原文Github地址:https://github.com/clawerO-O/ASMA
一、研究动机
目前的后门攻击模型是基于数字像素上的操作,例如增加噪声,从而使得深度模型在推理阶段表现为不正常,但这种attack隐蔽性很差,可以被人眼所观察到。因为这些模型是在整个面部区域增加对抗性扰动,增加了许多冗余扰动。为此,作者提出adversarial semantic mask attack algorithm 来提高生成的对抗数据的质量以及隐蔽性。
[!TIP]
该算法的关键点在于限制增加扰动的范围,通过
class activation mapping,face semantic parsing module定位关键的语义区域
二、adversarial semantic mask attack algorithm
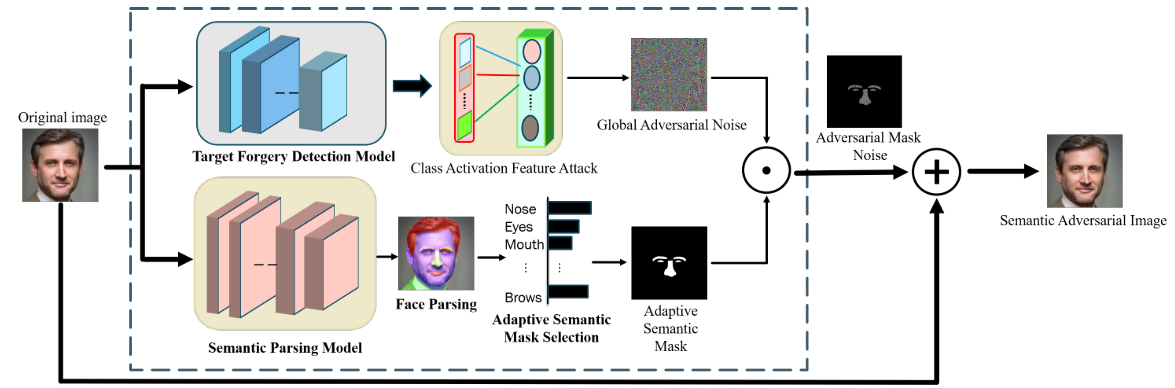
2.1 Adversarial Semantic Mask Attack Generation
[!NOTE]
类激活函数:将模型注意力与输入图像联系起来
模块的关键:干扰类激活函数的特征会影响到模型输出,得到对抗样本的假注意力后,对人脸的各个区域进行分割,通过计算不同区域的像素平均值作为伪造相关得分并进行排序,选择语义掩码区域加入对抗性噪声,以达到原图和对抗样本的距离最大化。
- 实现
首先将对抗样本初始化为原图像,在预训练好的伪造检测模型中分别提取两者的类激活特征\(\Phi_x\)和\(\Phi_x'\),利用两者的特征距离计算梯度更新对抗样本的特征

在对抗样本的更新过程中,还受到了扰动的制约
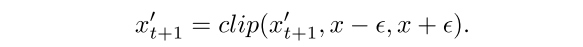
2.2 Adaptive Semantic Mask Selection
