里面呢。
我们还发现它有这种季节性,就是这种。周期的波动对吧?周期的波动,但是你会发现这个波动呢一个越来越大越来越大,它并不是随着我们的一个就是说。跟我们的趋势无关的。那么在这种情况下呢。
他一般情况下可以用这种乘法模型,就是说两者进行相乘。这是什么意思呢?当你的边当你的一个趋势变得越来越大的情况下,你的一个周期也会它的一个变化的幅度也会越来越大,对吧?所以说这是不同的一个时间序列。
它的形态。然后我们就是可以选择它到底是用加法模型还是这种乘法模型。好,那么我们继续啊这个地方嗯需要注意的就是我们第一第一第一部分呢其实给大家介绍一下时间序列的一个介绍,以及如何把它做一个就是具体的分解。
它是由chanend以及sn以及我们的残差三者进行组成的。然后我们有加合模型成法模型。当然如果嗯有同学想深入学习这个时间序列啊,这这个地方其实也有很多的一些教程啊。嗯。
可能嗯在本科或者说硕士呢有这种时间序列的分析。就是这种time series的ana。嗯,这些一系列的书呢都是就是中文翻译叫时间序列分析啊,然后呢有很多的一些教材都可以深入去学。但是呢其实。
如果你是呃想要做一个呃时间序列的一个呃,就是说这种从业者。嗯,现在没必要去读这些教材。嗯,为什么呢?因为这些教材啊,这些教材它大部分都是偏理论的。就是现在中文呢你可以去找时间序列的分析。这在中文上面。
不管你是在任意的电商平台上面,都可以找到类似的这种教材。但是呢这种教材它一般情况下都是偏统计的。就是说。及原理级别的。统计相关的。书,但是这个书其实并不特别适合。这种计算机的同学去学。
或者说并不一定适合我们这个。数据化结后或者说这种算法的同学去学,为什么呢?因为这种时间序列分析,它的一些这种教材呢,一般情况下都会讲,我们如何去判断一下这个是序列是不是稳定的,如何去分解这个序列。
以及如何去。就是说。得到这个血液的相关性质。嗯,但是呢其实我们日常生活中呢,我们并不会过于去追究这个序列内部的一些。就是说规律我们可能是需要对他进行一个礼合。我们如果是想要对它进行礼盒呢。
就是说我们有一个模型。我们输入的数据就行了,对吧?输入我们的X,然后得到我们的Y就行了。然后呢,这个其实是我们现在的这种数据挖掘的这种思路。我们不需要去考虑这个数据,它原本的规律是什么。
我们就是用一个模型去理合它就行。嗯,其实这是两种学习路线啊。第一种你就是学这个时时间序列的非常底层的一步一步学习。第二种呢就是说以这种积极学习的思路去学习时间序列,我们就直接。
去尝试用这种机极学习的模型来做。那么如果是想要用机学习的模型来做。这种玄序的分类啊回归啊,其实就会遇到一个问题。我们原有的一个数据呢,其实是这种形式的。对吧我们的原来的序列是按照时间的一个推移。
它是1011、12、13、14。假如是这种形态。这个其实是一个样的,纤为是这个。是一个样本。那么我们都知道这个样本呢,它的一个维度并不一定是。规整的。也就是说这个样本它有5条记录。
那么下面一个时续的样本呢,它可能有1条记录。就是说我们的不同样本,它的一个长度有可能是不规整的。对吧它的长度有可能是不规整的。但是呢在这个不规式不规整的情况下。我们能不能直接把它送到你的模型进行建模呢?
其实就不一定能够直接送到你模型进行建模。因为我们的一个具体的一个机忆学习的模型呢,它输入的样本的维度是要相同的。也就是我们的一个现在的记忆模型。他输入的样本的维度是要相等的。
也就是说所有的样本要不都是10位的,要不都是20位的。但不能就是说输入的样本的维度不等,这个肯定不行,对吧?所以说我们假如说想要对一个序列做一些操,就是说想要直接把它送到继续的模型。
那么就需要对他做一些特征工程。那么我们就开始第二部分时间序列的特征工程。那么对于时间序练呢,其实我们可以对他提取很多的信息啊。很多的信息。那么。我们仍然是把原始的图给它画一下。
X轴是我们的一个具体的一个时间。Y轴是我们的一个随着时间推移的取值。我们在进行提取的时候呢,首先可以提取什么?我们可以提取出。这个时间他的一些信息。对吧这个时间。这是它的一个确定式一个时间。
这个count呢就是我们的value。其实原始的就这两页。对吧原始就这两个例。那么我们现在现在呢可以从中提取得到什么呢?我们可以从中提取到以下一些信息。比如我们可以提取得到我们的一个具体的一个年份。
我们的一个月份,我们的天以及我们的具体的一个。新期数这个新期数呢就是说在这个月我们的一个具体的一个所就是说这一天所形的是这第一周啊,还是第二周还是第几周,对吧?
这个就是说我们的一个具体的一个一些特性都可以提取到。当然我们也可以提取到,就是说当在他具体的一个是周一啊,周二啊,还是周几,对吧?这个都是可以提取不到的。所以说呢在我们的一个具体的一个建模的过程中呢。
我们基基本上都可以将我们的一个时间,特别是我们的日期啊把它提取出来。这些预常的信息。然后呢,我们还可以根据这个时间可以提取,就是说它到底是小时啊,以及它的一个分工数啊,对吧?
以及他嗯就是说是这一天开始的多少分钟啊,以及距离这一天结束,它是有多少分钟,对吧?所以说我们在进行一个统计的时候,你们其实都是可以提取的这些信息的。那么比较完整的呢,就是可以看右边这个图。
对于我们python里面的这种date time格式呢,我们可以提取非常多的一些信息。比如说它的连月日分钟秒毫秒,以及它的一个就是说这种reday,就是到底是周几以及第几第几个月第几个周,对吧?
