Codeforces Round 982 div2 个人题解(A~D1)
Dashboard - Codeforces Round 982 (Div. 2) - Codeforces
火车头
#define _CRT_SECURE_NO_WARNINGS 1#include <algorithm>
#include <array>
#include <bitset>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <chrono>
#include <fstream>
#include <functional>
#include <iomanip>
#include <iostream>
#include <iterator>
#include <list>
#include <map>
#include <numeric>
#include <queue>
#include <random>
#include <set>
#include <stack>
#include <string>
#include <tuple>
#include <unordered_map>
#include <utility>
#include <vector>#define ft first
#define sd second#define yes cout << "yes\n"
#define no cout << "no\n"#define Yes cout << "Yes\n"
#define No cout << "No\n"#define YES cout << "YES\n"
#define NO cout << "NO\n"#define pb push_back
#define eb emplace_back#define all(x) x.begin(), x.end()
#define all1(x) x.begin() + 1, x.end()
#define unq_all(x) x.erase(unique(all(x)), x.end())
#define unq_all1(x) x.erase(unique(all1(x)), x.end())
#define sort_all(x) sort(all(x))
#define sort1_all(x) sort(all1(x))
#define reverse_all(x) reverse(all(x))
#define reverse1_all(x) reverse(all1(x))#define inf 0x3f3f3f3f
#define infll 0x3f3f3f3f3f3f3f3fLL#define RED cout << "\033[91m"
#define GREEN cout << "\033[92m"
#define YELLOW cout << "\033[93m"
#define BLUE cout << "\033[94m"
#define MAGENTA cout << "\033[95m"
#define CYAN cout << "\033[96m"
#define RESET cout << "\033[0m"// 红色
#define DEBUG1(x) \RED; \cout << #x << " : " << x << endl; \RESET;// 绿色
#define DEBUG2(x) \GREEN; \cout << #x << " : " << x << endl; \RESET;// 蓝色
#define DEBUG3(x) \BLUE; \cout << #x << " : " << x << endl; \RESET;// 品红
#define DEBUG4(x) \MAGENTA; \cout << #x << " : " << x << endl; \RESET;// 青色
#define DEBUG5(x) \CYAN; \cout << #x << " : " << x << endl; \RESET;// 黄色
#define DEBUG6(x) \YELLOW; \cout << #x << " : " << x << endl; \RESET;using namespace std;typedef long long ll;
typedef unsigned long long ull;
typedef long double ld;
// typedef __int128_t i128;typedef pair<int, int> pii;
typedef pair<ll, ll> pll;
