102202143 梁锦盛
1.中国气象网信息爬取
爬取这个网站中的所有图片,控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施
一、作业代码与展示
1.编写spider代码文件
import scrapy
from urllib.parse import urljoin
from scrapy.pipelines.images import ImagesPipelineclass A31Spider(scrapy.Spider):name = 'weather'allowed_domains = ['weather.com.cn']start_urls = ['http://www.weather.com.cn/'] # 修正了URLheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',}def parse(self, response):# 提取页面中的所有图片链接并补全 URLimage_urls = [urljoin(response.url, url) for url in response.css('img::attr(src)').getall()]# 输出图片链接for url in image_urls:self.log(f'Downloading image: {url}')# 递归访问子链接,只跟随有效的 URLfor next_page in response.css('a::attr(href)').getall():if next_page.startswith("http"):yield response.follow(next_page, self.parse)# 返回图片链接if image_urls:yield {'image_urls': image_urls}2.编写piplines代码文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipeline
import scrapyclass MyImagesPipeline(ImagesPipeline):def __init__(self, store_uri, *args, **kwargs):super(MyImagesPipeline, self).__init__(store_uri, *args, **kwargs)self.downloaded_count = 0self.target_count = 143 # 目标下载数量@classmethoddef from_settings(cls, settings):store_uri = settings.get('IMAGES_STORE') # 获取存储图片的路径return cls(store_uri)def get_media_requests(self, item, info):for image_url in item['image_urls']:yield scrapy.Request(image_url)def