这个都是我们在这个python的一个date time的这个模块可以提取得到的。好,这是第一个跟我们的时续特征相关的一个特征,就是说直接跟日期相关的。第二个呢就是我们可以根据我们的一个取值。
就是我们的value来做。第一类呢是做我们的一个滞后特征。滞后特征呢就是说我们在进行一个嗯做特征的时候呢。我们是可以做一个叫做neag feature。
nake featurelike fish呢其实我们可以看右边这个图啊。neagfi呢就是本质,就是说我们将历史的一个数据当做当前的一个特征。什么意思呢?我们在进行一个构建模型的时候。
假如说原始的一个数据集是我们的基于d time和count。这样的两列的数据。那么我们在进行一个具体的一个嗯编码的过程中呢,我们其实是可以这样做一个操作。我们n个一呢就是说是以上一个点的一个取值。
上一个点Y的取值作为我们的一个特征。这地方上一个点。上一个时刻值值是8。🤧对吧。那么这个地方。那比一。上一个取值是二对吧?leg2就是上上个取值,对吧?是8,以此类推。
那么这个leg feature是什么意思呢?就是说我们把不同时刻的一个。之前不同时刻的一个点,把它当做当前时刻的取值。这个其实是有点类似于这种嗯窗口的这种思路啊,所是我们的一个窗口呢。
它不断的进行一个滑动。然后呢,在滑动过程中呢,我们在就使用历史的窗口的一个去取值啊,作为我们当前的这个特征的一个就当前时刻的一个特征。这个叫做m feature,叫做一个滞后特征。
第二个呢就我们的一个滑动窗口或者说滚动窗口的这个聚合特征。这个是什么意思呢?在我们进行一个具体的一个嗯。对于时间序列进行一个提取特征的时候呢,就说我们也可以考虑。
对我们的数据集呢按照某个窗口来进行一个提取一个平均值。对吧这个平均值呢我们是可以嗯按照这样的思路来看的。我们有一个窗口,就是这个窗口呢扫去扫一下我们的一个具体的一个valueue的一个取值。然后呢。
假设我们的窗口的大小是7的情况下,我们就统计一下这个窗口下面的一个valueue,它的一个具体的平均值是多少。或者说这个这个窗口下面的一个最大值,这个相关的都少,这个都是我们可以继取到。
待会呢我们也会用代码来进行一个具体的一个操作啊,大家不用担心。我们有了这个持续的一个特征呢,我们还可以做什么呢?嗯不仅仅是可以就是说嗯直接抽取得到我们当前的一些日期的信息。我们还可以做这样一些操作。
比如说我们可以不仅仅是可以统计它的年月日啊,季度啊小时等等,对吧?这些都是非常基础的,我们还可以做什么呢?我们还可以提取一下它到底是不是节假日啊,以及于最近节假日的间隔啊,以及这个它的一个是上午啊。
早上啊还是晚上啊。以及它的一个是不是高峰时间,这些都是可以来进行一个提取的。其次呢我们还可以做一些对比,对吧?对比什么呢?这个对比就是说它跟同期的值的相差多少。也就是说我们的一个时间序列啊。
它并不是说是完全完安全全,只能是。就是说跟当前值或者说往届的值做的比。也就是说我们可以对于训练的,我们假如说是可以把它画成。多个周期的把它画成一个图里面。
这个地方呢就是说是前面一个周期的一个图和我们当前周期的一个具体取值。我们我们都可以把它画在这个图里面。画出来之后呢,我们可以做什么呢?就是说我们可以比一下这个值跟它。
就是说上一个周期的一个值的一个比较是什么?比较直接的一个思路,就是说假如说我们想比较一下,我们想就是说对我们当前,比如说现在是晚上8点半,对吧?我们想要记录一下8点半的一个取值。
那么我们可以有一个很好的思路,就是说我们对比一下昨天8点半的,就是说这个序列,昨天8点半的时间下面情况下,这个取值取值是多少?对吧或者说我们上个月8点半对吧?这个具体取值是多少?我们做一个相减。
或者是说相比,这个都是非常常见的。对,然后呢我们在进行一个具体的一个编码的过程中呢,这些都是可以就是说按照我们的一个具体的一个。就是中位数啊,也可以按照我们的风度啊这些具体的操作的。对嗯。
我们的校长也说了,我们在这个具体的一个呃,我们正好这一部分就讲完了。对,然后呢我们在完开始我们的这部分呢开始之前呢,大家也可以嗯参与我们的一个呃抽奖活动啊。
就是在我们的一个弹幕区里面打出AI就是大写的大写的AI然后呢前5名同学,然后送我们这个企业在线的一个VIP的月卡,应该是我们VIP月卡。然后VIP的月卡里面,也是包含100100多门AI小课。嗯。
大家如果想要领取我们的月卡呢,可以在我们的一个弹幕群里面进行打AI这两个啊,就是发一下。好,大家如果想领取我们的月卡的同学呢,可以领一下,这个直接是可以领的啊。好。
那么我们接下来呢我就先对我们的刚才所讲的这些内容呢,先用代码来进行实践一下,好不好?那么在对于我们的一个时间序列呢,其实在实践的过程中呢,也并不是说是特别难啊。对于我们的时间序练呢,其实你在学的时候。
你可以直接用我们的一个呃这个就是。嗯。on的一些环境的实践都是足够的。我们首先呢这个地方我们首先呢对我们的一个序列呢,我们导入一些相关的模型,比如说tic model对。
然后呢我们的然后呢嗯导入我们的是做我们的画图的对吧?好,我们来看一看今天我们的第一波抽奖是哦哪几位同学啊,第一波抽奖,我们的lever never most sF同学以及M0。嗯。
我们的96598同学啊,我截一下图啊。然后这几位同学呢可以待会儿去加一下我们的杨老师杨老师的微信啊,我看一下。对。等一下,我把这个截图找一下。然后这几位同学一定要去加我们杨老师的微信啊。对,嗯。
这试呃这是第一位同学第二位、第三位、第四位第五位。对,就是这5位同学。大家可以这5位同学呢可以加一下我们的杨老师的微信啊,然后就是领取一下我们的月卡啊,这是我们的第一波抽奖。对。
我们待会呢也会有我们的抽奖。这几位同学啊,这5位同学。好,嗯,我们杨老师的微信呢就是这个啊,大家拿出手机微信扫一下,或者说先截图。嗯嗯待会儿听完课再扫也都可以啊,也都可以。好。
那么我们就继续我们的一个代码讲解啊。嗯,我打不我怎么打不上,嗯,你应该是打的比较。嗯,怎么打不上是加不上吗?加不上,应该是你待会儿再就是说你先先加啊,待会儿我们杨老师同意就行了。对,反正加的人比较多。
好,我们继续啊,我们首先呢创建一个time的这个呃就是说一个airry,就是说从嗯这个从1到50的这个取值。然后呢,对我们time呢,我们乘以1个2。75。乘以1个275得到我们的train。
这train就是我们的取值取值。然后我们可以绘制得到我们的这样一个散点图,对吧?一个pl绘制到我们的一个散点图。然后呢,我们可以看到这个地方它就是一个非常规整的一个直线。
这个直线就是一个具体的一个我们的一个取值是从对吧?1到50。然后我们的对应的取值就是对应的取值乘以1个2。75,对吧?然后呢,我们在这个取值的过程中呢,我们也可以。构建一些其他的周期,对对吧?