[!TIP]
由于需要选择语义掩码区域加入噪声,该文献利用了类激活函数自适应的选择语义掩码区域,采用语义分割算法对人的脸部进行语义分割,包括左眼、右眼、左眉、右眉、鼻子、上唇、下唇、嘴内、脸、头发或背景,在获得掩码后,与上一节中得到的类激活函数特征进行相加,得到最终的区域类激活特征,并在最后加入原图中得到对抗性样本。
三、数据与模型
- 人脸数据集
DFDC:包括了使用DeepFakes,face2face和一些其他的人脸生成和表情编辑算法。 特点:分辨率高,最高 3840\(\times\) 2160。选取1000张假图生成对抗攻击样本
- 人脸检测模型:
MobileNet_SSD, 并将检测到的人脸设置为320 \(\times\) 320。 - 训练和攻击模型:
XceptionNet,ResNet50,EfficientNet-B0, andEfficientNet-B4,检测模型训练50轮,采用Adam优化器。 - 对比的攻击算法:
FGSM[7],BIM[15],PGD[16],C&W[17],DeepFool[18],TRM[19]
四、实验
- 白盒和黑盒模型攻击对比
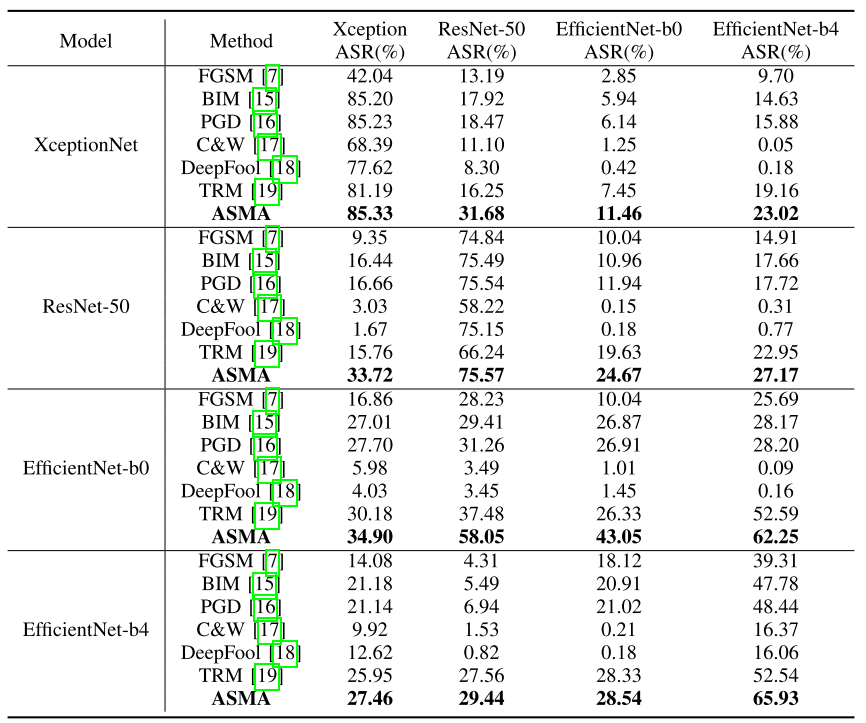
- 生成图像质量对比
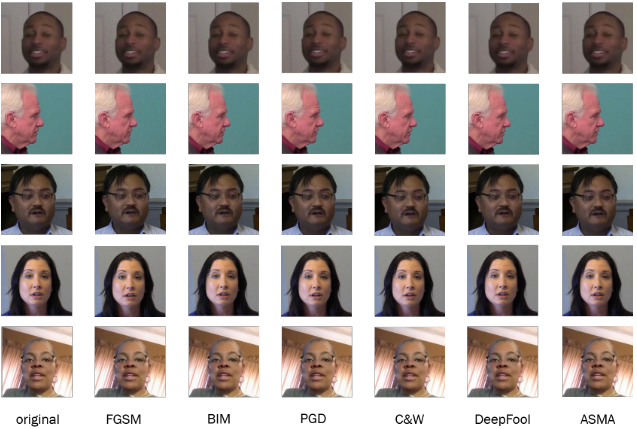
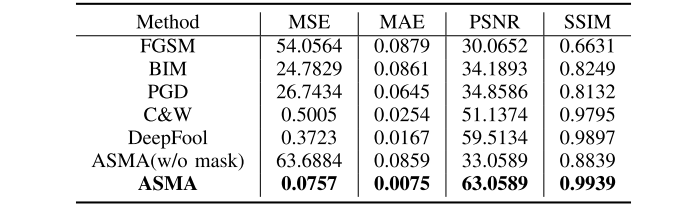
- 类激活函数的可视化分析结果

参考论文
- 目前主要的攻击方式:
- 基于补丁的方式:通过替换人脸的方式实现
- 转移化妆特征实现对抗性攻击;[9] [10]
- 最小话真实图像和攻击图像的统计差异;[12]
- 可视化技术:
Class Activation Mapping