file_path(self, request, response=None, info=None):return f'images/{request.url.split("/")[-1]}'def item_completed(self, results, item, info):# 检查是否成功下载图片for ok, result in results:if ok:self.downloaded_count += 1# 检查是否达到目标下载数量if self.downloaded_count >= self.target_count:self.close_spider(reason='Reached target download count')breakreturn itemdef close_spider(self, spider, reason):spider.crawler.engine.close_spider(spider, reason=reason)class Hw1Pipeline:def process_item(self, item, spider):return item3.编写settings代码文件,如果单线程可删除CONCURRENT_REQUESTS = 16代码
BOT_NAME = 'hw1'SPIDER_MODULES = ['hw1.spiders']
NEWSPIDER_MODULE = 'hw1.spiders'
LOG_LEVEL = 'ERROR'
# 设置每个请求之间的下载延迟(单位:秒)
CONCURRENT_REQUESTS = 16 # 并发请求的数量
DOWNLOAD_DELAY = 0.25 # 每请求之间的延迟时间,单位为秒# 在settings.py中配置管道
ITEM_PIPELINES = {'hw1.pipelines.MyImagesPipeline': 1, # 替换 `your_project_name` 为你的实际项目名称
}IMAGES_STORE = 'E:\\Pycharm\\数据采集\\作业代码\\实验3\\hw1'4.运行结果
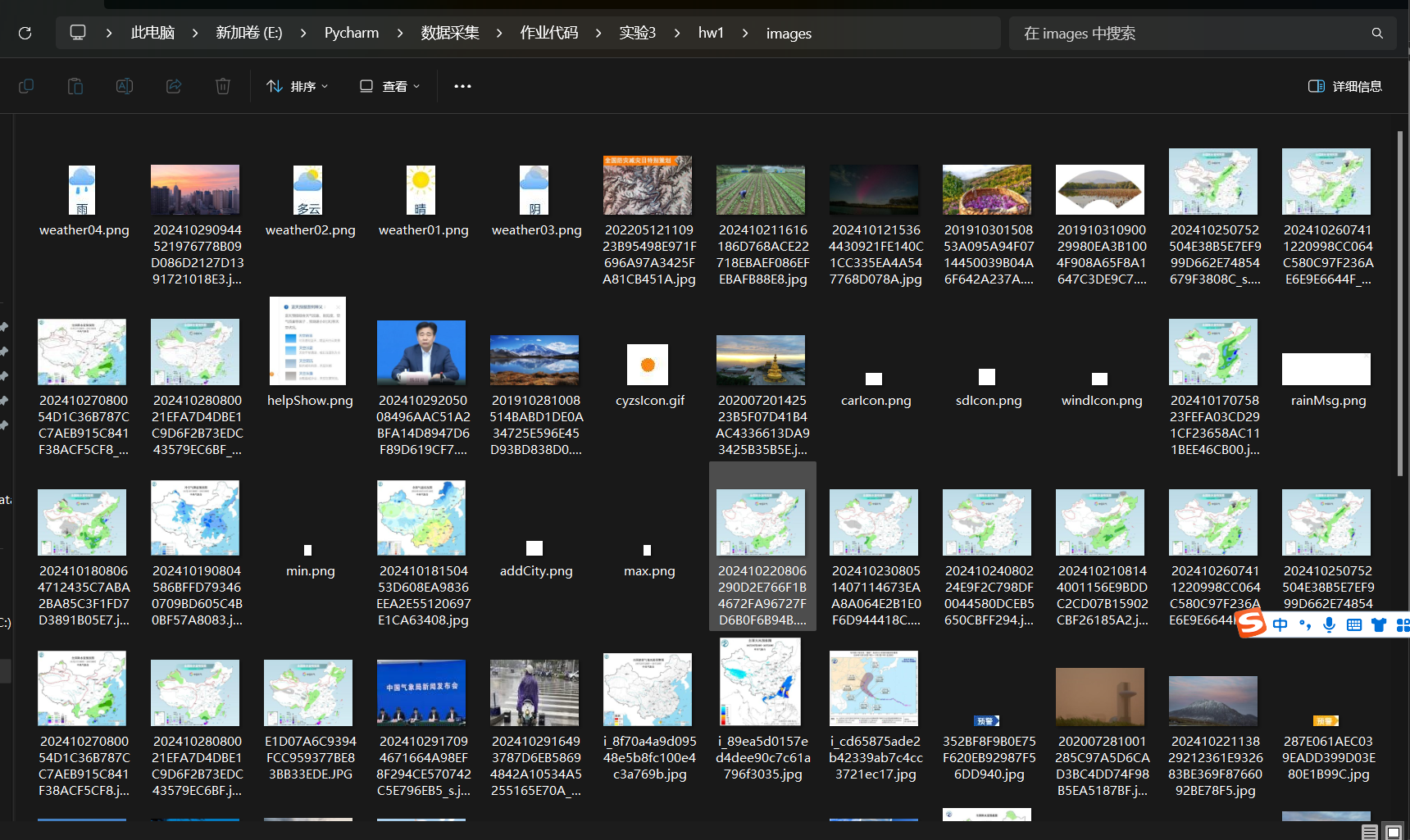
3.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业3/3.1
二、作业心得
scrapy的多线程存储免去了python中threading的许多麻烦,更方便地允许我们实现大量数据的爬取
2.东方财富网信息爬取
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。候选网站:东方财富网:https://www.eastmoney.com/
一、作业代码与展示
1.编写spider代码
import scrapy