比如说我们对于我们的time呢,把它对应取一个余弦。取正选,然后呢乘以个10,然后再加20,对吧?这个呢就是我们的一个具体的一个带有周期项的我们的一个序列。这个就是我们的一个这这个是我们的一个趋势。
这个是我们的一个周期,对吧?明显的一个周期。当然如果你想要产生一个就是说只有我们的一个残差的东西,产就只有。产生这个残差量的同学啊,就可以直接是生成一个随机数。比如说随机数呢。
就是从我们的零到我们的一个一。就是说从我们的一个呃固定住我们的随机种子之后呢,然后产生一个质能分布的一个随机数。这个随机数呢,它可能的范围并不是从0到1的,应该是从负2点几到正二点几之间的。
那么它总共产生了应该也是50个随机数。好,这是我们的一个三个部分啊,趋势周期和残差。然后呢,我们接下来根据我们的所称我们刚才所生成的这个趋势周期和残差,能够,然后呢可以生成一系列的模型。
比如说我们将我们的一个趋势周期和残差加起来,然后就可以得到我们的加法模型,对吧?就是在我们的PPT里面也看到了。其次呢,如果我们将我们的一个趋势周期和产差进行相乘,我们就可以得到我们的乘法模型。
对吧这个在我们的一个具体的1个PPT里面也有讲到,就是说它产生的一个过程,本质就和我们的一个具体的一个形态是完全相关的。那么有同学可能就会问到。老师,当我们就是说给定了一个序列的时候,如果我们。
就是说不知道它原有的这个嗯趋势,也不知道它原有的这个周期的情况下,我们如何对它进行一个分解呢?嗯,或者说如何对它进行识别呢?这个其实也有一些嗯对应的一些方法。
我们这个地方呢是可以从这个stattics model里面inport我们的一个season de,就是说相当于是一个持续的分解的这个啊函数。在这个实际分解的函数里面呢,我们就可以直接传入一个。
具体的一个序列。这个地方我们传入的是一个加法的,就是说我们的一个。顺子。再加上我们的C的。这加上我们的残差,这就是我们的应用加法,对吧?得到的我们的一个取值。然后呢,我们通过一个加法模型去做一个分解。
那么这个呢就是说这个其实是ttic model,它所提供的这种分解的这个函数。这个分解函数呢,其实它内部的计算呢,它会通过去拟合我们的一个具体的一个序列它的周期。
然后去将我们的原有的这个序列去分解知到它的一个趋势周期以及参照项。这个是我们的这个statistics model,它可以整解得到的。也就是说,如果你识别得到我们的一个具体的一个趋势。啊,sorry啊。
如果你识别得到我们的这个曲线,它是以这种加el模型。那么你可以用ttics model直接把它分解成我们的一个趋势周期和参差,这个是直接可以分解的啊。对,直接就可以分解的。好。
那么如果你想要知道这个具体怎么分解的呢,这个地方稍微讲深入一点啊。这个分解的过程,其实它就会去计算这个我们的一个序列,它的一个周期。对。相当于是我们在做一个分解的时候呢,其实本质就是需要计算我们的这个。
周期趋势和残差对吧?我们当我们把趋势和周期都计算出来之后,我们这个残差就很好计算。那么这个趋势趋势呢这个。你可以理解,就是说随着时间推移,它整体的一个均值是如何。是如何的对吧?
我们的一个原始的曲线往下翻。他随着时间的推移,它的均值。对吧整体的一个均值,它是实相当于是在这个范时间范围内,它整体的一个波动的一个幅度是没有什么变化。那么我们就可以用这个窗口类的一个均值去替代。
它的整体的一个趋势项。那么我们的周期呢就相当于是我们去减去了我们的趋势项之后,然后去分解它具体的一个周期的一个情况。然后这两项都有之后呢,然后就可以找到它的具体的一个残差项。好。嗯,叠加吗?
老板这个地方是一个加法模型啊,这个地方我们刚才也讲了,它是一个就是说我们传入一个加法的一个这个地方ag a数据就是我们最开始这个地方加法得到的。对吧这个地方是我们加法得到的一个嗯序列。然后呢。
我们再用这个t model这个库去做一个分解。对。然后我们接下来就是说我们对于我们的乘法的一个序列。存法模型就是说我们对我们的train和我们的一个。具体的一个。季节和我们残渣三者进行相乘等等的序列。
我们也可以用这个t提示mod进行分解。只不过这个地方呢需要手动设置一下,就是说具体用成长模型去做一个分解,对吧?分解的到的就是我们的整体的是也有我们的一个趋势。周期和参品差对吧?
那么这个也是识别的非常准确,对吧?我们的趋势周期和参差。那么如果想要提取我们的一个序列的一个。日期相关的特征呢,这个也是非常简单的也非常简单,对吧?我们如果是使用pandas呢。
我们就直接是使用这个pindas的一个date timed time将我们的一个具体的一个时间呢,把它转成d time的格式。
然后呢就可以提取这个d time的一个具体的一个ear months和 day对吧?以及de week对吧?这个直接是从padas就可以完成我们的一个计算的。其次呢如果想要提取它的时间,对吧?
our minutes这个也是很方便的。好。那么如果想提取它的一个leg特征,对吧?这个其实。就稍微有一点的难度。那个t是什么意思呢?我们刚才也给大家讲了啊。也就是说在我们的一个具体的一个序练里面呢。
他就是这样一个对应关系。上一时刻呢是作为下一时刻的值。对吧上一时刻的一个相当于是它的一个取值,是下一个时刻的一个特征。对吧相当于是这是L一,就相当于是间隔一个时刻,间隔一个时刻。
那么如果我们想要做这个就是leg多个的话,其实也是很简很简单。就是说我们直接用pennda shift shift呢这个地方我们传入的一呢就是相当于是间隔一个单位,一个时间单位。这个地方其实是这样的啊。
leg一。好,我们可以看到这个地方就在这儿。那个二对吧?这个地方。啊L3L4leg5。like6like7对吧?这是我们的这种滞后的特征,也现在是按照某种时间的一个单位间隔。
把历史的一个取值当做当前的一个样本的一个特征。这个就是我们在提取这个时间序列的时候呢,可以用这个这些相关的一些模型来提取特征的,都是非常有效的。当然呢我们也可以做一个这种滑动。
或者我们的滚动的一个窗口啊,这个窗口呢我们这个地方用paas的rolling rollinging的函数。这个rolling呢我们的window设置为7。这是什么意思呢?就是说你们统计一下。
具体的一个窗口范围内,也就是说在这个窗口范围内。它的一个平均值。这几批位数。他的一个平均值是的就计算知道。这个这是平行值。然后呢,我们这下面呢就是说我们的窗口呢会滑到这个位置。然后呢。