typedef pair<ld, ld> pdd;
typedef pair<ll, int> pli;
typedef pair<string, string> pss;
typedef pair<string, int> psi;
typedef pair<string, ll> psl;typedef tuple<int, int, int> ti3;
typedef tuple<ll, ll, ll> tl3;
typedef tuple<ld, ld, ld> tld3;typedef vector<bool> vb;
typedef vector<int> vi;
typedef vector<ll> vl;
typedef vector<string> vs;
typedef vector<pii> vpii;
typedef vector<pll> vpll;
typedef vector<pli> vpli;
typedef vector<pss> vpss;
typedef vector<ti3> vti3;
typedef vector<tl3> vtl3;
typedef vector<tld3> vtld3;typedef vector<vi> vvi;
typedef vector<vl> vvl;typedef queue<int> qi;
typedef queue<ll> ql;
typedef queue<pii> qpii;
typedef queue<pll> qpll;
typedef queue<psi> qpsi;
typedef queue<psl> qpsl;typedef priority_queue<int> pqi;
typedef priority_queue<ll> pql;
typedef priority_queue<string> pqs;
typedef priority_queue<pii> pqpii;
typedef priority_queue<psi> pqpsi;
typedef priority_queue<pll> pqpll;
typedef priority_queue<psi> pqpsl;typedef map<int, int> mii;
typedef map<int, bool> mib;
typedef map<ll, ll> mll;
typedef map<ll, bool> mlb;
typedef map<char, int> mci;
typedef map<char, ll> mcl;
typedef map<char, bool> mcb;
typedef map<string, int> msi;
typedef map<string, ll> msl;
typedef map<int, bool> mib;typedef unordered_map<int, int> umii;
typedef unordered_map<ll, ll> uml;
typedef unordered_map<char, int> umci;
typedef unordered_map<char, ll> umcl;
typedef unordered_map<string, int> umsi;
typedef unordered_map<string, ll> umsl;std::mt19937_64 rng(std::chrono::steady_clock::now().time_since_epoch().count());template <typename T>
inline T read()
{T x = 0;int y = 1;char ch = getchar();while (ch > '9' || ch < '0'){if (ch == '-')y = -1;ch = getchar();}while (ch >= '0' && ch <= '9'){x = (x << 3) + (x << 1) + (ch ^ 48);ch = getchar();}return x * y;
}template <typename T>
inline void write(T x)
{if (x < 0){putchar('-');x = -x;}if (x >= 10){write(x / 10);}putchar(x % 10 + '0');
}/*#####################################BEGIN#####################################*/
void solve()
{
}int main()