import jsonfrom ..items import StockItemclass EastmoneySpider(scrapy.Spider):name = 'eastmoney'allowed_domains = ['eastmoney.com']start_urls = ['https://quote.eastmoney.com/center/gridlist.html#hs_a_board']def start_requests(self):for page_number in range(1, 6): # 爬取前5页url = f'https://12.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124049801084556447983_1730190060013&pn={page_number}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1730190060014'yield scrapy.Request(url=url, callback=self.parse, cookies=self.get_cookies(), headers=self.get_headers())def get_headers(self):return {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'}def get_cookies(self):return {'qgqp_b_id': '2d31e8f17cf8a3447185efdf4e253235','st_si': '66228653710444','st_asi': 'delete','st_pvi': '25044947399556','st_sp': '2024-10-15 16:41:44','st_inirUrl': 'https://www.eastmoney.com/','st_sn': '13','st_psi': '20241015165715752-111000300841-2878299811'}def parse(self, response):json_data = response.text[response.text.index('(') + 1: -2]data = json.loads(json_data)if 'data' in data and 'diff' in data['data']:for stock in data['data']['diff']:item = StockItem()item['bStockNo'] = stock.get('f62') # 股票代码item['bStockName'] = stock.get('f14') # 股票名称item['fPrice'] = stock.get('f2') # 最新报价item['fPriceChangeRate'] = stock.get('f3') # 涨跌幅item['fPriceChange'] = stock.get('f4') # 涨跌额item['fVolume'] = stock.get('f5') # 成交量item['fAmount'] = stock.get('f6') # 成交额item['fAmplitude'] = stock.get('f7') # 振幅item['fHigh'] = stock.get('f8') # 最高item['fLow'] = stock.get('f9') # 最低item['fOpen'] = stock.get('f10') # 今开item['fClose'] = stock.get('f11') # 昨收yield item