再计算一下这7位数的一个平均值,然后换算为这个。对吧所以说这个地方其实它的一个window的意思就是说是这个窗口的一个大小啊,我们统计一下这个窗口的大小,然后就算一个平均值。对。那么我们继续啊我们继续。
那么还有一类呢,就是我们的一个嗯这当于是一个。啊这种整体的这个expandendingexending是什么意思呢?就是说我们在进行一个具体一个计算的过程中呢,我们就是在进行计算的过程中呢。
我们整体算一下,等于是它一个叠加的或者说累计的这种窗口。这个窗口呢我们是设置的是相当于是一个二啊是一个2。然后呢我们再进行一个具体的一个嗯。这个迭代过程中是什么意思呢?我们这个一个pening。
它的一个窗口现在于是二是一个最小的窗口。8。它是只有一个取值,就是说一个取值的时候,它是小于我们的一个窗口的对吧?小于窗口2,那么他不做一个统计。那么这个地方如果窗口是满足我们的要求的时候。
做一个平均值求命。8加2对吧?等于5,然后在这个的时候。8加2加6除以3等于5。33。嗯以此类推,8加2加6加2除以4。不断取平均值,那么这个值是什么意思?就是说这个序列它累加的一个平均值。
累计的一个平均值。这个话我们在paice里面呢也可以很方便的对它进行一个计算啊。那么我们再回到PPT啊。我们第三部分呢我们就看一看对于时间序列呢,我们有哪些分类模型或哪些回归模型。呃。
有没有同学知道分类和回归的具体的区别是什么?有没有同学知道的?对。然后如果知道的话呢,也可以在我们的一个直播间里面打字啊,就是说啊就是回答一下啊。呃,分类呢就是说我们给另一个序列呢。
我们需要划分得到它具体的一个类比。呃,就是说我们给另一个序列。这是人类序列。这是第二类序列,对吧?这一类序列呢,假如说我们把它划分成了A序列。这一类序列呢我们把它划分成B序列。就是一个序列分类。
就是我们给进序列把它划分到一个具体的类别里面。那么对于这个呢,其实呃它本质上也就是一个分类任务,对吧?分类任务。那么这个分类任务呢,它并不一定是很简单的。嗯,为什么呢?因为对于这个分类任务呢,我们是。
这个地方输入的一个序是一个序列。它是一个序列,也就是说我们这个序列呢。比如说我们输入的一个X。它是一个序列的时候呢。持区目前只有趋势残渣和周期三种,就是它的组成啊,基础的同学可以把它把它拆分成这个。然。
就是从趋势财务转化周期。这三三种组成。对。一般情况下是这样做一个分解的。它的组成是这样的。然后呢。你根据这个就是说。它的一个具体趋势,具体的一个残差,以及它的一个周期不同。
它的一个时间序列呢是千变万化的。并不是所有的序列,它的一个趋势是不变的嘛,也并不是所有的趋势,就是说序列它的周期也是不变的。不是的,现实生活中呢,很多情况下我们的一个。周期趋势和采查都会不断的推移。
不断的改变。我举一个非常简单的一个例子啊,就是说我们的现在呢一年我们的一个一年四季的温度。其实假如说我们的Y轴是我们的温度。我们的温度其实随着时间推移,对吧?我们的一个春天是比较低的,然后夏天。
对吧然后我们的一个秋天,然后我们的冬天对吧?这是一年,对吧?然后呢。我们如此反复如此反复,但是呢随着我们现在不是有温室效应吗?让我们的一年的温度比一年高。吧一年比一年高。然后呢。
我们还有一一些具体的一些时间呢,他可能就是说。不是说一年比一年高,有可能在在某一年遇到了,比如说夏天它的温度没有往年高。对吧然后呢又比之前高。这种是可能的这是什么是可行的。
就是说我们的一个具体的一个时习训练呢,它的一个变化的过程并不是说。只有。这种。就是说它的一个趋势上并不是说是一定是不不断就是相当于是上升的,它有可能是在中间有一些其他的一些波动啊,这个都是有可能。好。
嗯,这个就是额外的啊。然后呢,对于一个时间序列,它其实是一想要对它进行分类呢,其实是一件非常困难的事情。为什么呢?对于我们的样本,假如说对于一个样本,它有假如说是。50个。值50个值。
就相当于是50个点。那么相当于是从T1到T50。对吧T1到T50,然后呢,这50个值我们假如说一个样本。你样本是50个折。那么我们对于这种情况呢,我们另一个样本。也是有50个值,对吧?
我们现现在呢需要对它进行一个分类。假如说这个是我们的一个具体的一个。区离A类别就是区类B。那么我们如何对它进行划分呢?其实是需要一定的一些方法的。
第一种的方法就是说我们可以做一个基于序列的一个距离来做一个计算。就是说。我们有了一堆去了A。有了一堆蓄的币。我们接下来有了一个新的序列。我们需要对他进行判别,它到底是序列A啊,还是序列B?怎么做呢?
你算一算这个序列跟我们的一个A和B之间它的一个。就是说到底相似度是怎么样的,这个这个就是做一个序的距离。序的距离。这序的距离呢,我们一般情况下可以从欧式距离和DCW做。嗯,股票预测准确怎么样?
股票股票应该是不能预测的。股票是不能预测。对,我们在做一个时间序列的一个就是预测的时候呢,我们一般情况下会对它的一个稳定性,以及是不是有周期性做一个分析。现在的一个嗯股票呢可能并不是说是直接做预测。
很们可能是。嗯,你可以去看一下量化的,他可能就是做一些买入买出的一个实际的判断。他可能并不是说直接预测一下股票的一个未来的趋势啊,并不是这么简单。好,我们继续啊。然后呢。
第一种方法就是说我们是基于序列的,就是说给另一个序列,我们去算一下它跟A序列的一个距离,以及B序列的一个距离。然后呢去看一看。如果是它跟A的距离比较短的话,比如说跟A比较相近的话,我们就选择。
把它复值为A,对吧?这是第一种方法。第二种方法呢就是说我们对于时间序列的一个轨迹呢,把它进行一个统计一下特征。彩票是不是也不能预算彩票的话应该也不不能啊。彩票彩票也不能,对吧?我们现在是。呃。
法制社会对吧?法制社会,然后我们是相信科学的对吧?这个应该都是一个随机产生的啊随机产生的。还是一个有放回的一个随机的啊,有放回的一个随机的组合,所以说也是不能的。可以预测吧。嗯,这个我暂时暂时。呃。
觉得彩票不能预到。如果你觉得能预测的话,你可以多买一下彩票啊啊然后试验一下你的模型,看看你能不能中奖。应该是不能预测的啊。现在很多像市面上的一些预测模型,彩票预测模型都是基于什么尾数规律啊。
其实它都是不可靠的啊,都是不可靠的。对。嗯,方法二就是说基于这种呃就是说我们的一个嗯持续的一个特征。就是说对于一个时间序列啊。我们是可以提取它的一些特征的。比如说这个序列它的一个波动。
我们可以用方差进行衡量。它的一个整体的一个趋势,我们可以用均值衡量,对吧?它的一个相当于是嗯相邻点的一个波动情况。我们可以用它的一个相邻点的一个DF值来做一个衡量,对吧?