{ios::sync_with_stdio(false), std::cin.tie(0), std::cout.tie(0);// freopen("test.in", "r", stdin);// freopen("test.out", "w", stdout);int _ = 1;std::cin >> _;while (_--){solve();}return 0;
}/*######################################END######################################*/
// 链接:
A. Rectangle Arrangement
您正在为一个无限的正方形网格着色,其中所有单元格最初都是白色的。为此,您将获得 \(n\) 个印章。每个印章都是一个宽度为 \(w_i\)、高度为 \(h_i\) 的矩形。
您将使用每个印章恰好一次,将与网格上的印章大小相同的矩形涂成黑色。您不能旋转印章,并且对于每个单元格,印章必须完全覆盖它或根本不覆盖它。您可以在网格上的任何位置使用印章,即使印章区域覆盖的部分或全部单元格已经是黑色。
使用完所有印章后,您可以获得的黑色方块连接区域的周长的最小总和是多少?
输入
每个测试包含多个测试用例。第一行包含测试用例的数量 \(t\) \((1 \leq t \leq 500)\)。测试用例的描述如下。
每个测试用例的第一行包含一个整数 \(n\) \((1 \leq n \leq 100)\)。
接下来的 \(n\) 行中的第 \(i\) 行包含两个整数 \(w_i\) 和 \(h_i\) \((1 \leq w_i, h_i \leq 100)\)。
输出
对于每个测试用例,输出一个整数——使用完所有邮票后可以获得的黑色方块连通区域周长的最小和。
示例
输入
5
5
1 5
2 4
3 3
4 2
5 1
3
2 2
1 1
1 2
1
3 2
3
100 100
100 100
100 100
4
1 4
2 3
1 5
3 2
输出
20
8
10
400
16
提示
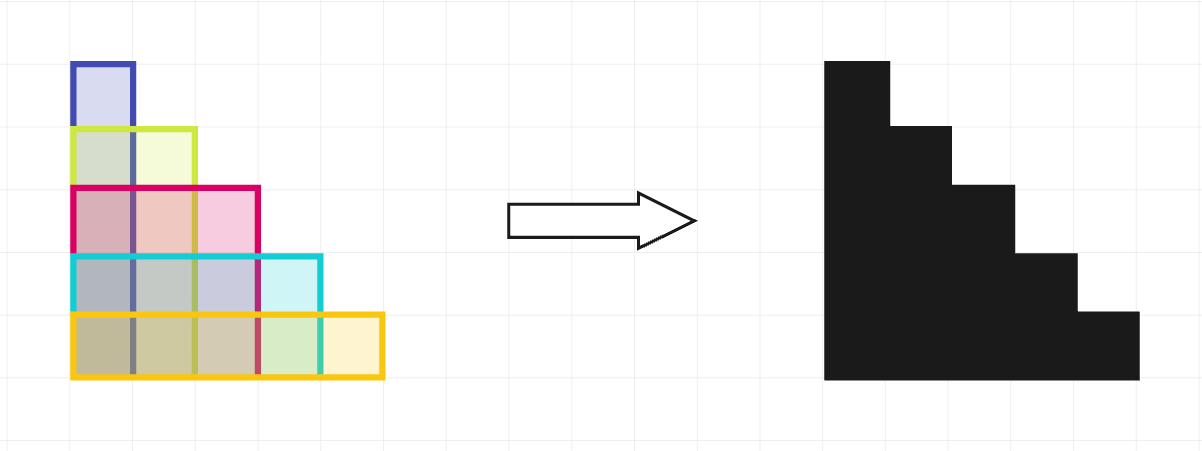
在第一个测试用例中,印章可以如左侧所示使用。每个印章用不同的颜色突出显示以便于识别。
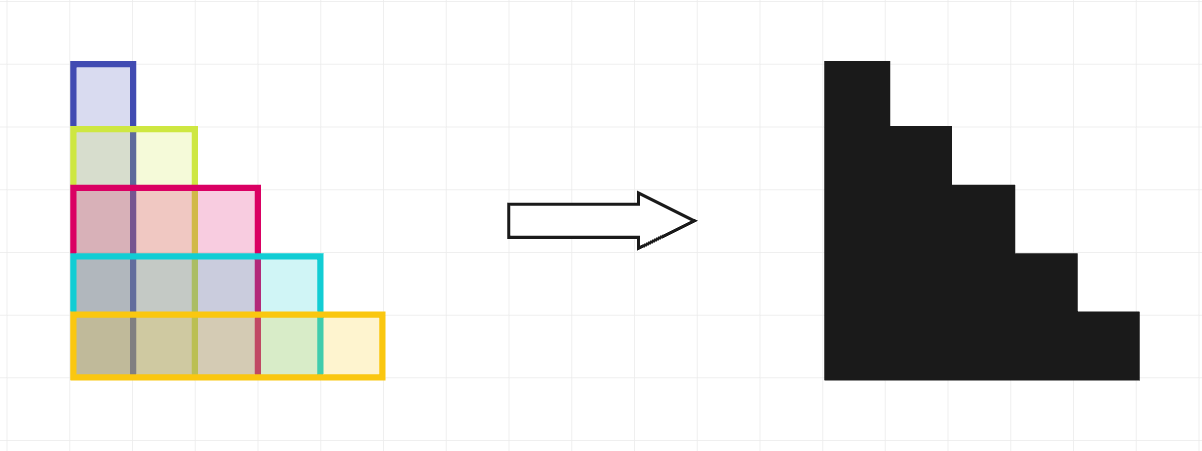
在使用完这些印章后,形成一个黑色区域(如右侧所示),其周长为 20。可以证明,没有其他方式使用印章可以得到更低的总周长。
在第二个测试用例中,第二个和第三个印章可以完全放置在第一个印章内部,因此最小周长为 8。解题思路
解题思路
小学数学,观察样例发现总周长一定为$2\times (\text{max}(w)+\text{max}(h)) $
当然观察数据范围发现,也可以使用暴力模拟
代码实现
方法一
void solve()
{int n;cin >> n;int max_w = 0, max_h = 0;for (int i = 0; i < n; i++){int w, h;cin >> w >> h;if (w > max_w)max_w = w;if (h > max_h)max_h = h;}cout << 2 * (max_w + max_h) << "\n";
}
方法二
赛时写的方法二,想了下好像会被hack掉,有可能超时,有改成方法一了,结果赛后再交没超时,白丢分
void solve()
{int n;cin >> n;vvi board(102, vi(102, 0));for (int i = 0; i < n; i++){int x;int y;cin >> x >> y;// 把所有印章从左上角开始印for (int j = 1; j <= x; j++){for (int k = 1; k <= y; k++){board[j][k] = 1;}}}int ans = 0;for (int i = 1; i <= 100; i++){for (int j = 1; j <= 100; j++){if (board[i][j] == 1){// 如果遇到一个方块盖了章,给答案加4,再减去和相邻方块也盖了章的数量ans += 4;ans -= board[i - 1][j] + board[i + 1][j] + board[i][j - 1] + board[i][j + 1];}}}cout << ans << endl;
}
B. Stalin Sort
斯大林排序是一种有趣的排序算法,旨在消除不合适的元素,而不是费心对它们进行正确排序,这使其具有 \(O(n)\) 的时间复杂度。