2.编写items代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass StockItem(scrapy.Item):bStockNo = scrapy.Field() # 股票代码bStockName = scrapy.Field() # 股票名称fPrice = scrapy.Field() # 最新报价fPriceChangeRate = scrapy.Field() # 涨跌幅fPriceChange = scrapy.Field() # 涨跌额fVolume = scrapy.Field() # 成交量fAmount = scrapy.Field() # 成交额fAmplitude = scrapy.Field() # 振幅fHigh = scrapy.Field() # 最高fLow = scrapy.Field() # 最低fOpen = scrapy.Field() # 今开fClose = scrapy.Field() # 昨收3.编写piplines代码
import mysql.connector
from mysql.connector import Error
from hw2.items import StockItemclass StockPipeline:def __init__(self):self.connection = self.connect_to_database()def connect_to_database(self):try:connection = mysql.connector.connect(host='localhost',database='stock_database',user='root',password='2896685056Qq!')return connectionexcept Error as e:print(f"Error: {e}")def process_item(self, item, spider):cursor = self.connection.cursor()query = ("INSERT INTO stock_table ""(bStockNo, bStockName, fPrice, fPriceChangeRate, fPriceChange, fVolume, fAmount, fAmplitude, fHigh, fLow, fOpen, fClose) ""VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")data = (item['bStockNo'],item['bStockName'],item['fPrice'],item['fPriceChangeRate'],item['fPriceChange'],item['fVolume'],item['fAmount'],item['fAmplitude'],item['fHigh'],item['fLow'],item['fOpen'],item['fClose'])cursor.execute(query, data)self.connection.commit()cursor.close()return item
4.编写settings代码
BOT_NAME = 'hw2'SPIDER_MODULES = ['hw2.spiders']
NEWSPIDER_MODULE = 'hw2.spiders'
DOWNLOAD_DELAY = 1.0 # 1秒延迟
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {'hw2.pipelines.StockPipeline': 300,
}# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '2896685056Qq!'
MYSQL_DB = 'stock_database'
5.运行结果
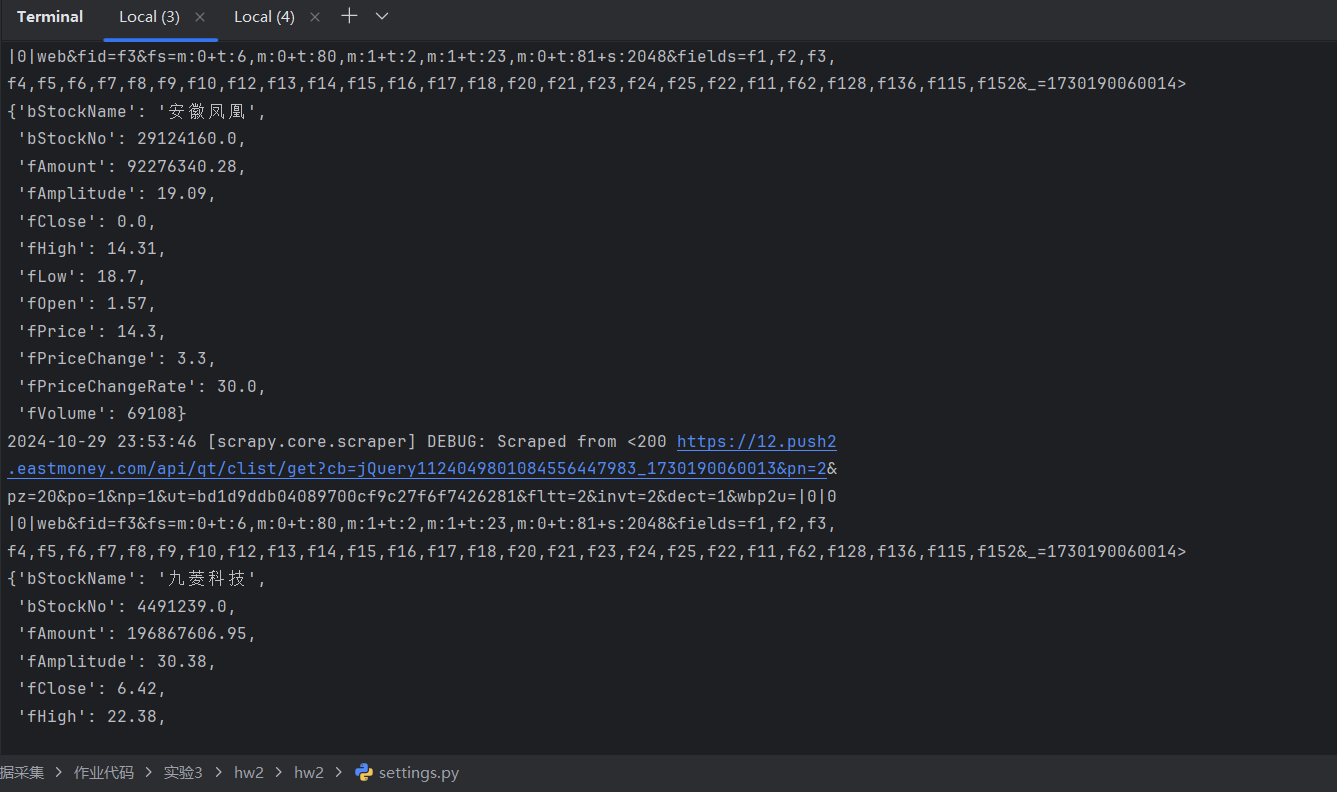
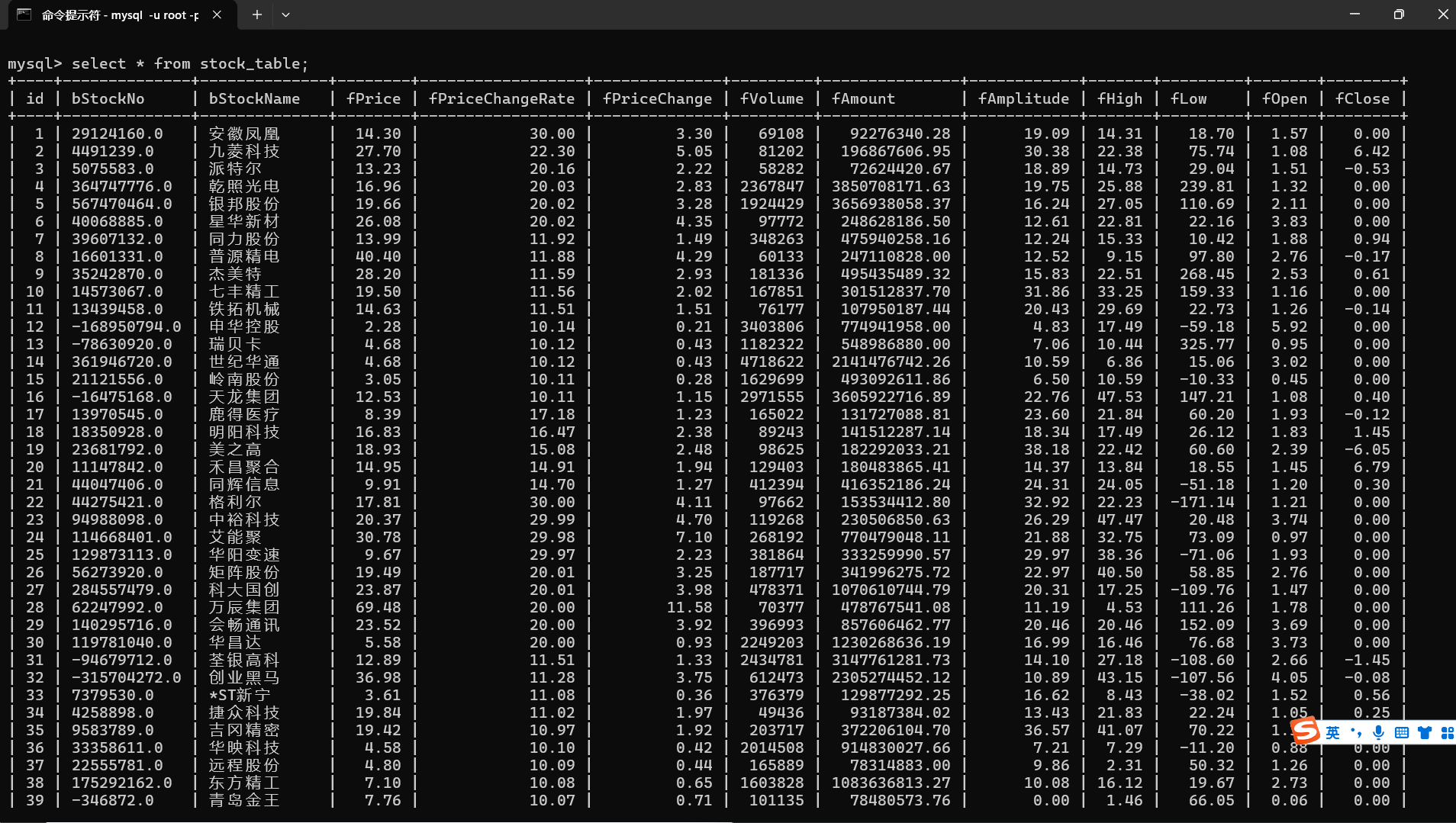
6.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业3/3.2/hw2
二、作业心得
一个一个对应数据库里面的表格属性进行插入,使用scrapy的pipline能够帮助我们更好地与数据库联通存储
3.外汇网站数据爬取
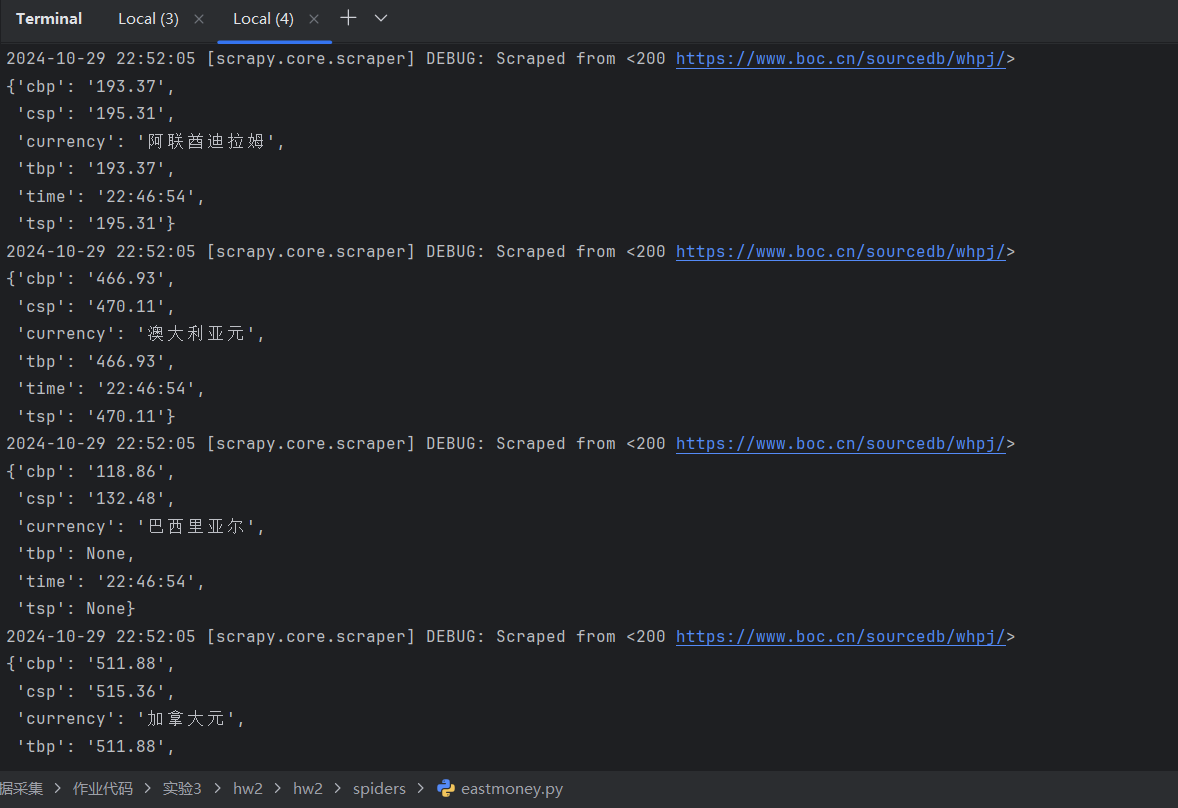
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
一、作业代码与展示
1.分析页面源代码
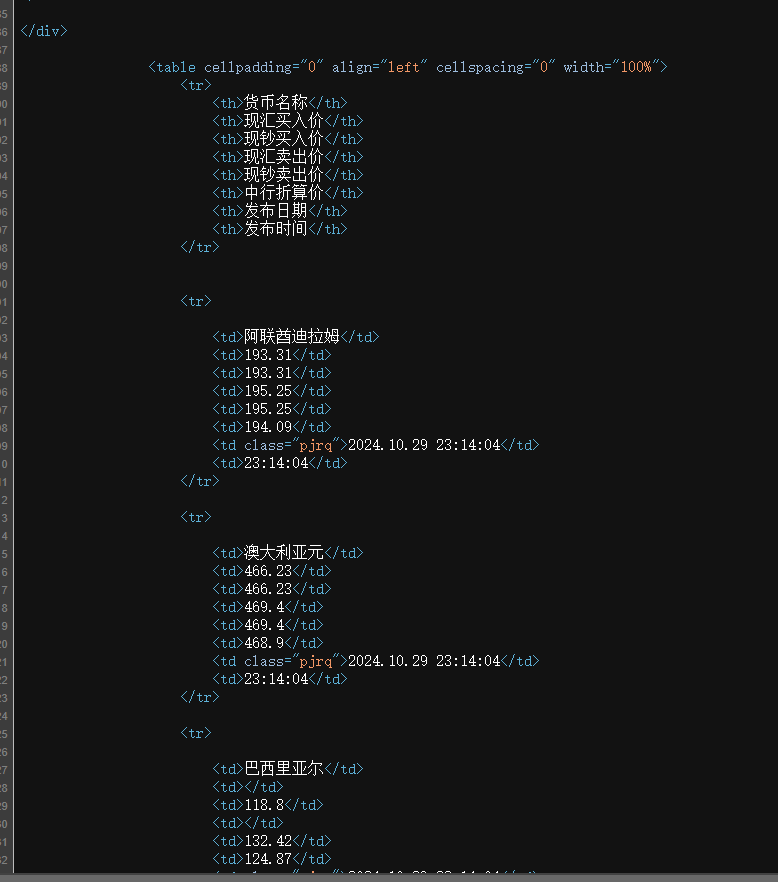
2.编写spider代码
import scrapy
from ..items import ForexItemclass SourceSpider(scrapy.Spider):name = 'source'allowed_domains = ['boc.cn']start_urls = ['https://www.boc.cn/sourcedb/whpj/']def parse(self, response):rows = response.xpath('//div/table/tr')for row in rows: # 跳过表头item = ForexItem()item['currency'] = row.xpath('./td[1]/text()').get()item['tbp'] = row.xpath('./td[2]/text()').get()item['cbp'] = row.xpath('./td[3]/text()').get()item['tsp'] = row.xpath('./td[4]/text()').get()item['csp'] = row.xpath('./td[5]/text()').get()item['time'] = row.xpath('./td[8]/text()').get()yield item
3.编写items代码
import scrapyclass ForexItem(scrapy.Item):currency = scrapy.Field() # 货币名称tbp = scrapy.Field() # 现汇买入价cbp = scrapy.Field() # 现钞买入价tsp = scrapy.Field() # 现汇卖出价csp = scrapy.Field() # 现钞卖出价time = scrapy.Field() # 发布时间
4.编写piplines代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterimport mysql.connector
from .items import ForexItemclass ForexPipeline:def open_spider(self, spider):self.connection = mysql.connector.connect(host='localhost',database='forex_db',user='root',password='2896685056Qq!')self.cursor = self.connection.cursor()def close_spider(self, spider):self.cursor.close()self.connection.close()def process_item(self, item, spider):self.cursor.execute("""INSERT INTO forex_rates (currency, tbp, cbp, tsp, csp, time)VALUES (%s, %s, %s, %s, %s, %s)""", (item['currency'],item['tbp'],item['cbp'],item['tsp'],item['csp'],item['time']))self.connection.commit()return item5.编写settings代码
BOT_NAME = 'hw3'SPIDER_MODULES = ['hw3.spiders']
NEWSPIDER_MODULE = 'hw3.spiders'ITEM_PIPELINES = {'hw3.pipelines.ForexPipeline': 300,
}# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '2896685056Qq!'
MYSQL_DB = 'forex_db'
运行结果