这个系相当于是我们用一些统计值去提取一些原始的一个序列的特征,然后再构建一个分类模型,这个也是可以的,这个也是可以的,就相当于是这种是机学习的方法,提取特征,然后分类模型。如果是深度选习的方法呢。
就是说我们直接是将序列把它输入到深度学习的模型里面。这个地方呢我们用卷积升经网络ED的卷积来进行体取特征,然后用全连接的网络做我们的一个分类的模型,对吧?这个是我们的一个基于这种持续分类的啊。
那么我们现在呢可能是方宝三,它的精度是最好的啊。方宝三精度是最好的。好。第二个呢是我们的回归模型。回归模型呢这个不是我们今天所讲的重点啊,我们就就是把这个稍微说讲简单一点。有四种方法。
我个人评认的比较多的啊。第一种是滑动平均。滑动平均呢就是我们利用历史的值去构建一个先相当于是一个新先进回归来得到我们的未来的值,或者说用我们的二维码,或者说我们的profit。
或者说用我们的深度学习端落端的模型来做一个回归。这个地方呢一个回归呢,其实呃深度学习的一个这种实际回归要我就持续预测它就比较比较复杂。为什么复杂呢?我们再进行一个。具体的一个预测的过程中啊。
我们在进行一个预测的过程中呢,为什么为什么说回归?他比较复杂呢。我们这个地方我们不仅仅是需要预测未来一个点,我们有可能是需要预测未来的多个点。对吧就相当于是我们假如说需要预测未来的4个点。四个点。
那么假如说我们在进行一个具体的一个预测的过程中呢。我们如果是想用深度学行,我们怎么做呢?对,这个地方就是说我们可能是需要基于这种sequence去于sequence的这种机制。经有同学说到了啊。
长短STM和profit比较近。对,现在profit现在是应该是用到的比较多的。现在profi应该是用的比较多的,它是facebook所提出的一个持续回归的一个模型。如果是纯深度学习呢。
就是sequence tos,就是说我们给进一个序列。然后预测下一个序列。今在是我们给定100个做我们的训练集,然后mter下20个,这就是一种sd to sequence的这种格式。
那我们可以给大家进行一个演示啊,我也给大家准备了一个代码。我们这个地方呢是用这个。gg TS这个功呢其实它是基于MXnetMXnet的一个。高层的一个持续的一个。呃,就是说嗯就这个回归模型啊。
我们从那个公用TS里面呢,inport我们D部AR。dAR呢是基于深度学习的一个RN的一个回归的这种预测模型啊。我们这个地方呢就是利用我们这个给定的一个序列。
然后呢用它的最后的60个点做我们测试集来做一个回归预测啊。那么这个地方如果用DPAR,我们这个地方直接设置一下,我们需要训练10个。然后我们可以看一下。这个前面的点前面的这个序列是我们的一个训练级的。
然后后面的这个是我们的一个预测得到的啊,这个预测得到的为什么是有个范围呢?大家可以看一下,这个地方是有一个实心的,这个实心的线是它真实的一个标签。真实的标签,这个这个绿色的一个范围。
就是它是一个置信度啊,置撑区间。进行区间啊就相当于是它的一个有一个预测的一个,等于是上界和下界。然后我们可以看到这个模型整体的一个预算的一个结果啊。
整体的预测结果和我们的实际值的一个范围其实是比较一致的。然后呢,如果你就是用profi也可以得到类似的结果啊,profit也可以得到类似的结果。但是呢我现在用我个人用国用TS这个库会多一些。
因为国用TS这个库呢,其实现在它是包含了很多的一些模型的啊。我可以给大家搜一下这个库啊。这个库其实现在应该是用到的比较,就是说就是说应该是用的比较多的一个库。而且呢它里面包含的模型应该是比较多的啊。
我们看一下。在这个介绍页面应该是有的。他是支持装飞机。对。这个裤子是可以直接就是相当于是套娃的这种形式啊,还可以直接支持这个pro。然后这里面还是支持其他模型的。比如说我们的一个。
Second two seconds。或者基于这种春酸嘛的。对,这公用TS这里面都有。然后呢,现在对于我们的这个从业者而言,其实。我们并不是说完完全全去自己实现的模型,可能还是用这些库会比较多一些。
所以说这个地方就需要大家就是对这些库啊。可能是有一定了解啊有一定了解。当然如果你是啊就是初击者啊,你可以先了解一下这边有哪些库啊,然后再去啊做一个就是实际的学习啊。🤧嗯,好。我们继续。好。
然后我们再做第二波抽奖好不好?然后呢,我们这个今天所讲的一些内容呢都是非常非常基础的啊。然后呢,我们第二波抽第二波抽奖呢也是抽我们的一个契约在线的1个AI的一个会员啊,我们其约在线的1个AI的会员。
然后呢大家可以在我们的一个。就是直播间呢打入我们的1个AI。对,然后呢我们的首先打入AI的这5位同学呢可以送我们的月卡啊,我们的月卡我们的月卡是在7约在线上面可以免费。
就是说学习100多门的AI小课的这个就是说这个会员啊。对。扫不到二维码啊,这个地方应该是可以扫到吧,你可以截图截图一下啊,截图一下。截图一下,待会扫可以也可以啊。好,我们来看一看是哪几位同学啊。
我截一下图。好,嗯,我们看一看是哪几位同学啊,我们第二波的。我们第二波呢是这几位同学。呃,我们的思言同学penccer820同学AGH同学M0同学以及我们的1个QQ353599056同学,这几位同学啊。
好。二维二维码上半身被挡住的。哦,这样。等一下啊。

嗯。这样可以吗?这样可以扫到吗?这样大家可以先截一下图,这样应该是没有挡住啊。这是没挡住吧。对,然后大家如果是没有加加我们杨老师的微信啊,可以加一下。因为我们的这个讲义啊,以及我们的代码。
以及大家刚才所获奖的一些同学啊,你的领取的这个呃奖品的方式啊,都是从我们杨老师这儿获取的啊。对,大个现在可以截一下图啊,然后或者说直接加一下我们杨老师的微信。那么我们继续啊我们继续。
所以现在应该都加上了啊。好。嗯。然后呢,我们继续啊,我们再看第三部分,我们第三部分呢我们就是做一个心电图的一个级别的一个识别的挑战,也是一个分类的问题啊,也是一个持续的一个分类的问题。
我们的一个问题背景就是说嗯心电图呢其实它的一个问题就是说它本身就是我们日常的一个心脏脉搏,相当于它的一个起跳的一个呃诊断的一个指标。但是呢心电图其实我们在具体的一个去医院体检的时候呢,其实我们是。
需要我们的一个虽然是一个医生去对我们的一个具体的一个。啊,就相当于是这个心电图去做一个识别,做一个精行测,做一个分类。但是呢我们现在呢。
我们能不能去人工去确定去构建一个模型来帮助我们的帮助我们这个心电图做一个分类呢。其实是可以做这样一个尝试的。也就是说我们是输入我们的一个心电图的数据,然后呢去构建一个经济学习模型。
然后去做我们的一个分类的模这种尝试。这个尝试呢就是说我们去识别一下这个心电图的到底是不是正常的,或者说是不是异常的。对,我们就是做这样一个挑战啊,做这样一个挑战。好,那么我们做这样一挑战我们怎么做呢?