它的流程如下:从数组中的第二个元素开始,如果它严格小于前一个元素(忽略那些已经被删除的元素),则删除它。继续遍历数组,直到按非递减顺序排序。例如,数组 \([1,4,2,3,6,5,5,7,7]\) 经过斯大林排序后变为 \([1,4,6,7,7]\)。
如果您可以通过对任何子数组重复应用斯大林排序,按非递增顺序对数组进行排序,则我们将数组定义为易受攻击的。
给定一个包含 \(n\) 个整数的数组 \(a\),确定必须从数组中删除的最小整数数量,以使其易受攻击。
输入
每个测试由多个测试用例组成。第一行包含一个整数 \(t\) \((1 \leq t \leq 500)\) — 测试用例的数量。后面是测试用例的描述。
每个测试用例的第一行包含一个整数 \(n\) \((1 \leq n \leq 2000)\) — 数组的大小。
每个测试用例的第二行包含 \(n\) 个整数 \(a_1,a_2,…,a_n\) \((1 \leq a_i \leq 10^9)\)。
保证所有测试用例的 \(n\) 之和不超过 2000。
输出
对于每个测试用例,输出一个整数——必须从数组中删除的最小整数数量,以使其易受攻击。
示例
输入
6
7
3 6 4 9 2 5 2
5
5 4 4 2 2
8
2 2 4 4 6 6 10 10
1
1000
9
6 8 9 10 12 9 7 5 4
7
300000000 600000000 400000000 900000000 200000000 400000000 200000000
输出
2
0
6
0
4
2
提示
在第一个测试用例中,最优答案是删除数字 3 和 9。然后我们剩下 \(a=[6,4,2,5,2]\)。为了证明这个数组是易受攻击的,我们可以首先对子数组 \([4,2,5]\) 应用斯大林排序,得到 \(a=[6,4,5,2]\),然后对子数组 \([6,4,5]\) 应用斯大林排序,得到 \(a=[6,2]\),该数组是非递增的。
在第二个测试用例中,数组已经是非递增的,因此我们不需要删除任何整数。
解题思路
题目要求剩下的数组按照非递减排序,所以无论最后数组是什么情况,我们一定可以对它进行斯大林排序,使得它只剩一种数字。
因此,题目实际上可以转化成有两种操作
- 花费1代价删除任意数字
- 花费0代价删除\(a_j(a_j \lt a_i,j \gt i)\)
所以我们可以枚举剩下的数字\(a_i\),它的花费\(cost_i=i-1+\sum_{j=i+1}^{n}[a_j\lt a_i]\)
由于\(n\le2000\),我们可以直接枚举统计\(a_j\lt a_i\)的数量
代码实现
方法一
void solve()
{int n;cin >> n;vi a(n + 1);for (int i = 1; i <= n; i++){cin >> a[i];}int ans = inf;for (int i = 1; i <= n; i++){int cnt = 0;for (int j = i + 1; j <= n; j++){if (a[j] > a[i])cnt++;}ans = min(ans, i - 1 + cnt);}cout << ans << endl;
}
方法二
对于\(n\le200000\),方法一会超时,所有这时候我们可以倒着枚举\(a_i\),然后开一个对顶堆存储\(a_i\)
void solve()
{int n;cin >> n;vi a(n + 1);for (int i = 1; i <= n; i++){cin >> a[i];}int ans = inf;priority_queue<int, vi, greater<int>> ge;priority_queue<int> le;for (int i = n; i >= 1; i--){while (!ge.empty() && ge.top() <= a[i]){le.push(ge.top());ge.pop();}while (!le.empty() && le.top() > a[i]){ge.push(le.top());le.pop();}ans = min(ans, int(i - 1 + ge.size()));ge.push(a[i]);}cout << ans << endl;
}
C. Add Zeros
给定一个数组 \(a\),最初包含 \(n\) 个整数。在一次操作中,您必须执行以下操作:
选择一个位置 \(i\),使得 \(1<i\leq |a|\) 和 \(a_i=|a|+1−i\),其中 \(|a|\) 是数组的当前大小。
将 \(i−1\) 个零附加到 \(a\) 的末尾。
在执行此操作多次后,数组 \(a\) 的最大可能长度是多少?