我们其实本质就是需要输入我们的这心电图的数据,然后构建一个分类模型。对吧好,我们来看一看啊。那么我们怎么做呢?其实这个地方。我们首先呢来看一看,这样读取一下我们的数据啊。读一下我们的数据。
我们数据型呢其实本质我们就是用依然依然是用n派和我们的一个padas可以读取啊。我们可以对我们的数据集呢把读取进来,其实本质上涨的就是这样的啊。这个地方我们的每一行是我们的一个序列。每一行是我们的序列。
然后呢,每一列呢相当于是是一个10克的啊,每一列是一个10克的。这个地方呢我们的。序列呢它的长度有可能是不相同的,但是呢它是把它做了一个填充的。所有的序列呢应该都是有188个值。
因为是它的一个时间呢有188个。那我们对我们的序列把它读取完成之后呢,我们接下来要做什么呢?我们接下来要做的对于我们的序列呢,就是计算一下它的就是说我们的样本是不是有趋势值。
我们样本呢我们怎么计算它是不是有缺失值呢?我们就是用喷nda的啊后这个EZNA来判断一下每列是不是有缺失值。也就是说每每个时刻是不是有缺失值的情况,对吧?那么我们可以看一下这么一个时刻。
它都是没有确失值的对吧?趋失值的一个比例都是零的。好。我们接下来可以做一个什么呢?我们可以做一下我们的一个标签。嗯,标签呢其实本质就是我们的1个187列,它是我们的一个。对应的一个。
这种序列的一个类别的标签。那么我们可以看一下。我的大部分的一个是这个序列呢都是说类别为零的。对吧除此除此之外呢,还有一些类别是1234的对吧?当然类别是零的,这个呃样本呢是最多的是最多的。好,我们继续。
那么我们接下来呢可以做一个采样,为什么呢?因为我们的一个嗯就是说类别为零的一个具体的一个就是说样本是过于多的。那么我们可以做一个采样,就相当于是把我们的一个类别为零的样本把它做一个下采样。
对吧下载样之后呢,然后再去对我们的一个这个数数据器来再继续做一个分类。好,因为做了一个下采样之后呢,我们的一个就是相当于是我们把这这一个原始类别云的样本来采样。一些出来。然后呢,我们的嗯采用之后呢。
我们的数据以整体的就是比较规整的啊,整体的就是比较规整的。嗯。那么我们接下来呢可以绘制一些具体的一些我们的形态啊。嗯,那这个形态这个矩形形态是我们的类边零的。
这个是我们的类比一的这是类比二的这是类比3的这是类比4的对吧?其实这个呃对于我们的这个受过专业培养的,或者就是说对心电图比较了解的同学呢,其实是能够得到就是能够区分的?比如说类别0和类比一有什么区别呢?
类比0和类比一整体差不多。只不过类比0它的一个曲线会比较光滑一些。对吧。整体的形态两个角度差不多,但是那边印呢它不是那么光滑。那么从这个具体的一个形态而言呢,类别一和类比2吧在形态上面是存在区别的。
对吧类别二和类别3对吧?在形态上也是存在区别。然后我们更不用说类别3和类别4。所以说呢我们在做一个具体的一个建模的时候呢,我们是可以考虑从形态上做。当然也可以考虑从什么?
从这个具体的一个时序在不同时刻这个取值。对吧嗯,类个零它的一个取值应该是大部分在0到0。5之间。对吧那么类别3的一个取值呢,大部分是从0到0。25之间。他的取值范围有可能不一样。
对吧这个呢其实我们对于我们的一个这个取值范围,对我们的一个具体的一个分类的一个过程也是有帮助的。对吧当然你也可以参考我们刚才所说的这种思路啊,手动去去提取这些特征。比如说它整体的一个趋势的一个变化。
以及整体的是不是光滑的这种,就是说这个形态啊,我们都是可以把它考虑这提取这个特征的。当然这个地方我们是直接用深度学习的方法来做的。也就是说我们不提取特征,我们直接把这些序列呢送到我们的深度学习模型里面。
让我们的深度学习模型来做一个建模。好,为了验证我们的模型呢,我们将我们的一个数据集呢把它划分为我们的训练集和我们的一个验证级。对吧这个就是说10%的一个数据集,把它当做我们的验证集。
然后90%的呢当做我们的训练集。好,然后接下来呢就是构建我们的模型。这个地方呢我们的模型呢,我们是用这个ED卷积做我们的一个特征提取器。ED卷积做成特征提取器。它呢在做一个具体的一个操作的过程中。
其实是做一个卷积核。如果大家之前没有学习过这个卷积啊,我们这个地方给大家解释一下。我们这个卷积呢相当于是有一个卷积盒。雪地阀呢在我们这个地方呢一个cur size是3。也就是说我们有一个窗口3。
然后呢去统计一下在这个窗口下面的一个具体的一个值。然后呢这个卷积好它会滑动,每次滑动我们相当于是往它是一个滑动的过程。这个滑动呢相当于是我们的一个统计这个窗口下面具体的一个值。那么我们不断的滑动。
我们就可以提取对它不同特征。这个卷积盒你可以理解,就是一个特征的提取器。特征提取器。特别一个extract,对吧?或者说我们是那种基于上升的这模型作为一个特征。那么这个特征呢,其实。
我们并没有去人为去规定他提取什么特征。对吧也就是说没有提没有任何规律。因为这个卷积核是可以可学习的。因为这个卷积头其实它里面有一些参数,它是可学习的。然后呢,对于深度学习模型。
它可以不断的去套这个卷积核,什么意思呢?我们原始的一个我们这个地方呢,我们可以给大家把这个model给它打印出来啊。我把它打印出来,大家就可能会更加直观一些。稍等一下啊,把这个代码运行一下。
这个是对深度性象而言,这就就是每一层对吧?每一层。那么对于这每一层而言呢,其实我们是可以对它进行。就相当于是把它做一个叠加的。好,我们搬到下面。6DF啊这个地方要拼接。好。嗯,我们一步一步就行啊。好。
模型定义好了。模型定义好之后呢,我们可以把它打,就是看它的一个具体网络结构啊,sumary。他没人能我们来看一看。我错了。这个地方来看一下我们的一个具体的一个输入的一个操作。我们输入的一个特征。
输入的原始的一个维度是浪乘以一个。1啊187186的一个维度吧。然后呢,我们在进行一个卷积的时候,它的个维度会不断进行变化。这个地方呢是通道数3264、128,对吧?然后就相当于是主每层提取特征。
然后这一层是对前一层的一个特征做一个继续的一个提取。然后做一个铺ing,然后再加上flatten,然后再加上全新阶层。对吧相于是这前面的是特征提取。后面几层是做分类。后面几层就做一个分类。对。
这个就是我们构建了1个ED卷级的这种分类模型。嗯,有同学问到可以用wideden deep的模型来做吗?加上前面所提到的特征工程。呃,这个是可以的。就是相当于是你是想把结构化的一个特征,也是嗯把的。
你可以把它直接拼接到全连阶层。你可以直接把结构化的特征把它拼接到全链阶层,也是类似于挖地的这种操作,其实是可以的。但是呢按照我的一个经验啊,就是说。这种结嗯结构化的特征呢。
它并不一定就是精度会比这种呃就是纯CN的这种精度会高一些。一般情况下结构化的一个特征呢,可能是需要你提取的一个特征比较好的情况下,才可能有可能啊会比这种就是说CN的这个精度会高。你当然也可以做一个尝试。
就是直接把结构化的特征把它偏接到这儿。这个也是可行的啊是可行的。当我们模型把它边嗯构造好之后呢,然后接下来就是边用模型,我们就是用分类。的一个存成函数对吧?我们是一个多分类的存成函数。
然后呢去用我们的一个对我们的模型进行编译。然后对我们的训练集做一个废itch进行一个训练。训练呢我们就是传入我们的数据集以及它对应的标签。训练10倍poke,我们最终在训练集上的一个精度是98%,对吧?
这个精度是非常非常好的。然后呢,我们可以看一下我们的模型,在测试集上面的明新度。

我们的测略之间的一个嗯这终的混淆矩阵呢,就这种形态。这种形态啊,混淆矩证是这种形态,基本上是能够预测对的,就预测对的对吧?嗯,这个精度也是非常高的。呃,测试这量的精度呢也是96%,也是非常非常高的啊。
非常非常高的。

好,这个呢就是我们对就是基于我们的1个CN的1个ADCN的这种。方法来构建一个分类模型啊,对是我们实间区别的分类模型。比较核心的点就是我们的一个模型的构建。模先拟给大家建啊。
就是这一部分是我们比较核心的一个点。好,这部分大家有问题吗?对,好,那么我们接下来呢就嗯给大家详细介绍一下我们的一个机忆学习集训营啊。我们先做第三波抽奖好不好?然后呢,我们现在呢大家可以在我们的一个。
嗯,就是。做我们的第三波抽奖。我们各位同学呢也可以在我们的一个直播间里面就是说输入AI。然后呢,前5名的同学送我们的70在线的月卡。这个月卡呢就可以免费学100多门小课啊,就是说不用再额外购买。对。
大家如果想要领取我们的月卡的同学呢,可以现在就是说参与我们的抽奖啊,前五位的啊前五位同学。啊,这五位同学分别是我们的冯。
冯KK同学QQ3599056同学日合坊同学AITANIS同学以及happy water同学啊,这几位同学。然后AK同学也可以去领啊,AK同学答。呃,有同学问到数据集的一个序列长度不同怎么办?嗯。
我给你这样给你解释啊。嗯,画个图。序数据集的序列长度不同,其实是很简单的一种解决方法。没有。有很很多解决方法啊。假设啊我们数数据机的一个长度。你的样本是10个。有的样本是20个,有的样本是30个。
25啊,不同长度长度不同。有有的就是说有的序的长度是这么长的。对吧这是不同长度的。那么我们都知道,对于机学习模型或者对于深度学习模型。它的一个长度竖的纬度是要固定的对吧?一有两种方法。
第一种方我们是把它都把它。填充的相同的长度。这个地方我们把它后面可以填名。对吧我们把它所有的一个维度都把它转成1个30维。这个是可以的吧,这个操作呢我们把它叫做一个填充。啊,这叫做一个配置。
把它交给云配的。第二种方法我们可以做这样一个操作。我们对于我们的数字数据呢,我们把它做一个截取。所有的样本能把它截取成10。这个操作是什么意思呢?对于这个样子。它就是只有1个10个长度的一个序列素组成。
那么对于这个样本呢就不一样。对于这个样本,它的一个就是说它是可以不断滑动的,原始长度为20的。它可以不断滑动为多少个10个序列,你可以下去可以推算一下,应该是10个或者是9或1,应该也是10个序列。
对吧我们相当于是我们的可以可以把它拆分成。现在是原始是在这儿,然后不断是在这儿,然后在这儿也是相当于是划窗这种思路。你可以把它拆分成短的序列,然后再去做建模,这个也是可以的,就是两种方法,一种是填充。
一种是做一个截段。我们继续啊。然后当你刚才已经领取到,就是说成功领取了我们的。说这个中奖的同学啊,一定要加一下我们杨老师的微信啊。然后呢,我们接下来的时间呢,我们就给大家介绍一下。
我们现在在区在线正在开设的积极学习集训营的这个课程。这个课程呢也是非常干货的。这个课程呢,它的一个名字叫机器学习集训云,也是现在7月在线和CSCSDN一起举办着我们的这个集训营的课程。在这个课程里面呢。
我们会讲解啊这个机器学习和深度学习的非常重要的知识点。然后呢,我们也会不管是从机器学习的原理。然后再到我们的深度学习的原理,我们都会给大家讲到。其次呢我们也会提供这个GPU的一个实践的云平台。
以及有一些具体的一些实训的项目。这些呢都是大家自己去学习的时候呢,会比如说你可能是没有GPU的平台,没有GPU的实践的。那么我们会提供给大家。然后呢这个实训的数据集呢以及解决方案呢。
我们也会一步一步的就是说教给大家。比如我们在积极学习的原理阶段,我们会从逻辑回归先进回归讲起,然后讲到这个积器学习的一些介绍,角色素的介绍,以及角色素的原理以及具体的实践。
这些呢都是哦就是说非常非常干货的啊,也是非常非常适合我们的入门的同学,以及想要。继续深入学习继忆学习的同学,非常适合大家。那么我们今天晚上呢,我们的这个机器云呢,其实也是有我们的一个报名的优惠的啊。
我们的机器云呢今天晚上如果是在我们的零点之前,通过我们的杨老师的这个渠道进行报名呢,在我们的官官网的一个价格。继续优优惠1600以上,然后再额外给大家优惠1000。也就是说我们的官网的这个价格。
其实就是我们的一个。

12100。我们今天晚上呢大家如果想要购买我们的这个课程呢,只要9500,然后是优惠了2000多啊,优惠了2600是非常非常优惠的。其次呢如果购买了我们的机器学习机器营啊。
它可以给大家送价值4999元的一个大数据机器营,以及我们的一个深度学习机器营,以及送大家100多个1个AI的小课,也就是说我们的这个企在线上面的很多的一些小的一些这种课程啊,都是免费送给大家的。对。
所以说我们如果大家现在想要报名我们的机器学习机器营啊,都是可以优惠的啊,原价就是说12000的,今天晚上是优惠了2600块钱啊,只要9500块钱。当然如果大家就是说对我们的机器学习机器营。
这个相关的一些报名啊,或者是说是签约啊,有什么一些问题的,都可以去咨询一下我们的。

老师就是加一下我们杨老师的微信。对,其实呢我们今天的一个具体的一个。嗯,代码和课程啊以及PPT啊,都是从我们杨老师的微信领取的啊,领取的。大家一定要加一下我们杨老师的微信。🤧好。嗯。
大家对我们今天的一个课程有什么问题吗?对我再给大家介绍一下我们的今天那期训营的这个课程啊。这个课程呢其实是安排的非常非常。


就是说接地气的不仅仅是有这种基础的一些原理的讲解,也会讲解到比较深入的。比如说结构化的数据值的一些案例,或者说CV的一些案例,以及AIP的一些案例。在我们的集器云里面都会讲解到的。然后呢,我们的集器云。
都是由我们的专门的这个嗯QQ群或者说我们的微信群来进行一个答疑的啊。所以说大家也不用去担心找不到我们的老师,我们都是24小时给大家进行答疑的。然后呢,我们的这个机器营呢,其实包含了很多的实训项目。
也是让我们的一些老师呢带着大家一步一步去完成。所以说大家也不用担心,就是说如果你不会啊,就是说你就是说学起来会比较吃力,这个也不用担心。对,然后大家如果想要今天晚上报名。
我们机器营呢是直接有很多优惠的啊,有很多优惠的。如果是今天晚上过了过了零点呢,我们的优惠力度就没有这么大的。

对。嗯,对,大家对我们今天所讲解的内容,以及我们的集器云的这个细节有什么疑问吗?如果有疑问的话呢,可以啊现在进行提问啊,现在可以可以进行提问。

对,如果大家想要领取我们今天所送出的V这个。月卡福利以及领取我们的PPT啊等。那么大家可以加一下我们的一个杨老师的微信。请问有金融方面的项目吗?嗯,我记得在我们这个地方,现在现在也有金融相关的一些。
金融的课程啊,也有的。

金融AI高技时训营也是有的。对,嗯,就是如果大家报名我们的一个机器机器机器云是可以送AI相关的一些以及金融相关的一些课程的,都是可以送给大家的。

嗯。对,大家还有什么问题吗?对。是可以送给大家这个金融相关的一些课程的。如果有问题可以嗯及时提问啊,再给大家创新大家一一两分钟。

大家我再稍等大家一两分钟,大家如果有问题的话呢,可以嗯继续提问啊。如果没有问题的话呢,大家可以扣个一好不好?然后我们就啊对大家如果想要报名我们的一个集训营的同学。
或者是了解我们的相关的一些课程细节的同学,大家都可以加一下我们杨老师的微信啊。好。那么我们就来最后一波抽奖吧,好不好?大家刚才也有还有很多同学没有抽到我们的这个VIP的月卡,对吧?