输入
每个测试包含多个测试用例。第一行包含测试用例的数量 \(t\) \((1 \leq t \leq 1000)\)。测试用例的描述如下。
每个测试用例的第一行包含 \(n\) \((1 \leq n \leq 3 \cdot 10^5)\)——数组 \(a\) 的长度。
每个测试用例的第二行包含 \(n\) 个整数 \(a_1,a_2,…,a_n\) \((1 \leq a_i \leq 10^{12})\)。
保证所有测试用例的 \(n\) 之和不超过 \(3 \cdot 10^5\)。
输出
对于每个测试用例,输出一个整数——执行某些操作序列后可能的最大长度为 \(a\)。
示例
输入
4
5
2 4 6 2 5
5
5 4 4 5 1
4
6 8 2 3
1
1
输出
10
11
10
1
提示
在第一个测试用例中,我们可以首先选择 \(i=4\),因为 \(a_4=5+1−4=2\)。之后,数组变为 \([2,4,6,2,5,0,0,0]\)。然后我们可以选择 \(i=3\),因为 \(a_3=8+1−3=6\)。之后,数组变为 \([2,4,6,2,5,0,0,0,0,0]\),其长度为 10。可以证明没有其他操作序列会使最终数组更长。
在第二个测试用例中,我们可以选择 \(i=2\),然后 \(i=3\),再然后 \(i=4\)。最终数组将是 \([5,4,4,5,1,0,0,0,0,0,0]\),长度为 11。
解题思路
我们把题目给的式子转化一下,变成\(|a|=a_i+i-1\)。
由于每个\(a_i\)操作一次会使得\(|a|\)增加\(i-1\),实际上就相当于每个\(a_i\)都是对\(a_i+i-1\)到\(a_i+2i-2\)建了一条边,点权为数组长度。
所以我们可以按照上面的规则进行建图,对这个图从\(n\)进行\(dfs\),\(dfs\)过程中维护一下遇到的最大点权,即为答案。
记得要加\(vis\)数组,不然会超时。
代码实现
void solve()
{ll n;cin >> n;vl a(n + 1);for (int i = 1; i <= n; i++){cin >> a[i];}map<ll, vl> adj;for (ll i = 1; i <= n; i++){adj[a[i] + i - 1].pb(a[i] + 2 * (i - 1));}ll ans = n;mlb vis;function<void(ll, ll)> dfs = [&](ll u, ll fa){ans = max(ans, u);vis[u] = 1;for (auto &v : adj[u]){if (v == fa)continue;if (vis[v])continue;dfs(v, u);}};dfs(n, 0);cout << ans << endl;
}
D1. The Endspeaker (Easy Version)
这是该问题的简单版本。唯一的区别是,您只需要在此版本中输出最小的总操作成本。您必须解决两个版本才能破解。
您将获得一个长度为 \(n\) 的数组 \(a\) 和一个长度为 \(m\) 的数组 \(b\)(对于所有 \(1 \leq i < m\),其值为 \(b_i > b_{i+1}\))。最初,\(k\) 的值为 1。您的目标是通过重复执行以下两个操作之一来使数组 \(a\) 为空:
类型 1 — 如果 \(k\) 的值小于 \(m\) 且数组 \(a\) 不为空,则可以将 \(k\) 的值增加 1。这不会产生任何成本。
类型 2 — 删除数组 \(a\) 的非空前缀,使其总和不超过 \(b_k\)。这会产生 \(m−k\) 的成本。
您需要最小化操作的总成本,以使数组 \(a\) 为空。如果通过任何操作序列都无法做到这一点,则输出 \(−1\)。否则,输出操作的最小总成本。
输入
每个测试包含多个测试用例。第一行包含测试用例的数量 \(t\) \((1 \leq t \leq 1000)\)。测试用例的描述如下。
每个测试用例的第一行包含两个整数 \(n\) 和 \(m\) \((1 \leq n,m \leq 3 \cdot 10^5, 1 \leq n \cdot m \leq 3 \cdot 10^5)\)。
第二行包含 \(n\) 个整数 \(a_1,a_2,…,a_n\) \((1 \leq a_i \leq 10^9)\)。
第三行包含 \(m\) 个整数 \(b_1,b_2,…,b_m\) \((1 \leq b_i \leq 10^9)\)。
还保证所有 \(1 \leq i < m\) 的结果是 \(b_i > b_{i+1}\)。
保证所有测试用例的 \(n \cdot m\) 之和不超过 \(3 \cdot 10^5\)。
输出
对于每个测试用例,如果有可能使 \(a\) 为空,则输出操作的最小总成本。如果没有可能的操作序列使 \(a\) 为空,则输出单个整数 \(−1\)。
示例
输入
5
4 2
9 3 4 3
11 7
1 2
20
19 18
10 2
2 5 2 1 10 3 2 9 9 6
17 9
10 11
2 2 2 2 2 2 2 2 2 2
20 18 16 14 12 10 8 6 4 2 1
1 6
10
32 16 8 4 2 1
输出
1
-1
2
10
4
提示
在第一个测试用例中,最优操作序列的总成本为 1,过程如下:
- 执行类型 2 的操作,选择前缀为 \([9]\),成本为 1。