大家现在呢也可以在我们的弹幕区呢再抽最后一次,然后发送AI就可以领取我们7月在线的月卡。这个月卡呢就可以在我们的这个具体的一个嗯官网可以领取100多个我们的AI小课。对。
呃如果刚才还没有领取到我们的月卡的同学呢,可以现在在抽奖啊,我们送10个啊送10个月卡。对。去。好,嗯,我们的这个happy water以及石栋冉印同学啊,你可以去找加一下我们的杨老师微信啊。
领取我们的月考。好。呃,范文宇同学也可以嗯,欢迎加一下我们杨老师的微信啊,然后领取一下。好。大家如果想领取我们月卡的同学呢,都可以去加一下我们杨老师的微信啊。大家还有问题吗?
还有问题的同学可以及时提问啊。好,呃,那么我们今天的一个直播就到此结束。然后我是刘老师,然后如果大家想了解我们的课程体系,想要了解我们的机器及训营,都可以加一下我们杨老师的微信。
以及我们今天的PPT代码以及相关的一些讲励,都是通过我们杨老师的微信发给大家。然后欢迎大家就是说跟我们的杨老师保持很好的微信联系。好吧,然后呢我们今天的一个课程呢就到此结束,谢谢大家。😊。






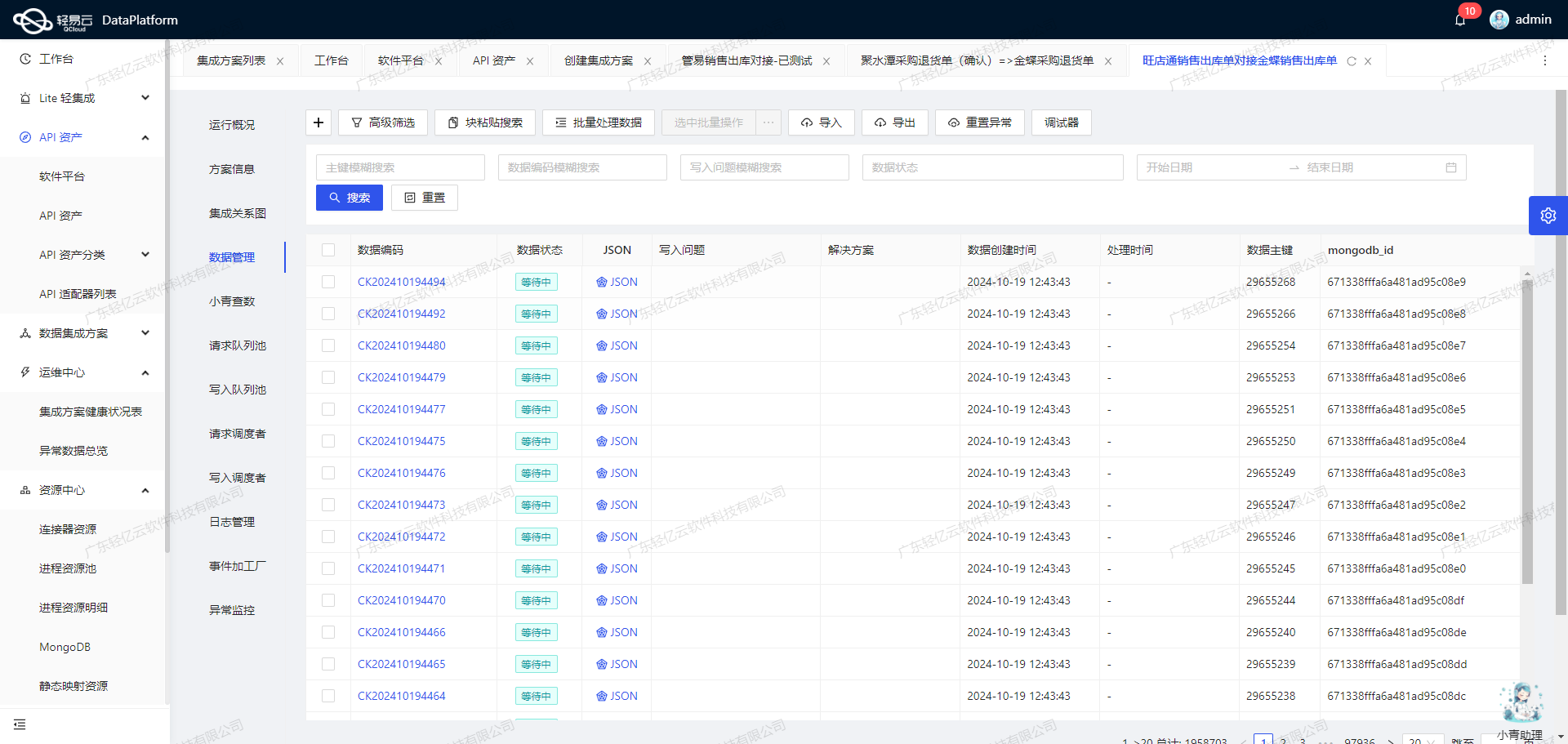

![[LibreOffice Calc]打印表格时自动缩放到与纸张尺寸匹配](https://img2024.cnblogs.com/blog/1324435/202410/1324435-20241023180847841-1688722778.png)