- 执行类型 1 的操作,\(k\) 现在为 2,成本为 0。
- 执行类型 2 的操作,选择前缀为 \([3,4]\),成本为 0。
- 执行类型 2 的操作,选择前缀为 \([3]\),成本为 0。
数组 \(a\) 现在为空,所有操作的总成本为 1。
在第二个测试用例中,由于 \(a_1 > b_1\),无法删除任何前缀,因此数组 \(a\) 不能通过任何操作序列变为空。
解题思路
观察题目,发现是使用多种操作完成一个目标求最小代价,考虑dp
我们设\(dp[i][j]\)为对于前\(i\)个数字,使用第\(j\)总操作时的最小代价。
易得状态转移方程
其中\(\text{sum}[p,i]\)数组\(a\)的区间和
根据状态转移方程写出递推式
for (int i = 1; i <= n; i++)
{for (int j = 1; j <= m; j++){int p = i;while (p >= 1 && pre[i] - pre[p - 1] <= b[j]){p--;}p++;for (int k = 1; k <= j; k++){dp[i][j] = min(dp[i][j], dp[p - 1][k] + m - j);}}
}
发现时间复杂度为\(O(nm\times \text{max}(n,m))\),在\(n\)或\(m\)特别大的情况下肯定超时。
考虑优化。
对于\(p\)的位置,我们可以使用二分优化枚举
for (int i = 1; i <= n; i++)
{for (int j = 1; j <= m; j++){int l = 1, r = i;int p = i;while (l < r){int mid = (l + r) >> 1;if (pre[i] - pre[mid - 1] <= b[j]){r = mid;p = mid;}else{l = mid + 1;}}for (int k = 1; k <= j; k++){dp[i][j] = min(dp[i][j], dp[p - 1][k] + m - j);}}
}
时间复杂度降为\(O(nm^2)\),在\(m\)特别大的时候仍会超时
对\(k\)的枚举,我们实际上是在查询区间\([1,j]\)的最小\(dp[i][j]\)值,所以我们可以使用树状数组存储\(dp[i][j]\)。
时间复杂度\(O(nm\times \text{max}(\log n,\log m))\)
代码实现
void solve()
{int n, m;cin >> n >> m;vl a(n + 1);vl pre(n + 1);ll max_a = 0;for (int i = 1; i <= n; i++){cin >> a[i];max_a = max(max_a, a[i]);pre[i] = pre[i - 1] + a[i];}vl b(m + 1);for (int i = 1; i <= m; i++){cin >> b[i];}// 如果数组a中的最大值大于b[1],无法把a数组删完,输出-1if (max_a > b[1]){cout << "-1\n";return;}// 初始化动态规划数组dp,dp[i][j]表示删除前i个元素,使用第j个操作时的最小成本vvl dp(n + 1, vl(m + 1, infll));// 对于删除0个元素的情况,成本为0for (int i = 1; i <= m; i++){dp[0][i] = 0;}// 创建树状数组trvector<Fenwick<ll>> tr(n + 1, Fenwick<ll>(m));tr[0].add(1, 0); // 初始状态,删除0个元素成本设置为0// 动态规划状态转移for (int i = 1; i <= n; i++){for (int j = 1; j <= m; j++){// 如果当前元素大于b[j],无法继续删除,跳出循环if (a[i] > b[j])break;// 二分查找,找到可以一次性删除的最远位置pint l = 1, r = i;int p = i;while (l < r){int mid = (l + r) >> 1;if (pre[i] - pre[mid - 1] <= b[j]){r = mid;p = mid;}else{l = mid + 1;}}// 使用树状数组查询,查询1<=k<=j中最小的dp[i][k]ll mn = tr[p - 1].query(j);// 更新dp[i][j]dp[i][j] = min(dp[i][j], mn + m - j);// 将dp[i][j]插入树状数组树中,以便后续查询tr[i].add(j, dp[i][j]);}}// 计算最终答案,即dp[n][i]的最小值ll ans = infll;for (int i = 1; i <= m; i++){ans = min(ans, dp[n][i]);}cout << ans << "\n";
}
赛时把D1 dp的i和j写反了,找这个bug找了快一个小时,麻了,后面想到正解没时间写了,结束后三分钟写完了。太菜了,这几场掉大分。
![[rCore学习笔记 031] SV39多级页表的硬件机制](https://img2024.cnblogs.com/blog/3071041/202410/3071041-20241027025008968-705552299.png)